LLM文档对话 —— pdf解析关键问题
一、为什么需要进行pdf解析?
最近在探索ChatPDF和ChatDoc等方案的思路,也就是用LLM实现文档助手。在此记录一些难题和解决方案,首先讲解主要思想,其次以问题+回答的形式展开。
二、为什么需要对pdf进行解析?
当利用LLMs实现用户与文档对话时,首要工作就是对文档中内容进行解析。
由于pdf是最通用,也是最复杂的文档形式,所以对pdf进行解析变成利用LLM实现用户与文档对话的重中之重工作。
如何精确地回答用户关于文档的问题,不重也不漏?笔者认为非常重要的一点是文档内容解析。如果内容都不能很好地组织起来,LLM只能瞎编。
三、pdf解析有哪些方法,对应的区别是什么?
pdf的解析大体上有两条路,一条是基于规则,一条是基于AI。
-
方法一:基于规则:
- 介绍:根据文档的组织特点去"算"每部分的样式和内容
- 存在问题:不通用,因为pdf的类型、排版实在太多了,没办法穷举
-
方法二:基于AI:
- 介绍:该方法为目标检测和OCR文字识别pipeline方法

- 介绍:该方法为目标检测和OCR文字识别pipeline方法
四、pdf解析存在哪些问题?
pdf转text这块存在一定的偏差,尤其是paper中包含了大量的figure和table,以及一些特殊的字符,直接调用langchain官方给的pdf解析工具,有一些信息甚至是错误的。
这里,一方面可以用arxiv的tex源码直接抽取内容,另一方面,可以尝试用各种ocr工具来提升表现。
五、如何长文档(书籍)中关键信息?
对于长文档(书籍),如何获取其中关键信息,并构建索引:
-
方法一:分块索引法
- 介绍:直接对长文档(书籍)进行分块,然后构建索引入库。后期问答,只需要从库中召回和用户query相关的内容块进行拼接成文章,输入到LLMs生成回复;
- 存在问题:
- 将文章分块,会破坏文章语义信息;
- 对于长文章,会被分割成很多块,并构建很多索引,这严重影响知识库存储空间;
- 如果内容都不能很好地组织起来,LLM只能瞎编;
-
方法二:文本摘要法
- 介绍:直接利用文本摘要模型对每一篇长文档(书籍)做文本摘要,然后对文本摘要内容构建索引入库。后期问答,只需要从库中召回和用户query相关的摘要内容,输入到LLMs生成回复;
- 存在问题:
- 由于每篇长文档(书籍)内容比较多,直接利用文本摘要模型对其做文本摘要,需要比较大算力成本和时间成本;
- 生成的文本摘要存在部分内容丢失问题,不能很好的概括整篇文章;
-
方法三:多级标题构建文本摘要法:
- 介绍:把多级标题提取出来,然后适当做语义扩充,或者去向量库检索相关片段,最后用LLM整合即可。
六、为什么要提取标题甚至是多级标题?
没有处理过LLM文档对话的朋友可能不明白为什么要提取标题甚至是多级标题,因此我先来阐述提取标题对于LLM阅读理解的重要性有多大。
- 如Q1阐述的那样,标题是快速做摘要最核心的文本;
- 对于有些问题high-level的问题,没有标题很难得到用户满意的结果。
举个栗子:假如用户就想知道3.2节是从哪些方面讨论的(标准答案就是3个方面),如果我们没有将标题信息告诉LLM,而是把所有信息全部扔给LLM,那它大概率不会知道是3个方面(要么会少,要么会多。做过的朋友秒懂)
七、如何提取文章标题?
- 第一步:pdf转图片。用一些工具将pdf转换为图片,这里有很多开源工具可以选,笔者采用fitz,一个python库。速度很快,时间在毫秒之间;
- 第二步:图片中元素(标题、文本、表格、图片、列表等元素)识别。采用目标检测模型识别元素。
- 工具介绍:
- Layout-parser:
- 优点:最大的模型(约800MB)精度非常高
- 缺点:速度慢一点
- PaddlePaddle-ppstructure:
- 优点:模型比较小,效果也还行
- unstructured:
- 缺点:fast模式效果很差,基本不能用,会将很多公式也识别为标题。其他模式或许可行,笔者没有尝试

- 缺点:fast模式效果很差,基本不能用,会将很多公式也识别为标题。其他模式或许可行,笔者没有尝试
- Layout-parser:
- 工具介绍:
利用上述工具,可以得到了一个list,存储所有检测出来的标题
- 第三步:标题级别判断。利用标题区块的高度(也就是字号)来判断哪些是一级标题,哪些是二级、三级、…N级标题。这个时候我们发现一些目标检测模型提取的区块并不是严格按照文字的边去切,导致这个idea不能实施,那怎么办呢?unstructured的fast模式就是按照文字的边去切的,同一级标题的区块高度误差在0.001之间。因此我们只需要用unstructured拿到标题的高度值即可(虽然繁琐,但是不耗时,unstructured处理也在毫秒之间)。
我们来看看提取效果,按照标题级别输出:

论文https://arxiv.org/pdf/2307.14893.pdf
八、如何区分单栏还是双栏pdf?如何重新排序?
- 动机:很多目标检测模型识别区块之后并不是顺序返回的,因此我们需要根据坐标重新组织顺序。单栏的很好办,直接按照中心点纵坐标排序即可。双栏pdf就很棘手了,有的朋友可能不知道pdf还有双栏形式

双栏论文示例
-
问题一:首先如何区分单双栏论文?
- 方法:得到所有区块的中心点的横坐标,用这一组横坐标的极差来判断即可,双栏论文的极差远远大于单栏论文,因此可以设定一个极差阈值。
-
问题二:双栏论文如何确定区块的先后顺序?
- 方法:先找到中线,将左右栏的区块分开,中线横坐标可以借助上述求极差的两个横坐标x1和x2来求,也就是(x1+x2)/2。分为左右栏区块后,对于每一栏区块按照纵坐标排序即可,最后将右栏拼接到左栏后边。
九、如何提取表格和图片中的数据?
思路仍然是目标检测和OCR。无论是layoutparser还是PaddleOCR都有识别表格和图片的目标检测模型,而表格的数据可以直接OCR导出为excel形式数据,非常方便。
- 以下是layoutparser demo的示例:

Layout parser效果示例
- 以下是PaddlePaddle的PP structure示例:

PP structure效果示例
提取出表格之后喂给LLM,LLM还是可以看懂的,可以设计prompt做一些指导。关于这一块两部分demo代码都很清楚明白,这里不再赘述。
十、基于AI的文档解析有什么优缺点?
- 优点:准确率高,通用性强。
- 缺点:耗时慢,建议用GPU等加速设备,多进程、多线程去处理。耗时只在目标检测和OCR两个阶段,其他步骤均不耗时。
总结
笔者建议按照不同类型的pdf做特定处理,例如论文、图书、财务报表、PPT都可以根据特点做一些小的专有设计。
没有GPU的话目标检测模型建议用PaddlePaddle提供的,速度很快。Layout parser只是一个框架,目标检测模型和OCR工具可以自有切换。
相关文章:
LLM文档对话 —— pdf解析关键问题
一、为什么需要进行pdf解析? 最近在探索ChatPDF和ChatDoc等方案的思路,也就是用LLM实现文档助手。在此记录一些难题和解决方案,首先讲解主要思想,其次以问题回答的形式展开。 二、为什么需要对pdf进行解析? 当利用L…...

MySQL单表查询时索引使用情况
本文针对 MySQL 单表查询时索引使用的几种场景情况进行分析。 假设有一个表如下: CREATE TABLE single_table (id INT NOT NULL AUTO_INCREMENT,key1 VARCHAR(100),key2 INT,key3 VARCHAR(100),key_part1 VARCHAR(100),key_part2 VARCHAR(100),key_part3 VARCHAR(1…...

Qt邮箱程序改良版(信号和槽)
上一版代码可以正常使用,但是会报错 上一篇文章 错误信息 "QSocketNotifier: Socket notifiers cannot be enabled or disabled from another thread" 指出了一个问题,即在非主线程中尝试启用或禁用套接字通知器(QSocketNotifier)…...

入门到精通mysql数据(四)
5、运维篇 5.1、日志 5.1.1、错误日志 错误日志是MySQL中最重要的日志之一,它记录了当mysqld启动和停止,以及服务器在运行过程中发生任何严重错误时的相关信息。当数据库出现任何故障导致无法正常使用时,建议首先查看此日志。 该日志是默认开启的,默认存放目录/var/log…...

Java 设计模式 详解
在Java开发中,设计模式是一种常见的、成熟的解决方案,用于应对特定的设计问题和复杂性管理。以下是一些常用的设计模式,它们可以分为三类:创建型模式、结构型模式和行为型模式。 一、创建型模式 创建型模式主要负责对象的创建&a…...

卡尔曼滤波学习资料汇总
卡尔曼滤波学习资料汇总 其实,当初的目的,是为了写 MPU6050 的代码的,然后不知不觉学了那么多,也是因为好奇、感兴趣吧 有些还没看完,之后笔记也会同步更新的 学习原始材料 【卡尔曼滤波器】1_递归算法_Recursive P…...

linux003.在ubuntu中安装cmake的方法
1.cmake安装程序下载 https://cmake.org/files/v3.30/ 2.解压并下载包 解压cmake压缩包 tar -xvzf cmake.tar.gz进入解压目录 cd cmake-<version>编辑~/.bashrc nano ~/.bashrc在文件的末尾添加如下代码 export PATH/home/xwl/software/cmake/bin:$PATH然后运行以…...

EtherNet/IP转Profinet网关连接发那科机器人配置实例解析
本案例主要展示了如何通过Ethernet/IP转Profinet网关实现西门子1200PLC与发那科搬运机器人的连接。所需的设备有西门子1200PLC、开疆智能Ethernet/IP转Profinet网关以及Fanuc机器人。 具体配置步骤:打开西门子博图配置软件,添加PLC。这是配置的第一步&am…...
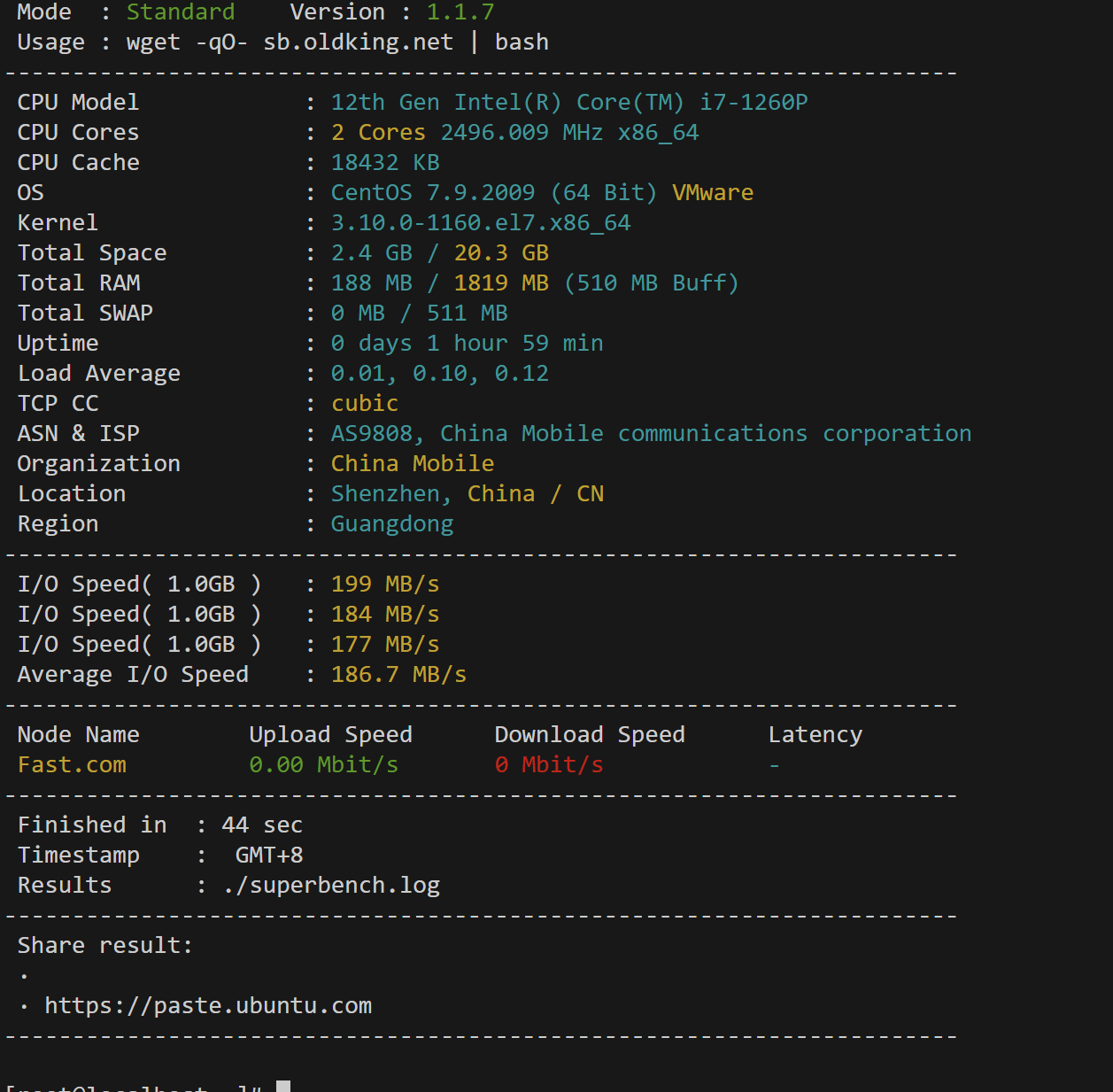
自动化运维-检测Linux服务器CPU、内存、负载、IO读写、机房带宽和服务器类型等信息脚本
前言:以上脚本为今年8月1号发布的,当时是没有任何问题,但现在脚本里网络速度测试py文件获取不了了,测速这块功能目前无法实现,后面我会抽时间来研究,大家如果有建议也可以分享下。 脚本内容: #…...

ubuntu24.04设置开机自启动Eureka
ubuntu24.04设置开机自启动Eureka 之前我们是在/root/.bashrc的文件中增加了一条命令 nohup java -jar /usr/software/eurekaServer-auth-prd-03.jar > /usr/software/log.log 2>&1 &但上面这条命令只有在登录root的用户时,才会执行,如果…...

从视频帧生成点云数据、使用PointNet++模型提取特征,并将特征保存下来的完整实现。
文件地址 https://github.com/yanx27/Pointnet_Pointnet2_pytorch?spm5176.28103460.0.0.21a95d27ollfze Pointnet_Pointnet2_pytorch\log\classification\pointnet2_ssg_wo_normals文件夹改名为Pointnet_Pointnet2_pytorch\log\classification\pointnet2_cls_ssg "E:…...

工化企业内部能源能耗过大 落实能源管理
一、精准监测与数据分析 实时准确的数据采集 企业能耗管理系统能够对企业内各种能源(如电、水、气、热等)的使用情况进行实时监测。通过安装在能源供应线路和设备上的智能传感器,可以精确地采集能源消耗的各项数据,包括瞬时流量、…...

LSTM 和 LSTMCell
1. LSTM 和 LSTMCell 的简介 LSTM (Long Short-Term Memory): 一种特殊的 RNN(循环神经网络),用于解决普通 RNN 中 梯度消失 或 梯度爆炸 的问题。能够捕获 长期依赖关系,适合处理序列数据(如自然语言、时间序列等&…...

python成长技能之正则表达式
文章目录 一、认识正则表达式二、使用正则表达式匹配单一字符三、正则表达式之重复出现数量匹配四、使用正则表达式匹配字符集五、正则表达式之边界匹配六、正则表达式之组七、正则表达式之贪婪与非贪婪 一、认识正则表达式 什么是正则表达式 正则表达式(英语&…...

解决docker报Error response from daemon Get httpsregistry-1.docker.iov2错误
解决docker报Error response from daemon: Get "https://registry-1.docker.io/v2/"错误 报错详情 首先先看一下问题报错效果,我想要拉去nacos-serve:1.1.4的镜像,报如下错误,从报错信息可以看到,用于网络的愿意&…...

【论文分享】利用多源大数据衡量街道步行环境的老年友好性:以中国上海为例
本次给大家带来一篇SCI论文的全文翻译!该论文考虑了绿化程度、可步行性、安全性、形象性、封闭性和复杂性这六个指标,提出了一种基于多源地理空间大数据的新型定量评价模型,用于从老年人和专家的角度评估街道步行环境的老年友好程度ÿ…...

说说软件工程中的“协程”
在软件工程中,协程(coroutine)是一种程序运行的方式,可以理解成“协作的线程”或“协作的函数”。以下是对协程的详细解释: 一、协程的基本概念 定义:协程是一组序列化的子过程,用户能像指挥家…...

使用IDE实现java端远程调试功能
使用IDE实现java端远程调试功能 1. 整体描述2. 前期准备3. 具体操作3.1 修改启动命令3.2 IDE配置3.3 打断点3.4 运行Debug 4. 总结 1. 整体描述 在做项目时,有些时候,需要和第三方进行调式,但是第三方不在一起,需要进行远程调试&…...

javaScript交互案例2
1、京东侧边导航条 需求: 原先侧边栏是绝对定位当页面滚动到一定位置,侧边栏改为固定定位页面继续滚动,会让返回顶部显示出来 思路: 需要用到页面滚动事件scroll,因为是页面滚动,所以事件源是document滚动…...

JavaScript 浏览器对象模型 BOM
浏览器对象模型(Browser Object Model,BOM)是指一组与浏览器进行交互的 JavaScript 对象。它允许 JavaScript 与浏览器的组件进行交互,比如窗口、文档、历史记录等。BOM 不同于 DOM(文档对象模型)ÿ…...


AUTOSAR Wdg模块的两种“狗”:片内看门狗与SPI外挂看门狗配置异同点解析
AUTOSAR Wdg模块深度解析:片内与SPI外挂看门狗的工程实践指南 在汽车电子控制单元(ECU)开发中,看门狗(Watchdog)模块是确保系统可靠性的关键组件。AUTOSAR标准下的Wdg模块支持两种典型硬件架构——片内集成…...

3分钟掌握B站缓存视频转换:m4s-converter终极使用指南
3分钟掌握B站缓存视频转换:m4s-converter终极使用指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾经遇到过这样的困扰&a…...

NVIDIA显卡终极调校指南:用Profile Inspector释放游戏潜能的简单方法
NVIDIA显卡终极调校指南:用Profile Inspector释放游戏潜能的简单方法 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector 还在为游戏卡顿、画面撕裂而烦恼吗?NVIDIA Profile Inspect…...

41《CAN总线报文周期、抖动与实时性分析》
CAN总线基础:从物理层到数据链路层的核心概念 一、一个让我熬夜的CAN问题 去年调试某款车载ECU时遇到个诡异现象:同一批次的控制器,有的在-20℃低温下CAN通信完全正常,有的却频繁丢帧。示波器挂上去一看,显性电平的下降沿斜率明显变缓,从正常的15ns拖到了40ns。查了三天…...

告别本地卡顿!用Pycharm 2023.3远程连接Spark集群,5步搞定开发环境
告别本地卡顿!用Pycharm 2023.3远程连接Spark集群,5步搞定开发环境 当你的笔记本风扇开始像喷气发动机一样轰鸣,而PySpark脚本才处理到第3万条数据时,就该考虑换个战场了。去年我用一台16GB内存的MacBook Pro分析800万条电商日志&…...

AD19原理图编译总报off grid pin警告?手把手教你从库源头搞定封装与栅格对齐
AD19原理图编译报off grid pin警告?从库源头解决封装与栅格对齐问题 每次在AD19中编译原理图时,看到那一长串的"off grid pin"警告,是不是感觉特别烦躁?这些看似无害的警告实际上可能隐藏着严重的设计隐患。作为一位经历…...

【仅限首批Early Access用户】Claude 3.5 Sonnet的“动态温度调节”机制详解:如何让模型在严谨性与创意性间智能切换?
更多请点击: https://intelliparadigm.com 第一章:Claude 3.5 Sonnet新功能详解 Anthropic 正式发布的 Claude 3.5 Sonnet 在推理速度、多模态理解与工具调用能力上实现显著跃升,尤其在代码生成与结构化输出方面表现突出。该模型原生支持 JS…...
)
别再为手眼标定头疼了!用Matlab+机器人工具箱搞定Eye-in-Hand/Eye-to-Hand(附完整代码)
机器人视觉实战:从零实现手眼标定与平面九点标定 在工业自动化领域,机器人视觉系统的精度直接影响着抓取、装配等关键任务的可靠性。许多工程师在理论阶段能够理解手眼标定的数学原理,但一到实际代码实现环节就陷入困境——数据格式如何准备…...

OpenClaw 汉化版 Windows 一键安装指南|零基础 5 分钟部署 告别命令行
前言 在本地部署 AI 智能体时,英文界面晦涩、命令行操作复杂、环境配置繁琐,是很多零基础用户的三大痛点。OpenClaw 汉化中文版专为国内用户优化,采用全中文图形化界面 免环境配置 一键部署设计,全程无任何命令行操作ÿ…...