【机器学习】机器学习中用到的高等数学知识-7.信息论 (Information Theory)
- 熵 (Entropy):用于评估信息的随机性,常用于决策树和聚类算法。
- 交叉熵 (Cross-Entropy):用于衡量两个概率分布之间的差异,在分类问题中常用。
信息论作为处理信息量和信息传输的数学理论,在机器学习中具有广泛的应用。本文将围绕熵(Entropy)和交叉熵(Cross-Entropy),探讨它们的定义、公式推导、应用场景及代码实现。
1. 熵 (Entropy)
1.1 定义
熵衡量信息的不确定性或随机性。它可以理解为“信息的平均量”,即某一分布下每个事件的信息量的期望值。
1.2 数学公式
对于一个离散随机变量 X,取值为 ,其熵定义为:
其中:
是事件
的概率;
- log 通常以 2 为底(信息量以比特为单位)或以 e 为底(信息量以 nat 为单位)。
1.3 推导过程
熵的来源可以从信息量(Information Content)定义出发:
熵是信息量的加权平均值,因而有:
1.4 应用场景
- 决策树算法:选择分裂点时使用熵减少量(信息增益)。
- 聚类算法:评估聚类后类别分布的随机性。
- 语言模型:评估文本序列的不确定性。
1.5 熵的Python代码实现
import numpy as np# 定义熵函数
def entropy(p):return -np.sum(p * np.log2(p))# 示例概率分布
p = np.array([0.5, 0.25, 0.25])
print("熵:", entropy(p))
熵: 1.51.6 图示
熵的图示展示了单一事件概率分布变化时的熵值变化。
import matplotlib.pyplot as plt
import numpy as npp = np.linspace(0.01, 0.99, 100)
entropy_values = -p * np.log2(p) - (1 - p) * np.log2(1 - p)plt.plot(p, entropy_values, label='Entropy')
plt.xlabel('P(x)')
plt.ylabel('H(X)')
plt.title('Entropy vs Probability')
plt.legend()
plt.grid()
plt.show()

2. 交叉熵 (Cross-Entropy)
2.1 定义
交叉熵用于衡量两个概率分布之间的差异。给定真实分布 P 和预测分布 Q,其定义为:
当 P 和 Q 相等时,交叉熵退化为熵。
2.2 推导过程
交叉熵的来源是 Kullback-Leibler (KL) 散度:
其中:
说明交叉熵包含了真实分布的熵和两分布之间的 KL 散度。
2.3 应用场景
- 分类问题:在机器学习中作为目标函数,尤其是多分类问题中的 Softmax 回归。
- 语言模型:衡量生成模型输出的分布与目标分布的匹配度。
- 聚类算法:评估聚类后的分布与目标分布的差异。
2.4 交叉熵的Python代码实现
import numpy as np# 定义交叉熵函数
def cross_entropy(p, q):return -np.sum(p * np.log2(q))# 示例真实分布和预测分布
p = np.array([1, 0, 0]) # 实际类别
q = np.array([0.7, 0.2, 0.1]) # 预测分布
print("交叉熵:", cross_entropy(p, q))
交叉熵: 0.51457317282975832.5 图示
交叉熵的图示对比了真实分布和不同预测分布间的差异。
import matplotlib.pyplot as plt
import numpy as npdef cross_entropy(p, q):return -np.sum(p * np.log2(q))p = np.array([1, 0, 0])
q_values = [np.array([0.7, 0.2, 0.1]), np.array([0.4, 0.4, 0.2])]ce_values = [cross_entropy(p, q) for q in q_values]
labels = ['Q1 (Closer)', 'Q2 (Further)']plt.bar(labels, ce_values, color=['blue', 'orange'])
plt.title('Cross-Entropy Comparison')
plt.ylabel('Cross-Entropy')
plt.show()
3. 实际案例:分类问题中的交叉熵
在图像分类中,交叉熵是常用的损失函数。对于一个三类分类问题:
- 真实类别为 [1, 0, 0]。
- 模型预测的概率分布为 [0.7, 0.2, 0.1]。
交叉熵计算结果为 0.514,比完全随机预测([1/3, 1/3, 1/3])的交叉熵小,表明模型预测效果更好。
总结
熵和交叉熵是信息论中的核心概念,其在机器学习中的重要性不可忽视。通过公式理解、代码实现和图示分析,我们可以更好地掌握这些工具,并有效地将其应用于实际问题中。
拓展阅读
【机器学习】数学知识:对数-CSDN博客
【机器学习】机器学习中用到的高等数学知识-2.概率论与统计 (Probability and Statistics)_机器学习概率-CSDN博客
相关文章:
【机器学习】机器学习中用到的高等数学知识-7.信息论 (Information Theory)
熵 (Entropy):用于评估信息的随机性,常用于决策树和聚类算法。交叉熵 (Cross-Entropy):用于衡量两个概率分布之间的差异,在分类问题中常用。 信息论作为处理信息量和信息传输的数学理论,在机器学习中具有广泛的应用。…...
《现代制造技术与装备》是什么级别的期刊?是正规期刊吗?能评职称吗?
问题解答 问:《现代制造技术与装备》是不是核心期刊? 答:不是,是知网收录的第二批认定学术期刊。 问:《现代制造技术与装备》级别? 答:省级。主管单位:齐鲁工业大学࿰…...

09 - Clickhouse的SQL操作
目录 1、Insert 1.1、标准 1.2、从表到表的插入 2、Update和Delete 2.1、删除操作 2.2、修改操作 3、查询操作 3.1、with rollup:从右至左去掉维度进行小计 3.2、with cube : 从右至左去掉维度进行小计,再从左至右去掉维度进行小计 3.3、with …...

如何解决pdf.js跨域从url动态加载pdf文档
摘要 当我们想用PDF.js从URL加载文档时,将会因遇到跨域问题而中断,且是因为会触发了PDF.js和浏览器的双重CORS block,这篇文章将会介绍:①如何禁用pdf.js的跨域?②如何绕过浏览器的CORS加载URL文件?②如何使…...
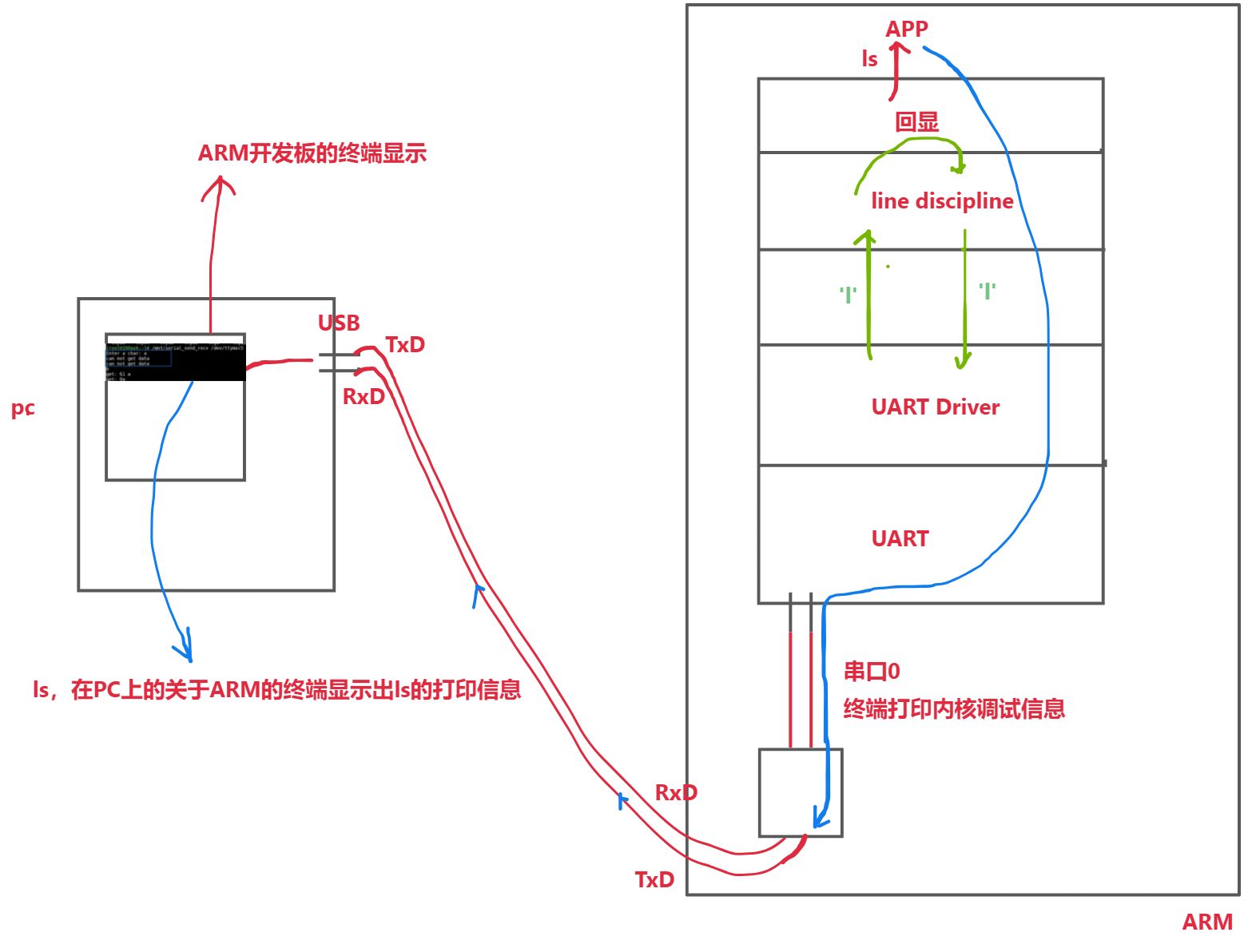
深入理解TTY体系:设备节点与驱动程序框架详解
往期内容 本专栏往期内容:Uart子系统 UART串口硬件介绍 interrupt子系统专栏: 专栏地址:interrupt子系统Linux 链式与层级中断控制器讲解:原理与驱动开发 – 末片,有专栏内容观看顺序 pinctrl和gpio子系统专栏…...
)
库的操作(MySQL)
1.创建数据库 语法: CREATE DATABASE [IF NOT EXISTS] db_name [create_specification [, create_specification] ...] create_specification:[DEFAULT] CHARACTER SET charset_name[DEFAULT] COLLATE collation_name说明: 大写的表示关键字 [ ] 是可…...

在 for 循环中,JVM可能会将 arr.length 提升到循环外部,仅计算一次。可能会将如何解释 详解
在 Java 的 for 循环中,JVM 有能力进行优化,将 arr.length 的访问提升到循环外部,避免每次迭代都重新计算 arr.length。这种优化主要是由于 JVM 的 即时编译器(JIT) 和 逃逸分析(Escape Analysis࿰…...

回溯--数据在内存中的存储:整数、大小端和浮点数的深度解析
目录 引言 1. 整数在内存中的存储 1.1 原码、反码和补码 1.2 为什么使用补码? 1.3 示例代码:整数的存储 2. 大小端字节序和字节序判断 2.1 什么是大端和小端? 2.2 为什么会有大端和小端之分? 2.3 字节序的判断小程序 2.…...

第二十二章 Spring之假如让你来写AOP——Target Object(目标对象)篇
Spring源码阅读目录 第一部分——IOC篇 第一章 Spring之最熟悉的陌生人——IOC 第二章 Spring之假如让你来写IOC容器——加载资源篇 第三章 Spring之假如让你来写IOC容器——解析配置文件篇 第四章 Spring之假如让你来写IOC容器——XML配置文件篇 第五章 Spring之假如让你来写…...

探索设计模式:原型模式
设计模式之原型模式 🧐1. 概念🎯2. 原型模式的作用📦3. 实现1. 定义原型接口2. 定义具体的原型类3. 定义客户端4. 结果 📰 4. 应用场景🔍5. 深拷贝和浅拷贝 在面向对象编程中,设计模式是一种通用的解决方案…...
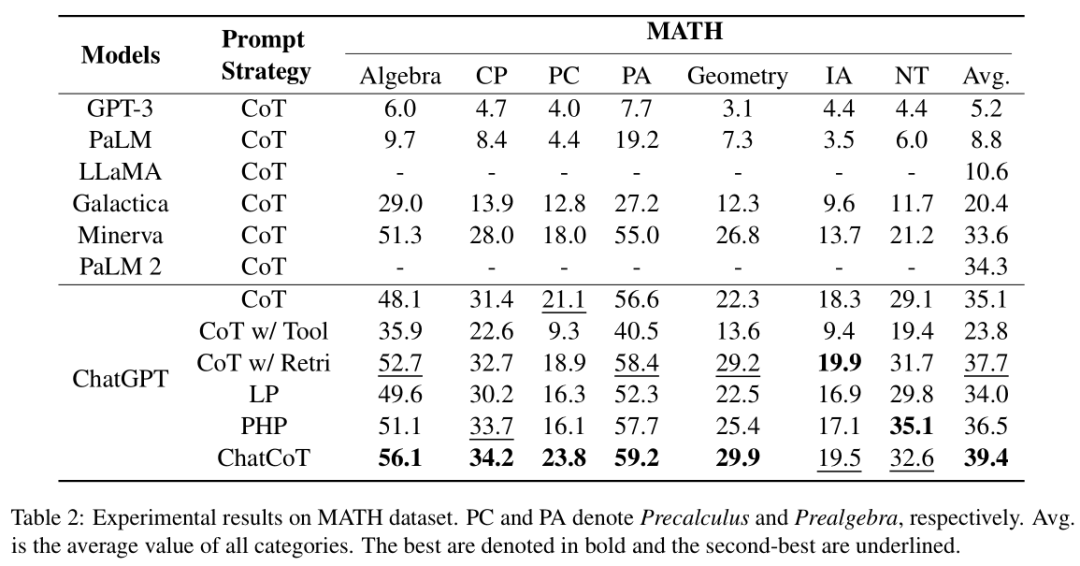
NLP论文速读(EMNLP 2023)|工具增强的思维链推理
论文速读|ChatCoT: Tool-Augmented Chain-of-Thought Reasoning on Chat-based Large Language Models 论文信息: 简介: 本文背景是关于大型语言模型(LLMs)在复杂推理任务中的表现。尽管LLMs在多种评估基准测试中取得了优异的成绩…...

JVM垃圾回收详解.②
空间分配担保 空间分配担保是为了确保在 Minor GC 之前老年代本身还有容纳新生代所有对象的剩余空间。 《深入理解 Java 虚拟机》第三章对于空间分配担保的描述如下: JDK 6 Update 24 之前,在发生 Minor GC 之前,虚拟机必须先检查老年代最大…...

什么是事务,事务有什么特性?
事务的四大特性(ACID) 原子性(Atomicity) 解释:原子性确保事务中的所有操作要么全部完成,要么全部不做。这意味着事务是一个不可分割的工作单元。在数据库中,这通常通过将事务的操作序列作为一个…...

深入解析:如何使用 PyTorch 的 SummaryWriter 进行深度学习训练数据的详细记录与可视化
深入解析:如何使用 PyTorch 的 SummaryWriter 进行深度学习训练数据的详细记录与可视化 为了更全面和详细地解释如何使用 PyTorch 的 SummaryWriter 进行模型训练数据的记录和可视化,我们可以从以下几个方面深入探讨: 初始化 SummaryWriter…...

企业微信中设置回调接口url以及验证 spring boot项目实现
官方文档: 接收消息与事件: 加密解密文档:加解密库下载与返回码 - 文档 - 企业微信开发者中心 下载java样例 加解密库下载与返回码 - 文档 - 企业微信开发者中心 将解压开的代码 ‘将文件夹:qq\weixin\mp\aes的代码作为工具拷…...

电脑超频是什么意思?超频的好处和坏处
嗨,亲爱的小伙伴!你是否曾经听说过电脑超频?在电脑爱好者的圈子里,这个词似乎非常熟悉,但对很多普通用户来说,它可能还是一个神秘而陌生的存在。 今天,我将带你揭开超频的神秘面纱,…...
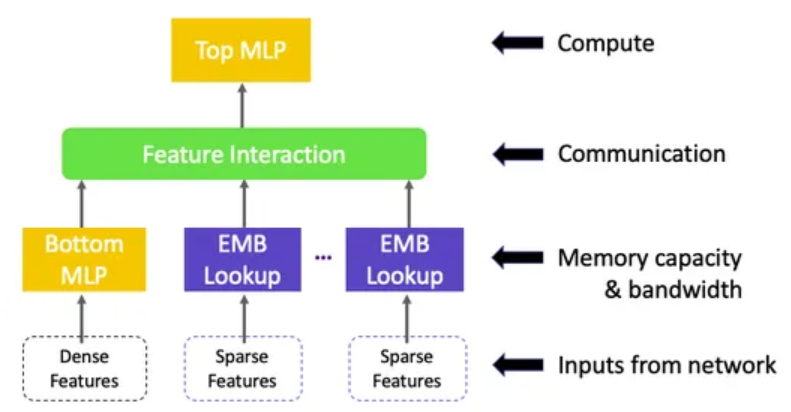
在 AMD GPU 上构建深度学习推荐模型
Deep Learning Recommendation Models on AMD GPUs — ROCm Blogs 2024 年 6 月 28 日 发布者 Phillip Dang 在这篇博客中,我们将演示如何在支持 ROCm 的 AMD GPU 上使用 PyTorch 构建一个简单的深度学习推荐模型 (DLRM)。 简介 DLRM 位于推荐系统和深度学习的交汇…...

阿里云IIS虚拟主机部署ssl证书
宝塔配置SSL证书用起来是很方便的,只需要在站点里就可以配置好,但是云虚拟主机在管理的时候是没有这个权限的,只提供了简单的域名管理等信息。 此处记录下阿里云(原万网)的IIS虚拟主机如何配置部署SSL证书。 进入虚拟…...

Python运算符列表
运算符 描述 xy,x—y 加、减,“"号可重载为连接符 x*y,x**y,x/y,x%y 相乘、求平方、相除、求余,“*”号可重载为重复,“%"号可重载为格式化 <,<,&…...

MFC图形函数学习09——画多边形函数
这里所说的多边形是指在同一平面中由多条边构成的封闭图形,强调封闭二字,否则无法进行颜色填充,多边形包括凸多边形和凹多边形。 一、绘制多边形函数 原型:BOOL Polygon(LPPOINT lpPoints,int nCount); 参数&#x…...

信发系统-排版/发布 配置操作教程-智慧大屏幕—东方仙盟
政务大屏幕节目管理-选择系统模板选择对应行业选择适合的模板选中你的节目点击设计设计节目直接管理/上传 资源:图片/视频/网页/文字/文档手指/鼠标选中显示区域上传资源,在右侧点击上传从资源库选择图片选择历史素材上传网站选中网页区域点击上传配置文…...

算力入门:从FLOPS到PUE全解析
算力入门:FLOPS、TFLOPS、EFLOPS、算力规模、能效比、PUE 全解 算力(计算能力)是衡量计算机系统性能的关键指标,尤其在科学计算、人工智能和大数据处理等领域至关重要。本指南将逐步解释FLOPS、TFLOPS、EFLOPS、算力规模、能效比和PUE这些核心概念,帮助您快速入门。所有内…...

STM32+EMMC+GL3227E固件调试:从扇区偏移到数据同步的实战解析
1. 问题现象与背景分析 最近在调试一个嵌入式存储系统时遇到了奇怪的现象:STM32主控将数据写入EMMC存储后,通过GL3227E桥接芯片连接电脑却无法识别。更诡异的是,电脑格式化后的EMMC,STM32写入的数据在电脑端又"消失"了。…...

从零构建现代化个人作品集网站:技术选型、架构设计与性能优化实战
1. 项目概述与核心价值 最近在GitHub上看到一个挺有意思的项目,叫“YasirAwan4831/arch-technologies-internship-task-1-portfolio-website”。光看这个仓库名,信息量其实不小。这明显是一个实习生的任务项目,来自一家叫“Arch Technologies…...

别再只把PCA当降维工具了!用它处理三维点云,5分钟搞定地面和墙面分割
别再只把PCA当降维工具了!用它处理三维点云,5分钟搞定地面和墙面分割 当我们在处理三维点云数据时,常常会遇到需要将地面、墙面和其他物体点进行分割的场景。传统方法可能需要复杂的算法和大量的计算资源,但今天我要分享的是一个…...

利用大模型分歧优化NLP标注
In this blogpost I’d like to talk about large language models. There’s a bunch of hype, sure, but there’s also an opportunity to revisit one of my favourite machine learning techniques: disagreement. 在本文中,我想讨论大语言模型。虽然存在大量炒…...

从入门到精通:Systrace性能分析实战指南
1. Systrace入门:认识Android性能分析利器 第一次打开Systrace报告时,我完全被那些彩色线条和条形图搞懵了。这玩意儿看起来就像地铁线路图一样复杂,但别担心,它其实是Android开发者最得力的性能分析助手。Systrace是Android SDK自…...

【信息科学与工程学】【财务管理】 第二十三篇 ICT行业商业逻辑分析框架03
136. 硅光子集成芯片的激光器外延片 行业代码 行业名称 行业级别 产品/服务 商业逻辑核心 投资者类型与代表公司/机构 外部关系类型与关联公司 销售与买卖经营 供应链经营 利益/利润设计/资源绑定/信息宣传 分销商/代理商/关系节点 销售策略、打法与复杂关系网络 3…...

Linux下Cursor IDE智能安装器:企业级Bash脚本设计与实践
1. 项目概述:一个为Linux而生的Cursor IDE智能安装器如果你是一名在Linux环境下工作的开发者,并且对Cursor这款集成了AI辅助编程能力的现代IDE感兴趣,那么你很可能已经遇到过那个经典难题:如何优雅地在Linux上安装它?官…...

sndcpy:Android设备音频转发终极指南
sndcpy:Android设备音频转发终极指南 【免费下载链接】sndcpy Android audio forwarding PoC (scrcpy, but for audio) 项目地址: https://gitcode.com/gh_mirrors/sn/sndcpy 想要在电脑上享受Android设备的音频体验吗?sndcpy音频转发工具正是您需…...