问题: redis-高并发场景下如何保证缓存数据与数据库的最终一致性
在高并发场景下,Redis 通常用作缓存层,与数据库结合使用以提高系统的性能。为了保证缓存数据与数据库的最终一致性,通常采用的有双写机制、缓存失效机制,基于双写机制、缓存失效机制又衍生出来了消息队列、事件驱动架构等
常见机制
常见的机制如下,个人理解无非是先后或各种手段操作数据库、redis,代码ai给写的示列只需看懂即可。
- 双写机制
在更新数据库的同时,同步更新缓存。
适用于写操作较少的场景
public class CacheService {private final JdbcTemplate jdbcTemplate;private final RedisTemplate<String, Object> redisTemplate;public void updateData(String key, String value) {// 更新数据库jdbcTemplate.update("UPDATE table SET value = ? WHERE key = ?", value, key);// 更新缓存redisTemplate.opsForValue().set(key, value);}
- 缓存失效机制
在更新数据库后,删除缓存中的旧数据,读取数据时候时写入缓存
适用于写操作频繁的场景。
public class CacheService {private final JdbcTemplate jdbcTemplate;private final RedisTemplate<String, Object> redisTemplate;public void updateData(String key, String value) {// 更新数据库jdbcTemplate.update("UPDATE table SET value = ? WHERE key = ?", value, key);// 删除缓存redisTemplate.delete(key);}public String getData(String key) {// 从缓存中获取数据String value = (String) redisTemplate.opsForValue().get(key);if (value == null) {// 缓存未命中,从数据库中获取数据value = jdbcTemplate.queryForObject("SELECT value FROM table WHERE key = ?", new Object[]{key}, String.class);if (value != null) {// 将数据写入缓存redisTemplate.opsForValue().set(key, value);}}return value;}}
- 消息队列机制
使用消息队列异步更新redis,确保数据的一致性。
适用于高并发写操作的场景。
import com.rabbitmq.client.Channel;import com.rabbitmq.client.Connection;import com.rabbitmq.client.ConnectionFactory;public class CacheService {private final JdbcTemplate jdbcTemplate;private final RedisTemplate<String, Object> redisTemplate;public void updateData(String key, String value) {// 更新数据库jdbcTemplate.update("UPDATE table SET value = ? WHERE key = ?", value, key);// 发送消息到消息队列sendUpdateMessage(key, value);}private void sendUpdateMessage(String key, String value) {ConnectionFactory factory = new ConnectionFactory();factory.setHost("localhost");try (Connection connection = factory.newConnection();Channel channel = connection.createChannel()) {channel.queueDeclare("cache_update_queue", true, false, false, null);channel.basicPublish("", "cache_update_queue", null, (key + ":" + value).getBytes());} catch (Exception e) {e.printStackTrace();}}public void consumeUpdateMessages() {ConnectionFactory factory = new ConnectionFactory();factory.setHost("localhost");try (Connection connection = factory.newConnection();Channel channel = connection.createChannel()) {channel.queueDeclare("cache_update_queue", true, false, false, null);DeliverCallback deliverCallback = (consumerTag, delivery) -> {String message = new String(delivery.getBody(), "UTF-8");String[] parts = message.split(":");String key = parts[0];String value = parts[1];// 更新缓存redisTemplate.opsForValue().set(key, value);};channel.basicConsume("cache_update_queue", true, deliverCallback, consumerTag -> {});} catch (Exception e) {e.printStackTrace();}}}
- 事件驱动机制
使用事件驱动架构,当数据库数据发生变化时,触发事件,事件处理器负责更新缓存。
适用于复杂的数据更新逻辑。
import org.springframework.context.ApplicationEventPublisher;import org.springframework.context.ApplicationEventPublisherAware;import org.springframework.stereotype.Service;@Servicepublic class CacheService implements ApplicationEventPublisherAware {private final JdbcTemplate jdbcTemplate;private final RedisTemplate<String, Object> redisTemplate;private ApplicationEventPublisher eventPublisher;public void updateData(String key, String value) {// 更新数据库jdbcTemplate.update("UPDATE table SET value = ? WHERE key = ?", value, key);// 发布事件eventPublisher.publishEvent(new DataUpdatedEvent(this, key, value));}@Overridepublic void setApplicationEventPublisher(ApplicationEventPublisher applicationEventPublisher) {this.eventPublisher = applicationEventPublisher;}@Servicepublic class EventListener {private final RedisTemplate<String, Object> redisTemplate;@org.springframework.context.event.EventListenerpublic void handleDataUpdatedEvent(DataUpdatedEvent event) {// 更新缓存redisTemplate.opsForValue().set(event.getKey(), event.getValue());}}}public class DataUpdatedEvent extends ApplicationEvent {private final String key;private final String value;public DataUpdatedEvent(Object source, String key, String value) {super(source);this.key = key;this.value = value;}public String getKey() {return key;}public String getValue() {return value;}}
- 定期补偿机制
定期对缓存和数据库的数据进行校验,发现不一致时进行补偿操作。
适用于对数据一致性要求较高的场景。
import java.util.concurrent.Executors;import java.util.concurrent.ScheduledExecutorService;import java.util.concurrent.TimeUnit;public class DataConsistencyChecker {private final JdbcTemplate jdbcTemplate;private final RedisTemplate<String, Object> redisTemplate;private final ScheduledExecutorService scheduler = Executors.newScheduledThreadPool(1);public void startChecking() {scheduler.scheduleAtFixedRate(() -> {// 从数据库中获取所有数据List<Map<String, Object>> dataFromDB = jdbcTemplate.queryForList("SELECT key, value FROM table");for (Map<String, Object> row : dataFromDB) {String key = (String) row.get("key");String value = (String) row.get("value");// 从缓存中获取数据String cacheValue = (String) redisTemplate.opsForValue().get(key);if (!value.equals(cacheValue)) {// 数据不一致,更新缓存redisTemplate.opsForValue().set(key, value);}}}, 0, 1, TimeUnit.HOURS);}}
废弃缓存与更新缓存的取舍
由上面代码可看出 1和2 最大的区别在于更新数据库时到底是更新缓存还是删除缓存。
【废弃缓存】
优点:
操作简单,只需在更新数据库后删除缓存,下次读取时重新从数据库加载数据,减少了写的操作日数
缺点:
可能短暂不一致:在缓存删除后和新数据写入缓存前,可能会出现短暂的缓存不一致
【更新缓存】
优点:
数据强一致性:更新数据库和缓存同时进行,确保数据的一致性。
减少数据库读压力:缓存始终是最新的,减少了对数据库的读操作。
缺点:
复杂性增加:需要处理缓存更新失败的情况,可能需要回滚操作。
性能影响:每次更新操作都需要同时更新数据库和缓存,增加了操作的复杂性和时间
- 写操作较少的场景:
推荐使用更新缓存:因为写操作较少,更新缓存的额外开销相对较小,且可以确保数据的一致性。 - 写操作频繁的场景:
推荐使用废弃缓存:因为写操作频繁,更新缓存会增加系统的复杂性和开销,而废弃缓存可以减少缓存的写操作,降低系统负担。 - 对数据一致性要求极高的场景:
推荐使用更新缓存:尽管复杂性增加,但可以确保数据的强一致性。 - 对性能要求较高且可以容忍短暂不一致的场景:
推荐使用废弃缓存:可以减少数据库的读压力,提高系统的整体性能
淘汰缓存的顺序
https://blog.csdn.net/qq_39033181/article/details/119276120
【 方案一 】先淘汰缓存,再更新数据库
在并发量较大的情况下,会导致数据的不一致。
1. A线程进行写操作,先成功淘汰缓存,但由于网络或其它原因,还未更新数据库
2. B线程进行读操作,发现缓存中没有想要的数据,从数据库中读取到的是旧数据,并把旧数据放入缓存。此时数据库与缓存都是旧值,数据没有不一致
3. A线程将数据库更新完成,数据库中是更新后的新数据,缓存中是更新前的旧数据,造成数据不一致。
【 方案二 】先更新数据库,再淘汰缓存
在并发量较大的情况下,会导致数据的短暂不一致,但是数据会最终一致。
1. A线程进行写操作,更新数据库,还未淘汰缓存
2. B线程从缓存中可以读取到旧数据,此时数据不一致
3. A线程完成淘汰缓存操作,其它线程进行读操作,从数据库中读入最新数据,此时数据一致
延时双删
上述方案二更简单,在高并发场景下也能保证数据的最终一致性,但是如果我就想用方案一呢?
什么是延时双删
先删再更新数据库 过N秒后再删一次缓存,怎么实现放后面spring-cache集成里,大概有 1.延时队列、2.线程池实现延时任务。
小结
- 这些都是理论,真正写代码,有cache框架,哪有这么烦,很多人喜欢问,那我们就得理,理了总比不理好,写这个就是怕我自己忘,呵
- 无论怎么样在高并发场景下,我们也只能要求缓存数据与数据库的最终一致性,如果要求强一致性还要缓存干嘛呢?操作直接走DB更香
- 大多数情况下建议使用淘汰缓存机制,然后先更新数据库,再淘汰缓存,满足大多数的场景了
相关文章:

问题: redis-高并发场景下如何保证缓存数据与数据库的最终一致性
在高并发场景下,Redis 通常用作缓存层,与数据库结合使用以提高系统的性能。为了保证缓存数据与数据库的最终一致性,通常采用的有双写机制、缓存失效机制,基于双写机制、缓存失效机制又衍生出来了消息队列、事件驱动架构等 常见机…...

Stable Diffusion核心网络结构——CLIP Text Encoder
🌺系列文章推荐🌺 扩散模型系列文章正在持续的更新,更新节奏如下,先更新SD模型讲解,再更新相关的微调方法文章,敬请期待!!!(本文及其之前的文章均已更新&…...

C语言-11-18笔记
1.C语言数据类型 类型存储大小值范围char1 字节-128 到 127 或 0 到 255unsigned char1 字节0 到 255signed char1 字节-128 到 127int2 或 4 字节-32,768 到 32,767 或 -2,147,483,648 到 2,147,483,647unsigned int2 或 4 字节0 到 65,535 或 0 到 4,294,967,295short2 字节…...

数据结构_图的遍历
深度优先搜索遍历 遍历思想 邻接矩阵上的遍历算法 void Map::DFSTraverse() {int i, v;for (i 0; i < MaxLen; i){visited[i] false;}for (i 0; i < Vexnum; i){// 如果顶点未访问,则进行深度优先搜索if (visited[i] false){DFS(i);}}cout << endl…...

设计LRU缓存
LRU缓存 LRU缓存的实现思路LRU缓存的操作C11 STL实现LRU缓存自行设计双向链表 哈希表 LRU(Least Recently Used,最近最少使用)缓存是一种常见的缓存淘汰算法,其基本思想是:当缓存空间已满时,移除最近最少使…...

python中的base64使用小笑话
在使用base64的时候将本地的图片转换为base64 代码如下,代码绝对正确 import base64 def image_to_data_uri(image_path):with open(image_path, rb) as image_file:image_data base64.b64encode(image_file.read()).decode(utf-8)file_extension image_path.sp…...

Python之time时间库
time时间库 概述获取当前时间time库datetime库区别 时间元组处理获取时间元组的各个部分时间戳和时间元组的转换 格式化时间格式化时间解析时间格式符号说明 暂停程序计时操作简单计时高精度计时计时器类的实现 UTC时间操作time库datetime库 概述 time是Python标准库中的一个模…...

Easyexcel(4-模板文件)
相关文章链接 Easyexcel(1-注解使用)Easyexcel(2-文件读取)Easyexcel(3-文件导出)Easyexcel(4-模板文件) 文件导出 获取 resources 目录下的文件,使用 withTemplate 获…...

国产linux系统(银河麒麟,统信uos)使用 PageOffice 动态生成word文件
PageOffice 国产版 :支持信创系统,支持银河麒麟V10和统信UOS,支持X86(intel、兆芯、海光等)、ARM(飞腾、鲲鹏、麒麟等)、龙芯(LoogArch)芯片架构。 数据区域填充文本 数…...

Window11+annie 视频下载器安装
一、ffmpeg环境的配置 下载annie之前需要先配置ffmpeg视频解码器。 网址下载地址 https://ffmpeg.org/download.html1、在网址中选择window版本 2、点击后选择该版本 3、下载完成后对压缩包进行解压,后进行环境的配置 (1)压缩包解压&#…...
配置篇(七))
SAP GR(Group Reporting)配置篇(七)
1.7、合并处理的配置 1.7.1 定义方法 菜单路径 组报表的SAP S4HANA >合并处理的配置>定义方法 事务代码 SPI4...

共建智能软件开发联合实验室,怿星科技助力东风柳汽加速智能化技术创新
11月14日,以“奋进70载,智创新纪元”为主题的2024东风柳汽第二届科技周在柳州盛大开幕,吸引了来自全国的汽车行业嘉宾、技术专家齐聚一堂,共襄盛举,一同探寻如何凭借 “新技术、新实力” 这一关键契机,为新…...
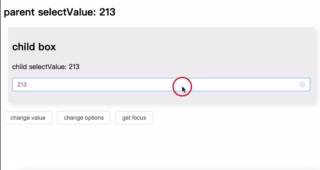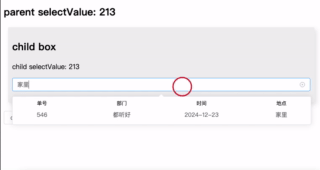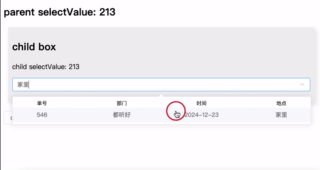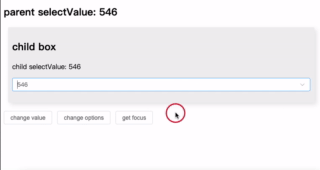
优化表单交互:在 el-select 组件中嵌入表格显示选项
介绍了一种通过 el-select 插槽实现表格样式数据展示的方案,可更直观地辅助用户选择。支持列配置、行数据绑定及自定义搜索,简洁高效,适用于复杂选择场景。完整代码见GitHub 仓库。 背景 在进行业务开发选择订单时,如果单纯的根…...

每日一题 LCR 079. 子集
LCR 079. 子集 主要应该考虑遍历的顺序 class Solution { public:vector<vector<int>> subsets(vector<int>& nums) {vector<vector<int>> ans;vector<int> temp;dfs(nums,0,temp,ans);return ans;}void dfs(vector<int> &…...

cocos creator 3.8 Node学习 3
//在Ts、js中 this指向当前的这个组件实例 //this下的一个数据成员node,指向组件实例化的这个节点 //同样也可以根据节点找到挂载的所有组件 //this.node 指向当前脚本挂载的节点//子节点与父节点的关系 // Node.parent是一个Node,Node.children是一个Node[] // th…...

微信小程序底部button,小米手机偶现布局错误的bug
预期结果:某button fixed 到页面底部,进入该页面时,正常显示button 实际结果:小米13pro,首次进入页面,button不显示。再次进入时,则正常展示 左侧为小米手机第一次进入。 遇到bug的解决思路&am…...

【计组】复习题
冯诺依曼型计算机的主要设计思想是什么?它包括哪些主要组成部分? 主要设计思想: ①采用二进制表示数据和指令,指令由操作码和地址码组成。 ②存储程序,程序控制:将程序和数据存放在存储器中,计算…...

Apache Maven 标准文件目录布局
Apache Maven 采用了一套标准的目录布局来组织项目文件。这种布局提供了一种结构化和一致的方式来管理项目资源,使得开发者更容易导航和维护项目。理解和使用标准目录布局对于有效的Maven项目管理至关重要。本文将探讨Maven标准目录布局的关键组成部分,并…...
Android 功耗分析(底层篇)
最近在网上发现关于功耗分析系列的文章很少,介绍详细的更少,于是便想记录总结一下功耗分析的相关知识,有不对的地方希望大家多指出,互相学习。本系列分为底层篇和上层篇。 大概从基础知识,测试手法,以及案例…...

【Xbim+C#】创建圆盘扫掠IfcSweptDiskSolid
基础回顾 https://blog.csdn.net/liqian_ken/article/details/143867404 https://blog.csdn.net/liqian_ken/article/details/114851319 效果图 代码示例 在前文基础上,增加一个工具方法: public static IfcProductDefinitionShape CreateDiskSolidSha…...

从API密钥管理角度感受Taotoken控制台的安全与便捷
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从API密钥管理角度感受Taotoken控制台的安全与便捷 作为项目或团队的技术负责人,管理多个大模型服务的API密钥是一项既…...

BilibiliDown:B站视频批量下载的终极解决方案
BilibiliDown:B站视频批量下载的终极解决方案 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirrors/bi/Bilibi…...
)
别再被Windows权限卡脖子!用`--user`参数搞定pip安装报错(附详细排查步骤)
彻底解决Windows下Python包安装权限问题:从--user参数到环境配置全攻略 在Windows系统上进行Python开发时,许多开发者都曾遭遇过这样的尴尬时刻:当你满怀期待地输入pip install package_name准备安装一个新工具时,屏幕上却突然跳出…...

BiliDownloader实战演练:解锁B站视频离线观看的智能解决方案
BiliDownloader实战演练:解锁B站视频离线观看的智能解决方案 【免费下载链接】BiliDownloader BiliDownloader是一款界面精简,操作简单且高速下载的b站下载器 项目地址: https://gitcode.com/gh_mirrors/bi/BiliDownloader 你是否曾为无法下载B站…...
)
Qt无边框窗口毛玻璃太常见?试试保留原生标题栏的‘高级’模糊方案(附Widget跟随层实现代码)
Qt保留原生标题栏的毛玻璃效果实现方案 在Qt开发中,实现毛玻璃效果通常需要移除窗口边框,但这会牺牲系统原生窗口管理功能。本文将介绍一种创新方案,通过创建跟随主窗口的子Widget来实现毛玻璃效果,同时保留原生标题栏和边框。 1.…...

考研数学避坑指南:那些课本不讲但真题爱考的极限与无穷小细节
考研数学避坑指南:那些课本不讲但真题爱考的极限与无穷小细节 考研数学中,极限与无穷小的概念看似基础,却暗藏玄机。每年都有大量考生在看似简单的题目上失分,原因往往是对这些概念的深层理解不足。本文将聚焦真题中最常见的陷阱&…...

Ubuntu下编译与测试libwebsockets:从x86环境验证到嵌入式移植
1. 项目概述与背景 在嵌入式开发中,尤其是涉及到网络通信模块时,我们常常会遇到一个典型的困境:直接在资源受限的目标板(比如ARM架构的开发板)上进行代码的编译、调试和功能验证,过程往往非常痛苦。编译速…...

对比自行维护多个API与使用Taotoken聚合平台在运维复杂度上的差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比自行维护多个API与使用Taotoken聚合平台在运维复杂度上的差异 在构建基于大模型的应用时,开发者常常需要接入多个不…...

长期使用Taotoken官方折扣活动对项目运营成本的实际影响
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken官方折扣活动对项目运营成本的实际影响 在项目开发与运营中,大模型API调用成本是技术决策者持续关注的…...

PyCharm里import报错?别急着pip install,先检查这个Python解释器配置
PyCharm中import报错的终极排查指南:从解释器配置到环境隔离 当你满心欢喜地在PyCharm中敲下import requests准备大展身手时,突然出现的红色波浪线就像一盆冷水浇下来。大多数人的第一反应是打开终端输入pip install requests——但等等,这真…...