深度学习day2-Tensor 2
六 Tensor常见操作
Tensor:多维数组,用于存储和操作数据
1 获取元素值
data.item():单个元素tensor转为python数值
import torch
#标量
x=torch.tensor(1)
print(x.item())
#一阶
x=torch.tensor([100])
print(x.item())
#如果输入的数据超过1个,就不能用item函数取
#取出来的是基本数据的数字
x=torch.tensor([1,2])
print(x.item())2 元素值运算
加减乘除幂次方取余取整等,带有_的方法会替换原始值
import torch
def test01():#带_结尾的函数基本都是直接操作原tensorx=torch.manual_seed(66)x=torch.randint(1,10,(3,3))print(x)#加x2=x.add(100)#返回一个新的数print(x2)x.add_(200)print(x)#减x=x.sub(1)print(x)x.sub_(100)print(x)#乘x=x.mul(2)print(x)x=x.mul_(2)print(x)#除x=x.div(4)print(x)x.div_(2)print(x)
x=x.pow(2)#平方print(x)
x=x**2print(x)x=x+10print(x)x=x-10print(x)x=x*10print(x)x=x/2print(x)x=x//2#取整print(x)x=x%2#取余print(x)x-=100#x=x-100print(x)
if __name__=='__main__':test01()3 阿达玛积
矩阵对应位置的元素相乘,mul函数或者*
import torch
def test():x1=torch.tensor([1,2],[3,4])x2=torch.tensor([1,2],[3,4])#阿达玛积时必须形状一样x3=x1*x2print(x3)x4=x1.mul(x2)print(x4)if __name__=='__main__':test()4 Tensor相乘
将两个向量映射为一个标量,如果第一个矩阵是(N,M),那么第二个矩阵的shape必须是(M,P),最后两个矩阵的点积运算的shape为(N,P),使用@或者matmul完成
mm只能用于2维矩阵
import torch
def test2():x1=torch.tensor([1,2],[3,4])x2=torch.tensor([1,2],[3,4])x3=torch.matmul(x1,x2)x3=x1.matmul(x2)x3=x1 @ x2x3=x1.mm(x2)print(x3)
x=torch.randint(1,4,(3,3,3))print(x)x2=torch.tensor(1,4,(3,3,3))print(x2)x3=x@x2x3=x.matmul(x2)print(x3)if __name__=='__main__':test2()5 索引操作
1.简单索引
根据指定的下标选取数据
import torch
def test():data = torch.randint(0, 10, (3, 4))print(data)# 1. 行索引print("行索引:", data[0])# 2. 列索引print("列索引:", data[:, 0])# 3. 固定位置索引:2种方式都行print("索引:", data[0, 0], data[0][0])
if __name__ == "__main__":test()2.列表索引
import torch
def test():torch.manual_seed(66)x=torch.randint(1,10,(5,5,3))#5个模块,模块里面的size是(5×3)print(x)print(x.shape)print(x[1])#取下标为1,实际上排序为第2个的模块print(x[1,2])#取模块下标为1行数下标为2的数据print(x[1,2,1].item())#取出实际上排序为第2个模块里面第3行2列的数据6print(x[0:2])#0,1print(x[0:2,1])#第1个第2个模块里面的第2行print(x[0:2,1:3])#第1个第2个模块里面的第2.3行print(x[0:2,1:3,2])#第1个第2个模块里面的第2.3行的第3列print(x[[1,3]])#第2和第4个模块print(x[[1,3],1])#第2和第4个模块的第2行print(x[[1,3],[1,2]])#取第2个模块的第2行和第4个模块的第3行,并非笛卡尔积坐标,而是:[1,1]×[3,2]print(x[2,[1,3],0:2])#取第3个模块的2.4行的1-2列数据#注意点:如果填列表,那么列表中的下标的数字是讲究顺序的print(x[[3,1]])#可以不按顺序取,结果是有顺序的print(x[[1,3]])#切片:冒号左右两边不写就表示到开头或者末尾print(x[0,1,:2])print(x[-1])print(x[:-1])#不取最后一个print(x[:-2])print(x[1][1][1])#[]:成员访问符print(x[1,1])print(x[[1,1]])
if __name__ == "__main__":test()3.布尔索引
def tool(x):return x%2==0#进行布尔运算得到跟tensor形状一样的布尔数组, 算术运算符例如x-得到原来的tensor
def test2():#tensor的布尔运算torch.manual_seed(66)x=torch.randint(1,10,(5,5))print(x)x2=x>8print(x2)x3=x[x2]print(x3)print(x[x==5])print(x[x%2==1])#取出所有的奇数print(x[tool(x)])
if __name__ == "__main__":test2()#思考:找出第一列是偶数 第二列是奇数 第三列是闰年的行中的第4列和第5列数据
x=torch.tensor([],[],[])
x[:,0]%2==0
x[:,1]%2==1
(x[:,2]%4==0 and x[:,2]%100!=0) or (x[:,2]%400==0 )
x[:,3:5]4.索引赋值
def test3():torch.manual_seed(66)x=torch.randint(1,10,(5,5))print(x)x2=x[1,1]print(x2)x[1,1]=100print(x)x[:,3]=200print(x)x[:,:]=99x.fill_(66)print(x)
if __name__=='__main__':test3()6 张量拼接
cat:在现有的维度上拼接,不会增加新维度
stack:在新维度上堆叠,会增加一个新维度
1.torch.cat
orch.cat(concatenate):在现有维度上将多个张量连接到一起,这些张量在除了指定拼接的维度之外的所有维度上的大小必须相同
import torch
def test01():torch.manual_seed(66)x=torch.randint(1,10,(3,3))y=torch.randint(1,10,(2,3))print(x)print(y)z=torch.cat([x,y],dim=0)#0是行1是列#不能在1的维度上拼接,因为x有3行y只有2行print(z)if __name__=='__main__':test01()2.torch.stack
torch.stack:在新维度上拼接张量,它会增加一个新的维度,然后沿着指定维度堆叠张量。这些张量必须具有相同的形状。
堆叠指沿着某个维度一人出一个交替添加(stack)
拼接指一人出完下个人再出完(cat)
import torch
def test02():torch.manual_seed(66)x=torch.randint(1,10,(3,3))y=torch.randint(1,10,(3,3))print(x)print(y)z=torch.stack((x,y),dim=0)#维度的堆叠z=torch.stack([x,y],dim=1)print(z)
def test03():torch.manual_seed(66)x=torch.randint(1,10,(3,3,2))y=torch.randint(1,10,(3,3,2))print(x)print(y)z=torch.stack([x,y],dim=3)print(z)def test04():#加载本地图片为PIL对象img_pil=Image.open('./data/1.png')#把pil对象转化为张量transfer=transforms.ToTensor()img_tensor=transfer(img_pil)print(img_tensor)print(img_tensor.shape)print(img_tensor.shape)print(img_tensor)res=torch.stack([img_tensor[0],img_tensor[1],img_tensor[2]],dim=2)print(res,res.shape)print(sum(sum(res>100)))
if __name__=='__main__':test02()
7 形状操作
1.reshape
转换后的形状与原始形状具有相同的元素数量
import torch
def test01():x=torch.randint(1,10,(4,3))print(x)#reshape改变形状x2=torch.reshape(x,(2,6))#改变原x的数据内存空间和连续性,生成新的数据内存空间(具有连续性)print(x2)x3=torch.reshape(x,(2,2,3))print(x3)x4=torch.reshape(x,(3,5))#改变形状后的数量不能改变print(x4)#-1表示自动计算x5=torch.reshape(x,(-1,6))#-1相当于替代符,当不知道该填多少可以用-1替代print(x5)print(torch.reshape(x,(2,2,-1)))#-1表示某个维度的数量推出来,但是只能有一个维度为-1
if __name__=='__main__':test01()2.view
特征:张量在内存中是连续的;返回的是原始张量视图,不重新分配内存,效率更高;
def test02():#内存上具有连续性才能viewx=torch.randint(1,10,(4,3))print(x)x2=x.view((2,6))#view操作的是连续的原始张量视图,不重新分配内存,只是重新编了一个下标,速度快print(x2)#改变形状,由于没有改变原x中的数据内存空间,因此它改变形状比reshape快
#非连续性不能view#x3=torch.randint(1,10,(4,3))#x4=torch.reshape(x3,(2,6))# x4=x3.t()#转置后x4的数据在内存中不连续# print(x4)# x5=x4.view(1,12)#改变形状,在内存中不连续的数据不能通过view来转换# print(x5)
#改变形状后,数据是否共享内存x6=torch.randint(1,10,(4,3))x7=x6.view(2,6)x6[1,1]=100print(x6,x7)if __name__=='__main__':test02()view:高效,但需要连续性
reshape:灵活,但涉及内存复制
3.transpose
用于交换张量的两个维度,返回原张量的视图(内存)
def test03():x=torch.randint(1,10,(4,3,2))print(x,x.shape)x2=torch.transpose(x,0,1)#只调换前2个维度print(x2,x2.shape)if __name__=='__main__':test03()4.permute
用于改变张量的所有维度顺序,可以交换多个维度
def test04():x=torch.randint(0,255,(3,512,360))#包不包含255print(x)#(C,h,w)(0,1,2)x2=x.permute(1,2,0)#(h,w,c)print(x2,x2.shape)if __name__=='__main__':test04()5.flatten
用于将张量展平为一维向量
tensor.flatten(start_dim=0, end_dim=-1)
-
start_dim:从哪个维度开始展平。
-
end_dim:在哪个维度结束展平。默认值为
-1,表示展平到最后一个维度。
def test05():x=torch.randint(0,255,(3,4))x2=x.flatten()print(x2)
x=torch.randint(0,255,(3,4,2,2))x2=x.flatten(start_dim=1,end_dim=2)#(3,[],2)print(x)print(x2)if __name__=='__main__':test05()6升维和降维
-
unsqueeze:用于在指定位置插入一个大小为 1 的新维度。
-
squeeze:用于移除所有大小为 1 的维度,或者移除指定维度的大小为 1 的维度。
1.squeeze降维
def test06():#数据降维x=torch.randint(0,255,(1,3,4,1))print(x)x2=x.squeeze()#全部print(x2)x3=x.squeeze(0).squeeze(-1)#指定维度print(x3)if __name__=='__main__':test06()2.unsqueeze升维
def test07():#数据升维x=torch.randint(0,255,(3,4))print(x)x2=x.unsqueeze(0)print(x2)print(x2.shape)
x2=x.unsqueeze(1)#(3,4)(3,1,4)print(x2)print(x2.shape)if __name__=='__main__':test01()8 张量分割
chunk(data,x):把data分成x份
split(data,x):把data按照大小为x进行分割
def test08():x=torch.randint(0,255,(21,4))x2=torch.split(x,2)#每个tensor有2行print(x2)x3=torch.chunk(x,2)#分割成2份print(x3)
if __name__=='__main__':test08()9 广播机制
允许对不同形状的张量进行计算,广播机制会自动扩展较小维度的张量,使其与较大维度的张量兼容,实现计算
规则:每个张量的维度至少为1,满足右对齐
import torch
def test01():torch.manual_seed(66)x=torch.randint(1,10,(4,3))print(x)x2=torch.randint(1,10,(1,3))print(x2)x3=x+x2print(x3)
x4=torch.randint(1,10,(4,3))x5=torch.randint(1,10,(4,1))print(x4)print(x5)x6=x4+x5print(x6)
def test02():data1d = torch.tensor([1, 2, 3])data2d = torch.tensor([[4], [2], [3]])print(data1d.shape, data2d.shape)# 进行计算:会自动进行广播机制print(data1d + data2d)
if __name__=='__main__':test01()#2D和3D张量广播时会根据需要对两个张量进行形状扩展,从而能够进行运算。
def test003():# 2D 张量a = torch.tensor([[1, 2, 3], [4, 5, 6]])#2*3#2*2*3#[[[1, 2, 3], [4, 5, 6]],[[1, 2, 3], [4, 5, 6]]]# 3D 张量b = torch.tensor([[[2, 3, 4]], [[5, 6, 7]]])#2*1*3#2*2*3#[[[2, 3, 4],[2, 3, 4]], [[5, 6, 7],[5, 6, 7]]]print(a.shape, b.shape)# 进行运算result = a + bprint(result, result.shape)
if __name__=='__main__':test03()10 数学运算
1基本操作
import torch
def test():data = torch.tensor([[1, 2, -3.5], [4, 5, 6], [10.5, 18.6, 19.6], [11.05, 19.3, 20.6], ])print(data)x1=torch.floor(data)#向下取整(下指往下取整)print(x1)x2=torch.ceil(data)#向上取整(上指往大取整)print(x2)x3=torch.round(data)#四舍五入(内部用的py的round函数:四舍6入 5看整数的个位的奇数偶数,奇进偶不进)print(x3)x4=torch.trunc(data)#截断(只保留整数部分)print(x4)x5=torch.frac(data)#截断(只保留小数部分)print(x5)x6=torch.fix(data)#向0的方向取整,负数往向大的方向取整,正数往向小的方向取整print(x6)x7=data%2#取模print(x7)x8=torch.abs(data)#取绝对值(曼哈顿街道距离)print(x8)if __name__=='__main__':test()
2三角函数
import torch
def test02():#3.141592653 里面的是数字,相当于弧度print(torch.pi)deg=torch.pi/180#相当于度data=torch.tensor([0,90*deg,3])x=torch.sin(data)print(x)x=torch.cos(data)print(x)x=torch.sinh(data)#双曲正弦函数print(x)x=torch.cosh(data)#双曲余弦函数print(x)x=torch.tan(data)print(x)x=torch.tanh(data)#双曲正切函数print(x)
if __name__=='__main__':test02()3统计学函数
import torch
import math
import cv2
def test03():torch.manual_seed(66)x=torch.randint(1,10,(4,3)).type(torch.float32)print(x)x1=x.mean()#平均数print(x1)x2=torch.mean(x)#平均数print(x2)x3=torch.sum(x)#求和print(x3)x5=torch.std(x)#标准差print(x5)x6=torch.var(x)#方差print(x6)x7=torch.median(x)#中位数print(x7)x8=torch.mode(x)#众数print(x8.values)x9=torch.max(x)#最大值print(x9)x9=torch.min(x)#最小值print(x9)x10=torch.sort(x)#排序print(x10)print(x10.values)#值print(x10.indices)#下标x11=x.sort()print(x11)arr=[8,10,11,13,14]res=arr.sort(key=lambda x:abs(x-10))#列表 谁离10近谁排前面print(res)def myabs(x):return abs(x-10)arr.sort(key=myabs)#列表print(arr)x=torch.tensor([1,1,1,2,3,4,5,2,3,4,5,6],dtype=torch.float32)print(torch.topk(x,3))#大概率是快排print(torch.histc(x,bins=5,min=2,max=4))#统计每个数出现的次数,指定个数print(torch.unique(x))#分类的数据集中看有几种类型print(torch.unique(x).shape)x=torch.tensor([1,1,1,2,3,4,5,2,3,4,5,6],dtype=torch.float32)print(torch.bincount(x))#统计每个数出现的次数,不指定个数
img=cv2.imread("./data/1.png")img_tensor=torch.from_numpy(img).flatten()bincount=torch.bincount(img_tensor)print(bincount)res=torch.topk(bincount,1)#出现得最多的像素值print(res)
if __name__=='__main__':test()11保存和加载
torch.save(x,"路径")
torch.load(x,"路径")
import torch
def test01():x=torch.tensor([1,2,3])torch.save(x,"./data/tensor.pth")#保存
def test01():device=torch.device("cuda" if torch.cuda.is_available() else "cpu")x=torch.load("./data/tensor.pth",map_location=device)#加载到指定设备x=x.cuda()#返回一个新的x=x.to("cuda")#返回一个新的print(x)print(x.device)
if __name__=='__main__':test01()12并行化
torch.get_num_threads()#获取cpu的线程
torch.set_num_threads(4)#设置pytorch使用cpu的线程数量
import torch
def test03():count=torch.get_num_threads()#获取cpu的线程print(count)
def test04():torch.set_num_threads(4)#设置cpu的线程count=torch.get_num_threads()#获取cpu的线程print(count)
if __name__=='__main__':test03()相关文章:

深度学习day2-Tensor 2
六 Tensor常见操作 Tensor:多维数组,用于存储和操作数据 1 获取元素值 data.item():单个元素tensor转为python数值 import torch #标量 xtorch.tensor(1) print(x.item()) #一阶 xtorch.tensor([100]) print(x.item()) #如果输入的数据超过1个&#…...

【Android踩过的坑】14.小米系统TTS无法生效的问题
【Android踩过的坑】14.小米系统TTS无法生效的问题 解决办法: 在AndroidManifest.xml中添加: <?xml version"1.0" encoding"utf-8"?> <manifest xmlns:android"http://schemas.android.com/apk/res/android"…...
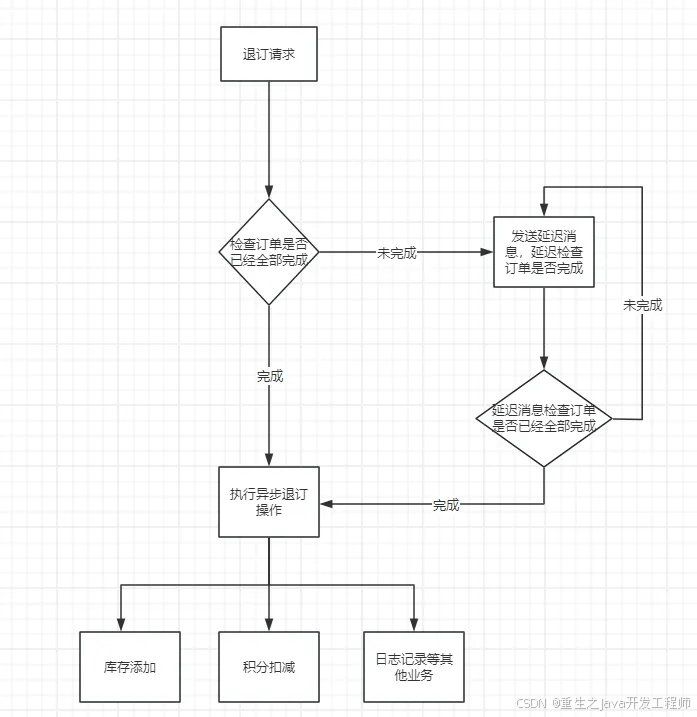
RabbitMQ实现异步下单与退单
前言: 在电商项目中的支付模块也是一个很重要的模块,其中下订操作以及退订操作就是主要的操作。其次的下单是同步下单,也就是第三方支付、数据库扣减、积分增加、等等其他业务操作,等待全部执行完毕后向用户返回成功响应请求。对…...

鸿蒙NEXT开发案例:随机数生成
【引言】 本项目是一个简单的随机数生成器应用,用户可以通过设置随机数的范围和个数,并选择是否允许生成重复的随机数,来生成所需的随机数列表。生成的结果可以通过点击“复制”按钮复制到剪贴板。 【环境准备】 • 操作系统:W…...

nwjs崩溃复现、 nwjs-控制台手动操纵、nwjs崩溃调用栈解码、剪切板例子中、nwjs混合模式、xdotool显示nwjs所有进程窗口列表
-1. nwjs在低版本ubuntu运行情况 ubuntu16.04运行nw-v0.93或0.89报错找不到NSS_3.30、GLIBC_2.25 uname -a #Linux Asus 4.15.0-112-generic #113~16.04.1-Ubuntu SMP Fri Jul 10 04:37:08 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux cat /etc/issue #Ubuntu 16.04.7 LTS \n \l…...

视觉SLAM--经典视觉SLAM框架
整个视觉SLAM流程主要包括以下步骤: 1、传感器信息读取:在视觉SLAM中主要为相机图像信息的读取和预处理。 2、前端视觉里程计:估算相邻图像间相机的运动,以及局部地图的样子。 3、后端(非线性)优化&#…...

Wallpaper壁纸制作学习记录05
效果简介 效果可以应用于现有组件,主要是您导入的图像。您可以在图像图层、文本图层、全屏图层和合成图层上使用效果。要添加效果需要打开之前的项目或创建一个新的项目,然后点击右侧效果区域的添加按钮。 将鼠标悬停在效果列表是,将显示眼睛…...

Elasticsearch 中的热点以及如何使用 AutoOps 解决它们
作者:来自 Elastic Sachin Frayne 探索 Elasticsearch 中的热点以及如何使用 AutoOps 解决它。 Elasticsearch 集群中出现热点的方式有很多种。有些我们可以控制,比如吵闹的邻居,有些我们控制得较差,比如 Elasticsearch 中的分片分…...

springboot基于微信小程序的食堂预约点餐系统
摘 要 基于微信小程序的食堂预约点餐系统是一种服务于学校和企事业单位食堂的智能化解决方案,旨在提高食堂就餐的效率、缓解排队压力,并优化用户的就餐体验。系统作为一种现代化的解决方案,为食堂管理和用户就餐提供了便捷高效的途径。它不仅…...

字符串学习篇-java
API:应用程序编程接口。 ctrlaltv,自动生成一个变量接收数据 字符串: 注意点 创建string对象两种方式 1.直接赋值 2.构造器来创建 详情看黑马JAVA入门学习笔记7-CSDN博客 常用方法:比较 引用数据类型,比较的是地址值。 b…...

2024亚太杯数学建模C题【Development Analyses and Strategies for Pet Industry 】思路详解
C:宠物行业及相关产业的发展分析与战略 随着人们消费观念的发展,宠物行业作为一个新兴产业,正在全球范围内逐渐积聚势头,这得益于快速的经济发展和人均收入的提高。1992年,中国小动物保护协会成立,随后1993…...

STM32串口——5个串口的使用方法
参考文档 STM32串口——5个串口的使用方法_51CTO博客_stm32串口通信的接收与发送 串口是我们常用的一个数据传输接口,STM32F103系列单片机共有5个串口,其中1-3是通用同步/异步串行接口USART(Universal Synchronous/Asynchronous Receiver/Transmitter)…...

NVR接入录像回放平台EasyCVR视频融合平台加油站监控应用场景与实际功能
在现代社会中,加油站作为重要的能源供应点,面临着安全监管与风险管理的双重挑战。为应对这些问题,安防监控平台EasyCVR推出了一套全面的加油站监控方案。该方案结合了智能分析网关V4的先进识别技术和EasyCVR视频监控平台的强大监控功能&#…...

Ubuntu24.04安装gpfs客户端
文章目录 Ubuntu24.04安装gpfs客户端拷贝软件包在客户端执行命令,提取产品包进入安装包目录,安装相关产品包编译。编译过程中会检查系统依赖接入集群(后续) Ubuntu24.04安装gpfs客户端 拷贝软件包 scp /root/Spectrum_Scale_Dat…...

Android Framework层介绍
文章目录 前言一、Android Framework 层概述二、主要组件1. 应用程序接口(API)2. 系统服务3. Binder4. 资源管理5. Content Provider6. 广播接收器(BroadcastReceiver)7. 服务(Service) 三、与 Linux Kerne…...

如何利用 Puppeteer 的 Evaluate 函数操作网页数据
介绍 在现代的爬虫技术中,Puppeteer 因其强大的功能和灵活性而备受青睐。Puppeteer 是一个用于控制 Chromium 或 Chrome 浏览器的 Node.js 库,提供了丰富的 API 接口,能够帮助开发者高效地处理动态网页数据。本文将重点讲解 Puppeteer 的 ev…...

SpringMVC接收请求参数
(5)请求参数》五种普通参数 1.普通参数 代码块 RequestMapping("/commonParam") ResponseBody public String commonParam(String name,int age){System.out.println("普通参数传递 name > "name);System.out.println("普通…...

安宝特方案 | AR助力紧急救援,科技守卫生命每一刻!
在生死时速的紧急救援战场上,每一秒都至关重要!随着科技的发展,增强现实(AR)技术正在逐步渗透到医疗健康领域,改变着传统的医疗服务模式。 安宝特AR远程协助解决方案,凭借其先进的技术支持和创新…...

蓝桥杯每日真题 - 第18天
题目:(出差) 题目描述(13届 C&C B组E题) 解题思路: 问题分析 问题实质是一个带权图的最短路径问题,但路径的权重包含两个部分: 从当前城市到下一个城市的路程时间。 当前城市的…...

HTTP 协议应用场景
一、HTTP 协议简介 HTTP(Hypertext Transfer Protocol)即超文本传输协议,是用于分布式、协作式和超媒体信息系统的应用层协议,是互联网数据通信的基础。它采用客户端 - 服务器(Client-Server)的通信模式&am…...

从 0 到 1 搭建 RuoyiOffice:30 分钟跑通后端+前端+移动端
从 0 到 1 搭建 RuoyiOffice:30 分钟跑通后端前端移动端 🌐 演示地址:http://ruoyioffice.com | 📦 源码1:https://gitcode.com/zhouzhongyan/ruoyi-office-vben.git | 📦 源码2:https://gitcod…...

P6 马铃薯病害识别
🍨 本文为🔗365天深度学习训练营中的学习记录博客🍖 原作者:K同学啊 个人总结:了解VGG由 5 组卷积池化块堆叠构成,依靠小尺寸卷积核逐层提取图像浅层、深层特征,最后通过全连接层完成分类。&…...

千问 LeetCode 2569. 更新数组后处理求和查询 Java实现
这道题的核心是高效维护nums1的区间反转操作,因为数据规模达到10^5,暴力反转会超时。需要用到线段树(区间更新区间查询)或BitSet来优化。下面给出Java实现,采用线段树 懒标记的方案:class Solution {publi…...

2026年,揭秘浙江废铝回收界的明星企业!
引言:废铝回收,绿色循环的先锋随着我国经济的快速发展和工业生产的不断扩大,废铝回收行业逐渐成为资源循环利用的重要环节。在浙江省,众多废铝回收企业脱颖而出,其中腾兰再生资源回收有限公司以其卓越的表现࿰…...

大模型推理优化:激活稀疏性技术解析与实践
1. 大模型推理优化的核心挑战与机遇在自然语言处理领域,大型语言模型(LLM)的推理效率已成为制约其广泛应用的关键瓶颈。以GPT-3 175B为例,单次推理需要约350GB显存和数千亿次浮点运算,这对硬件资源提出了极高要求。传统…...

软件测试会被AI取代吗?我用数据告诉你真相
在探讨“取代”之前,我们先看一组具有代表性的数据。根据Gartner的预测,到2027年,80%的企业将把AI驱动的测试工具整合进其测试流程中,目前这一比例仅为大约20%。与此同时,World Quality Report显示,过去五年…...

Unity背包系统架构设计:数据驱动、事件总线与三层物品模型
1. 为什么“背包系统”不是功能模块,而是游戏体验的神经中枢 很多人第一次在Unity里拖一个Panel、加几个Image和Text,就以为背包做完了。我见过太多项目——美术资源堆得漂亮,UI动效拉满,结果点开背包,物品不能拖拽、堆…...

Flutter动画系统完全指南:构建流畅用户体验
引言 Flutter提供了强大而灵活的动画系统,允许开发者创建流畅、高性能的动画效果。本文将深入探讨Flutter动画系统的核心概念、使用模式和最佳实践。 一、Flutter动画基础 1.1 动画类型 动画类型说明适用场景补间动画从起始值到结束值的平滑过渡简单属性动画物理动画…...

终极德州扑克GTO求解器完整指南:从零开始掌握博弈论最优策略的三大突破
终极德州扑克GTO求解器完整指南:从零开始掌握博弈论最优策略的三大突破 【免费下载链接】TexasSolver 🚀 A very efficient Texas Holdem GTO solver :spades::hearts::clubs::diamonds: 项目地址: https://gitcode.com/gh_mirrors/te/TexasSolver …...

嵌入式Linux驱动移植:基于MAX31865与PT100的高精度温度采集方案
1. 项目概述与核心思路最近在做一个工业边缘计算网关的项目,需要高精度地监测几个关键节点的温度,精度要求至少达到0.5℃。市面上常见的DS18B20这类数字温度传感器,在精度和抗干扰能力上有点力不从心。于是,我把目光投向了铂电阻温…...