【阅读记录-章节3】Build a Large Language Model (From Scratch)
目录
- 3 Coding attention mechanisms
- 3.1 The problem with modeling long sequences
- 背景:注意力机制的动机
- 3.2 Capturing data dependencies with attention mechanisms
- RNN的局限性与改进
- Transformer架构的革命
- 3.3 Attending to different parts of the input with self-attention
- “自”注意力的含义
- 3.3.1 A simple self-attention mechanism without trainable weights
- 自注意力机制简化实现
- 实现步骤
- 自注意力中的点积
- 3.3.2 Computing attention weights for all input tokens
- 3.4 Implementing self-attention with trainable weights
- 3.4.1 Computing the attention weights step by step
- 1. 权重矩阵初始化
- 2. 查询、键和值向量的计算
- 3. 计算所有键和值向量
- 4. 计算注意力分数
- 5. 缩放并归一化注意力分数
- 6. 计算上下文向量
- 7. 推广到所有上下文向量
- 为什么使用 Query、Key 和 Value?
- 3.4.2 Implementing a compact self-attention Python class
- 1. 自注意力机制的实现
- 2. 对比 `SelfAttention_v1` 和 `SelfAttention_v2`**
- 3.5 Hiding future words with causal attention
- 3.5.1 Applying a causal attention mask
- 因果注意力掩码的实现步骤
- 第一步:计算注意力分数与权重
- 第二步:生成掩码并应用
- 第三步:重新归一化注意力权重
- 优化后的因果注意力实现
- 3.5.2 Masking additional attention weights with dropout
- 什么是Dropout?
- Transformer模型中的Dropout(例如GPT)
- PyTorch代码示例
- 3.5.3 Implementing a compact causal attention class
- 3.6 Extending single-head attention to multi-head attention
- 3.6.1 堆叠多个因果注意力模块
- 3.6.2 Implementing multi-head attention with weight splits
- MultiHeadAttention 类的核心概念总结
- 本章总结
3 Coding attention mechanisms
在前面的章节你已经了解了如何为训练大型语言模型(LLM)准备输入文本。具体包括将文本分割为单个单词和子词(subword)token,然后将这些token编码为向量表示(即嵌入,embeddings)。
接下来会探讨LLM架构中的一个核心部分:注意力机制(attention mechanisms),包括其理论和实现。编写完整代码,构建围绕**自注意力机制(self-attention mechanism)**的其余模型部分。实现四种注意力机制变体,最终完成多头注意力的紧凑实现。将多头注意力机制集成到LLM架构中,构建完整模型并生成文本。

3.1 The problem with modeling long sequences
背景:注意力机制的动机
在深入探讨LLM核心的**自注意力机制(self-attention mechanism)**之前,我们先来看传统不包含注意力机制的架构所面临的问题。
-
语言翻译的挑战
-
对于语言翻译任务,不能逐词翻译,因为源语言和目标语言的语法结构不同(如图3.3所示)。

-
常见的解决方案是使用包含编码器(encoder) 和 解码器(decoder) 的深度神经网络架构:
- 编码器:读取并处理完整的输入文本。
- 解码器:生成目标语言文本。
-
-
RNN时代的编码器-解码器架构
- 在Transformer出现之前,**循环神经网络(RNN)**是最流行的编码器-解码器架构。
- RNN通过将前一步的输出作为当前步骤的输入,非常适合处理像文本这样具有顺序性的数据。
- 即便不了解RNN的详细原理,只需理解其在编码器-解码器框架中的大致概念:
-
编码器逐步处理输入文本,每一步更新其隐藏状态(hidden state)。
-
最终的隐藏状态包含输入句子的完整语义(图3.4所示)。

-
解码器使用这个隐藏状态作为初始信息,逐词生成翻译句子,同时不断更新其隐藏状态。
-
-
隐藏状态的作用与局限性
- 隐藏状态可以被视为一种嵌入向量(embedding vector),用于表示输入句子的语义信息。
- 然而,编码器-解码器RNN存在一个明显的局限性:
- 在解码阶段,无法直接访问编码器的早期隐藏状态。
- 解码器只能依赖于当前隐藏状态,这种信息压缩会导致语义上下文的丢失,特别是在复杂句子中,存在远距离依赖时尤为明显。
-
注意力机制的诞生
- 虽然无需掌握RNN的具体工作原理,但需要理解它的局限性正是推动 注意力机制(attention mechanisms) 设计的动力:
- 注意力机制通过直接访问编码器的所有隐藏状态,解决了上下文信息丢失的问题。
- 虽然无需掌握RNN的具体工作原理,但需要理解它的局限性正是推动 注意力机制(attention mechanisms) 设计的动力:
3.2 Capturing data dependencies with attention mechanisms
RNN的局限性与改进
-
RNN的短板
- RNN在处理短句翻译时效果尚可,但在处理较长文本时表现不佳。
- 问题在于RNN的架构设计:编码器必须将输入文本的全部信息压缩到一个隐藏状态(hidden state)中,然后再传递给解码器(如图3.4所示)。这种方式导致信息表达能力有限。
-
Bahdanau注意力机制的提出
-
为了解决上述问题,2014年Bahdanau等人提出了Bahdanau注意力机制(以论文第一作者命名,详见附录B)。

-
它对传统RNN的编码器-解码器架构进行了改进:
- 解码器可以在每个解码步骤中选择性访问输入序列的不同部分(如图3.5所示)。

- 解码器可以在每个解码步骤中选择性访问输入序列的不同部分(如图3.5所示)。
-
这一改进显著提高了RNN在长文本翻译任务中的表现。
-
Transformer架构的革命
-
从RNN到Transformer的过渡
- 仅仅三年后,研究人员发现RNN架构并非自然语言处理的必要条件。
- 2017年,研究者提出了原始的Transformer架构(在第1章中已有介绍),其核心创新是引入了受Bahdanau注意力机制启发的自注意力机制(self-attention mechanism)。
-
自注意力机制的原理与意义
- 自注意力机制允许输入序列中的每个位置在计算序列表示时关注序列中所有其他位置的相关性。
- 它成为现代LLM(如GPT系列)基于Transformer架构的关键组成部分。

-
本章与后续内容的重点
-
本章将重点介绍并实现GPT模型中使用的自注意力机制(如图3.6所示)。
-
下一章将继续编码LLM的其他部分,完成完整模型的构建。
-
3.3 Attending to different parts of the input with self-attention
自注意力机制的重要性
- 核心地位:自注意力机制是基于Transformer架构的大型语言模型(LLM)的核心组件。
- 学习目标:掌握自注意力机制的原理和实现是理解LLM及其开发的关键环节,也是本书最具挑战性的部分之一。
- 学习方法:从基础的简化版本开始,逐步实现带有可训练权重的自注意力机制。
“自”注意力的含义
-
定义:
- 自注意力中的“自”指代机制能够在单个输入序列中,计算各个位置之间的注意力权重。
- 它通过评估输入自身的各部分(如句子中的单词或图像中的像素)之间的关系和依赖性,来学习全局上下文信息。
-
与传统注意力的区别:
- 自注意力机制关注单个序列内的元素间关系。
- 传统注意力机制通常用于两个不同序列间的关系,例如在序列到序列(sequence-to-sequence)模型中,计算输入序列与输出序列间的相关性(如图3.5所示)。
实现路径
- 简化学习:
- 由于自注意力机制初看可能比较复杂,尤其是第一次接触时,学习将从一个简化版本入手。
- 逐步深入:
- 在掌握基础概念后,将进一步实现带有可训练权重的完整自注意力机制,这是LLM的核心构建模块。
3.3.1 A simple self-attention mechanism without trainable weights
自注意力机制简化实现
- 目标:实现一个简化版的自注意力机制,不涉及可训练权重,以便理解核心概念。
- 背景:
- 输入序列 x x x 由 T T T 个元素组成,表示经过嵌入后的句子,如 “Your journey starts with one step.”。
- 每个序列元素 x ( i ) x^{(i)} x(i) 是一个 d d d-维的嵌入向量,例如,“Your” 的嵌入为三维向量 [ 0.43 , 0.15 , 0.89 ] [0.43, 0.15, 0.89] [0.43,0.15,0.89]。
- 自注意力机制的任务是为每个输入元素 x ( i ) x^{(i)} x(i) 生成一个上下文向量 z ( i ) z^{(i)} z(i),它结合了序列中所有其他元素的信息。

上下文向量的意义
- 定义:上下文向量 z ( i ) z^{(i)} z(i)是一个增强的嵌入向量,综合了输入序列中所有元素的信息。
- 作用:帮助模型理解序列中各元素间的关系和重要性(如词语间的语义关联)。
- 实例:以 “journey” 对应的嵌入 x ( 2 ) x^{(2)} x(2) 为例,计算的 z ( 2 ) z^{(2)} z(2)包含了 “journey” 与句子中所有其他单词(如 “Your”, “starts” 等)的信息。
实现步骤
输入准备
- 示例句子:
import torchinputs = torch.tensor([[0.43, 0.15, 0.89], # Your (x^1)[0.55, 0.87, 0.66], # journey (x^2)[0.57, 0.85, 0.64], # starts (x^3)[0.22, 0.58, 0.33], # with (x^4)[0.77, 0.25, 0.10], # one (x^5)[0.05, 0.80, 0.55] # step (x^6)
])

第一步:计算注意力分数 ω \omega ω
- 原理:通过点积(dot product)计算查询向量与其他输入向量之间的注意力分数。
- 实现:以 “journey” x ( 2 ) x^{(2)} x(2) 为查询向量:
query = inputs[1] # 查询向量 x(2)# 初始化注意力分数张量
attn_scores_2 = torch.empty(inputs.shape[0])# 计算与每个输入向量的点积
for i, x_i in enumerate(inputs):attn_scores_2[i] = torch.dot(x_i, query)print(attn_scores_2)
- 输出:
tensor([0.9544, 1.4950, 1.4754, 0.8434, 0.7070, 1.0865])
- 解释:
- 每个值表示查询向量 ( x(2) ) 和输入序列中对应向量的相似性。
- 注意力分数衡量每个输入元素对查询元素的重要性。
自注意力中的点积
-
定义:点积是两个向量对应元素逐项相乘后求和的结果。
示例代码:res = 0. for idx, element in enumerate(inputs[0]):res += inputs[0][idx] * query[idx] print(res) print(torch.dot(inputs[0], query))输出:
tensor(0.9544) tensor(0.9544) -
在自注意力中的作用:
- 衡量两个向量的相似性(向量间的对齐程度)。
- 点积越大 → 相似性越高 → 注意力得分越高。
- 自注意力利用这种相似性来确定序列中一个元素与其他元素的相关性。

归一化注意力得分
-
为什么归一化:
- 确保注意力权重的和为 1。
- 使得输出易于解释,同时在训练中更加稳定。
-
简单归一化方法:
attn_weights_2_tmp = attn_scores_2 / attn_scores_2.sum() print("注意力权重:", attn_weights_2_tmp) print("权重和:", attn_weights_2_tmp.sum())输出:
注意力权重: tensor([0.1455, 0.2278, 0.2249, 0.1285, 0.1077, 0.1656]) 权重和: tensor(1.0000) -
使用 Softmax 归一化:
- Softmax 的优点:
- 能更好处理极端值,避免数值不稳定(如溢出或下溢)。
- 输出权重为正数,易解释为概率或相对重要性。
- 示例实现:
输出:def softmax_naive(x):return torch.exp(x) / torch.exp(x).sum(dim=0) attn_weights_2_naive = softmax_naive(attn_scores_2) print("注意力权重:", attn_weights_2_naive) print("权重和:", attn_weights_2_naive.sum())注意力权重: tensor([0.1385, 0.2379, 0.2333, 0.1240, 0.1082, 0.1581]) 权重和: tensor(1.)
- Softmax 的优点:
-
推荐使用 PyTorch 的 Softmax 实现:
attn_weights_2 = torch.softmax(attn_scores_2, dim=0) print("注意力权重:", attn_weights_2) print("权重和:", attn_weights_2.sum())输出与上面一致。

通过加权求和计算上下文向量,构建丰富的表示,为模型的后续任务(如生成下一个词)提供支持。
-
上下文向量定义:
每个输入元素的上下文向量是加权求和后的结果,权重由注意力权重决定。 -
实现步骤:
query = inputs[1] # 以第二个输入为查询向量 context_vec_2 = torch.zeros(query.shape) for i, x_i in enumerate(inputs):context_vec_2 += attn_weights_2[i] * x_i print(context_vec_2)输出:
tensor([0.4419, 0.6515, 0.5683]) -
作用:
上下文向量通过整合序列中所有元素的信息,为序列中的每个元素创建丰富的表示。
3.3.2 Computing attention weights for all input tokens
接下来介绍如何通过代码计算所有输入的注意力权重和上下文向量。
-
自注意力机制的实现包括三步:
- 计算注意力分数(点积)。
- 对分数进行归一化(softmax)。
- 基于权重计算上下文向量(矩阵乘法)。
-
代码优化:
- 使用矩阵乘法代替嵌套循环。
- 利用 PyTorch 的
torch.softmax实现快速归一化。
-
验证结果:
- 归一化后每行权重之和为 1。
- 新的上下文向量与预计算结果一致。
步骤 1:计算注意力分数 (Attention Scores)
- 逐对计算注意力分数
对于每对输入向量x_i和x_j,注意力分数是它们的点积:
结果:attn_scores = torch.empty(6, 6) for i, x_i in enumerate(inputs):for j, x_j in enumerate(inputs):attn_scores[i, j] = torch.dot(x_i, x_j) print(attn_scores)tensor([[0.9995, 0.9544, 0.9422, 0.4753, 0.4576, 0.6310],[0.9544, 1.4950, 1.4754, 0.8434, 0.7070, 1.0865],[0.9422, 1.4754, 1.4570, 0.8296, 0.7154, 1.0605],[0.4753, 0.8434, 0.8296, 0.4937, 0.3474, 0.6565],[0.4576, 0.7070, 0.7154, 0.3474, 0.6654, 0.2935],[0.6310, 1.0865, 1.0605, 0.6565, 0.2935, 0.9450] ])

- 优化:使用矩阵乘法计算
为了加速计算,可以用矩阵乘法代替嵌套的for循环:
结果与之前相同,说明优化后的代码是正确的。attn_scores = inputs @ inputs.T print(attn_scores)
步骤 2:归一化注意力分数

为了将注意力分数转化为概率分布,需要对每一行进行归一化,使其和为 1。这可以通过Softmax函数实现:
attn_weights = torch.softmax(attn_scores, dim=-1)
print(attn_weights)
归一化后的注意力权重:
tensor([[0.2098, 0.2006, 0.1981, 0.1242, 0.1220, 0.1452],[0.1385, 0.2379, 0.2333, 0.1240, 0.1082, 0.1581],[0.1390, 0.2369, 0.2326, 0.1242, 0.1108, 0.1565],[0.1435, 0.2074, 0.2046, 0.1462, 0.1263, 0.1720],[0.1526, 0.1958, 0.1975, 0.1367, 0.1879, 0.1295],[0.1385, 0.2184, 0.2128, 0.1420, 0.0988, 0.1896]
])
注意:
dim=-1表示沿着最后一个维度(即每一行)进行归一化。- 每一行的值加起来等于 1:
输出结果:print(attn_weights.sum(dim=-1))tensor([1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000])
步骤 3:计算上下文向量 (Context Vectors)
使用注意力权重矩阵与输入向量矩阵进行矩阵乘法,得到每个输入对应的上下文向量:
all_context_vecs = attn_weights @ inputs
print(all_context_vecs)
计算结果:
tensor([[0.4421, 0.5931, 0.5790],[0.4419, 0.6515, 0.5683],[0.4431, 0.6496, 0.5671],[0.4304, 0.6298, 0.5510],[0.4671, 0.5910, 0.5266],[0.4177, 0.6503, 0.5645]
])
验证结果的正确性
通过比较上下文向量 z ( 2 ) z^{(2)} z(2)(第二个输入的上下文向量)与之前计算的结果,可以验证代码的正确性:
print("Previous 2nd context vector:", context_vec_2)
输出:
Previous 2nd context vector: tensor([0.4419, 0.6515, 0.5683])
可以看到,新的上下文向量结果的第二行完全匹配 z ( 2 ) z^{(2)} z(2),说明实现是正确的。
接下来,可以引入可训练的权重,使模型能够通过学习优化注意力机制,从而提升特定任务中的性能。
3.4 Implementing self-attention with trainable weights
接下来,我们将实现用于 Transformer 架构、GPT 模型以及大多数流行大语言模型(LLMs)的自注意力机制。这种机制被称为缩放点积注意力(Scaled Dot-Product Attention)。

自注意力机制的核心思路
-
目标:
- 计算每个输入元素对应的上下文向量(context vector),作为输入向量的加权和,与之前的基础自注意力机制类似。
-
关键区别:
- 引入可训练的权重矩阵,这些矩阵在模型训练过程中更新,使模型能够学习如何生成更优的上下文向量。
-
重要性:
- 可训练权重使注意力模块能够适应特定任务需求,生成更有意义的上下文向量。
- 这是现代 LLM(如 GPT 和 Transformer)成功的关键。
3.4.1 Computing the attention weights step by step

-
引入可训练权重矩阵:
- 三个权重矩阵 W q W_q Wq、 W k W_k Wk、 W v W_v Wv 用于将输入嵌入 x ( i ) x(i) x(i) 投影到 查询 (Query)、键 (Key) 和 值 (Value) 向量空间。
- 这些权重矩阵是模型训练过程中优化的参数,决定了上下文表示的质量。
-
缩放点积注意力的计算流程:
- 查询 (Query):表示当前关注的输入元素。
- 键 (Key):表示序列中每个元素的匹配特征。
- 值 (Value):表示输入序列中每个元素的实际内容。
- 目标:通过查询和键计算注意力权重,然后用权重对值进行加权求和,生成上下文向量。
- 实现过程:逐步计算查询、键、值向量 → 点积计算注意力分数 → 缩放与归一化 → 加权求和生成上下文向量。
1. 权重矩阵初始化
首先,定义输入和输出嵌入的维度 d in d_{\text{in}} din 和 d out d_{\text{out}} dout,并初始化三个权重矩阵 W q W_q Wq、 W k W_k Wk、 W v W_v Wv:
# 定义输入和输出嵌入维度
x_2 = inputs[1] # 第二个输入元素
d_in = inputs.shape[1] # 输入嵌入维度 d_in = 3
d_out = 2 # 输出嵌入维度 d_out = 2# 初始化权重矩阵
torch.manual_seed(123)
W_query = torch.nn.Parameter(torch.rand(d_in, d_out), requires_grad=False)
W_key = torch.nn.Parameter(torch.rand(d_in, d_out), requires_grad=False)
W_value = torch.nn.Parameter(torch.rand(d_in, d_out), requires_grad=False)
注意:在实际训练中,
requires_grad=True使得这些矩阵可以更新,但这里为了简化输出结果,设置为False。
2. 查询、键和值向量的计算
通过矩阵乘法,将输入 x 2 x_2 x2 投影到查询、键和值向量空间:
query_2 = x_2 @ W_query
key_2 = x_2 @ W_key
value_2 = x_2 @ W_value
print(query_2)
结果:
查询向量是一个二维向量(因为 d out = 2 d_{\text{out}} = 2 dout=2):
tensor([0.4306, 1.4551])
权重参数 vs. 注意力权重:
- 权重参数是神经网络的可训练参数,定义了网络的连接模式。
- 注意力权重是动态计算的值,决定了上下文向量对输入序列不同部分的关注程度。
3. 计算所有键和值向量
虽然当前目标是计算上下文向量 z ( 2 ) z^{(2)} z(2),但需要整个输入序列的键和值向量来计算注意力权重:
keys = inputs @ W_key
values = inputs @ W_value
print("keys.shape:", keys.shape)
print("values.shape:", values.shape)
结果:
keys.shape: torch.Size([6, 2])
values.shape: torch.Size([6, 2])
投影成功将六个输入词从三维嵌入空间映射到二维空间。
4. 计算注意力分数

对于查询向量 q ( 2 ) q^{(2)} q(2) 和键向量 k ( 2 ) k^{(2)} k(2),点积计算未归一化的注意力分数:
keys_2 = keys[1]
attn_score_22 = query_2.dot(keys_2)
print(attn_score_22)
结果:
tensor(1.8524)
推广到所有注意力分数:
attn_scores_2 = query_2 @ keys.T
print(attn_scores_2)
结果:
tensor([1.2705, 1.8524, 1.8111, 1.0795, 0.5577, 1.5440])

5. 缩放并归一化注意力分数
为了避免梯度过小的问题,将注意力分数除以键向量维度的平方根 d k \sqrt{d_k} dk,然后用 Softmax 对其归一化:
d_k = keys.shape[-1]
attn_weights_2 = torch.softmax(attn_scores_2 / d_k**0.5, dim=-1)
print(attn_weights_2)
结果:
tensor([0.1500, 0.2264, 0.2199, 0.1311, 0.0906, 0.1820])
缩放的意义:
- 避免注意力分数过大导致的梯度消失问题。
- 在嵌入维度较高(如 GPT 模型中常见的 d k > 1000 d_k > 1000 dk>1000)时尤其重要。

6. 计算上下文向量
使用归一化的注意力权重对值向量进行加权求和,得到上下文向量:
context_vec_2 = attn_weights_2 @ values
print(context_vec_2)
结果:
tensor([0.3061, 0.8210])
7. 推广到所有上下文向量
虽然上面只计算了 z ( 2 ) z^{(2)} z(2),但可以将该过程推广到整个序列,计算所有上下文向量 z ( 1 ) , z ( 2 ) , . . . , z ( T ) z^{(1)}, z^{(2)}, ..., z^{(T)} z(1),z(2),...,z(T)。
为什么使用 Query、Key 和 Value?
“Query(查询)”、“Key(键)” 和 “Value(值)” 是注意力机制中的核心概念,这些术语借鉴自信息检索和数据库领域,在这些领域中,类似的概念被用来存储、搜索和检索信息。
1. Query(查询)
- 类比于数据库中的搜索查询。
- 它表示当前模型关注的输入元素(例如句子中的一个单词或一个 token)。
- Query 用于探测输入序列的其他部分,判断需要对哪些部分给予更多注意力。
2. Key(键)
- 类比于数据库中的索引键,用于匹配和搜索。
- 在注意力机制中,输入序列中的每个元素(例如每个单词)都关联一个 Key,用于与 Query 进行比较。
- Key 用来表示输入序列中每个部分的匹配特征。
3. Value(值)
- 类比于数据库中的键值对中的值。
- 在注意力机制中,Value 表示输入序列中每个元素的实际内容或表示。
- 当模型通过 Query 和 Key 判断出哪些部分最相关时,它会检索对应的 Value,作为最终的输出。
注意力机制通过 Query 和 Key 的交互确定相关性,并使用 Value 构造最终的上下文表示。这种设计使得模型能够专注于输入序列中最重要的信息。
3.4.2 Implementing a compact self-attention Python class
1. 自注意力机制的实现
1.1 初版实现:SelfAttention_v1
特点:
- 使用
nn.Parameter手动初始化权重矩阵 W q W_q Wq、 W k W_k Wk、 W v W_v Wv。 - 权重矩阵将输入嵌入 x x x 投影到查询、键和值向量。
- 通过矩阵操作实现注意力机制,包括:
- 计算注意力分数(点积)。
- 使用 Softmax 归一化。
- 根据注意力权重加权求和值向量,生成上下文向量。
代码:
import torch.nn as nnclass SelfAttention_v1(nn.Module):def __init__(self, d_in, d_out):super().__init__()self.W_query = nn.Parameter(torch.rand(d_in, d_out))self.W_key = nn.Parameter(torch.rand(d_in, d_out))self.W_value = nn.Parameter(torch.rand(d_in, d_out))def forward(self, x):keys = x @ self.W_keyqueries = x @ self.W_queryvalues = x @ self.W_valueattn_scores = queries @ keys.Tattn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)context_vec = attn_weights @ valuesreturn context_vec
示例输出:
torch.manual_seed(123)
sa_v1 = SelfAttention_v1(d_in=3, d_out=2)
print(sa_v1(inputs))
输出结果为六个上下文向量:
tensor([[0.2996, 0.8053],[0.3061, 0.8210],[0.3058, 0.8203],[0.2948, 0.7939],[0.2927, 0.7891],[0.2990, 0.8040]], grad_fn=<MmBackward0>)

1.2 改进版实现:SelfAttention_v2
改进点:
- 使用 PyTorch 的
nn.Linear替代nn.Parameter初始化权重矩阵。 - 优势:
- 自动优化的权重初始化:
nn.Linear提供更稳定的训练效果。 - 代码更加简洁:
nn.Linear内置了权重矩阵和偏置项的管理。
- 自动优化的权重初始化:
代码:
class SelfAttention_v2(nn.Module):def __init__(self, d_in, d_out, qkv_bias=False):super().__init__()self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)def forward(self, x):keys = self.W_key(x)queries = self.W_query(x)values = self.W_value(x)attn_scores = queries @ keys.Tattn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)context_vec = attn_weights @ valuesreturn context_vec
示例输出:
torch.manual_seed(789)
sa_v2 = SelfAttention_v2(d_in=3, d_out=2)
print(sa_v2(inputs))
输出结果为:
tensor([[-0.0739, 0.0713],[-0.0748, 0.0703],[-0.0749, 0.0702],[-0.0760, 0.0685],[-0.0763, 0.0679],[-0.0754, 0.0693]], grad_fn=<MmBackward0>)
2. 对比 SelfAttention_v1 和 SelfAttention_v2**
-
核心区别:
v1使用手动初始化的权重矩阵,权重由torch.rand随机生成。v2使用nn.Linear初始化权重,采用优化的初始化策略,训练更加稳定。
-
结果不同:
- 两种实现的输出不同,原因是权重初始化方式不同。
练习:验证两种实现的等价性
可以将 v2 的权重转移到 v1,以验证两者的等价性。
# 将 v2 的权重赋值给 v1
sa_v1.W_query.data = sa_v2.W_query.weight.data.T
sa_v1.W_key.data = sa_v2.W_key.weight.data.T
sa_v1.W_value.data = sa_v2.W_value.weight.data.T
提示:
nn.Linear中的权重矩阵是转置存储的,因此需要转置赋值。
自注意力机制的进一步增强:
1. 因果注意力 (Causal Attention)
- 定义:限制模型只能关注输入序列中当前及之前的部分,防止访问未来信息。
- 适用场景:语言建模任务中,预测下一个单词时不能参考未来的单词。
2. 多头注意力 (Multi-Head Attention)
- 定义:将注意力机制拆分为多个并行的“头”,每个头学习数据的不同特征。
- 优势:
- 不同头可以关注输入序列的不同部分,捕获更丰富的语义信息。
- 提高模型在复杂任务中的性能。
3.5 Hiding future words with causal attention
在许多大语言模型 (LLM) 任务中,模型在预测序列中的下一个 token 时,自注意力机制需要仅关注当前及之前的 token,而不能访问未来的 token。这种受限的注意力机制称为因果注意力 (Causal Attention),也叫掩码注意力 (Masked Attention)。

1. 因果注意力的定义与作用
- 定义:因果注意力限制模型在计算注意力分数时,只能考虑输入序列中当前位置及之前的 token。
- 对比标准自注意力:
- 标准自注意力:可以访问整个输入序列(包括未来的 token)。
- 因果注意力:只能访问当前位置及之前的 token,屏蔽未来 token 的信息。
- 作用:
- 防止模型泄露未来信息,确保预测下一个 token 时仅依赖过去和当前的上下文。
- 是 GPT 类语言模型实现的核心机制之一。
3.5.1 Applying a causal attention mask
因果注意力掩码的实现步骤

第一步:计算注意力分数与权重
- 通过点积计算注意力分数,并使用
Softmax归一化为注意力权重。
代码:
# 使用 SelfAttention_v2 对象的 W_query 和 W_key 线性层计算查询向量和键向量
queries = sa_v2.W_query(inputs) # 查询向量 (queries),形状为 [batch_size, seq_len, d_out]
keys = sa_v2.W_key(inputs) # 键向量 (keys),形状为 [batch_size, seq_len, d_out]# 计算注意力分数 (attention scores) 矩阵
# queries @ keys.T: 点积计算每个查询与所有键之间的相似度
# 结果形状为 [batch_size, seq_len, seq_len],表示每个查询与所有键的注意力分数
attn_scores = queries @ keys.T# 使用 Softmax 函数对注意力分数进行缩放和归一化,得到注意力权重 (attention weights)
# 缩放因子 keys.shape[-1]**0.5 用于平衡高维点积的数值范围,防止梯度过小或过大
# dim=-1 指定在最后一个维度 (seq_len) 上进行归一化,使每一行的权重和为 1
attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.
输出示例:
tensor([[0.1921, 0.1646, 0.1652, 0.1550, 0.1721, 0.1510],[0.2041, 0.1659, 0.1662, 0.1496, 0.1665, 0.1477],[0.2036, 0.1659, 0.1662, 0.1498, 0.1664, 0.1480],[0.1869, 0.1667, 0.1668, 0.1571, 0.1661, 0.1564],[0.1830, 0.1669, 0.1670, 0.1588, 0.1658, 0.1585],[0.1935, 0.1663, 0.1666, 0.1542, 0.1666, 0.1529]],
grad_fn=<SoftmaxBackward0>)
第二步:生成掩码并应用
- 使用 PyTorch 的
tril函数生成一个下三角矩阵掩码,用于屏蔽对角线以上的未来 token。 - 将掩码矩阵与注意力权重相乘,屏蔽未来 token 的权重。
代码:
# 获取注意力分数矩阵的序列长度 (seq_len)
# 注意:这里假设 attn_scores 是一个方阵,形状为 [seq_len, seq_len]
context_length = attn_scores.shape[0]# 创建一个下三角矩阵掩码(Mask),形状为 [seq_len, seq_len]
# torch.ones(context_length, context_length):生成全 1 矩阵
# torch.tril(...):将矩阵的上三角部分置为 0,仅保留对角线及以下部分
mask_simple = torch.tril(torch.ones(context_length, context_length)) # 对注意力权重矩阵应用掩码
# 将注意力权重与下三角掩码逐元素相乘
# 结果中,上三角部分的注意力权重被置为 0,防止未来 token 的干扰
masked_simple = attn_weights * mask_simple
掩码示例:
tensor([[1., 0., 0., 0., 0., 0.],[1., 1., 0., 0., 0., 0.],[1., 1., 1., 0., 0., 0.],[1., 1., 1., 1., 0., 0.],[1., 1., 1., 1., 1., 0.],[1., 1., 1., 1., 1., 1.]])
应用掩码后的结果:
tensor([[0.1921, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],[0.2041, 0.1659, 0.0000, 0.0000, 0.0000, 0.0000],[0.2036, 0.1659, 0.1662, 0.0000, 0.0000, 0.0000],[0.1869, 0.1667, 0.1668, 0.1571, 0.0000, 0.0000],[0.1830, 0.1669, 0.1670, 0.1588, 0.1658, 0.0000],[0.1935, 0.1663, 0.1666, 0.1542, 0.1666, 0.1529]],
grad_fn=<MulBackward0>)
第三步:重新归一化注意力权重
- 将掩码后的注意力权重重新归一化,以确保每一行的权重和为 1。
- 归一化通过将每一行的权重除以其行和完成。
代码:
row_sums = masked_simple.sum(dim=-1, keepdim=True) # 计算行和
masked_simple_norm = masked_simple / row_sums # 归一化
归一化后的结果:
tensor([[1.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],[0.5517, 0.4483, 0.0000, 0.0000, 0.0000, 0.0000],[0.3800, 0.3097, 0.3103, 0.0000, 0.0000, 0.0000],[0.2758, 0.2460, 0.2462, 0.2319, 0.0000, 0.0000],[0.2175, 0.1983, 0.1984, 0.1888, 0.1971, 0.0000],[0.1935, 0.1663, 0.1666, 0.1542, 0.1666, 0.1529]],
grad_fn=<DivBackward0>)
优化后的因果注意力实现

可以进一步优化掩码操作,减少步骤数。通过以下“掩码技巧”,直接在注意力分数矩阵中用 -inf 替代被掩码的位置,从而避免单独的归一化步骤。
优化步骤:
- 使用
triu函数生成上三角掩码矩阵,并将掩码位置替换为-inf。 - 直接对掩码后的分数矩阵应用
Softmax,无需手动归一化,因为Softmax会自动将-inf位置视为 0。
代码:
mask = torch.triu(torch.ones(context_length, context_length), diagonal=1) # 上三角掩码
masked = attn_scores.masked_fill(mask.bool(), -torch.inf) # 替换为 -inf
attn_weights = torch.softmax(masked / keys.shape[-1]**0.5, dim=-1) # 直接归一化
掩码后的注意力分数矩阵:
tensor([[0.2899, -inf, -inf, -inf, -inf, -inf],[0.4656, 0.1723, -inf, -inf, -inf, -inf],[0.4594, 0.1703, 0.1731, -inf, -inf, -inf],[0.2642, 0.1024, 0.1036, 0.0186, -inf, -inf],[0.2183, 0.0874, 0.0882, 0.0177, 0.0786, -inf],[0.3408, 0.1270, 0.1290, 0.0198, 0.1290, 0.0078]],
grad_fn=<MaskedFillBackward0>)
最终归一化的注意力权重:
tensor([[1.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],[0.5517, 0.4483, 0.0000, 0.0000, 0.0000, 0.0000],[0.3800, 0.3097, 0.3103, 0.0000, 0.0000, 0.0000],[0.2758, 0.2460, 0.2462, 0.2319, 0.0000, 0.0000],[0.2175, 0.1983, 0.1984, 0.1888, 0.1971, 0.0000],[0.1935, 0.1663, 0.1666, 0.1542, 0.1666, 0.1529]],
grad_fn=<SoftmaxBackward0>)
尽管在未归一化的分数矩阵中包含了被掩码的位置,Softmax 的归一化特性确保了这些位置不会影响最终的注意力权重:
- 掩码位置的值为
-inf,其指数为 ( e^{-\infty} \approx 0 ),因此对权重分布没有实际贡献。 - 最终的归一化效果相当于仅在未掩码的位置上计算
Softmax,从而避免了未来 token 的信息泄漏。
3.5.2 Masking additional attention weights with dropout
深度学习中的Dropout技术
- Dropout的作用:防止模型过拟合,随机丢弃部分神经元以提升模型泛化能力。
- 在注意力机制中,通常在计算注意力权重后应用Dropout,并按比例放大剩余权重以保持均衡。
- Dropout仅在训练阶段使用,推理阶段禁用。
什么是Dropout?
- 定义:
Dropout是一种正则化技术,在训练过程中随机忽略(即“丢弃”)部分隐藏层的神经元,从而防止模型过拟合。 - 关键点:
- Dropout 仅在训练阶段使用,推理阶段会禁用,即所有神经元都会参与预测。

Transformer模型中的Dropout(例如GPT)
- 在注意力机制中的应用:
Dropout可以在以下两种时机应用:- 计算完注意力权重之后。
- 将注意力权重应用到**值向量(value vectors)**之后。
- 常见实践:通常在计算完注意力权重后应用Dropout。
PyTorch代码示例
-
使用PyTorch实现Dropout:
import torch torch.manual_seed(123) # 保证随机性可复现 dropout = torch.nn.Dropout(0.5) # 50%的dropout概率 example = torch.ones(6, 6) # 创建一个6x6的全1矩阵 print(dropout(example))- 输出结果:
Dropout会随机将约50%的值置零,同时对剩余的非零值按比例放大(放大因子为1/0.5=2),以保持整体权重的均衡。示例输出如下:tensor([[2., 2., 0., 2., 2., 0.],[0., 0., 0., 2., 0., 2.],[2., 2., 2., 2., 0., 2.],[0., 2., 2., 0., 0., 2.],[0., 2., 0., 2., 0., 2.],[0., 2., 2., 2., 2., 0.]])
- 输出结果:
-
在注意力权重矩阵中的Dropout
- 应用在注意力权重上:
attn_weights = torch.rand(6, 6) # 假设注意力权重矩阵 torch.manual_seed(123) # 保证一致性 print(dropout(attn_weights))- 输出结果:随机置零一部分注意力权重,剩余权重按比例放大。例如:
tensor([[2.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],[0.7599, 0.6194, 0.6206, 0.0000, 0.0000, 0.0000],[0.0000, 0.4921, 0.4925, 0.0000, 0.0000, 0.0000],[0.0000, 0.3966, 0.0000, 0.3775, 0.0000, 0.0000],[0.0000, 0.3327, 0.3331, 0.3084, 0.3331, 0.0000]],grad_fn=<MulBackward0>)- 注意:不同操作系统可能导致输出结果略有差异,具体可参考PyTorch Issue。
3.5.3 Implementing a compact causal attention class
接下来我们要将因果注意力(Causal Attention)和Dropout功能整合到SelfAttention类中,为后续开发多头注意力机制(Multi-Head Attention)提供模板。
支持批量输入
- 背景:需要确保支持多输入批次的处理,因为数据加载器可能生成多条输入文本的批次。
- 实现方法:
- 示例输入(假设每条输入包含6个标记,每个标记有3维嵌入向量):
batch = torch.stack((inputs, inputs), dim=0) # 生成批量数据 print(batch.shape) # 输出: torch.Size([2, 6, 3])
- 示例输入(假设每条输入包含6个标记,每个标记有3维嵌入向量):
CausalAttention类
功能扩展:在之前SelfAttention类的基础上新增了Dropout层和因果掩码(causal mask)。
代码实现:
import torch
import torch.nn as nnclass CausalAttention(nn.Module):def __init__(self, d_in, d_out, context_length, dropout, qkv_bias=False):super().__init__()self.d_out = d_outself.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)self.dropout = nn.Dropout(dropout)self.register_buffer('mask',torch.triu(torch.ones(context_length, context_length), diagonal=1))def forward(self, x):b, num_tokens, d_in = x.shapekeys = self.W_key(x)queries = self.W_query(x)values = self.W_value(x)# 计算注意力得分attn_scores = queries @ keys.transpose(1, 2)attn_scores.masked_fill_(self.mask.bool()[:num_tokens, :num_tokens], -torch.inf)# 应用Softmax和Dropoutattn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)attn_weights = self.dropout(attn_weights)# 计算上下文向量context_vec = attn_weights @ valuesreturn context_vec
关键组件分析
-
register_buffer的作用:- 注册因果掩码为缓冲区(buffer),避免它被视为模型的可训练参数。
- 自动管理缓冲区的设备位置(CPU或GPU),避免手动管理可能导致的设备不匹配问题。
-
因果掩码(Causal Mask):
- 确保只关注当前或之前的标记,而不会泄露未来的信息。掩码通过
torch.triu函数生成上三角矩阵来实现。
- 确保只关注当前或之前的标记,而不会泄露未来的信息。掩码通过
-
Dropout层:
- 在注意力权重(
attn_weights)上随机丢弃一部分权重,增强正则化效果。
- 在注意力权重(
-
高效操作:
- 使用带下划线的方法(如
masked_fill_)进行原地操作,避免额外的内存拷贝。
- 使用带下划线的方法(如
运行示例
torch.manual_seed(123)
context_length = batch.shape[1]
ca = CausalAttention(d_in=3, d_out=2, context_length=context_length, dropout=0.0)
context_vecs = ca(batch)
print("context_vecs.shape:", context_vecs.shape)
- 输出:
context_vecs.shape: torch.Size([2, 6, 2])- 每个标记的嵌入向量维度从输入的3维降到输出的2维。

我们已经实现了因果注意力(Causal Attention)的基础功能。接下来将扩展此类,开发多头注意力模块,通过并行实现多个因果注意力机制进一步增强模型能力。
3.6 Extending single-head attention to multi-head attention
本节专注于将之前实现的CausalAttention扩展为多头注意力(Multi-Head Attention),实现并行化的注意力机制,提升模型的表达能力。
多头注意力概念
-
“多头”定义:
- 多头注意力通过将注意力机制分为多个独立的“头”并行运行,每个头具有独立的权重。
- 单个因果注意力模块是单头注意力,即只有一个注意力权重集逐步处理输入。
-
多头的作用:
- 不同头对输入数据进行不同的线性变换(Query、Key、Value)以捕捉更复杂的模式。
- 通过将多个注意力模块的输出拼接,丰富嵌入的表征能力。

3.6.1 堆叠多个因果注意力模块
实现思路:
- 创建多个
CausalAttention实例,每个实例独立计算。 - 将每个实例的输出沿最后一个维度拼接形成最终上下文向量。
实现代码:
import torch
import torch.nn as nnclass MultiHeadAttentionWrapper(nn.Module):def __init__(self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False):"""多头注意力封装类的初始化方法。Args:d_in (int): 输入嵌入的维度。d_out (int): 每个注意力头输出嵌入的维度。context_length (int): 输入序列的长度(标记数)。dropout (float): dropout概率,用于防止过拟合。num_heads (int): 注意力头的数量。qkv_bias (bool): 是否为Query、Key、Value线性变换添加偏置。"""super().__init__()# 创建多个 CausalAttention 模块,每个模块对应一个独立的注意力头# 使用 nn.ModuleList 保存这些模块,以便逐一调用self.heads = nn.ModuleList([CausalAttention(d_in, d_out, context_length, dropout, qkv_bias)for _ in range(num_heads) # 根据头数 num_heads 创建多个模块])def forward(self, x):"""前向传播方法,计算多头注意力的输出。Args:x (Tensor): 输入张量,形状为 [batch_size, context_length, d_in]。Returns:Tensor: 多头注意力拼接后的输出张量,形状为 [batch_size, context_length, num_heads * d_out]。"""# 遍历所有头,对输入 x 进行逐一处理,并沿最后一维(嵌入维度)拼接所有头的输出return torch.cat([head(x) for head in self.heads], dim=-1)
运行示例
torch.manual_seed(123)
context_length = batch.shape[1] # 序列长度为6
d_in, d_out = 3, 2 # 输入嵌入3维,输出嵌入每头2维
mha = MultiHeadAttentionWrapper(d_in, d_out, context_length, 0.0, num_heads=2)context_vecs = mha(batch)
print(context_vecs)
print("context_vecs.shape:", context_vecs.shape)
输出:
context_vecs.shape: torch.Size([2, 6, 4])
解释:
- 第一维:
2(表示两条输入文本)。 - 第二维:
6(每条文本包含6个标记)。 - 第三维:
4(每个标记的嵌入维度为d_out*num_heads = 2*2 = 4)。

习题示例:嵌入降维
目标:将输出的上下文向量维度调整为2,而不是4,同时保持num_heads=2。
提示:无需修改类的实现,仅调整d_out。
解决方法:
d_in, d_out = 3, 1 # 每头输出嵌入1维,总嵌入维度为 num_heads*d_out = 2*1 = 2
mha = MultiHeadAttentionWrapper(d_in, d_out, context_length, 0.0, num_heads=2)
context_vecs = mha(batch)
print("context_vecs.shape:", context_vecs.shape) # 输出: torch.Size([2, 6, 2])
当前实现中,多个CausalAttention模块是顺序计算的([head(x) for head in self.heads])。
可以通过矩阵操作实现并行处理,显著提升效率,具体方法将在后续优化中展开。
3.6.2 Implementing multi-head attention with weight splits
- 背景
早期实现中,多头注意力机制是通过MultiHeadAttentionWrapper和CausalAttention两个类的组合来实现的。具体方式为:
CausalAttention类:实现单头注意力。MultiHeadAttentionWrapper类:通过创建多个CausalAttention实例(即多个注意力头)并将其结果拼接,完成多头注意力。
这种实现存在效率问题:
- 对每个注意力头分别执行矩阵变换(queries、keys、values 的线性变换),导致冗余计算。
- 优化设计
为了解决上述问题,定义了一个新的MultiHeadAttention类,它直接整合了多头注意力的功能,核心优化如下: - 在类中通过张量变换实现对输入的分头操作(无需多个单头实例)。
- 使用线性层(
nn.Linear)一次性计算 query、key、value 的投影,避免重复计算。 - 引入
view和transpose操作,将投影后的张量重新整形为多头结构,并高效执行批量矩阵乘法。 - 在拼接多头输出后,使用一个额外的输出投影层(
self.out_proj)整合结果。
MultiHeadAttention 类的核心概念总结
-
整体概览:
- 虽然
MultiHeadAttention类中张量的.view和.transpose操作看似复杂,但其核心思想与MultiHeadAttentionWrapper类相同。 - 在
MultiHeadAttentionWrapper中,我们通过堆叠多个单头注意力模块创建多头注意力层,而MultiHeadAttention类采用的是集成方法:直接从一个多头层开始,然后内部拆分为多个注意力头。
- 虽然
-
张量拆分:
- 查询(Query)、键(Key)和值(Value)的张量通过
.view和.transpose方法进行拆分。 - 输入首先经过线性层转换,得到查询、键和值的嵌入表示。随后通过
.view将张量从形状(b, num_tokens, d_out)重新调整为(b, num_tokens, num_heads, head_dim),其中head_dim = d_out / num_heads。 - 再通过
.transpose将num_heads维度移动到num_tokens维度之前,形成最终形状(b, num_heads, num_tokens, head_dim)。
- 查询(Query)、键(Key)和值(Value)的张量通过
-
批量矩阵乘法:
- 使用批量矩阵乘法高效计算注意力分数。
- 比如,张量
a的形状为(b, num_heads, num_tokens, head_dim),执行操作a @ a.transpose(2, 3)会对最后两个维度(num_tokens和head_dim)执行矩阵乘法,并在各个头上独立重复。 - 此操作等效于对每个头分别计算注意力分数,但更简洁和高效。
-
代码示例说明:
-
批量矩阵乘法:
print(a @ a.transpose(2, 3))- 输出是每个注意力头的矩阵乘积结果。
-
单独计算每个注意力头的结果:
first_head = a[0, 0, :, :] first_res = first_head @ first_head.T print("First head:\n", first_res)- 此方法验证了批量矩阵乘法的正确性,与直接操作各头的结果一致。
-
-
输出重组:
- 在计算注意力权重和上下文向量后,将各个头的上下文向量从
(b, num_heads, num_tokens, head_dim)转置回(b, num_tokens, num_heads, head_dim)。 - 再通过
.view将其重组为(b, num_tokens, d_out),将所有头的输出整合为最终的输出。
- 在计算注意力权重和上下文向量后,将各个头的上下文向量从
-
输出投影层:
- 在
MultiHeadAttention类中添加了一个输出投影层(self.out_proj)。 - 虽然这层不是必须的,但常见于大规模语言模型(LLMs)的架构中,因此在此实现中也被保留。
- 在
-
效率对比:
- 相较于
MultiHeadAttentionWrapper,MultiHeadAttention更高效。 - 在
MultiHeadAttentionWrapper中,每个注意力头都需要单独计算查询、键和值的线性变换,这会重复执行昂贵的矩阵乘法操作。而在MultiHeadAttention中,这些操作只需执行一次,随后通过张量拆分完成不同头的计算。
- 相较于
总结来看,MultiHeadAttention 的实现通过张量重塑和批量矩阵操作,显著提升了多头注意力的计算效率,同时保留了灵活性和功能性。
MultiHeadAttention类代码解析
以下是关键代码和功能解析:
class MultiHeadAttention(nn.Module):def __init__(self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False):super().__init__()assert d_out % num_heads == 0, "d_out 必须能被 num_heads 整除"self.d_out = d_outself.num_heads = num_headsself.head_dim = d_out // num_heads# 定义 query、key、value 的线性变换self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)# 输出投影层self.out_proj = nn.Linear(d_out, d_out)self.dropout = nn.Dropout(dropout)# 定义因果掩码,防止当前 token 关注未来 tokenself.register_buffer("mask", torch.triu(torch.ones(context_length, context_length), diagonal=1))def forward(self, x):b, num_tokens, d_in = x.shape# 计算投影后的 query、key、valuekeys = self.W_key(x).view(b, num_tokens, self.num_heads, self.head_dim)queries = self.W_query(x).view(b, num_tokens, self.num_heads, self.head_dim)values = self.W_value(x).view(b, num_tokens, self.num_heads, self.head_dim)# 调整维度以方便矩阵运算keys = keys.transpose(1, 2)queries = queries.transpose(1, 2)values = values.transpose(1, 2)# 计算注意力分数attn_scores = queries @ keys.transpose(-2, -1)mask_bool = self.mask.bool()[:num_tokens, :num_tokens]attn_scores.masked_fill_(mask_bool, -torch.inf)# 计算注意力权重attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)attn_weights = self.dropout(attn_weights)# 计算上下文向量并恢复维度context_vec = (attn_weights @ values).transpose(1, 2).contiguous()context_vec = context_vec.view(b, num_tokens, self.d_out)# 应用输出投影层return self.out_proj(context_vec)
- 张量分头操作:
- 将投影后的张量
keys、queries、values从(b, num_tokens, d_out)调整为(b, num_tokens, num_heads, head_dim)。 - 使用
.view和.transpose操作完成分头与维度排列。
- 将投影后的张量
- 批量矩阵乘法:
- 注意力权重计算:
attn_scores = queries @ keys.transpose(-2, -1)。 - 结果与
values相乘得到上下文向量:context_vec = (attn_weights @ values)。 - 使用 PyTorch 的批量矩阵乘法功能,同时处理多个头的数据。
- 注意力权重计算:
相比之前的实现,这种方式效率更高,主要得益于:
- 一次性完成线性变换,避免对每个头重复执行计算。
- 利用张量操作(
view、transpose、@)在批量中高效实现矩阵运算。

- 使用实例
以下是MultiHeadAttention类的使用示例:
torch.manual_seed(123)
batch_size, context_length, d_in = batch.shape
d_out = 768 # GPT-2 的最小模型输出维度
num_heads = 12 # GPT-2 的最小模型头数mha = MultiHeadAttention(d_in, d_out, context_length, 0.0, num_heads)
context_vecs = mha(batch)
print(context_vecs)
print("context_vecs.shape:", context_vecs.shape)
- 与 GPT-2 对比
- GPT-2 小模型:
- 12 个注意力头。
- 输入和输出嵌入维度为 768。
- 上下文长度为 1024。
- 实现对比:
- 本代码实现支持 GPT-2 的最小配置。
- 可扩展至更大模型(如 25 个头,嵌入维度 1600)。
练习
请尝试初始化一个与 GPT-2 小模型类似的多头注意力模块,确保:
num_heads=12- 输入和输出嵌入维度均为 768。
- 上下文长度为 1024。
import torch
import torch.nn as nnclass MultiHeadAttention(nn.Module):def __init__(self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False):super().__init__()assert d_out % num_heads == 0, "d_out must be divisible by num_heads"self.d_out = d_outself.num_heads = num_headsself.head_dim = d_out // num_headsself.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)self.out_proj = nn.Linear(d_out, d_out)self.dropout = nn.Dropout(dropout)self.register_buffer("mask",torch.triu(torch.ones(context_length, context_length), diagonal=1))def forward(self, x):b, num_tokens, d_in = x.shapekeys = self.W_key(x).view(b, num_tokens, self.num_heads, self.head_dim).transpose(1, 2)queries = self.W_query(x).view(b, num_tokens, self.num_heads, self.head_dim).transpose(1, 2)values = self.W_value(x).view(b, num_tokens, self.num_heads, self.head_dim).transpose(1, 2)attn_scores = queries @ keys.transpose(-2, -1) / (self.head_dim ** 0.5)mask_bool = self.mask[:num_tokens, :num_tokens].bool()attn_scores.masked_fill_(mask_bool, float('-inf'))attn_weights = torch.softmax(attn_scores, dim=-1)attn_weights = self.dropout(attn_weights)context_vec = (attn_weights @ values).transpose(1, 2).contiguous().view(b, num_tokens, self.d_out)return self.out_proj(context_vec)# 初始化与 GPT-2 小模型类似的多头注意力模块
torch.manual_seed(123)# 参数设置
d_in = 768
d_out = 768
num_heads = 12
context_length = 1024
dropout = 0.1# 初始化模块
mha = MultiHeadAttention(d_in, d_out, context_length, dropout, num_heads)# 模拟输入数据
batch_size = 2
x = torch.randn(batch_size, context_length, d_in)# 前向计算
context_vecs = mha(x)# 打印输出结果
print("Output shape:", context_vecs.shape)
输出结果
运行代码后,输出形状将为:
Output shape: torch.Size([2, 1024, 768])
本章总结
-
增强的上下文表示:
注意力机制将输入元素转化为上下文向量,这些向量综合了所有输入的信息,从而丰富了输入表示。 -
自注意力(Self-Attention):
- 通过对输入元素进行加权求和,计算上下文向量。
- 注意力权重决定了每个输入元素对上下文向量的贡献大小。
-
点积注意力(Dot Product Attention):
- 注意力权重通过点积计算得出,点积是对两个向量逐元素相乘后求和的操作。
- 这种方法计算简洁高效,是实现加权求和的核心。
-
矩阵乘法的作用:
- 矩阵乘法代替了嵌套的循环操作,大幅提高了计算效率。
- 特别适用于大规模的注意力机制计算,使操作更加简洁和快速。
-
LLMs 中的缩放点积注意力:
- 引入了可训练的权重矩阵,用于从输入嵌入中计算查询(queries)、键(keys)和值(values)。
- 这些中间表示是计算注意力分数的基础。
-
因果注意力掩码(Causal Attention Mask):
- 在从左到右处理文本的语言模型中,因果掩码用于阻止模型访问未来的词元。
- 确保预测仅基于当前和之前的上下文。
-
Dropout 掩码:
- 在训练过程中通过随机将部分注意力权重置为零,防止模型过拟合。
- 提升模型的泛化能力。
-
多头注意力(Multi-Head Attention):
- 基于 Transformer 的模型通过多个注意力头(称为多头注意力)提取更丰富的特征。
- 每个注意力头独立运行,专注于输入的不同方面。
-
堆叠因果注意力:
- 多头注意力通过堆叠多个因果注意力模块实现。
- 这种堆叠增强了模型捕获数据中多样依赖关系的能力。
-
高效实现多头注意力:
- 使用批量矩阵乘法优化多头注意力模块的创建。
- 降低计算开销,提高模型性能。
相关文章:
【阅读记录-章节3】Build a Large Language Model (From Scratch)
目录 3 Coding attention mechanisms3.1 The problem with modeling long sequences背景:注意力机制的动机 3.2 Capturing data dependencies with attention mechanismsRNN的局限性与改进Transformer架构的革命 3.3 Attending to different parts of the input wit…...

three.js 对 模型使用 视频进行贴图修改材质
three.js 对 模型使用 视频进行贴图修改材质 https://threehub.cn/#/codeMirror?navigationThreeJS&classifyapplication&idvideoModel import * as THREE from three import { OrbitControls } from three/examples/jsm/controls/OrbitControls.js import { GLTFLoad…...

MySQL - 数据库基础 | 数据库操作 | 表操作
文章目录 1、数据库基础1.1为什么要有数据库1.2主流的数据库1.3连接MySQL1.4服务器、数据库、表的关系1.5 MySQL框架1.6 SQL分类1.7储存引擎 2.数据库操作2.1创建数据库2.2字符集和校验规则2.3删除数据库2.4修改数据库2.5备份与恢复2.6查看连接情况 3.表的操作3.1创建表3.2查看…...

maven父子项目
目录 一、创建Maven父子项目 二、父子项目的关联 三、父子项目的继承关系 四、构建父子项目 五、Maven父子项目的优势 Maven父子项目是一种项目结构,它允许一个父项目(也称为根项目)管理多个子项目(也称为模块)。…...
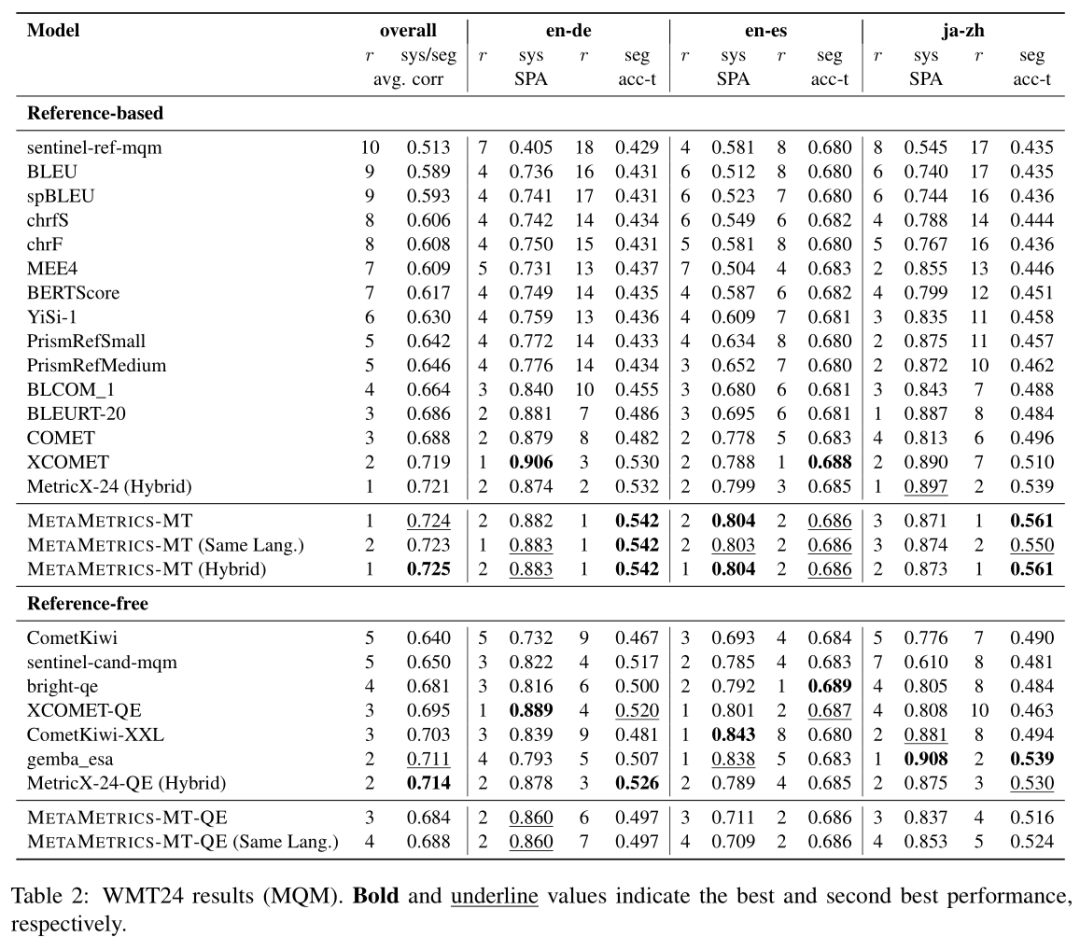
NLP论文速读(多伦多大学)|利用人类偏好校准来调整机器翻译的元指标
论文速读|MetaMetrics-MT: Tuning Meta-Metrics for Machine Translation via Human Preference Calibration 论文信息: 简介: 本文的背景是机器翻译(MT)任务的评估。在机器翻译领域,由于不同场景和语言对的需求差异&a…...
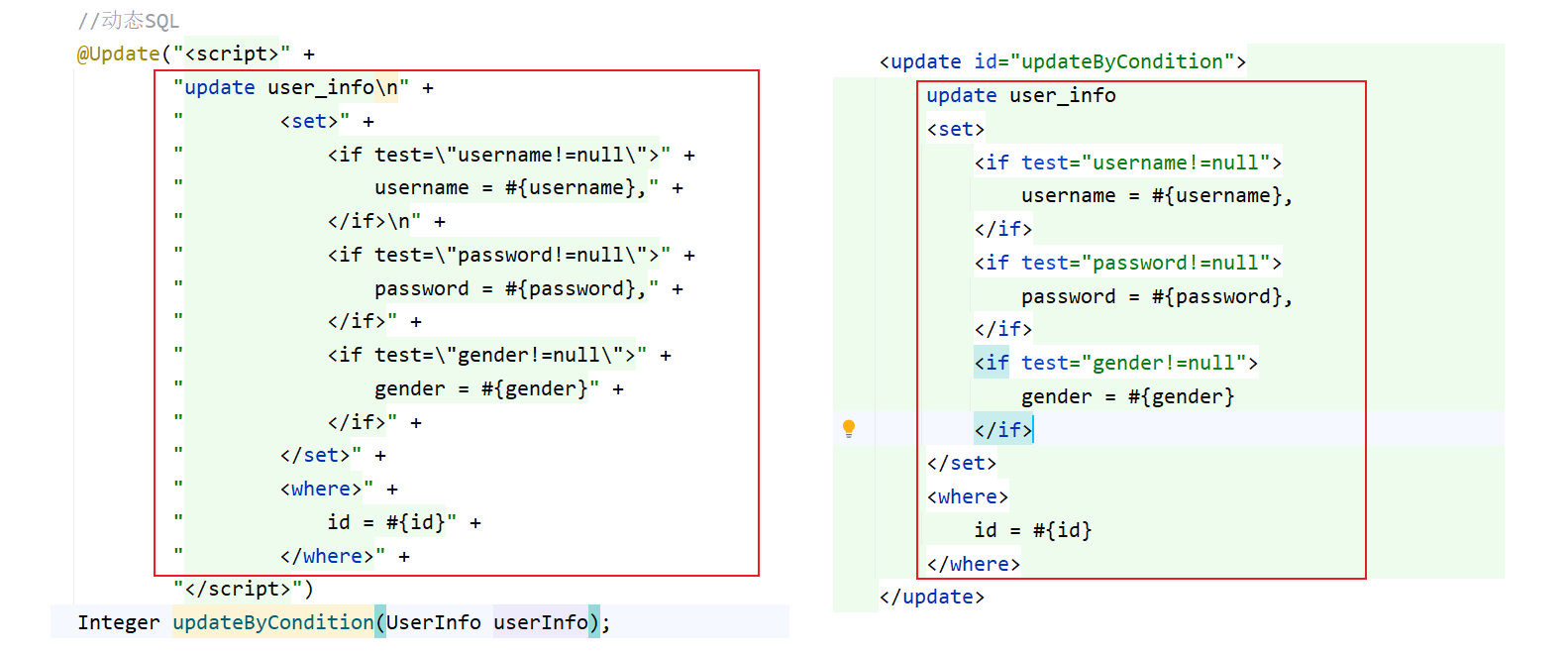
MyBatis——#{} 和 ${} 的区别和动态 SQL
1. #{} 和 ${} 的区别 为了方便,接下来使用注解方式来演示: #{} 的 SQL 语句中的参数是用过 ? 来起到类似于占位符的作用,而 ${} 是直接进行参数替换,这种直接替换的即时 SQL 就可能会出现一个问题 当传入一个字符串时ÿ…...

解决sql字符串
根据你描述的情况以及调试截图中的内容,我可以确认你的 sql 字符串在 Python 中由于转义字符的问题,可能导致在 Oracle 中运行时出错。 以下是一些排查和修改建议: 问题分析 转义字符问题: 在调试界面中可以看到,DEC…...

深度解析:Android APP集成与拉起微信小程序开发全攻略
目录 一、背景以及功能介绍 二、Android开发示例 2.1 下载 SDK 2.2 调用接口 2.3 获取小程序原始Id 2.4 报错提示:bad_param 2.4.1 错误日志 2.4.2 解决方案 相关推荐 一、背景以及功能介绍 需求:产品经理需要APP跳转到公司的小程序(最好指定页…...
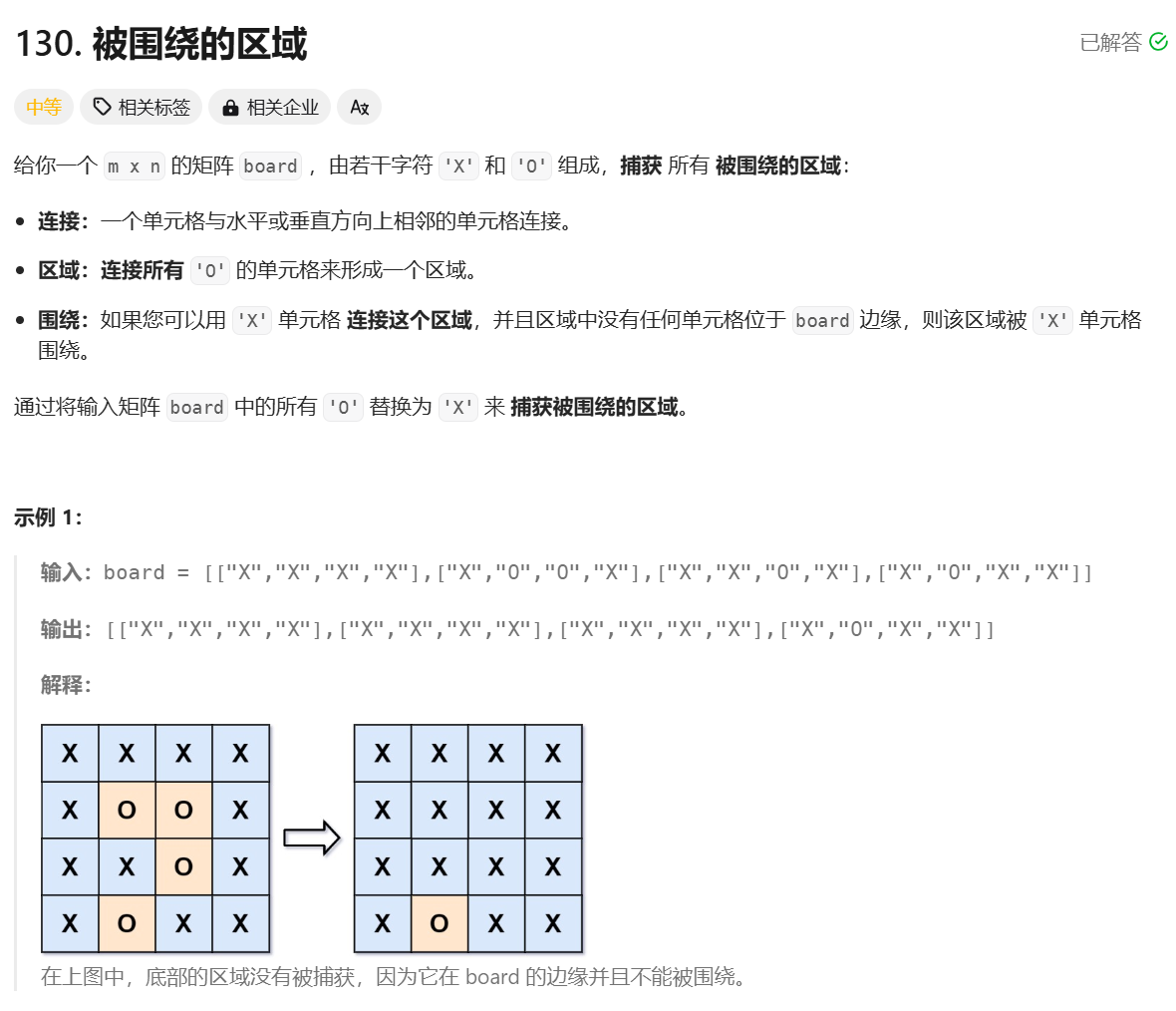
Leetcode 被围绕的区域
算法思想(解题思路): 这道题的核心是 将所有被边界包围的 O 保留下来,而将其他被围绕的 O 转换为 X。为了实现这一目标,我们可以分三步完成: 第一步:标记边界及其相连的 O 为特殊标记ÿ…...

ssm框架-spring-spring声明式事务
声明式事务概念 声明式事务是指使用注解或 XML 配置的方式来控制事务的提交和回滚。 开发者只需要添加配置即可, 具体事务的实现由第三方框架实现,避免我们直接进行事务操作! 使用声明式事务可以将事务的控制和业务逻辑分离开来,提…...

React第五节 组件三大属性之 props 用法详解
特性 a、props最好是仅限于父子上下级之间的数据传递,如果是祖孙多级之间传递属性,可以考虑使用props是否合适,或者使用替代方案 useContext() 或者使用 redux状态管理; b、props 中的属性是只读属性,如果想修改其中的…...

测评部署和管理 WordPress 最方便的面板
新版宝塔面板快速搭建WordPress新手教程 - 倚栏听风-Morii - 博客园 初学者使用1Panel面板快速搭建WordPress网站 - 倚栏听风-Morii - 博客园 可以看到,无论是宝塔还是1Panel,部署和管理WordPress都有些繁琐,而且还需要额外去配置Nginx和M…...

【系统分析师】-2024年11月论文-论DevOps开发
1、题目要求 论Devops及其应用。Devops是一组过程、方法与系统的统称,用于促进开发、技术运营和质量保障部门之间的沟通,协作与整合。它是一种重视软体开发人员和工厂运维技术人员之间沟通合作的模式。透过自动化“软件交付”和“架构变更”的流程&…...

算法【子数组最大累加和问题与扩展】
子数组最大累加和问题是一个非常经典的问题,也比较简单。但是扩展出的问题很多,在笔试、面试中特别常见,扩展出的问题很多非常有趣,解法也比较巧妙。 下面通过一些题目来加深理解。 题目一 测试链接:https://leetcode…...

小程序23-页面的跳转:navigation 组件详解
小程序中,如果需要进行跳转,需要使用 navigation 组件,常用属性: 1.url :当前小程序内的跳转链接 2.open-type:跳转方式 navigate:保留当前页面,跳转应用内的某个页面,…...

AI社媒引流工具:解锁智能化营销的新未来
在数字化浪潮的推动下,社交媒体成为品牌营销的主战场。然而,面对海量的用户数据和日益复杂的运营需求,传统营销方法显得力不从心。AI社媒引流王应运而生,帮助企业在多平台中精准触达目标用户,提升营销效率和效果。 1.…...

【Node.js】全面解析 Node.js 安全最佳实践:保护您的应用
Node.js 是一种强大的 JavaScript 运行时,广泛用于构建现代 Web 应用和 API。然而,由于其开放性和异步特性,Node.js 应用容易受到多种安全威胁的攻击,比如 SQL 注入、跨站脚本 (XSS) 和拒绝服务攻击 (DoS)。在本文中,我…...

Docker 用法详解
文章目录 一、Docker 快速入门1.1 部署 MYSQL1.2 命令解读: 二、Docker 基础2.1 常见命令:2.1.1 命令介绍:2.1.2 演示:2.1.3 命令别名: 2.2 数据卷:2.2.1 数据卷简介:2.2.2 数据卷命令ÿ…...
Python小游戏28——水果忍者
首先,你需要安装Pygame库。如果你还没有安装,可以使用以下命令进行安装: 【bash】 pip install pygame 《水果忍者》游戏代码: 【python】 import pygame import random import sys # 初始化Pygame pygame.init() # 设置屏幕尺寸 …...

Kafka Offset 自动提交和手动提交 - 漏消费与重复消费
目录 1. 引言 2. Offset 提交方式概述 2.1 自动提交 Offset 2.2 手动提交 Offset 3. 漏消费与重复消费的问题分析 3.1 自动提交模式下的漏消费和重复消费 漏消费 重复消费 3.2 手动提交模式下的漏消费和重复消费 漏消费 重复消费 4. 自动提交与手动提交的选择 4.1…...

ncmdumpGUI:彻底解决网易云音乐NCM格式限制的图形化工具
ncmdumpGUI:彻底解决网易云音乐NCM格式限制的图形化工具 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经遇到这样的情况:在网…...

Ryujinx模拟器全攻略:从硬件适配到性能优化的进阶指南
Ryujinx模拟器全攻略:从硬件适配到性能优化的进阶指南 【免费下载链接】Ryujinx 用 C# 编写的实验性 Nintendo Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/ry/Ryujinx Ryujinx是一款采用C#语言开发的开源Nintendo Switch模拟器࿰…...

Adobe Illustrator效率脚本:10个自动化工具让设计师工作效率提升300%
Adobe Illustrator效率脚本:10个自动化工具让设计师工作效率提升300% 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 为什么设计师总在重复相同的操作?调整画…...

7-Zip中文版:免费开源压缩软件的终极完整教程
7-Zip中文版:免费开源压缩软件的终极完整教程 【免费下载链接】7z 7-Zip Official Chinese Simplified Repository (Homepage and 7z Extra package) 项目地址: https://gitcode.com/gh_mirrors/7z1/7z 7-Zip中文版是Windows平台上一款功能强大的免费开源文件…...

SiameseUniNLU镜像免配置部署:预置中文分词器+标点规范化+繁简转换中间件
SiameseUniNLU镜像免配置部署:预置中文分词器标点规范化繁简转换中间件 1. 什么是SiameseUniNLU? SiameseUniNLU是一个通用自然语言理解模型,采用了创新的"提示(Prompt)文本(Text)"…...
技术实现)
微信小程序+Pixel Couplet Gen:多语言切换(中/英/日)技术实现
微信小程序Pixel Couplet Gen:多语言切换(中/英/日)技术实现 1. 项目背景与核心价值 Pixel Couplet Gen是一款融合传统春节文化与现代像素游戏风格的创新应用。通过ModelScope大模型驱动,它能生成独特的马年像素春联,…...

告别重复劳动:5分钟掌握Python剪映API,让视频剪辑自动化10倍提效
告别重复劳动:5分钟掌握Python剪映API,让视频剪辑自动化10倍提效 【免费下载链接】JianYingApi Third Party JianYing Api. 第三方剪映Api 项目地址: https://gitcode.com/gh_mirrors/ji/JianYingApi 你是否每天都要重复同样的视频剪辑操作&#…...

抖音音频提取终极指南:5分钟掌握douyin-downloader免费工具
抖音音频提取终极指南:5分钟掌握douyin-downloader免费工具 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback …...

ZenTimings:释放Ryzen平台内存潜力的专业调校工具
ZenTimings:释放Ryzen平台内存潜力的专业调校工具 【免费下载链接】ZenTimings 项目地址: https://gitcode.com/gh_mirrors/ze/ZenTimings 在AMD Ryzen平台的性能优化领域,内存时序调校常常被视为提升系统响应速度的"最后一块拼图"。然…...

Qwen2.5-14B-Instruct实战部署:像素剧本圣殿与Jira集成的剧本任务管理方案
Qwen2.5-14B-Instruct实战部署:像素剧本圣殿与Jira集成的剧本任务管理方案 1. 项目概述 像素剧本圣殿(Pixel Script Temple)是一款基于Qwen2.5-14B-Instruct深度微调的专业剧本创作工具。这个创新性解决方案将先进的大语言模型能力与复古像…...