机器学习系列----关联分析
目录
1. 关联分析的基本概念
1.1定义
1.2常用算法
2.Apriori 算法的实现
2.1 工作原理
2.2 算法步骤
2.3 优缺点
2.4 时间复杂度
2.5实际运用----市场购物篮分析
3. FP-Growth 算法
3.1 工作原理
3.2 算法步骤
3.3 优缺点
3.4 时间复杂度
3.5实际运用——网页点击行为分析
4.Apriori 与 FP-Growth 的对比
5.具体项目——基于Apriori 算法的市场篮子分析
5.1项目目标
5.2项目目录结构
5.3核心功能实现
在机器学习和数据挖掘领域,关联分析(Association Analysis) 是一种非常重要的技术,尤其在市场篮子分析和推荐系统中得到了广泛的应用。它的核心任务是发现不同变量或项目之间的有趣关系,通常以关联规则的形式表示。关联分析通过揭示数据之间的隐藏模式,帮助我们理解数据的结构,并为决策提供支持。
本文将介绍关联分析的基本概念、常用算法以及一个较为复杂的项目实现,以帮助大家更好地理解和应用关联分析技术。
1. 关联分析的基本概念
1.1定义
关联分析主要用于挖掘数据集中的频繁项集(Frequent Itemsets)和关联规则(Association Rules)。关联规则通常采用“如果-那么”的形式,即:如果条件 A 成立,则条件 B 成立。最常见的应用场景是市场篮子分析,在这个场景中,A 和 B 代表顾客购买的商品。
关联规则通常包含三个重要的度量:
支持度(Support):规则中项集的出现频率,表示在整个数据集中,A 和 B 同时出现的概率。
置信度(Confidence):规则的可靠性,表示在所有包含 A 的记录中,有多少比例同时包含 B。
提升度(Lift):规则的增强程度,衡量规则中项集之间的关联程度,表示 A 出现时,B 出现的概率是 A 不出现时的多少倍。
这些度量帮助我们从数据中筛选出最有意义的规则。
1.2常用算法
在实际应用中,关联分析最常用的算法是 Apriori 算法 和 FP-Growth 算法。
Apriori 算法
Apriori 算法通过逐层生成候选频繁项集,来挖掘数据中最频繁的项集。它的核心思想是“剪枝”:如果某个项集不是频繁的,那么它的所有超集也一定不是频繁的。该算法的过程通常包括以下几个步骤:
从单个项集开始,生成所有候选项集。
计算候选项集的支持度,并筛选出频繁项集。
使用频繁项集生成更大的候选项集,并重复步骤2。
FP-Growth 算法
FP-Growth(Frequent Pattern Growth)算法是一种基于压缩数据结构FP树(Frequent Pattern Tree)的算法,相比于 Apriori,FP-Growth 更加高效。它通过构建 FP 树来压缩数据,并递归地挖掘频繁项集,避免了候选项集生成的过程,因此在大数据集上具有较好的性能。
2.Apriori 算法的实现
2.1 工作原理
Apriori 算法是最早用于挖掘频繁项集和生成关联规则的算法之一,其核心思想是通过“剪枝”来减少候选项集的数量。算法的基本步骤如下:
生成候选项集:
首先,从单个项集开始,生成所有候选项集。然后,通过计算每个候选项集的支持度,筛选出支持度大于最小支持度的频繁项集。
接着,使用频繁项集生成更大的候选项集,直到不能生成新的候选项集为止。
剪枝:
剪枝策略是 Apriori 算法的核心思想。如果一个项集不是频繁的,那么它的所有超集也不可能是频繁的。因此,可以通过剪除不频繁的项集来减少计算量。
迭代计算:
每次迭代都会生成更大的项集,并筛选出频繁项集。这个过程会持续,直到找不到新的频繁项集为止。
2.2 算法步骤
假设数据集为 (D),最小支持度为 (min_support),最小置信度为 (min_confidence),Apriori 算法的基本步骤如下:
初始化:
将单项集(长度为1的项集)作为候选项集生成。
频繁项集生成:
在每一轮迭代中,从上一次得到的频繁项集生成候选项集。
计算这些候选项集的支持度,筛选出频繁项集。
生成规则:
基于频繁项集生成关联规则,并计算每条规则的置信度和提升度。
过滤出置信度和提升度大于最小阈值的规则。
2.3 优缺点
优点:
算法简单,容易理解。
可以用于发现各种类型的关联规则,不限于二元关联。
缺点:
计算代价较高,因为候选项集生成的过程会导致大量的计算。
在数据集较大时,计算频繁项集的过程中需要扫描数据库多次,效率较低。
2.4 时间复杂度
假设数据集中的项数为 (n),数据集的大小为 (m),最小支持度为 (min_support)。
最坏情况下,Apriori 需要扫描数据集 (k) 次((k) 为频繁项集的最大长度),每次扫描时,需要生成和验证大量的候选项集,因此时间复杂度通常较高。
2.5实际运用----市场购物篮分析
from mlxtend.frequent_patterns import apriori, association_rules
import pandas as pd# 示例交易数据
transactions = [['牛奶', '面包', '黄油'],['面包', '黄油'],['牛奶', '黄油'],['面包', '牛奶', '黄油'],
]# 转换为 DataFrame 格式
from mlxtend.preprocessing import TransactionEncoder
te = TransactionEncoder()
te_ary = te.fit(transactions).transform(transactions)
df = pd.DataFrame(te_ary, columns=te.columns_)# 使用 Apriori 算法挖掘频繁项集
frequent_itemsets = apriori(df, min_support=0.5, use_colnames=True)# 生成关联规则
rules = association_rules(frequent_itemsets, metric="confidence", min_threshold=0.7)# 输出关联规则
print(rules)
3. FP-Growth 算法
3.1 工作原理
FP-Growth 算法(Frequent Pattern Growth)是一个改进的算法,旨在提高频繁项集挖掘的效率。与 Apriori 不同,FP-Growth 避免了候选项集生成过程,通过构建一个压缩的树结构(FP-tree)来存储数据集,从而显著提高了性能。
3.2 算法步骤
FP-Growth 算法的步骤如下:
构建 FP-树:
扫描数据集,统计各项的频率,然后按频率排序。
根据频率排序后的项集,构建一个树结构(FP-tree)。树的每个节点表示一个项,每个路径表示一个事务的项集。
递归挖掘频繁项集:
从 FP-树中逐步挖掘频繁项集。对于每个节点,构造条件模式基(Conditional Pattern Base)并递归地构建条件 FP-树,直到无法生成新的频繁项集为止。
生成关联规则:
基于挖掘出的频繁项集,生成关联规则,并计算规则的置信度。
3.3 优缺点
优点:
FP-Growth 通过构建 FP 树来压缩数据,避免了频繁项集生成的过程,因此通常比 Apriori 更高效。
不需要多次扫描整个数据集,计算速度较快,适合大规模数据集。
FP-Growth 支持快速的递归计算,避免了生成大量候选项集的开销。
缺点:
需要存储树结构,可能会消耗较多内存,尤其是在数据集非常大的情况下。
需要构建树结构,理解和实现相对复杂。
3.4 时间复杂度
FP-Growth 的时间复杂度通常较低,因为它仅需要扫描数据集两次:第一次构建 FP 树,第二次递归地挖掘频繁项集。
如果数据集非常大,构建和递归过程中的内存消耗可能会成为瓶颈,但总体上比 Apriori 更高效。
3.5实际运用——网页点击行为分析
from mlxtend.frequent_patterns import fpgrowth, association_rules
import pandas as pd# 示例用户点击数据
transactions = [['首页', '产品页面A', '购物车'],['首页', '产品页面B', '购物车'],['产品页面A', '购物车'],['首页', '产品页面A', '产品页面B', '购物车'],
]# 转换为 DataFrame 格式
from mlxtend.preprocessing import TransactionEncoder
te = TransactionEncoder()
te_ary = te.fit(transactions).transform(transactions)
df = pd.DataFrame(te_ary, columns=te.columns_)# 使用 FP-Growth 算法挖掘频繁项集
frequent_itemsets = fpgrowth(df, min_support=0.6, use_colnames=True)# 生成关联规则
rules = association_rules(frequent_itemsets, metric="confidence", min_threshold=0.75)# 输出关联规则
print(rules)
4.Apriori 与 FP-Growth 的对比

5.具体项目——基于Apriori 算法的市场篮子分析
5.1项目目标
数据准备:从数据源(如HBase、HDFS等)读取用户的购买记录。
数据处理:清洗数据,进行合适的格式化。
Apriori算法实现:用于发现频繁项集,并生成关联规则。
结果存储:将关联规则存储到HBase或HDFS,并进行进一步分析。
性能优化:使用Spark进行分布式计算,以提高算法效率。
5.2项目目录结构
market-basket-analysis/
├── data/
│ └── transactions.csv # 输入的交易数据
├── src/
│ ├── main/
│ │ ├── scala/
│ │ │ ├── Apriori.scala # Apriori算法核心实现
│ │ │ ├── DataPreprocessor.scala # 数据清洗与预处理
│ │ │ ├── HBaseConnector.scala # HBase连接与数据存储
│ │ │ ├── SparkApriori.scala # 使用Spark并行化Apriori算法
│ │ │ └── ResultWriter.scala # 结果存储模块
│ ├── test/
│ │ └── AprioriTest.scala # 单元测试
├── pom.xml # Maven构建文件
└── README.md # 项目说明文档
5.3核心功能实现
1. 数据预处理(DataPreprocessor.scala)
首先,我们需要从存储系统(如HDFS、HBase)读取原始数据,进行清洗和格式化。
import org.apache.spark.sql.SparkSessionobject DataPreprocessor {def main(args: Array[String]): Unit = {val spark = SparkSession.builder.appName("Market Basket Analysis").getOrCreate()// 假设数据源是一个CSV文件,格式为: 用户ID, 商品IDval data = spark.read.option("header", "true").csv("data/transactions.csv")// 将交易数据格式化成购物篮的形式val transactions = data.groupBy("user_id").agg(collect_list("product_id").alias("basket"))transactions.show()// 你可以将数据保存到HDFS、HBase或者其他地方transactions.write.parquet("data/processed_transactions")spark.stop()}
}
2. Apriori算法实现(Apriori.scala)
Apriori.scala 实现了经典的 Apriori 算法,用于发现频繁项集和生成关联规则。为了简化,我们使用 RDD 操作,且算法会输出每一轮的候选项集。
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSessionobject Apriori {def generateFrequentItemsets(transactions: RDD[Set[String]], minSupport: Double): RDD[(Set[String], Int)] = {var k = 1var frequentItemsets: RDD[(Set[String], Int)] = transactions.flatMap(t => t.subsets(k)).map(itemset => (itemset, 1)).reduceByKey(_ + _).filter { case (_, count) => count >= minSupport * transactions.count() }// 生成k项集while (!frequentItemsets.isEmpty()) {k += 1val candidateItemsets = frequentItemsets.flatMap { case (itemset, _) =>itemset.subsets(k).toSeq}.map(itemset => (itemset, 1)).reduceByKey(_ + _).filter { case (_, count) => count >= minSupport * transactions.count() }frequentItemsets = candidateItemsets}frequentItemsets}def generateAssociationRules(frequentItemsets: RDD[(Set[String], Int)], minConfidence: Double): RDD[(Set[String], Set[String], Double)] = {frequentItemsets.flatMap { case (itemset, support) =>itemset.subsets(itemset.size - 1).map { antecedent =>val consequent = itemset -- antecedentval confidence = support.toDouble / frequentItemsets.lookup(antecedent).headif (confidence >= minConfidence) Some(antecedent, consequent, confidence)else None}.flatten}}def main(args: Array[String]): Unit = {val spark = SparkSession.builder.appName("Apriori Algorithm").getOrCreate()val sc = spark.sparkContext// 加载数据val transactions = sc.textFile("data/processed_transactions").map(line => line.split(",").toSet) // 数据转换为 Set 形式的交易数据val minSupport = 0.03val minConfidence = 0.6// 生成频繁项集val frequentItemsets = generateFrequentItemsets(transactions, minSupport)// 生成关联规则val associationRules = generateAssociationRules(frequentItemsets, minConfidence)// 输出结果associationRules.saveAsTextFile("data/association_rules")spark.stop()}
}
3. 分布式 Apriori 算法(SparkApriori.scala)
为了提高计算效率,可以使用 Spark 对 Apriori 算法进行并行化。以下代码对 Apriori 算法进行了 Spark 优化,支持大规模数据集的处理。
import org.apache.spark.sql.SparkSession
import org.apache.spark.rdd.RDDobject SparkApriori {def parallelGenerateFrequentItemsets(transactions: RDD[Set[String]], minSupport: Double): RDD[(Set[String], Int)] = {// 同前面简单Apriori算法,使用RDD进行并行化Apriori.generateFrequentItemsets(transactions, minSupport)}def parallelGenerateAssociationRules(frequentItemsets: RDD[(Set[String], Int)], minConfidence: Double): RDD[(Set[String], Set[String], Double)] = {// 同前面Apriori算法,生成关联规则Apriori.generateAssociationRules(frequentItemsets, minConfidence)}def main(args: Array[String]): Unit = {val spark = SparkSession.builder.appName("Distributed Apriori").getOrCreate()val sc = spark.sparkContextval transactions = sc.textFile("data/processed_transactions").map(line => line.split(",").toSet)val minSupport = 0.03val minConfidence = 0.6// 并行化生成频繁项集val frequentItemsets = parallelGenerateFrequentItemsets(transactions, minSupport)// 并行化生成关联规则val associationRules = parallelGenerateAssociationRules(frequentItemsets, minConfidence)// 输出结果associationRules.saveAsTextFile("data/association_rules_output")spark.stop()}
}
4. 结果存储模块(ResultWriter.scala)
结果存储部分使用 HBase 将生成的关联规则存储到表中,便于查询。
import org.apache.hadoop.hbase.client._
import org.apache.hadoop.hbase.util.Bytes
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.hadoop.hbase.TableName
import org.apache.hadoop.hbase.client.ConnectionFactory
import org.apache.hadoop.hbase.HTableDescriptor
import org.apache.hadoop.hbase.TableNotFoundExceptionobject ResultWriter {def saveToHBase(rules: RDD[(Set[String], Set[String], Double)]): Unit = {val conf = HBaseConfiguration.create()val connection = ConnectionFactory.createConnection(conf)try {val table = connection.getTable(TableName.valueOf("association_rules"))// 向 HBase 写入每条规则rules.foreach { case (antecedent, consequent, confidence) =>val rowKey = Bytes.toBytes(antecedent.mkString(",") + ":" + consequent.mkString(","))val put = new Put(rowKey)// 将前提和结论、置信度存储在对应的列族中put.addColumn(Bytes.toBytes("rule"), Bytes.toBytes("antecedent"), Bytes.toBytes(antecedent.mkString(",")))put.addColumn(Bytes.toBytes("rule"), Bytes.toBytes("consequent"), Bytes.toBytes(consequent.mkString(",")))put.addColumn(Bytes.toBytes("rule"), Bytes.toBytes("confidence"), Bytes.toBytes(confidence.toString))// 执行写操作table.put(put)}println("Successfully written association rules to HBase.")table.close()} catch {case e: TableNotFoundException =>println("HBase table 'association_rules' not found. Please ensure the table exists.")case e: Exception =>println(s"An error occurred while saving results to HBase: ${e.getMessage}")} finally {// 关闭连接connection.close()}}def main(args: Array[String]): Unit = {val spark = SparkSession.builder.appName("Result Writer").getOrCreate()// 假设之前我们已经生成了关联规则,存在文件中val rules = spark.sparkContext.textFile("data/association_rules_output").map { line =>val parts = line.split(",")val antecedent = parts(0).split(":").toSetval consequent = parts(1).split(":").toSetval confidence = parts(2).toDouble(antecedent, consequent, confidence)}// 将关联规则保存到 HBasesaveToHBase(rules)spark.stop()}
}
5. 测试模块(AprioriTest.scala)
为了确保代码的正确性,我们需要为 Apriori 算法编写一些单元测试。你可以使用 ScalaTest 或 JUnit 等框架进行测试。以下是使用 ScalaTest 编写的一个简单的测试示例
import org.scalatest._
import org.apache.spark.sql.SparkSession
import org.apache.spark.rdd.RDDclass AprioriTest extends FlatSpec with Matchers {"Apriori algorithm" should "generate correct frequent itemsets" in {val spark = SparkSession.builder.appName("AprioriTest").master("local").getOrCreate()val sc = spark.sparkContext// 示例交易数据val transactions = sc.parallelize(Seq(Set("apple", "banana", "cherry"),Set("banana", "cherry"),Set("apple", "banana"),Set("apple", "cherry")))// 生成频繁项集val frequentItemsets = Apriori.generateFrequentItemsets(transactions, minSupport = 0.5)// 检查频繁项集frequentItemsets.collect() should contain allOf((Set("apple"), 3),(Set("banana"), 3),(Set("cherry"), 3),(Set("apple", "banana"), 2),(Set("banana", "cherry"), 2))spark.stop()}it should "generate correct association rules" in {val spark = SparkSession.builder.appName("AprioriTest").master("local").getOrCreate()val sc = spark.sparkContext// 示例交易数据val transactions = sc.parallelize(Seq(Set("apple", "banana", "cherry"),Set("banana", "cherry"),Set("apple", "banana"),Set("apple", "cherry")))// 生成频繁项集val frequentItemsets = Apriori.generateFrequentItemsets(transactions, minSupport = 0.5)// 生成关联规则val associationRules = Apriori.generateAssociationRules(frequentItemsets, minConfidence = 0.5)// 检查生成的关联规则associationRules.collect() should contain allOf((Set("apple"), Set("banana"), 0.6666666666666666),(Set("banana"), Set("apple"), 0.6666666666666666))spark.stop()}
}
6. 项目构建与依赖(pom.xml)
为了方便项目的构建和依赖管理,我们使用 Maven。以下是 pom.xml 文件的基础配置。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.example</groupId><artifactId>market-basket-analysis</artifactId><version>1.0-SNAPSHOT</version><packaging>jar</packaging><dependencies><!-- Spark Core --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>3.3.0</version></dependency><!-- Spark SQL (for SparkSession) --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.12</artifactId><version>3.3.0</version></dependency><!-- HBase client --><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-client</artifactId><version>2.4.8</version></dependency><!-- ScalaTest for unit testing --><dependency><groupId>org.scalatest</groupId><artifactId>scalatest_2.12</artifactId><version>3.2.9</version><scope>test</scope></dependency><!-- Hadoop Common (required for HBase and Spark) --><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>3.3.0</version></dependency></dependencies><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.8.1</version><configuration><source>1.8</source><target>1.8</target></configuration></plugin></plugins></build>
</project>
相关文章:
机器学习系列----关联分析
目录 1. 关联分析的基本概念 1.1定义 1.2常用算法 2.Apriori 算法的实现 2.1 工作原理 2.2 算法步骤 2.3 优缺点 2.4 时间复杂度 2.5实际运用----市场购物篮分析 3. FP-Growth 算法 3.1 工作原理 3.2 算法步骤 3.3 优缺点 3.4 时间复杂度 3.5实际运用——网页点…...

json数据四大加载方式
效果: 一、使用 import 静态加载 JSON 原理 使用 ES 模块的 import 语法直接引入 JSON 文件。Webpack/Vite 等构建工具会将 JSON 文件解析成 JavaScript 对象。 优点 简单直接,适合静态数据。不需要额外的网络请求。数据会随着打包文件一起部署。 缺点 J…...
对象的内置方法)
JavaScript 中的数组(Array)对象的内置方法
JavaScript 中的数组(Array)对象提供了许多内置方法,用于对数组进行创建、操作、遍历和搜索等操作。以下是一些常用的数组方法及其简要说明: 创建和初始化数组 Array(): 创建一个新的空数组,或者根据提供的参数创建一…...

网络安全之国际主流网络安全架构模型
目前,国际主流的网络安全架构模型主要有: ● 信息技术咨询公司Gartner的ASA(Adaptive Security Architecture自适应安全架构) ● 美国政府资助的非营利研究机构MITRE的ATT&CK(Adversarial Tactics Techniques &…...

电子应用设计方案-16:智能闹钟系统方案设计
智能闹钟系统方案设计 一、系统概述 本智能闹钟系统旨在为用户提供更加个性化、智能化和便捷的闹钟服务,帮助用户更有效地管理时间和起床。 二、系统组成 1. 微控制器 - 选用低功耗、高性能的微控制器,如 STM32 系列,负责整个系统的控制和数据…...

【FRP 内网穿透 从0到1 那些注意事项】
【摘要】 最近跟第三方团队调试问题,遇到一个比较烦的操作。就是,你必须要发个版到公网环境,他们才能链接到你的接口地址,才能进行调试。按理说,也没啥,就是费点时间。但是,在调试的时候&#…...

力扣 LRU缓存-146
LRU缓存-146 /* 定义双向链表节点,用于存储缓存中的每个键值对。 成员变量:key和value存储键值对。preb和next指向前一个和后一个节点,形成双向链表。 构造函数:默认构造函数:初始化空节点。参数化构造函数࿱…...

Elasticsearch简介与实操
Elasticsearch是一个分布式、高扩展、高实时的搜索与数据分析引擎。以下是对Elasticsearch的详细介绍: 一、基本概述 Elasticsearch是Elastic Stack(以前称为ELK Stack)的核心组件,Logstash和Beats有助于收集、聚合和丰富数据并将…...

用python将一个扫描pdf文件改成二值图片组成的pdf文件
使用墨水屏读书现在似乎越来越流行,这确实有一定的好处,例如基本不发热,电池续航时间超长,基本不能游戏所以有利于沉浸式阅读,还有不知道是不是真的有用的所谓防蓝光伤害。但是,如果阅读的书籍是扫描图片组…...

Failed to start Docker Application Container Engine
说明: 1)访问应用业务,读取不到数据,show databases;查看数据库报错 2)重启docker服务,服务启动失败,查看日志报错如下图所示 3)报错信息:chmod /data/docker: read-only…...

ESLint的简单使用(js,ts,vue)
一、ESLint介绍 1.为什么要用ESLint 统一团队编码规范(命名,格式等) 统一语法 减少git不必要的提交 减少低级错误 在编译时检查语法,而不是等js引擎运行时才检查 2.eslint用法 可以手动下载配置 可以通过vue脚手架创建项…...
实景三维赋能国土空间智慧治理
随着城市化进程的不断推进,国土空间的合理规划与高效管理成为政府面临的一项重大挑战。在这个过程中,实景三维技术作为一种新兴的信息技术手段,正在逐渐改变传统国土空间治理的方式,为智慧城市的建设提供了新的可能。本文旨在探讨…...

树链剖分(重链剖分)
树链剖分的核心思想就是将一棵树剖分成一条一条的链 因为树不好处理 但链比较好处理 为了学会它 我们先要学会树上dfs(深度优先搜索) 然后就没了(雾) Because 树链剖分需要用到两个dfs 哦对了 我们还要了解以下的知识点 1.子…...

幻读是什么?用什么隔离级别可以防止幻读?
幻读是什么? 幻读(Phantom Read) 是数据库事务中的一种现象,指的是在一个事务中,当执行两次相同的查询时,第二次查询返回的结果集包含了第一次查询中不存在的行,或者第一次查询中存在的行在第二…...

[Unity Demo]从零开始制作空洞骑士Hollow Knight第二十集:制作专门渲染HUD的相机HUD Camera和画布HUD Canvas
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、制作HUD Camera以及让两个相机同时渲染屏幕二、制作HUD Canvas 1.制作法力条Soul Orb引入库2.制作生命条Health读入数据3.制作吉欧统计数Geo Counter4.制作…...
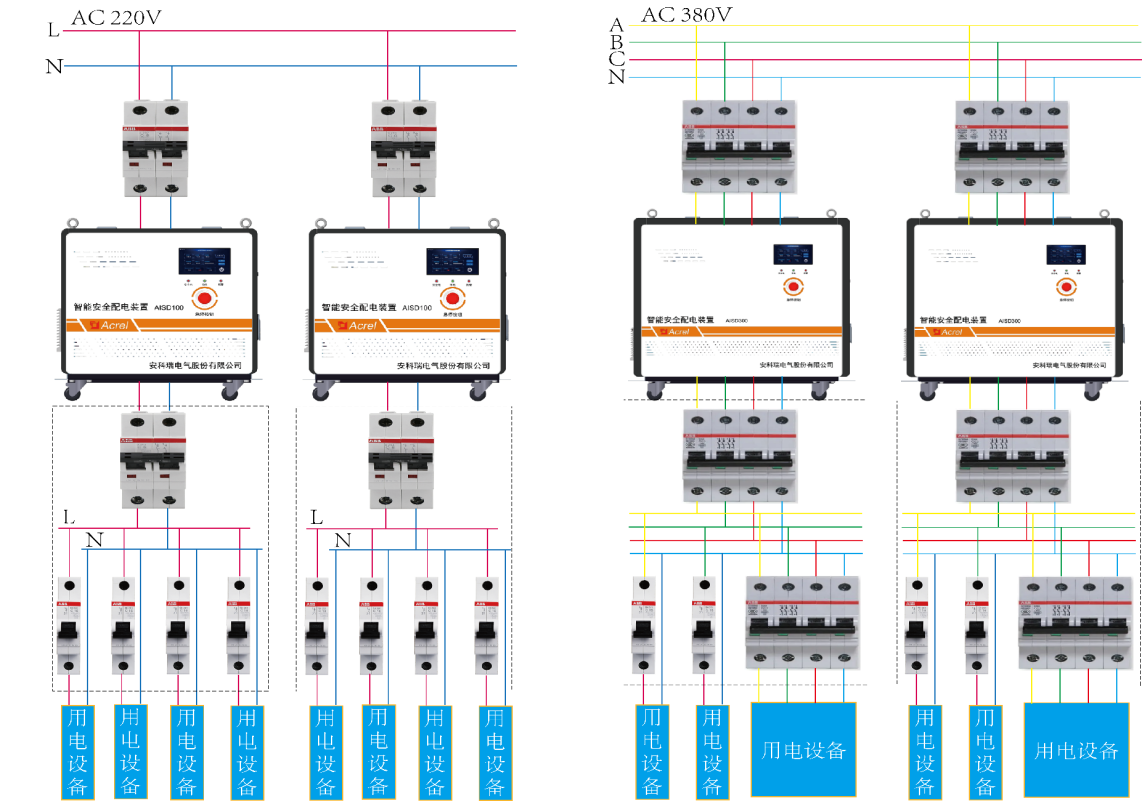
智能安全配电装置在高校实验室中的应用
摘要:高校实验室是科研人员进行科学研究和实验的场所,通常会涉及到大量的仪器设备和电气设备。电气设备的使用不当或者维护不周可能会引发火灾事故。本文将以一起实验室电气火灾事故为例,对事故原因、危害程度以及防范措施进行分析和总结…...
)
网络安全等级保护测评机构管理办法(全文)
网络安全等级保护测评机构管理办法(公信安〔2018〕765号) 第一章 总则 第一条 为加强网络安全等级保护测评机构(以下简称“测评机构”)管理,规范测评行为,提高等级测评能力和服务水平,根据《中华人民共和国网络安全法…...

Flutter:shared_preferences数据存储,数据持久化,token等信息存储
官方示例:简单调用 // 初始化示例 final SharedPreferences prefs await SharedPreferences.getInstance(); // 存int await prefs.setInt(counter, 10); // 存bool await prefs.setBool(repeat, true); // 存double await prefs.setDouble(decimal, 1.5); // 存st…...

FileProvider高版本使用,跨进程传输文件
高版本的android对文件权限的管控抓的很严格,理论上两个应用之间的文件传递现在都应该是用FileProvider去实现,这篇博客来一起了解下它的实现原理。 首先我们要明确一点,FileProvider就是一个ContentProvider,所以需要在AndroidManifest.xml里面对它进行声明: <provideran…...

python学习记录18
1 函数的定义 python中的函数指使用某个定义好的名字指代一段完整的代码,在使用名字时可以直接调用整个代码,这个名字叫做函数名。利用函数可以达到编写一次即可多次调用的操作,从而减少代码量。 函数分为内置函数与自定义函数。内置函数例…...

YOLOv11公共场所人群年龄目标检测数据集-280张-pedestrian-1_5
YOLOv11公共场所人群年龄目标检测数据集 📊 数据集基本信息 目标类别: [‘adult’, ‘child’, ‘elder’]中文类别:[‘成人’, ‘儿童’, ‘老人’]训练集:196 张验证集:56 张测试集:28 张总计:…...

从用户一句话到任务完成:Hermes Agent 一次请求完整链路详解
一、先说结论:Hermes 不是“问一句答一句”的普通聊天框很多人理解 AI 应用时,会把它想成一个 Chatbot:用户发一句话,模型回一句话。但 Hermes Agent 的请求链路更像一个“任务操作系统”。用户的一句话进入系统后,Her…...

Unity中DragonBones多动画性能优化:图集复用与骨骼模板化
1. 为什么DragonBones动画在Unity里总“卡得莫名其妙”?我第一次在Unity项目里接入DragonBones时,美术给的是一套角色的12个独立动画:idle、walk、run、jump、attack1、attack2、hurt、die、victory、taunt、cast、reload——每个都带完整骨骼…...

Unity哥特UI资源包:SDF字体与Shader Graph工程化实践
1. 为什么哥特UI在游戏开发中长期被低估,又为何现在必须认真对待“哥特UI”这个词,很多Unity开发者第一反应是:不就是黑底、尖角、浮雕字、带玫瑰纹样的按钮吗?配个暗红渐变完事。我2019年接手一个中世纪黑暗奇幻RPG时也这么想——…...

网页端嵌入 Agent 对接前端方案
本文将深入探讨「网页端嵌入AI」的核心概念与实战技巧,帮助你快速掌握关键要点。让我们开始吧! 网页端嵌入 Agent 对接前端方案 1. 引言 当前前端项目正从被动展示走向主动交互,AI Agent 嵌入网页端可自动化 UI 操作、优化布局并辅助编码。…...

免费在线去水印软件怎样选择?2026 优缺点对比及推荐指南
随着内容创作和素材收集的日常化,去水印的需求越来越普遍。一张素材上的水印、一段视频中的平台标志,都可能影响二次创作或个人使用的体验。市面上的去水印方案从专业软件到在线工具五花八门,选择合适的工具需要了解各自的特点和适用场景。本…...

受够了网盘限速?2026年更顺手的不限速同步盘选择
受够了网盘限速、下载慢、传大文件卡顿?如果你的核心诉求是“上传下载不被限速、同步稳定、多人协作更省心”,下面这4款网盘可以作为备选参考。本文以“传输体验 同步效率 安全合规 协作能力”做客观对比,方便你按需选择。 先看对比表&am…...

使用电脑快速测试 PROFINET 设备通讯
Anybus PROFINET主站仿真工具介绍日常对客户进行技术支持的时候,我们发现工厂自动化领域的不同部门不同职能的人员对于工业通讯设备都面临着一些使用的困难,例如设备研发人员,尤其是嵌入式研发部门,对于工厂自动化使用的工业通讯协…...

0 基础跨行斩获月薪 10k 实力远不及破局魄力
人生如同奔涌的比特流,暗礁与漩涡总在不经意间出现。 当挑战如恶意攻击般袭来,切莫因一时受阻而缴械投降。 那些在代码与协议中鏖战的日夜终将铸就铠甲,正如防火墙抵御入侵守护核心,只要目标坚定持续精进,终将在攻防…...
第3小节:超高纯氟化钙材料难点)
0603光刻机 第六篇:EUV超精密光学系统(S级 长期死磕突破)第3小节:超高纯氟化钙材料难点
第六篇:EUV超精密光学系统(S级 长期死磕突破) 第3小节:超高纯氟化钙材料难点(深紫外配套核心,全维度死磕解析) 前置硬核声明 氟化钙单晶(CaF₂)是DUV深紫外光刻核心光学基…...