一文详解kafka知识点
目录
1、kafka定义
2、消息队列
2.1、产品选择
2.2、应用场景
2.3、消息队列的两种模式
3、kafka架构
4、kafka生产者
4.1、kafka生产者原理
4.2、kafka生产者异步发送
4.3、同步发送
4.4、分区
4.4.1、kafka分区好处
4.4.2、分区策略
4.4.3、自定义分区
4.5、生成吞吐量
4.6、数据可靠性
4.7、数据重复分析
4.7.1、幂等性
4.7.2、事务原理
4.8、数据有序
4.9、数据乱序
5、kafka-broker
5.1、zk存储
5.2、broker-工作原理
5.3、节点服役和退役
5.4、kafka-副本
5.5、Leader选举
5.6、Follower故障
5.7、Leader故障
5.8、分区副本分配
5.9、Leader Partition自动平衡
5.10、文件存储机制
5.10.1、Log文件和Index文件详解
5.11、文件清除策略
5.12、高效读写数据
6、kafka消费者
6.1、kafka消费方式
6.2、kafka消费者总体工作流程
6.3、消费者组
6.3.1、消费者组初始化流程
6.3.2、消费者组详细消费流程
6.4、kafka分区分配策略
6.4.1、Range
6.4.2、RoundRobin
6.4.3、Sticky
6.5、offset
6.5.1、自动提交offset
6.5.2、手动提交offset
6.5.3、指定offset消费
6.6、指定时间消费
6.7、漏消费与重复消费
6.8、消费者事务
6.9、数据积压
1、kafka定义
传统定义:kafka是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用于大数据实时处理领域。
发布/订阅:消息的发布者不会将消息直接发生给特定的订阅者。而是将发布的消息分为不同的类别,订阅者只接收感兴趣的消息。
新定义:kafka是一个开源的分布式事件流平台(Event Streaming Platform),被数千家公司用于高性能数据管道、流分析、数据集成和关键任务。

2、消息队列
2.1、产品选择
目前企业中比较常见的消息队列产品主要有kafka、ActiveMQ、RabbitMQ、RoketMQ等
| ActiveMQ | RabbitMQ | RocketMQ | kafka | Pulsar | |
| 单机吞吐量 | 较低(万级) | 一般(万级) | 高(十万级) | 高(十万级) | 高(十万级) |
| 开发语言 | Java | Erlang | Java | Java/Scala | Java |
| 维护者 | Apache | Spring | Apache(Alibaba) | Apache(Confluent) | Apache(StreamNative) |
| Star数量 | 2.1K | 10.4K | 18.8K | 24.3K | 12.4K |
| Contributor | 126 | 246 | 438 | 991 | 600 |
| 社区活跃度 | 低 | 高 | 较高 | 高 | 高 |
| 消费模式 | P2P、Pub-Sub | direct、topic、Headers、fanout | 基于Topic和MessageTag的的Pub-Sub | 基于Topic的Pub-Sub | 基于Topic的Pub-Sub,支持独占(exclusive)、共享(shared)、灾备(failover)、key共享(key_shared)4种模式 |
| 持久化 | 支持(小) | 支持(小) | 支持(大) | 支持(大) | 支持(大) |
| 顺序消息 | 不支持 | 不支持 | 支持 | 支持 | 支持 |
| 性能稳定性 | 好 | 好 | 一般 | 较差 | 一般 |
| 集群支持 | 主备模式 | 复制模式 | 主备模式 | Leader-Slave每台既是master也是slave,集群可扩展性强 | 集群模式,broker无状态,易迁移,支持跨数据中心 |
| 管理界面 | 一般 | 较好 | 一般 | 无 | 无 |
| 计算和存储分离 | 不支持 | 不支持 | 不支持 | 不支持 | 支持 |
| AMQP支持 | 支持 | 支持 | 支持 | 不完全支持 | 不完全支持 |
2.2、应用场景
传统的消息队列的主要应用场景包括:缓存/消峰、解耦和异步通信。
(1)缓存/消峰:有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。

(2)解耦:允许你独立的扩展或修改两边的处理过程,只确保他们遵循同样的接口约束

(3) 异步通信:允许用户把一个消息放入队列,但并不立即处理它,然后在需要的时候再去处理它们。

2.3、消息队列的两种模式
(1)点对点
- 消费者主动拉取数据,消息收到后清除消息

(2)发布/订阅模式
- 可以有多个topic主题(浏览、点赞、收藏、评论等)
- 消费者消费数据之后,不删除数据
- 每个消费者相互独立、都可以消费到数据

思考:那么什么时候删呢?
3、kafka架构
1、为方便扩展,并提高吞吐量,一个topic分为多个partition
2、配合分区的设计,提出消费者组的概念,组内每个消费者并行消费,一个分区partition只能由一个消费者来消费。
3、为了提高可用性,为每个partition增加若干副本,类型NameNode HA。分区挂掉之后follow可以成为leader。
4、ZK中记录谁是leader,kafka2.8以后也可以不配置不采用ZK。


4、kafka生产者
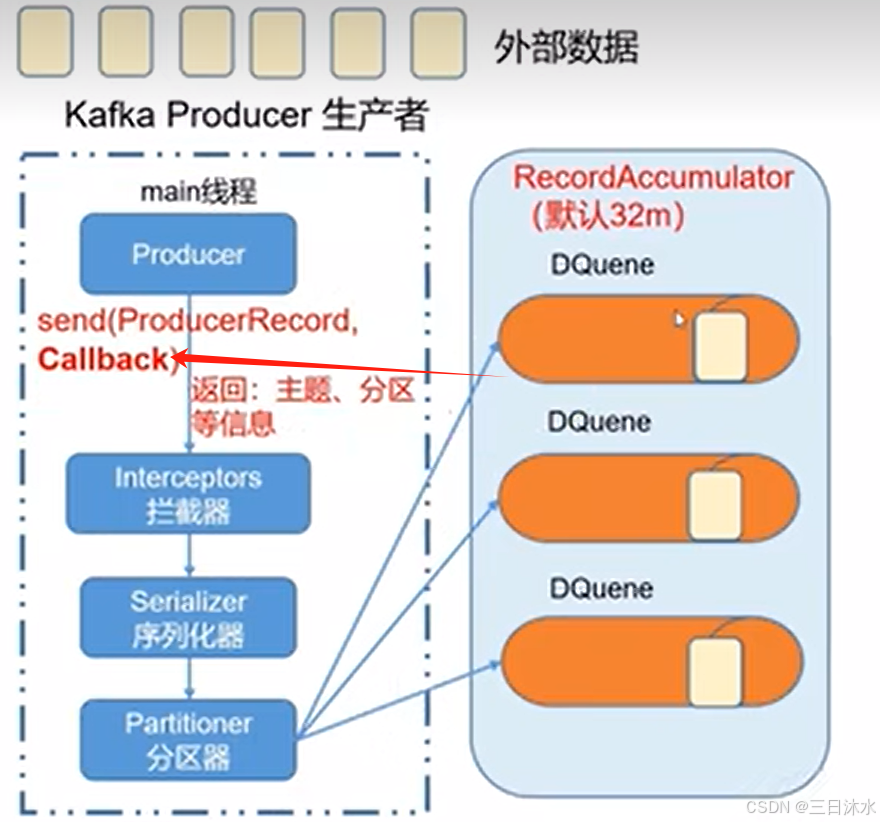
4.1、kafka生产者原理
(1)主线程:kafka producer生产者send(ProduceRecord)、可选的拦截器Interceptor、序列化器、分区器。
创建多个分配,都是在内存里面完成的,(RecordAccumulator)总大小默认32M,(ProducerBatch)一批次16k。
(2)sender线程:NetWorkClient 汽车、各个请求。以每个broker为key,把数据放到一个队列里面,发送给broker应答,每个队列最多缓存5个请求。selector:高速公路,链路。
什么时候拉数据发生?
- batch.size:只有数据积累到batch.size之后,sender才会发生数据。默认16k
- linger.ms:如果数据迟迟未达到batch.size,sender等待linger.ms设置的时间到了之后就会发送数据。单位ms,默认值是0ms,表示没有延迟。
(3)kafka集群:分为多个broker、拥有备份的能力,收到数据之后,发送acks应答。
- 0:生产者发送过来的数据,不需要等待数据落盘应答;
- 1:生产者发送过来的数据,Leader收到数据后应答;
- -1(all):生产者发送过来的数据,Leader和ISR队列里面的所有节点收齐数据后应答。-1和all等价。
什么是ISR?
- AR(Assigned Repllicas):一个partition的所有副本(就是replica,不区分leader或follower)
- ISR(In-Sync Replicas)能够和 leader 保持同步的 follower + leader本身 组成的集合。
- OSR(Out-Sync Relipcas)不能和 leader 保持同步的 follower 集合
- 公式:AR = ISR + OSR

应答机制-成功:清理掉每个分区的数据。
应答机制-失败:默认是一直重试,可以修改retries重试次数。

4.2、kafka生产者异步发送
异步发送:外部的数据发送到队列里面的,kafka回调异步发送。

相关文章:
一文详解kafka知识点
目录 1、kafka定义 2、消息队列 2.1、产品选择 2.2、应用场景 2.3、消息队列的两种模式 3、kafka架构 4、kafka生产者 4.1、kafka生产者原理 4.2、kafka生产者异步发送 4.3、同步发送 4.4、分区 4.4.1、kafka分区好处 4.4.2、分区策略 4.4.3、自定义分区 4.5、生成吞…...

C语言基础学习:抽象数据类型(ADT)
基础概念 抽象数据类型(ADT)是一种数据类型,它定义了一组数据以及可以在这组数据上执行的操作,但隐藏了数据的具体存储方式和实现细节。在C语言中,抽象数据类型(ADT)是一种非常重要的概念&…...

提升性能测试效率与准确性:深入解析JMeter中的各类定时器
在软件性能测试领域,Apache JMeter是一款广泛使用的开源工具,它允许开发者模拟大量用户对应用程序进行并发访问,从而评估系统的性能和稳定性。在进行性能测试时,合理地设置请求之间的延迟时间对于模拟真实用户行为、避免服务器过载…...

施密特正交化与单位化的情形
在考研数学的线性代数部分,施密特正交化和单位化是两种不同的处理向量的方法,它们在特定的情况下被使用。以下是详细说明: 施密特正交化的应用场景 施密特正交化(Gram-Schmidt Orthogonalization)是一种从线性无关向…...
ROS机器视觉入门:从基础到人脸识别与目标检测
前言 从本文开始,我们将开始学习ROS机器视觉处理,刚开始先学习一部分外围的知识,为后续的人脸识别、目标跟踪和YOLOV5目标检测做准备工作。我采用的笔记本是联想拯救者游戏本,系统采用Ubuntu20.04,ROS采用noetic。 颜…...

2024 APMCM亚太数学建模C题 - 宠物行业及相关产业的发展分析和策略(详细解题思路)
在当下, 日益发展的时代,宠物的数量应该均为稳步上升,在美国出现了下降的趋势, 中国 2019-2020 年也下降,这部分变化可能与疫情相关。需要对该部分进行必要的解释说明。 问题 1: 基于附件 1 中的数据及您的团队收集的…...

C#里怎么样访问文件时间
C#里怎么样访问文件时间 文件时间也是一个关键信息, 因为很多数据处理需要时间来判断数据的有效性,比如股票中的股价, 它是的权重,是随着时间递减的。 一般来说,超过5年以上的数据,都是可以删除掉了。 或者说超过三年的数据,就需要压缩保存了,这样可以省掉很多磁盘空…...

Cesium教程01_认识View
Cesium 地图视图组件 目录 一、引言二、功能说明三、代码实现 1. 模板结构2. 脚本逻辑3. 样式设计 四、总结 一、引言 在三维地球可视化中,Cesium 是一个强大的开源 JavaScript 库,它能够展示精美的地球和地图应用。本示例展示了如何使用 Vue 组件化…...

【SQL Server】华中农业大学空间数据库实验报告 实验八 存储过程
1.实验目的 通过实验课程与理论课的学习深入理解掌握的存储过程的原理、创建、修改、删除、基本的使用方法、主要用途,并且可以在练习的基础上,熟练使用存储过程来进行数据库的应用程序的设计;深入学习深刻理解与存储过程相关的T-SQL语句的编…...

ArcMap 处理栅格数据的分辨率功能操作
ArcMap 处理栅格数据的分辨率功能操作 一、统一多分辨率栅格数据 1、查看两个栅格数据的分辨率 1)raster1 点击属性 2) raster2 2、统一像元大小 1)点击环境 展示和填写 处理范围 栅格分析 点击确定 3、重采样 让raster1和..2保持一致,即…...
 ae事件处理器(一))
redis7.x源码分析:(4) ae事件处理器(一)
ae模块是redis实现的Reactor模型的封装。它的主要代码实现集中在 ae.c 中,另外还提供了平台相关的io多路复用的封装,它们都实现了一套相同的poll接口,就类似于C中提供了一个接口基类,由针对不同平台的派生类去实现。 // 创建平台…...

【React】React Router:深入理解前端路由的工作原理
🌈个人主页: 鑫宝Code 🔥热门专栏: 闲话杂谈| 炫酷HTML | JavaScript基础 💫个人格言: "如无必要,勿增实体" 文章目录 React Router:深入理解前端路由的工作原理路由的演进历程传统多页面…...

51单片机-独立按键与数码管联动
独立键盘和矩阵键盘检测原理及实现 键盘的分类:编码键盘和非编码键盘 键盘上闭合键的识别由专用的硬件编码器实现,并产生键编码号或键值的称为编码键盘,如:计算机键盘。靠软件编程识别的称为非编码键盘;在单片机组成…...

visual studio 2005的MFC各种线程函数之间的调用关系
在 Visual Studio 2005 的 MFC 程序中的函数和消息机制涉及线程间通信、消息处理以及与窗口消息的交互。接下来我将详细分析以下每个函数的作用、如何使用它们以及它们之间的调用关系。 1. PostThreadMessage(m_iThOpID, MSG_OP_OVER, 0, (LPARAM)iLparm); 函数用途࿱…...

网页中调用系统的EXE文件,如打开QQ
遇到一个实际的问题,需要在网页中打开本地的某个工业软件。 通过点击exe文件就可以调用到程序。 比如双击qq的exe就可以启动qq的程序。 那么问题就变成了如何加载exe程序呢? 可以通过Java的 Process process Runtime.getRuntime().exec(command);通过…...

【单点知识】基于PyTorch讲解自动编码器(Autoencoder)
文章目录 0. 前言1. 自动编码器的基本概念1.1 定义1.2 目标1.3 结构 2. PyTorch实现自动编码器2.1 导入必要的库2.2 定义自动编码器模型2.3 加载数据2.4 训练自动编码器 3. 自动编码器的意义4. 自动编码器的应用4.1 图像处理4.2自然语言处理:4.3推荐系统:…...
Halo 正式开源: 使用可穿戴设备进行开源健康追踪
在飞速发展的可穿戴技术领域,我们正处于一个十字路口——市场上充斥着各式时尚、功能丰富的设备,声称能够彻底改变我们对健康和健身的方式。 然而,在这些光鲜的外观和营销宣传背后,隐藏着一个令人担忧的现实:大多数这些…...

summernote富文本批量上传音频,视频等附件
普通项目,HTML的summernote富文本批量上传音频,视频等附件(其他附件同理) JS和CSS的引入 <head><th:block th:include"include :: summernote-css" /> </head> <body><th:block th:include"include :: summernote-js" /> …...
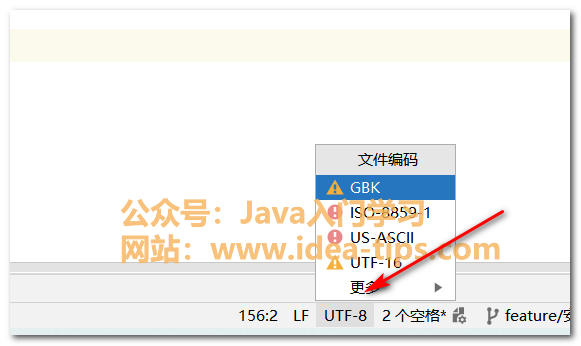
IDEA如何设置编码格式,字符编码,全局编码和项目编码格式
前言 大家好,我是小徐啊。我们在开发Java项目(Springboot)的时候,一般都是会设置好对应的编码格式的。如果设置的不恰当,容易造成乱码的问题,这是要避免的。今天,小徐就来介绍下我们如何在IDEA…...
【计算机网络实验】之静态路由配置
【计算机网络实验】之静态路由配置 实验题目实验目的实验任务实验设备实验环境实验步骤路由器配置设置静态路由测试路由器之间的连通性配置主机PC的IP测试 实验题目 静态路由协议的配置 实验目的 熟悉路由器工作原理和机制;巩固静态路由理论;设计简单…...

【深度解析】Gemini 3.5 Flash:面向 Agentic Workflow 的高速多模态大模型选型与实战
摘要 本文围绕 Gemini 3.5 Flash 的技术定位、Agentic Workflow、多模态能力、速度优势与模型选型策略展开分析,并给出可落地的 Python 调用示例,帮助开发者判断其在编码助手、智能体、多模态应用中的适用边界。背景介绍 近两年,大模型迭代速…...

【大模型12步学习路线 · 第12步 · ①原理篇】多模态 LLM + Multimodal RAG 全景:从 Qwen3-VL 到 ColPali / ColQwen2.5,让 LLM看懂Spec
【大模型12步学习路线 第12步 ①原理篇】多模态 LLM + Multimodal RAG 全景:从 Qwen3-VL 到 ColPali / ColQwen2.5,让 LLM"看懂"Spec 时序图 系列定位:「大模型正确学习顺序」12 步系列 第 12 步 多模态 的 ①原理篇 —— 最后一步,Veri-Copilot v1.0 大结局。 前…...

编程语言对比:从C到Python
好的,我将为你清晰介绍这几种编程语言的主要区别:1. C语言定位:面向过程的系统级编程语言。特点:接近硬件,可直接操作内存(如指针)。语法简洁,无面向对象特性。应用场景:…...

Taotoken API Key的权限管理与审计日志功能初探
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken API Key的权限管理与审计日志功能初探 对于将大模型能力集成到业务流程中的团队而言,API Key的安全管理与操作…...

从 AI 工具到音乐生态:可酷加速布局,构建数字音乐全新基础设施
当数字音乐行业从流量竞争迈入生态竞争的新阶段,单一产品的功能边界已难以支撑企业长期增长,完善的生态协同能力逐渐成为企业突围的核心竞争力,也成为定义行业未来格局的关键变量。在此背景下,可酷公司近日对外披露其全新发展战略…...

实测好用降AI工具盘点 2026高性价比首选
前言 刚完成毕业答辩的过来人真心建议,别再跟论文AI检测死磕了!我当初对着检测报告上飘红的高风险提示熬了好几个通宵,自己改了三版,导师扫了两眼就说“AI痕迹太重,回去重改”。那段时间我把市面上能找到的降AI工具试了…...

初创公司技术选型时为何将Taotoken作为大模型统一接入层
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创公司技术选型时为何将Taotoken作为大模型统一接入层 对于初创公司的技术负责人而言,在构建基于大模型的应用时&…...

内网终端安全管控:筑牢企业内部网络入侵防火墙
内网终端安全管控的核心目标内网终端安全管控旨在通过技术和管理手段,防止未经授权的访问、数据泄露及恶意攻击,确保企业内部网络资源的机密性、完整性和可用性。终端设备准入控制部署网络准入控制(NAC)系统,强制终端设…...

语音修复终极指南:如何用VoiceFixer在3分钟内拯救受损音频
语音修复终极指南:如何用VoiceFixer在3分钟内拯救受损音频 【免费下载链接】voicefixer General Speech Restoration 项目地址: https://gitcode.com/gh_mirrors/vo/voicefixer 在数字时代,音频质量问题困扰着无数内容创作者、历史档案工作者和普…...

如何在GTA5在线模式中保护自己?YimMenu安全增强菜单完整指南
如何在GTA5在线模式中保护自己?YimMenu安全增强菜单完整指南 【免费下载链接】YimMenu YimMenu, a GTA V menu protecting against a wide ranges of the public crashes and improving the overall experience. 项目地址: https://gitcode.com/GitHub_Trending/y…...