24/11/22 项目拆解 艺术风格转移
我们有时候想把两种艺术风格整合,创造更具艺术特色的艺术品,人很难办到,但是人工智能可以,比如下面将艺术画的风格转移到照片上。

我们先来初步了解一下实现上述功能的数学原理
所谓艺术风格,其实就是边缘,颜色,纹理等各种要素的组合,因此可以通过卷积网络对图片识别后,所得的结果就已经包含了图片的艺术风格,因此我们可以通过卷积网络将构成图片风格的各种要素抽取出来。
风格转移这一过程可以通过以下几个关键步骤实现:
-
内容和风格的表示:
- 内容表示:通常使用深度卷积神经网络(如VGG19)的中间层来提取图像的内容特征。网络的深层能够捕捉到图像的高级语义信息,即内容。
- 风格表示:风格则通过计算特征图的格拉姆矩阵(Gram matrix)来表示,它描述了特征图之间的相关性,即纹理和颜色分布等风格信息。
-
损失函数:
- 风格迁移的目标是最小化一个损失函数,该函数由两部分组成:风格损失和内容损失。
- 风格损失:计算生成图像与风格图像在每个层的特征图的格拉姆矩阵之间的差异。
- 内容损失:计算生成图像与内容图像在相应层的特征图之间的差异。
- 通过最小化这些损失,生成图像逐渐接近目标风格和内容。
-
优化过程:
- 从一个随机噪声图像或内容图像开始,使用梯度下降算法不断优化图像,以最小化损失函数。
- 通常使用L-BFGS算法或Adam优化器进行优化。
-
总变差损失(Total Variation Loss):
- 为了保持生成图像的平滑性,通常会添加一个总变差损失项,它惩罚图像中的高频信息,即图像中的噪声和细节
网络从输入图像中抠出一小片做卷积运算,之后得到一个向量。抠出的一小片是二维的,由于每一个像素点被计算成一个向量,因此卷积运算后得到一个三维的”一小块“。
我们假设抠出的这一小片映射到第 L 层后,对应的”小块“其宽度为 W ,高度为 H ,深度为NL,如果我们将它压扁,从三维降为二维,把它的一个面积为 W * H平面拉长成一条长度为 ML = W * H的一条线,于是一个三维向量就转化为二维向量,用数学表达式表示为:
同时我们用表示把深度为 i 的切片拉成一条直线后的第 j 个元素。通过前面讲述的卷积操作的内容就知道,
包含了输入图片的某些内容。如果反过来先想,给定了
后,我们如何还原它所蕴含的画面信息呢?
做法是拿一张白色图片,每个像素点的值都是255,让它经过卷积网络运算后,我们拿出同处于 l 层的结果,这个结果记为。接着调整白色图片像素点的值,使得
与
不断接近,当他们足够接近时,白色图片的像素点发生转变后,就呈现出与输入图片相似的图案。
我们用差值的平方和来表示”接近“:
(1)
当公式(1)的值越小时,白色图片转换出的画面内容与输入图片越相似。因此我们只要把白色图片中的像素点按照公式(1)的值越来越小的方向调整即可。
我们知道是白色图片中某个像素点x经过卷积运算后得到的结果,于是x与
之间存在函数关系
(x),当像素点x的值变动后,
也会跟着变动。因此要想调整x使得公式(1)最小,我们只要将公式(1)对x求偏导即可:
(2)
其中,可以i通过对VGG网络进行梯度下降法来获取。根据公式(2)我们就知道了如何调整每个像素点 x 的值,使得白色图片转变为与输入图片内容相同的画风。现在内容有了,风格如何实现呢?
我们把抽取风格的绘画图片输入VGG网络中,在卷积层中已经包含了“风格”信息。要想对所谓的风格进行量化,我们需要计算对应卷积层的格莱姆矩阵。我们用 表示第 l 层卷积层对应的格莱姆矩阵,那么有:
(3)
也就是说格莱姆矩阵第 i 行第 j 列个元素就是把卷积层对应的第 i 行和第 j 行做点乘后得到。公式(3)中对应的就是对输入图片“风格”的量化。与前面描述类似,我们要想把一张白色图片转换成给定图片风格相近的图片,就需要对下面的公式进行量化。
(4)
其中,是将白色图片输入到VGG网络后,将第L层卷积层转换后的格莱姆矩阵,我们选L个卷积层的格莱姆之和作为“风格”的量化:
(5)
于是要调整像素点的值使得公式(5)最小,其中对应每个卷积层权重,一般而言,权重会平均分配给每个卷积层。
对于像素点x,它的调整幅度为:
(6)
现在出现一个问题,对内容进行调整时,我们对像素点x进行更改;对风格进行调整时,我们又会对像素点进行更改,如何将两种更改统一起来呢?我们对两种更改赋予不同的权重:
(7)
如果 系数比较大,那么我们就使白色图片的改变偏向于内容;如果系数
比较大,那么我们就让图片的调整偏向于风格。于是像素点的调整只要把像素点x的值减去
即可,其中
是调整率,它跟我们前面提到过的学习率是一致的
接下来我们1启动代码加以理解。
代码理解
1.导入函数库
import tensorflow as tf
#import tensorflow.contrib.eager as tfe
#from tensorflow.python.keras.preprocessing import image as kp_image
from tensorflow.python.keras import models
from tensorflow.python.keras import losses
from tensorflow.python.keras import layers
from tensorflow.python.keras import backend as K
import IPython.display
#启动eager
#tf.enable_eager_execution()
#print("Enger execution:{}".format(tf.executing_eagerly()))2.加载内容图片和风格图片
from PIL import Image
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['figure.figsize'] = (10,10)
mpl.rcParams['axes.grid'] = False
import numpy as np
import time
import functoolscontent_path = "C:\\Users\\91144\\Pictures\\Screenshots\\屏幕截图 2024-09-23 214511.png"
style_path = "C:\\Users\\91144\\Pictures\\Screenshots\\屏幕截图 2024-09-26 184416.png"# 加载显示图片
def load_img(path):max_dim = 512 #设置图像的最大尺寸为512像素img = Image.open(path) #打开图片long = max(img.size) #计算图像最长边scale = max_dim / long #计算缩放比例if scale < 1: # 使用 Image.Resampling.LANCZOSimg = img.resize((int(img.size[0] * scale), int(img.size[1] * scale)), Image.Resampling.LANCZOS) #使用LANCZOS算法缩放图像img = np.array(img) #转为numpy数组img = np.expand_dims(img, axis=0)#增加一个维度,使其符合深度学习模型输入的要求return img def show_img(img, title=None): #定义显示图像的函数out = np.squeeze(img, axis=0)#从图像数组中移除批次维度out = out.astype('uint8') #将图像数组的数据类型转为无符号整型,这是图像显示的标准格式plt.imshow(out) if title is not None: plt.title(title)plt.figure(figsize=(10,10)) #加载图像内容
content = load_img(content_path)
style = load_img(style_path)
plt.subplot(1, 2, 1)
show_img(content, 'Content Image')
plt.subplot(1, 2, 2)
show_img(style, 'Style Image')
plt.show()
TIPs:
上面有一个LANCZOS算法,它主要用于求解稀疏矩阵的特征值问题,我们这里用它缩放图像。
LANCZOS算法的原理
Lanczos 插值使用 Lanczos 核函数来计算插值后的像素值。Lanczos 核函数是一种低通滤波器,可以消除缩放过程中产生的混叠现象。
Lanczos 核函数定义如下:

其中,sinc(x) = sin(πx) / (πx),a 是核函数的宽度。
Lanczos 插值的过程如下:
- 确定插值点的位置。
- 以插值点为中心,在原图像中取一个窗口。
- 对窗口中的每个像素,使用 Lanczos 核函数计算其权重。
- 将窗口中所有像素的权重和插值值相乘,得到插值点的最终值。
Lanczos 插值公式:

Lanczos 插值的优点
- 与其他插值方法相比,Lanczos 插值可以产生更清晰、更平滑的图像。
- Lanczos 插值可以有效地抑制混叠现象,尤其是在图像缩小的情况下。
Lanczos 插值的缺点
- 与其他的插值方法相比,Lanczos 插值的计算量更大。
- Lanczos 插值可能会产生轻微的振铃效应,尤其是在图像放大边缘处
3.用vgg卷积网络抽取特征
import tensorflow as tf
from tensorflow.keras.applications import vgg19
from tensorflow.keras.preprocessing import image as kp_image
from tensorflow.keras.models import Modeldef load_and_process_img(path):# 加载图片img = kp_image.load_img(path, target_size=(224, 224)) # 确保图片大小与 VGG19 输入一致# 将图片转换为数组img = kp_image.img_to_array(img)# 扩展维度,因为 VGG19 需要批次维度img = np.expand_dims(img, axis=0)# 预处理图片img = vgg19.preprocess_input(img)return img# 定义用于内容调整的卷积层
content_layers = ['block5_conv2'] # 使用存在的层名称
# 定义用于风格计算的卷积层
style_layers = ['block1_conv1','block2_conv1','block3_conv1','block4_conv1','block5_conv1']
num_content_layers = len(content_layers)
num_style_layers = len(style_layers)# 加载 VGG19 网络,让它识别内容
def get_model():# 我们不需要最后的全连接层vgg = vgg19.VGG19(include_top=False, weights='imagenet')# 获取用于计算风格的卷积层style_outputs = [vgg.get_layer(name).output for name in style_layers]# 获取用于计算内容的卷积层content_outputs = [vgg.get_layer(name).output for name in content_layers]model_outputs = style_outputs + content_outputsreturn Model(vgg.input, model_outputs)# 获取模型
model = get_model()TIPs:
我们来解释一下里面的VGG卷积网络和block5_conv2,block1_conv2这些网络层的含义

在VGG网络层中,每个卷积块包含若干卷积层,后面跟着一个最大池化层,这些卷积块被编号为
block1、block2、block3、block4 和 block5。
block5_conv2:这是VGG网络中第五个卷积块的第二个卷积层,在VGG-19中,block5包含三个卷积层(conv5_1、conv5_2、conv5_3),其中conv5_2对应于block5_conv2。
这些层的名称通常用于风格迁移任务中,用于提取图像的内容特征和风格特征,block5_conv2 由于其在网络的较深位置,能够捕捉到图像的高级语义信息,适合作为内容特征层。而block1_conv1等较浅层的卷积层则能捕捉到图像的纹理和颜色信息,适合作为风格特征层。
4.计算内容对应卷积层的差值,以便后面调整图片的像素点
def get_content_loss(base_content,target):return tf.reduce_mean(tf.square(base_content - target))5.计算风格差异
#计算风格差异
def gram_matrix(input_tensor): #格拉姆矩阵channels = int(input_tensor.shape[-1])'''这里的-1相当于把卷积层对应的平面拉成一条直线'''a = tf.reshape(input_tensor,[-1,channels])n = tf.shape(a)[0]gram = tf.matmul(a,a,transpose_a = True) #将第一个张量a进行转置,然后与第二个张量a进行矩阵乘法return gram/tf.cast(n,tf.float32)#计算风格差异
def get_style_loss(base_style,gram_target):gram_style = gram_matrix(base_style)return tf.reduce_mean(tf.square(gram_style - gram_target))TIPs:
这里有一个格拉姆矩阵,图像处理和风格迁移的上下文中,格拉姆矩阵用于捕捉和表示图像的风格特征,特别是纹理和颜色分布。
定义
对于一个给定的矩阵 A,其格拉姆矩阵 G 定义为 A 与其自身的内积。如果 A 是一个 m×n 的矩阵,那么格拉姆矩阵 G 是一个 n×n 的矩阵,计算方式如下:

其中 A^T 是 A 的转置。
图像风格迁移中的应用
在图像风格迁移中,格拉姆矩阵用于表示风格图像的特征图(feature maps)。特征图是深度卷积神经网络(如VGG)中某一层的输出,它捕捉了图像的局部特征。格拉姆矩阵则将这些局部特征转换为全局风格特征,因为它包含了特征图之间的相关性信息。
计算步骤
-
提取特征图:
- 从风格图像中提取特征图。这通常是通过将风格图像输入到预训练的深度学习模型(如VGG)中,并选择特定层的输出来完成的。
-
计算格拉姆矩阵:
- 对于每个特征图,计算其格拉姆矩阵。如果特征图的形状是 [1,h,w,c][1,h,w,c](其中 hh 是高度,ww 是宽度,cc 是通道数),那么格拉姆矩阵的形状将是 [c,c][c,c]。
-
风格损失:
- 在风格迁移的损失函数中,格拉姆矩阵用于计算生成图像的风格特征与目标风格图像之间的差异。这种差异通常通过格拉姆矩阵的元素之间的差异来衡量。
-
计算差异:
1.使用均方误差衡量两矩阵的差异:
均方误差是衡量两个矩阵之间差异的一种简单方法,定义为两个矩阵元素差的平方的平均值:

2.交叉相关:在风格迁移中,我们通常使用一种特殊的交叉相关来衡量风格差异,这实际上是格拉姆矩阵的差异。如果 GAGA 和 GBGB 分别是两个特征图 AA 和 BB 的格拉姆矩阵,那么它们的差异可以表示为:

其中 NN 是特征图的通道数,MM 是格拉姆矩阵的维度(通常是特征图通道数)。
6.把内容图片和风格图片输入到VGG19卷积网络,获得相应卷积层的输出结果
def get_feature_representations(model,content_path,style_path):#把图片内容和风格图片输入到vgg网络,然后获取相应的卷积计算结果content_img = load_and_process_img(content_path)style_img = load_and_process_img(style_path)style_outputs = model(style_img)content_outputs = model(content_img) #抽取风格图片对应的卷积层输出style_features = [style_layer[0] for style_layer in style_outputs[:num_style_layers]]content_features = [content_layer[0] for content_layer in content_outputs[num_style_layers:]]return style_features,content_features7.计算公式(2),和公式(6),最后根据公式(7)来调整白色图片的像素点
def computer_loss(model, loss_weights, init_image, gram_style_features, content_features):style_weight, content_weight = loss_weights# 计算白色图片对应卷积层的输出model_outputs = model(init_image)# 获得白色图片对应风格卷积层的计算结果style_output_features = model_outputs[:num_style_layers]content_output_features = model_outputs[num_style_layers:]style_score = 0content_score = 0# 计算风格对应卷积层权重weight_per_style_layer = 1.0 / float(num_style_layers)for target_style, comb_style in zip(gram_style_features, style_output_features):style_score += weight_per_style_layer * get_style_loss(comb_style[0], target_style)# 计算内容差值weight_per_content_layer = 1.0 / float(num_content_layers)
#将两个列表组合在一起,使得每次迭代都能同时访问目标内容特征(target_content)和生成图像的内容特征(comb_content)for target_content, comb_content in zip(content_features, content_output_features):content_score += weight_per_content_layer * get_content_loss(comb_content[0], target_content)# 根据公式7计算像素点的调节style_score *= style_weight #调整风格得分content_score *= content_weight #调整内容得分loss = style_score + content_score #计算总损失return loss, style_score, content_score8.根据公式(2)和公式(6)我们还得计算像素点相对于卷积层输出结果的偏导,把差值和偏导结合在一起才得到像素点的调整幅度
#把差值和偏导结合在一起才得到像素点的调整幅度
def compute_grads(cfg):with tf.GradientTape() as tape:all_loss = computer_loss(**cfg)total_loss = all_loss[0]#根据差值反向对像素点求偏导gradient = tape.gradient(total_loss,cfg['init_image'])#计算梯度return gradient,all_loss9.最后我们把所有计算流程连接起来,不断调整白色图片像素点的值,让它慢慢变成具体有相应内容和风格的新的图片
import numpy as np
import tensorflow as tf
from tensorflow import keras
from PIL import Image
import IPython
import time#用于将处理过的图像(经过 VGG 网络预处理的图像)转换回可显示的图像格式。
def deprocess_img(processed_img):x = processed_img.copy()if len(x.shape) == 4:x = np.squeeze(x, 0) #去掉批次维度assert len(x.shape) == 3x[:, :, 0] += 103.939 #将vgg网络均值加回到每个颜色通道上,以撤销预处理步骤x[:, :, 1] += 116.779x[:, :, 2] += 123.68x = x[:, :, ::-1] #将通道顺序从RBGR转换到RGBx = np.clip(x, 0, 255).astype('uint8')#将像素点限制在0-255,并转化为无符号整型,这是图像显示的标准格式return x#实现风格迁移的主要逻辑。
def run_style_transfer(content_path, style_path,num_iterations=1000,content_weight=1e3,style_weight=1e-2):model = get_model() # 假设这个函数返回一个预训练的VGG模型for layer in model.layers:layer.trainable = Falsestyle_features, content_features = get_feature_representations(model, content_path, style_path)gram_style_features = [gram_matrix(style_feature) for style_feature in style_features]init_image = load_and_process_img(content_path)init_image = tf.Variable(init_image, dtype=tf.float32)opt = tf.keras.optimizers.Adam(learning_rate=5, beta_1=0.99, epsilon=1e-1)#优化器iter_count = 1best_loss, best_img = float('inf'), Noneloss_weights = (style_weight, content_weight)#配置字典cfg = {'model': model,'loss_weights': loss_weights,'init_image': init_image,'gram_style_features': gram_style_features,'content_features': content_features}num_rows = 2num_cols = 5display_interval = num_iterations / (num_rows * num_cols)start_time = time.time()global_start = time.time()norm_means = np.array([103.939, 116.779, 123.68])min_vals = -norm_meansmax_vals = 255 - norm_meansimgs = []#在迭代过程中,使用 compute_grads 函数(未提供)计算损失相对于初始图像的梯度,并使用优化器更新图像for i in range(num_iterations):grads, all_loss = compute_grads(cfg) #计算梯度和损失loss, style_score, content_score = all_lossopt.apply_gradients([(grads, init_image)]) #使用优化器clipped = tf.clip_by_value(init_image, min_vals, max_vals)#使用 tf.clip_by_value 将图像的像素值限制在合法范围内,防止梯度更新导致的像素值超出 [0, 255] 的范围。init_image.assign(clipped) #将裁剪后的图像值赋回 init_imageend_time = time.time()#如果当前损失小于最佳损失,则更新最佳损失和最佳图像。if loss < best_loss:best_loss = lossbest_img = deprocess_img(init_image.numpy())if i % display_interval == 0:start_time = time.time()plot_img = init_image.numpy()plot_img = deprocess_img(plot_img)imgs.append(plot_img)IPython.display.clear_output(wait=True) #清除之前的输出,以便显示新的图像。IPython.display.display_png(Image.fromarray(plot_img)) #显示图像print('Iteration: {}'.format(i))print('Total loss: {:.4e}, style loss: {:.4e}, content loss: {:.4e}, time: {: .4f}s'.format(loss, style_score, content_score, time.time() - start_time))print('Total time: {:.4f}s'.format(time.time() - global_start))return best_img, best_loss10.最后跑出来
run_style_transfer(content_path,style_path,num_iterations = 1000)
相关文章:
24/11/22 项目拆解 艺术风格转移
我们有时候想把两种艺术风格整合,创造更具艺术特色的艺术品,人很难办到,但是人工智能可以,比如下面将艺术画的风格转移到照片上。 我们先来初步了解一下实现上述功能的数学原理 所谓艺术风格,其实就是边缘,颜色&#…...
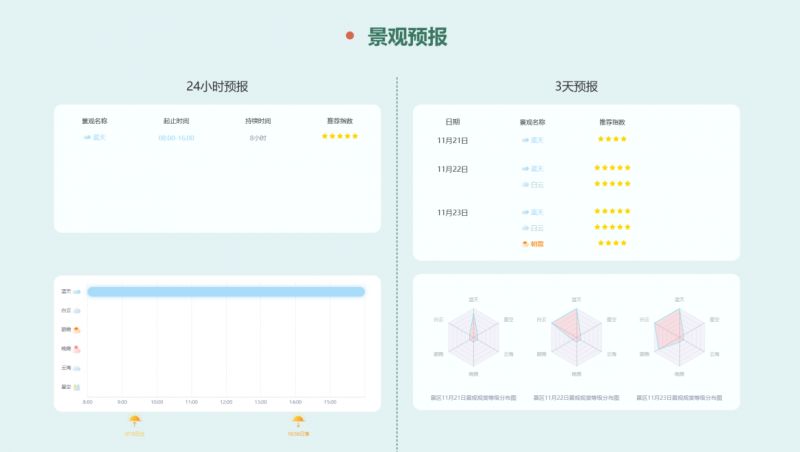
数字赋能,气象引领 | 气象景观数字化服务平台重塑京城旅游生态
在数字化转型的浪潮中,旅游行业正以前所未有的速度重塑自身,人民群众对于高品质、个性化旅游服务需求的日益增长,迎着新时代的挑战与机遇,为开展北京地区特色气象景观预报,打造“生态气象旅游”新业态,助推…...

关于Redux的学习(包括Redux-toolkit中间件)
目录 什么是 Redux ? 我为什么要用 Redux ? 我什么时候应该用 Redux ? Redux 库和工具 React-Redux Redux Toolkit Redux DevTools 拓展 一个redux小示例 代码示例(很有用): Redux 术语 Actions Reducers Store Dis…...

【无人机】
GJI Mini 4 Pro学习 首次飞行使用 01 开箱 打开长飞套装 依次取出产品及配件 飞行器、DJI RC - N2(DJI RC 2)、桨叶/螺丝、云台保护罩、束桨器、电池、螺丝刀、USB-C快接线、单肩包、USB-C数据线、充电管家 02 准备飞行器 取下束桨器,…...
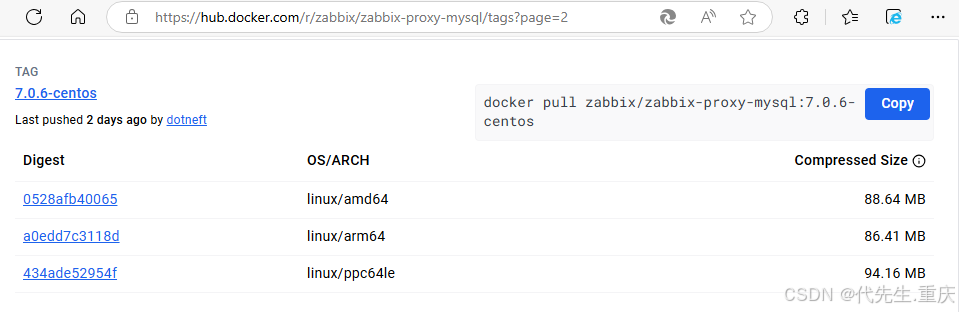
Zabbix7.0.6的容器镜像准备
准备Zabbix7.0.6部署所需的容器镜像。 更新时间:20241122 一、准备数据库镜像 1、核对版本支持 根据Zabbix官网文档requirements 可知,当前最新的Zabbix 7.0.6对PostgreSQL数据库的要求如下: support for PostgreSQL versions:- 17.X …...

利用 GitHub 和 Hexo 搭建个人博客【保姆教程】
利用 GitHub 和 Hexo 搭建个人博客 利用 GitHub 和 Hexo 搭建个人博客一、前言二、准备工作(一)安装 Node.js 和 Git(二)注册 GitHub 账号 三、安装 Hexo(一)创建博客目录(二)安装 H…...

React第四节 组件的三大属性之state
前言 状态 state适用于类式组件中,而再函数式组件中需要使用 useState HOOK 模拟状态; React的组件就是一个状态机,通过与用户的交互,实现不同的状态,根据不同的状态展现出不一样的UI视图 并不是组件中所有的属性 都是组件的状态…...

MongoDB进阶篇-索引(索引概述、索引的类型、索引相关操作、索引的使用)
文章目录 1. 索引概述2. 索引的类型2.1 单字段索引2.2 复合索引2.3 其他索引2.3.1 地理空间索引(Geospatial Index)2.3.2 文本索引(Text Indexes)2.3.3 哈希索引(Hashed Indexes) 3. 索引相关操作3.1 查看索…...

使用FFmpeg实现视频与GIF的画中画效果
用FFmpeg命令行工具将GIF动画作为画中画(Picture-in-Picture,简称PiP)叠加到视频上。FFmpeg是一个强大的多媒体框架,能够处理几乎所有格式的音频和视频文件。通过这个教程,你将学会如何将一个小的GIF动画循环播放&…...

车载信息安全框架 --- 车载信息安全相关事宜
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 所有人的看法和评价都是暂时的,只有自己的经历是伴随一生的,几乎所有的担忧和畏惧,都是来源于自己的想象,只有你真的去做了,才会发现有多快乐。…...

Unreal5从入门到精通之EnhancedInput增强输入系统详解
前言 从Unreal5开始,老版的输入系统,正式替换为EnhancedInput增强型输入系统,他们之间有什么区别呢? 如果有使用过Unity的同学,大概也知道,Unity也在2020版本之后逐渐把输入系统也升级成了新版输入系统,为什么Unreal和Unity都热衷于升级输入系统呢?这之间又有什么联系…...

泛微E9与金蝶云星空的集成方案:实现审批流程与财务管理的无缝对接
泛微E9与金蝶云星空的集成方案:实现审批流程与财务管理的无缝对接 背景介绍: 在企业日常运营中,泛微OA-E9和金蝶云星空是两个关键的系统。泛微OA-E9是一款广受企业青睐的办公自动化软件,它通过流程管理、文档管理、协同办公等模…...

理解设计模式与 UML 类图:构建稳健软件架构的基石
在软件开发的广阔天地里,设计模式与 UML(统一建模语言)类图犹如两座灯塔,为开发者照亮前行的道路,指引着我们构建出高质量、可维护且易于扩展的软件系统。今天,就让我们一同深入探索单一职责、开闭原则、简…...

FastAPI重载不生效?解决PyCharm中Uvicorn无法重载/重载缓慢的终极方法!
文章目录 📖 介绍 📖🏡 演示环境 🏡📒 重载缓慢 📒📝 问题概述🚨 相关原因📝 解决方案一📝 解决方案二📝 解决方案三📝 解决方案四⚓️ 相关链接 ⚓️📖 介绍 📖 在使用FastAPI开发时,reload=True 本应让你在修改代码后自动重启服务,提升开发效率…...
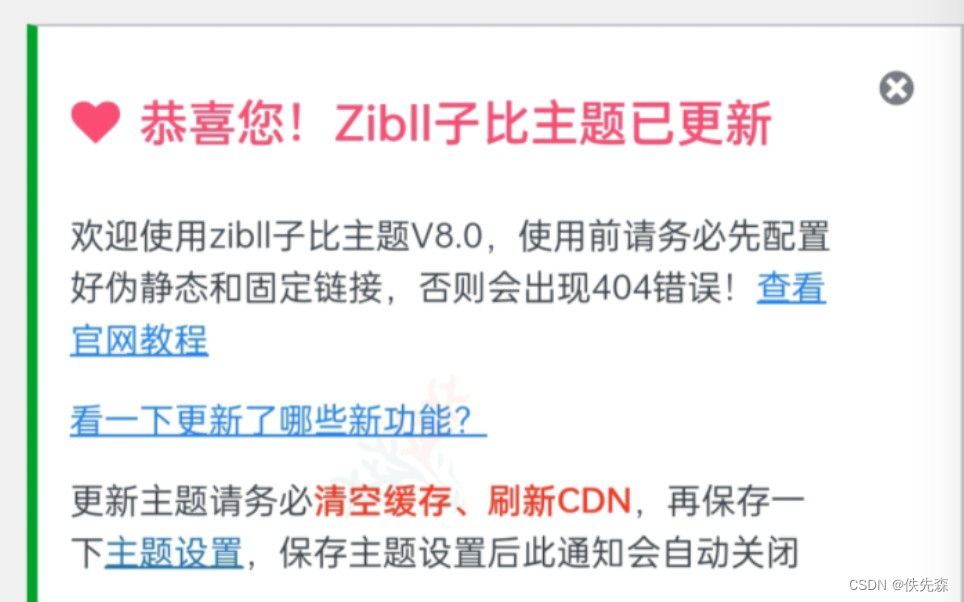
最新子比主题zibll8.0开心版源码 无加密无后门
Zibll子比主题专为博客、自媒体及资讯类网站精心打造,以其简约而不失高雅的设计风格,为网站增添独特魅力与视觉美感。 8.0更新内容: 新增发帖选择板块、话题、标签时支持搜索,同时优化了选择栏目,更加方便快捷 新增小工具文章列表…...

【数据分析】认清、明确
1、什么是数据分析。 - 通过对大量的数据进行科学的分析。 - 得出结论,提出建议,辅助公司企业的决策。2、数据分析分为几步。 - 1.明确目的! - 2.收集数据!自己的数据! 自动化采集的数据! - 3.数据处理! - 4.数据分析!数据分析(业务)数据挖掘(代码算法…...

工业生产安全-安全帽第二篇-用java语言看看opencv实现的目标检测使用过程
一.背景 公司是非煤采矿业,核心业务是采选,大型设备多,安全风险因素多。当下政府重视安全,头部技术企业的安全解决方案先进但价格不低,作为民营企业对安全投入的成本很敏感。利用我本身所学,准备搭建公司的…...

人工智能(AI)与机器学习(ML)基础知识
目录 1. 人工智能与机器学习的核心概念 什么是人工智能(AI)? 什么是机器学习(ML)? 什么是深度学习(DL)? 2. 机器学习的三大类型 (1)监督式学…...
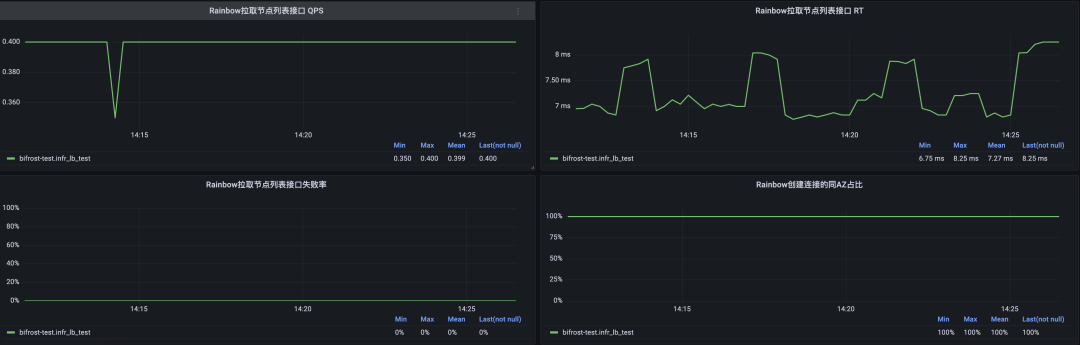
得物彩虹桥架构演进之路-负载均衡篇
文 / 新一 一、前言 一年一更的彩虹桥系列又来了,在前面两期我们分享了在稳定性和性能2个层面的一些演进&优化思路。近期我们针对彩虹桥 Proxy 负载均衡层面的架构做了一次升级,目前新架构已经部署完成,生产环境正在逐步升级中…...
Jmeter中的断言(四)
13--XPath断言 功能特点 数据验证:验证 XML 响应数据是否包含或不包含特定的字段或值。支持 XPath 表达式:使用 XPath 表达式定位和验证 XML 数据中的字段。灵活配置:可以设置多个断言条件,满足复杂的测试需求。 配置步骤 添加…...

网易云音乐NCM转MP3终极指南:ncmdump工具完整使用教程
网易云音乐NCM转MP3终极指南:ncmdump工具完整使用教程 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾经从网易云音乐下载了心爱的歌曲,却发现只能在特定播放器上收听?NCM格式的限制让音乐…...

从Gamma函数到泊松分布:一个概率论中的含参量积分实用案例解析
Gamma函数与泊松分布:概率论中的数学之美 在数据科学和机器学习的实践中,概率分布构成了建模的基石。当我们深入探究这些分布背后的数学原理时,Gamma函数以其优雅的性质和广泛的应用脱颖而出。它不仅连接了离散与连续概率世界,更在…...

服务器日志分析实战:用Python追踪HTTP 404错误并可视化异常频率
作为一名爬虫开发者或网站运维人员,服务器日志就像飞机的“黑匣子”——它记录了每个请求的来龙去脉。而404错误(页面未找到)尤其值得关注:它可能是用户输错了网址,可能是你爬虫的URL构造逻辑有漏洞,也可能是网站改版后旧的链接失效了。更严重的是,大量突然涌出的404请求…...

光效崩坏?噪点泛滥?色温漂移?——Midjourney专业级光效渲染全流程校准协议,含ACEScg色彩空间适配模板
更多请点击: https://kaifayun.com 第一章:光效崩坏、噪点泛滥与色温漂移的系统性归因诊断 图像采集链路中出现的光效崩坏、噪点泛滥与色温漂移并非孤立现象,而是光学设计、传感器响应、ISP管线调度及环境耦合失配共同作用的结果。三者常呈现…...

美团外卖mtgsig与waimai_sign双层签名逆向解析
1. 这不是“爬虫教程”,而是一份反向工程现场笔记你搜到这篇内容,大概率正卡在某个调试窗口前:抓包看到mtgsig和waimai_sign两个参数像两堵墙,无论怎么改请求头、换UA、清缓存,返回永远是{"code":403,"…...

基于ATtiny84的智能冰箱监控器:低功耗温度与门状态监测方案
1. 项目概述:一个装在树莓派盒子里的智能冰箱管家如果你家里有台老冰箱,或者对食物储存温度特别在意,总担心冰箱门没关严或者突然断电导致内部升温,那么这个自己动手做的“冰箱看门狗”项目就太适合你了。它本质上是一个高度定制化…...

网络配置工具类详解
CNet 网络配置工具类详解平台:仅支持 Linux,大量使用 ioctl 系统调用一、概述 CNet 是一个 纯静态方法的网络配置工具类,封装了 Linux 下常用的网络操作:功能类别涵盖内容IP 地址读取/设置本机 IP、子网掩码网关读取/添加/删除/设…...

AI率总超标?2026年AI写作辅助网站排行榜权威发布,轻松定稿不是梦!
写论文效率低、熬夜赶稿、查重不过关?别慌!2026 年最新 AI 论文写作工具合集来了,覆盖选题、大纲、初稿、润色、降重、格式、文献引用全流程,帮你精准匹配最适合的学术助手,彻底告别论文内耗!🏆…...

3分钟快速安装BetterNCM插件管理器,让你的网易云音乐功能翻倍
3分钟快速安装BetterNCM插件管理器,让你的网易云音乐功能翻倍 【免费下载链接】BetterNCM-Installer 一键安装 Better 系软件 项目地址: https://gitcode.com/gh_mirrors/be/BetterNCM-Installer 还在为网易云音乐功能单一而烦恼吗?想要解锁更多个…...

用图神经网络做缺陷定位,准确率比传统方法高出30%
在现代软件工程的复杂迷宫中,缺陷定位始终是测试团队面临的核心挑战。想象这样一个场景:一个电商系统在特定压力条件下偶发订单丢失,日志中只留下泛泛的超时错误,问题可能深藏在上百个微服务的调用链、分布式事务的竞态条件或某个…...