MongoDB进阶篇-索引(索引概述、索引的类型、索引相关操作、索引的使用)
文章目录
- 1. 索引概述
- 2. 索引的类型
- 2.1 单字段索引
- 2.2 复合索引
- 2.3 其他索引
- 2.3.1 地理空间索引(Geospatial Index)
- 2.3.2 文本索引(Text Indexes)
- 2.3.3 哈希索引(Hashed Indexes)
- 3. 索引相关操作
- 3.1 查看索引
- 3.2 创建索引
- 3.3.1 创建单字段索引
- 3.3.2 创建复合索引
- 3.3.3 创建文本索引
- 3.4 移除索引
- 3.4.1 移除指定索引
- 3.4.2 移除所有索引
- 4. 索引的使用
- 4.1 执行计划
- 4.2 执行计划中各个字段的含义
- 4.3 stage字段的取值及含义
- 4.4 覆盖查询
阅读本文前可以先阅读以下文章:
- MongoDB快速入门(MongoDB简介、MongoDB的应用场景、MongoDB中的基本概念、MongoDB的数据类型、MongoDB的安装与部署、MongoDB的常用命令)
- MongoDB的常用命令(数据库操作、集合操作、文档操作)
1. 索引概述
MongoDB 索引的官网文档:索引-MongoDB手册
索引支持在 MongoDB 中高效执行查询。如果没有索引,MongoDB 就必须扫描集合中的每个文档以返回查询结果。如果查询存在适当的索引,MongoDB 就可以使用该索引来限制其必须扫描的文档数
索引可提高查询性能,但添加索引会影响写入操作的性能。对于写入读取率高的集合,由于每次插入操作都必须同时更新所有索引,因此会带来较高的索引成本
MongoDB 索引使用 B-Tree 数据结构(MySQL 是 B+Tree)
2. 索引的类型
2.1 单字段索引
MongoDB 支持在文档的单个字段上创建用户定义的升序索引或降序索引,称为单字段索引(Single Field Index)
对于单个字段索引和排序操作,索引键的排序顺序(即升序或降序)并不重要,因为 MongoDB 可以在任何方向上遍历索引
2.2 复合索引
MongoDB 支持多个字段的自定义索引,即复合索引(Compound Index)
复合索引中列出的字段顺序具有重要意义。例如,如果复合索引由 { user_id: 1, score: -1 } 组成,则索引首先会按 user_id 正序排序,然后在每个 user_id 的值内,再按 score 倒序排序
2.3 其他索引
2.3.1 地理空间索引(Geospatial Index)
为了支持对地理空间坐标数据的有效查询,MongoDB 提供了两种特殊的索引:返回结果时使用平面几何的二维索引和返回结果时使用球面几何的二维球面索引
2.3.2 文本索引(Text Indexes)
文本索引的特点:
- 分词:MongoDB 在创建文本索引时会对字段内容进行分词处理,将文本分解成单词或术语(tokens)
- 权重:可以为不同的字段指定不同的权重,以便在搜索时影响文档的相关性得分
- 停用词:MongoDB 会忽略某些常用词(如 “the”、“and” 等),这些词被称为停用词。MongoDB 有一个内置的停用词列表,也可以自定义停用词列表
- 语言支持:MongoDB 的文本索引支持多种语言的分词和搜索
注意事项:
- 文本索引不存储停止词和词干。这意味着它们不会影响索引的大小
- 文本索引不能用于文本字段中的二进制数据
- 文本索引不能用于数组字段中的字符串元素
$text查询不能与$或$$运算符一起使用
2.3.3 哈希索引(Hashed Indexes)
为了支持基于散列的分片,MongoDB 提供了散列索引类型,它对字段值的散列进行索引。这些索引在其范围内的值分布更加随机,但只支持相等匹配,不支持基于范围的查询
3. 索引相关操作
3.1 查看索引
查看索引的语法
db.collection.getIndexes()
查看 comment 集合中所有的索引
db.collection.getIndexes()
查询结果如下
[ { v: 2, key: { _id: 1 }, name: '_id_' } ]
结果中显示的是默认的 _id_ 索引(MongoDB 在创建集合的过程中,会在 _id 字段上创建一个唯一的索引,默认名字为 _id_,该索引可防止插入两个具有相同 _id 值的文档)
- _id 索引是唯一索引,因此 _id 值不能重复
- 在分片集群中,通常使用 _id 作为片键
3.2 创建索引
创建索引的语法
db.collection.createIndex(keys, options)
| 参数名 | 类型 | 描述 | 必需 |
|---|---|---|---|
keys | 文档 | 指定索引的字段和索引类型。对于文本索引,字段类型应该设置为 "text"。可以指定单个字段或多个字段 | 是 |
options | 文档 | 索引的额外选项。这是一个可选参数,可以包含多个字段 | 否 |
options 参数的详细说明:
| 选项 | 类型 | 描述 | 默认值 |
|---|---|---|---|
background | 布尔 | 是否在后台创建索引。如果为 true,MongoDB 将在后台创建索引,这样就不会阻塞其他数据库操作 | false |
unique | 布尔 | 是否创建唯一索引。如果为 true,则索引字段的值必须是唯一的 | false |
name | 字符串 | 索引的名称。如果未指定,MongoDB 会自动生成一个名称 | 自动生成 |
partialFilterExpression | 文档 | 指定部分索引的过滤条件。只有满足条件的文档才会包含在索引中 | 无 |
sparse | 布尔 | 是否创建稀疏索引。如果为 true,则索引只包含具有指定字段的文档,忽略没有该字段的文档 | false |
expireAfterSeconds | 整数 | 对于具有日期类型的字段,指定文档在集合中的生存时间(TTL) | 无 |
storageEngine | 文档 | 指定索引的存储引擎配置 | 使用默认存储引擎配置 |
weights | 文档 | 对于文本索引,为索引中的每个字段指定权重。权重越高,字段在文本搜索中的相关性得分越高 | 所有字段权重相等 |
3.3.1 创建单字段索引
对 user_id 字段建立单字段索引
db.comment.createIndex({ user_id: 1 });
再次查看 comment 集合中所有的索引
[{ v: 2, key: { _id: 1 }, name: '_id_' },{ v: 2, key: { user_id: 1 }, name: 'user_id_1' }
]
3.3.2 创建复合索引
对 user_id 和 nickname 建立复合(Compound)索引
db.comment.createIndex({ userid: 1, nickname: -1 });
再次查看 comment 集合中所有的索引
[{ v: 2, key: { _id: 1 }, name: '_id_' },{ v: 2, key: { user_id: 1 }, name: 'user_id_1' },{v: 2,key: { userid: 1, nickname: -1 },name: 'userid_1_nickname_-1'}
]
3.3.3 创建文本索引
对 content 字段建立单字段索引
db.comment.createIndex({ content: "text" });
3.4 移除索引
3.4.1 移除指定索引
db.collection.dropIndex(index);
删除 comment 集合中 user_id 字段上的升序索引
db.comment.dropIndex({ user_id: 1 }
);
3.4.2 移除所有索引
db.collection.dropIndexes()
删除 comment 集合中的所有索引
db.comment.dropIndexes()
_id 的字段的索引是无法删除的,只能删除非 _id 字段的索引
4. 索引的使用
4.1 执行计划
分析查询性能(Analyze Query Performance)通常使用执行计划(Explain Plan)来查看查询的情况,如查询耗费的时间、是否基于索引查询等
db.collection.find(query,options).explain(options)
| 参数名 | 类型 | 描述 | 必需 |
|---|---|---|---|
query | document | 查询选择器,用于指定查询条件 | 是 |
options | document | 可选的。用于修改查询的默认行为的各种选项,如排序、限制等 | 否 |
explain | function | 用于获取查询执行计划的详细信息 | 是(调用时) |
explainOptions | document | 可选的。用于修改解释操作的默认行为的各种选项 | 否 |
每个参数的详细解释:
query: 这是一个文档,用于定义查询条件。它可以是简单的字段等值查询,也可以是复杂的条件组合,包括逻辑运算符和正则表达式options: 这是一个文档,可以包含多个键,用于控制查询的行为。常见的选项包括:sort: 排序条件limit: 限制返回的文档数量skip: 跳过文档的数量。projection: 投影,用于指定返回的字段
explain: 这是一个函数,当你在查询后面调用它时,MongoDB 不会返回查询结果,而是返回查询执行计划的详细信息。这有助于理解查询是如何执行的,以及如何优化查询explainOptions: 这是一个文档,用于控制解释操作的输出。例如,可以指定是否返回所有阶段的执行计划或者只返回获胜计划
根据 user_id 字段查询数据
db.comment.find({ user_id: "1003" }).explain();
MongoDB 返回的结果
{explainVersion: '1',queryPlanner: {namespace: 'test.comment',parsedQuery: {user_id: {'$eq': '1003'}},indexFilterSet: false,queryHash: 'B7F3AE51',planCacheKey: '8C1EE785',optimizationTimeMillis: 0,maxIndexedOrSolutionsReached: false,maxIndexedAndSolutionsReached: false,maxScansToExplodeReached: false,prunedSimilarIndexes: false,winningPlan: {isCached: false,stage: 'COLLSCAN',filter: {user_id: {'$eq': '1003'}},direction: 'forward'},rejectedPlans: []},command: {find: 'comment',filter: {user_id: '1003'},'$db': 'test'},serverInfo: {host: 'LAPTOP-G7HILK54',port: 27017,version: '8.0.3',gitVersion: '89d97f2744a2b9851ddfb51bdf22f687562d9b06'},serverParameters: {internalQueryFacetBufferSizeBytes: 104857600,internalQueryFacetMaxOutputDocSizeBytes: 104857600,internalLookupStageIntermediateDocumentMaxSizeBytes: 104857600,internalDocumentSourceGroupMaxMemoryBytes: 104857600,internalQueryMaxBlockingSortMemoryUsageBytes: 104857600,internalQueryProhibitBlockingMergeOnMongoS: 0,internalQueryMaxAddToSetBytes: 104857600,internalDocumentSourceSetWindowFieldsMaxMemoryBytes: 104857600,internalQueryFrameworkControl: 'trySbeRestricted',internalQueryPlannerIgnoreIndexWithCollationForRegex: 1},ok: 1
}
重点关注 winningPlan 中的 stage 字段(COLLSCAN 表示全盘扫描)

下面对 user_id 字段建立索引
db.comment.createIndex({ user_id: 1 });
再次查看执行计划
{explainVersion: '1',queryPlanner: {namespace: 'test.comment',parsedQuery: {user_id: {'$eq': '1003'}},indexFilterSet: false,queryHash: 'B7F3AE51',planCacheKey: '57E4C731',optimizationTimeMillis: 0,maxIndexedOrSolutionsReached: false,maxIndexedAndSolutionsReached: false,maxScansToExplodeReached: false,prunedSimilarIndexes: false,winningPlan: {isCached: false,stage: 'FETCH',inputStage: {stage: 'IXSCAN',keyPattern: {user_id: 1},indexName: 'user_id_1',isMultiKey: false,multiKeyPaths: {user_id: []},isUnique: false,isSparse: false,isPartial: false,indexVersion: 2,direction: 'forward',indexBounds: {user_id: ['["1003", "1003"]']}}},rejectedPlans: []},command: {find: 'comment',filter: {user_id: '1003'},'$db': 'test'},serverInfo: {host: 'LAPTOP-G7HILK54',port: 27017,version: '8.0.3',gitVersion: '89d97f2744a2b9851ddfb51bdf22f687562d9b06'},serverParameters: {internalQueryFacetBufferSizeBytes: 104857600,internalQueryFacetMaxOutputDocSizeBytes: 104857600,internalLookupStageIntermediateDocumentMaxSizeBytes: 104857600,internalDocumentSourceGroupMaxMemoryBytes: 104857600,internalQueryMaxBlockingSortMemoryUsageBytes: 104857600,internalQueryProhibitBlockingMergeOnMongoS: 0,internalQueryMaxAddToSetBytes: 104857600,internalDocumentSourceSetWindowFieldsMaxMemoryBytes: 104857600,internalQueryFrameworkControl: 'trySbeRestricted',internalQueryPlannerIgnoreIndexWithCollationForRegex: 1},ok: 1
}
可以发现,stage 字段已经变成了 FETCH,inputStage 属性里面的 stage 字段变成了 IXSCAN(基于索引的扫描)

4.2 执行计划中各个字段的含义
| 字段名 | 描述 |
|---|---|
| explainVersion | 解释输出的版本号。 |
| queryPlanner | 查询计划器的详细信息。 |
| namespace | 执行查询的命名空间(数据库和集合)。 |
| parsedQuery | 解析后的查询条件。 |
| indexFilterSet | 是否设置了索引过滤器。 |
| queryHash | 查询的哈希值。 |
| planCacheKey | 用于查询缓存的键。 |
| optimizationTimeMillis | 查询优化所花费的时间(毫秒)。 |
| maxIndexedOrSolutionsReached | 是否达到了索引 OR 解决方案的最大数量。 |
| maxIndexedAndSolutionsReached | 是否达到了索引 AND 解决方案的最大数量。 |
| maxScansToExplodeReached | 是否达到了索引爆炸扫描的最大数量。 |
| prunedSimilarIndexes | 是否修剪了相似的索引。 |
| winningPlan | 被选中的查询计划。 |
| isCached | 是否从计划缓存中检索到计划。 |
| stage | 查询执行的阶段。 |
| inputStage | 当前阶段的输入阶段(用于嵌套阶段)。 |
| keyPattern | 索引的键模式。 |
| indexName | 索引的名称。 |
| isMultiKey | 索引是否是多键索引。 |
| multiKeyPaths | 包含多键路径的索引字段。 |
| isUnique | 索引是否是唯一索引。 |
| isSparse | 索引是否是稀疏索引。 |
| isPartial | 索引是否是部分索引。 |
| indexVersion | 索引的版本。 |
| direction | 索引扫描的方向。 |
| indexBounds | 索引扫描的边界。 |
| rejectedPlans | 被拒绝的查询计划列表。 |
| command | 执行的命令的详细信息。 |
| serverInfo | 服务器信息,包括主机名、端口、版本等。 |
| serverParameters | 影响查询执行的服务器参数。 |
| ok | 命令是否成功执行的标志。 |
4.3 stage字段的取值及含义
| 阶段名称 | 描述 |
|---|---|
| COLLSCAN | 集合扫描,即全集合扫描,没有使用索引。 |
| IXSCAN | 索引扫描,使用索引来查找文档。 |
| FETCH | 获取阶段,用于检索索引扫描后找到的文档的其余字段。 |
| SHARD_MERGE | 在分片集群中,合并来自不同分片的查询结果。 |
| SORT | 排序阶段,对结果进行排序。 |
| LIMIT | 限制阶段,限制返回的文档数量。 |
| SKIP | 跳过阶段,跳过指定数量的文档。 |
| IDHACK | 对于 _id 的查询,MongoDB 可以使用特殊的优化。 |
| SHARDING_FILTER | 在分片集群中,用于过滤掉不属于当前查询的分片数据的阶段。 |
| PROJECTION | 投影阶段,只返回文档中的特定字段。 |
| TEXT | 文本搜索阶段,用于文本索引的搜索。 |
| GEONEAR | 地理空间查询阶段,用于查找最接近某个点的文档。 |
| GEOFILTER | 地理空间过滤阶段,用于过滤地理空间查询的结果。 |
| COUNT | 计数阶段,用于 count 操作。 |
| COUNT_SCAN | 使用索引进行计数扫描的阶段。 |
| COUNT_SCAN_WITH_FILTER | 使用索引进行计数扫描,并且应用过滤器的阶段。 |
| DISTINCT_SCAN | 用于 distinct 操作的索引扫描阶段。 |
| SUBPLAN | 子计划阶段,用于处理复杂查询的一部分。 |
| IXHASH | 使用散列索引的阶段。 |
| FORCED_SCAN | 强制进行集合扫描,即使存在索引。 |
| COVERED | 索引覆盖查询,所有需要的字段都在索引中,不需要回表查询。 |
| EOF | 查询结束。 |
4.4 覆盖查询
当查询条件和查询的投影仅包含索引字段时,MongoDB 会直接从索引返回结果,而不扫描任何文档或将文档带入内存,这些覆盖的查询非常高效(类似于 MySQL 中的覆盖索引)
db.comment.find({ user_id: "1003" },{ user_id: 1, _id: 0 }
).explain();
MongoDB 返回的结果
{explainVersion: '1',queryPlanner: {namespace: 'test.comment',parsedQuery: {user_id: {'$eq': '1003'}},indexFilterSet: false,queryHash: 'DC80EEEF',planCacheKey: 'B8237218',optimizationTimeMillis: 0,maxIndexedOrSolutionsReached: false,maxIndexedAndSolutionsReached: false,maxScansToExplodeReached: false,prunedSimilarIndexes: false,winningPlan: {isCached: false,stage: 'PROJECTION_COVERED',transformBy: {user_id: 1,_id: 0},inputStage: {stage: 'IXSCAN',keyPattern: {user_id: 1},indexName: 'user_id_1',isMultiKey: false,multiKeyPaths: {user_id: []},isUnique: false,isSparse: false,isPartial: false,indexVersion: 2,direction: 'forward',indexBounds: {user_id: ['["1003", "1003"]']}}},rejectedPlans: []},command: {find: 'comment',filter: {user_id: '1003'},projection: {user_id: 1,_id: 0},'$db': 'test'},serverInfo: {host: 'LAPTOP-G7HILK54',port: 27017,version: '8.0.3',gitVersion: '89d97f2744a2b9851ddfb51bdf22f687562d9b06'},serverParameters: {internalQueryFacetBufferSizeBytes: 104857600,internalQueryFacetMaxOutputDocSizeBytes: 104857600,internalLookupStageIntermediateDocumentMaxSizeBytes: 104857600,internalDocumentSourceGroupMaxMemoryBytes: 104857600,internalQueryMaxBlockingSortMemoryUsageBytes: 104857600,internalQueryProhibitBlockingMergeOnMongoS: 0,internalQueryMaxAddToSetBytes: 104857600,internalDocumentSourceSetWindowFieldsMaxMemoryBytes: 104857600,internalQueryFrameworkControl: 'trySbeRestricted',internalQueryPlannerIgnoreIndexWithCollationForRegex: 1},ok: 1
}

相关文章:
MongoDB进阶篇-索引(索引概述、索引的类型、索引相关操作、索引的使用)
文章目录 1. 索引概述2. 索引的类型2.1 单字段索引2.2 复合索引2.3 其他索引2.3.1 地理空间索引(Geospatial Index)2.3.2 文本索引(Text Indexes)2.3.3 哈希索引(Hashed Indexes) 3. 索引相关操作3.1 查看索…...

使用FFmpeg实现视频与GIF的画中画效果
用FFmpeg命令行工具将GIF动画作为画中画(Picture-in-Picture,简称PiP)叠加到视频上。FFmpeg是一个强大的多媒体框架,能够处理几乎所有格式的音频和视频文件。通过这个教程,你将学会如何将一个小的GIF动画循环播放&…...

车载信息安全框架 --- 车载信息安全相关事宜
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 所有人的看法和评价都是暂时的,只有自己的经历是伴随一生的,几乎所有的担忧和畏惧,都是来源于自己的想象,只有你真的去做了,才会发现有多快乐。…...

Unreal5从入门到精通之EnhancedInput增强输入系统详解
前言 从Unreal5开始,老版的输入系统,正式替换为EnhancedInput增强型输入系统,他们之间有什么区别呢? 如果有使用过Unity的同学,大概也知道,Unity也在2020版本之后逐渐把输入系统也升级成了新版输入系统,为什么Unreal和Unity都热衷于升级输入系统呢?这之间又有什么联系…...

泛微E9与金蝶云星空的集成方案:实现审批流程与财务管理的无缝对接
泛微E9与金蝶云星空的集成方案:实现审批流程与财务管理的无缝对接 背景介绍: 在企业日常运营中,泛微OA-E9和金蝶云星空是两个关键的系统。泛微OA-E9是一款广受企业青睐的办公自动化软件,它通过流程管理、文档管理、协同办公等模…...

理解设计模式与 UML 类图:构建稳健软件架构的基石
在软件开发的广阔天地里,设计模式与 UML(统一建模语言)类图犹如两座灯塔,为开发者照亮前行的道路,指引着我们构建出高质量、可维护且易于扩展的软件系统。今天,就让我们一同深入探索单一职责、开闭原则、简…...

FastAPI重载不生效?解决PyCharm中Uvicorn无法重载/重载缓慢的终极方法!
文章目录 📖 介绍 📖🏡 演示环境 🏡📒 重载缓慢 📒📝 问题概述🚨 相关原因📝 解决方案一📝 解决方案二📝 解决方案三📝 解决方案四⚓️ 相关链接 ⚓️📖 介绍 📖 在使用FastAPI开发时,reload=True 本应让你在修改代码后自动重启服务,提升开发效率…...
最新子比主题zibll8.0开心版源码 无加密无后门
Zibll子比主题专为博客、自媒体及资讯类网站精心打造,以其简约而不失高雅的设计风格,为网站增添独特魅力与视觉美感。 8.0更新内容: 新增发帖选择板块、话题、标签时支持搜索,同时优化了选择栏目,更加方便快捷 新增小工具文章列表…...

【数据分析】认清、明确
1、什么是数据分析。 - 通过对大量的数据进行科学的分析。 - 得出结论,提出建议,辅助公司企业的决策。2、数据分析分为几步。 - 1.明确目的! - 2.收集数据!自己的数据! 自动化采集的数据! - 3.数据处理! - 4.数据分析!数据分析(业务)数据挖掘(代码算法…...

工业生产安全-安全帽第二篇-用java语言看看opencv实现的目标检测使用过程
一.背景 公司是非煤采矿业,核心业务是采选,大型设备多,安全风险因素多。当下政府重视安全,头部技术企业的安全解决方案先进但价格不低,作为民营企业对安全投入的成本很敏感。利用我本身所学,准备搭建公司的…...

人工智能(AI)与机器学习(ML)基础知识
目录 1. 人工智能与机器学习的核心概念 什么是人工智能(AI)? 什么是机器学习(ML)? 什么是深度学习(DL)? 2. 机器学习的三大类型 (1)监督式学…...
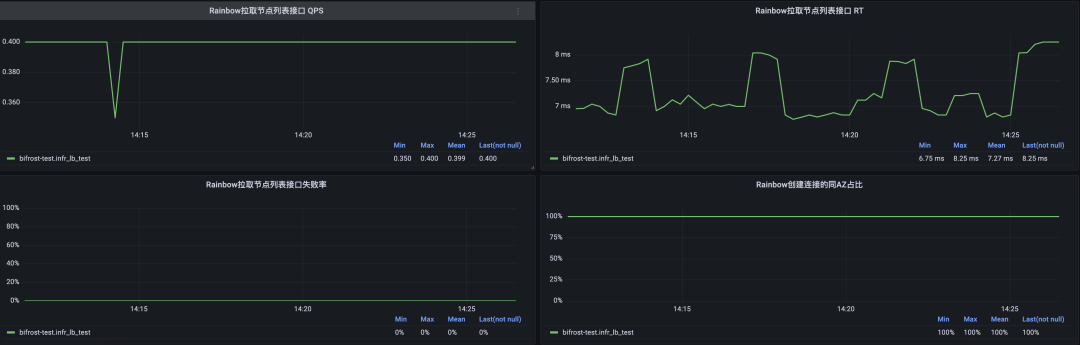
得物彩虹桥架构演进之路-负载均衡篇
文 / 新一 一、前言 一年一更的彩虹桥系列又来了,在前面两期我们分享了在稳定性和性能2个层面的一些演进&优化思路。近期我们针对彩虹桥 Proxy 负载均衡层面的架构做了一次升级,目前新架构已经部署完成,生产环境正在逐步升级中…...
Jmeter中的断言(四)
13--XPath断言 功能特点 数据验证:验证 XML 响应数据是否包含或不包含特定的字段或值。支持 XPath 表达式:使用 XPath 表达式定位和验证 XML 数据中的字段。灵活配置:可以设置多个断言条件,满足复杂的测试需求。 配置步骤 添加…...
)
vue2 src_Todolist编辑($nextTick)
main.js //引入Vue import Vue from "vue"; //引入App import App from ./App;//关闭Vue的生产提示 Vue.config.productionTip false;new Vue({el: #app,render: h > h(App),beforeCreate() {//事件总线Vue.prototype.$bus this;} });App.vue <template>…...

driver.js实现页面操作指引
概述 在访问某些网站的时候,第一次进去你会发现有个操作指引,本文引用driver.js,教你在你的页面也加入这般高大上的操作指引。 实现效果 实现 driver.js简介 driver.js是一个功能强大且高度可定制的基于原生JavaScript开发的新用户引导库…...

ffmpeg区域颜色覆盖
ffmpeg去除水印(遮盖指定区域)的几种办法_ffmpeg去水印-CSDN博客 ffmpeg -i a.mp4 -vf "drawboxx1560:y30:w310:h100:tfill" b.mp4 drawbox在视频帧上绘制一个矩形: x和y:矩形左上角的坐标。默认值是0。 w和h:矩形的宽度和高度。…...

【Python TensorFlow】进阶指南(续篇三)
在前几篇文章中,我们探讨了TensorFlow的高级功能,包括模型优化、分布式训练、模型解释等多个方面。本文将进一步深入探讨一些更具体和实用的主题,如模型持续优化的具体方法、异步训练的实际应用、在线学习的实现细节、模型服务化的最佳实践、…...

QT 实现仿制 网络调试器(未实现连接唯一性) QT5.12.3环境 C++实现
网络调试助手: 提前准备:在编写代码前,要在.pro工程文件中,添加network模块。 服务端: 代码: widget.h #ifndef WIDGET_H #define WIDGET_H#include <QWidget> #include <QtWidgets> #inclu…...

【英特尔IA-32架构软件开发者开发手册第3卷:系统编程指南】2001年版翻译,2-31
文件下载与邀请翻译者 学习英特尔开发手册,最好手里这个手册文件。原版是PDF文件。点击下方链接了解下载方法。 讲解下载英特尔开发手册的文章 翻译英特尔开发手册,会是一件耗时费力的工作。如果有愿意和我一起来做这件事的,那么ÿ…...

面试题---深入源码理解MQ长轮询优化机制
引言 在分布式系统中,消息队列(MQ)作为一种重要的中间件,广泛应用于解耦、异步处理、流量削峰等场景。其中,延时消息和定时消息作为MQ的高级功能,能够进一步满足复杂的业务需求。为了实现这些功能…...

DeepSeek系统设计辅助:如何在48小时内完成可审计、可回滚、可压测的AI服务架构图?
更多请点击: https://intelliparadigm.com 第一章:DeepSeek系统设计辅助 DeepSeek系统设计辅助模块面向架构师与后端工程师,提供模型能力调用、接口契约生成、异步任务编排等核心支撑能力。该模块不替代人工设计决策,而是通过结构…...

终极鼠标连点器使用指南:3分钟掌握高效自动化技巧
终极鼠标连点器使用指南:3分钟掌握高效自动化技巧 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 ,操作…...

自制极低频电流探头:负电阻补偿原理与低频方波测量实践
1. 项目概述:为极低频电流测量而生在电子测试领域,电流探头是个再常见不过的工具,无论是排查开关电源的纹波,还是分析电机驱动的波形,都离不开它。但如果你尝试用市面上常见的电流探头去观察一个频率低至几赫兹&#x…...

GEO生成引擎优化:当AI成为信息分发的主角,品牌如何抢占对话窗口?
当用户不再"搜索-浏览",而是直接"AI提问-获取答案",传统SEO的逻辑正在被彻底改写。2026年,GEO(Generative Engine Optimization,生成式引擎优化)已经从概念走向规模化落地。本文从技术…...

关联规则挖掘在Calabi-Yau流形Hodge数分析中的应用与复现
1. 项目概述:当数据挖掘遇见高维几何在理论物理和代数几何的交叉领域,Calabi-Yau流形一直扮演着核心角色。这些具有特殊拓扑结构的空间,不仅是弦理论中额外维度紧化的关键候选者,其本身丰富的数学性质也吸引着无数研究者。然而&am…...

PCL 基于强度的双边滤波【2026最新版】
目录 一、算法原理 1、计算步骤 2、算法源码 3、函数解析 4、参考文献 二、代码实现 三、结果展示 四、滤波后未发生变化的原因 五、解决办法 六、结果展示 七、相关链接 本文由CSDN点云侠原创,博客长期更新,本文最近一次更新时间为:2026年5月24日。 一、算法原理 1、计算…...

机器学习在犬类癌症筛查中的性能极限与挑战:基于血液数据的多癌种分析
1. 项目概述:当机器学习遇见犬类癌症筛查作为一名长期关注数据科学在生命科学领域应用的从业者,我常常被问及一个充满希望的问题:我们能否像分析人类健康数据一样,利用宠物的常规体检数据,通过机器学习提前发现癌症的蛛…...

关于软件版本升级的故事
起因在群里有网友说软件的版本升级比较简单,俺就回了四个字母“PACS”,并补上了一个表情 然后看见开始细说了:一、PACS 属于哪一类?PACS 软件 第二类医疗器械(独立软件)国家药监局分类:Ⅱ 类 2…...

D3KeyHelper终极指南:5分钟掌握暗黑3最强自动化工具
D3KeyHelper终极指南:5分钟掌握暗黑3最强自动化工具 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper D3KeyHelper是一款专为《暗黑破坏神3…...

当“画笔”变成“画笔”,世界便不再扁平:上海科技大学师玉娇团队 BevSplat 论文深度解读
用高斯画笔为地面图像“补上高度”,让卫星图片与街景的配对不再尴尬 想象一下这幅情境:一辆自动驾驶汽车在密集的城市楼群中行驶。GPS 信号被摩天大楼遮挡得断断续续,车辆根本无法准确知道自己的位置。于是,它需要一种备用方案&am…...