【Python TensorFlow】进阶指南(续篇三)

在前几篇文章中,我们探讨了TensorFlow的高级功能,包括模型优化、分布式训练、模型解释等多个方面。本文将进一步深入探讨一些更具体和实用的主题,如模型持续优化的具体方法、异步训练的实际应用、在线学习的实现细节、模型服务化的最佳实践、安全与隐私保护的技术细节,以及数据流处理的高级应用等,帮助读者全面掌握TensorFlow在实际部署中的应用。
1. 模型持续优化
1.1 模型诊断与调试
在模型训练过程中,使用TensorBoard等工具可以帮助诊断模型训练过程中出现的各种问题。
import tensorflow as tf
from tensorflow.keras import layers# 创建模型
model = tf.keras.Sequential([layers.Dense(64, activation='relu', input_shape=(10,)),layers.Dense(64, activation='relu'),layers.Dense(10, activation='softmax')
])# 编译模型
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])# 使用 TensorBoard 监控模型
log_dir = "logs/fit/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)# 训练模型
model.fit(x_train, y_train, epochs=5, validation_data=(x_val, y_val), callbacks=[tensorboard_callback])# 启动 TensorBoard
!tensorboard --logdir {log_dir}
1.2 模型再训练
为了保持模型性能,定期对模型进行再训练是非常必要的。
# 假设一段时间后模型表现下降
initial_score = model.evaluate(x_test, y_test)
print(f"Initial test accuracy: {initial_score[1]}")# 使用新的数据重新训练模型
new_data = load_new_data() # 加载新数据
model.fit(new_data[0], new_data[1], epochs=5)# 重新评估模型
new_score = model.evaluate(x_test, y_test)
print(f"Updated test accuracy: {new_score[1]}")
2. 异步训练
2.1 异步更新
异步训练允许多个工作节点同时更新模型参数,这有助于加速训练过程。这里我们将展示如何使用TensorFlow的Distributed Strategy API来进行异步训练。
import tensorflow as tf
from tensorflow.keras import layersstrategy = tf.distribute.experimental.MultiWorkerMirroredStrategy()# 创建模型
with strategy.scope():model = tf.keras.Sequential([layers.Dense(64, activation='relu', input_shape=(10,)),layers.Dense(64, activation='relu'),layers.Dense(10, activation='softmax')])model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])# 训练模型
def train_per_epoch(strategy, dataset, epochs=1):distributed_dataset = strategy.experimental_distribute_dataset(dataset)@tf.functiondef train_step(inputs):def step_fn(inputs):with tf.GradientTape() as tape:predictions = model(inputs)loss = loss_object(labels, predictions)gradients = tape.gradient(loss, model.trainable_variables)optimizer.apply_gradients(zip(gradients, model.trainable_variables))strategy.run(step_fn, args=(inputs,))for epoch in range(epochs):for batch in distributed_dataset:strategy.run(train_step, args=(batch,))# 假设我们有多个worker节点
train_per_epoch(strategy, train_dataset, epochs=5)
3. 在线学习
3.1 实时更新模型
在线学习允许模型根据实时数据进行更新,这对于推荐系统等需要即时响应的应用尤为重要。以下是一个简单的在线学习框架示例。
import tensorflow as tf
from tensorflow.keras import layers# 创建模型
model = tf.keras.Sequential([layers.Dense(64, activation='relu', input_shape=(10,)),layers.Dense(64, activation='relu'),layers.Dense(10, activation='softmax')
])# 编译模型
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])# 模拟实时数据流
class DataStream:def __init__(self, data):self.data = dataself.index = 0def __iter__(self):return selfdef __next__(self):if self.index < len(self.data):result = self.data[self.index]self.index += 1return resultelse:raise StopIterationdata_stream = DataStream([(x_train[i:i+32], y_train[i:i+32]) for i in range(0, len(x_train), 32)])# 实时更新模型
for x_batch, y_batch in data_stream:model.fit(x_batch, y_batch, epochs=1, verbose=0)
4. 模型服务化
4.1 模型部署
将模型部署为Web服务可以方便地在生产环境中使用。以下是一个使用Flask部署模型的例子。
from flask import Flask, request, jsonify
import tensorflow as tf
from tensorflow.keras import layersapp = Flask(__name__)# 创建模型
model = tf.keras.Sequential([layers.Dense(64, activation='relu', input_shape=(10,)),layers.Dense(64, activation='relu'),layers.Dense(10, activation='softmax')
])# 编译模型
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])@app.route('/predict', methods=['POST'])
def predict():data = request.get_json(force=True)input_data = np.array(data['input'], dtype=np.float32)prediction = model.predict(input_data).tolist()return jsonify({'prediction': prediction})if __name__ == '__main__':app.run(host='0.0.0.0', port=5000)
5. 安全与隐私保护
5.1 差分隐私
差分隐私是一种保护个人隐私的方法,在训练模型时可以加入噪声来保护个体数据的安全。以下是一个使用TensorFlow Privacy库实现差分隐私的示例。
import tensorflow as tf
from tensorflow_privacy.privacy.optimizers.dp_optimizer_keras import DPGradientDescentGaussianOptimizer# 创建模型
model = tf.keras.Sequential([layers.Dense(64, activation='relu', input_shape=(10,)),layers.Dense(64, activation='relu'),layers.Dense(10, activation='softmax')
])# 使用差分隐私优化器
dp_optimizer = DPGradientDescentGaussianOptimizer(l2_norm_clip=1.0,noise_multiplier=0.1,num_microbatches=1000,learning_rate=0.15)# 编译模型
model.compile(optimizer=dp_optimizer,loss='sparse_categorical_crossentropy',metrics=['accuracy'])# 训练模型
model.fit(x_train, y_train, epochs=5)
5.2 模型安全防御
模型安全防御涉及到保护模型不受对抗样本的攻击。以下是一个使用CleverHans库实现对抗样本防御的示例。
import tensorflow as tf
from cleverhans.tf2.attacks import projected_gradient_descent# 创建对抗样本
epsilon = 0.01
pgd_attack = projected_gradient_descent(model, epsilon=epsilon, eps_iter=epsilon / 4, nb_iter=10)# 评估对抗样本的影响
adv_x = pgd_attack(x_test)
score_adv = model.evaluate(adv_x, y_test)
print("Adversarial accuracy:", score_adv[1])
6. 数据流处理
6.1 使用 TensorFlow Data Service
TensorFlow提供了Data Service,可以在分布式环境中共享数据流。以下是一个使用TensorFlow Data Service的例子。
import tensorflow as tf# 创建一个数据集
dataset = tf.data.Dataset.range(100).batch(10)# 使用参数 server_address 设置数据服务器地址
params = tf.data.experimental.service.Parameters(processing_instance_name="instance_name",service_address="localhost:5000")# 将数据集应用于参数
dataset = dataset.apply(tf.data.experimental.service.distribute(params=params))# 从数据集中获取数据
for batch in dataset:print(batch.numpy())
7. 模型版本控制与回滚
7.1 版本控制
在模型的生命周期管理中,版本控制和回滚机制可以确保在出现问题时快速恢复到先前的状态。
import mlflow# 初始化 MLflow
mlflow.tensorflow.autolog()# 创建实验
mlflow.set_experiment("my-experiment")# 记录模型
with mlflow.start_run():model.fit(x_train, y_train, epochs=5)model.evaluate(x_test, y_test)# 查看实验结果
mlflow.ui.open_ui()
7.2 回滚机制
如果发现新部署的模型性能不如旧版本,可以通过版本控制系统轻松回滚到之前的版本。
# 获取最新版本的模型
run_id = "latest_run_id"
model_uri = f"runs:/{run_id}/models"# 加载模型
loaded_model = mlflow.pyfunc.load_model(model_uri)# 使用加载的模型进行预测
predictions = loaded_model.predict(x_test)
8. 模型监控与告警
8.1 模型性能监控
在模型上线后,持续监控模型的表现并通过告警系统及时发现问题是非常重要的。
import tensorflow as tf
from tensorflow.keras import layers# 创建模型
model = tf.keras.Sequential([layers.Dense(64, activation='relu', input_shape=(10,)),layers.Dense(64, activation='relu'),layers.Dense(10, activation='softmax')
])# 编译模型
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])# 使用 TensorBoard 监控模型
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir="logs", histogram_freq=1)# 训练模型
model.fit(x_train, y_train, epochs=5, callbacks=[tensorboard_callback])# 启动 TensorBoard
!tensorboard --logdir logs
8.2 告警系统
可以通过设置阈值并发送通知来建立模型性能的告警系统。
import smtplib
from email.mime.text import MIMETextdef send_email(subject, body):sender = "your_email@example.com"receivers = ["receiver@example.com"]msg = MIMEText(body)msg['Subject'] = subjectmsg['From'] = sendermsg['To'] = ", ".join(receivers)smtp_server = "smtp.example.com"smtp_port = 587smtp_user = "your_username"smtp_password = "your_password"with smtplib.SMTP(smtp_server, smtp_port) as server:server.starttls()server.login(smtp_user, smtp_password)server.sendmail(sender, receivers, msg.as_string())# 模型评估
score = model.evaluate(x_test, y_test)
accuracy = score[1]# 发送邮件告警
if accuracy < 0.8:subject = "Model Performance Alert"body = f"The model's test accuracy has dropped below 80%, current accuracy is {accuracy:.2f}"send_email(subject, body)
9. 结论
通过本文的学习,你已经掌握了TensorFlow在实际应用中的更多高级功能和技术细节。从模型持续优化、异步训练、在线学习,到模型服务化、安全与隐私保护,再到数据流处理、模型版本控制与回滚、模型监控与告警,每一步都展示了如何利用TensorFlow的强大功能来解决复杂的问题。
相关文章:
【Python TensorFlow】进阶指南(续篇三)
在前几篇文章中,我们探讨了TensorFlow的高级功能,包括模型优化、分布式训练、模型解释等多个方面。本文将进一步深入探讨一些更具体和实用的主题,如模型持续优化的具体方法、异步训练的实际应用、在线学习的实现细节、模型服务化的最佳实践、…...

QT 实现仿制 网络调试器(未实现连接唯一性) QT5.12.3环境 C++实现
网络调试助手: 提前准备:在编写代码前,要在.pro工程文件中,添加network模块。 服务端: 代码: widget.h #ifndef WIDGET_H #define WIDGET_H#include <QWidget> #include <QtWidgets> #inclu…...

【英特尔IA-32架构软件开发者开发手册第3卷:系统编程指南】2001年版翻译,2-31
文件下载与邀请翻译者 学习英特尔开发手册,最好手里这个手册文件。原版是PDF文件。点击下方链接了解下载方法。 讲解下载英特尔开发手册的文章 翻译英特尔开发手册,会是一件耗时费力的工作。如果有愿意和我一起来做这件事的,那么ÿ…...

面试题---深入源码理解MQ长轮询优化机制
引言 在分布式系统中,消息队列(MQ)作为一种重要的中间件,广泛应用于解耦、异步处理、流量削峰等场景。其中,延时消息和定时消息作为MQ的高级功能,能够进一步满足复杂的业务需求。为了实现这些功能…...

stable diffusion生成模型
1、stable diffusion Stable Diffusion 是一种扩散模型,基于对图像的逐步去噪过程训练和生成。它的核心包括以下几个步骤: 扩散过程(Diffusion Process)在训练时,向真实图像逐步添加噪声,最终将其变为纯随机噪声。这是一个正向过程,目的是学习如何将复杂的图像分解成随…...

分治法的魅力:高效解决复杂问题的利器
文章目录 分治法 (Divide and Conquer) 综合解析一、基本原理二、应用场景及详细分析1. 排序算法快速排序 (Quicksort)归并排序 (Mergesort) 2. 大整数运算大整数乘法 3. 几何问题最近点对问题 4. 字符串匹配KMP算法的优化版 三、优点四、局限性五、分治法与动态规划的对比六、…...

Spring IOC实战指南:从零到一的构建过程
Spring 优点: 方便解耦,简化开发。将所有对象创建和依赖关系维护交给 Spring 管理(IOC 的作用)AOP 切面编程的支持。方便的实现对程序进行权限的拦截、运行监控等功能(可扩展性)声明式事务的支持。只需通过配置就可以完成对事务的管理,无需手…...
)
3.langchain中的prompt模板 (few shot examples in chat models)
本教程将介绍如何使用LangChain库和智谱清言的 GLM-4-Plus 模型来理解和推理一个自定义的运算符(例如使用鹦鹉表情符号🦜)。我们将通过一系列示例来训练模型,使其能够理解和推断该运算符的含义。 环境准备 首先,确保…...
量子感知机
神经网络类似于人类大脑,是模拟生物神经网络进行信息处理的一种数学模型。它能解决分类、回归等问题,是机器学习的重要组成部分。量子神经网络是将量子理论与神经网络相结合而产生的一种新型计算模式。1995年美国路易斯安那州立大学KAK教授首次提出了量子…...
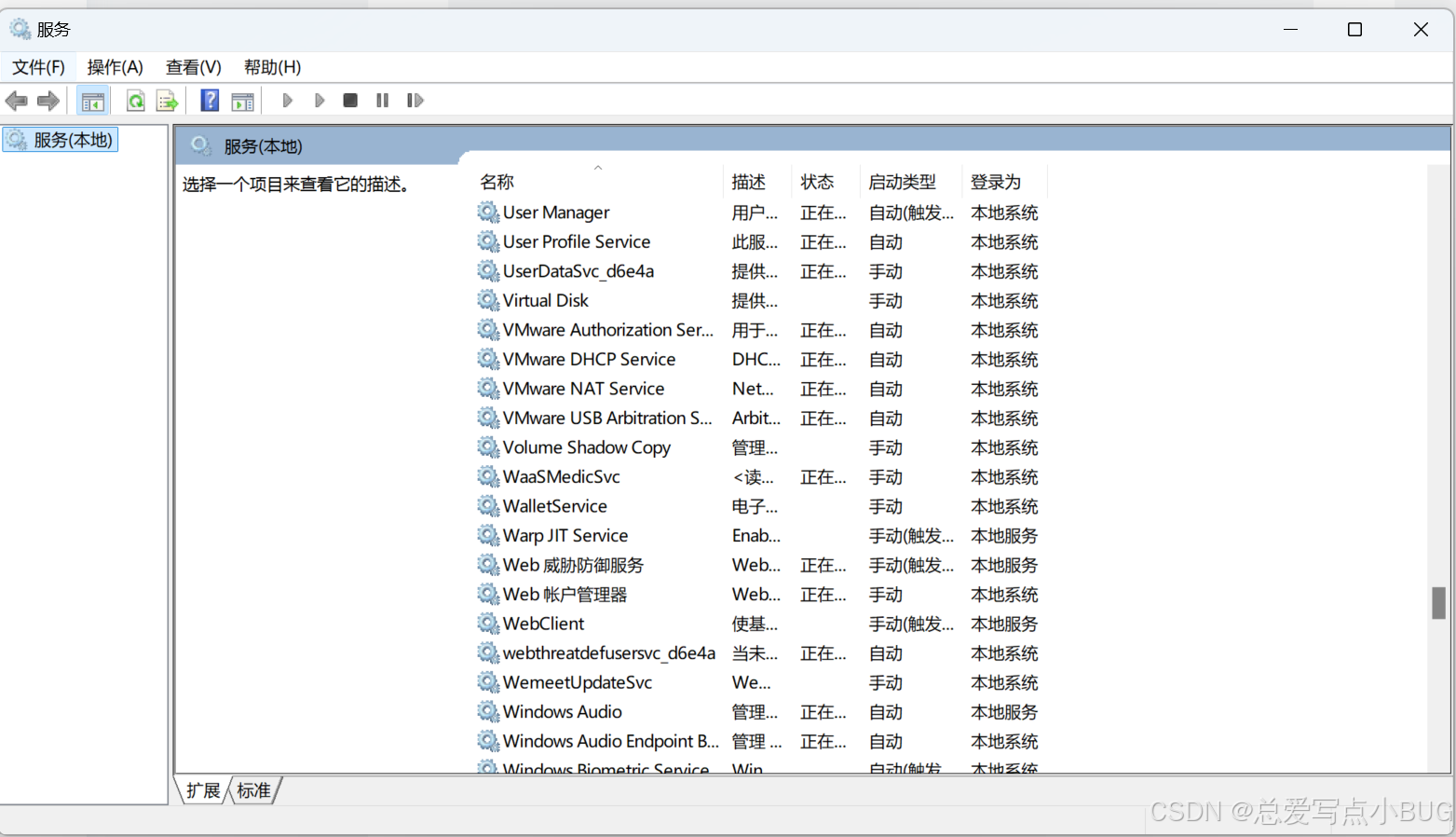
VM虚拟机装MAC后无法联网,如何解决?
✨在vm虚拟机上,给虚拟机MacOS设置网络适配器。选择NAT模式用于共享主机的IP地址 ✨在MacOS设置中设置网络 以太网 使用DHCP ✨回到本地电脑上,打开 服务,找到VMware DHCP和VMware NAT,把这两个服务打开,专一般问题就…...
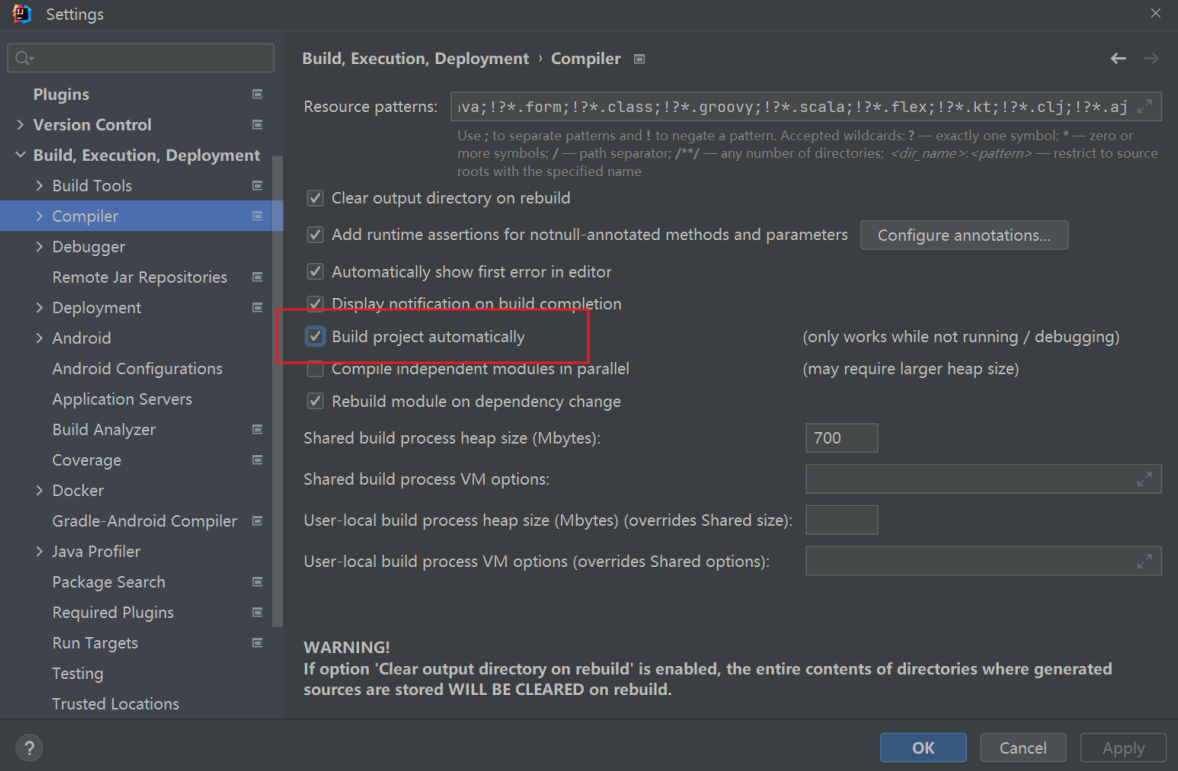
IDEA 基本设置
设置主题 设置字体 设置编码格式 改变字体大小 开启 按住 ctrl 滚轮 改变字体大小。 开启自动编译...
Chrome 浏览器 131 版本新特性
Chrome 浏览器 131 版本新特性 一、Chrome 浏览器 131 版本更新 1. 在 iOS 上使用 Google Lens 搜索 自 Chrome 126 版本以来,用户可以通过 Google Lens 搜索屏幕上看到的任何图片或文字。 要使用此功能,请访问网站,并点击聚焦时出现在地…...

使用php和Xunsearch提升音乐网站的歌曲搜索效果
文章精选推荐 1 JetBrains Ai assistant 编程工具让你的工作效率翻倍 2 Extra Icons:JetBrains IDE的图标增强神器 3 IDEA插件推荐-SequenceDiagram,自动生成时序图 4 BashSupport Pro 这个ides插件主要是用来干嘛的 ? 5 IDEA必装的插件&…...

计算机毕设-基于springboot的高校网上缴费综合务系统视频的设计与实现(附源码+lw+ppt+开题报告)
博主介绍:✌多个项目实战经验、多个大型网购商城开发经验、在某机构指导学员上千名、专注于本行业领域✌ 技术范围:Java实战项目、Python实战项目、微信小程序/安卓实战项目、爬虫大数据实战项目、Nodejs实战项目、PHP实战项目、.NET实战项目、Golang实战…...
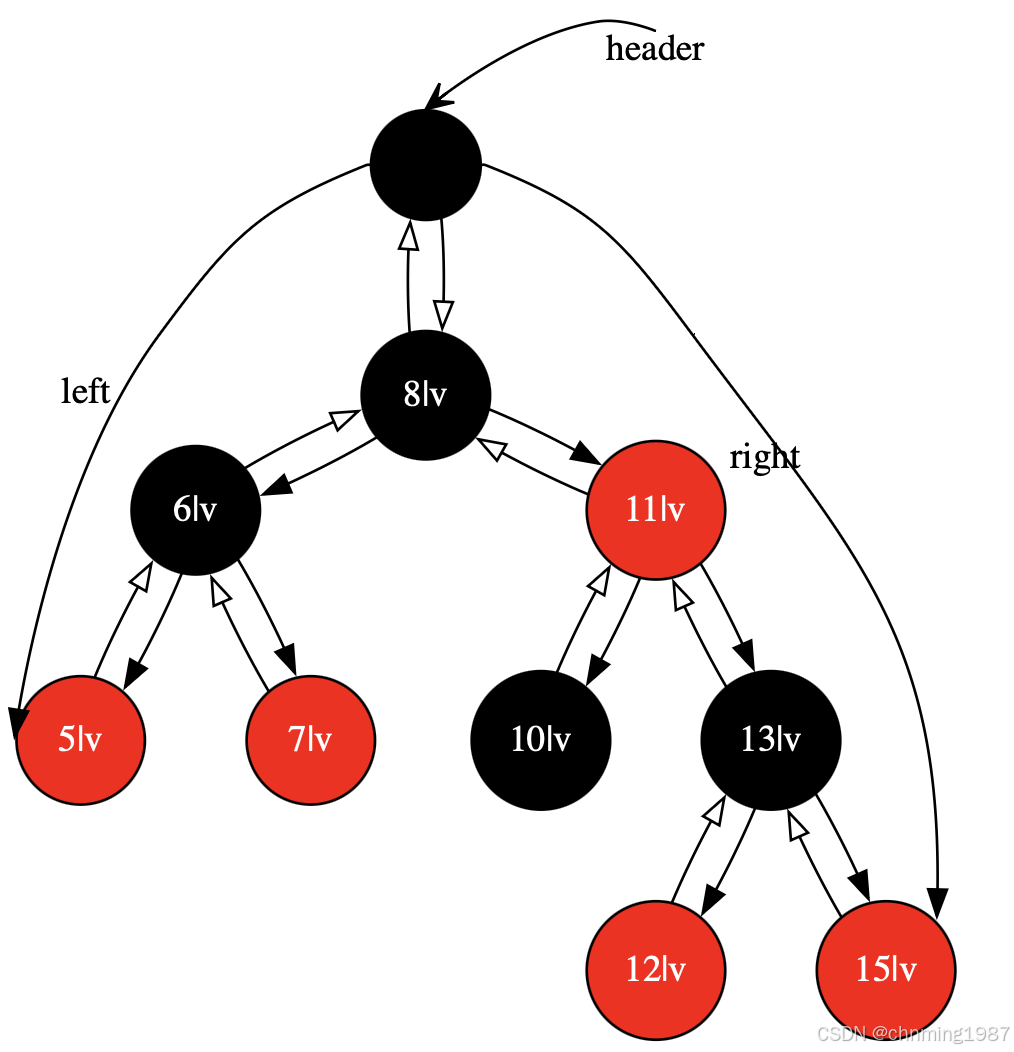
STL关联式容器之map
map的特性是,所有元素都会根据元素的键值自动被排序。map的所有元素都是pair,同时拥有实值(value)和键值(key)。pair的第一元素被视为键值,第二元素被视为实值。map不允许两个元素拥有相同的键值。下面是<stl_pair.h>中pair的定义 tem…...
【HarmonyOS】鸿蒙应用唤起系统相机拍照
【HarmonyOS】鸿蒙应用唤起系统相机拍照 方案一: 官方推荐的方式,使用CameraPicker来调用安全相机进行拍照。 let pathDir getContext().filesDir;let fileName ${new Date().getTime()}let filePath pathDir /${fileName}.tmpfileIo.createRandomA…...

Linux系统使用valgrind分析C++程序内存资源使用情况
内存占用是我们开发的时候需要重点关注的一个问题,我们可以人工根据代码推理出一个消耗内存较大的函数,也可以推理出大概会消耗多少内存,但是这种方法不仅麻烦,而且得到的只是推理的数据,而不是实际的数据。 我们可以…...

Java基础夯实——2.7 线程上下文切换
线程上下文切换(Thread Context Switching)是操作系统在多线程环境中,切换CPU从执行一个线程的上下文到另一个线程的上下文的过程。这种切换是实现多线程并发执行的核心机制之一。 1 上下文: 线程的上下文指线程在某一时刻的执行状态,如&am…...

死锁相关习题 10道 附详解
2022 设系统中有三种类型的资源(A,B,C)和五个进程(P1,P2,P3,P4,P5),A资源的数量是17,B资源的数量是6,C资源的数量是19。在T0时刻系统的状态: 最大资源需求量已分配资源量A,B,CA,B,…...
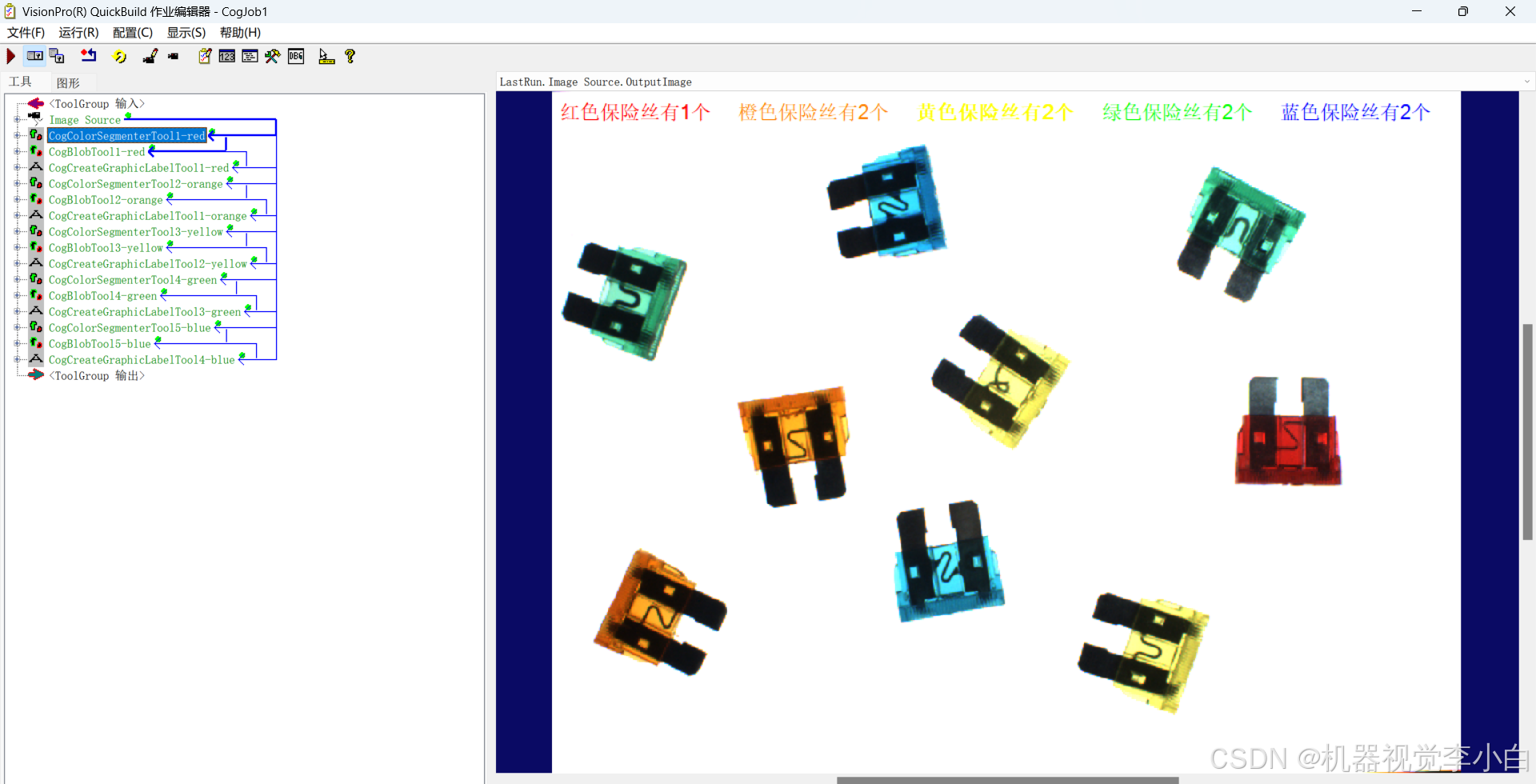
VisionPro 机器视觉案例 之 彩色保险丝个数统计
第十四篇 机器视觉案例 之 彩色保险丝颜色识别个数统计 文章目录 第十四篇 机器视觉案例 之 彩色保险丝颜色识别个数统计1.案例要求2.实现思路2.1 方法一 颜色分离工具CogColorSegmenterTool将每一种颜色分离出来,得到对应的单独图像,使用斑点工具CogBlo…...
 显卡排行榜 天梯图)
top50 BF16算力(TFLOPS) 显卡排行榜 天梯图
排名显卡型号BF16算力(TFLOPS)售价(元)单TFLOPS价格(元)1B200(SXM)45002200000488.892H200(SXM)19801200000606.063MI300X1307750000573.834H100 SXM519501100000564.105RTX PRO 6000 Blackwell1150780000678.266H100 PCIe 80GB1560850000544.877RTX 50906803400050.008A100 80…...

30岁裸辞后,我用两个月拿下AI应用认证,现在OFFER选择困难症犯了
30岁裸辞那天,我最怕的不是没收入,而是突然发现:过去积累的经验,正在被AI重新定价。以前会写方案、做表格、跟项目,算是职场硬通货;到了2026年,招聘JD里开始频繁出现AI工具应用、智能工作流、Pr…...

Python开发者首次使用Taotoken接入大模型API的完整步骤指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Python开发者首次使用Taotoken接入大模型API的完整步骤指南 对于Python开发者而言,接入大模型API进行应用开发已成为一…...

告别拍脑袋规划!用ArcGIS做绿道选线:如何科学量化坡度、水域、道路成本并加权计算
科学规划绿道的ArcGIS高阶技法:从成本栅格构建到最优路径生成绿道规划从来不是简单的"两点之间直线最短",而是需要综合考虑地形、生态、人文等多维因素的复杂决策过程。传统规划中常见的"拍脑袋"决策方式,往往导致建成后…...

光效崩坏?噪点泛滥?色温漂移?——Midjourney专业级光效渲染全流程校准协议,含ACEScg色彩空间适配模板
更多请点击: https://kaifayun.com 第一章:光效崩坏、噪点泛滥与色温漂移的系统性归因诊断 图像采集链路中出现的光效崩坏、噪点泛滥与色温漂移并非孤立现象,而是光学设计、传感器响应、ISP管线调度及环境耦合失配共同作用的结果。三者常呈现…...

PDF 可视化签名盖章页技术解析
本文是我在设备检测系统项目开发中,无设备检测的技术实现备忘录,记载实现过程。 本文以 PC 端页面 sign-pdf.vue 为主线,说明「无设备报检」在报告审批环节如何通过前后端协作,完成报告/记录 PDF 上的签名、印章、报告编号拖放定位,并在审批通过后由后端合并生成带签章的正…...

【紧急预警】Lindy衰减临界点已提前至第8.3个月!2024最新《营销自动化寿命健康度白皮书》限时开放前500份
更多请点击: https://kaifayun.com 第一章:Lindy衰减临界点的理论重构与实证突破 Lindy效应传统上描述“越老越长寿”的非线性生存规律,但其在现代软件系统、开源生态与协议层技术栈中的适用边界正遭遇结构性挑战。本文首次将Lindy模型从静…...
_kaic)
ssm207基于SSM的视频播放系统的设计与实现+vue(文档+源码)_kaic
第五章 系统的实现5.1 用户功能模块的实现5.1.1系统主界面用户进入本系统可查看系统信息,系统主界面展示如图5.1所示。图5.1网站主界面5.1.2视频详情界面用户可选择视频查看视频详情信息,并可进行视频播放操作,视频详情界面展示如图5.2所示。…...

关联规则挖掘在Calabi-Yau流形Hodge数分析中的应用与复现
1. 项目概述:当数据挖掘遇见高维几何在理论物理和代数几何的交叉领域,Calabi-Yau流形一直扮演着核心角色。这些具有特殊拓扑结构的空间,不仅是弦理论中额外维度紧化的关键候选者,其本身丰富的数学性质也吸引着无数研究者。然而&am…...

告别Postman!用APIfox搞定接口测试+自动化,这份保姆级教程带你从环境配置到报告生成
从Postman到APIfox:接口测试自动化的高效迁移指南如果你还在为接口测试中的重复劳动和多环境切换头疼,是时候考虑从Postman迁移到APIfox了。作为一名经历过这个转型过程的开发者,我想分享一些实战经验,帮助你平滑过渡并最大化利用…...