Python和MATLAB示例临床因素分析
🌵Python片段
为了演示临床因素的分析,让我们模拟一个数据集并执行一些基本的统计和机器学习分析。我们将重点关注以下步骤:
- 模拟数据集:创建具有年龄、性别、BMI、吸烟状况和疾病结果等特征的临床数据。
- 描述性统计:使用平均值、标准差和分布总结数据。
- 相关性分析:识别临床因素之间的关系。
- 预测模型:建立逻辑回归模型,根据临床特征预测疾病结果。
- 可视化:绘制重要关系和模型性能。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report# Step 1: Simulate the dataset
np.random.seed(42)# Simulating clinical factors
n_samples = 500
age = np.random.normal(50, 12, n_samples).clip(18, 90) # Age between 18 and 90
gender = np.random.choice(['Male', 'Female'], n_samples) # Binary gender
bmi = np.random.normal(25, 5, n_samples).clip(15, 50) # BMI between 15 and 50
smoking_status = np.random.choice(['Smoker', 'Non-Smoker'], n_samples, p=[0.3, 0.7])
disease_outcome = np.random.choice([0, 1], n_samples, p=[0.7, 0.3]) # Disease prevalence of 30%# Combine into a DataFrame
data = pd.DataFrame({'Age': age,'Gender': gender,'BMI': bmi,'Smoking_Status': smoking_status,'Disease_Outcome': disease_outcome
})# Encode categorical variables
data['Gender'] = data['Gender'].map({'Male': 1, 'Female': 0})
data['Smoking_Status'] = data['Smoking_Status'].map({'Smoker': 1, 'Non-Smoker': 0})data.head()
ResultAge Gender BMI Smoking_Status Disease_Outcome
0 55.960570 0 21.478282 0 0
1 48.340828 0 17.957694 0 0
2 57.772262 0 17.216854 0 0
3 68.276358 1 28.030050 0 1
4 47.190160 0 18.597853 1 1
模拟数据集包含 500 个样本,包含以下列:
- 年龄:表示患者年龄的连续变量。
- 性别:二元变量(1 = 男性,0 = 女性)。
- BMI:表示体重指数的连续变量。
- 吸烟状况:二元变量(1 = 吸烟者,0 = 非吸烟者)。
- 疾病结果:二元结果变量(1 = 有病,0 = 无病)。
下一步:
- 描述性统计和可视化
- 相关性分析
- 预测模型
让我们计算描述性统计并可视化数据分布
# Descriptive statistics
desc_stats = data.describe()# Visualizations
plt.figure(figsize=(14, 6))
plt.subplot(1, 3, 1)
sns.histplot(data['Age'], kde=True, bins=20, color='blue')
plt.title('Age Distribution')plt.subplot(1, 3, 2)
sns.histplot(data['BMI'], kde=True, bins=20, color='green')
plt.title('BMI Distribution')plt.subplot(1, 3, 3)
sns.countplot(x='Smoking_Status', data=data, palette='pastel')
plt.title('Smoking Status')plt.tight_layout()
plt.show()desc_stats
ResultAge Gender BMI Smoking_Status Disease_Outcome
count 500.000000 500.0000 500.000000 500.000000 500.000000
mean 50.083381 0.5200 25.540743 0.306000 0.298000
std 11.687369 0.5001 4.864940 0.461291 0.457838
min 18.000000 0.0000 15.000000 0.000000 0.000000
25% 41.596311 0.0000 22.200960 0.000000 0.000000
50% 50.153566 1.0000 25.652685 0.000000 0.000000
75% 57.641399 1.0000 28.568301 1.000000 1.000000
max 90.000000 1.0000 38.161910 1.000000 1.000000
描述性统计:
- 年龄:平均年龄约为 50 岁,标准差约为 11.7 岁。范围为 18-90 岁。
- BMI:平均年龄约为 25.5,与正常 BMI 范围一致,标准差约为 4.9。
- 吸烟状况:约 30.6% 的人口是吸烟者。
- 疾病结果:约 29.8% 患有该疾病,与模拟患病率一致。
可视化观察结果:
- 年龄分布:以平均年龄(~50)为中心的对称分布。
- BMI 分布:以~25 为中心的正态分布。
- 吸烟状况:非吸烟者占主导地位(~70% 的样本)。
接下来,我们分析这些因素与疾病结果之间的相关性。
# Correlation matrix (including only numerical variables)
correlation_matrix = data.corr()# Plotting the correlation heatmap
plt.figure(figsize=(8, 6))
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', fmt='.2f')
plt.title('Correlation Matrix')
plt.show()correlation_matrix
ResultAge Gender BMI Smoking_Status Disease_Outcome
Age 1.000000 0.062456 -0.005557 -0.064929 -0.065476
Gender 0.062456 1.000000 -0.071286 0.029883 0.074571
BMI -0.005557 -0.071286 1.000000 -0.034530 -0.087904
Smoking_Status -0.064929 0.029883 -0.034530 1.000000 0.013341
Disease_Outcome -0.065476 0.074571 -0.087904 0.013341 1.00000
相关性分析:
-
疾病结果:
- 与性别呈弱正相关性((~0.075)),表明男性患病率可能略高。
- 与年龄((-0.065))和 BMI((-0.088))呈非常弱的负相关性,表明没有很强的线性关系。
-
其他特征
- 其他特征之间的相关性非常小,表明多重共线性较低
我们将建立一个逻辑回归模型,根据临床特征预测疾病结果。这将深入了解有助于疾病预测的因素。
# Splitting the dataset into training and testing sets
X = data[['Age', 'Gender', 'BMI', 'Smoking_Status']]
y = data['Disease_Outcome']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# Logistic regression model
log_reg = LogisticRegression()
log_reg.fit(X_train, y_train)# Predictions and evaluation
y_pred = log_reg.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
class_report = classification_report(y_test, y_pred)accuracy, conf_matrix, class_report🌵MATLAB片段
% Simulate Clinical Dataset
rng(42); % For reproducibility
numPatients = 500;% Generate clinical factors
Age = randi([30, 80], numPatients, 1); % Age in years
BMI = 18 + 15*rand(numPatients, 1); % BMI
BP = randi([90, 160], numPatients, 1); % Blood Pressure
Cholesterol = randi([150, 300], numPatients, 1); % Cholesterol levels
Smoking = randi([0, 1], numPatients, 1); % Smoking status (0=No, 1=Yes)% Generate binary outcome: Heart Disease (1) or No Heart Disease (0)
% Using a logistic model for simulation
coeff = [0.03, 0.04, 0.05, 0.02, 0.5]; % Coefficients for logistic function
X = [Age, BMI, BP, Cholesterol, Smoking];
logit_prob = 1 ./ (1 + exp(-(X * coeff' - 10))); % Logistic probability
HeartDisease = double(rand(numPatients, 1) < logit_prob); % Generate outcome% Combine into a table
clinicalData = table(Age, BMI, BP, Cholesterol, Smoking, HeartDisease);% Data Preprocessing: Normalize numeric variables
numericVars = {'Age', 'BMI', 'BP', 'Cholesterol'};
for i = 1:length(numericVars)clinicalData.(numericVars{i}) = (clinicalData.(numericVars{i}) - ...mean(clinicalData.(numericVars{i}))) / std(clinicalData.(numericVars{i}));
end% Statistical Analysis
disp('Correlation Matrix:');
corrMatrix = corr(table2array(clinicalData(:, 1:5))); % Correlation of predictors
disp(corrMatrix);% Logistic Regression Model
X = table2array(clinicalData(:, 1:5)); % Features
y = clinicalData.HeartDisease; % Outcome
mdl = fitglm(X, y, 'Distribution', 'binomial', 'Link', 'logit');% Display Model Coefficients
disp('Model Coefficients:');
disp(mdl.Coefficients);% Evaluate Model: Predict on the dataset
predictedProb = predict(mdl, X);
predictedOutcome = predictedProb > 0.5;% Confusion Matrix and Accuracy
confMat = confusionmat(y, predictedOutcome);
disp('Confusion Matrix:');
disp(confMat);accuracy = sum(diag(confMat)) / sum(confMat(:));
disp(['Accuracy: ', num2str(accuracy)]);% Plot Receiver Operating Characteristic (ROC) Curve
[Xroc, Yroc, T, AUC] = perfcurve(y, predictedProb, 1);
disp(['AUC: ', num2str(AUC)]);figure;
plot(Xroc, Yroc);
xlabel('False Positive Rate');
ylabel('True Positive Rate');
title('ROC Curve');
grid on;
👉更新:亚图跨际
相关文章:

Python和MATLAB示例临床因素分析
🌵Python片段 为了演示临床因素的分析,让我们模拟一个数据集并执行一些基本的统计和机器学习分析。我们将重点关注以下步骤: 模拟数据集:创建具有年龄、性别、BMI、吸烟状况和疾病结果等特征的临床数据。描述性统计:…...

嵌入式硬件实战基础篇(二)-稳定输出3.3V的太阳能电池-无限充放电
引言:本内容主要用作于学习巩固嵌入式硬件内容知识,用于想提升下述能力,针对学习稳压芯片和电容以及电池之间的运用,对于硬件PCB以及原理图的练习和前面硬件篇的实际运用;太阳能是一种清洁、可再生的能源,广…...

【数据结构】树——链式存储二叉树的基础
写在前面 书接上文:【数据结构】树——顺序存储二叉树 本篇笔记主要讲解链式存储二叉树的主要思想、如何访问每个结点、结点之间的关联、如何递归查找每个结点,为后续更高级的树形结构打下基础。不了解树的小伙伴可以查看上文 文章目录 写在前面 一、链…...

STM32-- keil常见报错与解决办法
调试问题 1. keil在线调试需要点击好几次运行才可以运行,要是直接下载程序直接就不运行。 解决:target里面的use microlib要勾选,因为使用了printf。 keil在线调试STM32,点三次运行才能跑到main的问题解决。 keil在线调试STM32…...
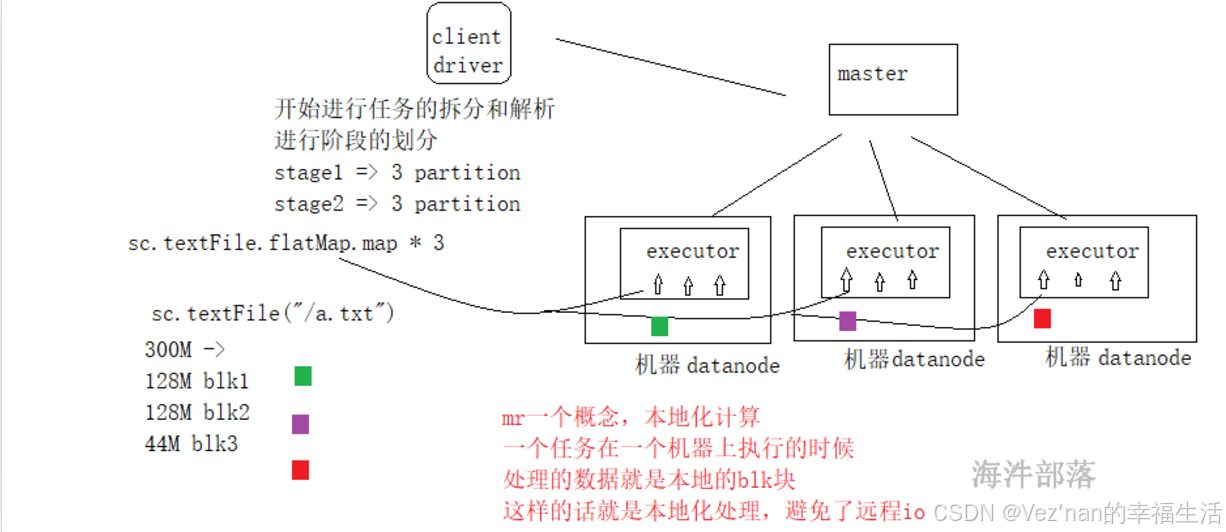
【大数据学习 | Spark-Core】RDD的概念与Spark任务的执行流程
1. RDD的设计背景 在实际应用中,存在许多迭代式计算,这些应用场景的共同之处是,不同计算阶段之间会重用中间结果,即一个阶段的输出结果会作为下一个阶段的输入。但是,目前的MapReduce框架都是把中间结果写入到HDFS中&…...

一文读懂埋阻埋容工艺
PCB 埋阻埋容工艺是一种在 PCB 板内部埋入电阻和电容的工艺。通常情况下, PCB 上电阻和电容都是通过贴片技术直接焊接在板面上的,而埋阻埋容工艺则将电 阻和电容嵌入到 PCB 板的内部层中,这种印制电路板,其自下而上依次包括第一介电 层,隐埋电…...
)
mysql 数据表导出为 markdown(附 go 语言 gorm 的实际使用)
前言 通常业务系统开发中,数据库的设计与维护是至关重要的环节。而数据库的文档化则是确保团队成员之间有效沟通、快速理解系统架构的基础。 但目前数据文档都是手动写的,耗时费力,由于当前项目使用的是 mysql 作为存储引擎,找找…...

本地云存储 MinIO 中修改用户密码
本地云存储 MinIO 中修改用户密码 MinIO 中修改用户密码前提条件步骤 1:安装 MinIO Client对于 Linux/macOS:对于 Windows: 步骤 2:配置 MinIO Client步骤 3:查看现有用户步骤 4:修改用户密码步骤 5&#x…...

go项目中比较好的实践方案
工作两年来,我并未遇到太大的挑战,也没有特别值得夸耀的项目。尽管如此,在日常的杂项工作中,我积累了不少心得,许多实践方法也在思考中逐渐得到优化。因此,我在这里记录下这些心得。 转发与封装 这个需求…...
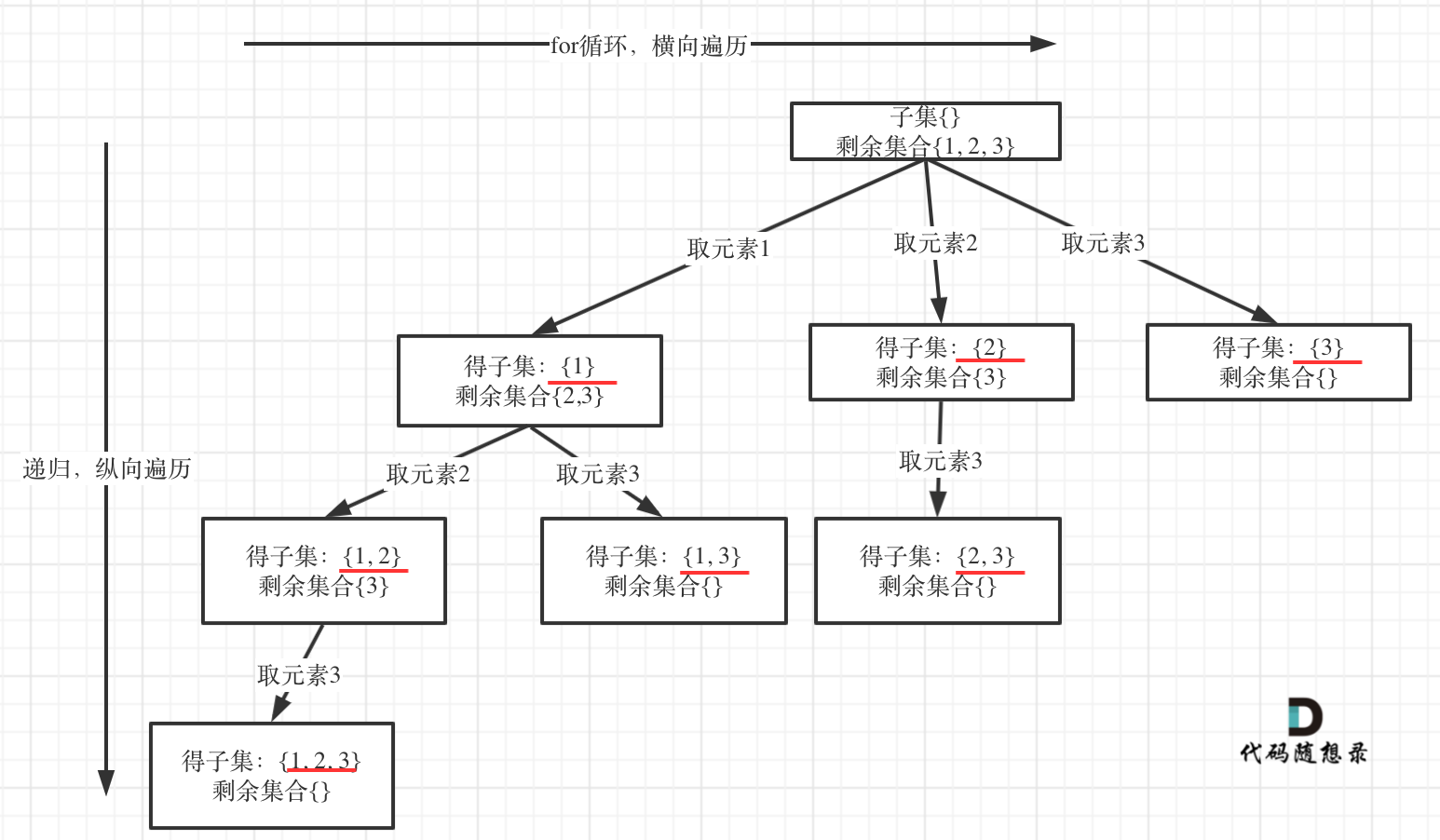
回溯法基础入门解析
回溯法 前 言 回溯法也可以叫做回溯搜索法,它是一种搜索的方式。回溯是递归的副产品,只要有递归就会有回溯。回溯法,一般可以解决如下几种问题: 组合问题:N个数里面按一定规则找出k个数的集合切割问题:一…...
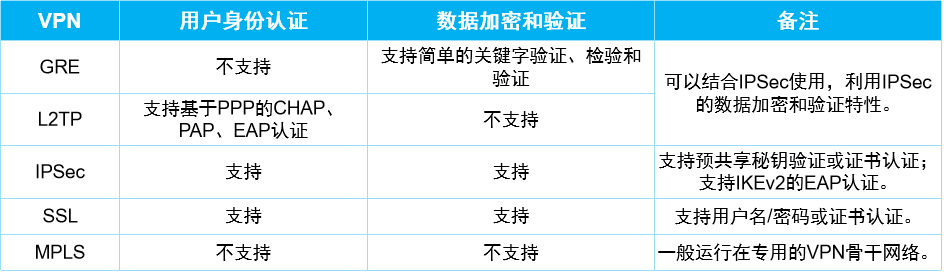
计算机网络-VPN虚拟专用网络概述
前面我们学习了在企业内部的二层交换机网络、三层路由网络包括静态路由、OSPF、IS-IS、NAT等,现在开始学习下VPN(Virtual Private Network,虚拟专用网络),其实VPN可能很多人听到第一反应就是梯子,但是其实这…...

信创时代的数据库之路:2024 Top10 国产数据库迁移与同步指南
数据库一直是企业数字化和创新的重要基础设施之一。从传统的关系型数据库到非关系型数据库、分析型数据库,再到云数据库和多模数据库,这一领域仍在持续变革中,各种新型数据库产品涌现,数据管理的能力和应用场景也由此得到了扩展。…...

自制游戏:监狱逃亡
第一个游戏,不喜勿喷: #include<bits/stdc.h> #include<windows.h> using namespace std; int xz; int ruond_1(int n){if(xz1){printf("撬开了,但站在你面前的是俄罗斯内务部特种部队的奥摩大帝,你被九把加特…...

小雪时节,阴盛阳衰,注意禁忌
宋张嵲《小雪作》 霜风一夜落寒林,莽苍云烟结岁阴。 把镜渐无勋业念,爱山唯驻隐沦心。 冰花散落衡门静,黄叶飘零一迳深。 世乱身穷无可奈,强将悲慨事微吟。 网络图片:小雪时节 笔者禁不住喟然而叹:“冰…...

CPU性能优化--微操作
x86 架构处理器吧复杂的CISC指令转为简单的RISC微操作。这样做最大的优势是微操作可以乱序执行,一条简单的相加指令--比如ADD,EAX, EBX,只产生一个微操作,而很多复杂指令--比如ADD, EAX 可能会产生两个微操作,一个将数…...

工厂模式
主要解决对象的创建问题 首先是简单工厂 只有一个工厂类,每次有新的产品就需要修改里面接口的内容,违反了封闭原则 //1、定义抽象产品类 class AbstractCar { public:AbstractCar() default;virtual ~AbstractCar() default;virtual void showName(…...

嵌入式系统与OpenCV
目录 一、OpenCV 简介 二、嵌入式 OpenCV 的安装方法 1. Ubuntu 系统下的安装 2. 嵌入式 ARM 系统中的安装 3. Windows10 和树莓派系统下的安装 三、嵌入式 OpenCV 的性能优化 1. 介绍嵌入式平台上对 OpenCV 进行优化的必要性。 2. 利用嵌入式开发工具,如优…...
编程之路,从0开始:动态内存笔试题分析
Hello大家好,很高兴我们又见面啦! 给生活添点passion,开始今天的编程之路。 今天我们来看几个经典的动态内存笔试题。 1、题目1 #define _CRT_SECURE_NO_WARNINGS #include<stdio.h> #include<string.h> void GetMemory(char* …...
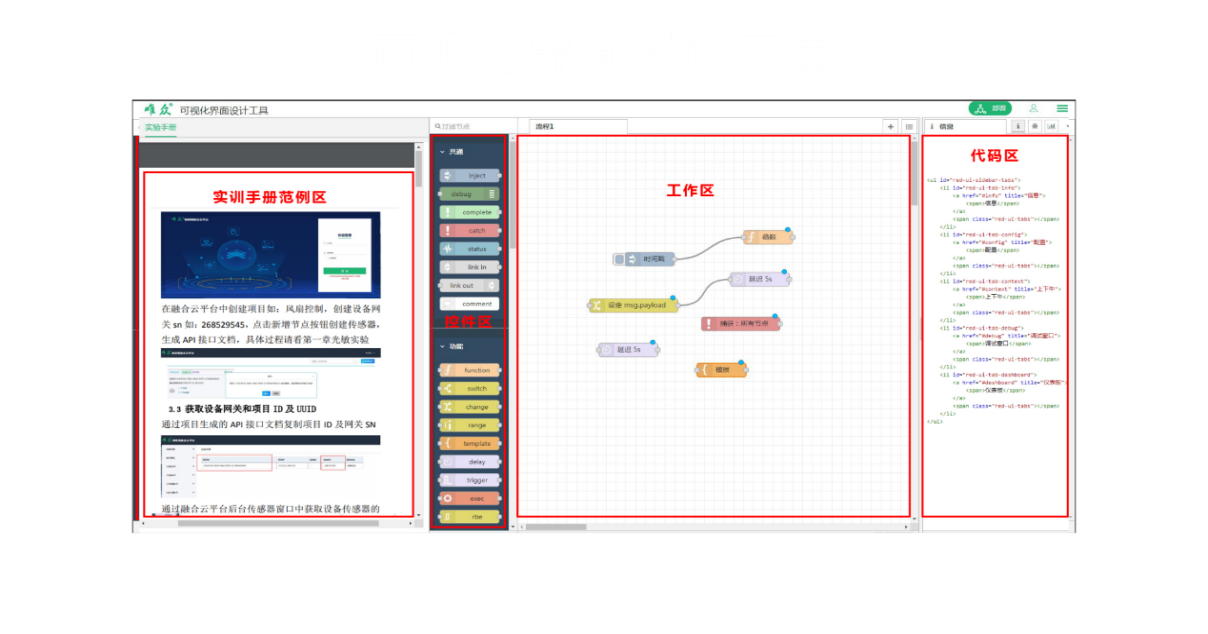
物联网研究实训室建设方案
一、引言 随着物联网技术的快速发展,其在各个行业的应用越来越广泛,对物联网专业人才的需求也日益增加。为满足这一需求,建设一个符合现代化教学需求的物联网研究实训室,对于提高学生的实践能力和创新能力具有重要意义。本方案旨…...
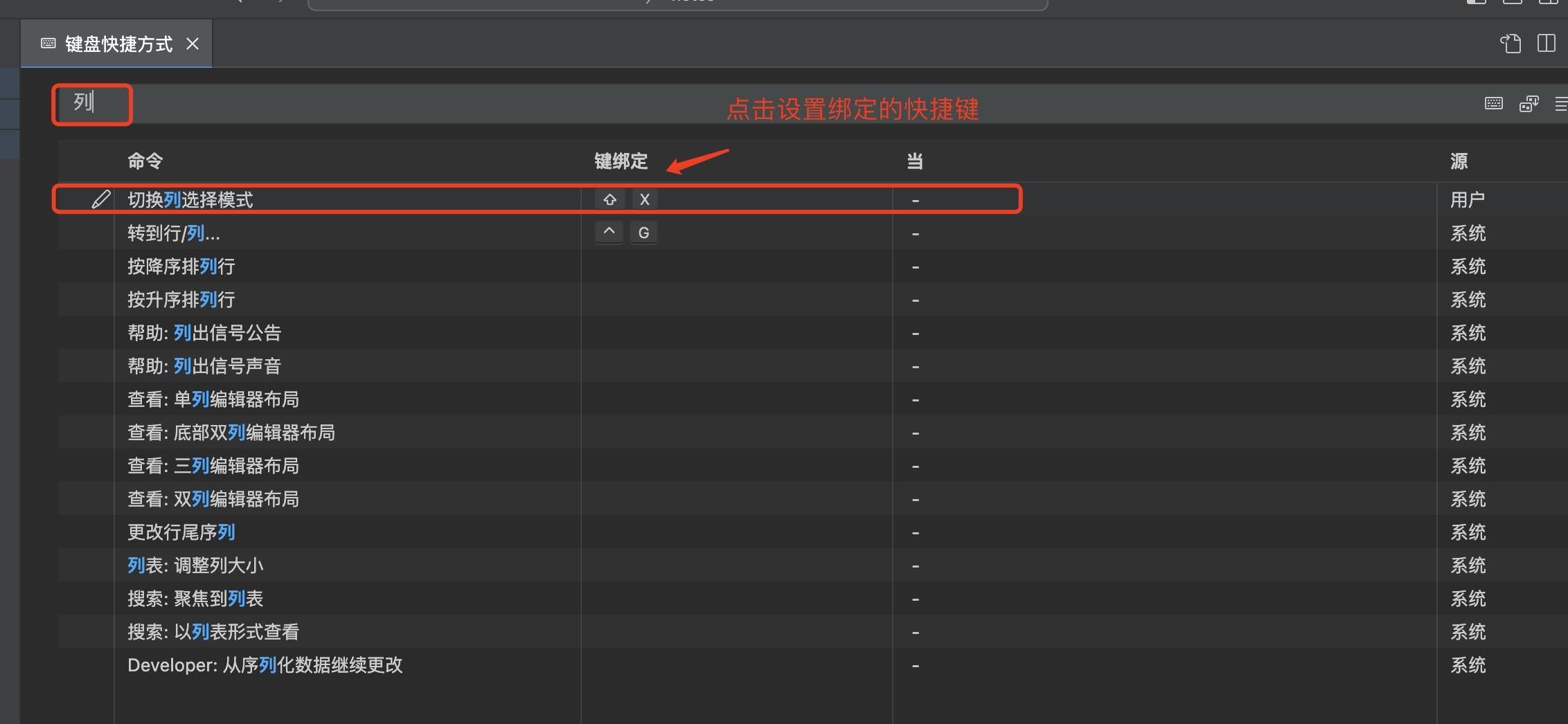
Mac vscode 激活列编辑模式
列编辑模式在批量处理多行文本时,非常有效,但 vscode 默认情况下,又没有激活,因此记录一下启动方法: 激活列编辑模式 然后就可以使用 Alt(Mac 上是 Option 或 Command 键) 鼠标左键 滑动选择了…...

tools.simonwillison.net图像处理工具集:从裁剪到优化的完整指南
tools.simonwillison.net图像处理工具集:从裁剪到优化的完整指南 【免费下载链接】tools Assorted useful tools, almost entirely generated using LLMs 项目地址: https://gitcode.com/gh_mirrors/tools23/tools tools.simonwillison.net图像处理工具集是一…...

T型翼/尾板导向的穿浪双体船姿态控制【附代码】
✨ 长期致力于穿浪双体船、T型翼、尾板、多自由度姿态控制、舒适性评估研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)动态水翼升力模型与耦合运动方…...

适合地产人用的中介房源管理系统
在房产经纪行业,房源管理与客源管理是经纪人日常工作的核心,直接影响业务效率与成交转化。选择一套适配行业需求的中介房源管理系统,能帮助中介团队规范流程、降低运营成本、大幅提升业绩。今天我们以客观视角,详细解析全房源系统…...

告别元素变动导致的报错:探索自动化测试脚本的 AI“自愈”能力
前言:一个所有测试人都经历过的噩梦 周三晚上十一点,CI/CD流水线再次亮起红灯。 你打开日志,满屏的NoSuchElementException扑面而来。仔细一看——前端团队在昨天的版本中重构了登录页面的DOM结构,原本的#login-btn变成了#signin-button-v2,30个测试用例因此全军覆没。 …...

论文润色深度测评:GPT-5.5 + Gemini 3.1 Pro:教你学会1+1>2的论文润色方法
各位同仁好,我是七哥。一个在高校里从事人工智能相关领域研究,钻研用大模型AI实操的学术人。可以和七哥交流学术写作或Gemini、GPT、Claude等大模型学术实操相关问题,多多交流,相互成就,共同进步。 2026年的科研圈,AI工具的选择已经从有没有变成了强不强,七哥评测了GPT…...

php有什么版本,php语言有几个版本
php有什么版本,php语言有几个版本PHP的大版本主要分四支:PHP4/PHP5/PHP6/PHP7 其中,PHP4由于太古老、对OO支持不力已基本被淘汰,请无视PHP4。 PHP6由于基本没有生产线上的应用,还基本只是一款概念产品,很多功能已在PHP…...

别再手动维护接口文档了!用Spring Boot 3和Swagger 3实现代码与文档的自动同步
Spring Boot 3与Swagger 3:构建零维护成本的API文档工作流 每次接口变更都要手动更新文档?团队成员总是抱怨文档与实际接口不一致?在敏捷开发时代,传统文档维护方式已成为拖累工程效率的典型痛点。本文将揭示如何通过Spring Boot …...

3步快速部署:智能茅台抢购平台的终极自动化解决方案
3步快速部署:智能茅台抢购平台的终极自动化解决方案 【免费下载链接】campus-imaotai i茅台app自动预约,每日自动预约,支持docker一键部署(本项目不提供成品,使用的是已淘汰的算法) 项目地址: https://gi…...

Burp抓包失败的五大隐形墙与HTTPS解密断裂点排查指南
1. 这不是Burp用得不对,是环境链路断在了你没看见的地方“Burp抓不到包”——这句话我过去三年里听开发、测试、刚转安全的新人说了不下两百遍。但真正打开Burp一看,Proxy标签页里空空如也,连个localhost:8080的请求都没有,十有八…...

京东自动购物终极指南:告别缺货烦恼,智能抢购神器
京东自动购物终极指南:告别缺货烦恼,智能抢购神器 【免费下载链接】Jd-Auto-Shopping 京东商品补货监控及自动下单 项目地址: https://gitcode.com/gh_mirrors/jd/Jd-Auto-Shopping 还在为心仪商品瞬间售罄而苦恼吗?还在熬夜等待补货却…...