分词器的概念(通俗易懂版)
什么是分词器?简单点说就是将字符序列转化为数字序列,对应模型的输入。
通常情况下,Tokenizer有三种粒度:word/char/subword
- word: 按照词进行分词,如:
Today is sunday. 则根据空格或标点进行分割[today, is, sunday, .] - character:按照单字符进行分词,就是以char为最小粒度。 如:
Today is sunday.则会分割成[t, o, d,a,y, .... ,s,u,n,d,a,y, .] - subword:按照词的subword进行分词。如:
Today is sunday.则会分割成[to, day,is , s,un,day, .]
可以看到这三种粒度分词截然不同,各有利弊。
对于word粒度分词:
- 优点:词的边界和含义得到保留;
- 缺点:1)词表大,稀有词学不好;2)OOV(可能超出词表外的词);3)无法处理单词形态关系和词缀关系,会将两个本身意思一致的词分成两个毫不相同的ID,在英文中尤为明显,如:cat, cats。
对于character粒度分词:
- 优点:词表极小,比如:26个英文字母几乎可以组合出所有词,5000多个中文常用字基本也能组合出足够的词汇;
- 缺点:1)无法承载丰富的语义,英文中尤为明显,但中文却是较为合理,中文中用此种方式较多。2)序列长度大幅增长;
最后为了平衡以上两种方法, 又提出了基于 subword 进行分词:它可以较好的平衡词表大小与语义表达能力;这种方法的目的是通过一个有限的词表 来解决所有单词的分词问题,同时尽可能将结果中 token 的数目降到最低。例如,可以用更小的词片段来组成更大的词,例如:
“unfortunately ” = “un ” + “for ” + “tun ” + “ate ” + “ly ”。
可以看到,有点类似英语中的词根词缀拼词法,其中的这些小片段又可以用来构造其他词。可见这样做,既可以降低词表的大小,同时对相近词也能更好地处理。
Subword 与传统分词方法的比较
- 传统词表示方法无法很好的处理未知或罕见的词汇(OOV 问题)。
- 传统词 tokenization 方法不利于模型学习词缀之间的关系,例如模型学到的“old”, “older”, and “oldest”之间的关系无法泛化到“smart”, “smarter”, and “smartest”。
- Character embedding 作为 OOV 的解决方法粒度太细。
- Subword 粒度在词与字符之间,能够较好的平衡 OOV 问题。
常见的子词算法有Byte-Pair Encoding (BPE) / Byte-level BPE(BBPE)、Unigram LM、WordPiece、SentencePiece等。
(BPE, Byte Pair Encoding)
字节对编码(BPE, Byte Pair Encoder),又称 digram coding 双字母组合编码,是一种数据压缩 算法,用来在固定大小的词表中实现可变⻓度的子词。该算法简单有效,因而目前它是最流行的方法。
BPE 首先将词分成单个字符,然后依次用另一个字符替换频率最高的一对字符 ,直到循环次数结束。
- 准备语料库,确定期望的 subword 词表大小等参数
- 通常在每个单词末尾添加后缀 </w>,统计每个单词出现的频率,例如,low 的频率为 5,那么我们将其改写为 "l o w </ w>”:5
- 注:停止符 </w> 的意义在于标明 subword 是词后缀。举例来说:st 不加 </w> 可以出现在词首,如 st ar;加了 </w> 表明该子词位于词尾,如 we st</w>,二者意义截然不同
- 将语料库中所有单词拆分为单个字符,用所有单个字符建立最初的词典,并统计每个字符的频率,本阶段的 subword 的粒度是字符
- 挑出频次最高的符号对 ,比如说 t 和 h 组成的 th,将新字符加入词表,然后将语料中所有该字符对融合(merge),即所有 t 和 h 都变为 th。
- 注:新字符依然可以参与后续的 merge,有点类似哈夫曼树,BPE 实际上就是一种贪心算法 。
- 重复遍历 2 和 3 操作,直到词表中单词数达到设定量 或下一个最高频数为 1 ,如果已经打到设定量,其余的词汇直接丢弃
- 注:看似我们要维护两张表,一个词表,一个字符表,实际上只有一张,词表只是为了我们方便理解。
一个完整的例子
我们举一个完整的例子,来直观地看一下这个过程:
获取语料库,这样一段话为例:“ FloydHub is the fastest way to build, train and deploy deep learning models. Build deep learning models in the cloud. Train deep learning models. ”
拆分,加后缀,统计词频:

建立词表,统计字符频率(顺便排个序)

以第一次迭代为例,将字符频率最高的 d 和 e 替换为 de,后面依次迭代:

更新词表

继续迭代直到达到预设的 subwords 词表大小或下一个最高频的字节对出现频率为 1。
如果将词表大小设置为 10,最终的结果为:
- d e
- r n
- rn i
- rni n
- rnin g</w>
- o de
- ode l
- m odel
- l o
- l e
这样我们就得到了更加合适的词表,这个词表可能会出现一些不是单词的组合,但是其本身有意义的一种形式
BPE 的优点
- 上面例子中的语料库很小,知识为了方便我们理解 BPE 的过程,但实际中语料库往往非常非常大,无法给每个词(token)都放在词表中。BPE 的优点就在于,可以很有效地平衡词典大小和编码步骤数(将语料编码所需要的 token 数量)。
- 随着合并的次数增加,词表大小通常先增加后减小。迭代次数太小,大部分还是字母,没什么意义;迭代次数多,又重新变回了原来那几个词。所以词表大小要取一个中间值。
BPE 的缺点
- 对于同一个句子, 例如 Hello world,如图所示,可能会有不同的 Subword 序列。不同的 Subword 序列会产生完全不同的 id 序列表示,这种歧义可能在解码阶段无法解决。在翻译任务中,不同的 id 序列可能翻译出不同的句子,这显然是错误的。
- 在训练任务中,如果能对不同的 Subword 进行训练的话,将增加模型的健壮性,能够容忍更多的噪声,而 BPE 的贪心算法无法对随机分布进行学习。

BPE 的适用范围
BPE 一般适用在欧美语言拉丁语系中,因为欧美语言大多是字符形式,涉及前缀、后缀的单词比较多。而中文的汉字一般不用 BPE 进行编码,因为中文是字无法进行拆分。对中文的处理通常只有分词和分字两种。理论上分词效果更好,更好的区别语义。分字效率高、简洁,因为常用的字不过 3000 字,词表更加简短。
BBPE
对于英文、拉美体系的语言来说使用BPE分词足以在可接受的词表大小下解决OOV的问题,但面对中文、日文等语言时,其稀有的字符可能会不必要的占用词汇表,因此考虑使用字节级别byte-level解决不同语言进行分词时OOV的问题。具体的,BBPE考虑将一段文本的UTF-8编码(UTF-8保证任何语言都可以通用)中的一个字节256位不同的编码作为词表的初始化基础Subword。
最主要区别是BPE基于char粒度去执行合并的过程生成词表,而BBPE是基于4个字节、总共256个不同的字节编码(Byte) 去执行合并过程生成词表。
BPE解决一个问题是能比较好支持语料是多种语言的分词,一方面正如上面所说,如果只考虑英文、法语、西班牙语等拉丁美系的语言,BEP足以支持能够以较小词表大小(Vocabulary Size)解决OOV的问题。但中文、日本如果使用BEP对字符(characters)进行构造词表的话,其具有的生僻词会占据浪费比较大词表空间。
WordPiece 算法
WordPiece:WordPiece算法可以看作是BPE的变种。不同的是,WordPiece基于概率生成新的subword而不是下一最高频字节对。WordPiece算法也是每次从词表中选出两个子词合并成新的子词。BPE选择频数最高的相邻子词合并,而WordPiece选择使得语言模型概率最大的相邻子词加入词表。
Unigram
它和 BPE 以及 WordPiece 从表面上看一个大的不同是,前两者都是初始化一个小词表,然后一个个增加到限定的词汇量,而 Unigram Language Model 却是先初始一个大词表,接着通过语言模型评估不断减少词表,直到限定词汇量。
SentencePiece
SentencePiece它是谷歌推出的子词开源工具包,它是把一个句子看作一个整体,再拆成片段,而没有保留天然的词语的概念。一般地,它把空格也当作一种特殊字符来处理,再用BPE或者Unigram算法来构造词汇表。SentencePiece除了集成了BPE、ULM子词算法之外,SentencePiece还能支持字符和词级别的分词。
SentencePiece 是一种无监督的文本 tokenizer 和 detokenizer,主要用于基于神经网络的文本生成系统,其中,词汇量在神经网络模型训练之前就已经预先确定了。 SentencePiece 实现了subword单元(例如,字节对编码 (BPE))和 unigram 语言模型),并可以直接从原始句子训练字词模型(subword model)。 这使得我们可以制作一个不依赖于特定语言的预处理和后处理的纯粹的端到端系统。
- SentencePiece可以从原始句子中直接训练分词和去分词模型,不需要依赖于特定语言的预处理或后处理。
- BPE的训练通常需要预分词步骤,例如使用空格或标点符号作为初始的分词依据。

相关文章:
分词器的概念(通俗易懂版)
什么是分词器?简单点说就是将字符序列转化为数字序列,对应模型的输入。 通常情况下,Tokenizer有三种粒度:word/char/subword word: 按照词进行分词,如: Today is sunday. 则根据空格或标点进行分割[today, is, sunda…...

速通前端篇 —— CSS
找往期文章包括但不限于本期文章中不懂的知识点: 个人主页:我要学编程程(ಥ_ಥ)-CSDN博客 所属专栏:速通前端 目录 CSS的介绍 基本语法规范 CSS选择器 标签选择器 class选择器 id选择器 复合选择器 通配符选择器 CSS常见样式 颜…...

数据库表设计范式
华子目录 MYSQL库表设计:范式第一范式(1NF)第二范式(2NF)第三范式(3NF)三范式小结巴斯-科德范式(BCNF)第四范式(4NF)第五范式(5NF&…...
经济增长初步
1.人均产出 人均产出,通常指的是一个国家、地区或组织在一定时期内,每个劳动人口平均创造的生产总值。它是衡量一个地区或国家经济效率和劳动生产率的重要指标。具体来说,人均产出可以通过以下公式计算: 人均产出总产出/劳动人口…...

【架构】主流企业架构Zachman、ToGAF、FEA、DoDAF介绍
文章目录 前言一、Zachman架构二、ToGAF架构三、FEA架构四、DoDAF 前言 企业架构(Enterprise Architecture,EA)是指企业在信息技术和业务流程方面的整体设计和规划。 最近接触到“企业架构”这个概念,转念一想必定和我们软件架构…...

时间请求参数、响应
(7)时间请求参数 1.默认格式转换 控制器 RequestMapping("/commonDate") ResponseBody public String commonDate(Date date){System.out.println("默认格式时间参数 date > "date);return "{module : commonDate}"; }…...

PyTorch图像预处理:计算均值和方差以实现标准化
在深度学习中,图像数据的预处理是一个关键步骤,它直接影响模型的训练效果和收敛速度。PyTorch提供的transforms.Normalize()函数允许我们对图像数据进行标准化处理,即减去均值并除以方差。这一步骤对于提高模型性能至关重要。 为什么需要标准…...
slice介绍slice查看器
Android Jetpack架构组件(十)之Slices - 阅读清单 - 腾讯云开发者社区-腾讯云 slice 查看器apk 用adb intall 安装 Releases android/user-interface-samples GitHubMultiple samples showing the best practices in the user interface on Android. - Releases android/u…...

Android音频采集
在 Android 开发领域,音频采集是一项非常重要且有趣的功能。它为各种应用程序,如语音聊天、音频录制、多媒体内容创作等提供了基础支持。今天我们就来深入探讨一下 Android 音频采集的两大类型:Mic 音频采集和系统音频采集。 1. Mic音频采集…...
通过轻易云平台实现聚水潭数据高效集成到MySQL的技术方案
聚水潭数据集成到MySQL的技术案例分享 在本次技术案例中,我们将详细探讨如何通过轻易云数据集成平台,将聚水潭的数据高效、可靠地集成到MySQL数据库中。具体方案为“聚水谭-店铺查询单-->BI斯莱蒙-店铺表”。这一过程不仅需要处理大量数据的快速写入…...

类和对象( 中 【补充】)
目录 一 . 赋值运算符重载 1.1 运算符重载 1.2 赋值运算符重载 1.3 日期类实现 1.3.1 比较日期的大小 : 1.3.2 日期天数 : 1.3.3 日期 - 天数 : 1.3.4 前置/后置 1.3.5 日期 - 日期 1.3.6 流插入 << 和 流提取 >> 二 . 取地址运算符重载 2.1 const…...
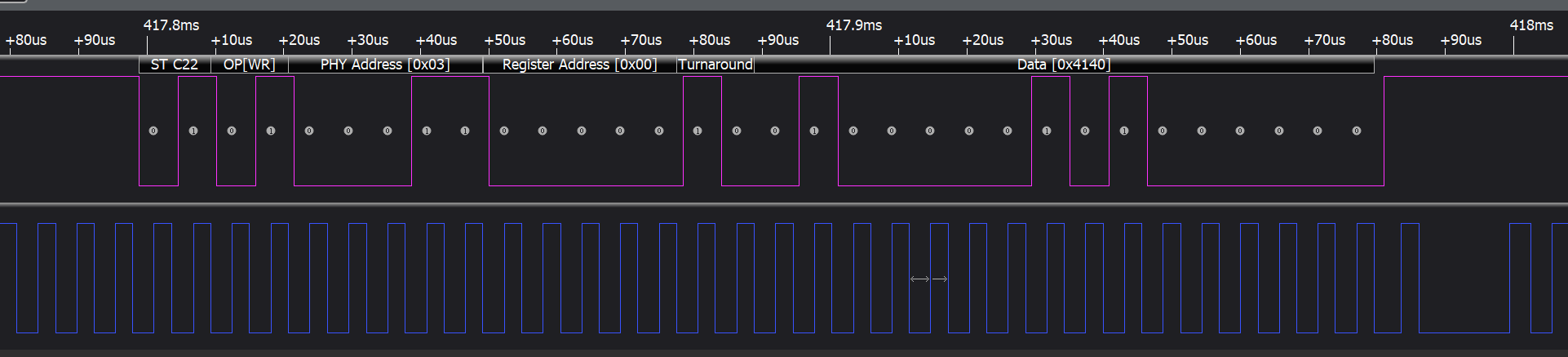
如何使用gpio模拟mdio通信?
一、前言 实际项目开发中,由于设计原因,会将phy的mdio引脚连接到SoC的2个空闲gpio上, 这样就无法通过Gmac自有的架构实现修改phy, 因此只能通过GPIO模拟的方式实现MDIO, 好在Linux支持MDIO via GPIO功能。 该功能…...

C# 中的事件和委托:构建响应式应用程序
C#中的事件和委托。事件和委托是C#中用于实现观察者模式和异步回调的重要机制,它们在构建响应式和交互式应用程序中发挥着重要作用。以下是一篇关于C#中事件和委托的文章。 引言 事件和委托是C#语言中非常重要的特性,它们允许你实现观察者模式和异步回…...

科技赋能健康:多商户Java版商城系统引领亚健康服务数字化变革
在当今社会,随着生活节奏的加快和工作压力的增大,越来越多的人处于亚健康状态。据《The Lancet》期刊2023年的统计数据显示,全球亚健康状态的人群比例已高达82.8%,这一数字背后,隐藏着巨大的健康风险和社会成本。亚健康…...
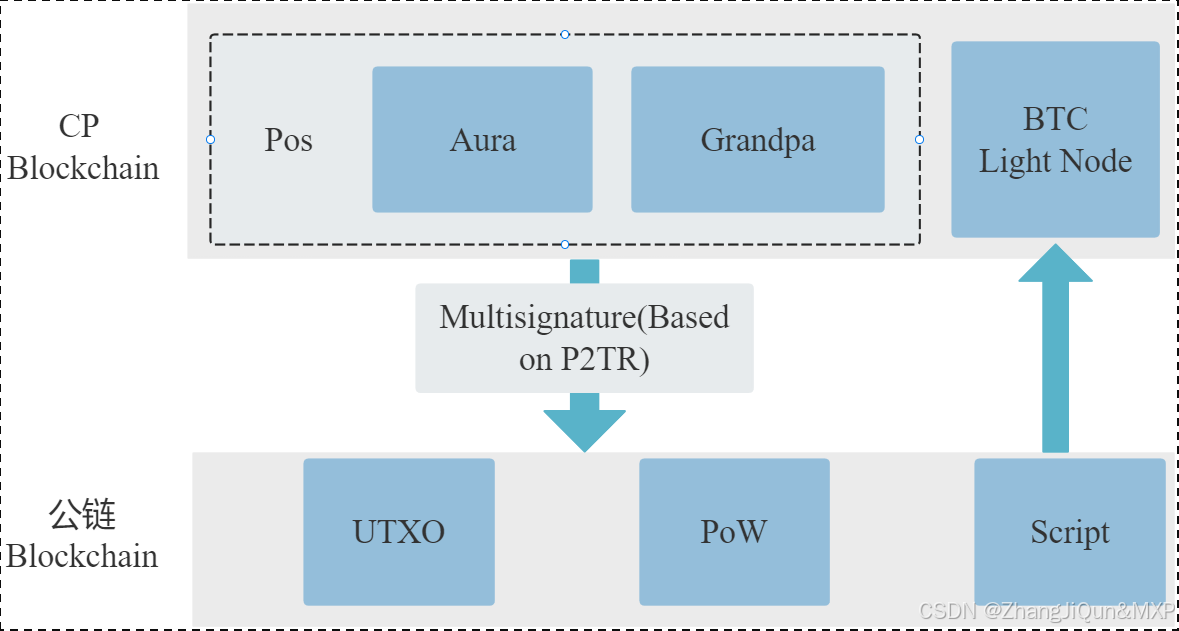
区块链网络示意图;Aura共识和Grandpa共识(BFT共识)
目录 区块链网络示意图 Aura共识和Grandpa共识(BFT共识) Aura共识 Grandpa共识(BFT共识) Aura与Grandpa的结合 区块链网络示意图 CP Blockchain:这是中央处理区块链(或可能指某种特定的处理单元区块链)的缩写。它可能代表了该区块链网络的主要处理或存储单元。在这…...
Javaweb梳理18——JavaScript
今日目标 掌握 JavaScript 的基础语法掌握 JavaScript 的常用对象(Array、String)能根据需求灵活运用定时器及通过 js 代码进行页面跳转能通过DOM 对象对标签进行常规操作掌握常用的事件能独立完成表单校验案例 18.1 JavaScript简介 JavaScript 是一门跨…...

面向对象-接口的使用
1. 接口的概述 为什么有接口? 借口是一种规则,对于继承而言,部分子类之间有共同的方法,为了约束方法的使用,使用接口。 接口的应用: 接口不是一类事物,它是对行为的抽象。 2. 接口的定义和使…...
)
失落的Apache JDBM(Java Database Management)
简介 Apache JDBM(Java Database Management)是一个轻量级的、基于 Java 的嵌入式数据库管理系统。它主要用于在 Java 应用程序中存储和管理数据。这个项目已经过时了,只是发表一下以示纪念,现在已经大多数被SQLite和Derby代替。…...
Vue3+SpringBoot3+Sa-Token+Redis+mysql8通用权限系统
sa-token支持分布式token 前后端代码,地球号: bright12389...

MySQL 三大日志详解
在 MySQL 数据库中,binlog(二进制日志)、redo log(重做日志)和 undo log(回滚日志)起着至关重要的作用。它们共同保障了数据库的高可用性、数据一致性和事务的可靠性。下面将对这三大日志进行详…...

AX-MES生产制造管理系统-总览
前言说起 MES 就不得不说 ERP,但是 ERP 大家基本上都知道,MES 就不一定了,常见的 ERP 系统包括 SAP、金蝶、用友等,ERP的流程相对来说也比较统一;MES就不同了,基本上熟悉业务流程的软件公司都可以开发并实施…...

多自由度冗余空间机械臂位姿一体化规划与控制【附代码】
✨ 长期致力于空间机械臂、对偶四元数、位姿一体化、路径规划、跟踪控制研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基于对偶四元数的冗余机械臂运…...

Python基础语法:访问器@property和修改器@xxx.setter
一、简介 访问器和修改器也是装饰器的一种。 property: 访问器,getter xxx.setter: 修改器,setter 访问器和修改器的根本目的是想将属性私有化,提供getter&setter去访问。 访问器和修改器能够做到访问属性其实在调用getter方法࿰…...

Unity UGUI轻量UI框架:200行代码实现零GC界面管理
1. 为什么还要自己手写UI框架?——当UGUI原生方案开始“卡脖子”很多人看到这个标题第一反应是:“都2024年了,还手写UI框架?Asset Store里几十个成熟方案,NGUI、FairyGUI、TextMeshPro配套的UI系统一抓一大把ÿ…...

Godot中型项目工程化实践:目录规范、资源引用与状态管理
1. 这不是续集,而是项目落地的分水岭“Godot 游戏引擎项目(二)”——看到这个标题,很多人第一反应是:“哦,上一篇讲了环境搭建和Hello World,这篇该讲节点树和信号了?”但我在带三个…...

量子计算中Loschmidt回声相位测量的创新方法
1. 量子计算中的Loschmidt回声相位测量方法概述Loschmidt回声是量子动力学中一个重要的概念,它描述了量子系统在时间反演演化后与初始状态的相似程度。在量子计算领域,精确测量Loschmidt回声的相位信息对于理解量子系统的非平衡态行为、计算能量本征值以…...

别再手动改路径了!用LabVIEW + MATLAB Script做自动化测试,这份环境配置指南让你效率翻倍
LabVIEW与MATLAB深度整合:构建自动化测试系统的工程实践指南在工业自动化与测试测量领域,LabVIEW和MATLAB的组合堪称黄金搭档。LabVIEW擅长硬件接口和实时控制,而MATLAB在算法开发和数据分析方面具有无可比拟的优势。本文将深入探讨如何将两者…...

照着用就行:2026 最新降AIGC软件测评与推荐
2026年真正好用的AI论文降重与改写工具,核心看降重效果、去AI味、格式保留、学术适配四大指标。综合实测,千笔AI、ThouPen、豆包、DeepSeek、Grammarly 是当前最值得推荐的梯队,覆盖从免费到付费、从中文到英文、从文科到理工的全场景需求。 …...

可解释AI新突破:基于局部帕累托最优的模型解释框架
1. 项目概述:当AI模型成为“黑箱”,我们如何撬开它?在机器学习项目里摸爬滚打十几年,我见过太多这样的场景:团队花大力气训练出一个准确率高达95%的复杂模型(比如深度神经网络),业务…...

Gazebo Sim多旋翼控制:四轴飞行器动力学建模与PID调参
Gazebo Sim多旋翼控制:四轴飞行器动力学建模与PID调参 【免费下载链接】gz-sim Open source robotics simulator. The latest version of Gazebo. 项目地址: https://gitcode.com/gh_mirrors/gz/gz-sim Gazebo Sim是一款功能强大的开源机器人模拟器ÿ…...