Kafka 数据倾斜:原因、影响与解决方案
Kafka:分布式消息系统的核心原理与安装部署-CSDN博客
自定义 Kafka 脚本 kf-use.sh 的解析与功能与应用示例-CSDN博客
Kafka 生产者全面解析:从基础原理到高级实践-CSDN博客
Kafka 生产者优化与数据处理经验-CSDN博客
Kafka 工作流程解析:从 Broker 工作原理、节点的服役、退役、副本的生成到数据存储与读写优化-CSDN博客
Kafka 消费者全面解析:原理、消费者 API 与Offset 位移-CSDN博客
Kafka 分区分配及再平衡策略深度解析与消费者事务和数据积压的简单介绍-CSDN博客
Kafka 数据倾斜:原因、影响与解决方案-CSDN博客
Kafka 核心要点解析_kafka mirrok-CSDN博客
Kafka 核心问题深度解析:全面理解分布式消息队列的关键要点_kafka队列日志-CSDN博客
目录
一、数据倾斜的概念
二、数据倾斜产生的原因
(一)生产者端原因
分区键(Partition Key)选择不当
消息发送不均匀
(二)消费者端原因
消费者处理能力差异
消费者数量与分区数量不匹配
三、数据倾斜带来的问题
(一)降低消费者处理效率
部分消费者过载
资源浪费
(二)影响数据准确性和完整性
数据处理不一致
数据丢失风险
四、数据倾斜的解决策略
(一)生产者端策略
优化分区键选择
自定义分区策略
(二)消费者端策略
动态调整消费者数量和分区分配
优化消费者处理逻辑
五、总结
在大数据处理领域,Kafka 作为一款高性能的分布式消息队列系统,被广泛应用于数据传输、实时流处理等场景。然而,在使用 Kafka 的过程中,数据倾斜问题可能会悄然出现,影响系统的性能和数据处理的准确性。本文将深入探讨 Kafka 数据倾斜的概念、产生原因、带来的问题以及相应的解决策略,帮助读者更好地应对这一挑战。
一、数据倾斜的概念
在 Kafka 环境中,数据倾斜是指数据在主题(Topic)的各个分区(Partition)之间分布不均匀的状况。理想情况下,分区设计期望数据能在各个分区均衡分布,如此一来,消费者组内的消费者便可均衡地从不同分区消费数据,从而充分利用系统资源实现高效并行处理。但当数据倾斜发生时,部分分区会承载大量数据,而其他分区的数据量则相对较少。
二、数据倾斜产生的原因
(一)生产者端原因
分区键(Partition Key)选择不当
当生产者向 Kafka 发送消息时,若分区策略基于分区键的哈希值确定消息所属分区,而分区键选择不合理,就可能引发数据倾斜。例如在电商系统中,若以商品类别作为分区键,某热门商品类别(如智能手机)的订单消息远超其他类别,对应分区的数据量就会远大于其他分区。
消息发送不均匀
生产者的业务逻辑可能导致消息发送不均匀。比如在数据采集系统中,某些数据源产生数据的频率远高于其他数据源,且未对数据进行合理分发处理,就会使数据集中发送到少数几个分区。
(二)消费者端原因
消费者处理能力差异
消费者组内各消费者处理能力不同。若部分消费者处理消息速度慢,而 Kafka 的分配策略未及时调整,就可能导致数据在某些分区堆积,产生数据倾斜。例如在复杂数据处理场景中,某些消费者需进行复杂计算或外部服务调用,导致处理速度下降,而其他消费者能快速处理消息,使得分配给处理速度慢的消费者的分区数据堆积。
消费者数量与分区数量不匹配
当消费者组内消费者数量与主题分区数量比例不合适时,也可能引发数据倾斜。比如消费者数量远少于分区数量,每个消费者可能分配到多个分区,若部分消费者因故障或性能问题无法正常消费分配的所有分区,就会导致这些分区的数据不能及时处理,出现数据倾斜。
三、数据倾斜带来的问题
(一)降低消费者处理效率
部分消费者过载
当某些分区数据量过大时,负责消费这些分区的消费者会承受较大负载,可能导致处理速度跟不上消息生产速度,出现消息积压,影响整个系统的实时性。例如在实时流数据处理系统中,数据倾斜可能使部分消费者需处理大量数据,无法及时完成处理,导致后续数据分析和决策环节延迟。
资源浪费
同时,其他消费者可能因分配到的数据量过少而处于空闲状态,造成系统资源浪费。例如在集群环境中,部分计算节点上的消费者因数据量少未充分利用计算资源,而其他节点上的消费者因数据过多性能下降。
(二)影响数据准确性和完整性
数据处理不一致
数据倾斜可能导致不同消费者处理的数据量差异过大,影响数据处理的一致性。例如在机器学习模型训练系统中,数据倾斜可能使部分模型使用的数据量远多于其他模型,导致模型训练结果出现偏差,影响数据准确性。
数据丢失风险
在极端情况下,当数据倾斜导致部分分区数据积压过多,而消费者又无法及时处理时,可能出现数据过期或被删除的情况,造成数据丢失,影响数据完整性。
四、数据倾斜的解决策略
(一)生产者端策略
优化分区键选择
重新评估分区键的选择,确保分区键能使数据均匀分布。如在电商系统中,可考虑使用订单 ID 作为分区键,而非商品类别,这样可使订单消息更均匀地分布在各个分区,避免因热门商品类别导致的数据倾斜。
自定义分区策略
除了默认分区策略,生产者可根据业务需求自定义分区策略。例如可根据数据的时间戳、地域等多种因素分配消息到不同分区,以实现数据的均衡分布。
(二)消费者端策略
动态调整消费者数量和分区分配
根据消费者处理能力和分区数据量,动态调整消费者数量和分区分配。例如当发现部分分区数据积压时,可增加消费者数量分担这些分区的消费任务。同时可使用 Kafka 提供的分区分配策略(如 Round - RobinAssignor、StickyAssignor 等)并根据实际情况优化,确保数据在消费者之间均衡分配。
优化消费者处理逻辑
对消费者处理逻辑进行优化,提高处理效率,减少因处理能力差异导致的数据倾斜。例如对处理速度较慢的消费者,可对其处理逻辑进行性能优化,如减少不必要的数据库查询、优化算法等,使其能更快地处理消息。
五、总结
Kafka 数据倾斜是在实际应用中可能遇到的重要问题,它会对系统性能、数据准确性和完整性产生多方面的负面影响。通过深入理解数据倾斜产生的原因,我们能够有针对性地采取生产者端和消费者端的策略来解决这一问题。在实际的 Kafka 应用开发和运维过程中,持续监控数据分布情况,及时发现并处理数据倾斜问题,对于构建高效、稳定、准确的数据处理系统至关重要。希望本文能为广大 Kafka 用户在应对数据倾斜问题时提供有益的参考和指导,让大家能够更好地发挥 Kafka 在大数据处理中的强大作用。
相关文章:

Kafka 数据倾斜:原因、影响与解决方案
Kafka:分布式消息系统的核心原理与安装部署-CSDN博客 自定义 Kafka 脚本 kf-use.sh 的解析与功能与应用示例-CSDN博客 Kafka 生产者全面解析:从基础原理到高级实践-CSDN博客 Kafka 生产者优化与数据处理经验-CSDN博客 Kafka 工作流程解析:…...
【从零开始的LeetCode-算法】3297. 统计重新排列后包含另一个字符串的子字符串数目 I
给你两个字符串 word1 和 word2 。 如果一个字符串 x 重新排列后,word2 是重排字符串的 前缀,那么我们称字符串 x 是 合法的 。 请你返回 word1 中 合法 子字符串的数目。 示例 1: 输入:word1 "bcca", word2 "…...

【2024APMCM亚太赛A题】完整参考论文与代码分享
A题 一、问题重述二、问题分析问题一:水下图像分类问题二:退化原因建模问题三:针对单一退化的图像增强方法问题四:复杂场景的综合增强模型问题五:针对性增强与综合增强的比较 三、问题假设退化特征独立性假设物理模型普…...
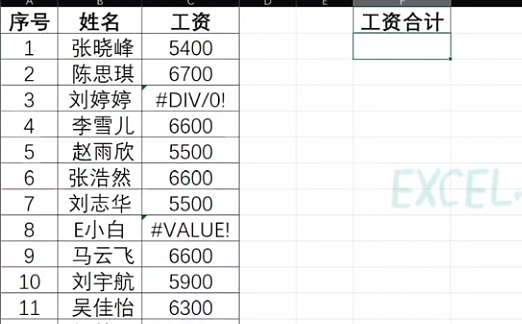
Excel求和如何过滤错误值
一、问题的提出 平时,我们在使用Excel时,最常用的功能就是求和了,一说到求和你可能想到用sum函数,但是如果sum的求和区域有#value #Div等错误值怎么办?如下图,记算C列中工资的总和。 直接用肯定会报错&…...

Android 常用命令和工具解析之GPU相关
目录 1、GPU基本信息 1.1 获取GPU基本信息 1.2 伪造GPU基本信息 2、GPU内存信息 3、经典案例 案例1:GPU伪造信息方案 案例2:GPU内存统计算法 GPU 指的是 Graphics Processing Unit,即图形处理单元。GPU 是一种专门用于处理图形和图像相…...

刷题——【模板】二维前缀和
前缀和 题目题目链接题解方法一方法二 题目 描述 给你一个 n 行 m 列的矩阵 A ,下标从1开始。 接下来有 q 次查询,每次查询输入 4 个参数 x1 , y1 , x2 , y2 请输出以 (x1, y1) 为左上角 , (x2,y2) 为右下角的子矩阵的和, 输入描述&#x…...

Xilinx 7 系列 FPGA的各引脚外围电路接法
Xilinx 7系列FPGA的外围电路接法涉及到多个方面,包括电源引脚、时钟输入引脚、FPGA配置引脚、JTAG调试引脚,以及其他辅助引脚。 本文参考资料: ds180 - 7 Series FPGAs Data Sheet - Overview ds181 - Artix 7 FPGAs Data Sheet - DC and AC…...
基础 | 目标网站)
Python 爬虫 (1)基础 | 目标网站
一、目标网站 1、加密网站 1.1、关键字比较明确 企名片:https://wx.qmpsee.com/articleDetail?idfeef62bfdac45a94b9cd89aed5c235be 1.2、关键字比较泛 烯牛数据:https://www.xiniudata.com/project/event/lib/invest...

数字后端零基础入门系列 | Innovus零基础LAB学习Day11(Function ECO流程)
###LAB 20 Engineering Change Orders (ECO) 这个章节的学习目标是学习数字IC后端实现innovus中的一种做function eco的flow。对于初学者,如果前面的lab还没掌握好的,可以直接跳过这节内容。有时间的同学,可以熟悉掌握下这个flow。 数字后端…...

量子卷积神经网络
量子神经网络由量子卷积层、量子池化层和量子全连接层组成 量子卷积层和量子池化层交替放置,分别实现特征提取和特征降维,之后通过量子全连接层进行特征综合 量子卷积层、量子池化层和量子全连接层分别由量子卷积单元、量子池化单元和量子全连接单元组…...
储能电站构成及控制原理
系列文章目录 能量管理系统(EMS)储能充放电策略 文章目录 系列文章目录一、储能电站构成二、储能系统关键部件及作用1.电池储能系统2.功率变换系统(Power Conversion System,PCS)3.变配电系统4.后台监控系统5.继电保护及安全自动装置 三、储能电站的功能四、储能电站控制策略 …...

Rocky Linux 系统安装/部署 Docker
1、下载docker-ce的repo文件 [rootlocalhost ~]# curl https://download.docker.com/linux/centos/docker-ce.repo -o /etc/yum.repos.d/docker.repo % Total % Received % Xferd Average Speed Time Time Time Current Dloa…...

12 —— Webpack中向前端注入环境变量
需求:开发模式下打印语句生效,生产模式下打印语句失效 使用Webpack内置的DefinePlugin插件 const webpack require(webpack) module.exports { plugins: [ new webpack.DefinePlugin({ process.env.NODE_ENV:JSON.stringify(process.env.NODE_ENV) }…...

uniapp接入BMapGL百度地图
下面代码兼容安卓APP和H5 百度地图官网:控制台 | 百度地图开放平台 应用类别选择《浏览器端》 /utils/map.js 需要设置你自己的key export function myBMapGL1() {return new Promise(function(resolve, reject) {if (typeof window.initMyBMapGL1 function) {r…...

外卖系统开发实战:从架构设计到代码实现
开发一套外卖系统,需要在架构设计、技术选型以及核心功能开发等方面下功夫。这篇文章将通过代码实例,展示如何构建一个基础的外卖系统,从需求梳理到核心模块的实现,帮助你快速掌握开发要点。 一、系统架构设计 一个完整的外卖系…...

神经网络反向传播算法公式推导
要推导反向传播算法,并了解每一层的参数梯度如何计算,以及每一层的梯度受到哪些值的影响,我们使用一个简单的神经网络结构: 输入层有2个节点一个有2个节点的隐藏层,激活函数是ReLU一个输出节点,激活函数是…...

Spark SQL 之 QueryStage
ExchangeQueryStageExec ExchangeQueryStageExec 分为两种...

【shodan】(三)vnc漏洞利用
shodan基础(三) 声明:该笔记为up主 泷羽的课程笔记,本节链接指路。 警告:本教程仅作学习用途,若有用于非法行为的,概不负责。 count count命令起到一个统计计数的作用。 用上节的漏洞指纹来试…...

每日OJ_牛客_游游的字母串_枚举_C++_Java
目录 牛客_游游的字母串_枚举 题目解析 C代码 Java代码 牛客_游游的字母串_枚举 游游的字母串 描述: 对于一个小写字母而言,游游可以通过一次操作把这个字母变成相邻的字母。a和b相邻,b和c相邻,以此类推。特殊的࿰…...

51c深度学习~合集8
我自己的原文哦~ https://blog.51cto.com/whaosoft/12491632 #patchmix 近期中南大学的几位研究者做了一项对比学习方面的工作——「Inter-Instance Similarity Modeling for Contrastive Learning」,主要用于解决现有对比学习方法在训练过程中忽略样本间相似关系…...

销售怎么通过各种方法获取电话号码
第一种就是那个用爬虫电话号码,然后再打电话给客户。第二种是在别人的挪车电话看车挪车电话,然后再打电话找客户。第三就是。扫楼一顿顿的扫,第四就是这个那种商店,一个个的去问陌拜地推一个个的问店子要不要贷款,去问…...

我靠这个测试设计方法,把漏测率降低了80%
当“直觉测试”撞上南墙很长一段时间里,我和许多测试同行一样,测试用例的设计主要依靠两样东西:需求文档和“测试直觉”。这种模式在业务逻辑相对简单、迭代速度平缓时还能勉强应付。一旦面对复杂的企业级应用、高频的敏捷迭代,或…...

Owl-Alpha 新手快速上手指南
在处理大规模数据或构建高性能应用时,我们常常会遇到一个棘手的问题:如何在不阻塞主线程的情况下,高效地执行耗时任务?无论是处理图像、解析大型文件,还是进行复杂的数学运算,传统的单线程模式往往会让界面…...
)
告别SVN恐惧症:美术策划也能轻松上手的Unity PlasticSCM极简入门(附团队项目拉取实战)
告别SVN恐惧症:美术策划也能轻松上手的Unity PlasticSCM极简入门(附团队项目拉取实战) 在游戏开发团队中,版本控制系统是协作的基石,但传统工具如SVN往往让非技术成员望而生畏。当美术资源频繁更新、策划案不断迭代时&…...

同步带装配工艺要点与损伤防控策略
一、引言在工业精密传动系统中,盖茨同步带凭借高精度、高效率、无滑差的优势,成为自动化设备、精密机床、输送产线的核心传动部件。多数企业在运维中,普遍将同步带异常磨损、断齿、断带等故障归咎于工况恶劣或产品质量问题,却忽略…...

通过Taotoken实现Hermes Agent自定义模型供应商接入
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken实现Hermes Agent自定义模型供应商接入 Hermes Agent是一个流行的AI智能体开发框架,它支持通过配置自定义…...

ComfyUI-WD14-Tagger:AI智能图像标签提取的终极完整指南
ComfyUI-WD14-Tagger:AI智能图像标签提取的终极完整指南 【免费下载链接】ComfyUI-WD14-Tagger A ComfyUI extension allowing for the interrogation of booru tags from images. 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-WD14-Tagger 在AI图像…...

如何用OpenHRMS打造企业级人力资源管理系统:30+模块完全指南
如何用OpenHRMS打造企业级人力资源管理系统:30模块完全指南 【免费下载链接】OpenHRMS 项目地址: https://gitcode.com/gh_mirrors/op/OpenHRMS 还在为繁琐的人力资源管理头疼吗?🤔 面对员工考勤、薪酬计算、绩效评估等复杂流程&…...

三分钟快速上手:FanControl让你的电脑风扇从此安静又高效
三分钟快速上手:FanControl让你的电脑风扇从此安静又高效 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending…...

“--glow”并不存在?!深度逆向Midjourney 6.1源码级辉光模拟协议,曝光官方刻意隐藏的4个隐式辉光增强开关
更多请点击: https://kaifayun.com 第一章:辉光效果的视觉本质与Midjourney 6.1协议悖论 辉光(Glow)并非物理光源的直接投射,而是人眼视网膜对高对比度边缘与饱和色域交界处产生的神经光学响应——一种由局部亮度梯度…...