Python操作neo4j库py2neo使用之创建和查询(二)
Python操作neo4j库py2neo使用之创建和查询(二)
py2neo 创建操作
1、连接数据库
from py2neo import Graph
graph = Graph("bolt://100.100.20.55:7687", auth=(user, pwd), name='neo4j')
2、创建Node
from py2neo import Node, Subgraph
# 创建单个节点
node = Node(label='公司',name='XX公司',创始人='XXX')
graph.node.create(node)
data = {"name": "XX公司","创始人": "XX"
}
node = Node(label='公司', **data)
graph.node.create(node)
# 创建多个节点
node1 = Node("Person", name="司马师", age=18)
node2 = Node("Person", name="司马懿", age=18)
node3 = Node("Person", name="司马昭", age=18)
nodes = Subgraph([node1, node2, node3])
self.graph.create(new_nodes)
# 批量创建节点, 注意只能创建同一label的节点
from py2neo.bulk import create_nodes
# 关键字参数
data = [{"name": "司马师", "age": 18},{"name": "司马懿", "age": 18},{"name": "司马昭", "age": 18, "职位": "大司马"}
]
create_nodes(graph.auto(), data, labels=("Person"))# 位置参数
data = [{"司马师", 18},{"司马懿", 18},{"司马昭", 18}
]create_nodes(graph.auto(), data, labels=("Person"), keys=["name", "age"])# 合并节点 根据name合并
node1 = Node("Person", name="司马师", age=18)graph.merge(node1, label='Person', "name")# 批量合并节点 根据name合并
from py2neo.bulk import merge_nodesdata = [{"name": "司马师", "age": 18},{"name": "司马懿", "age": 18},{"name": "司马昭", "age": 18}
]
merge_nodes(graph.auto(), data, labels=("Person", "name"))data = [{"司马师", 18},{"司马懿", 18},{"司马昭", 18}
]merge_nodes(graph.auto(), data, labels=("Person"), keys=["name", "age"])
py2neo 查询操作
1、连接数据库
from py2neo import Graph
graph = Graph("bolt://xx.xx.xx.xx:7687", auth=(user, pwd), name='neo4j')
2、查询节点
# 获取label为公司的单个节点
node = graph.nodes.match(label='公司').first()# 获取label为公司的所有节点
nodes = graph.nodes.match(label='公司').all()# 获取label为公司的10节点
nodes = graph.nodes.match(label='公司').limit(10)# 获取label为公司的10-20的节点
nodes = graph.nodes.match(label='公司').skip(10).limit(10)# 获取label为公司,属性name为''单个节点
node = graph.nodes.match(label='公司', name='XX公司').first()
3、查询关系
# 根据id获取关系
relationship = graph.relationships.get(1)# 获取关系为投资的单个关系
relationship = graph.match_one(r_type='投资')
relationship = graph.relationships.match(r_type='投资').first()# 获取关系为投资的所有关系
relationship = graph.relationships.match(r_type='投资').all()# 获取关系为投资的10关系
relationships = graph.match(r_type='投资', limit=10)# 获取关系为投资的10-20关系
relationship = graph.relationships.match(r_type='投资').skip(10).limit(10)# 获取节点为XX公司,关系为投资的第一个节点
node = graph.nodes.match(lable='公司', name='XX公司').first()
relationship = graph.relationships.match(node=node, r_type='投资').first()
4、查询高级方法
from py2neo import IS_NULL, IS_NOT_NULL, EQ, NE, LT, LE, GT, GE, STARTS_WIH, ENDS_WITH, CONTAINS, LIKE, IN, AND, OR, XOR# IS_NULL
# 获取label为公司的,名称为NULL的节点# IS_NOT_NULL# EQ# NE# LT# LE# GT# GE# STARTS_WIH# ENDS_WITH# CONTAINS# LIKE# IN
# 获取label为公司的,名称叫XX公司、aaa公司的公司
nodes = graph.nodes.match(label='公司', name = IN('XX公司', 'aaa公司')).all()# AND# OR# XOR# where
1
相关文章:
)
Python操作neo4j库py2neo使用之创建和查询(二)
Python操作neo4j库py2neo使用之创建和查询(二) py2neo 创建操作 1、连接数据库 from py2neo import Graph graph Graph("bolt://100.100.20.55:7687", auth(user, pwd), nameneo4j)2、创建Node from py2neo import Node, Subgraph # 创建…...

力扣11.23
1964. 找出到每个位置为止最长的有效障碍赛跑路线 你打算构建一些障碍赛跑路线。给你一个 下标从 0 开始 的整数数组 obstacles ,数组长度为 n ,其中 obstacles[i] 表示第 i 个障碍的高度。 对于每个介于 0 和 n - 1 之间(包含 0 和 n - 1&…...

golang实现TCP服务器与客户端的断线自动重连功能
1.服务端 2.客户端 生成服务端口程序: 生成客户端程序: 测试断线重连: 初始连接成功...

数据结构 (6)栈的应用举例
1. 递归调用 递归函数在执行时,会将每一层的函数调用信息(包括局部变量、参数和返回地址)存储在栈中。当递归函数返回时,这些信息会从栈中弹出,以便恢复之前的执行状态。栈的后进先出(LIFO)特性…...
)
谁的年龄最小(结构体专题)
题目描述 设计一个结构体类型,包含姓名、出生日期。其中出生日期又包含年、月、日三部分信息。输入n个好友的信息,输出年龄最小的好友的姓名和出生日期。 输入描述 首先输入一个整数n(1<n<10),表示好友人数,然后输入n行&…...

【论文笔记】LLaVA-KD: A Framework of Distilling Multimodal Large Language Models
Abstract 大语言模型(Large Language Models, LLM)的成功,使得研究者为了统一视觉和语言的理解去探索多模态大预言模型(Multimodal Large Language Models, MLLM)。 但是MLLM庞大的模型和复杂的计算使其很难应用在资源受限的环境,小型MLLM(s-MLLM)的表现…...

M|大脑越狱
rating: 7.0 豆瓣: 7.6 上映时间: “2015” 类型: M悬疑 导演: 约瑟夫怀特 Joseph White 主演: 亚历山大欧文 Alexander Owen爱德华富兰克林 Edward Franklin 国家/地区: 英国 片长/分钟: 20分钟 M|大脑越狱 想法不错,但是逻辑比较一般。属于…...
)
数据库编程(sqlite3)
一:数据库分类 常用的数据库 大型数据库 :Oracle商业、多平台、关系型数据库功能最强大、最复杂、市场占比最高的商业数据库 中型数据库 :Server是微软开发的数据库产品,主要支持windows平台 小型数据库 : mySQL是一个小型关系型…...

【C语言】关键字详解
【C语言】关键字详解 文章目录 [TOC](文章目录) 前言一、char1.定义字符串类型2.定义字符类型 二、short三、int四、long五、signed六、unsigned七、float八、double九、struct、union、enum十、void1.void用于函数声明,没有返回值的函数,其类型为 void。…...

什么是计算机网络
什么是计算机网络? 计算机网络的定义计算机网络的分类按覆盖范围分类按拓扑结构分类按通信传输介质分类按信号频带占用方式分类 计算机网络的功能信息交换资源共享分布式处理 计算机网络的组成计算机网络的定义计算机网络的分类按覆盖范围分类按拓扑结构分类按通信传…...

【大数据学习 | Spark-Core】Spark的分区器(HashPartitioner和RangePartitioner)
之前学过的kv类型上面的算子 groupby groupByKey reduceBykey sortBy sortByKey join[cogroup left inner right] shuffle的 mapValues keys values flatMapValues 普通算子,管道形式的算子 shuffle的过程是因为数据产生了打乱重分,分组、排序、join等…...
)
CSS3_BFC(十二)
BFC MDN对BFC的解释:块格式化上下文(Block Formating Context, BFC)是web页面的可视CSS渲染的一部分,是块盒子的布局过程发生的区域,也是浮动元素与其他元素交互的区域。 1、开启BFC flow-root对内容的影响是最低的&am…...

C0032.在Clion中使用MSVC编译器编译opencv的配置方法
使用MSVC编译器编译opencv的配置方法...

微信小程序中会议列表页面的前后端实现
题外话:想通过集成腾讯IM来解决即时聊天的问题,如果含语音视频,腾讯组件一年5万起步,贵了!后面我们改为自己实现这个功能,这里只是个总结而已。 图文会诊需求 首先是个图文列表界面 同个界面可以查看具体…...

WEB攻防-通用漏洞文件上传二次渲染.htaccess变异免杀
知识点: 1、文件上传-二次渲染 2、文件上传-简单免杀变异 3、文件上传-.htaccess妙用 4、文件上传-PHP语言特性 1、上传后门时,文件内容带.就不行 这时可以上传一个转换后的ip地址,ip地址对应网站包含后门代码 转换后的int会在访问的时候…...

vue实现列表滑动下拉加载数据
一、实现效果 二、实现思路 使用滚动事件监听器来检测用户是否滚动到底部,然后加载更多数据 监听滚动事件。检测用户是否滚动到底部。加载更多数据。 三、案例代码 <div class"drawer-content"><div ref"loadMoreTrigger" class&q…...

全面解析:HTML页面的加载全过程(四)--浏览器渲染之样式计算
主线程遍历得到的 DOM 树,依次为树中的每个节点计算出它最终的样式,称之为 Computed Style。 通过前面生成的DOM 树和 CSSOM 树,遍历 DOM 树,为每一个 DOM 节点,计算它的所有 CSS 属性,最后会得到一棵带有…...

#Verilog HDL# 谈谈代码中如何跨层次引用
目录 一 先谈作用问题 二 再谈跨层次问题 2.1 向下引用 2.2 向上引用 一 先谈作用问题 大多数编程语言都有一个称为作用域(scope)的特征,它定义了代码的某些部分对于变量和方法的可见性。作用域定义了一个命名空间,以避免同一命名空间内不同对象名称之间的冲突。 V…...

LeetCode 每日一题 2024/11/18-2024/11/24
记录了初步解题思路 以及本地实现代码;并不一定为最优 也希望大家能一起探讨 一起进步 目录 11/18 661. 图片平滑器11/19 3243. 新增道路查询后的最短距离 I11/20 3244. 新增道路查询后的最短距离 II11/21 3248. 矩阵中的蛇11/22 3233. 统计不是特殊数字的数字数量1…...
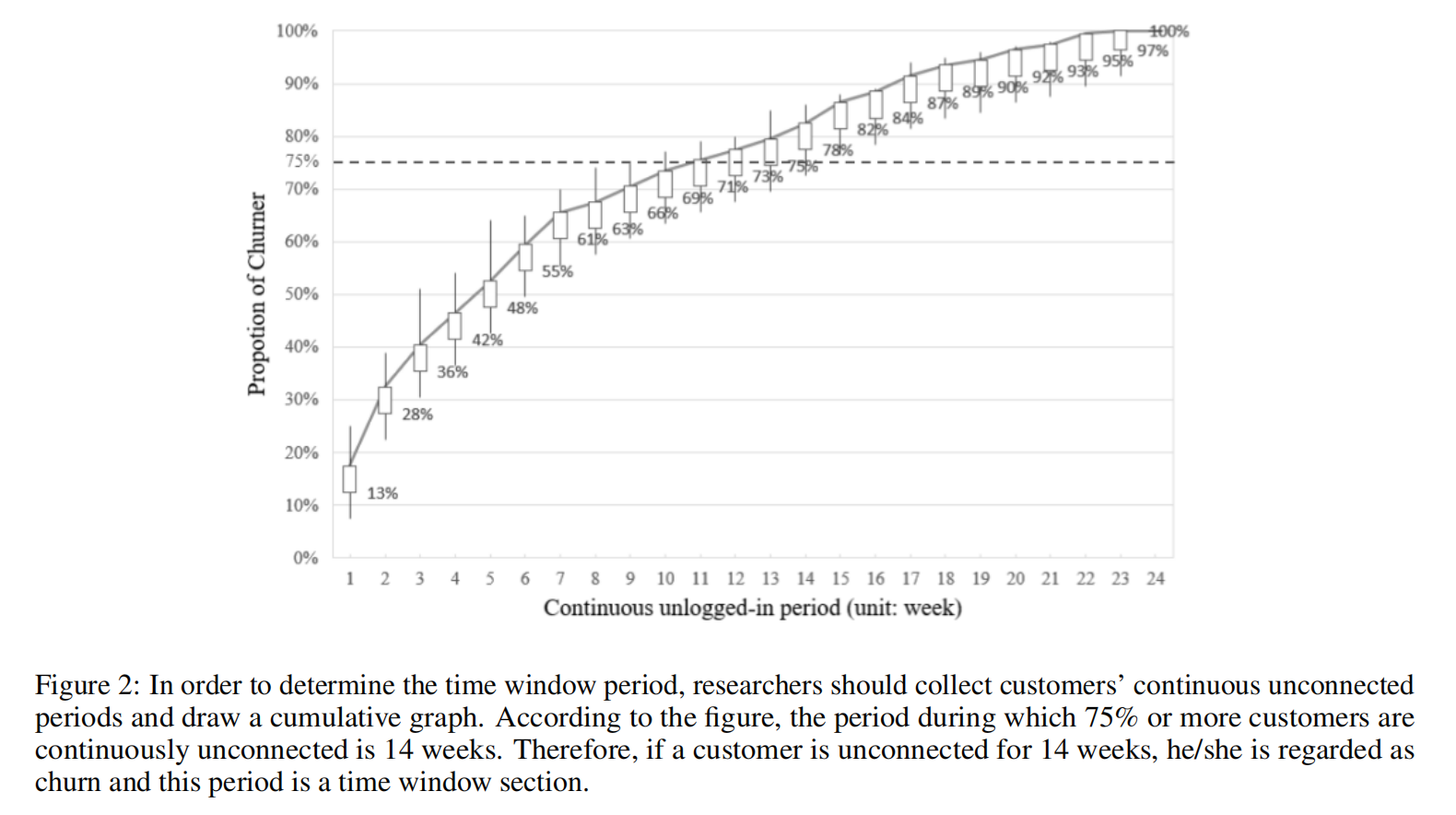
客户流失分析综述
引言 客户流失这个术语通常用来描述在特定时间或合同期内停止与公司进行业务往来的客户倾向性[1]。传统上,关于客户流失的研究始于客户关系管理(CRM)[2]。在运营服务时,防止客户流失至关重要。过去,客户获取相对于流失…...

如何快速上手DeepPurpose?5分钟完成你的第一个药物-靶点相互作用预测模型
如何快速上手DeepPurpose?5分钟完成你的第一个药物-靶点相互作用预测模型 【免费下载链接】DeepPurpose A Deep Learning Toolkit for DTI, Drug Property, PPI, DDI, Protein Function Prediction (Bioinformatics) 项目地址: https://gitcode.com/gh_mirrors/de…...

榨干Codex!OpenAI工程师亲授Codex真正用法
你可能把 Codex 当编程助手用,改改代码,跑跑测试。但它的能力远不止于此。OpenAI 的客户支持工程师 Jason(jxnlco)告诉你,Codex 其实是一套完整的电脑工作系统,从语音输入到自动化,从浏览器操控…...

基于STM32与LoRa的低功耗物联网气象站DIY全攻略
1. 项目概述:打造一个低功耗的家庭气象站前阵子想给家里的智能家居系统加点“环境感知”能力,琢磨着搞个能实时监测室外温湿度、风速风向的小玩意儿。市面上成品气象站要么数据出不来,要么功耗感人,不适合长期户外部署。于是&…...

基于Cynthion逆向USB协议,为DP100电源开发Linux控制软件
1. 项目概述:用Cynthion嗅探USB,为DP100电源打造Linux软件作为一名长期在Linux环境下折腾硬件和嵌入式开发的爱好者,我经常遇到一个头疼的问题:很多不错的桌面小设备,比如电源、示波器、逻辑分析仪,它们的官…...

学了几天 Web 安全,终于搞懂什么是 XSS 了
xss的详细介绍最近开始正式学习 Web 安全。前面陆续学了:HTTPCookieSessionJWT RBAC然后发现很多地方都会提到一个东西:XSS以前一直感觉这个漏洞很抽象。网上很多文章一上来就是:<script>alert(1)</script>然后说:“弹…...

正视孩童情绪波动,耐心陪伴平稳疏导
孩子的情绪就像夏天的天气,前一秒还晴空万里,后一秒可能就乌云密布。面对突如其来的哭闹、发脾气或者闷闷不乐,很多家长会急着“灭火”——要么讲道理,要么直接制止。但其实,情绪波动本身不是问题,它是孩子…...

Python-for-Android 完整指南:5分钟将Python应用打包为Android APK
Python-for-Android 完整指南:5分钟将Python应用打包为Android APK 【免费下载链接】python-for-android Turn your Python application into an Android APK 项目地址: https://gitcode.com/gh_mirrors/py/python-for-android Python-for-Android࿰…...

Hermes Agent工具如何自定义接入Taotoken提供商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Hermes Agent工具如何自定义接入Taotoken提供商 Hermes Agent 是一款功能强大的AI智能体开发框架,它支持通过自定义提供…...

智能烹饪助手:基于传感器融合与AI的厨房自动化实践
1. 项目概述:一个让厨房小白也能自信下厨的智能伙伴每次站在灶台前,你是不是也经历过这样的场景:一边手忙脚乱地翻着菜谱,一边担心锅里的菜是不是快糊了,还要分心去计算各种调料该放多少?对于很多刚接触烹饪…...

3大突破性功能:用HiveWE革新你的魔兽争霸III地图创作体验
3大突破性功能:用HiveWE革新你的魔兽争霸III地图创作体验 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为传统魔兽争霸III编辑器缓慢的加载速度和复杂的操作界面而烦恼吗?Hive…...