Python网络爬虫基础
Python网络爬虫是一种自动化工具,用于从互联网上抓取信息。它通过模拟人类浏览网页的行为,自动地访问网站并提取所需的数据。网络爬虫在数据挖掘、搜索引擎优化、市场研究等多个领域都有广泛的应用。以下是Python网络爬虫的一些基本概念:
1. 发送请求 (Request)
使用 requests 库
requests 是一个非常流行的 HTTP 客户端库,使用简单且功能强大。
import requestsurl = 'https://example.com'
response = requests.get(url)
print(response.text) # 打印网页内容
设置请求头 (Headers)
为了模拟浏览器行为,通常需要设置 User-Agent 和其他请求头。
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
response = requests.get(url, headers=headers)
2. 处理响应 (Response)
状态码 (Status Code)
检查响应的状态码以确保请求成功。
if response.status_code == 200:print('请求成功')
else:print(f'请求失败,状态码: {response.status_code}')
获取内容 (Content)
可以从响应对象中获取文本内容、二进制内容等。
html_content = response.text # 获取文本内容
binary_content = response.content # 获取二进制内容
3. 解析 HTML (Parsing)
使用 BeautifulSoup
BeautifulSoup 是一个强大的 HTML 解析库,可以方便地从 HTML 中提取数据。
from bs4 import BeautifulSoupsoup = BeautifulSoup(html_content, 'html.parser')
title = soup.title.string # 获取标题
print(title)
使用 lxml
lxml 是另一个高效的 XML 和 HTML 解析库,支持 XPath 表达式。
from lxml import etreehtml = etree.HTML(html_content)
title = html.xpath('//title/text()')[0] # 使用 XPath 获取标题
print(title)
4. 数据存储 (Storage)
写入文件
将提取的数据写入文件,例如 CSV 文件。
import csvdata = [['Name', 'Age'],['Alice', 30],['Bob', 25]
]with open('data.csv', 'w', newline='', encoding='utf-8') as file:writer = csv.writer(file)writer.writerows(data)
存储到数据库
将数据存储到关系型数据库(如 MySQL)或 NoSQL 数据库(如 MongoDB)。
import sqlite3# 连接到 SQLite 数据库
conn = sqlite3.connect('example.db')
cursor = conn.cursor()# 创建表
cursor.execute('''CREATE TABLE IF NOT EXISTS users (name TEXT, age INTEGER)''')# 插入数据
cursor.execute("INSERT INTO users (name, age) VALUES (?, ?)", ('Alice', 30))
cursor.execute("INSERT INTO users (name, age) VALUES (?, ?)", ('Bob', 25))# 提交事务
conn.commit()# 关闭连接
conn.close()
5. 用户代理 (User-Agent)
设置 User-Agent 可以模拟不同浏览器的行为,避免被网站识别为爬虫。
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
response = requests.get(url, headers=headers)
6. 遵守 Robots 协议
检查网站的 robots.txt 文件,确保爬虫行为符合网站的规定。
import requestsurl = 'https://example.com/robots.txt'
response = requests.get(url)
print(response.text)
7. 异常处理 (Error Handling)
处理网络请求中的各种异常,确保爬虫的稳定性。
try:response = requests.get(url, timeout=10)response.raise_for_status() # 如果响应状态码不是 200,抛出异常
except requests.exceptions.RequestException as e:print(f'请求失败: {e}')
8. 反爬策略
设置请求间隔
避免频繁请求导致被封禁。
import timefor i in range(10):response = requests.get(url, headers=headers)# 处理响应time.sleep(1) # 每次请求间隔 1 秒
使用代理 IP
使用代理 IP 可以绕过 IP 封禁。
proxies = {'http': 'http://123.45.67.89:8080','https': 'https://123.45.67.89:8080'
}
response = requests.get(url, headers=headers, proxies=proxies)
9. 法律与道德
尊重版权
不要侵犯他人的版权,合法使用数据。
保护隐私
不要收集和使用个人敏感信息,遵守相关法律法规。
合法用途
确保爬虫的用途是合法的,不用于非法活动。
总结
以上是 Python 网络爬虫的一些基本概念和技术细节。通过这些知识,你可以构建一个功能完善的网络爬虫。当然,实际应用中可能会遇到更多复杂的情况,需要不断学习和实践来提升技能。
相关文章:

Python网络爬虫基础
Python网络爬虫是一种自动化工具,用于从互联网上抓取信息。它通过模拟人类浏览网页的行为,自动地访问网站并提取所需的数据。网络爬虫在数据挖掘、搜索引擎优化、市场研究等多个领域都有广泛的应用。以下是Python网络爬虫的一些基本概念: 1.…...

每天五分钟机器学习:支持向量机数学基础之超平面分离定理
本文重点 超平面分离定理(Separating Hyperplane Theorem)是数学和机器学习领域中的一个重要概念,特别是在凸集理论和最优化理论中有着广泛的应用。该定理表明,在特定的条件下,两个不相交的凸集总可以用一个超平面进行分离。 定义与表述 超平面分离定理(Separating Hy…...

TCP/IP网络协议栈
TCP/IP网络协议栈是一个分层的网络模型,用于在互联网和其他网络中传输数据。它由几个关键的协议层组成,每一层负责特定的功能。以下是对TCP/IP协议栈的简要介绍: TCP/IP协议模型的分层 1. 应用层(Application Layer)…...

利用编程思维做题之最小堆选出最大的前10个整数
1. 理解问题 我们需要设计一个程序,读取 80,000 个无序的整数,并将它们存储在顺序表(数组)中。然后从这些整数中选出最大的前 10 个整数,并打印它们。要求我们使用时间复杂度最低的算法。 由于数据量很大,直…...

详解MVC架构与三层架构以及DO、VO、DTO、BO、PO | SpringBoot基础概念
🙋大家好!我是毛毛张! 🌈个人首页: 神马都会亿点点的毛毛张 今天毛毛张分享的是SpeingBoot框架学习中的一些基础概念性的东西:MVC结构、三层架构、POJO、Entity、PO、VO、DO、BO、DTO、DAO 文章目录 1.架构1.1 基本…...

Unity C# 影响性能的坑点
c用的时间长了怕unity的坑忘了,记录一下。 GetComponent最好使用GetComponent<T>()的形式, 继承自Monobehaviour的函数要避免空的Awake()、Start()、Update()、FixedUpdate().这些空回调会造成性能浪费 GetComponent方法最好避免在Update当中使用…...

工作学习:切换git账号
概括 最近工作用的git账号下发下来了,需要切换一下使用的账号。因为是第一次弄,不熟悉,现在记录一下。 打开设置 路径–git—git remotes,我这里选择项是Manage Remotes,点进去就可以了。 之后会出现一个输入框&am…...
)
量化交易系统开发-实时行情自动化交易-8.量化交易服务平台(一)
19年创业做过一年的量化交易但没有成功,作为交易系统的开发人员积累了一些经验,最近想重新研究交易系统,一边整理一边写出来一些思考供大家参考,也希望跟做量化的朋友有更多的交流和合作。 接下来会对于收集整理的33个量化交易服…...

Scala习题
姓名,语文,数学,英语 张伟,87,92,88 李娜,90,85,95 王强,78,90,82 赵敏,92,88,91 孙涛,…...

结构方程模型(SEM)入门到精通:lavaan VS piecewiseSEM、全局估计/局域估计;潜变量分析、复合变量分析、贝叶斯SEM在生态学领域应用
目录 第一章 夯实基础 R/Rstudio简介及入门 第二章 结构方程模型(SEM)介绍 第三章 R语言SEM分析入门:lavaan VS piecewiseSEM 第四章 SEM全局估计(lavaan)在生态学领域高阶应用 第五章 SEM潜变量分析在生态学领域…...

OpenCV图像基础处理:通道分离与灰度转换
在计算机视觉处理中,理解图像的颜色通道和灰度表示是非常重要的基础知识。今天我们通过Python和OpenCV来探索图像的基本组成。 ## 1. 图像的基本组成 在数字图像处理中,彩色图像通常由三个基本颜色通道组成: - 蓝色(Blue&#x…...

C++ 类和对象(类型转换、static成员)
目录 一、前言 二、正文 1.隐式类型转换 1.1隐式类型转换的使用 2.static成员 2.1 static 成员的使用 2.1.1static修辞成员变量 2.1.2 static修辞成员函数 三、结语 一、前言 大家好,我们又见面了。昨天我们已经分享了初始化列表:https://blog.c…...
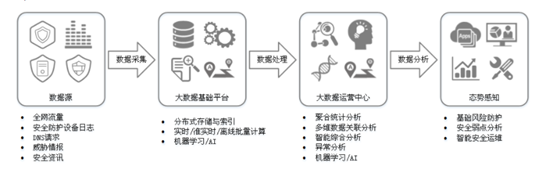
【网络安全设备系列】12、态势感知
0x00 定义: 态势感知(Situation Awareness,SA)能够检测出超过20大类的云上安全风险,包括DDoS攻击、暴力破解、Web攻击、后门木马、僵尸主机、异常行为、漏洞攻击、命令与控制等。利用大数据分析技术,态势感…...

Linux介绍与安装指南:从入门到精通
1. Linux简介 1.1 什么是Linux? Linux是一种基于Unix的操作系统,由Linus Torvalds于1991年首次发布。Linux的核心(Kernel)是开源的,允许任何人自由使用、修改和分发。Linux操作系统通常包括Linux内核、GNU工具集、图…...

BGE-M3模型结合Milvus向量数据库强强联合实现混合检索
在基于生成式人工智能的应用开发中,通过关键词或语义匹配的方式对用户提问意图进行识别是一个很重要的步骤,因为识别的精准与否会影响后续大语言模型能否检索出合适的内容作为推理的上下文信息(或选择合适的工具)以给出用户最符合…...
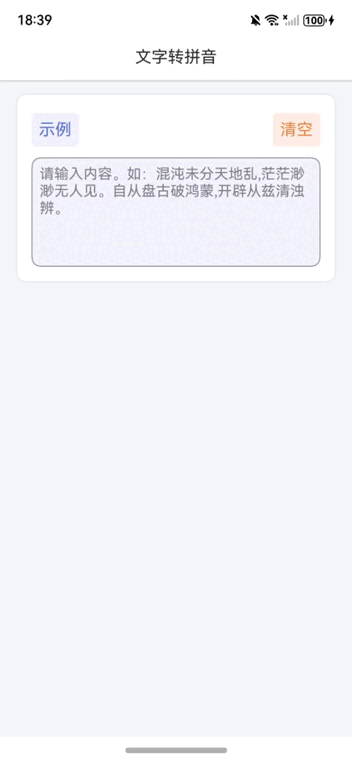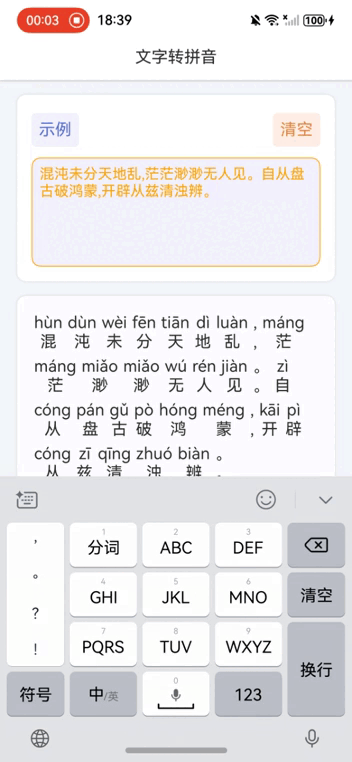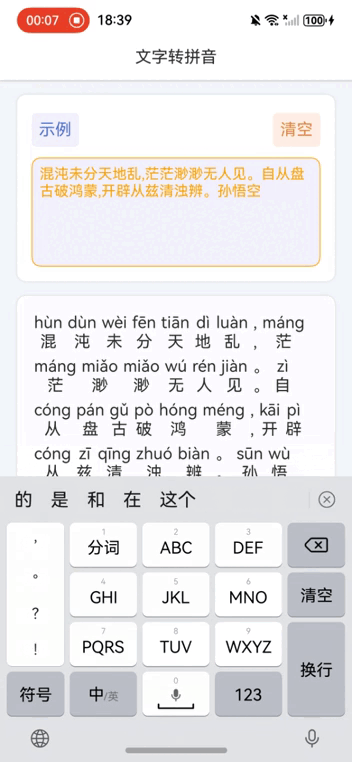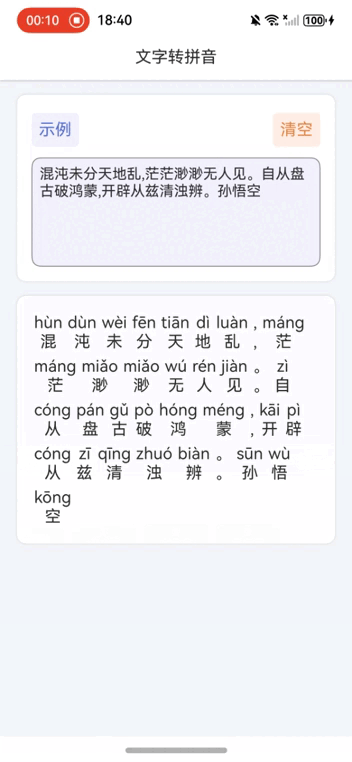
鸿蒙NEXT开发案例:文字转拼音
【引言】 在鸿蒙NEXT开发中,文字转拼音是一个常见的需求,本文将介绍如何利用鸿蒙系统和pinyin-pro库实现文字转拼音的功能。 【环境准备】 • 操作系统:Windows 10 • 开发工具:DevEco Studio NEXT Beta1 Build Version: 5.0.…...
)
CTF之密码学(栅栏加密)
栅栏密码是古典密码的一种,其原理是将一组要加密的明文划分为n个一组(n通常根据加密需求确定,且一般不会太大,以保证密码的复杂性和安全性),然后取每个组的第一个字符(有时也涉及取其他位置的字…...

修改插槽样式,el-input 插槽 append 的样式
需缩少插槽 append 的 宽度 方法1、使用内联样式直接修改,指定 width 为 30px <el-input v-model"props.applyBasicInfo.outerApplyId" :disabled"props.operateCommandType input-modify"><template #append><el-button click…...

UPLOAD LABS | PASS 01 - 绕过前端 JS 限制
关注这个靶场的其它相关笔记:UPLOAD LABS —— 靶场笔记合集-CSDN博客 0x01:过关流程 本关的目标是上传一个 WebShell 到目标服务器上,并成功访问: 我们直接尝试上传后缀为 .php 的一句话木马: 如上,靶场弹…...

【css实现收货地址下边的平行四边形彩色线条】
废话不多说,直接上代码: <div class"address-block" ><!-- 其他内容... --><div class"checked-ar"></div> </div> .address-block{height:120px;position: relative;overflow: hidden;width: 500p…...

魔兽争霸3终极优化指南:12个免费插件让你的经典游戏焕发新生
魔兽争霸3终极优化指南:12个免费插件让你的经典游戏焕发新生 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸3在现代电脑上…...

告别IDEA编译警告:深入解析JDK版本过时问题与多维度解决方案
1. 当IDEA开始"抱怨":那些烦人的编译警告从哪来? 每次打开老项目,总能看到那个熟悉的黄色警告:"Warning:java: 源值1.5已过时,将在未来所有发行版中删除"。这个提示就像个唠叨的老朋友,…...

YouTube 转 MP3 工具里,为什么预览要放在下载前
很多转换工具看起来解决的是“我要一个 MP3 文件”,但真正影响体验的,往往不是页面上有没有下载按钮。 用户真正想确认的是:这个链接是不是被正确识别了,转换任务是不是还在进行,最后得到的音频是不是值得保存。对 Yo…...

何为可编程控制器?可编程控制器4大内容介绍
可编程控制器在控制中常为使用,因此本文将从4大方面对可编程控制器予以介绍,以增进大家对可编程控制器的了解。这4大方面包括:1.何为可编程控制器?2. 可编程控制器的基本组成,3. 可编程控制器发展史,以及4. 可编程控制…...

Cesium三维地形剖切与开挖:从原理到可复用组件封装
1. 为什么需要地形剖切与开挖功能? 在三维地理信息系统中,地形剖切与开挖是最常用的分析功能之一。想象一下,你正在规划一条地下隧道,或者需要分析某处地质构造,这时候如果能把地表"切开"查看内部情况&#…...

PyTorch数据集加载进阶:除了CIFAR10,你的自定义数据该怎么准备?
PyTorch数据集加载进阶:从CIFAR10到自定义数据的深度实践 在深度学习项目中,数据准备往往比模型构建更耗时。许多开发者能熟练使用torchvision.datasets加载标准数据集,却对自定义数据束手无策。本文将带你深入PyTorch数据加载机制ÿ…...

如何快速导出API账单数据?New API 数据导出功能完整指南
如何快速导出API账单数据?New API 数据导出功能完整指南 【免费下载链接】new-api A unified AI model hub for aggregation & distribution. It supports cross-converting various LLMs into OpenAI-compatible, Claude-compatible, or Gemini-compatible for…...

从 AI 电影到小说:《凰标》延续《第一大道》的东方梦@凤凰标志
科技为翼,文脉为魂; 大道开路,凰标定局。一、时代之问:当AI沦为流量收割机,谁来守护东方文脉? AI 正以惊人的速度渗透文娱产业,却多数被资本用作「快餐内容」的流水线。 海棠山铁哥反其道而行—…...

2026十大建议考的经济学专业证书有哪些
2026年十大经济学专业证书推荐经济学专业证书能够提升职业竞争力,尤其在数据分析、金融和经济预测领域。以下是2026年值得考取的十大经济学专业证书,包括CDA数据分析师证书等热门选择。1. CDA数据分析师证书CDA数据分析师证书是数据分析领域的权威认证&a…...

运维实战:ESXi主机物理网卡闪断致部分VM网络中断的排查与应急恢复
1. 故障现象与初步判断 那天凌晨2点15分,值班手机突然响起刺耳的告警声。监控系统显示,ESXi主机上的三台关键业务虚拟机网络连接中断,而其他虚拟机却运行正常。这种部分VM断网的情况立刻引起了我的警觉——这通常意味着问题出在物理层而非虚拟…...