Kubernetes集群操作
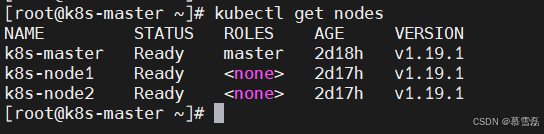
查看集群信息:
kubectl get nodes
删除节点
(⽆效且显示的也可以删除)
后期如果 要删除某个节点,为了不增加其他节点的访问压力,先增加一个节点,再删除要删除的节点
语法 :kubect delete node 节点名

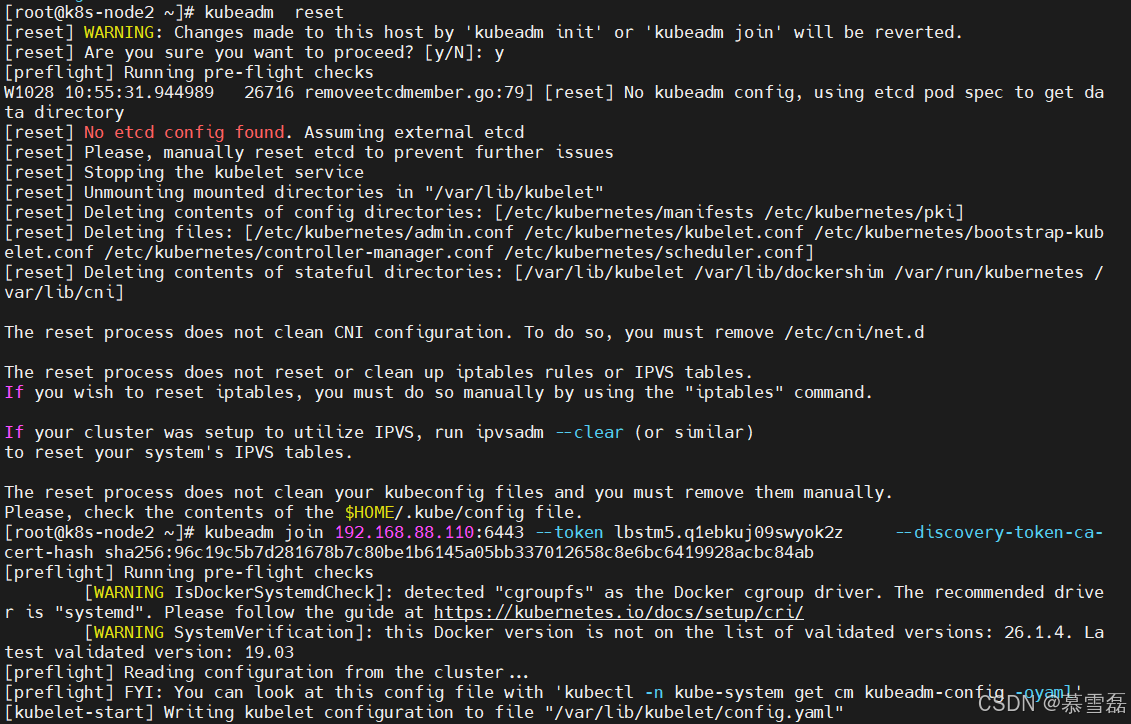
如果删除后,该节点需要再次加入集群,在master重置token,打印加入的命令
kubeadm token create --print-join-command

拿着打印的命令,再要加入的node节点执行
kubeadm reset
kubeadm join 192.168.88.110:6443 --token lbstm5.q1ebkuj09swyok2z --discovery-token-ca-cert-hash sha256:96c19c5b7d281678b7c80be1b6145a05bb337012658c8e6bc6419928acbc84ab
单独查看某⼀个节点
(节点名称可以用空格隔开写多个)
kubectl get node k8s-node1

使用 kubectl describe 命令,查看⼀个 API 对象的详细信息:
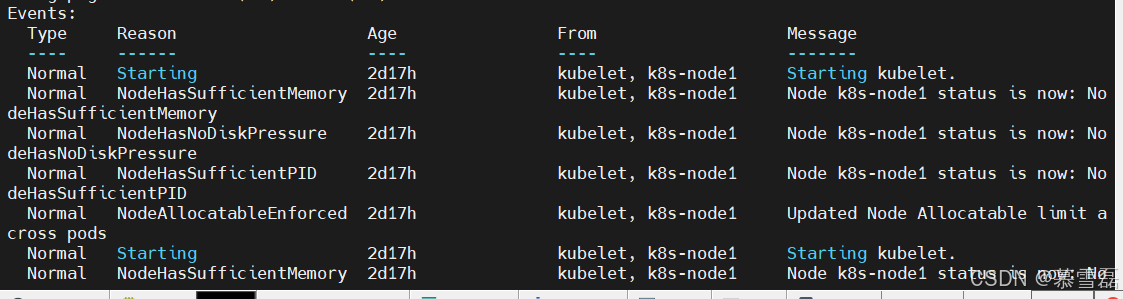
注意:Events(事件) 值得你特别关注
在 Kubernetes 执⾏的过程中,对 API 对象的所有重要操作,都会被记录在这个对象的 Events ⾥,并且显示在 kubectl describe 指令返回的结果中。
这个部分正是我们将来进⾏ Debug 的重要依据。如果有异常发⽣,⼀定要第⼀时间查看这些 Events,往往可以看到⾮常详细的错误信息。
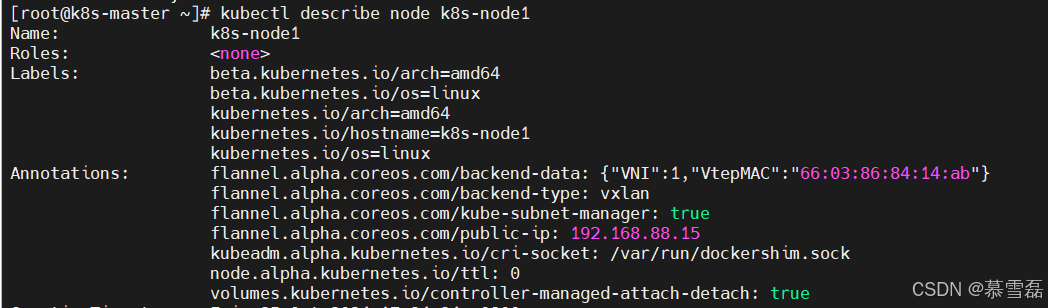
查看node的详细信息
kubectl describe node k8s-node1

#注意:最后被查看的节点名称只能用get nodes⾥⾯查到的name!
cpuRequests: 200m (10%) — 表示容器请求的 CPU 资源为 200 毫核(milli-cores),即 0.2 个核心,占据了总 CPU 资源的 10%。
Limits: 100m (5%) — 表示容器的 CPU 限制为 100 毫核,即 0.1 个核心,占据了总 CPU 资源的 5%。
memoryRequests: 100Mi (2%) — 表示容器请求的内存资源为 100 MiB,占据了总内存资源的 2%。
Limits: 50Mi (1%) — 表示容器的内存限制为 50 MiB,占据了总内存资源的 1%。
ephemeral-storageRequests: 0 (0%) — 表示容器请求的临时存储资源为 0。
Limits: 0 (0%) — 表示容器的临时存储限制为 0。
hugepages-1Gi解释
Requests 是容器启动时 Kubernetes 调度器用来决定节点上可用资源的基础。它代表了容器正常运行所需的最低资源量。
Limits 是容器可以使用的最大资源量。超出这个限制,容器可能会被限制或终止。
查看各组件信息:

NAME: kubernetes — 这是服务的名称。
TYPE: ClusterIP — 这是服务的类型。ClusterIP 类型的服务只能在集群内部访问,无法从外部直接访问。
CLUSTER-IP: 10.96.0.1 — 这是服务在集群内部的虚拟 IP 地址。它用于将流量路由到服务后端的 Pods。
EXTERNAL-IP: <none> — 这个字段显示为 <none>,意味着该服务没有配置外部 IP,也就是说,外部网络不能直接访问这个服务。ClusterIP 类型的服务默认没有外部 IP。
PORT(S): 443/TCP — 这是服务监听的端口和协议。这里是 TCP 协议的 443 端口。
AGE: 19h — 这是服务创建的时间,从创建到现在已经过去了 19 小时。
在不同的namespace⾥⾯查看service:
在不同的namespace⾥⾯查看service:
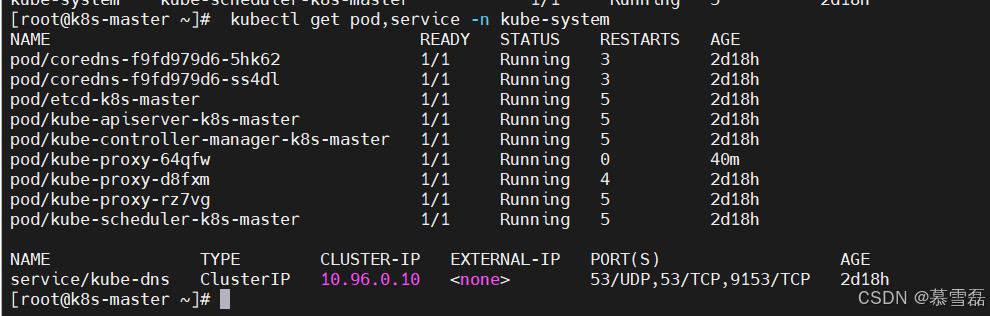
[root@kub-k8s-master ~]# kubectl get service -n kube-system
-n:namespace名称空间查看所有名称空间内的资源:
[root@kub-k8s-master ~]# kubectl get pods --all-namespaces
同时查看多种资源信息:
[root@kub-k8s-master ~]# kubectl get pod,service -n kube-system
查看主节点:
[root@k8s-master prome]# kubectl cluster-infoapi查询:
[root@kub-k8s-master ~]# kubectl api-versions


创建名称空间
1.编写yaml文件
[root@kub-k8s-master ~]# mkdir prome
[root@kub-k8s-master ~]# cd prome/
[root@kub-k8s-master prome]# vim namespace.yml--- # yaml开始的标记
apiVersion: v1 #api版本
kind: Namespace #类型---固定的
metadata: #元数据
name: ns-monitor #给命名空间起个名字
labels: #用于给这个 Namespace 添加标签。标签是键值对,可以用于标识、组织和选择资源
name: ns-monitor # 该namespace的标签
2.创建资源
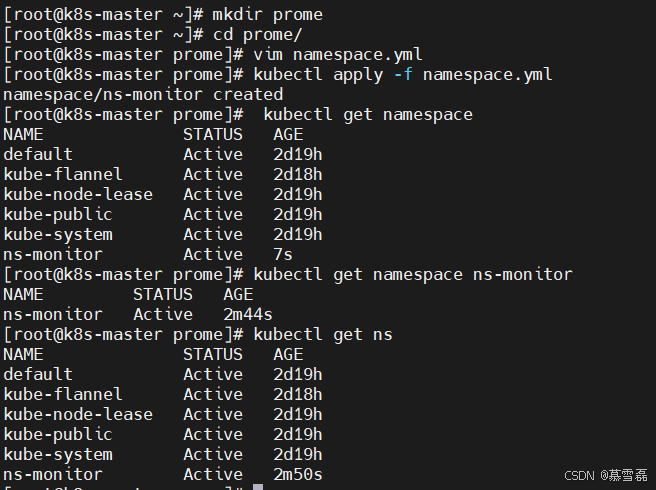
[root@k8s-master prome]# kubectl apply -f namespace.yml
3.查看资源
[root@k8s-master prome]# kubectl get namespace
注:
namespace 可以缩写为 ns
既:
kubectl get ns4.查看某⼀个namespace
[root@k8s-master prome]# kubectl get namespace ns-monitor
5.根据标签名查询命名空间
而我们在上面输入的lable中的name的值 monitor_hah_lale,是给这个命名空间打的一个标签,键值对形式出现,可以用于标签查询,查询有特定标签的namespace
[root@k8s-master prome]# kubectl get namespaces --selector=name=monitor_hah_lale
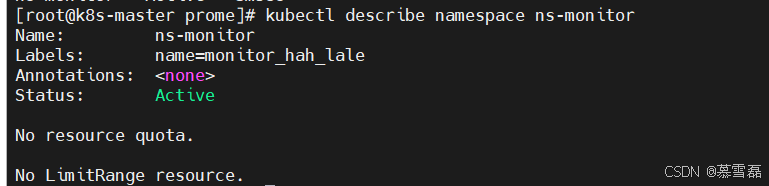
6.查看某个namespace的详细信息
Annotations: <none> # 没有注释
Status: Active #表示处于正常状态

7.修改名称空间的名字
不能直接修改,删除原有的命名空间,创建新的命名空间
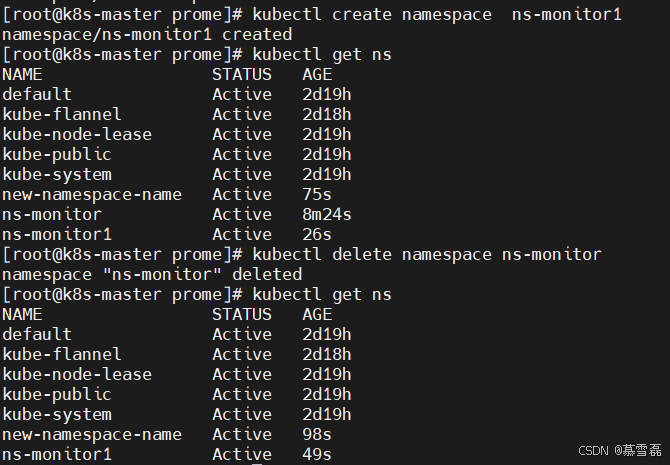
kubectl create namespace new-namespace-name或者 修改yml文件,重新创建
---
apiVersion: v1
kind: Namespace
metadata:
name: ns-monitor1 # 从ns-monitor 改为 ns-monitor1
labels:
name: monitor_hah_lale删除老的命名空间
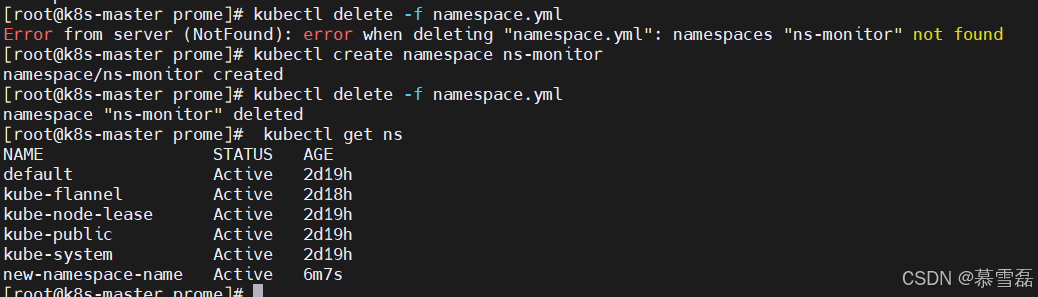
[root@k8s-master prome]# kubectl delete namespace ns-monitor
namespace "ns-monitor" deleted[root@k8s-master prome]# kubectl get ns
7.删除名称空间
[root@k8s-master prome]## kubectl delete -f namespace.yml
[root@k8s-master prome]## kubectl delete namespace ns-monitor
相关文章:
Kubernetes集群操作
查看集群信息: kubectl get nodes 删除节点 (⽆效且显示的也可以删除) 后期如果 要删除某个节点,为了不增加其他节点的访问压力,先增加一个节点,再删除要删除的节点 语法 :kubect delete…...

分布式事务调研
目录 需求背景: 本地事务 分布式基本理论 1、CAP 定理 2、BASE理论 分布式事务方案 #2PC #1. 运行过程 #1.1 准备阶段 #1.2 提交阶段 #2. 存在的问题 #2.1 同步阻塞 #2.2 单点问题 #2.3 数据不一致 #2.4 太过保守 3PC #本地消息表 TCC TCC原理 …...

Webpack 的构建流程
Webpack 的构建流程可以概括为以下几个步骤: 1. 初始化: Webpack 读取配置文件(webpack.config.js),合并默认配置和命令行参数,初始化Compiler对象。 2. 构建依赖图: 从入口文件开始递归地分…...

Cesium 当前位置矩阵的获取
Cesium 位置矩阵的获取 在 3D 图形和地理信息系统(GIS)中,位置矩阵是将地理坐标(如经纬度)转换为世界坐标系的一种重要工具。Cesium 是一个强大的开源 JavaScript 库,用于创建 3D 地球和地图应用。在 Cesi…...

ubuntu24.04 python环境
ubuntu24.04 python环境 0.引言1.使用整理 0.引言 新系统安装依赖库时报错: pip3installrequirements.txterror:externally−managed−environmentThisenvironmentisexternallymanaged╰–>ToinstallPythonpackagessystem−wide,tryaptinstallpython3−xyz,whe…...

YOLO系列论文综述(从YOLOv1到YOLOv11)【第9篇:YOLOv7——跨尺度特征融合】
YOLOv7 1 摘要2 网络架构3 改进点4 和YOLOv4及YOLOR的对比 YOLO系列博文: 【第1篇:概述物体检测算法发展史、YOLO应用领域、评价指标和NMS】【第2篇:YOLO系列论文、代码和主要优缺点汇总】【第3篇:YOLOv1——YOLO的开山之作】【第…...

Elasticearch索引mapping写入、查看、修改
作者:京东物流 陈晓娟 一、ES Elasticsearch是一个流行的开源搜索引擎,它可以将大量数据快速存储和检索。Elasticsearch还提供了强大的实时分析和聚合查询功能,数据模式更加灵活。它不需要预先定义固定的数据结构,可以随时添加或修…...

【大模型微调】一些观点的总结和记录
垂直领域大部分不用保持通用能力的,没必要跟淘宝客服聊天气预报,但是主要还是领导让你保持 微调方法没有大变数了,只能在数据上下功夫,我能想到的只有提高微调数据质量。 sft微调的越多,遗忘的越多. 不过对于小任务,rank比较低(例如8,16)的任务,影响还是有有限的。一…...

Vue 3 Hooks 教程
Vue 3 Hooks 教程 1. 什么是 Hooks? 在 Vue 3 中,Hooks 是一种组织和复用组件逻辑的强大方式。它们允许您将组件的状态逻辑提取到可重用的函数中,从而简化代码并提高代码的可维护性。 2. 基本 Hooks 介绍 2.1 ref 和 reactive 这两个函数…...

pandas数据处理及其数据可视化的全流程
Pandas数据处理及其可视化的全流程是一个复杂且多步骤的过程,涉及数据的导入、清洗、转换、分析、可视化等多个环节。以下是一个详细的指南,涵盖了从数据准备到最终的可视化展示的全过程。请注意,这个指南将超过4000字,因此请耐心…...
docker 在ubuntu系统安装,以及常用命令,配置阿里云镜像仓库,搭建本地仓库等
1.docker安装 1.1 先检查ubuntu系统有没有安装过docker 使用 docker -v 命令 如果有请先卸载旧版本,如果没有直接安装命令如下: 1.1.0 首先,确保你的系统包是最新的: 如果是root 权限下面命令的sudo可以去掉 sudo apt-get upda…...

torch.maximum函数介绍
torch.maximum 函数介绍 定义:torch.maximum(input, other) 返回两个张量的逐元素最大值。 输入参数: input: 张量,表示第一个输入。other: 张量或标量,表示第二个输入。若为张量,其形状需要能与 input 广播。输出&a…...

Java面试之多线程并发篇(9)
前言 本来想着给自己放松一下,刷刷博客,突然被几道面试题难倒!引用类型有哪些?有什么区别?说说你对JMM内存模型的理解?为什么需要JMM?多线程有什么用?似乎有点模糊了,那…...

Java全栈:超市购物系统实现
项目介绍 本文将介绍如何使用Java全栈技术开发一个简单的超市购物系统。该系统包含以下主要功能: 商品管理用户管理购物车订单处理库存管理技术栈 后端 Spring Boot 2.7.0Spring SecurityMyBatis PlusMySQL 8.0Redis前端 Vue.js 3Element PlusAxiosVuex系统架构 整体架构 …...

1.1 数据结构的基本概念
1.1.1 基本概念和术语 一、数据、数据对象、数据元素和数据项的概念和关系 数据:是客观事物的符号表示,是所有能输入到计算机中并被计算机程序处理的符号的总称。 数据是计算机程序加工的原料。 数据对象:是具有相同性质的数据元素的集合&…...

深度学习:GPT-2的MindSpore实践
GPT-2简介 GPT-2是一个由OpenAI于2019年提出的自回归语言模型。与GPT-1相比,仍基于Transformer Decoder架构,但是做出了一定改进。 模型规格上: GPT-1有117M参数,为下游微调任务提供预训练模型。 GPT-2显著增加了模型规模&…...

【Oracle11g SQL详解】ORDER BY 子句的排序规则与应用
ORDER BY 子句的排序规则与应用 在 Oracle 11g 中,ORDER BY 子句用于对查询结果进行排序。通过使用 ORDER BY,可以使返回的数据按照指定的列或表达式以升序或降序排列,便于数据的分析和呈现。本文将详细讲解 ORDER BY 子句的规则及其常见应用…...
【第15篇(完结):讨论和未来展望】)
YOLO系列论文综述(从YOLOv1到YOLOv11)【第15篇(完结):讨论和未来展望】
总结 0 前言1 YOLO与人工通用智能(AGI)2 YOLO作为“能够行动的神经网络”3 具身人工智能(EAI)4 边缘设备上的YOLO5 评估统计指标的挑战6 YOLO与环境影响 YOLO系列博文: 【第1篇:概述物体检测算法发展史、YO…...

Java设计模式 —— 【创建型模式】原型模式(浅拷贝、深拷贝)详解
文章目录 前言原型模式一、浅拷贝1、案例2、引用数据类型 二、深拷贝1、重写clone()方法2、序列化 总结 前言 先看一下传统的对象克隆方式: 原型类: public class Student {private String name;public Student(String name) {this.name name;}publi…...

SciAssess——评估大语言模型在科学文献处理中关于模型的记忆、理解和分析能力的基准
概述 大规模语言模型(如 Llama、Gemini 和 GPT-4)的最新进展因其卓越的自然语言理解和生成能力而备受关注。对这些模型进行评估对于确定其局限性和潜力以及促进进一步的技术进步非常重要。为此,人们提出了一些特定的基准来评估大规模语言模型…...

runtime.js实战部署:从本地QEMU到云端KVM的完整流程指南
runtime.js实战部署:从本地QEMU到云端KVM的完整流程指南 【免费下载链接】runtime [not maintained] Lightweight JavaScript library operating system for the cloud 项目地址: https://gitcode.com/gh_mirrors/runt/runtime runtime.js是一个革命性的Java…...

如何让Windows 11界面更顺手:ExplorerPatcher完整配置指南
如何让Windows 11界面更顺手:ExplorerPatcher完整配置指南 【免费下载链接】ExplorerPatcher This project aims to enhance the working environment on Windows 项目地址: https://gitcode.com/GitHub_Trending/ex/ExplorerPatcher 还在为Windows 11的新界…...

开源中间件IoTDM:破解物联网数据孤岛,实现异构设备统一管理
1. 项目概述:开源中间件如何成为物联网的“粘合剂”在物联网(IoT)领域摸爬滚打了十几年,我见过太多“数据孤岛”的困境。智能家居、工业传感器、可穿戴设备……每个设备、每个平台都像一座座信息孤岛,数据格式五花八门…...

如何快速检测微信单向好友:WechatRealFriends实用指南
如何快速检测微信单向好友:WechatRealFriends实用指南 【免费下载链接】WechatRealFriends 微信好友关系一键检测,基于微信ipad协议,看看有没有朋友偷偷删掉或者拉黑你 项目地址: https://gitcode.com/gh_mirrors/we/WechatRealFriends …...

QMCDecode:解锁QQ音乐加密文件,三步实现音乐格式自由转换
QMCDecode:解锁QQ音乐加密文件,三步实现音乐格式自由转换 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录&am…...

基于MCP协议与Playwright的AI智能体网页抓取工具部署与实战
1. 项目概述:一个为AI智能体打造的“网页抓取工具箱” 如果你正在开发或使用基于MCP(Model Context Protocol)的AI智能体,并且经常需要让它们从网页上获取结构化数据,那么你很可能已经遇到了一个核心痛点: …...

微信单向好友终极检测指南:如何快速发现谁已悄悄删除或拉黑你
微信单向好友终极检测指南:如何快速发现谁已悄悄删除或拉黑你 【免费下载链接】WechatRealFriends 微信好友关系一键检测,基于微信ipad协议,看看有没有朋友偷偷删掉或者拉黑你 项目地址: https://gitcode.com/gh_mirrors/we/WechatRealFrie…...

保姆级避坑指南:用STM32CubeMX配置NRF24L01 SPI通信,从硬件连接到软件调试一气呵成
STM32CubeMX实战:NRF24L01无线通信全流程避坑指南 第一次接触NRF24L01模块时,我被它小巧的体积和低廉的价格所吸引,但真正开始调试时才发现这个"玩具级"射频模块藏着不少坑。记得有一次项目交付前夜,模块突然无法通信&a…...

《如果你还愿意等》的搜索理由:等待场景怎样被记住
从内容传播角度看,《如果你还愿意等》的优势在于语气。它不是命令,也不是苦情控诉,而是把等待放成一个“如果”:有余地,也有边界。这个标题能自然带出使用场景:未读消息、夜车灯光、异地关系、还没完全离开…...

CANN/asc-devkit向量最小值函数
asc_min 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/ca…...