jmeter 获取唯一全局变量及多线程读写的问题
一、jmeter 获取唯一ID号全局变量
在JMeter中获取唯一ID号并设置为全局变量,可以通过以下几种方法实现:
-
使用JMeter内置的UUID函数: JMeter提供了一个内置的函数
__UUID,可以生成一个随机的UUID,这个UUID是全局唯一的。你可以在需要的地方直接使用${__UUID}来获取一个唯一的ID号。 -
使用BeanShell Sampler生成UUID: 如果你需要更多的自定义或者想要在生成UUID后进行一些额外的操作,可以使用BeanShell Sampler来编写Java代码生成UUID。例如:
java
import java.util.UUID; UUID uuid1 = UUID.randomUUID(); vars.put("uniqueID", (uuid1.toString()).replaceAll("-",""));这段代码会生成一个UUID,并去除其中的破折号,然后将这个值存储在名为
uniqueID的变量中。你可以在其他地方通过${uniqueID}来引用这个唯一ID号。 -
使用计数器和用户定义的变量: 如果你需要一个简单的递增唯一ID,可以使用JMeter的计数器。在线程组中添加一个计数器配置元件(Counter),并设置一个引用名称。然后在用户定义的变量中使用这个计数器的引用名称,例如
${__counter(myCounter,1,1)}。这样每次迭代都会递增这个计数器的值,从而保证唯一性。 -
使用正则表达式提取器和BeanShell PostProcessor: 如果你的唯一ID是从某个响应中提取的,你可以使用正则表达式提取器来提取这个ID,然后在BeanShell PostProcessor中使用
__setProperty函数将其设置为全局变量。例如:java
String uniqueID = vars.get("extractedID"); vars.put("globalUniqueID", uniqueID);这样你就可以在其他地方通过
${globalUniqueID}来引用这个全局唯一的ID号。
选择以上任何一种方法,都可以在JMeter中获取并使用唯一ID号作为全局变量。根据你的具体需求和测试场景,选择最适合你的方法。
二、如何确保JMeter中的全局变量在不同线程组中保持一致?
在JMeter中,确保全局变量在不同线程组中保持一致,可以通过以下步骤实现:
-
设置全局变量: 在一个线程组中,使用BeanShell或JSR223元件来设置全局变量。例如,使用
JSR223 PreProcessor,可以通过以下Groovy代码将一个局部变量的值设置为全局变量(Property):groovy
// 获取局部变量值 String localVar = vars.get("localVarName"); log.info("Local variable value: " + localVar); // 在第一个线程组中设置全局变量 props.put("globalVarName", localVar); log.info("Global variable set to: " + props.get("globalVarName"));这里,
localVarName是线程组内的局部变量,globalVarName是设置的全局变量名。 -
获取全局变量: 在另一个线程组中,可以通过类似的代码来获取之前设置的全局变量(Property):
groovy
// 在第二个线程组中获取全局变量 String globalVar = props.get("globalVarName"); log.info("Global variable value: " + globalVar); // 将全局变量的值赋给本线程组的局部变量 vars.put("localVarName", globalVar);这样,第二个线程组就可以使用第一个线程组设置的全局变量值。
-
使用
__setProperty函数: 你还可以使用JMeter的函数__setProperty来设置全局变量,并在其他线程组中通过${__property(变量名)}来引用这个全局变量。例如,在第一个线程组中设置全局变量:java
${__setProperty(globalVarName, localVarValue,)}然后在其他线程组中引用这个全局变量:
java
${__property(globalVarName,)} -
使用
BeanShell PostProcessor或BeanShell Sampler: 在第一个线程组中,使用BeanShell PostProcessor或BeanShell Sampler来将局部变量提升为全局变量。例如:java
props.put("globalVarName", vars.get("localVarName"));然后在其他线程组中,使用
BeanShell PreProcessor或BeanShell Sampler来获取这个全局变量:java
String globalVar = props.get("globalVarName"); vars.put("localVarName", globalVar);
通过上述方法,你可以确保在JMeter的不同线程组之间共享和保持全局变量的一致性。这样,无论在哪个线程组中,都可以访问和使用这些全局变量。
三、除了全局变量,JMeter还有其他共享数据的方法吗?
在JMeter中,除了使用全局变量来共享数据之外,还可以采用以下几种方法来实现不同线程组之间的数据共享:
-
使用JMeter属性(Properties): JMeter的属性是全局的,可以在所有线程之间共享。可以使用
__setProperty函数来设置属性,然后在其他线程组中使用${__P(propName)}来引用这个属性。这种方法适合传递静态值,如API密钥或配置参数。 -
使用文件转接法: 在一个线程组中将数据写入文件,然后在另一个线程组中通过CSV Data Set Config读取文件中的数据。这种方法适用于数据量较大且变化不频繁的情况。
-
使用JMeter的函数: JMeter提供了一些内置函数,如
__groovy,可以在不同线程组之间传递数据。例如,可以在一个线程组中使用__groovy{...}函数将数据写入共享变量,然后在另一个线程组中使用相同的函数来读取这个共享变量。 -
使用JSR223 PostProcessors或PreProcessors: 使用Groovy或其他语言编写脚本,在脚本中使用共享的变量或属性。这种方法提供了更大的灵活性,可以在脚本中执行更复杂的逻辑来处理数据共享。
-
使用HTTP Cookie Manager: 如果需要在多个线程组之间共享cookie,可以使用HTTP Cookie Manager。在第一个线程组中设置cookie后,其他线程组可以引用同一个HTTP Cookie Manager来共享这些cookie。
-
使用JMeter的监听器(Listeners): 例如,使用View Results Tree监听器查看一个请求的响应数据,然后在另一个线程组中使用BeanShell Sampler或JSR223 Sampler来提取并使用这些数据。
-
使用数据库: 如果数据共享需要跨多个测试计划或长时间保持,可以考虑使用数据库来存储和读取数据。在一个测试计划中将数据写入数据库,然后在另一个测试计划中从数据库读取数据。
每种方法都有其适用场景和限制,你可以根据实际的测试需求和环境选择最合适的方法来实现数据共享。
四、 在JMeter中,我该如何处理大量共享数据的读写性能问题?
在JMeter中处理大量共享数据的读写性能问题时,可以采取以下策略来优化性能:
-
使用分布式集群: 当单台机器无法承载更多线程时,可以采用分布式集群的方式。通过多台机器共同承担压测任务,可以显著提高性能和数据处理能力。
-
优化JVM参数: 调整JMeter的JVM参数,增加堆内存和新生代内存的大小,可以提高JMeter处理大量数据的能力。例如,可以修改
jmeter.bat文件中的set HEAP=-Xms2048m -Xmx2048m来增加内存分配。 -
使用CSV Data Set Config的共享模式: 在处理大量数据时,合理设置CSV Data Set Config的共享模式可以提高性能。例如,使用“Current thread group”模式可以让同一线程组内的线程共享数据集,减少文件的读写次数。
-
减少文件I/O操作: 频繁的文件读写会严重影响性能。可以通过减少文件打开次数、使用内存中的数据结构来传递数据,或者将数据存储在数据库中,通过JDBC请求来读取,以减少文件I/O操作。
-
使用数据库: 对于需要大量读写操作的数据,可以考虑使用数据库来存储和读取数据。JMeter可以通过JDBC Request直接与数据库交互,这样可以更有效地处理大量数据。
-
优化数据结构和算法: 在BeanShell或JSR223脚本中,优化数据结构和算法可以减少数据处理的时间。例如,使用更高效的数据结构来存储和检索数据。
-
使用缓存: 如果数据不经常变化,可以考虑使用缓存来存储热点数据,减少对后端数据源的访问压力。
-
监控和调优: 使用JMeter自带的监听器或更高级的工具(如Grafana与InfluxDB)进行实时监控,根据监控结果对性能进行调优。
-
避免使用非线程安全的元件: 在设计测试计划时,确保使用的元件是线程安全的,避免因为线程安全问题导致的性能瓶颈。
通过上述方法,可以有效提高JMeter在处理大量共享数据时的读写性能,从而更高效地进行性能测试。
相关文章:

jmeter 获取唯一全局变量及多线程读写的问题
一、jmeter 获取唯一ID号全局变量 在JMeter中获取唯一ID号并设置为全局变量,可以通过以下几种方法实现: 使用JMeter内置的UUID函数: JMeter提供了一个内置的函数__UUID,可以生成一个随机的UUID,这个UUID是全局唯一的。…...
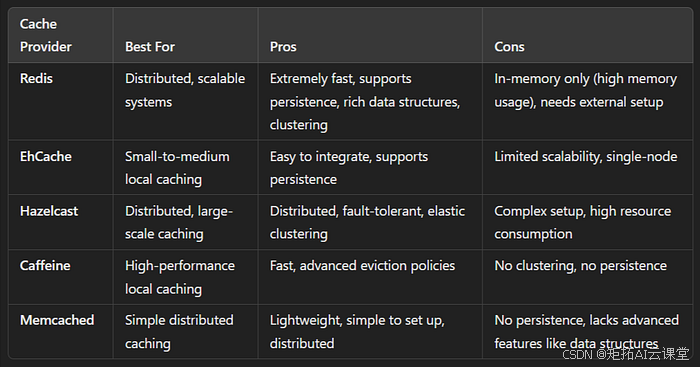
掌握 Spring Boot 中的缓存:技术和最佳实践
缓存是一种用于将经常访问的数据临时存储在更快的存储层(通常在内存中)中的技术,以便可以更快地满足未来对该数据的请求,从而提高应用程序的性能和效率。在 Spring Boot 中,缓存是一种简单而强大的方法,可以…...
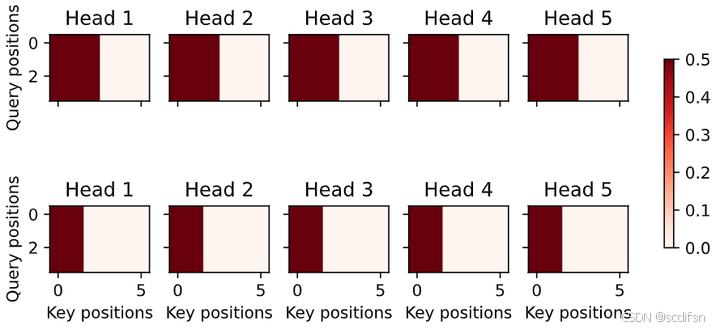
动手学深度学习10.5. 多头注意力-笔记练习(PyTorch)
本节课程地址:多头注意力代码_哔哩哔哩_bilibili 本节教材地址:10.5. 多头注意力 — 动手学深度学习 2.0.0 documentation 本节开源代码:...>d2l-zh>pytorch>chapter_multilayer-perceptrons>multihead-attention.ipynb 多头注…...
)
13 设计模式之外观模式(家庭影院案例)
一、什么是外观模式? 1.定义 在日常生活中,许多人喜欢通过遥控器来控制家中的电视、音响、DVD 播放器等设备。虽然这些设备各自独立工作,但遥控器提供了一个简洁的界面,让用户可以轻松地操作多个设备。而这一设计理念正是 外观模…...

单片机学习笔记 12. 定时/计数器_定时
更多单片机学习笔记:单片机学习笔记 1. 点亮一个LED灯单片机学习笔记 2. LED灯闪烁单片机学习笔记 3. LED灯流水灯单片机学习笔记 4. 蜂鸣器滴~滴~滴~单片机学习笔记 5. 数码管静态显示单片机学习笔记 6. 数码管动态显示单片机学习笔记 7. 独立键盘单片机学习笔记 8…...

Web安全基础实践
实践目标 (1)理解常用网络攻击技术的基本原理。(2)Webgoat实践下相关实验。 WebGoat WebGoat是由著名的OWASP负责维护的一个漏洞百出的J2EE Web应用程序,这些漏洞并非程序中的bug,而是故意设计用来讲授We…...

Zookeeper集群数据是如何同步的?
大家好,我是锋哥。今天分享关于【Zookeeper集群数据是如何同步的?】面试题。希望对大家有帮助; Zookeeper集群数据是如何同步的? 1000道 互联网大厂Java工程师 精选面试题-Java资源分享网 Zookeeper集群中的数据同步是通过一种称为ZAB(Zo…...
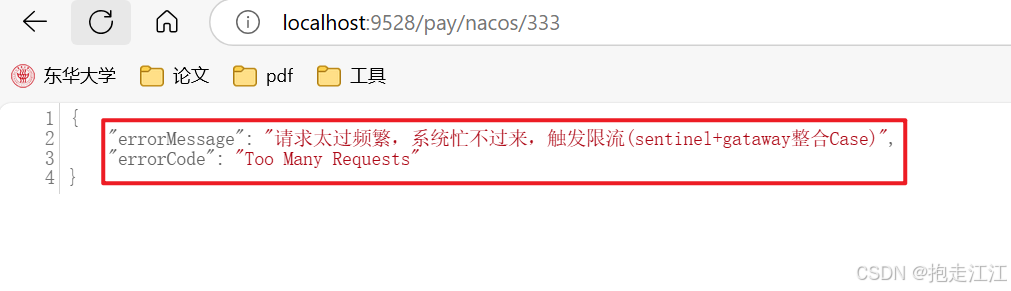
SpringCloud框架学习(第六部分:Sentinel实现熔断与限流)
目录 十四、SpringCloud Alibaba Sentinel实现熔断与限流 1.简介 2.作用 3.下载安装 4.微服务 8401 整合 Sentinel 入门案例 5.流控规则 (1)基本介绍 (2)流控模式 Ⅰ. 直接 Ⅱ. 关联 Ⅲ. 链路 (3࿰…...
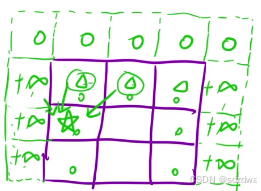
动态规划-----路径问题
动态规划-----路径问题 下降最小路径和1:状态表示2:状态转移方程3 初始化4 填表顺序5 返回值6 代码实现 总结: 下降最小路径和 1:状态表示 假设:用dp[i][j]表示:到达[i,j]的最小路径 2:状态转…...

Rust循环引用与多线程并发
循环引用与自引用 循环引用的概念 循环引用指的是两个或多个对象之间相互持有对方的引用。在 Rust 中,由于所有权和生命周期的严格约束,直接创建循环引用通常会导致编译失败。例如: // 错误的循环引用示例 struct Node {next: Option<B…...
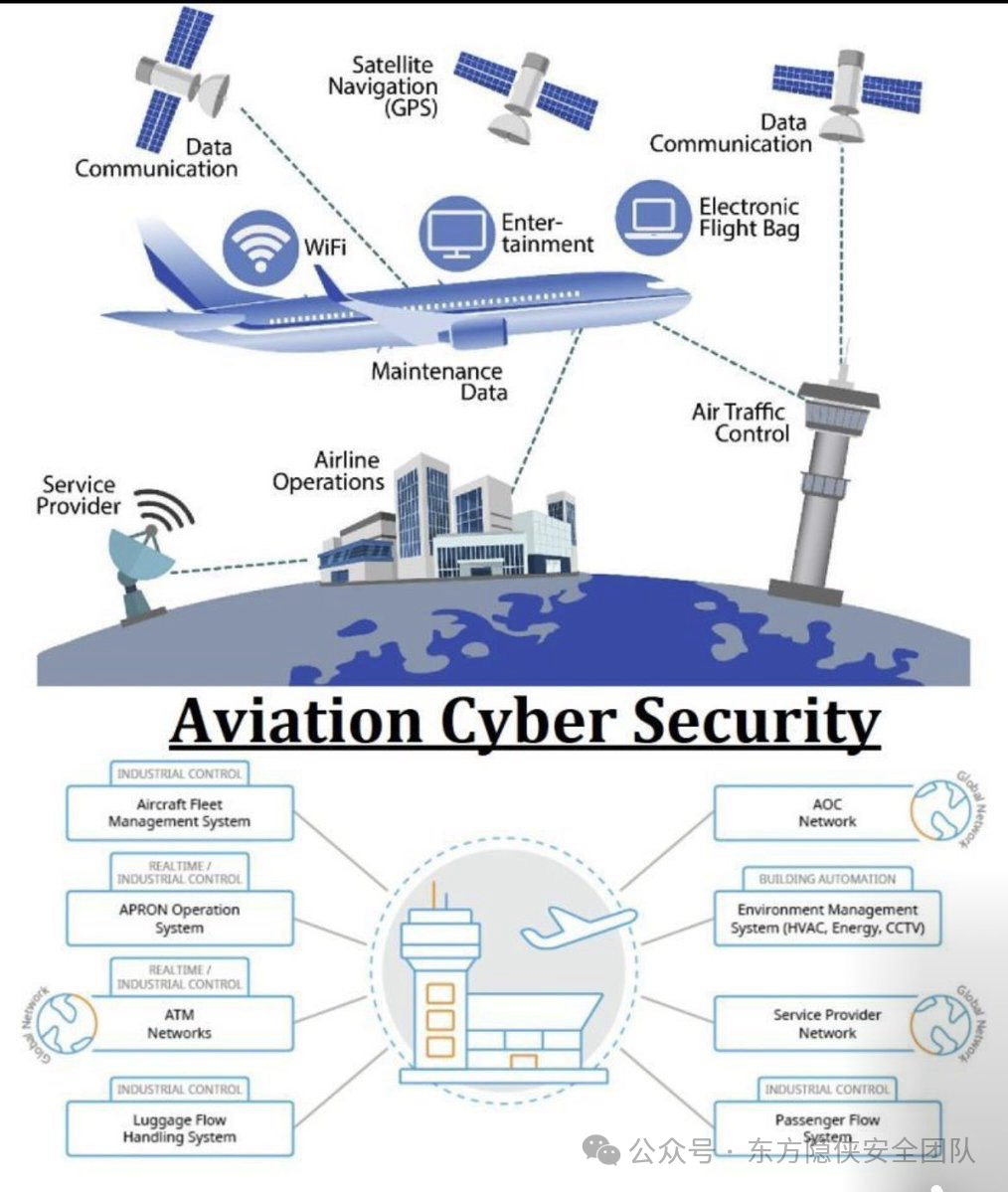
东方隐侠网安瞭望台第8期
谷歌应用商店贷款应用中的 SpyLoan 恶意软件影响 800 万安卓用户 迈克菲实验室的新研究发现,谷歌应用商店中有十多个恶意安卓应用被下载量总计超过 800 万次,这些应用包含名为 SpyLoan 的恶意软件。安全研究员费尔南多・鲁伊斯上周发布的分析报告称&…...
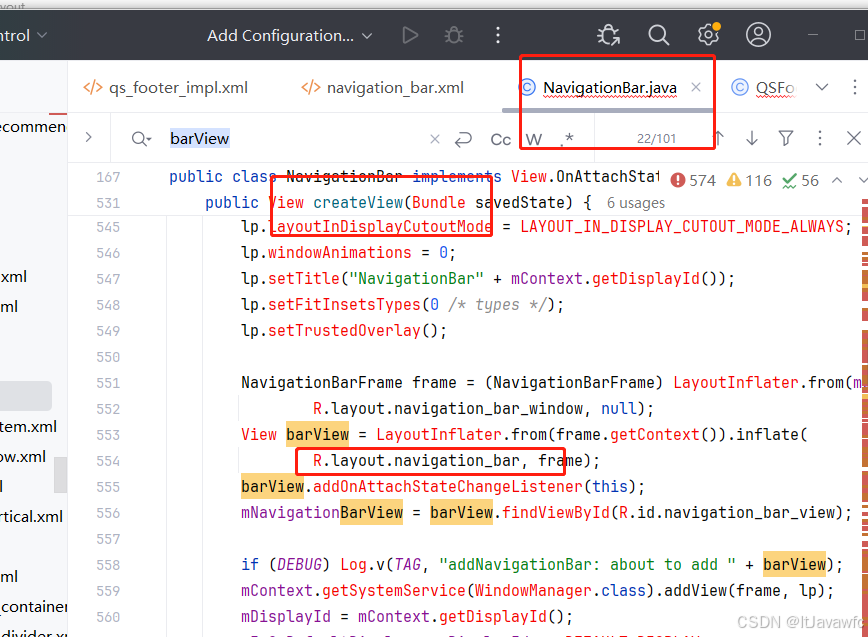
底部导航栏新增功能按键
场景需求: 在底部导航栏添加power案件,单击息屏,长按 关机 如下实现图 借此需求,需要掌握技能: 底部导航栏如何实现新增、修改、删除底部导航栏流程对底部导航栏部分样式如何修改。 比如放不下、顺序排列、坑点如…...
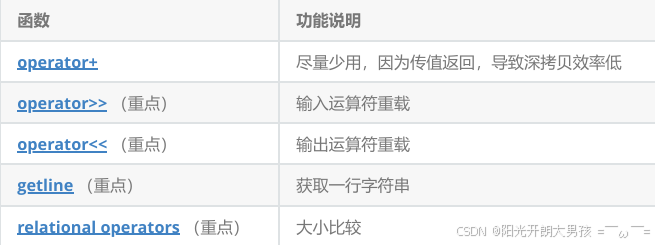
C++ 之弦上舞:string 类与多样字符串操作的优雅旋律
string 类的重要性及与 C 语言字符串对比 在 C 语言中,字符串是以 \0 结尾的字符集合,操作字符串需借助 C 标准库的 str 系列函数,但这些函数与字符串分离,不符合 OOP 思想,且底层空间管理易出错。而在 C 中࿰…...
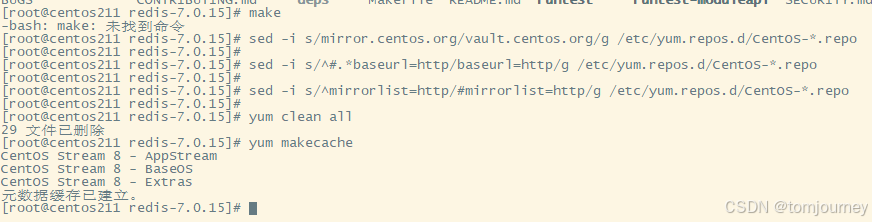
centos8:Could not resolve host: mirrorlist.centos.org
【1】错误消息: [rootcentos211 redis-7.0.15]# yum update CentOS Stream 8 - AppStream …...

Linux 定时任务 命令解释 定时任务格式详解
目录 时间命令 修改时间和日期 定时任务格式 定时任务执行 查看定时任务进程 重启定时任务 时间命令 #查看时间 [rootlocalhost ~]# date 2021年 07月 23日 星期五 14:38:19 CST --------------------------------------- [rootlocalhost ~]# date %F 2021-07-23 -----…...
aws(学习笔记第十五课) 如何从灾难中恢复(recover)
aws(学习笔记第十五课) 如何从灾难中恢复 学习内容: 使用CloudWatch对服务器进行监视与恢复区域(region),可用区(available zone)和子网(subnet)使用自动扩展(AutoScalingGroup) 1. 使用CloudWatch对服务器进行监视与恢复 整体架构 这里模拟Jenkins Se…...
github webhooks 实现网站自动更新
本文目录 Github Webhooks 介绍Webhooks 工作原理配置与验证应用云服务器通过 Webhook 自动部署网站实现复制私钥编写 webhook 接口Github 仓库配置 webhook以服务的形式运行 app.py Github Webhooks 介绍 Webhooks是GitHub提供的一种通知方式,当GitHub上发生特定事…...

【C语言】递归的内存占用过程
递归 递归是函数调用自身的一种编程技术。在C语言中,递归的实现会占用内存栈(Call Stack),每次递归调用都会在栈上分配一个新的 “栈帧(Stack Frame)”,用于存储本次调用的函数局部变量、返回地…...

365天深度学习训练营-第P6周:VGG-16算法-Pytorch实现人脸识别
🍨 本文为🔗365天深度学习训练营中的学习记录博客🍖 原作者:K同学啊 文为「365天深度学习训练营」内部文章 参考本文所写记录性文章,请在文章开头带上「👉声明」 🍺要求: 保存训练过…...

企业AI助理在数据分析与决策中扮演的角色
在当今这个数据驱动的时代,企业每天都需要处理和分析大量的数据,以支持其业务决策。然而,面对如此庞大的数据量,传统的数据分析方法已经显得力不从心。幸运的是,随着人工智能(AI)技术的不断发展…...

如何永久激活IDM?免费IDM激活脚本终极指南
如何永久激活IDM?免费IDM激活脚本终极指南 【免费下载链接】IDM-Activation-Script IDM Activation & Trail Reset Script 项目地址: https://gitcode.com/gh_mirrors/id/IDM-Activation-Script 还在为IDM试用期到期而烦恼吗?IDM Activation …...

免费德州扑克GTO求解器终极指南:如何用Desktop Postflop提升你的扑克决策能力
免费德州扑克GTO求解器终极指南:如何用Desktop Postflop提升你的扑克决策能力 【免费下载链接】desktop-postflop [Development suspended] Advanced open-source Texas Holdem GTO solver with optimized performance 项目地址: https://gitcode.com/gh_mirrors/…...

LeetDown深度解析:如何让iPhone 5s/6等老设备重返iOS 10.3.3黄金时代
LeetDown深度解析:如何让iPhone 5s/6等老设备重返iOS 10.3.3黄金时代 【免费下载链接】LeetDown a macOS app that downgrades A6 and A7 iDevices to OTA signed firmwares 项目地址: https://gitcode.com/gh_mirrors/le/LeetDown 还记得iPhone 5s的Touch I…...

资源下载神器:5分钟掌握全平台媒体内容下载技巧
资源下载神器:5分钟掌握全平台媒体内容下载技巧 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 你是否曾经遇到过…...
避坑指南)
【能力进阶】测试工程师必须了解的 Tokenization(分词器)避坑指南
写作日期:2026年5月 适用读者:后端/算法测试工程师、AI产品测试、LLM应用QA 1 为什么测试工程师必须关注分词器? 2 竞品对比:同一句话,不同模型差出一个量级 2.1 「中文税」到底有多重 2.2 各模型中文分词效...

终极HsMod炉石传说模改插件:如何用开源技术重塑你的游戏体验
终极HsMod炉石传说模改插件:如何用开源技术重塑你的游戏体验 【免费下载链接】HsMod Hearthstone Modification Based on BepInEx 项目地址: https://gitcode.com/GitHub_Trending/hs/HsMod 在炉石传说的世界里,每个玩家都渴望更流畅、更个性化的…...

Windows 11终极优化指南:用开源神器Win11Debloat快速清理系统垃圾
Windows 11终极优化指南:用开源神器Win11Debloat快速清理系统垃圾 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declu…...

LLM 本地部署框架 vLLM 和 LMDeploy
1. 安装vLLM的环境 1.1 安装要求 1. vLLM 包含预编译的 C 和 CUDA (12.8) 二进制文件。 2. 要求: 操作系统: LinuxPython: 3.9 -- 3.12 # (实测:推荐安装3.10以上版本)GPU: 计算能力 7.0 或更高 (例如, V100, T4, RTX20xx, A100, L4, H100 等…...

SQLines 数据库迁移工具深度解析:跨平台SQL转换的技术实现与最佳实践
SQLines 数据库迁移工具深度解析:跨平台SQL转换的技术实现与最佳实践 【免费下载链接】sqlines SQLines Open Source Database Migration Tools 项目地址: https://gitcode.com/gh_mirrors/sq/sqlines 在当今多数据库架构环境中,企业面临着从传统…...

CAXA 表格样式
位置属性和 CAD 类似默认【标准】自带,删不掉。预览常规-表格方向向上;向下;单元样式标题;表头;数据;【切换】对应下方 常规、文字的属性设置。常规【对齐】创建行时合并单元:文字命令位置先设置…...