RAG评估指南:从检索到生成,全面解析LLM性能评估方法
前言
这一节我们将从时间线出发对RAG的评估方式进行对比,这些评估方式不仅限于RAG流程之中,其中基于LLM的评估方式更加适用于各行各业。
RAG常用评估方式
上一节我们讲了如何用ROUGE 这个方法评估摘要的相似度,由于篇幅限制,没有讲到图片与文本之间的评估,由于涉及图片与文本评估的场景多见于RAG流程中,包括检索评估方法和生成评估方法,其中生成评估方法也就是通过对答案进行评估的方法,从而对LLM这个模型的生成能力进行间接的评估。也适用于我们的图片与上下文之间的评估。
此外本文还会对RAG中的其他重要内容的评估方式进行详尽的讲解。
检索评估指标
常用的检索评估方式有以下几种,包括文字和图片的检索评估,评估方式侧重点各不相同,没有好坏之分。
| Metric | Explanation | Row level metric value |
|---|---|---|
| source recall@k% ** | 这个指标表示在所有问答(Q&A)对中,至少有一个被标记为好的源(source)的文档在前k个块(chunks)中被找到的百分比。 | 如果第一个source chunk index <k则为1,否则为0 |
| all_img recall@k% ** | 这个指标表示在所有问答对中,所有预期的图像都被成功检索出来的百分比。 | 如果所有基本事实(ground-truth)的图像都被检索出来,则该指标的值为1,否则为0。 |
| img_recall@k_mean | 这个指标表示图像召回的平均值 | 即在前k个块中检索到的URL与基本事实的预期URL之间的召回率的平均值,其值在0到1之间。 |
| img_recall@k_median | 这个指标表示图像召回的中位数 | 即在前k个块中检索到的URL与基于事实的预期URL之间的召回率的中位数,其值在0到1之间。 |
| img_precision@k_mean | 这个指标表示图像精确度的平均值 | 即在前k个块中检索到的URL与基于事实的预期URL之间的精确度的平均值,其值在0到1之间。 |
| img_precision@k_median | 这个指标表示图像精确度的中位数 | 即在前k个块中检索到的URL与基于事实的预期URL之间的精确度的中位数,其值在0到1之间。 |
| similarity_search_time_in_sec_mean | 这个指标表示平均的AI搜索块检索时间 | 以秒为单位 |
| similarity_search_time_in_sec_median | 这个指标表示中位数的AI搜索块检索时间 | 以秒为单位 |
| #_source_chunks_sum | 这个指标表示所有问答对中基于事实检索到的所有块的总数 | 其值在0到k之间 |
| #_img_chunks_sum | 这个指标表示所有问答对中基于事实检索到的所有图像块的总数 | 其值在0到k之间 |
其中,**这里的 k 一般取10,5,3
生成评估指标
这些指标用于衡量一个系统在处理问答(Q&A)任务时的表现,特别是涉及到大型语言模型(LLM)和视觉增强服务时。下面是对表格中每个指标的解释:
| Metric | Explanation | Row level metric value |
|---|---|---|
| all_cited_img recall% | 所有预期图像都被LLM引用的问答对的百分比 | 如果LLM引用了所有基于事实的图像,则该指标的值为1,否则为0。 |
| cited_img_recall_mean | 引用图像召回的平均值 | 即生成答案中URL与基于事实的预期URL之间的召回率的平均值,其值在0到1之间。 |
| cited_img_recall_median | 引用图像召回的中位数 | 即生成答案中URL与基于事实的预期URL之间的召回率的中位数,其值在0到1之间。 |
| cited_img_precision_mean | 引用图像精确度的平均值 | 即生成答案中URL与基于事实的预期URL之间的精确度的平均值,其值在0到1之间。 |
| cited_img_precision_median | 引用图像精确度的中位数 | 即生成答案中URL与基于事实的预期URL之间的精确度的中位数,其值在0到1之间。 |
| cited_img_f1_mean | 引用图像F1分数的平均值 | F1分数是召回率和精确度的调和平均数,计算公式为 F1=2∗cited_img_recall∗cited_img_precisioncited_img_recall+cited_img_precisionF1=2∗cited_img_recall+cited_img_precisioncited_img_recall∗cited_img_precision。 |
| cited_img_f1_median | 引用图像F1分数的中位数 | F1分数是召回率和精确度的调和平均数,计算公式为 F1=2∗cited_img_recall∗cited_img_precisioncited_img_recall+cited_img_precisionF1=2∗cited_img_recall+cited_img_precisioncited_img_recall∗cited_img_precision。 |
| chat_query_time_in_sec_mean | 端到端响应时间的平均值 | 以秒为单位 |
| chat_query_time_in_sec_median | 端到端响应时间的中位数 | 以秒为单位 |
| inference_prompt_tokens_sum | 输入到LLM的总token数 | |
| inference_completion_tokens_sum | LLM用于回答的输出token数 | |
| vision_prompt_tokens_sum | 输入到视觉增强服务的总token数 | |
| vision_completion_tokens_sum | 视觉增强服务输出的token数。 | |
| gpt_correctness score>3% | 正确性得分高于3的问答对的百分比。 | |
| gpt_correctness_score_mean | 正确性得分的平均值 | 得分范围是1到5。 |
| gpt_correctness_score_median | 正确性得分的中位数 | 得分范围是1到5。 |
表格的描述强调了这些指标的重要性,它们提供了对系统每个部分有效性的宝贵见解。这些指标有助于分别衡量系统的搜索能力和生成部分,以便理解实验对每个组件的影响。
RAG常用实验改进流程
我们通过系统地测试不同的方法进行实验,一次调整一个配置设置并评估其对预定义基线的影响。使用下面概述的特定检索和生成指标来评估性能。对这些指标的详细分析有助于我们决定是否使用新配置更新基线或保留现有配置。

Q&A 评估数据集
为了在实验过程中进行准确评估,整理一组多样化的问答对至关重要。这些问答对应涵盖一系列文章,涵盖各种数据格式、长度和主题。这种多样性可确保全面的测试和评估,有助于提高结果和所获见解的可靠性。以下是可供参考的问答数据集示例。

好的数据集应该确保问答数据集中的问题均衡,既有来自文本的问题,也有来自图像和文本的问题,还有一些问题仅来自图像。还确保问题分布在各种源文档中。
当评估集相对较小时,可以通过纳入各种边缘情况来确保其多样性。可以从彻底的探索性数据分析 (EDA) 开始,图片中的例子提取了诸如文章长度、表格长度和文本表格数量以及图像类型、分辨率和图像数量等特征。然后,仔细地将评估集分布在这些特征上,以实现特征空间的全面表示和稳健覆盖。此外,该系统还支持同一问题的替代来源和图像。
评估图片实操
# 模拟的检索结果,即检索算法返回的结果
retrieved_images = ['img1.jpg', 'img2.jpg', 'img3.jpg', 'img4.jpg', 'img5.jpg']# 真实的标注结果,即与查询图像相关的所有图像
ground_truth_images = ['img1.jpg', 'img2.jpg', 'img3.jpg', 'img6.jpg', 'img7.jpg']# 计算召回率
def calculate_recall(retrieved, ground_truth):# 将列表转换为集合,以便使用集合操作retrieved_set = set(retrieved)ground_truth_set = set(ground_truth)# 计算召回率recall = len(retrieved_set.intersection(ground_truth_set)) / len(ground_truth_set)return recall# 调用函数计算召回率
recall = calculate_recall(retrieved_images, ground_truth_images)print(f"召回率: {recall:.2f}")
我们这里用比较简单的方式抽象一下,具体从markdown中提取图像的标签的细节就不罗嗦了,实际上是差不多的
![]()
各评估方式综述
评估方法衡量我们系统的表现。对每个摘要进行手动评估(人工审核)既耗时又费钱,而且不可扩展,因此通常用自动评估来补充。许多自动评估方法试图衡量人类评估者会考虑的文本质量。这些质量包括流畅性、连贯性、相关性、事实一致性和公平性。内容或风格与参考文本的相似性也是生成文本的重要质量。
下图包括用于评估 LLM 生成内容的许多指标及其分类方法。

Reference-based Metrics
基于参考的指标用于将生成的文本与参考(人工注释的地面实况文本)进行比较。许多此类指标是在 LLM 开发之前为传统 NLP 任务开发的,但仍然适用于 LLM 生成的文本。
N-gram based metrics
指标 BLEU (Bilingual Evaluation Understudy), ROUGE (Recall-Oriented Understudy for Gisting Evaluation), and JS divergence (JS2)https://arxiv.org/abs/2010.07100) 是基于重叠的指标,使用 n-gram 来衡量输出文本和参考文本的相似性。
BLEU Score
BLEU(双语评估测试)分数用于评估从一种自然语言到另一种自然语言的机器翻译文本的质量。因此,它通常用于机器翻译任务,但也用于其他任务,如文本生成、释义生成和文本摘要。其基本思想是计算精度,即参考翻译中候选词的比例。通过将单个翻译片段(通常是句子)与一组高质量的参考翻译进行比较,计算出分数。然后,将这些分数在整个语料库中取平均值,以估计翻译的整体质量。评分时不考虑标点符号或语法正确性。
很少有人工翻译能获得完美的 BLEU 分数,因为完美的分数表明候选译文与其中一个参考译文完全相同。因此,没有必要获得完美的分数。考虑到随着多个参考译文的增加,匹配的机会更多,我们鼓励提供一个或多个参考译文,这将有助于最大化 BLEU 分数。
P=mwtP=wtm m:参考中的候选词数。*wt:候选中的单词总数。
通常,上述计算会考虑目标中出现的候选单词或单元词组。但是,为了更准确地评估匹配,可以计算二元词组甚至三元词组,并对从各种 n 元词组获得的分数取平均值,以计算总体 BLEU 分数。
ROUGE
与 BLEU 分数相反,面向召回率的摘要评估 (ROUGE) 评估指标衡量的是召回率。它通常用于评估生成文本的质量和机器翻译任务。但是,由于它衡量的是召回率,因此它用于摘要任务。在这些类型的任务中,评估模型可以召回的单词数量更为重要。
ROUGE 类中最流行的评估指标是 ROUGE-N 和 ROUGE-L:
Rouge-N:测量参考(a)和测试(b)字符串之间匹配的“n-gram”的数量。Precision=在 a 和 b 中发现的 n-gram 数量b 中的 n-gram 数量Precision=b 中的 n-gram 数量在 a 和 b 中发现的 n-gram 数量 Recall=在 a 和 b 中发现的 n-gram 数量a 中的 n-gram 数量Recall=a 中的 n-gram 数量在 a 和 b 中发现的 n-gram 数量 Rouge-L:测量参考(a)和测试(b)字符串之间的最长公共子序列 (LCS)。 Precision=LCS(a,b)b 中的单元词数量Precision=b 中的单元词数量LCS(a,b) Recall=LCS(a,b)a 中的单元词数量Recall=a 中的单元词数量LCS(a,b) 对于 Rouge-N 和 Rouge-L: F1=2×precisionrecallF1=recall2×precision
Text Similarity metrics
文本相似度指标评估器专注于通过比较文本元素之间单词或单词序列的重叠来计算相似度。它们可用于为 LLM 和参考标准文本的预测输出生成相似度分数。这些指标还可以指示模型在各个任务中的表现如何。
Levenshtein Similarity Ratio
编辑相似度比率是用于衡量两个序列之间相似度的字符串指标。此度量基于编辑距离。通俗地说,两个字符串之间的编辑距离是将一个字符串更改为另一个字符串所需的最小单字符编辑(插入、删除或替换)次数。编辑相似度比率可以使用编辑距离值和两个序列的总长度来计算,定义如下:
编辑相似度比率(简单比率): Lev.ratio(a,b)=(∣a∣+∣b∣)−Lev.dist(a,b)∣a∣+∣b∣Lev.ratio(a,b)=∣a∣+∣b∣(∣a∣+∣b∣)−Lev.dist(a,b) 其中 |a| 和 |b| 分别是 a 和 b 的长度。
从简单编辑相似度比率中衍生出几种不同的方法:
部分比率:通过取最短字符串计算相似度,并将其与较长字符串中相同长度的子字符串进行比较。
标记排序比率:首先将字符串拆分为单个单词或标记,然后按字母顺序对标记进行排序,最后将它们重新组合成一个新字符串,以此计算相似度。然后使用简单比率方法比较这个新字符串。
Token-set Ratio:首先将字符串拆分成单个单词或者Token,然后计算两个字符串之间Token集的交集与并集,以此来计算相似度。
Semantic Similarity metrics
BERTScore, MoverScore 和 Sentence Mover Similarity (SMS) 这些指标都依赖于语境化嵌入来衡量两段文本之间的相似性。虽然与基于 LLM 的指标相比,这些指标相对简单、快速且计算成本低廉,但研究表明,它们与人类评估者的相关性较差、缺乏可解释性、固有偏见、对各种任务的适应性较差,并且无法捕捉语言中的细微差别。
两个句子之间的语义相似度是指它们的含义有多紧密相关。为此,首先将每个字符串表示为一个特征向量,以捕获其语义含义。一种常用的方法是生成字符串的嵌入(例如,使用 LLM),然后使用余弦相似度来测量两个嵌入向量之间的相似度。更具体地说,给定一个表示目标字符串的嵌入向量 (A) 和一个表示参考字符串的嵌入向量 (B),余弦相似度计算如下:
余弦相似度=A⋅B∣∣A∣∣∣∣B∣∣余弦相似度=∣∣A∣∣∣∣B∣∣A⋅B
如上所示,该度量测量两个非零向量之间角度的余弦,范围从 -1 到 1。1 表示两个向量相同,-1 表示它们不相似。
Reference-free Metrics
无参考(基于上下文)指标会为生成的文本生成分数,并且不依赖于基本事实。评估基于上下文或源文档。许多此类指标都是为了应对创建基本事实数据的挑战而开发的。这些方法往往比基于参考的技术更新,反映了随着 PTM 变得越来越强大,对可扩展文本评估的需求日益增长。这些指标包括基于质量、基于蕴涵、基于事实、基于问答 (QA) 和基于问题生成 (QG) 的指标。
- 基于质量的摘要指标。这些方法检测摘要是否包含相关信息。SUPERT质量衡量摘要与基于 BERT 的伪参考的相似性,而 BLANC质量衡量两个掩码标记重建的准确性差异。ROUGE-C是 ROUGE 的修改版,无需参考,并使用源文本作为比较的上下文。
- 基于蕴涵的指标。基于蕴涵的指标基于自然语言推理 (NLI) 任务,对于给定的文本(前提),它确定输出文本(假设)是否蕴涵、与前提相矛盾或破坏前提 [24]。这有助于检测事实不一致。 SummaC (Summary Consistency) benchmark 、FactCC和 DAE (Dependency Arc Entailment)指标可用作检测与源文本的事实不一致的方法。基于蕴涵的指标被设计为带有“一致”或“不一致”标签的分类任务。
- 基于事实性、QA 和 QG 的指标。基于事实性的指标(如 SRLScore (Semantic Role Labeling)和 QAFactEval)评估生成的文本是否包含与源文本不符的不正确信息。基于 QA(如 QuestEval)和基于 QG 的指标被用作另一种衡量事实一致性和相关性的方法。
与基于参考的指标相比,无参考指标与人类评估者的相关性有所提高,但使用无参考指标作为任务进度的单一衡量标准存在局限性。一些 limitations包括对其底层模型输出的偏见和对更高质量文本的偏见。
点击RAG评估指南:从检索到生成,全面解析LLM性能评估方法查看全文
相关文章:
RAG评估指南:从检索到生成,全面解析LLM性能评估方法
前言 这一节我们将从时间线出发对RAG的评估方式进行对比,这些评估方式不仅限于RAG流程之中,其中基于LLM的评估方式更加适用于各行各业。 RAG常用评估方式 上一节我们讲了如何用ROUGE 这个方法评估摘要的相似度,由于篇幅限制,没…...

贪心算法实例-问题分析(C++)
贪心算法实例-问题分析 饼干分配问题 有一群孩子和一堆饼干,每个小孩都有一个饥饿度,每个饼干都有一个能量值,当饼干的能量值大于等于小孩的饥饿度时,小孩可以吃饱,求解最多有多少个孩子可以吃饱?(注:每个小孩只能吃…...

Ubuntu20.04 配置虚拟显示器和切回物理显示器
1、安装软件,用中软安装虚拟显示器软件 sudo apt-get install xserver-xorg-core-hwe-18.04 sudo apt-get install xserver-xorg-video-dummy2、添加配置文件 进入 /usr/share/X11/xorg.conf.d/ 文件夹下创建xorg.conf文件 # 创建xorg.conf文件 touch xorg.conf …...

HTML 常用标签属性汇总一〈body〉标签
背景属性:包括:bgcolor,background <body background—color:black〉 背景颜色 <body background—image : url(image/bg.gif)〉 背景图片 <body background—attachment : fixed〉 固定背景 〈body background—repeat : repeat〉 重复排列—网页预设 〈b…...

Python yield关键字
1、什么是yield关键字 yield 是 Python 中的一个关键字,它用于定义生成器函数。生成器是一种特殊的迭代器,它可以在遍历过程中逐步产生值,而不是一次性生成所有值并将其存储在内存中。这使得生成器非常适合处理大量数据或无限序列࿰…...

tomcat的Mysql链接字符串问题
tomcat配置mysql链接需要改server.xml或content.xml。 但是server.xml或content.xml中mysql的配置看起来很古怪: url"jdbc:mysql://10.21.0.6:3306/hrdatabase?characterEncodinggbk&autoReconnecttrue" 而使用springboot开发java应用,使用ya…...

聊聊JVM G1(Garbage First)垃圾收集器
CMS的垃圾回收机制,为什么分为四步https://blog.csdn.net/genffe880915/article/details/144205658说完CMS垃圾回收器,必定要说到目前一般应用项目中都推荐的G1。G1在JDK1.7 update4时引入,在JDK9时取代CMS成为默认的垃圾收集器。它是HotSpot…...

【论文复现】隐式神经网络实现低光照图像增强
📝个人主页🌹:Eternity._ 🌹🌹期待您的关注 🌹🌹 ❀ 隐式神经网络实现低光照图像增强 引言那么目前低光照图像增强还面临哪些挑战呢? 挑战1. 不可预测的亮度降低和噪声挑战2.度量友好…...

Python知识分享第十九天-网络编程
网络编程 概述用来实现 网络互联 不同计算机上运行的程序间可以进行数据交互也叫Socket编程 套接字编程 三要素IP地址概述设备在网络中的唯一标识分类IPV4城域网13广域网22局域网31IPV6八字节 十六进制相关dos命令查看ipwindows: ipconfigmac和linux: ifconfig测试网络ping 域…...

C# 绘制GDI红绿灯控件
C# 绘制GDI红绿灯控件 using System; using System.Windows.Forms; using System.Drawing;public class TrafficLightControl : Control {protected override void OnPaint(PaintEventArgs e){base.OnPaint(e);Graphics g e.Graphics;g.SmoothingMode System.Drawing.Drawin…...

Centos 8 服务器时间校正
Centos 8 服务器时间校正 使用chrony服务自动同步时间: 1.安装chrony: sudo dnf install chrony 2.启动并使chrony服务自动启动: sudo systemctl start chronyd sudo systemctl enable chronyd 3.添加配置置文件/etc/chrony.conf指向了可靠…...
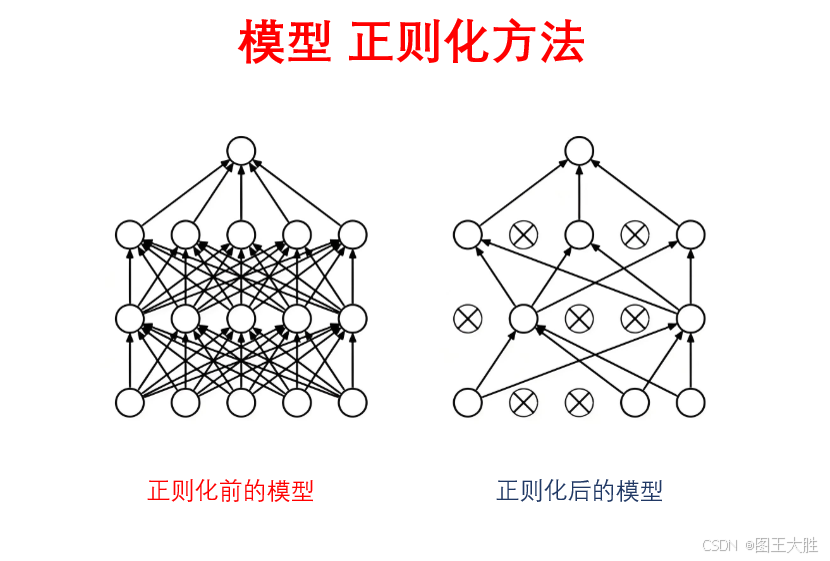
模型 正则化方法(通俗解读)
系列文章 分享 模型,了解更多👉 模型_思维模型目录。控制模型复杂度,防过拟合。 1 正则化方法的应用 1.1 正则化方法在教育领域的应用案例 - 重塑教学模式 背景: 在教育领域,正则化方法可以被理解为对教学模式和学习…...

ffmpeg命令
ffmpeg是专门处理多媒体文件(包括音频、视频)的命令; ffplay 是 ffmpeg 软件包中的一个命令行多媒体播放器,它主要用于播放音视频文件; # fmpeg命令转换格式,将mp3格式转换为wav格式 ffmpeg -i input.mp3…...

使用 EasyExcel 实现高效的 Excel 读写操作
在日常开发中,Excel 文件的读写操作是一个常见的需求。EasyExcel 是阿里巴巴开源的一个高性能、易用的 Excel 读写库,可以大幅提高处理 Excel 文件的效率。它通过事件驱动模型优化了大数据量 Excel 的读写性能,非常适合处理大文件或高并发场景…...

数据结构(栈Stack)
1.前言: 在计算机科学中,栈(Stack)是一种基础而存在的数据结构,它的核心特性是后进先出(LIFO,Last In, First Out)。想象一下,在现实生活中我们如何处理一堆托盘——我们…...

Windows 11 环境下 条码阅读器输入到记事本的内容不完整
使用Windows11时,为什么记事本应用程序中的扫描数据被截断或不完整?为什么sdo 特殊字符的显示与Windows 10 记事本应用程序不同? 很多人认为和中文输入法有关,其实主要问题出在这个windows11下的记事本程序上,大家知道这个就可以了&#x…...

【串口助手开发】visual studio 使用C#开发串口助手,生成在其他电脑上可执行文件,可运行的程序
1、改成Release,生成解决方案 串口助手调试成功后,将Debug改为Release,点击生成解决方案 2、运行exe文件 生成解决方案后,在bin文件夹下, Release文件夹下,生成相关文件 复制一整个Release文件夹…...

Redis设计与实现读书笔记
Redis设计与实现读书笔记 Redis设计与实现[^1]简单动态字符串SDS的基础定义与C字符串的差别常数获取长度杜绝缓冲区溢出减少修改字符串时带来的内存重分配次数二进制安全函数兼容 链表链表和链表节点的实现 字典字典的实现哈希表定义哈希表节点定义字典定义 哈希算法解决键冲突…...

UE5 Do Once 节点
在 Unreal Engine 5 (UE5) 中,Do Once 节点是一个蓝图节点,用于确保某个操作或代码只执行一次,直到某些条件被重置。它通常用于处理需要执行一次的逻辑,例如初始化、事件触发、或防止重复执行某些操作。 如何使用 Do Once 节点&a…...
作为客户端端通过grpc与cpp(服务端)交互)
javascript(前端)作为客户端端通过grpc与cpp(服务端)交互
参考文章 https://blog.csdn.net/pathfinder1987/article/details/129188540 https://blog.csdn.net/qq_45634989/article/details/128151766 前言 临时让我写前端, 一些配置不太懂, 可能文章有多余的步骤但是好歹能跑起来吧 你需要提前准备 公司有自带的这些, 但是版本大都…...

Godot纸牌游戏框架:分层架构与卡牌状态管理
1. 这不是又一个“通用游戏框架”,而是一套专为纸牌游戏设计的骨骼系统你有没有试过在Godot里从零搭一张卡牌游戏?我试过三次——第一次用Node2D硬堆,拖了二十多个场景,连抽卡动画都得手写Tween;第二次改用Resource做卡…...

跨镜头人物ID稳定性不足,深度拆解Sora 2的Temporal Identity Token机制与3层对抗对齐策略
更多请点击: https://kaifayun.com 第一章:跨镜头人物ID稳定性不足的根源诊断 跨镜头人物ID稳定性不足是多目标跟踪(MOT)系统在真实监控场景中面临的核心瓶颈。其本质并非单一模块失效,而是特征表征、时空建模与数据分…...
)
无人超市|基于Java+vue的无人超市管理系统(源码+数据库+文档)
无人超市管理系统 基于SprinBootvue的无人超市管理系统 一、前言 二、系统设计 三、系统功能设计 系统功能实现 后台管理员模块实现 四、数据库设计 五、核心代码 六、论文参考 七、最新计算机毕设选题推荐 八、源码获取: 博主介绍:✌️大厂…...

历史性突破,OpenAI模型搞定人类科学家80年未破难题,能发顶刊了
OpenAI 7个月前曾因虚假数学突破被同行嘲笑。 智东西5月21日报道,今日,OpenAI宣布,其一款未对外发布的内部通用推理模型,独立完成了一份原创数学证明。该证明推翻了匈牙利数学家保罗埃尔德什(Paul Erdős)…...

如何在浏览器中零安装查看SQLite数据库?完全指南
如何在浏览器中零安装查看SQLite数据库?完全指南 【免费下载链接】sqlite-viewer View SQLite file online 项目地址: https://gitcode.com/gh_mirrors/sq/sqlite-viewer 你是否曾遇到过这样的情况:收到一个SQLite数据库文件需要快速查看…...

TwicketSegmentedControl性能优化终极指南:内存管理与渲染技巧深度解析
TwicketSegmentedControl性能优化终极指南:内存管理与渲染技巧深度解析 【免费下载链接】TwicketSegmentedControl Custom UISegmentedControl replacement for iOS, written in Swift 项目地址: https://gitcode.com/gh_mirrors/tw/TwicketSegmentedControl …...

AspectCore-Framework扩展组件全解析:与ASP.NET Core、Autofac、LightInject无缝集成
AspectCore-Framework扩展组件全解析:与ASP.NET Core、Autofac、LightInject无缝集成 【免费下载链接】AspectCore-Framework AspectCore is an AOP-based cross platform framework for .NET Standard. 项目地址: https://gitcode.com/gh_mirrors/as/AspectCore-…...

中兴光猫工厂模式解锁工具:3分钟获得完全控制权
中兴光猫工厂模式解锁工具:3分钟获得完全控制权 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 你是否曾因中兴光猫的限制而无法进行高级配置?想要深度管理设备…...

Parsec虚拟显示驱动实战教程:5步创建完美游戏串流显示环境
Parsec虚拟显示驱动实战教程:5步创建完美游戏串流显示环境 【免费下载链接】parsec-vdd ✨ Perfect virtual display for game streaming 项目地址: https://gitcode.com/gh_mirrors/pa/parsec-vdd Parsec虚拟显示驱动(Parsec VDD)是一…...

服务网格实战:Istio与Linkerd对比选型与落地实践
服务网格实战:Istio与Linkerd对比选型与落地实践 大家好,我是迪哥。服务网格(Service Mesh)是微服务架构的基础设施层,负责服务间的通信、安全、监控和治理。从 Istio 到 Linkerd,我们对比了多种方案&#…...