深度学习笔记——模型压缩和优化技术(蒸馏、剪枝、量化)
本文详细介绍模型训练完成后的压缩和优化技术:蒸馏、剪枝、量化。

文章目录
- 1. 知识蒸馏 (Knowledge Distillation)
- 基本概念
- 工作流程
- 关键技术
- 类型
- 应用场景
- 优势与挑战
- 优势
- 挑战
- 总结
- 2. 权重剪枝 (Model Pruning)
- 基本原理
- 二分类
- 1. 非结构化剪枝(Unstructured Pruning)
- 2. 结构化剪枝(Structured Pruning)
- 常用方法
- 1. 基于权重大小的剪枝(Magnitude-based Pruning)
- 2. 基于梯度的剪枝(Gradient-based Pruning)
- 3. L1/L2 正则化剪枝(Regularization-based Pruning)
- 4. 基于熵的剪枝(Entropy-based Pruning)
- 5. 迭代剪枝与再训练(Iterative Pruning and Fine-tuning)
- 工作流程
- 优势和局限性
- 优势
- 局限性
- 实际应用
- 总结
- 3. 权值量化 (Quantization)
- 基本原理
- 类型
- 1. 静态量化(Post-training Quantization, PTQ)
- 2. 动态量化(Dynamic Quantization)
- 3. 量化感知训练(Quantization-aware Training, QAT)
- 常用方法
- 1. 线性量化
- 2. 非线性量化
- 3. 对称量化和非对称量化
- 4. 小数位量化(Fixed-point Quantization)
- 优势与挑战
- 优势
- 挑战
- 实际应用
- 量化技术总结
- 4. 权重共享 (Weight Sharing)
- 5. 低秩分解 (Low-Rank Factorization)
- 6. 神经架构搜索 (Neural Architecture Search, NAS)
- 其他优化
- 总结
- 应用场景
- 历史文章
- 机器学习
- 深度学习
模型压缩和优化技术是为了在保证模型性能(精度、推理速度等)的前提下,减少模型的体积、降低计算复杂度和内存占用,从而提高模型在资源受限环境中的部署效率。这些技术对于在边缘设备、移动设备等计算资源有限的场景中部署深度学习模型尤为重要。以下是几种常见的模型压缩和优化技术的解释:
1. 知识蒸馏 (Knowledge Distillation)
知识蒸馏是一种通过“教师模型”(通常是一个性能较高但规模较大的模型)来指导“学生模型”(通常是一个较小但高效的模型)训练的技术。其基本思想是让学生模型学习教师模型在输入数据上的输出分布,而不是直接学习真实标签。主要步骤如下:
- 训练教师模型: 首先训练一个大规模的教师模型,该模型通常有很好的性能。
- 蒸馏训练: 使用教师模型的预测结果(软标签)来训练学生模型。通常情况下,学生模型会通过一种称为“蒸馏损失”(Distillation Loss)的函数来最小化其输出与教师模型输出的差异。
- 优势: 知识蒸馏可以有效地提升学生模型的精度,即使学生模型结构相对简单,也能获得接近教师模型的性能。
推荐阅读:一文搞懂【知识蒸馏】【Knowledge Distillation】算法原理
基本概念
知识蒸馏(Knowledge Distillation)是一种将大模型的知识迁移到小模型的方法,旨在保持模型性能的同时,减少模型的参数量和计算复杂度。知识蒸馏广泛用于深度学习中模型压缩和加速的任务,使得小模型能够在有限资源的设备(如手机、嵌入式设备)上高效运行,同时仍保持高精度。
知识蒸馏通过训练一个小模型(学生模型) 来 模仿 一个 大模型(教师模型) 的行为。大模型的输出(通常是类别概率分布或特征表示)作为小模型的“软标签”或监督信号,使小模型能够更好地学习复杂的数据分布。
知识蒸馏可以分为以下几种基本形式:
- 软标签蒸馏:通过教师模型的输出概率作为目标,使得学生模型不仅学习正确的分类,还学习类别之间的相对关系。
- 中间层蒸馏:将教师模型的中间层表示传递给学生模型,使其学习更丰富的特征表示。
- 基于特征的蒸馏:直接从教师模型的隐藏层特征提取知识,并将其应用于学生模型。
工作流程
知识蒸馏的整个流程确保了小模型在有限资源的设备上高效运行,同时保留了教师模型的精度。这种方法被广泛应用于边缘计算、移动应用和其他对计算资源敏感的场景。
| 步骤 | 详细操作 |
|---|---|
| 训练教师模型 | 训练一个高精度的大模型,作为学生模型学习的知识源 |
| 准备软标签 | 通过温度调节生成教师模型的软标签,提供类别间相对关系信息 |
| 构建学生模型 | 设计一个小而高效的模型,用于模仿教师模型的行为 |
| 构建损失函数 | 使用软标签和硬标签损失的组合,以平衡学生模型对硬标签和软标签的学习 |
| 训练学生模型 | 通过前向传播、反向传播和参数更新迭代优化学生模型,模仿教师模型的输出 |
| 评估模型 | 对比教师和学生模型的性能,确保学生模型在效率和精度上的平衡 |
| 部署学生模型 | 导出学生模型到目标平台,进行量化、剪枝等优化,并在真实环境中进行测试 并部署 |
-
训练教师模型
- 目标:知识蒸馏的第一步是训练一个高精度的大模型,也就是教师模型。教师模型通常具有较大的参数量和复杂的结构,能有效学习到数据的复杂模式。
- 训练:教师模型通常在完整数据集上进行标准的监督学习训练,以确保其在任务上的性能足够好(例如分类任务中达到较高的准确率)。教师模型的高精度和强泛化能力为学生模型提供了可靠的“知识源”。
- 优化:教师模型可以使用标准的损失函数(例如分类任务中的交叉熵损失)进行优化。教师模型的最终性能将直接影响学生模型的学习效果,因此需要仔细调优确保教师模型的高质量。
-
准备教师模型的输出
-
目标:在知识蒸馏中,教师模型的输出不再是简单的硬标签(one-hot),而是称为“软标签”的类别概率分布。软标签提供了类别间的细微关系,是学生模型的重要学习目标。
-
温度调节:教师模型的输出通常使用温度调节(temperature scaling)进行平滑。具体来说,教师模型在生成输出的 softmax 概率分布时会加入温度参数 ( T T T ),以平滑各类别之间的概率分布。
-
输出软标签:经过温度调节后的 softmax 输出(软标签)会被保存下来,作为学生模型的目标。软标签比硬标签包含了更多类别间的信息,有助于学生模型更细致地学习数据分布。
-
教师模型生成的软标签的计算公式:

- ( p_i ):第 ( i ) 类的概率(软标签)。
- ( z_i ):第 ( i ) 类的 logit(教师模型输出的未归一化分数)。
- ( T ):温度参数,用于控制软化程度。
-
公式参数解释
Logits( z i z_i zi ):Logits 是教师模型在最后一层但是没有经过 softmax的输出(在应用 softmax 之前),通常表示各类别的非归一化得分。
温度参数( T T T):温度参数用于调节 softmax 函数的输出分布。在知识蒸馏中,通过调整温度参数 ( T T T ) 的值,教师模型可以生成更加平滑的概率分布,从而帮助学生模型学习类别之间的相对关系。
- 当 ( T = 1 T = 1 T=1 ) 时,这个公式就变成了普通的 softmax 函数,输出的概率分布直接对应教师模型对各类别的置信度。
- 当 ( T > 1 T > 1 T>1 ) 时,输出分布变得更加平滑,使得非最大类的概率变得较大,利于学生模型捕捉到类间关系。
温度参数 ( T ) 的作用
- 更高的温度(即 T > 1 T > 1 T>1)会使得 logits 被缩放得更小,从而使 softmax 函数的输出分布更平滑。这意味着各类别的概率差异会缩小,学生模型可以更好地理解不同类别之间的相对关系,而不仅仅关注于概率最高的类别。
- 通过这种方式,学生模型在训练时不仅学习到正确答案的类别标签,还学习到不同类别之间的关系(即类间相似性)。这有助于学生模型在实际应用中对未见数据具有更好的泛化能力。
-
构建学生模型
- 目标:学生模型通常比教师模型小,具有更少的参数量。它的目的是在保持教师模型精度的同时,显著降低计算和存储需求,以便在资源受限的设备(如手机、嵌入式设备)上高效运行。
- 设计:学生模型可以与教师模型具有相同的结构,但层数、参数量较少;也可以是其他架构,甚至与教师模型完全不同。学生模型的设计通常会根据目标硬件的限制来优化,以在保持精度的前提下达到更高的计算效率。
- 初始化:学生模型的权重可以从头初始化,也可以使用预训练模型的权重作为初始状态,以加快训练收敛速度。
-
构建损失函数
- 目标:在知识蒸馏过程中,学生模型不仅要匹配数据集的硬标签(真实标签),还要学习教师模型的软标签(类别概率分布)。
- 组合损失:通常,知识蒸馏的总损失是硬标签损失和软标签损失的加权组合。公式如下:

- 软标签损失(蒸馏损失):软标签损失通常使用 Kullback-Leibler (KL) 散度来衡量教师模型和学生模型输出概率分布之间的差异。KL 散度公式如下:

-
训练学生模型
- 目标:学生模型通过组合损失函数在软标签和硬标签的监督下进行训练。其目标是尽可能接近教师模型的表现。
- 过程:
- 前向传播:将输入数据经过学生模型,得到学生模型的输出概率分布。
- 计算损失:基于软标签损失和硬标签损失的加权组合,计算学生模型的总损失。
- 反向传播和参数更新:使用标准的优化算法(如 SGD 或 Adam)进行反向传播,更新学生模型的参数。
- 超参数调整:在训练学生模型时,温度参数 ( T T T ) 和损失加权系数 ( α \alpha α ) 都会显著影响蒸馏效果。通常通过实验调整,以找到最佳参数配置。
-
评估学生模型
- 目标:在学生模型训练完成后,对其进行评估,检查它的性能是否接近教师模型。评估学生模型的性能可以使用标准的评估指标,如分类任务中的准确率、F1 分数等。
- 对比:评估时,通常将学生模型的性能与教师模型的性能进行对比,确保学生模型在保持高效推理的同时,准确率尽可能接近教师模型。
- 优化:如果学生模型的精度未达到预期,可以调整模型架构、增加训练数据量或调整蒸馏超参数(如 ( T T T ) 和 ( α \alpha α )),然后重新训练。
-
部署学生模型
- 目标:知识蒸馏的最终目的是在性能受限的设备上部署学生模型。因此,部署学生模型时需要考虑计算成本、推理延迟和内存占用等因素。
- 模型导出和优化:根据目标平台(如手机、边缘设备)对模型进行导出和优化。常见的优化方法包括量化、剪枝、加速推理框架(如 TensorRT)等。
- 上线和测试:在真实环境中测试学生模型的表现,确保其推理速度和精度满足应用需求。必要时进行进一步优化和调整。
关键技术
-
温度调节(Temperature Scaling)
- 温度调节是知识蒸馏中的重要技术,常用于教师模型输出的平滑化处理。温度参数 ( T T T ) 增大时,类别概率分布会更加平滑,使学生模型更关注不同类别的相对关系,而不仅仅是最优类别。

- 温度调节是知识蒸馏中的重要技术,常用于教师模型输出的平滑化处理。温度参数 ( T T T ) 增大时,类别概率分布会更加平滑,使学生模型更关注不同类别的相对关系,而不仅仅是最优类别。
-
损失函数设计
- 知识蒸馏中的损失函数一般包括两个部分:一个是学生模型与真实标签之间的交叉熵损失,另一个是学生模型和教师模型的软标签之间的蒸馏损失。
- 蒸馏损失通常使用 Kullback-Leibler (KL) 散度来衡量教师和学生模型输出之间的差异,鼓励学生模型的输出接近教师模型的输出。
-
中间层蒸馏
- 在一些知识蒸馏方案中,不仅将教师模型的输出作为知识来源,还将其中间层特征传递给学生模型,使学生能够学习到更加丰富的表示。
- 通过匹配学生和教师模型的中间层表示,可以显著提升学生模型的表达能力和精度。
类型
-
单教师-单学生蒸馏
- 最基础的知识蒸馏类型,只有一个教师模型和一个学生模型。
- 教师模型通过软标签和中间层表示向学生模型传递知识。
-
多教师蒸馏
- 多个教师模型向单个学生模型提供知识。学生模型学习多个教师模型的组合输出,通常取平均值或加权融合。
- 这种方法可以进一步提升学生模型的泛化能力。
-
自蒸馏(Self-distillation)
- 不需要单独的教师模型,而是通过多轮训练让模型自己学习自己的知识。例如,每轮训练后生成新的软标签,进一步提升模型精度。
- 自蒸馏可用于模型的迭代提升,无需外部教师模型。
-
对比学习蒸馏(Contrastive Distillation)
- 使用对比学习的方法,使得学生模型和教师模型在生成相似样本时的输出更加接近,而在不同样本上输出差异更大。
- 对比学习蒸馏通过增加表示的区分度提升学生模型的效果。
应用场景
-
模型压缩与加速
- 知识蒸馏可以有效压缩模型,使得小模型在准确率接近大模型的同时,计算成本和存储需求大幅减少,适用于嵌入式设备或移动端。
-
迁移学习
- 将教师模型从某一领域迁移到其他相关领域,学生模型可以在新领域中得到更好的泛化表现。
-
多任务学习
- 通过知识蒸馏,可以将一个多任务的教师模型中的知识转移给多个单任务学生模型,使得学生模型在单一任务上表现更好。
-
自监督学习
- 在自监督学习中,知识蒸馏可以帮助模型有效利用未标注数据,进一步提升模型在下游任务中的性能。
优势与挑战
优势
- 有效的模型压缩:知识蒸馏能显著缩小模型规模,同时在准确率上与教师模型接近,适合在资源受限的设备上部署。
- 改进的泛化能力:学生模型通过学习教师模型的输出分布,能够更好地理解数据分布,提高泛化性能。
- 灵活性:知识蒸馏方法适用于多种深度学习任务和模型架构,能与其他模型压缩方法(如剪枝、量化)结合使用。
挑战
- 教师模型依赖:蒸馏效果依赖于教师模型的质量,若教师模型不准确,学生模型可能学到错误的知识。
- 训练时间:蒸馏过程通常需要额外的训练步骤,增加了训练时间和计算资源需求。
- 知识转移的有效性:如何选择最优的蒸馏方法、温度参数以及特征层是一个挑战,需要在不同任务和模型上调整。
总结
知识蒸馏是一种重要的模型压缩方法,通过让小模型(学生模型)学习大模型(教师模型)的知识,达到模型精简和高效推理的目的。它已广泛应用于计算受限环境下的深度学习模型部署,并在迁移学习、多任务学习等场景中表现出色。知识蒸馏仍在持续研究中,未来可能通过结合更多优化方法进一步提升学生模型的效果。
2. 权重剪枝 (Model Pruning)
模型剪枝是一种减少模型冗余参数的方法,通常通过移除对模型性能影响较小的权重或神经元来降低模型的计算复杂度和存储需求。模型剪枝的主要方法包括:
- 非结构化(权重)剪枝 (Weight Pruning): 将小于某个阈值的权重设为零。剪枝后可以使用稀疏矩阵表示模型,从而减少计算量和存储需求。
- 结构剪枝 (Structured Pruning): 移除整个滤波器(卷积核)、通道或层。结构剪枝通常在减少模型复杂度的同时更好地保持模型性能。
- 过程: 先训练一个全量模型,然后根据某种准则(如权重的绝对值、梯度等)进行剪枝,再在剪枝后的模型上进行微调以恢复性能。
- 优势: 剪枝可以大幅度减少模型参数量和计算量,适用于在资源有限的硬件上部署模型。
基本原理
权重剪枝(Weight Pruning)是一种用于深度学习模型压缩的技术,通过移除模型中的冗余权重(连接),来减少模型的参数量和计算量,进而降低内存占用并加速推理速度。权重剪枝主要应用于卷积神经网络(CNN)、循环神经网络(RNN)等结构,可以有效压缩模型,使其更适合在资源受限的设备(如移动端、嵌入式系统)上部署。
在神经网络中,不同权重对模型的输出影响程度不同。权重剪枝的核心思想是通过评估每个权重的重要性,移除对输出影响较小的权重连接。这样不仅能减少参数量,还可以保持模型精度。
权重剪枝通常可以划分为两个步骤:
- 剪枝过程:确定哪些权重不重要并移除。
- 微调(Fine-tuning):剪枝后对模型进行微调,以恢复可能受到损害的精度。
二分类
权重剪枝可以分为 非结构化剪枝 和 结构化剪枝,这两种方式各有优缺点。
1. 非结构化剪枝(Unstructured Pruning)
- 定义:在非结构化剪枝中,模型可以选择性地移除任意不重要的权重,剪枝过程不必遵循特定的结构化规则。
- 原理:通过评估每个权重的大小或梯度,将绝对值较小的权重置零,这些被剪掉的权重被认为对模型输出影响较小。
- 优势:非结构化剪枝的灵活性较高,理论上可以获得很高的剪枝比例。
- 缺点:非结构化剪枝后的权重稀疏性较强,结构不规则,不易直接加速硬件计算;需要专用的稀疏矩阵存储和运算库来支持高效的稀疏性加速。
- 应用场景:通常用于模型压缩,适合不考虑硬件加速的场景,例如压缩存储大小。
2. 结构化剪枝(Structured Pruning)
- 定义:结构化剪枝移除整个特定的权重组,遵循网络的结构化特性。例如,卷积层的通道、滤波器、卷积核、层等,形成更规则的结构化剪枝模式。
- 原理:通过评估神经元或通道的重要性,将不重要的神经元、通道、层进行移除,以减少计算负担。
- 优势:结构化剪枝后模型仍然保持结构完整,能够直接适配硬件加速(如 GPU、TPU 等),实现显著的推理加速。
- 缺点:剪枝过程中约束更多,压缩率和精度的平衡更难把握。
- 应用场景:适用于需要高效推理的场景,例如在边缘设备或移动端部署 CNN。
常用方法
权重剪枝可以基于不同的剪枝标准和方法实现。以下是一些常见的权重剪枝技术:
1. 基于权重大小的剪枝(Magnitude-based Pruning)
- 原理:基于权重的绝对值进行剪枝,通常认为绝对值较小的权重对模型的输出影响较小,因此可以被移除。
- 实现:按比例剪枝(例如剪掉 20% 的权重)或设定剪枝阈值(小于阈值的权重被剪掉),可以通过多轮剪枝迭代提高剪枝比例。
- 优点:实现简单,适用于大多数网络结构。
- 缺点:仅依赖权重的大小进行剪枝,可能忽略一些重要的但权重值小的连接。
2. 基于梯度的剪枝(Gradient-based Pruning)
- 原理:基于梯度对权重重要性的影响来判断是否剪枝。梯度值较小的权重通常对损失函数的影响较小,可以被剪枝。
- 实现:在训练过程中,通过权重的梯度信息评估每个权重的重要性,将梯度绝对值较小的权重剪枝。
- 优点:相比基于大小的剪枝,这种方法能够考虑权重在损失函数中的影响,更具针对性。
- 缺点:需要额外计算梯度信息,计算成本较高。
3. L1/L2 正则化剪枝(Regularization-based Pruning)
- 原理:通过引入 L1 或 L2 正则化项,鼓励模型中的一些权重接近于零,从而达到自动剪枝的效果。
- 实现:在训练过程中将 L1 或 L2 范数作为正则化项加入损失函数,使模型中不重要的权重逐渐变小,接近零后即可剪枝。
- 优点:正则化剪枝可以在训练中逐步实现,无需单独的剪枝步骤。
- 缺点:训练时间会增加,适合剪枝比例较小的情况。
4. 基于熵的剪枝(Entropy-based Pruning)
- 原理:计算每个权重或特征的重要性信息熵,信息熵较低的权重对输出不敏感,可以被移除。
- 实现:评估每个通道、滤波器或权重的信息熵,将信息熵较低的部分进行剪枝。
- 优点:能够精准衡量重要性,适合复杂模型。
- 缺点:计算复杂度较高,适合小规模网络。
5. 迭代剪枝与再训练(Iterative Pruning and Fine-tuning)
- 原理:逐步剪枝模型,避免一次性移除过多权重。每次剪枝后,对模型进行微调,以恢复模型性能。
- 实现:在每轮剪枝后微调模型,逐步提高剪枝比例,达到最大压缩率。
- 优点:保持精度的同时获得较高的压缩率。
- 缺点:剪枝和微调需要多轮迭代,增加训练时间。
工作流程
权重剪枝的基本流程如下:
- 训练基础模型:首先训练一个完整的模型,使其在任务上达到最佳性能。
- 评估权重重要性:选择合适的评估标准(如权重大小、梯度、信息熵等)来判断每个权重或连接的重要性。
- 选择剪枝比例:根据模型的规模、目标设备性能等因素设定剪枝比例(如 20% 的权重)。
- 剪枝不重要的权重:根据评估标准和剪枝比例,移除不重要的权重。可以是一次性剪枝,或者是逐步剪枝。
- 微调模型:剪枝后,通常会对模型进行再训练,以恢复剪枝过程中可能损失的精度。微调步骤可以多次进行,以确保剪枝后的模型保持较好的精度。
- 评估压缩效果:在剪枝和微调完成后,测试剪枝后的模型精度,并与原始模型进行对比,评估剪枝的效果。
优势和局限性
优势
- 显著减少模型参数量:剪枝可以有效减少模型的参数,减小模型存储需求。
- 加速推理速度:特别是结构化剪枝,可以显著减少计算量,实现推理加速。
- 保持较高精度:在适当的剪枝策略下,可以在较小的精度损失下获得高效的压缩效果。
局限性
- 非结构化剪枝难以加速推理:非结构化剪枝得到的稀疏模型结构不易直接在通用硬件上加速,需要稀疏矩阵库支持。
- 剪枝比例与精度的平衡难以把握:过高的剪枝比例可能导致模型性能显著下降。
- 迭代剪枝耗时较长:剪枝和微调过程通常需要多轮迭代,增加训练时间。
实际应用
- 卷积神经网络(CNN):CNN 的大量权重适合剪枝,通过剪枝可以显著减少参数量和卷积计算的开销。
- 循环神经网络(RNN):RNN 中的权重剪枝可用于减少循环网络的计算量,适合语音识别、机器翻译等
任务。
- 全连接层:全连接层的参数量较大,适合进行非结构化剪枝,减少存储需求。
总结
权重剪枝是一种有效的模型压缩技术,通过移除不重要的权重来降低模型的参数量和计算量。根据剪枝方法的不同,剪枝可以在不同程度上加速推理过程,同时保持较高的模型精度。在实际应用中,权重剪枝技术广泛用于模型压缩、推理加速和边缘设备部署中。
3. 权值量化 (Quantization)
量化是指将模型中的浮点数权重和激活值转换为低精度的整数表示(如8-bit)【类似上面提到的DeepSpeed的混合精度】,从而减少模型的存储和计算开销。量化的主要类型有:
- 静态量化 (Static Quantization): 在推理前【训练后】将模型的权重和激活值提前量化。
- 动态量化 (Dynamic Quantization): 推理时激活值根据输入动态量化,推理前权重已经量化。
- 量化感知训练 (Quantization-Aware Training): 在训练过程中考虑量化误差,以减小量化带来的精度损失。
- 优势: 量化可以在保持模型精度的前提下,显著减少模型大小和计算开销,适用于在移动设备和边缘设备上部署。
基本原理
权值量化(Weight Quantization)是一种通过降低模型中权重和激活值的数值精度来压缩模型的技术。量化技术能够显著减少模型的存储需求和计算开销,尤其适合资源受限的硬件设备(如手机、嵌入式系统、FPGA、TPU 等),在保持模型精度的同时大幅提高推理效率。
在传统深度学习中,权值和激活值通常使用 32 位浮点数(FP32)来表示,虽然精度高但计算量大。权值量化的基本思想是将这些 32 位浮点数转换为更低精度的数据类型(如 8 位整数,INT8),从而减少存储和计算的成本。
量化的常见数据类型有:
- INT8:8 位整数,是最常用的量化精度,平衡了性能和精度。
- FP16:16 位浮点数,在部分精度要求较高的场景中使用。
- 其他精度:如 INT4、INT2,甚至二值化(binary),适用于对精度要求较低的场景。
类型
权值量化根据实现的时间点和计算方式不同,可以分为以下几类:
| 量化类型 | 原理 | 优势 | 应用场景 |
|---|---|---|---|
| 静态量化 | 使用一组校准数据计算激活值的动态范围,在推理前将模型的权重和激活值量化为低精度(如 INT8) | 实现简单,推理加速 | 推理任务,适合精度要求较低的模型 |
| 动态量化 | 推理前对权重进行量化,推理时根据输入数据动态量化激活值 | 精度更高,适应实时变化的数据 | NLP 模型中的 RNN、LSTM 等,输入分布变化较大的任务 |
| 量化感知训练 | 在训练过程中对权重和激活值模拟量化误差,使用伪量化方法使模型在训练时适应量化的效果 | 精度损失最小,适合复杂模型 | 高精度模型(CNN、Transformer),适合需要保持高精度的任务 |
1. 静态量化(Post-training Quantization, PTQ)
静态量化是在模型训练完成后,将模型的权重和部分激活值量化为低精度的整数。这种方法不需要在训练中进行额外的调整,因此也称为后量化。
- 工作流程:
- 训练出完整精度模型。
- 将模型的权重和激活值量化为低精度。
- 在推理时直接使用量化后的模型进行计算。
- 优点:实现简单,不需要重新训练。
- 缺点:精度可能有所损失,尤其是对于复杂或精度要求较高的模型。
2. 动态量化(Dynamic Quantization)
动态量化是在推理时对部分激活值进行动态量化。通常在推理前(模型训练完成后)对模型的权重进行静态量化的(如 INT8),而在推理过程中对激活值进行动态量化(如 FP32 转换为 INT8),以减少量化误差。
- 工作流程:
- 训练完成后,对权重进行静态量化。
- 在推理时,根据当前输入动态量化激活值。
- 优点:相比静态量化有更好的精度保持。
- 缺点:计算复杂度增加,对推理速度有一定影响。
3. 量化感知训练(Quantization-aware Training, QAT)
量化感知训练是一种在训练阶段就考虑到量化影响的技术。QAT 在训练过程中引入量化噪声,对权重和激活值进行模拟量化,使模型逐步适应低精度表示。这样可以最大程度地减少量化带来的精度损失,是目前精度最高的量化方法。
- 工作流程:
- 在训练中加入量化模拟,即引入量化操作模拟推理中的低精度计算。
- 训练过程调整模型权重,使其更适应量化后的推理环境。
- 优点:量化精度最高,可以减少精度损失。
- 缺点:训练时间增加,需要更多的计算资源。
量化感知训练工作流程如下:
基础模型训练:训练一个完整精度模型,使其达到预期的高精度表现。
插入量化节点:在网络中加入量化操作,在每层后添加量化模拟,使模型在前向传播时模拟低精度计算的影响。
训练模型适应量化:在加入量化模拟的模型上继续训练,优化模型权重,使其逐步适应量化带来的精度损失。
量化模型参数:将最终训练得到的权重量化为整数表示,保存模型。
推理优化:部署到硬件上使用量化推理优化,使得模型在计算和存储方面都更高效。
混合精度训练就是量化感知。
常用方法
权值量化的实现方法通常包括线性量化、非线性量化、对称量化和非对称量化等,每种方法在精度和计算开销上有所不同。
| 量化方式 | 原理 | 优势 | 应用场景 |
|---|---|---|---|
| 线性量化 | 使用线性映射将权重和激活值缩放到低精度区间 | 实现简单,适合硬件加速 | 数据分布均匀的模型和任务,适合常规计算场景 |
| 非线性量化 | 采用对数或分段线性方法,将权重和激活值映射到低精度区间,以适应数据分布 | 减少量化误差,适合数据分布不均的模型 | 稀疏网络、复杂分布数据,适合对精度要求高的模型 |
| 对称量化 | 将正负数的量化范围对称,适用于数据分布对称的情况 | 实现简单,硬件友好 | 数据均匀分布的模型,适合标准硬件加速 |
| 非对称量化 | 使用不同的量化范围来覆盖正负数据,适用于数据分布不均的情况 | 适应性强,减少量化误差 | 数据分布不均的模型,适合高精度模型的量化 |
| 小数位量化 | 使用小数位来表示权重和激活值,适合存储精度较低的数据 | 节省存储空间,适合小范围权重 | 精度要求低、权重小范围变化的模型,适合轻量化模型部署 |
1. 线性量化
线性量化(Uniform Quantization)将权重映射到固定的低精度区间,例如将 FP32 权重映射到 INT8。具体过程如下:

- 优缺点:
- 线性量化实现简单,适用于硬件加速。
- 但对于分布不均匀的权重(如稀疏分布)会产生较大误差。
2. 非线性量化
非线性量化(Non-uniform Quantization)使用不同的步长或非均匀分布来量化权重,可以减少量化误差,尤其在数据分布不均匀时更有效。
- 实现:例如使用对数分布或自适应区间来量化,更多关注重要的权重区间。
- 优缺点:非线性量化可以有效减少误差,但计算和实现复杂,硬件支持有限。
3. 对称量化和非对称量化
- 对称量化(Symmetric Quantization):零点 ( z = 0 ),量化步长相同,适用于分布均匀的权重。
- 非对称量化(Asymmetric Quantization):零点 ( z 不等于 0 ),正负区间的步长不同,适合分布不均的权重。
4. 小数位量化(Fixed-point Quantization)
对于权重取值范围较小的情况,可以直接将权重映射到固定的小数位数上,这样既可以减少存储开销,也便于硬件计算。
优势与挑战
优势
- 内存节省:量化将 32 位浮点数转换为更低精度的数据类型(如 8 位整数),大幅减少模型的存储需求。
- 加速计算:低精度整数计算相比浮点数计算更高效,在专用硬件(如 TPU、FPGA)上能进一步加速推理过程。
- 能源效率:低精度计算的能耗显著降低,特别适合移动设备和嵌入式设备。
挑战
- 精度损失:量化会引入近似误差,对精度要求高的模型可能导致性能下降,尤其是静态量化方法。
- 不均匀分布:模型权重和激活值可能存在不均匀分布,线性量化可能无法很好地拟合这些分布,导致量化误差较大。
- 硬件支持:不同硬件平台对量化支持程度不同,需要在选择数据格式和量化方法时考虑目标设备的硬件特性。
实际应用
权值量化技术在多个深度学习任务和模型中得到了广泛应用:
- 计算机视觉:在 CNN 中广泛应用于图像分类、目标检测、图像分割等任务,以加速模型的推理过程。
- 自然语言处理:在 Transformer 等模型中,对注意力层和自注意力计算量化,减少大模型在推理中的存储和计算开销。
- 边缘计算与移动应用:量化技术非常适合资源受限的设备,例如手机、智能摄像头等,需要节省能耗和存储的场景。
- 实时推理:量化后的模型在实际部署中推理速度更快,适合要求低延迟的应用场景,如实时监控、自动驾驶等。
量化技术总结
权值量化是深度学习模型优化的重要技术,在移动设备、嵌入式系统和低功耗设备上部署深度学习模型时有着广泛的应用。量化感知训练(QAT)是当前精度保持最好的量化方法,静态量化则适合模型部署的快速应用。选择合适的量化方法可以在性能和精度之间取得良好平衡,使得深度学习模型在实际应用中更加高效。
4. 权重共享 (Weight Sharing)
权重共享是一种将多个模型参数共享相同的权重,从而减少模型参数数量的方法。常用于压缩神经网络和减少参数冗余。
- 过程: 训练过程中,将模型中多个类似参数强制约束为相同的值或从一个小的候选集(如哈希表)中选择。
- 优势: 权重共享可以大幅度减少模型参数量,从而节省存储空间和计算资源。
5. 低秩分解 (Low-Rank Factorization)
低秩分解是一种将模型参数矩阵分解为多个低秩矩阵的乘积,从而减少计算量和存储需求的方法。常用于压缩大型全连接层和卷积层。
- 过程: 将一个大的权重矩阵分解为两个或多个小的矩阵的乘积,这些小矩阵的秩比原矩阵低得多。
- 优势: 低秩分解可以显著减少矩阵乘法的计算量,提高推理速度。
6. 神经架构搜索 (Neural Architecture Search, NAS)
NAS是一种自动设计高效神经网络结构的方法,通过搜索算法(如强化学习或进化算法)自动寻找性能与效率兼具的模型架构。
- 过程: 定义一个模型结构搜索空间,使用搜索算法在这个空间中找到最优的模型结构。
- 优势: NAS可以自动化地找到高效且适合特定硬件或任务的模型架构,减少人工设计的复杂性。
这些技术可以单独使用,也可以组合使用,以在特定应用场景中最大化模型的效率和性能。
其他优化
在处理大型数据集时,Transformer模型可以通过以下几种方法加以优化
- 使用分布式训练
- 数据预处理与数据增强
- 混合精度训练
- 逐步增加数据集规模
总结
| 方法 | 主要目的 | 优点 | 缺点 |
|---|---|---|---|
| 剪枝 | 去除冗余参数 | 显著减小模型大小 | 可能导致结构不规则 |
| 量化 | 降低参数精度 | 显著减少存储需求 | 可能导致精度损失 |
| 知识蒸馏 | 训练轻量学生模型 | 性能接近大模型 | 训练需要教师模型 |
| 低秩分解 | 分解权重矩阵 | 降低计算量 | 适用性不广泛 |
| NAS | 自动设计轻量架构 | 高效模型,自动化 | 搜索成本高 |
应用场景
模型压缩技术广泛应用于移动设备、嵌入式系统和其他计算资源受限的场景,适合需要在有限资源下部署深度学习模型的情况。
历史文章
机器学习
机器学习笔记——损失函数、代价函数和KL散度
机器学习笔记——特征工程、正则化、强化学习
机器学习笔记——30种常见机器学习算法简要汇总
机器学习笔记——感知机、多层感知机(MLP)、支持向量机(SVM)
机器学习笔记——KNN(K-Nearest Neighbors,K 近邻算法)
机器学习笔记——朴素贝叶斯算法
机器学习笔记——决策树
机器学习笔记——集成学习、Bagging(随机森林)、Boosting(AdaBoost、GBDT、XGBoost、LightGBM)、Stacking
机器学习笔记——Boosting中常用算法(GBDT、XGBoost、LightGBM)迭代路径
机器学习笔记——聚类算法(Kmeans、GMM-使用EM优化)
机器学习笔记——降维
深度学习
深度学习笔记——优化算法、激活函数
深度学习——归一化、正则化
深度学习——权重初始化、评估指标、梯度消失和梯度爆炸
深度学习笔记——前向传播与反向传播、神经网络(前馈神经网络与反馈神经网络)、常见算法概要汇总
深度学习笔记——卷积神经网络CNN
深度学习笔记——循环神经网络RNN、LSTM、GRU、Bi-RNN
深度学习笔记——Transformer
深度学习笔记——3种常见的Transformer位置编码
深度学习笔记——GPT、BERT、T5
深度学习笔记——ViT、ViLT
深度学习笔记——DiT(Diffusion Transformer)
深度学习笔记——多模态模型CLIP、BLIP
深度学习笔记——AE、VAE
深度学习笔记——生成对抗网络GAN
深度学习笔记——模型训练工具(DeepSpeed、Accelerate)
相关文章:
深度学习笔记——模型压缩和优化技术(蒸馏、剪枝、量化)
本文详细介绍模型训练完成后的压缩和优化技术:蒸馏、剪枝、量化。 文章目录 1. 知识蒸馏 (Knowledge Distillation)基本概念工作流程关键技术类型应用场景优势与挑战优势挑战 总结 2. 权重剪枝 (Model Pruning)基本原理二分类1. 非结构化剪枝(Unstructur…...

开发手札:Win+Mac下工程多开联调
最近完成一个Windows/Android/IOS三端多人网络协同项目V1.0版本,进入测试流程了。为了方便自测,需要用unity将一个工程打开多次,分别是Win/IOS/Android版本,进行多角色联调。 在Win开发机上,以Windows版本为主版…...
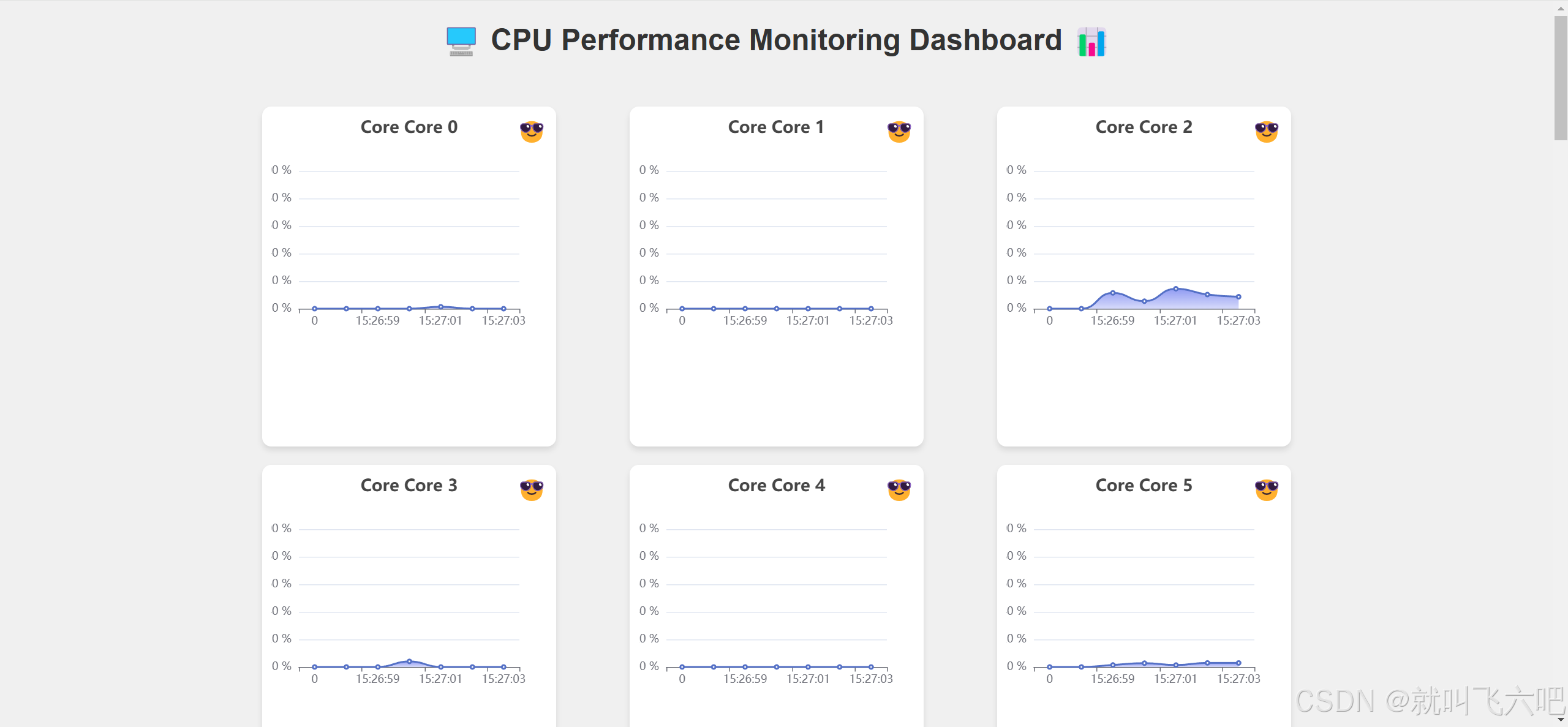
项目基于oshi库快速搭建一个cpu监控面板
后端: <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>com.github.oshi</groupId><artifactId>oshi-…...

【c语言】指针3
1、字符指针变量 指针类型中我们知道有一种为字符指针char*的指针类型,其使用方法如下: 上面我们是先将字符使用一个变量,然后将变量的地址传给一个字符指针变量,通过指针变 量实现了对这个字符的打印。还有下面的这种…...
【开源】A063—基于Spring Boot的农产品直卖平台的设计与实现
🙊作者简介:在校研究生,拥有计算机专业的研究生开发团队,分享技术代码帮助学生学习,独立完成自己的网站项目。 代码可以查看项目链接获取⬇️,记得注明来意哦~🌹 赠送计算机毕业设计600个选题ex…...

Can‘t find variable: token(token is not defined)
文章目录 例子 1:使用 var例子 2:使用 let 或 const例子 3:异步操作你的代码中的情况 Cant find variable: tokentoken is not defined源代码 // index.jsPage({data: {products:[],cardLayout: grid, // 默认卡片布局为网格模式isGrid: tr…...

【JavaEE 初阶】⽹络编程套接字
一、⽹络编程基础 1.应用层 操作系统提供的一组 api >socket api(传输层给应用层提供) 2.传输层 两个核心协议. TCPUDP 差别非常大,编写代码的时候,也是不同的风格 因此, socket api 提供了两套 TCP 有连接, 可靠传输, 面向字节流, 全双工 UDP …...

【Linux内核】Hello word程序
创建测试目录 mkdir -p ~/develop/kernel/hello-1 cd ~/develop/kernel/hello-1 创建MakeFile文件和内核.c文件 nano Makefile nano hello-1.c 编写内容 /* * hello-1.c - The simplest kernel module. */ #include <linux/module.h> /* Needed by all modules */…...

PHP 与 MySQL 搭配的优势
一、PHP 与 MySQL 搭配的优势 强大的动态网页开发能力 PHP 是一种服务器端脚本语言,能够生成动态网页内容。它可以根据用户的请求、数据库中的数据等因素,实时地生成 HTML 页面返回给客户端浏览器。而 MySQL 是一个流行的关系型数据库管理系统…...

深入浅出:PHP中的变量与常量全解析
文章目录 引言理解变量普通变量赋值操作变量间赋值引用赋值取消引用 可变变量预定义变量 理解常量声明常量使用define()函数const关键字 使用常量预定义常量 扩展话题:作用域与生命周期实战案例总结与展望参考资料 引言 在编程的世界里,变量和常量是两种…...

初步简单的理解什么是库,什么是静态库,什么是动态库
库是什么 库根据名字我们应该很容易理解,在我们日常生活种,包含库的东西有很多,像仓库,库房那些,库是拿来存放,方便管理东西的,在我们编程当中,库的定义也是如此 那么为什么要有库…...
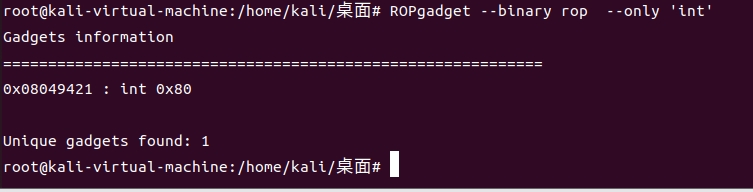
从ctfwiki开始的pwn之旅 3.ret2syscall
ret2syscall 原理 ret2syscall,即控制程序执行系统调用,获取 shell。 那么ret2text——程序中有system("/bin/sh")代码段,控制流执行 那么ret2shellcode——程序中不存在system("/bin/sh/")的代码段,自己…...

使用 httputils + protostuff 实现高性能 rpc
1、先讲讲 protostuf protostuf 一直是高性能序列化的代表之一。但是用起来,可难受了,你得先申明 protostuf 配置文件,并且要把这个配置文件转成类。所以必然要学习新语法、新工具。 可能真的太难受了!于是乎,&#…...

系统思考—战略共识
最近与和一位企业创始人深度交流时,他告诉我:“虽然公司在制定战略时总是非常明确,但在执行过程中,经常发现不同层级对战略的理解偏差,甚至部分团队的执行效果与预期大相径庭。每次开会讨论时,大家都说得头…...

Java版-速通数据结构-树基础知识
现在面试问mysql,红黑树好像都是必备问题了。动不动就让手写红黑树或者简单介绍下红黑树。然而,我们如果直接去看红黑树,可能会一下子蒙了。在看红黑树之前,需要先了解下树的基础知识,从简单到复杂,看看红黑树是在什么…...

详尽的oracle sql函数
1,CHR 输入整数,返回对应字符。 用法:select chr(65),chr(78) from dual; 2,ASCII 输入字符,返回对应ASCII码。 用法:select ascii(A),ascii(B) from dual; 3,CONCAT 输入两个字符串,…...

SAP IDOC Error VG205
今天在做IDOC 入栈处理销售订单的时候,一直报错VG205 There is no article description for item 000030 这个问题在通过WE19 前台显示的时候就不会遇见, 只有在接口传输的时候才会遇到 搜索发现,可以通过配置忽略此消息号 配置路径如下…...
DSP 的 CV 算子调用
01 前言 DSP 是 征程 5 上的数字信号处理器,专用于处理视觉、图像等信息。在 OE 包的 ddk/samples/vdsp_rpc_sample 路径下,提供了 DSP 使用示例,包括 nn 和 CV 两部分。 nn 示例涵盖了深度学习模型的相关算子,包括量化、反量化、…...
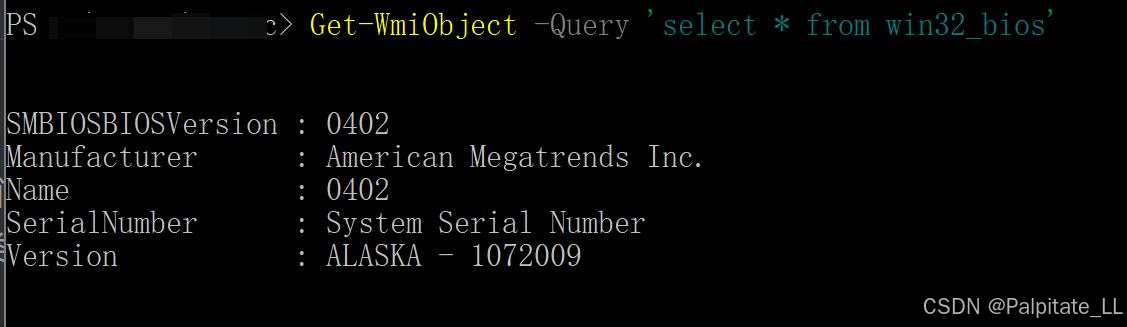
WMI攻击-基础篇(一)
#WMI攻击-基础篇(一) 这篇文章是关于WMI攻击系列文章的第一部分,面向新手。如果对Powershell有一定了解会对阅读本文有所帮助,但这并不是必需的,我们直接上干货。 #1、概述 为什么是WMI? WMI 是 Microso…...

使用Pygame创建一个简单的消消乐游戏
消消乐游戏是一种经典的益智游戏,玩家通过交换相邻的方块来形成三个或更多相同颜色的连续方块,从而消除它们。本文将介绍如何使用Python的Pygame库来创建一个简单的消消乐游戏。 准备工作 在开始之前,请确保已安装Pygame库。可以通过以下命…...

2025最权威的五大降重复率神器实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 处于内容营销范畴当中,标题属于勾引用户去点击的首个关卡。伴随AIGC也就是人工智…...

树莓派4B内存分配翻车实录:给GPU 512MB导致libcamera拍照报错‘内存不足’?
树莓派4B内存分配陷阱:GPU设置如何影响libcamera性能 树莓派4B作为一款功能强大的单板计算机,其8GB内存版本尤其受到开发者和创客的青睐。然而,许多用户在尝试使用libcamera进行高性能图像捕获时,会遇到一个令人困惑的问题&#x…...

OpenWrt opkg配置进阶:手把手教你设置代理、跳过证书检查,解决国内下载慢问题
OpenWrt opkg高效配置指南:突破网络限制的实战技巧 每次在OpenWrt上安装软件时,看着缓慢的下载进度条或者突如其来的连接错误,是不是感觉既熟悉又无奈?作为一款强大的路由器操作系统,OpenWrt的opkg包管理器本该是我们的…...

精密运放ADA4091-2驱动能力不够?试试‘复合放大器’这招,带宽和带载能力都翻倍
精密运放驱动能力不足的终极解决方案:复合放大器架构深度解析 在精密信号链设计中,工程师们常常面临一个两难选择:要么选择ADA4091-2这类具有超低噪声和卓越直流性能的精密运放,但牺牲驱动能力;要么选用大电流运放&…...

NoFences桌面整理工具:5步打造高效整洁的Windows桌面
NoFences桌面整理工具:5步打造高效整洁的Windows桌面 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 还在为Windows桌面上杂乱无章的图标而烦恼吗?NoF…...

从零到一:AI 3D建模革命,5分钟让图片“活“起来的完整实战指南
从零到一:AI 3D建模革命,5分钟让图片"活"起来的完整实战指南 【免费下载链接】TripoSR TripoSR: Fast 3D Object Reconstruction from a Single Image 项目地址: https://gitcode.com/GitHub_Trending/tr/TripoSR 你是否曾梦想过&#…...
:实现AI草图→虚拟缝合→力学模拟零损转换)
Midjourney × CLO 3D无缝协同方案(工业级打版前必读):实现AI草图→虚拟缝合→力学模拟零损转换
更多请点击: https://kaifayun.com 第一章:Midjourney CLO 3D无缝协同方案(工业级打版前必读):实现AI草图→虚拟缝合→力学模拟零损转换 在高精度服装数字样衣开发流程中,Midjourney生成的创意草图常因缺…...
)
Logisim新手避坑指南:手把手搞定头歌平台偶校验解码电路(附完整data.circ文件配置)
Logisim新手避坑指南:手把手搞定头歌平台偶校验解码电路 第一次打开Logisim时,那个简陋的界面和密密麻麻的逻辑门可能会让你望而生畏。更不用说还要在头歌平台上完成偶校验解码电路的评测——光是看到"找不到GB2312ROM.circ"的报错就足以让大多…...

终极指南:使用Play Integrity API Checker保护你的Android应用安全
终极指南:使用Play Integrity API Checker保护你的Android应用安全 【免费下载链接】play-integrity-checker-app Get info about your Device Integrity through the Play Intergrity API 项目地址: https://gitcode.com/gh_mirrors/pl/play-integrity-checker-a…...

JeecgBoot 低代码平台:协同工作与 Flowable 流程审批,如何选?
JeecgBoot 低代码平台两模块引困惑很多团队在接入 JeecgBoot 低代码平台后,面对 "协同工作" 和 "Flowable 流程审批" 两个模块时常常陷入困惑:两个都是处理审批流程的,到底用哪个?能混着用吗?设计…...