Java版-速通数据结构-树基础知识
现在面试问mysql,红黑树好像都是必备问题了。动不动就让手写红黑树或者简单介绍下红黑树。然而,我们如果直接去看红黑树,可能会一下子蒙了。在看红黑树之前,需要先了解下树的基础知识,从简单到复杂,看看红黑树是在什么场景下出现的,是哪种东西。
本文主要是介绍二叉树,二叉搜索树,然后到高度平衡二叉树,根据树的基本操作和特点,帮助理解那些特殊结构的树,是怎样演化而来的。
二叉树(Binary tree)基本概念
二叉树(Binary tree)是树形结构的一个重要类型。看它这名字,就是最多有俩叉的一种特殊的树形结构。通常,它的俩叉分别叫做左子树和右子树。
对二叉树的结构定义如下:
public class TreeNode {public int val;public TreeNode left;public TreeNode right;public TreeNode(int x) {val = x;}
}
二叉树的遍历

前序遍历
前序遍历首先访问根节点,然后遍历左子树,最后遍历右子树。
例如,对于如上图二叉树,访问的先后顺序依次是:FBADCEGIH。
下面使用简单递归来写个:
//前序遍历首先访问根节点,然后遍历左子树,最后遍历右子树public List<Integer> preorderTraversal(TreeNode root) {List<Integer> result = new ArrayList<>();generate(root, result);return result;}private void generate(TreeNode root, List<Integer> result) {if (root == null) {return;}result.add(root.val);if (root.left == null && root.right == null) {return;}if (root.left != null) {generate(root.left, result);}if (root.right != null) {generate(root.right, result);}}
中序遍历
中序遍历是先遍历左子树,然后访问根节点,然后遍历右子树。
例如,对于如上图二叉树,访问的先后顺序依次是:ABCDEFGHI。
public List<Integer> inorderTraversal(TreeNode root) {List<Integer> result = new ArrayList<>();inorderTraversal(root, result);return result;}/*** 递归方式求解** @param root* @param result*/void inorderTraversal(TreeNode root, List<Integer> result) {if (root.left != null) {inorderTraversal(root.left, result);}result.add(root.val);if (root.right != null) {inorderTraversal(root.right, result);}}
后序遍历
后序遍历是先遍历左子树,然后遍历右子树,最后访问树的根节点。
例如,对于如上图二叉树,访问的先后顺序依次是:ACEDBHIGF。
public List<Integer> postorderTraversal(TreeNode root) {List<Integer> result = new ArrayList<>();generate(root, result);return result;}/*** 递归方法** @param root* @param result*/private void generate(TreeNode root, List<Integer> result) {//后序遍历是先遍历左子树,然后遍历右子树,最后访问树的根节点if (root == null) {return;}if (root.left != null) {generate(root.left, result);}if (root.right != null) {generate(root.right, result);}result.add(root.val);}层次遍历
层序遍历就是逐层遍历树结构。
例如,对于如上图二叉树,访问的先后顺序依次是:FBGADICEH。
public List<List<Integer>> levelOrder(TreeNode root) {List<List<Integer>> result = new ArrayList<>();if (root == null) {return result;}Queue<TreeNode> queue = new LinkedList<>();queue.add(root);while (!queue.isEmpty()) {int size = queue.size();List<Integer> item = new ArrayList<>();for (int i = 0; i < size; i++) {TreeNode n = queue.poll();item.add(n.val);if (n.left != null) {queue.add(n.left);}if (n.right != null) {queue.add(n.right);}}result.add(item);}return result;}
二叉树的深度
二叉树的深度为根节点到最远叶子节点的最长路径上的节点数。
是不是通过上面对于二叉树的遍历,发现,二叉树用递归方法,简直是太好写了,下面我们对这个深度的求解也使用递归:
int answer = 0;public int maxDepth(TreeNode root) {if (root == null) {return 0;}int depth = 1;depth(root, depth);return answer;}private void depth(TreeNode root, int depth) {if (root.left == null && root.right == null) {answer = Math.max(answer, depth);}if (root.left != null) {depth(root.left, depth + 1);}if (root.right != null) {depth(root.right, depth + 1);}}
到这里我们会发现,对于二叉树的遍历操作,几乎都可以用递归来解决,超简单呀。
二叉搜索树(BinarySearchTree)
BST 定义
BST是二叉树的一种特殊表示形式,它满足如下特性:
- 1,每个节点中的值必须大于(或等于)存储在其左侧子树中的任何值
- 2,每个节点中的值必须小于(或等于)存储在其右子树中的任何值
我们可以把BST看成是进化了的二叉树。而且观察BST的这个特点,是不是让你想起来我们之前说过的数组的二分法,利用二分法对有序数组进行查找,可以提高搜索效率。如果对BST进行搜索,我们也可以充分利用BST的特征。
验证BST
对于二叉树,我们可以进行中序遍历(左中右),观察遍历得到的值是不是从小到大排列,可以使用此点验证二叉搜索树;
LinkedList<Integer> data = new LinkedList<>();public boolean isValidBST(TreeNode root) {if (root == null) {return true;}if (root.left != null && !isValidBST(root.left)) {return false;}//左中右遍历,让值依次增大即可if (!data.isEmpty()) {Integer n = data.peekLast();if (n >= root.val) {return false;}}data.add(root.val);if (root.right != null && !isValidBST(root.right)) {return false;}return true;}
BST基本操作
搜索
搜索的具体思路跟二分法也是蜜汁类似,不懂二分法的请翻看我以前写的关于数组的基本操作。
对于BST来说,如果当前比较数值过小,往右搜索,过大,往左搜索。
public TreeNode searchBST(TreeNode root, int val) {if (root == null) {return null;}if (root.val == val) {return root;}if (root.val > val && root.left != null) {return searchBST(root.left, val);}if (root.val < val && root.right != null) {return searchBST(root.right, val);}return null;}
插入
对于插入操作也是一样的,在比较的基础上,找到合适的位置,哈哈。
public TreeNode insertIntoBST(TreeNode root, int val) {if (root == null) {return root;}if (root.val > val && root.left == null) {root.left = new TreeNode(val);return root;}if (root.val < val && root.right == null) {root.right = new TreeNode(val);return root;}if (root.left != null && root.val > val) {insertIntoBST(root.left, val);}if (root.right != null && root.val < val) {insertIntoBST(root.right, val);}return root;}
删除
对于删除操作,可能比上面两种操作相对复杂一点。
-
- 如果目标节点没有子节点,我们可以直接移除该目标节点。
-
- 如果目标节只有一个子节点,我们可以用其子节点作为替换。
-
- 如果目标节点有两个子节点,我们需要用其中序后继节点或者前驱节点来替换,再删除该目标节点。
对于 1 和 2,很好理解。对于3,我们先来看一个结点,值的大小顺序为:左<中<右,如果我们要删除中间结点并且还要保持这个顺序不变,则我们有两个方法:1,使用左侧树的最大值去掉中间结点;2,使用右侧最小值取代中间结点。这样才能使得转变之后的树还满足BST的特征。
代码如下:
/*** @param root* @param key* @return*/public TreeNode deleteNode(TreeNode root, int key) {if (root == null) {return root;}if (root.val == key) {if (root.left == null && root.right == null) {return null;}if (root.left == null) {root = root.right;return root;}if (root.right == null) {root = root.left;return root;}root = getLeftChildMaxNode(root);return root;}if (root.val > key) {root.left = deleteNode(root.left, key);return root;}if (root.val < key) {root.right = deleteNode(root.right, key);return root;}return root;}/*** 转变右子树最小结点** @param root* @return*/private TreeNode getRightChildMinNode(TreeNode root) {if (root == null) {return root;}TreeNode left = root.left;TreeNode right = root.right;if (right.left == null) {right.left = left;return right;}//root的left直接挪到root.left的最小结点上TreeNode temp = right.left;while (temp.left != null) {temp = temp.left;}temp.left = left;return right;}/*** 转变左子树最大结点** @return*/private TreeNode getLeftChildMaxNode(TreeNode root) {if (root == null) {return root;}TreeNode left = root.left;TreeNode right = root.right;if (left.right == null) {left.right = right;return left;}TreeNode temp = left.right;while (temp.right != null) {temp = temp.right;}temp.right = right;return left;}
高度平衡二叉树
一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过1。
如果二叉搜索树的高度为 h ,则时间复杂度为 O(h) 。所以,二叉搜索树的高度的确很重要。对于一个有N个结点,高度为h的二叉树,h>= l o g 2 n {log_2{n}} log2n。对于具有 N 个节点的二叉搜索树的高度在 logN 到 N 区间变化。也就是说,搜索操作的时间复杂度可以从 logN 变化到 N 。这是一个巨大的性能差异。所以,我们应该尽量把二叉搜索树,往高度平衡的二叉搜索树上靠,来提高搜索效率。
高度平衡二叉树验证
emm,还是递归,超简单,按照定义写即可:
Boolean res = true;public boolean isBalanced(TreeNode root) {singleBalanced(root);return res;}int singleBalanced(TreeNode root) {if (root == null) {return 0;}int left = singleBalanced(root.left) + 1;int right = singleBalanced(root.right) + 1;if (Math.abs(left - right) > 1) {res = false;}return Math.max(left, right);}
有序数组转换成高度平衡二叉搜索树
我们取数组的中间元素作为根结点, 将数组分成左右两部分,对数组的两部分用递归的方法分别构建左右子树。
感觉其实是二分法的反作用。
这个可以用于对于普通二叉搜索树,先用中序遍历,生成有序数组,之后,将有序数组构建成高度平衡二叉树。
这是采用拆解重构建的方式构造高度平衡二叉树的一种方法。之后,我们还会介绍通过调整普通二叉搜索树,构建高度平衡二叉树或者近似于高度平衡二叉树的方法。
public TreeNode sortedArrayToBST(int[] nums) {if (nums == null || nums.length == 0) {return null;}return build(nums, 0, nums.length - 1);}TreeNode build(int[] nums, int left, int right) {if (left == right) {return new TreeNode(nums[left]);}int mid = (left + right) / 2;TreeNode root = new TreeNode(nums[mid]);if (left + 1 == right) {root.right = new TreeNode(nums[right]);return root;}if (left + 2 == right) {root.left = new TreeNode(nums[left]);root.right = new TreeNode(nums[right]);return root;}root.left = build(nums, left, mid - 1);root.right = build(nums, mid + 1, right);return root;}
N叉树
N叉树:一个结点有N个叉,哈哈。
二叉树属于N叉树的一个特例。
结点定义:
class Node {public int val;public List<Node> children;public Node() {}public Node(int _val, List<Node> _children) {val = _val;children = _children;}}
N叉树的遍历
前序遍历
public List<Integer> preorder(Node root) {List<Integer> res = new ArrayList<>();if (root == null) {return res;}res.add(root.val);if (root.children == null || root.children.size() < 1) {return res;}for (Node n : root.children) {List<Integer> items = preorder(n);res.addAll(items);}return res;}
后序遍历
/*** 递归方法** @param root* @return*/public List<Integer> postorder(Node root) {List<Integer> res = new ArrayList<>();if (root == null) {return res;}postorder(root, res);return res;}void postorder(Node root, List<Integer> res) {if (root.children == null) {res.add(root.val);return;}for (Node n : root.children) {postorder(n, res);}res.add(root.val);}
层序遍历
public List<List<Integer>> levelOrder(Node root) {List<List<Integer>> res = new ArrayList<>();if (root == null) {return res;}Queue<Node> queue = new LinkedList<>();queue.add(root);while (!queue.isEmpty()) {int size = queue.size();List<Integer> data = new ArrayList<>();for (int i = 0; i < size; i++) {Node node = queue.poll();data.add(node.val);if (node.children != null && node.children.size() > 0) {queue.addAll(node.children);}}res.add(data);}return res;}
前缀树
前缀树定义

前缀树特点:
- 根节点不包含字符,除根节点外每一个节点都只包含一个字符;
- 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串;
- 每个节点的所有子节点包含的字符都不相同。
下面为两种常用前缀树的结构:
1,使用数组来存储后缀结点:
class TrieNode {public static final int N = 26;public TrieNode[] children = new TrieNode[N];// ......}
2,使用map来存储后缀结点:
class TrieNode {public Map<Character, TrieNode> children = new HashMap<>();// ......
};
实现前缀树的插入和搜索
class Trie {private Map<Character, TrieNode> data = new HashMap<>();public Trie() {}public void insert(String word) {if (word == null || word.isEmpty()) {return;}if (search(word)) {return;}char[] words = word.toCharArray();char head = words[0];TrieNode currt = data.get(head);if (currt == null) {currt = new TrieNode(head);data.put(head, currt);}for (int i = 1; i < words.length; i++) {char c = words[i];if (currt.next == null) {currt.next = new ArrayList<>();}TrieNode target = currt.next.stream().filter(n -> n.c == c).findFirst().orElse(null);if (target == null) {target = new TrieNode(c);currt.next.add(target);}currt = target;}currt.isWord = true;}public boolean search(String word) {if (word == null || word.isEmpty()) {return false;}char[] words = word.toCharArray();char head = words[0];TrieNode currt = data.get(head);if (currt == null) {return false;}for (int i = 1; i < words.length; i++) {char c = words[i];if (currt.next == null || currt.next.size() == 0) {return false;}List<TrieNode> next = currt.next;TrieNode t = next.stream().filter(n -> n.c == c).findFirst().orElse(null);if (t == null) {return false;}currt = t;}return currt.isWord;}public boolean startsWith(String prefix) {if (prefix == null || prefix.isEmpty()) {return false;}char[] words = prefix.toCharArray();char head = words[0];TrieNode currt = data.get(head);if (currt == null) {return false;}for (int i = 1; i < words.length; i++) {char c = words[i];if (currt.next == null || currt.next.size() == 0) {return false;}List<TrieNode> next = currt.next;TrieNode t = next.stream().filter(n -> n.c == c).findFirst().orElse(null);if (t == null) {return false;}currt = t;}return true;}}
小结
本文从最简单的二叉树开始讲起,介绍了简单二叉树的遍历,
之后延伸到对于搜索友好的二叉搜索树,对比二叉搜索树和我之前chat里面讲过的二分法,你会发现,提高搜索效率的秘诀,在于构建有序的结构,之后尽量利用二分法的原理,使得搜索的时间复杂度靠近 l o g 2 n log_2n log2n。
但是在实际操作中,我们会发现,将树维护在高度平衡内,实在是要耗费的力气太大了,于是不得不在高度平衡和构建树上做一个妥协,由此衍生出了很多工业级别的树,但是限于本文篇幅,这里没有涉及,或许我会在后续的chat安排上。
除了二叉树,本文还简单介绍了下N叉树和前缀树,简单了解下树的其他应用方式。
相关文章:
Java版-速通数据结构-树基础知识
现在面试问mysql,红黑树好像都是必备问题了。动不动就让手写红黑树或者简单介绍下红黑树。然而,我们如果直接去看红黑树,可能会一下子蒙了。在看红黑树之前,需要先了解下树的基础知识,从简单到复杂,看看红黑树是在什么…...

详尽的oracle sql函数
1,CHR 输入整数,返回对应字符。 用法:select chr(65),chr(78) from dual; 2,ASCII 输入字符,返回对应ASCII码。 用法:select ascii(A),ascii(B) from dual; 3,CONCAT 输入两个字符串,…...

SAP IDOC Error VG205
今天在做IDOC 入栈处理销售订单的时候,一直报错VG205 There is no article description for item 000030 这个问题在通过WE19 前台显示的时候就不会遇见, 只有在接口传输的时候才会遇到 搜索发现,可以通过配置忽略此消息号 配置路径如下…...
DSP 的 CV 算子调用
01 前言 DSP 是 征程 5 上的数字信号处理器,专用于处理视觉、图像等信息。在 OE 包的 ddk/samples/vdsp_rpc_sample 路径下,提供了 DSP 使用示例,包括 nn 和 CV 两部分。 nn 示例涵盖了深度学习模型的相关算子,包括量化、反量化、…...
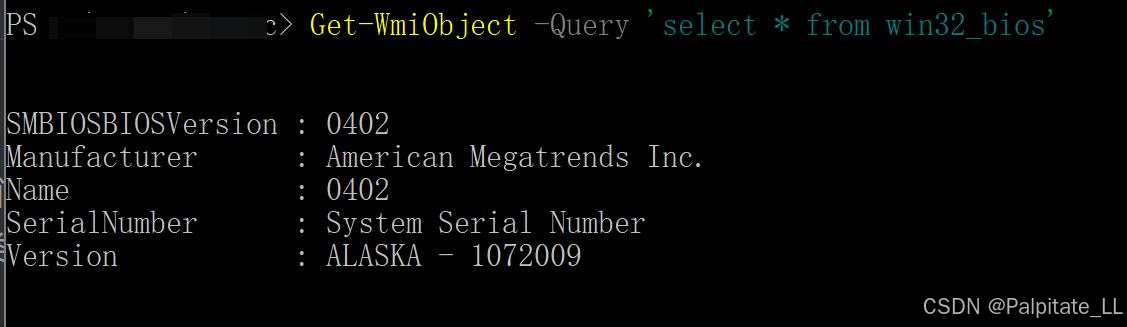
WMI攻击-基础篇(一)
#WMI攻击-基础篇(一) 这篇文章是关于WMI攻击系列文章的第一部分,面向新手。如果对Powershell有一定了解会对阅读本文有所帮助,但这并不是必需的,我们直接上干货。 #1、概述 为什么是WMI? WMI 是 Microso…...

使用Pygame创建一个简单的消消乐游戏
消消乐游戏是一种经典的益智游戏,玩家通过交换相邻的方块来形成三个或更多相同颜色的连续方块,从而消除它们。本文将介绍如何使用Python的Pygame库来创建一个简单的消消乐游戏。 准备工作 在开始之前,请确保已安装Pygame库。可以通过以下命…...

证明直纹面是可展曲面沿着直母线,曲面的切平面不变
目录 证明直纹面是可展曲面的当且仅当沿着直母线,曲面的切平面不变 证明直纹面是可展曲面的当且仅当沿着直母线,曲面的切平面不变 直纹面是可展曲面当且仅当沿着直母线,曲面的切平面不变. 证明:设直纹面 S S S的参数式为 r ( u …...

Chrome控制台 网站性能优化指标一览
打开chrome-》f12/右键查看元素-》NetWrok/网络 ctrlF5 刷新网页,可以看到从输入url到页面资源请求并加载网页,用于查看资源加载,接口请求,评估网页、网站性能等,如下图: request、stransferred、resour…...

Typora创建markdwon文件的基础语法
标题的创建 使用#空格xxx 可使xxx为标题,同时第一标题为#空格标题;第二标题为##空格标题2。以此类推最多可创建六个标题。 同时按住Ctrl1可创建第一标题,同时按住Ctrl2可创建第二标题,以此类推,最多可创建六个标题。也…...

《嵌入式硬件设计》
一、引言 嵌入式系统在现代科技中占据着至关重要的地位,广泛应用于消费电子、工业控制、汽车电子、医疗设备等众多领域。嵌入式硬件设计作为嵌入式系统开发的基础,直接决定了系统的性能、可靠性和成本。本文将深入探讨嵌入式硬件设计的各个方面ÿ…...

【AIGC】大模型面试高频考点-位置编码篇
【AIGC】大模型面试高频考点-位置编码篇 (一)手撕 绝对位置编码 算法(二)手撕 可学习位置编码 算法(三)手撕 相对位置编码 算法(四)手撕 Rope 算法(旋转位置编码…...

如何使用 SQL 语句创建一个 MySQL 数据库的表,以及对应的 XML 文件和 Mapper 文件
文章目录 1、SQL 脚本语句2、XML 文件3、Mapper 文件4、启动 ServiceInit 文件5、DataService 文件6、ComplianceDBConfig 配置文件 这个方式通常是放在项目代码中,使用配置在项目的启动时创建表格,SQL 语句放到一个 XML 文件中。在Spring 项目启动时&am…...

Unity性能优化---动态网格组合(二)
在上一篇中,组合的是同一个材质球的网格,如果其中有不一样的材质球会发生什么?如下图: 将场景中的一个物体替换为不同的材质球 运行之后,就变成了相同的材质。 要实现组合不同材质的网格步骤如下: 在父物体…...

JVM学习《垃圾回收算法和垃圾回收器》
目录 1.垃圾回收算法 1.1 标记-清除算法 1.2 复制算法 1.3 标记-整理算法 1.4 分代收集算法 2.垃圾回收器 2.1 熟悉一下垃圾回收的一些名词 2.2 垃圾回收器有哪些? 2.3 Serial收集器 2.4 Parallel Scavenge收集器 2.5 ParNew收集器 2.6 CMS收集器 1.垃圾…...

GPS模块/SATES-ST91Z8LR:电路搭建;直接用电脑的USB转串口进行通讯;模组上报定位数据转换地图识别的坐标手动查询地图位置
从事嵌入式单片机的工作算是符合我个人兴趣爱好的,当面对一个新的芯片我即想把芯片尽快搞懂完成项目赚钱,也想着能够把自己遇到的坑和注意事项记录下来,即方便自己后面查阅也可以分享给大家,这是一种冲动,但是这个或许并不是原厂希望的,尽管这样有可能会牺牲一些时间也有哪天原…...

什么是TCP的三次握手
TCP(传输控制协议)的三次握手是一个用于在两个网络通信的计算机之间建立连接的过程。这个过程确保了双方都有能力接收和发送数据,并且初始化双方的序列号。以下是三次握手的详细步骤: 第一次握手(SYN)&…...

《Clustering Propagation for Universal Medical Image Segmentation》CVPR2024
摘要 这篇论文介绍了S2VNet,这是一个用于医学图像分割的通用框架,它通过切片到体积的传播(Slice-to-Volume propagation)来统一自动(AMIS)和交互式(IMIS)医学图像分割任务。S2VNet利…...

Linux ifconfig ip 命令详解
简介 ifconfig 和 ip 命令用于配置和显示 Linux 上的网络接口。虽然 ifconfig 是传统工具,但现在已被弃用并被提供更多功能的 ip 命令取代。 ifconfig 安装 sudo apt install net-toolssudo yum install net-tools查看所有活动的网络接口 ifconfig启动/激活网络…...

Vue3 对于echarts使用 v-show,导致显示不全,宽度仅100px,无法重新渲染的问题
参考链接:解决Echarts图表使用v-show,显示不全,宽度仅100px的问题_echarts v-show图表不全-CSDN博客 Vue3 echarts v-show无法重新渲染的问题_v-show echarts不渲染-CSDN博客 原因不多赘述了,大概就是v-show 本身是结构已经存在,当数据发生…...
C++实现俄罗斯方块
俄罗斯方块 还记得俄罗斯方块吗?相信这是小时候我们每个人都喜欢玩的一个小游戏。顾名思义,俄罗斯方块自然是俄罗斯人发明的。这人叫阿列克谢帕基特诺夫。他设置这个游戏的规则是:由小方块组成的不同形状的板块陆续从屏幕上方落下来…...

网易云音乐FLAC无损下载工具:3步轻松获取专业级音质
网易云音乐FLAC无损下载工具:3步轻松获取专业级音质 【免费下载链接】NeteaseCloudMusicFlac 根据网易云音乐的歌单, 下载flac无损音乐到本地.。 项目地址: https://gitcode.com/gh_mirrors/nete/NeteaseCloudMusicFlac 还在为在线音乐平台的音质限制而烦恼吗…...

如何用MediaCrawler实现7大平台数据采集与追踪:从零到一的完整实战指南
如何用MediaCrawler实现7大平台数据采集与追踪:从零到一的完整实战指南 【免费下载链接】MediaCrawler 小红书笔记 | 评论爬虫、抖音视频 | 评论爬虫、快手视频 | 评论爬虫、B 站视频 | 评论爬虫、微博帖子 | 评论爬虫、百度贴吧帖子 &#x…...

OpenHarmony 5.0.3兼容性认证实战:BQ3576HM开发板全栈移植与调优
1. 项目概述:一次关键的“兼容性认证”实战最近,我们团队基于贝启科技的BQ3576HM开发板套件,成功通过了OpenHarmony 5.0.3 Release版本的兼容性测评。这听起来像是一个简单的“通过测试”的新闻,但对于真正在一线做OpenHarmony设备…...

Legacy iOS Kit:让旧iPhone重获新生的终极降级工具
Legacy iOS Kit:让旧iPhone重获新生的终极降级工具 【免费下载链接】Legacy-iOS-Kit An all-in-one tool to restore/downgrade, save SHSH blobs, jailbreak legacy iOS devices, and more 项目地址: https://gitcode.com/gh_mirrors/le/Legacy-iOS-Kit 你是…...

17 ThingsBoard网关设备-子设备数据模型实战:核心价值+完整落地指南
ThingsBoard网关设备-子设备数据模型实战:核心价值完整落地指南 一、任务说明 1.1 场景必要性 在物联网(IoT)/工业物联网(IIoT)场景中,「网关设备-子设备」层级数据模型是解决异构设备批量接入、统一管理…...

ViGEmBus:让Windows游戏外设兼容性不再是难题
ViGEmBus:让Windows游戏外设兼容性不再是难题 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus 你是否曾经遇到过心爱的游戏手柄在Windows上无法被…...
)
直线模组选型别再“先选电机“了!导程才是起点(附正向推导五步法)
引言:一个高频"翻车"现场在直线模组(丝杆模组)选型中,有个环节经常出现逆向翻车——工程师先选好了电机,再去配丝杆导程,结果发现:❌ 速度上不去❌ 推力不够大❌ 电机严重发热问题的根…...

终极碧蓝航线自动化脚本:Alas智能辅助工具完整指南
终极碧蓝航线自动化脚本:Alas智能辅助工具完整指南 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript AzurLaneAuto…...

【求职】衡量你职场流通性的,从来不是你的能力
衡量你职场流通性的,从来不是你的能力先问你一个问题。 你上一次被猎头主动联系,是什么时候? 如果你需要认真回忆,那这篇文章,你需要认真读完。一、"流通性"是个被严重低估的职场变量 大多数人谈职业发展&am…...

2025最权威的五大降重复率神器实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 处于内容营销范畴当中,标题属于勾引用户去点击的首个关卡。伴随AIGC也就是人工智…...