深度学习作业十 BPTT
目录
习题6-1P 推导RNN反向传播算法BPTT.
习题6-2 推导公式(6.40)和公式(6.41)中的梯度.
习题6-3 当使用公式(6.50)作为循环神经网络的状态更新公式时, 分析其可能存在梯度爆炸的原因并给出解决方法.
习题6-2P 设计简单RNN模型,分别用Numpy、Pytorch实现反向传播算子,并代入数值测试.
(1)RNNCell前向传播
(2)RNNcell反向传播
(3)RNN前向传播
(4)RNN反向传播
(5)分别用numpy和torch实现前向和反向传播
习题6-1P 推导RNN反向传播算法BPTT.

习题6-2 推导公式(6.40)和公式(6.41)中的梯度.

习题6-3 当使用公式(6.50)作为循环神经网络的状态更新公式时, 分析其可能存在梯度爆炸的原因并给出解决方法.

解决方法:
可以通过引入门控机制来进一步改进模型,主要有:长短期记忆网络(LSTM)和门控循环单元网络(GRU)。
LSTM:
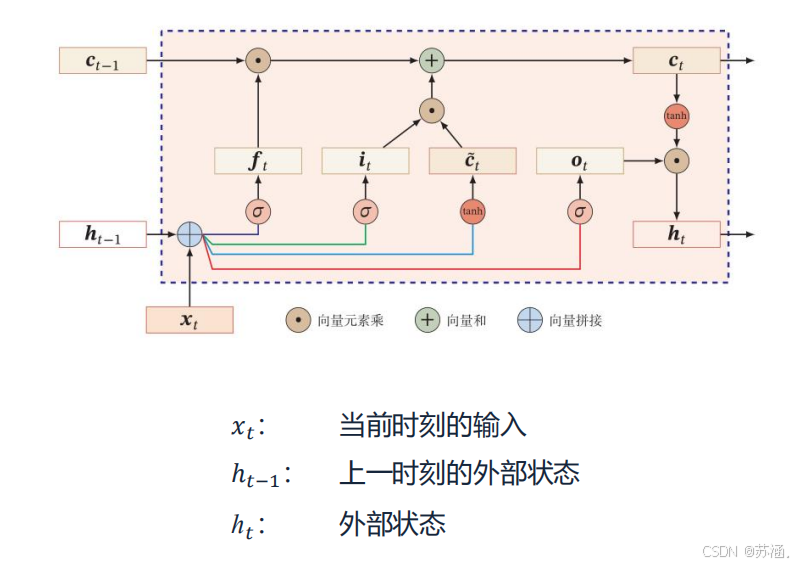
LSTM 通过引入多个门控机制(输入门、遗忘门和输出门)以及一个独立的细胞状态(Cell State),来实现对信息的选择性记忆和遗忘,从而捕捉长序列的依赖关系。
关键组件:


优点
- 能够捕捉长期依赖关系。
- 对梯度消失问题有较好的抑制效果。
缺点
- 结构复杂,参数较多,训练时间长。
- 在某些任务中可能存在过拟合问题。
GRU:
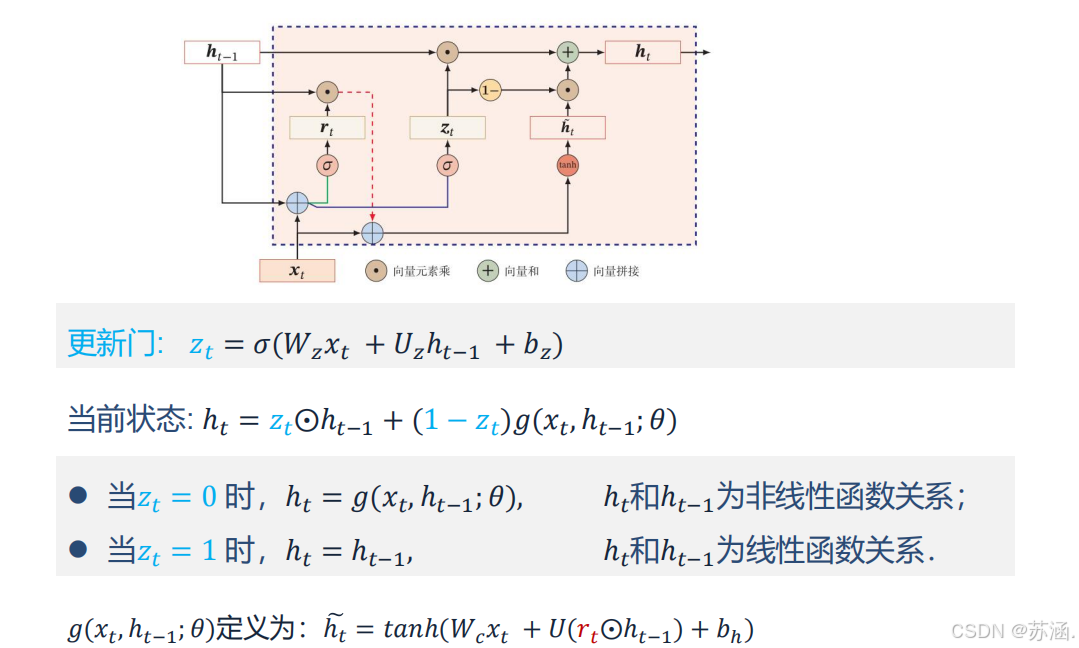
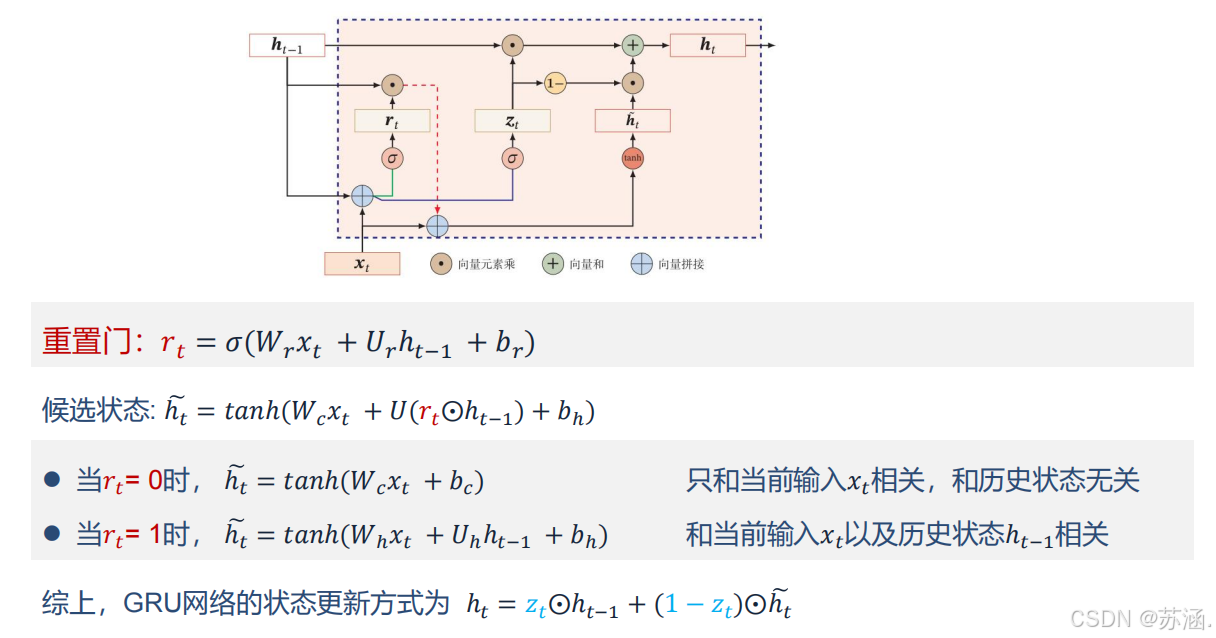
GRU 是 LSTM 的简化版本,融合了遗忘门和输入门,减少了网络的复杂性,同时保持了对长序列依赖关系的建模能力。
优点
- 参数比 LSTM 更少,计算效率更高。
- 能在某些任务中达到与 LSTM 类似的性能。
缺点
- 不具备 LSTM 的完全灵活性,在极长序列任务中可能表现略逊色。
习题6-2P 设计简单RNN模型,分别用Numpy、Pytorch实现反向传播算子,并代入数值测试.
(1)RNNCell前向传播
代码如下:
# ======RNNcell前向传播==================================================================
def rnn_cell_forward(xt, a_prev, parameters):# Retrieve parameters from "parameters"Wax = parameters["Wax"]Waa = parameters["Waa"]Wya = parameters["Wya"]ba = parameters["ba"]by = parameters["by"]### START CODE HERE ### (≈2 lines)# compute next activation state using the formula given abovea_next = np.tanh(np.dot(Wax, xt) + np.dot(Waa, a_prev) + ba)# compute output of the current cell using the formula given aboveyt_pred = F.softmax(torch.from_numpy(np.dot(Wya, a_next) + by), dim=0)### END CODE HERE #### store values you need for backward propagation in cachecache = (a_next, a_prev, xt, parameters)return a_next, yt_pred, cachenp.random.seed(1)
xt = np.random.randn(3, 10)
a_prev = np.random.randn(5, 10)
Waa = np.random.randn(5, 5)
Wax = np.random.randn(5, 3)
Wya = np.random.randn(2, 5)
ba = np.random.randn(5, 1)
by = np.random.randn(2, 1)
parameters = {"Waa": Waa, "Wax": Wax, "Wya": Wya, "ba": ba, "by": by}a_next, yt_pred, cache = rnn_cell_forward(xt, a_prev, parameters)
print("a_next[4] = ", a_next[4])
print("a_next.shape = ", a_next.shape)
print("yt_pred[1] =", yt_pred[1])
print("yt_pred.shape = ", yt_pred.shape)
print("===================================================================")
运行结果:

(2)RNNcell反向传播
代码如下:
# ======RNNcell反向传播========================================================
def rnn_cell_backward(da_next, cache):# Retrieve values from cache(a_next, a_prev, xt, parameters) = cache# Retrieve values from parametersWax = parameters["Wax"]Waa = parameters["Waa"]Wya = parameters["Wya"]ba = parameters["ba"]by = parameters["by"]### START CODE HERE #### compute the gradient of tanh with respect to a_next (≈1 line)dtanh = (1 - a_next * a_next) * da_next # 注意这里是 element_wise ,即 * da_next,dtanh 可以只看做一个中间结果的表示方式# compute the gradient of the loss with respect to Wax (≈2 lines)dxt = np.dot(Wax.T, dtanh)dWax = np.dot(dtanh, xt.T)# 根据公式1、2, dxt = da_next .( Wax.T . (1- tanh(a_next)**2) ) = da_next .( Wax.T . dtanh * (1/d_a_next) )= Wax.T . dtanh# 根据公式1、3, dWax = da_next .( (1- tanh(a_next)**2) . xt.T) = da_next .( dtanh * (1/d_a_next) . xt.T )= dtanh . xt.T# 上面的 . 表示 np.dot# compute the gradient with respect to Waa (≈2 lines)da_prev = np.dot(Waa.T, dtanh)dWaa = np.dot(dtanh, a_prev.T)# compute the gradient with respect to b (≈1 line)dba = np.sum(dtanh, keepdims=True, axis=-1) # axis=0 列方向上操作 axis=1 行方向上操作 keepdims=True 矩阵的二维特性### END CODE HERE #### Store the gradients in a python dictionarygradients = {"dxt": dxt, "da_prev": da_prev, "dWax": dWax, "dWaa": dWaa, "dba": dba}return gradientsnp.random.seed(1)
xt = np.random.randn(3, 10)
a_prev = np.random.randn(5, 10)
Wax = np.random.randn(5, 3)
Waa = np.random.randn(5, 5)
Wya = np.random.randn(2, 5)
b = np.random.randn(5, 1)
by = np.random.randn(2, 1)
parameters = {"Wax": Wax, "Waa": Waa, "Wya": Wya, "ba": ba, "by": by}a_next, yt, cache = rnn_cell_forward(xt, a_prev, parameters)da_next = np.random.randn(5, 10)
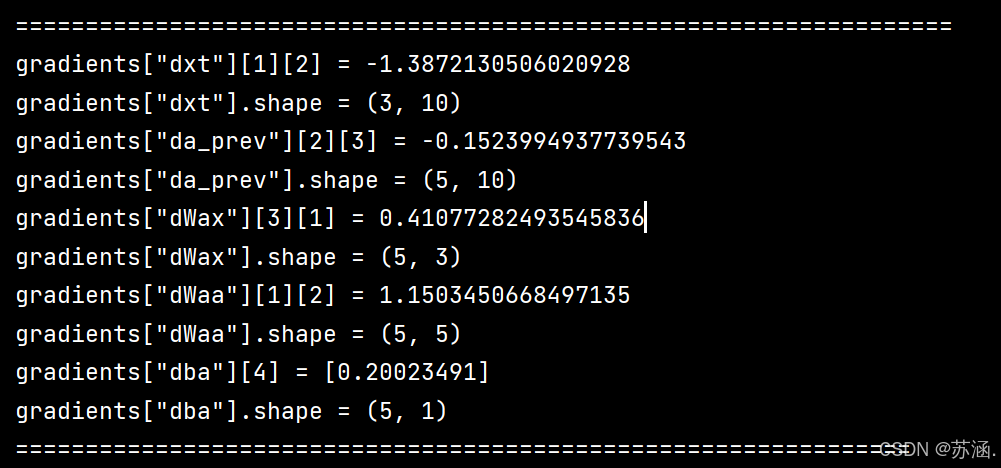
gradients = rnn_cell_backward(da_next, cache)
print("gradients[\"dxt\"][1][2] =", gradients["dxt"][1][2])
print("gradients[\"dxt\"].shape =", gradients["dxt"].shape)
print("gradients[\"da_prev\"][2][3] =", gradients["da_prev"][2][3])
print("gradients[\"da_prev\"].shape =", gradients["da_prev"].shape)
print("gradients[\"dWax\"][3][1] =", gradients["dWax"][3][1])
print("gradients[\"dWax\"].shape =", gradients["dWax"].shape)
print("gradients[\"dWaa\"][1][2] =", gradients["dWaa"][1][2])
print("gradients[\"dWaa\"].shape =", gradients["dWaa"].shape)
print("gradients[\"dba\"][4] =", gradients["dba"][4])
print("gradients[\"dba\"].shape =", gradients["dba"].shape)
gradients["dxt"][1][2] = -0.4605641030588796
gradients["dxt"].shape = (3, 10)
gradients["da_prev"][2][3] = 0.08429686538067724
gradients["da_prev"].shape = (5, 10)
gradients["dWax"][3][1] = 0.39308187392193034
gradients["dWax"].shape = (5, 3)
gradients["dWaa"][1][2] = -0.28483955786960663
gradients["dWaa"].shape = (5, 5)
gradients["dba"][4] = [0.80517166]
gradients["dba"].shape = (5, 1)
print("================================================================")
运行结果:
(3)RNN前向传播
代码如下:
# ====RNN前向传播==============================================================
def rnn_forward(x, a0, parameters):# Initialize "caches" which will contain the list of all cachescaches = []# Retrieve dimensions from shapes of x and Wyn_x, m, T_x = x.shapen_y, n_a = parameters["Wya"].shape### START CODE HERE #### initialize "a" and "y" with zeros (≈2 lines)a = np.zeros((n_a, m, T_x))y_pred = np.zeros((n_y, m, T_x))# Initialize a_next (≈1 line)a_next = a0# loop over all time-stepsfor t in range(T_x):# Update next hidden state, compute the prediction, get the cache (≈1 line)a_next, yt_pred, cache = rnn_cell_forward(x[:, :, t], a_next, parameters)# Save the value of the new "next" hidden state in a (≈1 line)a[:, :, t] = a_next# Save the value of the prediction in y (≈1 line)y_pred[:, :, t] = yt_pred# Append "cache" to "caches" (≈1 line)caches.append(cache)### END CODE HERE #### store values needed for backward propagation in cachecaches = (caches, x)return a, y_pred, cachesnp.random.seed(1)
x = np.random.randn(3, 10, 4)
a0 = np.random.randn(5, 10)
Waa = np.random.randn(5, 5)
Wax = np.random.randn(5, 3)
Wya = np.random.randn(2, 5)
ba = np.random.randn(5, 1)
by = np.random.randn(2, 1)
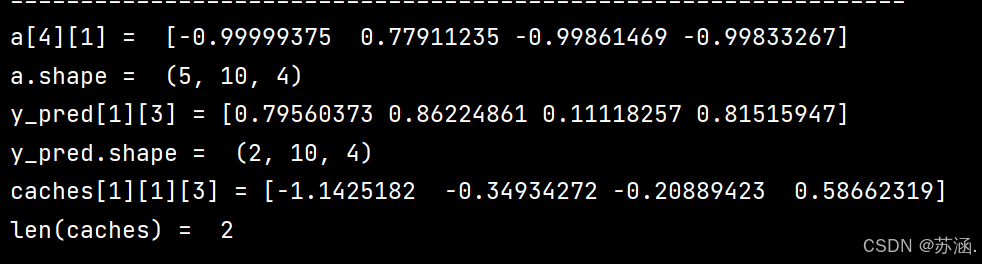
parameters = {"Waa": Waa, "Wax": Wax, "Wya": Wya, "ba": ba, "by": by}a, y_pred, caches = rnn_forward(x, a0, parameters)
print("a[4][1] = ", a[4][1])
print("a.shape = ", a.shape)
print("y_pred[1][3] =", y_pred[1][3])
print("y_pred.shape = ", y_pred.shape)
print("caches[1][1][3] =", caches[1][1][3])
print("len(caches) = ", len(caches))
print("=============================================================")
运行结果:
(4)RNN反向传播
代码如下:
# =====RNN反向传播=================================================================
def rnn_backward(da, caches):### START CODE HERE #### Retrieve values from the first cache (t=1) of caches (≈2 lines)(caches, x) = caches(a1, a0, x1, parameters) = caches[0] # t=1 时的值# Retrieve dimensions from da's and x1's shapes (≈2 lines)n_a, m, T_x = da.shapen_x, m = x1.shape# initialize the gradients with the right sizes (≈6 lines)dx = np.zeros((n_x, m, T_x))dWax = np.zeros((n_a, n_x))dWaa = np.zeros((n_a, n_a))dba = np.zeros((n_a, 1))da0 = np.zeros((n_a, m))da_prevt = np.zeros((n_a, m))# Loop through all the time stepsfor t in reversed(range(T_x)):# Compute gradients at time step t. Choose wisely the "da_next" and the "cache" to use in the backward propagation step. (≈1 line)gradients = rnn_cell_backward(da[:, :, t] + da_prevt, caches[t]) # da[:,:,t] + da_prevt ,每一个时间步后更新梯度# Retrieve derivatives from gradients (≈ 1 line)dxt, da_prevt, dWaxt, dWaat, dbat = gradients["dxt"], gradients["da_prev"], gradients["dWax"], gradients["dWaa"], gradients["dba"]# Increment global derivatives w.r.t parameters by adding their derivative at time-step t (≈4 lines)dx[:, :, t] = dxtdWax += dWaxtdWaa += dWaatdba += dbat# Set da0 to the gradient of a which has been backpropagated through all time-steps (≈1 line)da0 = da_prevt### END CODE HERE #### Store the gradients in a python dictionarygradients = {"dx": dx, "da0": da0, "dWax": dWax, "dWaa": dWaa, "dba": dba}return gradientsnp.random.seed(1)
x = np.random.randn(3, 10, 4)
a0 = np.random.randn(5, 10)
Wax = np.random.randn(5, 3)
Waa = np.random.randn(5, 5)
Wya = np.random.randn(2, 5)
ba = np.random.randn(5, 1)
by = np.random.randn(2, 1)
parameters = {"Wax": Wax, "Waa": Waa, "Wya": Wya, "ba": ba, "by": by}
a, y, caches = rnn_forward(x, a0, parameters)
da = np.random.randn(5, 10, 4)
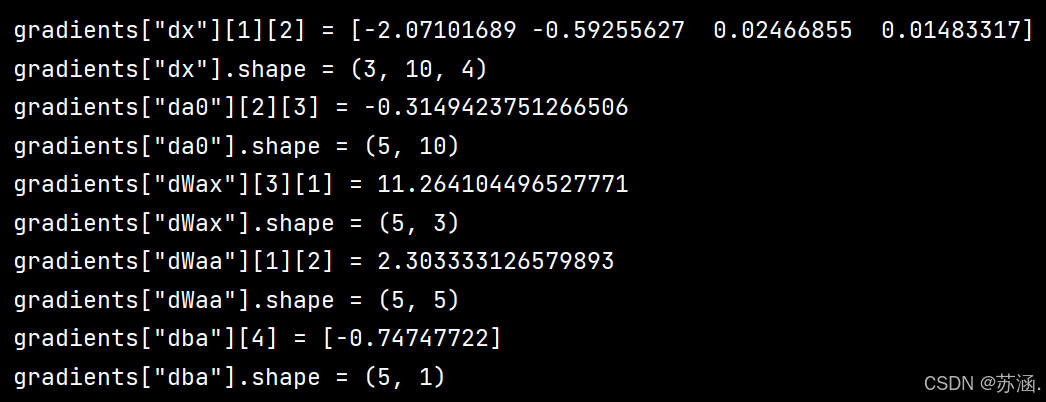
gradients = rnn_backward(da, caches)print("gradients[\"dx\"][1][2] =", gradients["dx"][1][2])
print("gradients[\"dx\"].shape =", gradients["dx"].shape)
print("gradients[\"da0\"][2][3] =", gradients["da0"][2][3])
print("gradients[\"da0\"].shape =", gradients["da0"].shape)
print("gradients[\"dWax\"][3][1] =", gradients["dWax"][3][1])
print("gradients[\"dWax\"].shape =", gradients["dWax"].shape)
print("gradients[\"dWaa\"][1][2] =", gradients["dWaa"][1][2])
print("gradients[\"dWaa\"].shape =", gradients["dWaa"].shape)
print("gradients[\"dba\"][4] =", gradients["dba"][4])
print("gradients[\"dba\"].shape =", gradients["dba"].shape)
print("===========================================================")
运行结果:
(5)分别用numpy和torch实现前向和反向传播
代码如下:
# =====分别用numpy和torch实现前向和反向传播===================================================
import torch
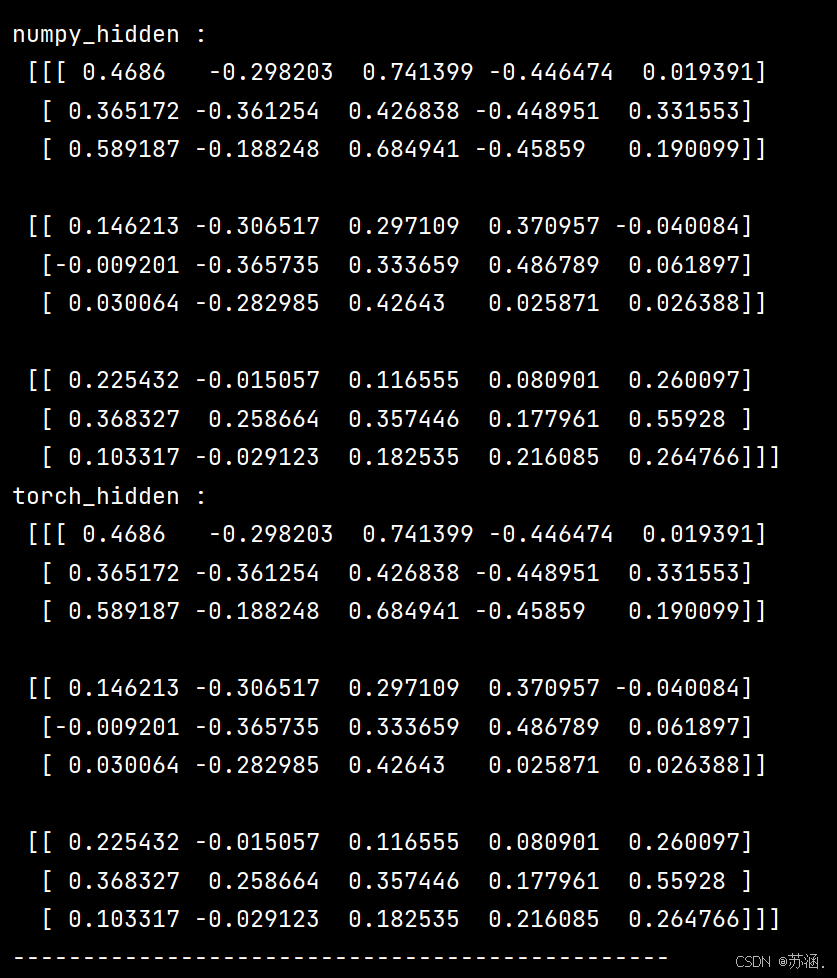
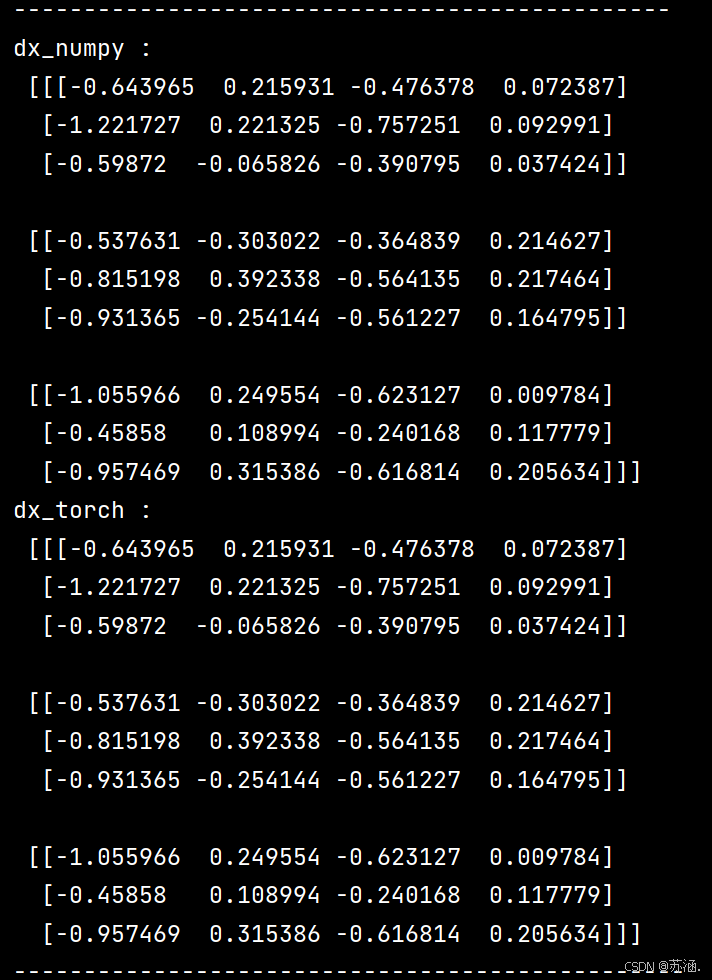
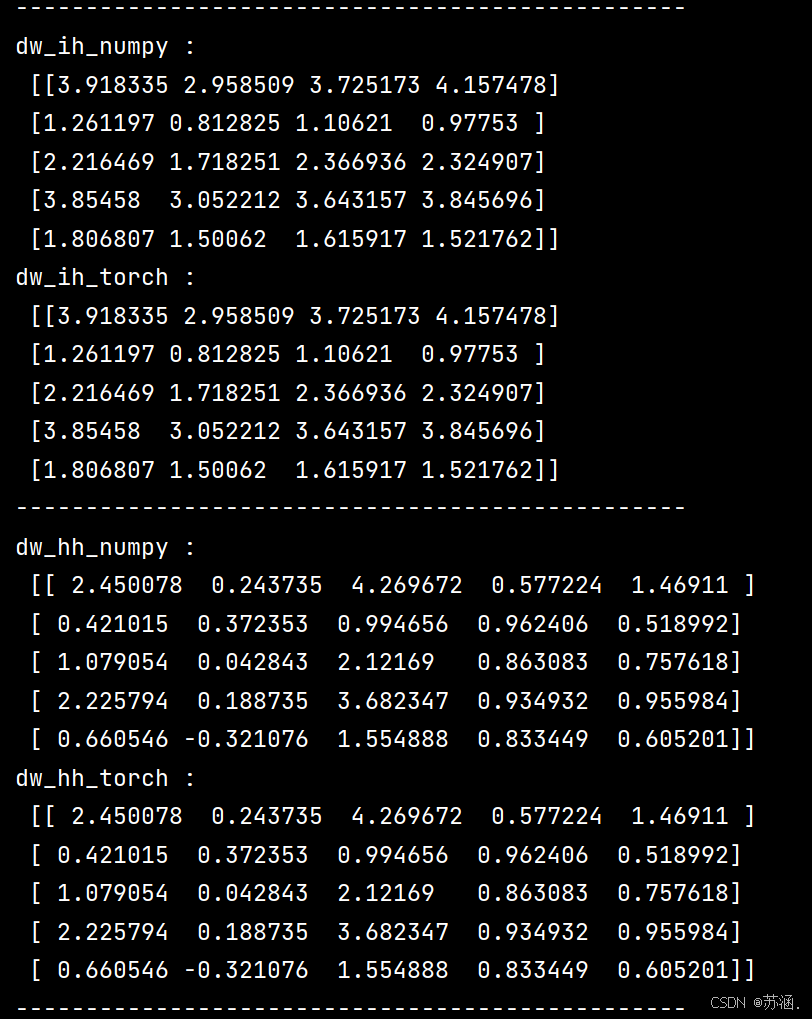
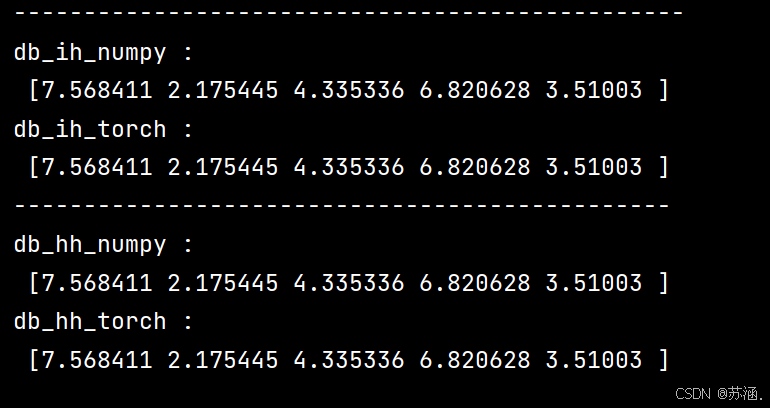
import numpy as npclass RNNCell:def __init__(self, weight_ih, weight_hh,bias_ih, bias_hh):self.weight_ih = weight_ihself.weight_hh = weight_hhself.bias_ih = bias_ihself.bias_hh = bias_hhself.x_stack = []self.dx_list = []self.dw_ih_stack = []self.dw_hh_stack = []self.db_ih_stack = []self.db_hh_stack = []self.prev_hidden_stack = []self.next_hidden_stack = []# temporary cacheself.prev_dh = Nonedef __call__(self, x, prev_hidden):self.x_stack.append(x)next_h = np.tanh(np.dot(x, self.weight_ih.T)+ np.dot(prev_hidden, self.weight_hh.T)+ self.bias_ih + self.bias_hh)self.prev_hidden_stack.append(prev_hidden)self.next_hidden_stack.append(next_h)# clean cacheself.prev_dh = np.zeros(next_h.shape)return next_hdef backward(self, dh):x = self.x_stack.pop()prev_hidden = self.prev_hidden_stack.pop()next_hidden = self.next_hidden_stack.pop()d_tanh = (dh + self.prev_dh) * (1 - next_hidden ** 2)self.prev_dh = np.dot(d_tanh, self.weight_hh)dx = np.dot(d_tanh, self.weight_ih)self.dx_list.insert(0, dx)dw_ih = np.dot(d_tanh.T, x)self.dw_ih_stack.append(dw_ih)dw_hh = np.dot(d_tanh.T, prev_hidden)self.dw_hh_stack.append(dw_hh)self.db_ih_stack.append(d_tanh)self.db_hh_stack.append(d_tanh)return self.dx_listif __name__ == '__main__':np.random.seed(123)torch.random.manual_seed(123)np.set_printoptions(precision=6, suppress=True)rnn_PyTorch = torch.nn.RNN(4, 5).double()rnn_numpy = RNNCell(rnn_PyTorch.all_weights[0][0].data.numpy(),rnn_PyTorch.all_weights[0][1].data.numpy(),rnn_PyTorch.all_weights[0][2].data.numpy(),rnn_PyTorch.all_weights[0][3].data.numpy())nums = 3x3_numpy = np.random.random((nums, 3, 4))x3_tensor = torch.tensor(x3_numpy, requires_grad=True)h3_numpy = np.random.random((1, 3, 5))h3_tensor = torch.tensor(h3_numpy, requires_grad=True)dh_numpy = np.random.random((nums, 3, 5))dh_tensor = torch.tensor(dh_numpy, requires_grad=True)h3_tensor = rnn_PyTorch(x3_tensor, h3_tensor)h_numpy_list = []h_numpy = h3_numpy[0]for i in range(nums):h_numpy = rnn_numpy(x3_numpy[i], h_numpy)h_numpy_list.append(h_numpy)h3_tensor[0].backward(dh_tensor)for i in reversed(range(nums)):rnn_numpy.backward(dh_numpy[i])print("numpy_hidden :\n", np.array(h_numpy_list))print("torch_hidden :\n", h3_tensor[0].data.numpy())print("-----------------------------------------------")print("dx_numpy :\n", np.array(rnn_numpy.dx_list))print("dx_torch :\n", x3_tensor.grad.data.numpy())print("------------------------------------------------")print("dw_ih_numpy :\n",np.sum(rnn_numpy.dw_ih_stack, axis=0))print("dw_ih_torch :\n",rnn_PyTorch.all_weights[0][0].grad.data.numpy())print("------------------------------------------------")print("dw_hh_numpy :\n",np.sum(rnn_numpy.dw_hh_stack, axis=0))print("dw_hh_torch :\n",rnn_PyTorch.all_weights[0][1].grad.data.numpy())print("------------------------------------------------")print("db_ih_numpy :\n",np.sum(rnn_numpy.db_ih_stack, axis=(0, 1)))print("db_ih_torch :\n",rnn_PyTorch.all_weights[0][2].grad.data.numpy())print("-----------------------------------------------")print("db_hh_numpy :\n",np.sum(rnn_numpy.db_hh_stack, axis=(0, 1)))print("db_hh_torch :\n",rnn_PyTorch.all_weights[0][3].grad.data.numpy())
运行结果:
这次的分享就到这里,下次再见~

相关文章:
深度学习作业十 BPTT
目录 习题6-1P 推导RNN反向传播算法BPTT. 习题6-2 推导公式(6.40)和公式(6.41)中的梯度. 习题6-3 当使用公式(6.50)作为循环神经网络的状态更新公式时, 分析其可能存在梯度爆炸的原因并给出解决方法. 习题6-2P 设计简单RNN模型࿰…...

html+css+JavaScript实现轮播图
html+css+JavaScript实现轮播图 实现思路 要实现一个轮播图功能,我们需要HTML来构建结构,CSS来设计样式,以及JavaScript来添加交互功能。下面我将分别分析这三个部分是如何协同工作来实现轮播图的。 HTML - 结构 HTML部分定义了轮播图的基本结构,包括图片列表、指示器和…...

Python+onlyoffice 实现在线word编辑
onlyoffice部署 version: "3" services:onlyoffice:image: onlyoffice/documentserver:7.5.1container_name: onlyofficerestart: alwaysenvironment:- JWT_ENABLEDfalse#- USE_UNAUTHORIZED_STORAGEtrue#- ONLYOFFICE_HTTPS_HSTS_ENABLEDfalseports:- "8080:8…...

PostgreSQLt二进制安装-contos7
1、安装依赖 yum install -y gcc readline readline-devel zlib-devel net-tools perl wget numactl libicu-devel bison flex openssl-devel pam pam-devel libxml2 libxml2-devel libxslt libxslt-devel openldap openldap-devel 2、创建目录 mkdir -p /data/postgresql/{…...

Neo4j启动时指定JDK版本
项目使用jdk1.8,同时需要安装neo4j5.15版本,使用jdk17. 1.mac或者liunx,找到neo4j目录bin的下neo4j文件 设置JAVA_HOME: 2.windows,找到bin下面的neo4j.bat文件 set "JAVA_HOME{JDK文件目录}" 重启后生效。...

kanzi3.6.10 窗口插件-美化绑定内容
文章目录 1. 创建kanzi窗口插件2. 业务逻辑3. 关键代码3.1 获取绑定信息3.2 解析绑定3.3 动态生成富文本控件 4. 安装 背景:kanzi的节点绑定信息是黑色的,看起来非常费劲,如果能代码高亮显示,对开发会很有帮助。 美化前 美化后 …...

利用tablesaw库简化表格数据分析
tableaw是处理表格数据的优秀工具。它提供了一组强大而灵活的功能,使操作、分析和可视化数据表变得容易。在这篇博文中,我们将介绍tableaw的主要特性、如何使用这些特性,以及如何使用tableaw处理表格数据的一些示例。 tablesaw简介 tableaw…...

记录一下,解决js内存溢出npm ERR! code ELIFECYCLEnpm ERR! errno 134 以及 errno 9009
项目是个老项目,依赖包也比较大,咱就按正常流程走一遍来详细解决这个问题,先看一下node版本,我用的是nvm管理的,详细可以看我的其他文章 友情提醒:如果项目比较老,包又大,又有一些需…...

【JavaWeb后端学习笔记】MySQL的数据查询语言(Data Query Language,DQL)
MySQL DQL 1、DQL语法与数据准备1.1 DQL语法1.2 数据准备 2、基础查询2.1 查询指定字段2.2 查询返回所有字段2.3 给查询结果起别名2.4 去除重复记录 3、条件查询3.1 条件查询语法3.2 条件查询案例分析 4、分组查询4.1 分组查询语法4.2 分组查询案例分析 5、排序查询5.1 排序查询…...

360 最新Android面试题及参考答案
一个 activity 只能有一个进程么【对进程的理解】 在 Android 中,一个 Activity 并不只能有一个进程。进程是操作系统进行资源分配和调度的一个独立单位。 从原理上来说,Android 系统允许开发者通过在 AndroidManifest.xml 文件中的<activity>标签设置 android:process…...

《操作系统 - 清华大学》6 -3:局部页面置换算法:最近最久未使用算法 (LRU, Least Recently Used)
文章目录 1. 最近最久未使用算法的工作原理2. 最近最久未使用算法示例3.LRU算法实现3.1 LRU的页面链表实现3.2 LRU的活动页面栈实现3.3 链表实现 VS 堆栈实现 1. 最近最久未使用算法的工作原理 最近最久未使用页面置换算法,简称 LRU, 算法思路ÿ…...
)
ES6新增了哪些特性(待更新)
1.let,const 1.1.var,let,const的区别 1.1.1 var存在变量提升,let和const不存在。 1.1.2 let和const只能在块作用域里访问。 1.1.3 同一作用域下let和const不能声明同名变量,而var可以。 1.1.4 const定义常量&am…...

剖析一下自己的简历第二条
剖析一下自己的简历第二条 背景前置说明可能会被问到的问题 背景 剖析一下自己简历, 增加对一些专业知识的掌握. 我的简历第二条是这样写的: “2. 熟悉JVM、JMM,包括内存模型,垃圾回收机制,了解其基本调优技巧并具备线上调优经验。”. 前置…...

威联通-001 手机相册备份
文章目录 前言1.Qfile Pro2.Qsync Pro总结 前言 威联通有两种数据备份手段:1.Qfile Pro和2.Qsync Pro,实践使用中存在一些区别,针对不同备份环境选择是不同。 1.Qfile Pro 用来备份制定目录内容的。 2.Qsync Pro 主要用来查看和操作文…...

性能测试基础知识jmeter使用
博客主页:花果山~程序猿-CSDN博客 文章分栏:测试_花果山~程序猿的博客-CSDN博客 关注我一起学习,一起进步,一起探索编程的无限可能吧!让我们一起努力,一起成长! 目录 性能指标 1. 并发数 (Con…...

Ceph文件存储
Ceph文件存储1.概念:数据以文件的形式存储在存储介质上,每个文件都有一个唯一的文件名并存储在一个目录结构中。提供方便的文件访问接口,支持多种文件操作,如创建、删除、读取、写入、复制等。用于存储和管理个人文件,如文档、图片…...

Hive分区表新增字段并指定位置
Hive分区表新增字段并指定位置 1、Hive分区表新增字段2、CASCADE关键字3、历史分区新增列为NULL问题 1、Hive分区表新增字段 Hive分区表新增字段并指定位置主要分为两步:新增字段和移动字段 1)新增字段 ALTER TABLE table_name ADD COLUMNS (col_name …...
与非关系型数据库(NoSQL)应用场景)
关系型数据库(RDBMS)与非关系型数据库(NoSQL)应用场景
关系型数据库适用于事务性、强一致性和结构化数据场景;非关系型数据库则在高并发、大数据、非结构化数据场景中表现更优;数据量和并发量增加时,应通过分库分表、缓存、集群扩展等手段进行优化。 1. 在什么样的业务场景下,你会优先…...

浅谈CI持续集成
1.什么是持续集成 持续集成(Continuous Integration)(CI)是一种软件开发实践,团队成员频繁地将他们的工作成果集成到一起(通常每人每天至少提交一次,这样每天就会有多次集成),并且在每次提交后…...

华为新手机和支付宝碰一下 带来更便捷支付体验
支付正在变的更简单。 11月26日,华为新品发布会引起众多关注。发布会上,华为常务董事余承东专门提到,华为Mate 70和Mate X6折叠屏手机的“独门支付秘技”——“碰一下”,并且表示经过华为和支付宝的共同优化,使用“碰…...

MarkdownViewer++:5分钟让Notepad++变身专业Markdown编辑器的终极指南
MarkdownViewer:5分钟让Notepad变身专业Markdown编辑器的终极指南 【免费下载链接】MarkdownViewerPlusPlus A Notepad Plugin to view a Markdown file rendered on-the-fly 项目地址: https://gitcode.com/gh_mirrors/ma/MarkdownViewerPlusPlus 你是否还在…...

终极指南:如何彻底禁用iPhone过热降频,告别游戏卡顿和屏幕变暗
终极指南:如何彻底禁用iPhone过热降频,告别游戏卡顿和屏幕变暗 【免费下载链接】thermalmonitordDisabler A tool used to disable iOS daemons. 项目地址: https://gitcode.com/gh_mirrors/th/thermalmonitordDisabler 你是否在玩高画质游戏时突…...

终极免费解锁Cursor Pro高级功能:完整解决方案深度解析
终极免费解锁Cursor Pro高级功能:完整解决方案深度解析 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your tr…...

智能汽车人机交互与ADAS系统融合:架构、场景与工程实践
1. 项目概述:当驾驶舱的“大脑”与“眼睛”开始对话“集成人机交互和ADAS系统”——这个标题听起来像是一个纯粹的工程命题,但在我过去十多年的汽车电子开发经历中,我越来越深刻地体会到,这其实是一个关于“人、车、路”三者关系如…...

如何用5分钟将B站视频变成文字稿:bili2text终极指南
如何用5分钟将B站视频变成文字稿:bili2text终极指南 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text 你是否曾经为了整理B站视频笔记而反复暂停、回…...

Phyphox实验避坑指南:测声速时管长、温度、管口校正那些事儿
Phyphox声速测量实验的进阶精度优化手册 在物理实验教学中,声速测量一直是验证波动理论的基础实践。但当智能手机传感器遇上共振管法,看似简单的实验背后藏着诸多魔鬼细节——管口切割的平整度会引入0.5%的误差,手掌温度能在3分钟内使铝管共振…...

从用户吐槽到功能升级:我们如何用sunny-video优化了uniapp视频课件的学习体验
从用户痛点到产品升级:sunny-video如何重塑uniapp视频学习体验 在线教育产品的核心价值在于高效传递知识,而视频播放体验往往成为用户留存的关键瓶颈。去年第三季度,我们团队收到超过1200条用户反馈,其中67%集中抱怨两个问题&…...

设计个人日常用品消耗周期测算程序,测算洗护生活用品消耗速度,提前规划采购时间。
个人日常用品消耗周期测算程序——基于 Python 的生活消耗建模实验一、实际应用场景描述在城市生活中,大多数人都会遇到这些情况:- 洗发水、牙膏、洗衣液突然用完- 临时补货导致时间成本增加- 囤货过多造成过期或占用空间- 无法判断“多久买一次才合理”…...

终极指南:使用免费开源工具SMUDebugTool解锁AMD Ryzen处理器全部性能 [特殊字符]
终极指南:使用免费开源工具SMUDebugTool解锁AMD Ryzen处理器全部性能 🚀 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power T…...
)
告别手动传图!用PicGo+Gitee给Typora配个自动图床(保姆级配置+避坑清单)
打造无缝Markdown写作体验:自动化图床配置全攻略 在技术写作和知识管理的世界里,Markdown已经成为事实上的标准格式。然而,一个长期困扰写作者的问题始终存在——图片管理。传统方式需要手动上传图片到图床,复制链接,再…...