stm32 spi接口传输asm330l速率优化(及cpu和dma方式对比)
最近一段时间做了一个mems的项目,项目的方案是stm32g071做主控,读写3颗asm330l的硬件形态。最初是想放置4颗imu芯片,因为pcb空间布局的问题,改放了3颗。但对于软件方案来说无所谓,关键是如何优化spi的传输速率,满足系统采样率1.667khz的帧率要求。因为如此高的采样率,意味着大量的数据传输处理,那么传输速率也需要很快才行。
一、SPI的三种读写模式
stm32提供了3种hal层读写接口形式。

xxx_IT和xxx_DMA是带有指定中断回调函数的接口,其中xxx_DMA不言而喻采用了dma资源。
每种接口在对应的场景下才能发挥作用,并非一味地说dma就一定比cpu快,根据开发过程,我们一点点来梳理总结。
二、CPU读写模式
cpu读写模式,我指的是用cpu来搬移数据,从spi接口的数据寄存器获取数据,或者赋值给spi接口的数据寄存器,接口是上图的第一和第二种。贴个波形来窥探这种方式的特点。

下面绿色的波形是时钟,可以看到1个写时钟+14个连续读时钟,上面黄色的是mosi指令。
乍看上去是不是有点奇怪,为什么每8bit的sck会有几个us的间隙,是什么地方的耗时呢?直接上代码。如下图,原来mcu的DR数据寄存器在取值和赋值的过程中,会一边判定一边移位,直到处理完当前的8bit数据。那这里已经到了硬件映射层,没有办法再优化了。cpu做搬移数据的极限也就这个耗时附近了。可以裁剪些hal库的冗余代码,但影响都不大,可做可不做。
可以看到,读取14B,spi时序的耗时约60+us左右,注意这里指的是spi时序。

三、DMA读写模式
dma读写模式指的是用dma通道做数据搬移,同样贴个图形来看下。

这个图像有特点。相比cpu做搬移,有2个大的不同。第一,写时钟后的时间明显加长了;第二,连续读取的时钟间隙消失了,为什么,都是有逻辑的。
首先来讲为什么写时钟后间隙为什么明显变长了,同样直接上代码。因为系统触发dma写完成后,会切入中断系统,进入tx通道完毕中断,再退出。整个进出中断+中断内处理,都增加了明显的耗时。设想一下,如果拿中断来每次传输1B,耗时会减少吗?答案是明显的。
 然后来讲下为什么读时钟没有8bit的间隙呢?同样直接上代码。
然后来讲下为什么读时钟没有8bit的间隙呢?同样直接上代码。

dma传输配置完成后,不管你是多少长度(只要不超过缓冲区,默认一般是4096字节),源地址、目地址一次性梭哈。但是,重点,这里只是开启,并不等于执行完这段代码,dma就真正执行搬移完数据,怎么才知道执行完呢?spi接口的state状态必须重新变成ready值。

什么意思呢?dma真正意义的传输完成,是dma重新进入可ready状态,它会主动抛中断告诉系统,与上面的写完成是一样的机制。
所以写到这里,dma真的能节省耗时吗?答案是要做在特定场景下,比如连续传输超多数据的前提下。别老提dma多牛逼是吧,不会用等于反作用。
四、CPU和DMA混合模式
既然dma写时钟耗时非常大,那能不能用cpu来做命令写入,dma做数据读出呢?可以。直接贴时序。

写入指令的时钟后间隙是不是直接短了一截,最后采用了这种方式,最终耗时60+us优化到45+us,dma在数据量小(当前是14B)的前提下,整体优化性能也提升不明显。
下一篇,讲讲怎么使用stm32的dma初始化编程。
相关文章:
stm32 spi接口传输asm330l速率优化(及cpu和dma方式对比)
最近一段时间做了一个mems的项目,项目的方案是stm32g071做主控,读写3颗asm330l的硬件形态。最初是想放置4颗imu芯片,因为pcb空间布局的问题,改放了3颗。但对于软件方案来说无所谓,关键是如何优化spi的传输速率…...

数字时代的文化宝库:存储技术与精神生活
文章目录 1. 文学经典的数字传承2. 音乐的无限可能3. 影视艺术的数字化存储4. 结语 数字时代的文化宝库:存储技术与精神生活 在数字化的浪潮中,存储技术如同一座桥梁,连接着过去与未来,承载着人类文明的瑰宝。随着存储容量的不断增…...

flex: 1 display:flex 导致的宽度失效问题
flex: 1 & display:flex 导致的宽度失效问题 问题复现 有这样的一个业务场景,详情项每行三项分别占33%宽度,每项有label字数不固定所以宽度不固定,还有content 占满标签剩余宽度,文字过多显示省略号, 鼠标划入展示…...

Hive 窗口函数与分析函数深度解析:开启大数据分析的新维度
Hive 窗口函数与分析函数深度解析:开启大数据分析的新维度 在当今大数据蓬勃发展的时代,Hive 作为一款强大的数据仓库工具,其窗口函数和分析函数犹如一把把精巧的手术刀,助力数据分析师们精准地剖析海量数据,挖掘出深…...

前端工程 Node 版本如何选择
1. Node 与 Npm 版本对应 这是一个必知必会的问题,尤其是对于维护那些老掉牙、一坨坨、非常大的有着长期历史的老破大工程。 1.1. package-lock.json 版本 首先你要会看项目的 package-lock.json 文件中的 lockfileVersion 版本号,这对于 NPM 安装来说…...
推荐在线Sql运行
SQL Fiddle 1、网址:SQL Fiddle - Online SQL Compiler for learning & practiceDiscover our free online SQL editor enhanced with AI to chat, explain, and generate code. Support SQL Server, MySQL, MariaDB, PostgreSQL, and SQLite.http://www.sqlfi…...

【数据结构】【线性表】特殊的线性表-字符串
目录 字符串的基本概念 字符串的三要素 字符串的基本概念 串的编码 串的实现及基本运算 顺序串的实现 串的静态数组实现 串的动态数组的实现 顺序存储的四种方案 链式串的实现 基本运算 方案三 方案一 字符串的基本概念 数据结构千千万,…...

app-1 App 逆向环境准备(mumu模拟器+magisk+LSPosed+算法助手+抓包(socksDroid+charles)+Frida环境搭建
一、前言 本篇是基于 mumu模拟器 进行环境配置记录。(真机的后面博客记录) 二、mumu模拟器magiskLSPosed算法助手 2.1、mumu模拟器 选择 mumu 模拟器,下载地址:https://mumu.163.com 安装完成后打开,找到设置中心进…...

在米尔FPGA开发板上实现Tiny YOLO V4,助力AIoT应用
学习如何在 MYIR 的 ZU3EG FPGA 开发板上部署 Tiny YOLO v4,对比 FPGA、GPU、CPU 的性能,助力 AIoT 边缘计算应用。 一、 为什么选择 FPGA:应对 7nm 制程与 AI 限制 在全球半导体制程限制和高端 GPU 受限的大环境下,FPGA 成为了中…...
)
【IT】测试用例模版(含示例)
这里写目录标题 一、测试用例模版二、怎么用模版示例如何使用这个模板 一、测试用例模版 一个相对标准的测试用例模板通常包含以下部分: 测试用例ID:唯一标识符,用于追踪测试用例。测试用例标题:简短描述测试用例的目的。测试用…...

react dnd——一个拖拽组件
React DnD是一个流行的库,用于在React应用程序中实现拖放功能。以下是对React DnD的详细解释,包括示例和API说明: 基本概念 在开始使用React DnD之前,了解以下几个基本概念是很重要的: Drag Source(拖动…...

3GPP R18 LTM(L1/L2 Triggered Mobility)是什么鬼?(三) RACH-less LTM cell switch
这篇看下RACH-less LTM cell switch。 相比于RACH-based LTM,RACH-less LTM在进行LTM cell switch之前就要先知道target cell的TA信息,进而才能进行RACH-less过程,这里一般可以通过UE自行测量或者通过RA过程获取,而这里的RA一般是通过PDCCH order过程触发。根据38.300中的描…...

Flutter解压文件并解析数据
Flutter解压文件并解析数据 前言 在 Flutter 开发中,我们经常需要处理文件的读取和解压。 这在处理应用数据更新、安装包、存档文件等场景中尤为常见。 本文将介绍如何在Flutter中使用archive插件来解压文件并解析数据。 准备 在开始之前,我们需要…...

21、结构体成员分布
结构体中的成员并不是紧挨着分布的,内存分布遵循字节对齐的原则。 按照成员定义的顺序,遵循字节对齐的原则存储。 字节对齐的原则: 找成员中占据字节数最大的成员,以它为单位进行空间空配 --- 遇到数组看元素的类型 每一个成员距离…...

TSWIKI知识库软件
TSWIKI 知识库软件介绍 推荐一个适合本地化部署、自托管的知识库软件 TSWIKI介绍 tswiki 是一个适合小团队、个人的知识库、资料管理的软件,所有数据均本地化存储。可以本地化、私有云部署,安装简单。在线预览。 主要功能说明 1、简化的软件依赖和安…...

深度学习安装环境笔记
1、输出cuda版本 torch.version.cuda 返回的是 PyTorch 在编译时所使用的 CUDA 版本,而不是运行时实际调用的 CUDA 版本。PyTorch 在运行时实际调用的 CUDA 版本取决于系统上安装的 CUDA 驱动和库。 import torch from torch.utils.cpp_extension import CUDA_HOME…...
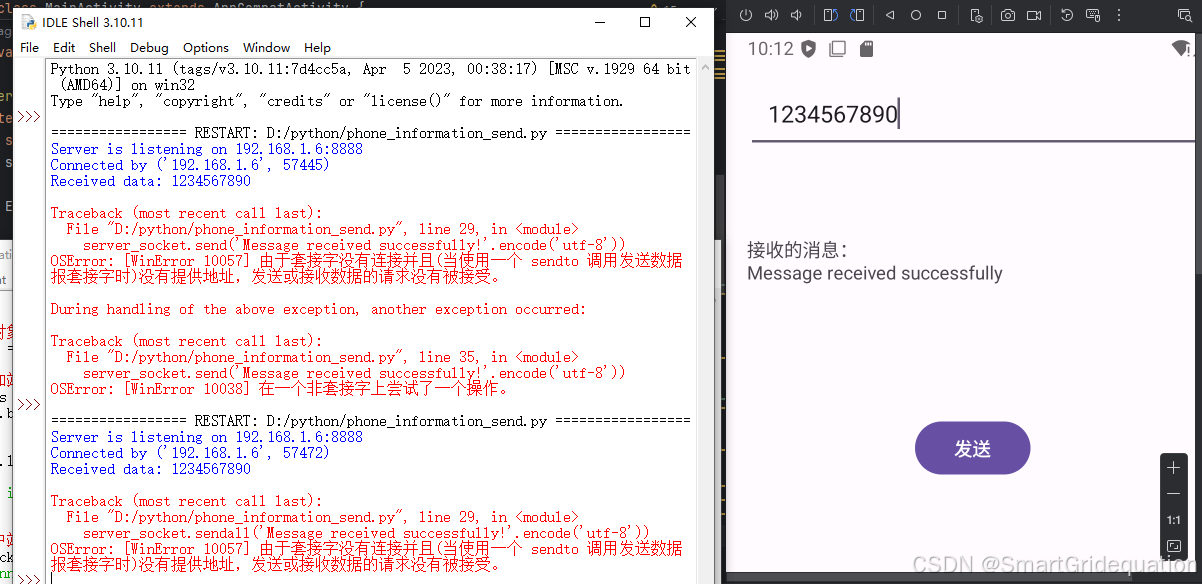
使用android studio写一个Android的远程通信软件(APP),有通讯的发送和接收消息界面
以下是使用 Android Studio 基于 Java 语言编写一个简单的 Android APP 实现远程通信(这里以 TCP 通信为例)的代码示例,包含基本的通信界面以及发送和接收消息功能。 1. 创建项目 打开 Android Studio,新建一个 Empty Activity …...

学习Python的笔记14--迭代器和生成器
1.迭代器(Iterator) 概念: 迭代意味着重复多次,就像循环一样。 迭代器是一个可以记住遍历的位置的对象。 迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。 迭代器只能往前不会后退。 1.iter…...

车机端同步outlook日历
最近在开发一个车机上的日历助手,其中一个需求就是要实现手机端日历和车机端日历数据的同步。然而这种需求似乎没办法实现,毕竟手机日历是手机厂商自己带的系统应用,根本不能和车机端实现数据同步的。 那么只能去其他公共的平台寻求一些机会&…...

教学案例:k相同的一次函数的图像关系
【题目】 请在同一个平面直角坐标系中画出一次函数y2x, y2x4的图象,并观察图象,你发现这两个图形有什么位置关系?为什么? 【答案】 图象是相互平行的两条直线 【解析】 一、教学活动形式 这里设计的教学活动形式是“画图 →…...

ARM架构操作系统内核设计与多线程优化实践
1. 操作系统内核基础与多线程实现1.1 内核架构与资源管理现代操作系统内核作为计算机系统的核心,承担着硬件抽象和资源管理的双重职责。在Raspberry Pi这样的ARM架构设备上,内核需要特别处理以下关键组件:内存管理单元(MMU):通过两…...

关于光缆,这些事儿通信人一定要知道
随着5G网络的全面铺开和持续深耕,通信工程师的工作边界正在不断拓展。过去,后台网优工程师可能更多地专注于参数调整、信令分析和性能优化;而如今,越来越多的项目要求前后台协同作业,网优人员也需要熟悉现场施工规范&a…...

JDK 17文本块实战:告别繁琐拼接,拥抱多行字符串新写法
1. 为什么我们需要文本块? 如果你写过Java代码,肯定遇到过这样的场景:需要处理多行字符串,比如HTML模板、SQL语句或者JSON数据。在JDK 17之前,我们只能通过字符串拼接的方式来实现,代码看起来就像是一团乱麻…...

AI黑魔法实战:LLM应用性能优化与成本控制高级技巧
1. 项目概述:当AI遇上“黑魔法”最近在GitHub上闲逛,发现了一个名为“lvcn/ai-black-magic”的项目,这个名字本身就充满了吸引力。对于任何在AI领域摸爬滚打过的开发者来说,“黑魔法”这个词往往意味着那些不按常理出牌、却能解决…...

MCP服务器构建指南:安全连接AI与外部工具的核心架构与实战
1. 项目概述:MCP服务器生态的构建者如果你最近在关注AI智能体开发,尤其是围绕Claude、Cursor这类工具的生态,那么“MCP”这个词大概率已经在你耳边出现了无数次。ViswaSrimaan/mcp_servers这个项目,正是这个新兴浪潮中的一个关键基…...

Linux只读挂载保护排查方法
Linux只读挂载保护排查方法本文面向具备一定 Linux 基础的技术人员,围绕只读挂载保护展开,重点讨论写入隔离、配置保护和异常诊断。在中级运维和系统管理工作中,这类主题常常与配置变更、资源状态、权限边界、自动化任务和业务影响交织在一起…...

别再只让小车跑了!给Arduino履带底盘加上机械臂,实现自动搬运的5个关键点
从玩具到工具:Arduino履带机械臂的工程化升级指南 当你的Arduino履带小车已经能在客厅里自如巡线时,是否想过让它真正"动手"做点事情?给底盘加装机械臂绝不是简单的物理拼接——我曾亲眼见证一个精心设计的六自由度机械臂在第一次抓…...
)
别再手动输密码了!手把手教你配置Linux服务器SSH免密登录(附known_hosts文件详解)
彻底告别密码输入:Linux服务器SSH免密登录全指南与known_hosts深度解析 每次在终端输入ssh userremote_host后,那个令人烦躁的密码提示符又出现了——作为需要频繁在多台服务器间穿梭的运维人员或开发者,这种重复性劳动不仅浪费时间ÿ…...

如何快速掌握PyInstaller Extractor:5步提取可执行文件的完整指南
如何快速掌握PyInstaller Extractor:5步提取可执行文件的完整指南 【免费下载链接】pyinstxtractor PyInstaller Extractor 项目地址: https://gitcode.com/gh_mirrors/py/pyinstxtractor PyInstaller Extractor是一款专为提取PyInstaller生成的可执行文件内…...
)
毕业设计:基于springboot的在线课程管理系统(源码)
4系统概要设计4.1概述本系统采用B/S结构(Browser/Server,浏览器/服务器结构)和基于Web服务两种模式,是一个适用于Internet环境下的模型结构。只要用户能连上Internet,便可以在任何时间、任何地点使用。系统工作原理图如图4-1所示:图4-1系统工作原理图4.2…...