Preprocess
Preprocess数据预处理
文本
使用Tokenizer将文本转换为标记序列,创建标记的数值表示,并将它们组装成张量。
预处理文本数据的主要工具是标记器。标记器根据一组规则将文本拆分为标记。标记被转换为数字,然后转换为张量,这些张量成为模型输入。模型所需的任何其他输入都由标记器添加。
from transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-cased")encoded_input = tokenizer("Do not meddle in the affairs of wizards, for they are subtle and quick to anger.")
print(encoded_input)# 输出结果
{ 'input_ids' : [ 101 , 2079 , 2025 , 19960 , 10362 , 1999 , 1996 , 3821 , 1997 , 16657 , 1010 , 2005 , 2027 , 2024 , 11259 , 1998 , 4248 , 2000 , 4963 , 1012 , 102 ],'token_type_ids' : [ 0 , 0 , 0 , 0 , 0 , 0 , 0,0,0,0,0,0,0,0,0,0,0,0,0 , 0 ,0,0 ],' attention_mask ' :[ 1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1 ] }
'''
input_ids是句子中每个标记对应的索引。
tention_mask表示是否应该关注一个标记。
当有多个序列时,token_type_ids标识一个 token 属于哪个序列。
'''
# 通过解码返回输入的内容
tokenizer.decode(encoded_input["input_ids"])
'[CLS] 不要干涉巫师的事务,因为他们很狡猾,而且很容易发怒。[SEP]'
padding填充
句子的长度并不总是相同的,但是张量(模型输入)需要具有统一的形状。因此填充是一种通过向较短的句子添加特殊填充标记来确保张量为矩形的策略。
将参数设置padding为True填充批次中较短的序列以匹配最长的序列;
batch_sentences = ["But what about second breakfast?","Don't think he knows about second breakfast, Pip.","What about elevensies?",
]
encoded_input = tokenizer(batch_sentences, padding=True)
print(encoded_input)
# 输出结果
{ 'input_ids' : [[ 101 , 1252 , 1184 , 1164 , 1248 , 6462 , 136 , 102 , 0 , 0 , 0 , 0 , 0 , 0 ] , [ 101 , 1790 , 112 , 189 , 1341 , 1119 , 3520 , 1164 , 1248 , 6462 , 117 , 21902 , 1643 , 119 , 102 ] , [ 101 , 1327 , 1164 , 5450 , 23434 , 136 , 102 , 0 , 0 , 0 , 0 , 0 , 0 , 0 ]] , ' token_type_ids ' : [ [ 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 ] , [ 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 ] , [0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 ]] , ' attention_mask ' : [ [ 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 0 , 0 , 0 , 0 , 0 ] , [ 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 ] , [ 1 , 1 , 1 , 1 , 1 , 1 , 1 , 0 , 0 , 0 ,0 , 0 , 0 ]]}Truncation 截断
另一方面,有时序列可能太长,模型无法处理。在这种情况下,您需要将序列截断为较短的长度。
将参数设置truncation为True将序列截断为模型接受的最大长度;
batch_sentences = ["But what about second breakfast?","Don't think he knows about second breakfast, Pip.","What about elevensies?",
]
encoded_input = tokenizer(batch_sentences, padding=True, truncation=True)
print(encoded_input)
# 输出结果
{ 'input_ids' : [[ 101 , 1252 , 1184 , 1164 , 1248 , 6462 , 136 , 102 , 0 , 0 , 0 , 0 , 0 , 0 , 0 ], [ 101 , 1790 , 112 , 189 , 1341 , 1119 , 3520 , 1164 , 1248 , 6462 , 117 , 21902 , 1643 , 119 , 102 ], [ 101,1327,1164,5450,23434,136,102,0,0,0,0,0,0,0,0,0,0 ] ] , ' token_type_ids ':[ [ 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0 ] , [ 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0 ] ,[ 0,0,0,0,0,0,0,0,0,0,0,0,0 ,0,0 ] ],' attention_mask ' : [ [ 1 ,1,1,1,1,1,1,1,1,0,0,0,0,0,0 ] , [ 1,1,1,1,1,1,1,1,1,1,1,1,1 ],[ 1,1,1 ,1,1,1,1 ,0,0,0 ,0 ,0,0,0 ] ] }
构建张量
基于Pytorch构建
batch_sentences = ["But what about second breakfast?","Don't think he knows about second breakfast, Pip.","What about elevensies?",
]
encoded_input = tokenizer(batch_sentences, padding=True, truncation=True, return_tensors="pt")
print(encoded_input)
#输出结果
{'input_ids': tensor([[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],[101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],[101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]]),'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]),'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]])}
基于TensorFlow构建
batch_sentences = ["But what about second breakfast?","Don't think he knows about second breakfast, Pip.","What about elevensies?",
]
encoded_input = tokenizer(batch_sentences, padding=True, truncation=True, return_tensors="tf")
print(encoded_input)
# 输出结果
{'input_ids': <tf.Tensor: shape=(2, 9), dtype=int32, numpy=
array([[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],[101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],[101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]],dtype=int32)>,'token_type_ids': <tf.Tensor: shape=(2, 9), dtype=int32, numpy=
array([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], dtype=int32)>,'attention_mask': <tf.Tensor: shape=(2, 9), dtype=int32, numpy=
array([[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]], dtype=int32)>}
不同的管道在其 __call__() 中对标记器参数的支持不同。text-2-text-generation 管道仅支持(即传递)truncation。text-generation 管道支持 max_length、truncation、padding 和 add_special_tokens。在 fill-mask 管道中,标记器参数可以在 tokenizer_kwargs 参数(字典)中传递。
音频
对于音频任务,您需要一个特征提取器来为模型准备数据集。特征提取器旨在从原始音频数据中提取特征,并将其转换为张量。
from datasets import load_dataset, Audio
# 从公共数据中下载数据
dataset = load_dataset("PolyAI/minds14", name="en-US", split="train")
# audio列会自动加载并重新采样音频文件
dataset[0]["audio"]
# 输出结果
{ 'array' : array([ 0. , 0.00024414 , - 0.00024414 , ..., - 0.00024414 ,0. , 0. ], dtype=float32),'path' : '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~JOINT_ACCOUNT/602ba55abb1e6d0fbce92065.wav' ,'sampling_rate' : 8000 }
"""
array是以一维数组形式加载(并可能重新采样)的语音信号。
path指向音频文件的位置。
sampling_rate指每秒测量语音信号中的数据点数。
"""
改变采样频率的方法有两种:
# 在加载数据时可以规定采样频率
dataset = dataset.cast_column("audio", Audio(sampling_rate=16_000))# 在传递给特征提取时可以规定采样频率
audio_input = [dataset[0]["audio"]["array"]]
feature_extractor(audio_input, sampling_rate=16000)
如果存在数据的尺寸不合适,可以采用填充或者截断来处理可变序列;
# 创建一个函数来预处理数据集,使音频样本具有相同的长度。指定最大样本长度,特征提取器将填充或截断序列以匹配它;
def preprocess_function(examples):audio_arrays = [x["array"] for x in examples["audio"]]inputs = feature_extractor(audio_arrays,sampling_rate=16000,padding=True,max_length=100000,truncation=True,)return inputs
计算机视觉
对于计算机视觉任务,您需要一个图像处理器来为模型准备数据集。图像预处理包括几个步骤,将图像转换为模型所需的输入。这些步骤包括但不限于调整大小、规范化、颜色通道校正以及将图像转换为张量。
图像预处理通常遵循某种形式的图像增强。图像预处理和图像增强都会转换图像数据,但它们的用途不同:
图像增强可以改变图像,有助于防止过度拟合并提高模型的稳健性。您可以发挥创意来增强数据 - 调整亮度和颜色、裁剪、旋转、调整大小、缩放等。但是,请注意不要通过增强改变图像的含义。
图像预处理可确保图像与模型的预期输入格式相匹配。在微调计算机视觉模型时,必须像最初训练模型时一样对图像进行预处理。
可以使用任何库来进行图像增强。对于图像预处理,请使用ImageProcessor与模型相关的库。
from transformers import AutoImageProcessorimage_processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")# 一些图像增强的功能
from torchvision.transforms import RandomResizedCrop, ColorJitter, Composesize = (image_processor.size["shortest_edge"]if "shortest_edge" in image_processor.sizeelse (image_processor.size["height"], image_processor.size["width"])
)_transforms = Compose([RandomResizedCrop(size), ColorJitter(brightness=0.5, hue=0.5)])
多模态数据
对于涉及多模态输入的任务,需要一个处理器来为模型准备数据集。处理器将两个处理对象(例如标记器和特征提取器)结合在一起。
使用AutoProcessor.from_pretrained()加载处理器:
from transformers import AutoProcessorprocessor = AutoProcessor.from_pretrained("facebook/wav2vec2-base-960h")
相关文章:

Preprocess
Preprocess数据预处理 文本 使用Tokenizer将文本转换为标记序列,创建标记的数值表示,并将它们组装成张量。 预处理文本数据的主要工具是标记器。标记器根据一组规则将文本拆分为标记。标记被转换为数字,然后转换为张量,这些张量…...

stm32 spi接口传输asm330l速率优化(及cpu和dma方式对比)
最近一段时间做了一个mems的项目,项目的方案是stm32g071做主控,读写3颗asm330l的硬件形态。最初是想放置4颗imu芯片,因为pcb空间布局的问题,改放了3颗。但对于软件方案来说无所谓,关键是如何优化spi的传输速率…...

数字时代的文化宝库:存储技术与精神生活
文章目录 1. 文学经典的数字传承2. 音乐的无限可能3. 影视艺术的数字化存储4. 结语 数字时代的文化宝库:存储技术与精神生活 在数字化的浪潮中,存储技术如同一座桥梁,连接着过去与未来,承载着人类文明的瑰宝。随着存储容量的不断增…...

flex: 1 display:flex 导致的宽度失效问题
flex: 1 & display:flex 导致的宽度失效问题 问题复现 有这样的一个业务场景,详情项每行三项分别占33%宽度,每项有label字数不固定所以宽度不固定,还有content 占满标签剩余宽度,文字过多显示省略号, 鼠标划入展示…...

Hive 窗口函数与分析函数深度解析:开启大数据分析的新维度
Hive 窗口函数与分析函数深度解析:开启大数据分析的新维度 在当今大数据蓬勃发展的时代,Hive 作为一款强大的数据仓库工具,其窗口函数和分析函数犹如一把把精巧的手术刀,助力数据分析师们精准地剖析海量数据,挖掘出深…...

前端工程 Node 版本如何选择
1. Node 与 Npm 版本对应 这是一个必知必会的问题,尤其是对于维护那些老掉牙、一坨坨、非常大的有着长期历史的老破大工程。 1.1. package-lock.json 版本 首先你要会看项目的 package-lock.json 文件中的 lockfileVersion 版本号,这对于 NPM 安装来说…...
推荐在线Sql运行
SQL Fiddle 1、网址:SQL Fiddle - Online SQL Compiler for learning & practiceDiscover our free online SQL editor enhanced with AI to chat, explain, and generate code. Support SQL Server, MySQL, MariaDB, PostgreSQL, and SQLite.http://www.sqlfi…...

【数据结构】【线性表】特殊的线性表-字符串
目录 字符串的基本概念 字符串的三要素 字符串的基本概念 串的编码 串的实现及基本运算 顺序串的实现 串的静态数组实现 串的动态数组的实现 顺序存储的四种方案 链式串的实现 基本运算 方案三 方案一 字符串的基本概念 数据结构千千万,…...

app-1 App 逆向环境准备(mumu模拟器+magisk+LSPosed+算法助手+抓包(socksDroid+charles)+Frida环境搭建
一、前言 本篇是基于 mumu模拟器 进行环境配置记录。(真机的后面博客记录) 二、mumu模拟器magiskLSPosed算法助手 2.1、mumu模拟器 选择 mumu 模拟器,下载地址:https://mumu.163.com 安装完成后打开,找到设置中心进…...

在米尔FPGA开发板上实现Tiny YOLO V4,助力AIoT应用
学习如何在 MYIR 的 ZU3EG FPGA 开发板上部署 Tiny YOLO v4,对比 FPGA、GPU、CPU 的性能,助力 AIoT 边缘计算应用。 一、 为什么选择 FPGA:应对 7nm 制程与 AI 限制 在全球半导体制程限制和高端 GPU 受限的大环境下,FPGA 成为了中…...
)
【IT】测试用例模版(含示例)
这里写目录标题 一、测试用例模版二、怎么用模版示例如何使用这个模板 一、测试用例模版 一个相对标准的测试用例模板通常包含以下部分: 测试用例ID:唯一标识符,用于追踪测试用例。测试用例标题:简短描述测试用例的目的。测试用…...

react dnd——一个拖拽组件
React DnD是一个流行的库,用于在React应用程序中实现拖放功能。以下是对React DnD的详细解释,包括示例和API说明: 基本概念 在开始使用React DnD之前,了解以下几个基本概念是很重要的: Drag Source(拖动…...

3GPP R18 LTM(L1/L2 Triggered Mobility)是什么鬼?(三) RACH-less LTM cell switch
这篇看下RACH-less LTM cell switch。 相比于RACH-based LTM,RACH-less LTM在进行LTM cell switch之前就要先知道target cell的TA信息,进而才能进行RACH-less过程,这里一般可以通过UE自行测量或者通过RA过程获取,而这里的RA一般是通过PDCCH order过程触发。根据38.300中的描…...

Flutter解压文件并解析数据
Flutter解压文件并解析数据 前言 在 Flutter 开发中,我们经常需要处理文件的读取和解压。 这在处理应用数据更新、安装包、存档文件等场景中尤为常见。 本文将介绍如何在Flutter中使用archive插件来解压文件并解析数据。 准备 在开始之前,我们需要…...

21、结构体成员分布
结构体中的成员并不是紧挨着分布的,内存分布遵循字节对齐的原则。 按照成员定义的顺序,遵循字节对齐的原则存储。 字节对齐的原则: 找成员中占据字节数最大的成员,以它为单位进行空间空配 --- 遇到数组看元素的类型 每一个成员距离…...

TSWIKI知识库软件
TSWIKI 知识库软件介绍 推荐一个适合本地化部署、自托管的知识库软件 TSWIKI介绍 tswiki 是一个适合小团队、个人的知识库、资料管理的软件,所有数据均本地化存储。可以本地化、私有云部署,安装简单。在线预览。 主要功能说明 1、简化的软件依赖和安…...

深度学习安装环境笔记
1、输出cuda版本 torch.version.cuda 返回的是 PyTorch 在编译时所使用的 CUDA 版本,而不是运行时实际调用的 CUDA 版本。PyTorch 在运行时实际调用的 CUDA 版本取决于系统上安装的 CUDA 驱动和库。 import torch from torch.utils.cpp_extension import CUDA_HOME…...
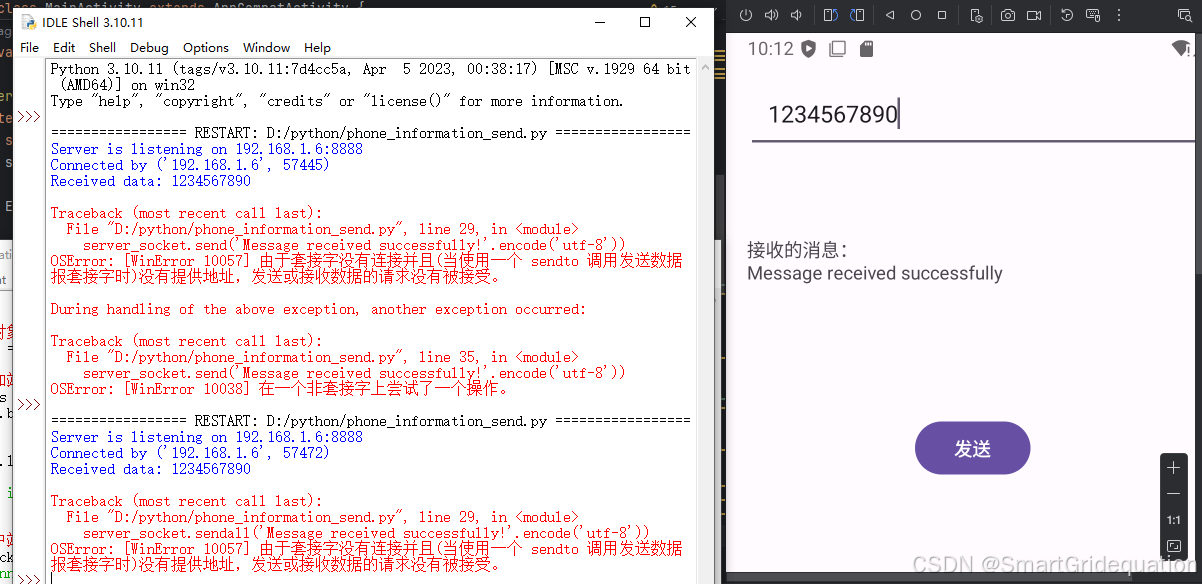
使用android studio写一个Android的远程通信软件(APP),有通讯的发送和接收消息界面
以下是使用 Android Studio 基于 Java 语言编写一个简单的 Android APP 实现远程通信(这里以 TCP 通信为例)的代码示例,包含基本的通信界面以及发送和接收消息功能。 1. 创建项目 打开 Android Studio,新建一个 Empty Activity …...

学习Python的笔记14--迭代器和生成器
1.迭代器(Iterator) 概念: 迭代意味着重复多次,就像循环一样。 迭代器是一个可以记住遍历的位置的对象。 迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。 迭代器只能往前不会后退。 1.iter…...

车机端同步outlook日历
最近在开发一个车机上的日历助手,其中一个需求就是要实现手机端日历和车机端日历数据的同步。然而这种需求似乎没办法实现,毕竟手机日历是手机厂商自己带的系统应用,根本不能和车机端实现数据同步的。 那么只能去其他公共的平台寻求一些机会&…...

Circuit Playground Express 硬件解析与四步编程实战:从创客入门到项目开发
1. 项目概述:为什么选择 Circuit Playground Express 作为创客起点 如果你对硬件编程、物联网或者智能设备感兴趣,但又被 Arduino Uno 上密密麻麻的杜邦线和面包板劝退,或者觉得树莓派 Zero 的 Linux 系统门槛太高,那么 Adafruit…...

图记忆架构:用知识图谱增强AI智能体的长期记忆与推理能力
1. 项目概述:当记忆成为可编程的图最近在探索如何让AI应用真正“记住”复杂的上下文时,我遇到了一个非常有意思的项目:openclaw-memory-graphiti。这个名字听起来有点拗口,但拆解一下就能明白它的野心——“OpenClaw”可能是一个开…...

OxyGent入门指南:10分钟快速搭建你的第一个多智能体系统
OxyGent入门指南:10分钟快速搭建你的第一个多智能体系统 【免费下载链接】OxyGent [ACL 2026] OxyGent: Making Multi-Agent Systems Modular, Observable, and Evolvable via Oxy Abstraction 项目地址: https://gitcode.com/gh_mirrors/ox/OxyGent OxyGent…...

如何用OpenWebRTC实现音视频通话:完整开发教程
如何用OpenWebRTC实现音视频通话:完整开发教程 【免费下载链接】openwebrtc A cross-platform WebRTC client framework based on GStreamer 项目地址: https://gitcode.com/gh_mirrors/op/openwebrtc OpenWebRTC是一个基于GStreamer的跨平台WebRTC客户端框架…...

3步让Windows电脑变身苹果设备:AirPlay 2投屏完全指南
3步让Windows电脑变身苹果设备:AirPlay 2投屏完全指南 【免费下载链接】airplay2-win Airplay2 for windows 项目地址: https://gitcode.com/gh_mirrors/ai/airplay2-win 还在为iPhone视频无法在Windows电脑上播放而烦恼吗?Airplay2-win项目就是为…...

机器人遥测系统设计:从数据采集到可视化监控的工程实践
1. 项目概述:从开源代码仓库到可观测性实践最近在梳理一些开源机器人项目时,遇到了一个名为jizb880/openclaw_telemetry的仓库。乍一看,这个标题由两部分组成:一个可能是作者的用户名jizb880,以及一个极具指向性的项目…...

【无人机路径规划】基于K-means 聚类和遗传算法实现多架无人机任务区域进行划分,并优化各区域内的访问路径附matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、程序设计科研仿真。🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室👇 关注我领取海量matlab电子书和数学建模资料 dz…...

别再死记硬背了!用SPSS搞定系统聚类法,手把手教你从数据录入到谱系图解读
SPSS系统聚类法实战:从数据导入到商业解读的全流程指南 当你的数学建模作业截止日期临近,或者老板突然要求对市场调研数据进行分类分析时,系统聚类法往往是救命稻草。但传统教材中复杂的距离矩阵计算和迭代过程,常让初学者望而生畏…...

Codex自主规划开发工作流实践 Codex CLI、AI编程、自动规划开发、Agent工作流、长任务AI开发、CodexLoop
Codex自主规划开发工作流实践 Codex CLI、AI编程、自动规划开发、Agent工作流、长任务AI开发、CodexLoop 老规矩 先放最新地址: Codex 最新官方客户端下载地址 https://codexdown.cn/ 最近在折腾一件很有意思的事情: 不再给 Codex 写“超详细步骤”&…...

高校实验室项目如何利用Taotoken的Token Plan套餐控制科研实验成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 高校实验室项目如何利用Taotoken的Token Plan套餐控制科研实验成本 对于高校实验室的科研团队和学生项目组而言,在探索…...