Kafka-Connect源码分析
一、上下文
《Kafka-Connect自带示例》中我们尝试了零配置启动producer和consumer去生产和消费数据,那么它内部是如何实现的呢?下面我们从源码来揭开它神秘的面纱。
二、入口类有哪些?
从启动脚本(connect-standalone.sh)中我们可以获取到启动类为ConnectStandalone
# ......省略......exec $(dirname $0)/kafka-run-class.sh $EXTRA_ARGS org.apache.kafka.connect.cli.ConnectStandalone "$@"此外我们在参数中还给了source和sink的配置文件,从这source文件中可以获取到入口类为:FileStreamSource,从sink文件中可以获取到入口类为:FileStreamSink
FileStreamSource对应源码中的FileStreamSourceConnector
FileStreamSink对应源码中的FileStreamSinkConnector
connect-file-source.properties
name=local-file-source
connector.class=FileStreamSource
tasks.max=1
file=/opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/etc/kafka/conf.dist/connect-file-test-data/source.txt
topic=connect-test
connect-file-sink.properties
name=local-file-sink
connector.class=FileStreamSink
tasks.max=1
file=/opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/etc/kafka/conf.dist/connect-file-test-data/sink.txt
topics=connect-test
三、ConnectStandalone
它将Kafka Connect作为独立进程运行。在此模式下,work(连接器和任务)不会被分配。相反,所有正常的Connect机器都在一个过程中工作。适合一些临时、小型或实验性工作。
在此模式下,连接器和任务配置存储在内存中,不是持久的。但是,连接器偏移数据是持久的,因为它使用文件存储(可通过offset.storage.file.filename配置)
public class ConnectStandalone extends AbstractConnectCli<StandaloneConfig> {public static void main(String[] args) {ConnectStandalone connectStandalone = new ConnectStandalone(args);//调用父类的run()connectStandalone.run();}}//这里用到了AbstractConnectCli,它里面有Kafka Connect的通用初始化逻辑。
public abstract class AbstractConnectCli<T extends WorkerConfig> {//验证第一个CLI参数、进程工作器属性,并启动Connectpublic void run() {if (args.length < 1 || Arrays.asList(args).contains("--help")) {log.info("Usage: {}", usage());Exit.exit(1);}try {//connect-standalone.properties 配置文件String workerPropsFile = args[0];//从connect-standalone.properties 中将配置的参数都转成 mapMap<String, String> workerProps = !workerPropsFile.isEmpty() ?Utils.propsToStringMap(Utils.loadProps(workerPropsFile)) : Collections.emptyMap();//这里面存放了 connect-standalone.properties 后的其他参数//比如connect-file-source.properties、connect-file-sink.propertiesString[] extraArgs = Arrays.copyOfRange(args, 1, args.length);//启动ConnectConnect connect = startConnect(workerProps, extraArgs);// 关机将由Ctrl-C或通过HTTP关机请求触发connect.awaitStop();} catch (Throwable t) {log.error("Stopping due to error", t);Exit.exit(2);}}}总结下来做了两件事情
1、初始化connect-standalone.properties配置信息
2、启动Connect
那什么是Connect,且它有做了什么呢?下面我们来看下
1、启动Connect
public abstract class AbstractConnectCli<T extends WorkerConfig> {public Connect startConnect(Map<String, String> workerProps, String... extraArgs) {//Kafka Connect工作进程初始化log.info("Kafka Connect worker initializing ...");long initStart = time.hiResClockMs();WorkerInfo initInfo = new WorkerInfo();initInfo.logAll();//正在扫描插件类。这可能需要一点时间log.info("Scanning for plugin classes. This might take a moment ...");Plugins plugins = new Plugins(workerProps);plugins.compareAndSwapWithDelegatingLoader();T config = createConfig(workerProps);log.debug("Kafka cluster ID: {}", config.kafkaClusterId());RestClient restClient = new RestClient(config);ConnectRestServer restServer = new ConnectRestServer(config.rebalanceTimeout(), restClient, config.originals());restServer.initializeServer();URI advertisedUrl = restServer.advertisedUrl();String workerId = advertisedUrl.getHost() + ":" + advertisedUrl.getPort();//connector.client.config.override.policy 默认值 All//ConnectorClientConfigOverridePolicy 实现的类名或别名。// 定义连接器可以覆盖哪些客户端配置。默认实现为“All”,这意味着连接器配置可以覆盖所有客户端属性。// 框架中的其他可能策略包括“无”禁止连接器覆盖客户端属性,“主体”允许连接器仅覆盖客户端主体ConnectorClientConfigOverridePolicy connectorClientConfigOverridePolicy = plugins.newPlugin(config.getString(WorkerConfig.CONNECTOR_CLIENT_POLICY_CLASS_CONFIG),config, ConnectorClientConfigOverridePolicy.class);Herder herder = createHerder(config, workerId, plugins, connectorClientConfigOverridePolicy, restServer, restClient);final Connect connect = new Connect(herder, restServer);//Kafka Connect工作进程初始化已完成log.info("Kafka Connect worker initialization took {}ms", time.hiResClockMs() - initStart);try {connect.start();} catch (Exception e) {log.error("Failed to start Connect", e);connect.stop();Exit.exit(3);}//这里面会依次处理 connect-file-source.properties、connect-file-sink.properties 等参数processExtraArgs(herder, connect, extraArgs);return connect;}}可以理解connect-standalone.properties是用于启动connect的,connect-file-source.properties是用于启动source任务的的,connect-file-sink.properties是用于启动sink任务的,source、sink的任务是在processExtraArgs(herder, connect, extraArgs)中完成的,这里用到了三个参数,
1、Herder:牧民,可用于在Connect群集上执行操作的实例,它里面有Worker
2、Connect:这个类将Kafka Connect进程的所有组件(牧民、工人、存储、命令接口)联系在一起,管理它们的生命周期
3、extraArgs:用于配置source、sink任务的参数
2、启动source、sink任务
这里我们对着参数(connect-file-source.properties、connect-file-sink.properties)来看更为形象
protected void processExtraArgs(Herder herder, Connect connect, String[] extraArgs) {try {//一个配置一个配置去解析//按照官方的例子会依次解析connect-file-source.properties、connect-file-sink.propertiesfor (final String connectorConfigFile : extraArgs) {CreateConnectorRequest createConnectorRequest = parseConnectorConfigurationFile(connectorConfigFile);FutureCallback<Herder.Created<ConnectorInfo>> cb = new FutureCallback<>((error, info) -> {if (error != null)log.error("Failed to create connector for {}", connectorConfigFile);elselog.info("Created connector {}", info.result().name());});//依次把每个配置文件的解析结果放入 herder 牧民中herder.putConnectorConfig(createConnectorRequest.name(), createConnectorRequest.config(),createConnectorRequest.initialTargetState(),false, cb);//Future的get方法是一个阻塞方法,用于获取任务的运行结果。当调用get方法时,如果任务尚未完成,线程会阻塞,直到任务完成。cb.get();}} catch (Throwable t) {//.....}}下面我们分别用connect-file-source.properties、connect-file-sink.properties带入看看牧民(herder)是如何将任务进行执行的。一份文件就是一个connector,这里我们先分析StandaloneHerder
public class StandaloneHerder extends AbstractHerder {private final ScheduledExecutorService requestExecutorService;StandaloneHerder(Worker worker,String workerId,String kafkaClusterId,StatusBackingStore statusBackingStore,MemoryConfigBackingStore configBackingStore,ConnectorClientConfigOverridePolicy connectorClientConfigOverridePolicy,Time time) {super(worker, workerId, kafkaClusterId, statusBackingStore, configBackingStore, connectorClientConfigOverridePolicy, time);this.configState = ClusterConfigState.EMPTY;//创建一个单线程执行器,可以安排命令在给定延迟后运行,或定期执行。this.requestExecutorService = Executors.newSingleThreadScheduledExecutor();configBackingStore.setUpdateListener(new ConfigUpdateListener());}public void putConnectorConfig(final String connName, final Map<String, String> config, final TargetState targetState,final boolean allowReplace, final Callback<Created<ConnectorInfo>> callback) {try {validateConnectorConfig(config, (error, configInfos) -> {if (error != null) {callback.onCompletion(error, null);return;}//向执行器提交 source 或 sink 的 ConnectorConfigrequestExecutorService.submit(() -> putConnectorConfig(connName, config, targetState, allowReplace, callback, configInfos));});} catch (Throwable t) {callback.onCompletion(t, null);}}private synchronized void putConnectorConfig(String connName,final Map<String, String> config,TargetState targetState,boolean allowReplace,final Callback<Created<ConnectorInfo>> callback,ConfigInfos configInfos) {try {//........//将此连接器配置(以及可选的目标状态)写入持久存储,并等待其被确认,//然后通过在Kafka日志中添加消费者来读回。如果将worker配置为使用fencable生产者写入配置topic,//则必须在调用此方法之前成功调用claimWritePrivileges()configBackingStore.putConnectorConfig(connName, config, targetState);startConnector(connName, (error, result) -> {if (error != null) {callback.onCompletion(error, null);return;}//执行器提交任务requestExecutorService.submit(() -> {updateConnectorTasks(connName);callback.onCompletion(null, new Created<>(created, createConnectorInfo(connName)));});});} catch (Throwable t) {callback.onCompletion(t, null);}}private synchronized void updateConnectorTasks(String connName) {//......//配置 connectorTask 这里会用到配置文件中的connector.class//既:List<Map<String, String>> newTaskConfigs = recomputeTaskConfigs(connName);List<Map<String, String>> rawTaskConfigs = reverseTransform(connName, configState, newTaskConfigs);if (taskConfigsChanged(configState, connName, rawTaskConfigs)) {removeConnectorTasks(connName);configBackingStore.putTaskConfigs(connName, rawTaskConfigs);createConnectorTasks(connName);}}private void createConnectorTasks(String connName) {List<ConnectorTaskId> taskIds = configState.tasks(connName);createConnectorTasks(connName, taskIds);}private void createConnectorTasks(String connName, Collection<ConnectorTaskId> taskIds) {Map<String, String> connConfigs = configState.connectorConfig(connName);for (ConnectorTaskId taskId : taskIds) {//依次启动每个task(配置的 source和sink task)startTask(taskId, connConfigs);}}private boolean startTask(ConnectorTaskId taskId, Map<String, String> connProps) {switch (connectorType(connProps)) {case SINK:return worker.startSinkTask(taskId,configState,connProps,configState.taskConfig(taskId),this,configState.targetState(taskId.connector()));case SOURCE:return worker.startSourceTask(taskId,configState,connProps,configState.taskConfig(taskId),this,configState.targetState(taskId.connector()));default:throw new ConnectException("Failed to start task " + taskId + " since it is not a recognizable type (source or sink)");}}}牧民(Herder)会用Worker来启动配置的SouceTask和SinkTask,最终他们调用的还是同一个方法,只是任务构建器不同而已,下面我们继续分析
Worker启动SouceTask
public boolean startSourceTask(...) {return startTask(id, connProps, taskProps, configState, statusListener,new SourceTaskBuilder(id, configState, statusListener, initialState));}Worker启动SinkTask
public boolean startSinkTask(...) {return startTask(id, connProps, taskProps, configState, statusListener,new SinkTaskBuilder(id, configState, statusListener, initialState));}下面我们共同来分析startTask(...)
//线程池//Executors.newCachedThreadPool()private final ExecutorService executor;private boolean startTask(...){//......//从 connector.class 获取类进行加载String connType = connProps.get(ConnectorConfig.CONNECTOR_CLASS_CONFIG);ClassLoader connectorLoader = plugins.connectorLoader(connType);//......final Class<? extends Task> taskClass = taskConfig.getClass(TaskConfig.TASK_CLASS_CONFIG).asSubclass(Task.class);//对应的sourceTask 和 sinkTaskfinal Task task = plugins.newTask(taskClass);//此处就是根据传的参数来workerTask 会加载不同的Task// SourceTaskBuilder ---> SouceTask// SinkTaskBuilder ---> SinkTaskworkerTask = taskBuilder.withTask(task).withConnectorConfig(connConfig).withKeyConverter(keyConverter).withValueConverter(valueConverter).withHeaderConverter(headerConverter).withClassloader(connectorLoader).build();workerTask.initialize(taskConfig);WorkerTask<?, ?> existing = tasks.putIfAbsent(id, workerTask);//我们继续往下分析,看看 SourceTask 和 SinkTask 都是怎么执行的executor.submit(plugins.withClassLoader(connectorLoader, workerTask));if (workerTask instanceof WorkerSourceTask) {SourceTask 有一个单独 定时提交 offset 的 任务,默认间隔为 1minsourceTaskOffsetCommitter.ifPresent(committer -> committer.schedule(id, (WorkerSourceTask) workerTask));}return true;}
FileStreamSource对应的Task为:FileStreamSourceTask
FileStreamSink对应的Task为:FileStreamSinkTask
Worker会将WorkerTask调起去生产和消费数据
3、调度运行WorkerTask
WorkerTask会提供Worker用于管理任务的基本方法。实现将用户指定的Task与Kafka相结合,以创建数据流。且WorkerTask会放到线程池中进行调度,下面我们看下它的run()
//以下只是主要代码
abstract class WorkerTask<T, R extends ConnectRecord<R>> implements Runnable {public void run() {doRun();}private void doRun() throws InterruptedException {//会初始化 我们在connect-file-source.properties、connect-file-sink.properties中对Producer、Consumer的参数配置doStart();//真的开始// 用对应的SourceTask去读取数据,并交由Producer去生产// 用Consumer接收数据交由 SinkTask去处理数据execute();}}doStart()
void doStart() {retryWithToleranceOperator.reporters(errorReportersSupplier.get());initializeAndStart();statusListener.onStartup(id);}Source 和 Sink 会对initializeAndStart()有不同的实现
Source
这里用的是WorkerTask的子类:AbstractWorkerSourceTask
public abstract class AbstractWorkerSourceTask extends WorkerTask<SourceRecord, SourceRecord> {protected void initializeAndStart() {prepareToInitializeTask();offsetStore.start();//启动标记设置为 truestarted = true;//使用指定的上下文对象初始化此SourceTask。task.initialize(sourceTaskContext);//启动任务。这应该处理任何配置解析和任务的一次性设置。//这里会实际调用 FileStreamSourceTask 或者我们指定的其他 SourceTask的 start()task.start(taskConfig);log.info("{} Source task finished initialization and start", this);}}public class FileStreamSourceTask extends SourceTask {public void start(Map<String, String> props) {AbstractConfig config = new AbstractConfig(FileStreamSourceConnector.CONFIG_DEF, props);//name=local-file-source//connector.class=FileStreamSource//tasks.max=1//file=/opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/etc/kafka/conf.dist/connect-file-test-data/source.txt//topic=connect-test// filefilename = config.getString(FileStreamSourceConnector.FILE_CONFIG);if (filename == null || filename.isEmpty()) {stream = System.in;//跟踪stdin的偏移量没有意义streamOffset = null;reader = new BufferedReader(new InputStreamReader(stream, StandardCharsets.UTF_8));}//topic=connect-testtopic = config.getString(FileStreamSourceConnector.TOPIC_CONFIG);//batch.sizebatchSize = config.getInt(FileStreamSourceConnector.TASK_BATCH_SIZE_CONFIG);}}Sink
这里用的是WorkerTask的子类:WorkerSinkTask
protected void initializeAndStart() {SinkConnectorConfig.validate(taskConfig);//订阅 topicif (SinkConnectorConfig.hasTopicsConfig(taskConfig)) {List<String> topics = SinkConnectorConfig.parseTopicsList(taskConfig);consumer.subscribe(topics, new HandleRebalance());log.debug("{} Initializing and starting task for topics {}", this, String.join(", ", topics));} else {//topics.regex//根据正则设置的 要消费的 topicString topicsRegexStr = taskConfig.get(SinkTask.TOPICS_REGEX_CONFIG);Pattern pattern = Pattern.compile(topicsRegexStr);consumer.subscribe(pattern, new HandleRebalance());log.debug("{} Initializing and starting task for topics regex {}", this, topicsRegexStr);}//初始化此任务的上下文。task.initialize(context);//启动任务。这应该处理任何配置解析和任务的一次性设置。//这里会真正的调用 FileStreamSinkTask 或者 其他我们配置的SinkTask 的 start()task.start(taskConfig);log.info("{} Sink task finished initialization and start", this);}public class FileStreamSinkTask extends SinkTask {public void start(Map<String, String> props) {AbstractConfig config = new AbstractConfig(FileStreamSinkConnector.CONFIG_DEF, props);filename = config.getString(FileStreamSinkConnector.FILE_CONFIG);if (filename == null || filename.isEmpty()) {outputStream = System.out;} else {try {//根据我们在配置文件中结果文件 创建输出流outputStream = new PrintStream(Files.newOutputStream(Paths.get(filename), StandardOpenOption.CREATE, StandardOpenOption.APPEND),false,StandardCharsets.UTF_8.name());} catch (IOException e) {throw new ConnectException("Couldn't find or create file '" + filename + "' for FileStreamSinkTask", e);}}}}execute()
为了看的清晰,这里我们只列举主要代码
Source
public abstract class AbstractWorkerSourceTask extends WorkerTask<SourceRecord, SourceRecord> {public void execute() {while (!isStopping()) {//这里会调用 task.poll(); 也就是从文件读取数据toSend = poll();//这里真的就会调用producer.send() 发送数据sendRecords()}}
}Sink
class WorkerSinkTask extends WorkerTask<ConsumerRecord<byte[], byte[]>, SinkRecord> {public void execute() {while (!isStopping())iteration();}}protected void iteration() {poll(timeoutMs);}protected void poll(long timeoutMs) {//用consumer拉回数据 ConsumerRecords<byte[], byte[]> msgs = pollConsumer(timeoutMs);//转化并交由 自己定义的 SinkTask 处理数据convertMessages(msgs);deliverMessages()}private ConsumerRecords<byte[], byte[]> pollConsumer(long timeoutMs) {ConsumerRecords<byte[], byte[]> msgs = consumer.poll(Duration.ofMillis(timeoutMs));}
}相关文章:

Kafka-Connect源码分析
一、上下文 《Kafka-Connect自带示例》中我们尝试了零配置启动producer和consumer去生产和消费数据,那么它内部是如何实现的呢?下面我们从源码来揭开它神秘的面纱。 二、入口类有哪些? 从启动脚本(connect-standalone.sh&#…...

项目五 李白个人生平(资源)
本项目旨在能够灵活运用整章知识点设计页面。本项目创建了“唐朝诗人群像”网站的第三个页面——即李白个人生平页面,主要完成其 HTML部分。 【项目目的】 灵活运用HTML 基本标记。掌握在 HTML页面中嵌入多媒体对象的方法。【项目内容】 利用HTML标记对网页进行结…...

计算机视觉与各个学科融合:探索新方向
目录 引言计算机视觉与其他学科的结合 与医学的结合与机械工程的结合与土木工程的结合与艺术与人文的结合发文的好处博雅知航的辅导服务 引言 计算机视觉作为人工智能领域的重要分支,正迅速发展并渗透到多个学科。通过与其他领域的结合,计算机视觉不仅…...
)
数据分析类论文通过stata进行数据预处理(一)
一:导入数据 打开Stata命令窗口,输入以下命令: use "文件路径\数据文件名.dta", clear其中,.dta是Stata的数据文件格式。clear选项用于在打开新数据文件前关闭当前数据集。 以下是一些导入不同格式数据的方法&#x…...

力扣——1.返回字符串中第一个唯一的字符;2.把字符串转换成整数(C++)
1.返回字符串中第一个唯一的字符 1.1题目描述 给定一个字符串s ,找到它的第一个不重复的字符,并返回它的索引 。如果不存在,则返回 -1 。 示例: 1.2思路 这里提供两种思路:第一种是利用哈希表,先遍历一…...
M-LAG【根桥方式】
1.M-LAG不是有单向隔离机制天然防环吗,为什么还要使用STP? 答:因为M-LAG设备下面不是只接服务器,也不是和所有下联设备组成M-LAG,和没有组成M-LAG的设备可能会造成环路。 2.为什么要关闭peer-link接口的生成树计算&a…...

新书速览|循序渐进Node.js企业级开发实践
《循序渐进Node.js企业级开发实践》 1 本书内容 《循序渐进Node.js企业级开发实践》结合作者多年一线开发实践,系统地介绍了Node.js技术栈及其在企业级开发中的应用。全书共分5部分,第1部分基础知识(第1~3章)…...

Xlsxwriter生成Excel文件时TypeError异常处理
在使用 XlsxWriter 生成 Excel 文件时,如果遇到 TypeError,通常是因为尝试写入的值或格式与 XlsxWriter 的限制或要求不兼容。 1、问题背景 在使用 Xlsxwriter 库生成 Excel 文件时,出现 TypeError: “expected string or buffer” 异常。此…...

【NLP高频面题 - LLM架构篇】大模型使用SwiGLU相对于ReLU有什么好处?
【NLP高频面题 - LLM架构篇】大模型使用SwiGLU相对于ReLU有什么好处? 重要性:★★★ 💯 NLP Github 项目: NLP 项目实践:fasterai/nlp-project-practice 介绍:该仓库围绕着 NLP 任务模型的设计、训练、优化…...

2021 年“泰迪杯”数据分析技能赛B 题肥料登记数据分析
2021 年“泰迪杯”数据分析技能赛B 题肥料登记数据分析 完整代码请私聊 博主 # 一、背景 肥料是农业生产中一种重要的生产资料,其生产销售必须遵循《肥料登记管理办法》,依法在农业行政管理部门进行登记。各省、自治区、直辖市人民政府农业行政主管部门主…...

网络原理之 IP 协议
目录 1. IP 协议报文格式 2. 网段划分 3. 地址管理 1) 动态分配 2) NAT 机制 (网络地址转换) 3) IPv6 4. 路由选择 1. IP 协议报文格式 IP 协议是网络层的重点协议。 网络层要做的事情,主要就是两方面: 1) 地址管理 制定一系列的规则ÿ…...
来在开发过程中更快速地看到页面的变化。)
在 Spring Boot 项目中使用 Thymeleaf 时,通常情况下,你需要配置热加载(Hot Reload)来在开发过程中更快速地看到页面的变化。
配置步骤: 1. 添加 DevTools 依赖 在 pom.xml 中添加 spring-boot-devtools 依赖。DevTools 提供了自动重启、LiveReload、模板热加载等功能。 <dependencies><!-- Spring Boot DevTools (用于热加载) --><dependency><groupId>org.spri…...

arm-linux GPIO控制-脚本及shell格式
以下是针对BCM编号27, 28, 29, 30, 31的shell命令 shell方式 导出GPIO引脚 echo 27 > /sys/class/gpio/export echo 28 > /sys/class/gpio/export echo 29 > /sys/class/gpio/export echo 30 > /sys/class/gpio/export echo 31 > /sys/class/gpio/export 设…...

Go 语言基础知识语法
很早听人说过一句话:“每年学习(接触)一门新的编程语言”,这听起来可能有点不太现实,但是其实很多种语言都是相通的。掌握新的编程语言不仅仅是增加职业工具箱中的工具,更是一种扩展我们思维方式、解决问题…...

贪心算法part05
文章参考来源代码随想录 (programmercarl.com) 56. 合并区间 本题和前几题类似,都是判断上一个元素的右边界与当前元素的左边界大小关系 但是需要注意是:本题需要更新结果数组元素的右边界,因此比较的是数组最后一个元素右边界与当前元素左…...
)
02、SpringMVC核心(上)
一、RequestMapping注解 @Target({ElementType.TYPE, ElementType.METHOD}) @Retention(RetentionPolicy.RUNTIME) @Documented @Mapping @Reflective({ControllerMappingReflectiveProcessor.class}) public @interface RequestMapping {String name() default "";…...

EasyPlayerPro的同一个组件实例根据url不同展示视频流
效果 学习 url的组成 webrtc://192.168.1.225:8101/index/api/webrtc?applive&stream001&typeplay 协议部分 webrtc://: 这表示使用 WebRTC 协议来进行实时通信。WebRTC 允许浏览器之间直接交换音频、视频和其他数据,而不需要通过中间服务器 主机和端口部分…...
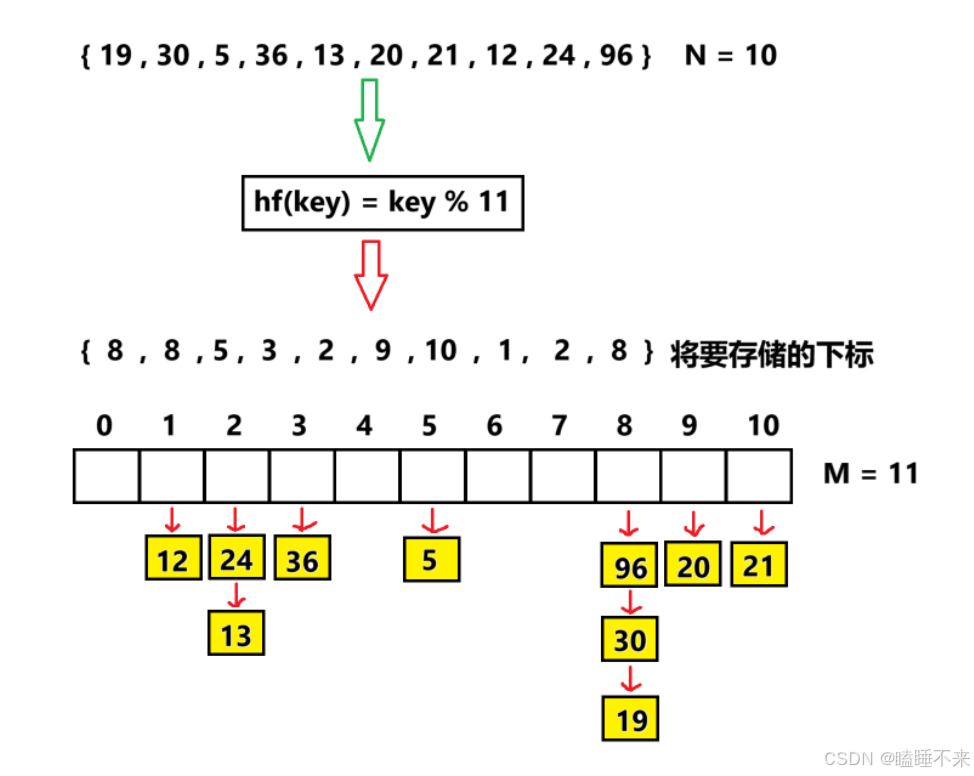
哈希表介绍、实现与封装
哈希表介绍、实现与封装 一、哈希概念二、哈希表实现直接定址法其他映射方法介绍1. 哈希冲突2. 负载因子3. 将关键字转为整数4. 设计哈希函数除法散列法 / 除留余数法乘法散列法全域散列法其他方法 将关键字转为整数处理哈希冲突开放定址法线性探测二次探测双重散列 开放定址法…...

使用vm配置网络
查看本地ip 配置vm网络 配置固定ip vi /etc/sysconfig/network-script/ifcfg-ens33参考 vm使用nat模式,导致vm中docker部署的服务,无法通过局域网中其他机器连接 https://www.cnblogs.com/junwind/p/14345385.html 三张图看懂vm中,三种网…...

OpenStack介绍
OpenStack概述 OpenStack是一个开源的云计算管理平台软件,主要用于构建和管理云计算环境。它允许企业或组织通过数据中心的物理服务器创建和管理虚拟机、存储资源和网络等云计算服务。其核心组件包括计算(Nova)、网络(Neutron)、存储(Cinder、Swift)等。这些组件相互协作…...

Python网络编程利器:pincer中间件框架的设计原理与应用实践
1. 项目概述与核心价值最近在折腾一个游戏服务器的网络通信模块,偶然间在GitHub上看到了一个名为“pincer”的项目,作者是TheOneWhoAlwaysWatches。这个项目名挺有意思,直译过来是“钳子”或“夹子”,在计算机领域,尤其…...

Keil5编译报错‘Target not created’?别急着重装,先试试这几招排查思路
Keil5编译报错‘Target not created’的深度排查指南 当你满怀期待地点击Keil5的编译按钮,却看到冰冷的"Target not created"提示时,那种挫败感我深有体会。这个报错就像一扇紧闭的门,背后可能藏着各种原因——从简单的语法错误到复…...

两个日期到底差几天?
两个日期到底差几天? 网上搜「两个日期相差几天」,底下问题五花八门:合同从签字日到到期日算不算头尾、请假单跨了周末怎么填、租房从 3 月 1 住到 6 月 30 一共多少天、项目里程碑隔了几年 2 月会不会踩闰年……本质都是一件事:…...

别再死记硬背了!用这5个真实项目案例,彻底搞懂Python函数参数与返回值
别再死记硬背了!用这5个真实项目案例,彻底搞懂Python函数参数与返回值 函数是Python编程的基石,但很多初学者在学完基础语法后,面对实际项目依然无从下手。本文将通过5个真实开发场景,带你从"会用"到"懂…...

ComfyUI Video Combine节点3个核心技巧:解决视频合并常见问题
ComfyUI Video Combine节点3个核心技巧:解决视频合并常见问题 【免费下载链接】ComfyUI-VideoHelperSuite Nodes related to video workflows 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-VideoHelperSuite 在AI动画创作中,ComfyUI的Vi…...

别再死记硬背了!用Python模拟超前进位加法器,直观理解其速度优势
用Python模拟超前进位加法器:从硬件原理到算法思维的跨越 在计算机科学和电子工程交叉领域,加法器是最基础却又最精妙的设计之一。传统教学中,我们往往通过抽象的电路图来理解超前进位加法器(CLA)的速度优势࿰…...

终极免费Switch模拟器yuzu:解决电脑玩任天堂游戏的5大痛点
终极免费Switch模拟器yuzu:解决电脑玩任天堂游戏的5大痛点 【免费下载链接】yuzu 任天堂 Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/yu/yuzu 想在电脑上畅玩Switch游戏却总是遇到各种问题?yuzu模拟器作为全球最受欢迎的开源任…...

如何用PCL2启动器打造完美的Minecraft模组体验:从零到精通的完整指南
如何用PCL2启动器打造完美的Minecraft模组体验:从零到精通的完整指南 【免费下载链接】PCL Minecraft 启动器 Plain Craft Launcher(PCL)。 项目地址: https://gitcode.com/gh_mirrors/pc/PCL 你是否厌倦了每次启动Minecraft都要手动配…...
)
别再死记硬背了!用MATLAB手把手教你画根轨迹图(附代码与避坑指南)
MATLAB实战:从零绘制根轨迹图的完整指南与避坑技巧 在控制系统的设计与分析中,根轨迹图是理解系统动态特性的重要工具。传统教学中,学生往往被要求死记硬背绘制规则,却难以理解其实际应用价值。本文将彻底改变这一现状——通过MAT…...

百度网盘直链解析工具:告别限速,实现高速下载的Python解决方案
百度网盘直链解析工具:告别限速,实现高速下载的Python解决方案 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 在数字资源共享日益频繁的今天ÿ…...