基于框架的逻辑回归:原理、实现与应用

目录
编辑
逻辑回归原理
损失函数与优化
正则化
基于框架的实现
1. 数据预处理
2. 模型初始化与训练
3. 模型评估与调优
4. 特征缩放
逻辑回归的应用
信用评分
医疗诊断
垃圾邮件识别
推荐系统
结论
在机器学习领域,逻辑回归是一种基础且强大的分类算法,尤其适用于二分类问题。本文将详细介绍逻辑回归的原理、如何在流行的机器学习框架中实现逻辑回归,以及其在实际应用中的价值。
逻辑回归原理
逻辑回归的核心在于使用逻辑函数(通常是Sigmoid函数)将线性回归模型的输出映射到0和1之间,从而预测一个事件发生的概率。Sigmoid函数的公式为:
[ ]
其中,( ) 是输入特征的线性组合,即 (
)。这个函数的输出值在0到1之间,可以被解释为属于某个类别的概率。
损失函数与优化
逻辑回归的损失函数通常采用交叉熵损失(Binary Cross-Entropy Loss),它衡量的是模型预测概率与实际发生事件之间的差异。优化算法,如梯度下降,用于最小化这个损失函数,从而找到最佳的模型参数。
为了更深入地理解这一点,我们可以手动计算交叉熵损失:
import numpy as np# 假设y_true是真实标签,y_pred是模型预测的概率
y_true = np.array([0, 1, 1, 0])
y_pred = np.array([0.1, 0.9, 0.8, 0.2])# 计算交叉熵损失
def binary_cross_entropy(y_true, y_pred):# 避免对数为0的情况y_pred = np.clip(y_pred, 1e-15, 1 - 1e-15)return -np.mean(y_true * np.log(y_pred) + (1 - y_true) * np.log(1 - y_pred))loss = binary_cross_entropy(y_true, y_pred)
print(f"Cross-Entropy Loss: {loss:.4f}")这个损失函数的计算涉及到对数函数,因此我们需要确保预测概率y_pred不会是0或1,因为这会导致对数函数的输入为0,从而产生数学上的错误。np.clip函数在这里被用来限制y_pred的值,防止这种情况的发生。
正则化
为了防止过拟合,逻辑回归可以加入L1正则化(Lasso)或L2正则化(Ridge)。这些正则化技术通过在损失函数中添加一个惩罚项来限制模型的复杂度。正则化项是模型参数的函数,通常与参数的平方和(L2正则化)或绝对值(L1正则化)成比例。
以下是如何在逻辑回归中加入L2正则化的示例:
from sklearn.linear_model import LogisticRegression# 创建带有L2正则化的逻辑回归模型
model_l2 = LogisticRegression(penalty='l2', C=1.0)# 假设X_train和y_train是训练数据和标签
# model_l2.fit(X_train, y_train)# 预测
# y_pred_l2 = model_l2.predict(X_test)# 评估模型
# accuracy_l2 = accuracy_score(y_test, y_pred_l2)
# print(f"Accuracy with L2 regularization: {accuracy_l2:.2f}")在这个例子中,C参数控制正则化的强度。较小的C值表示更大的正则化强度,这会使得模型参数更趋向于0,从而减少模型的复杂度。相反,较大的C值会减弱正则化的效果,允许模型更加复杂。
基于框架的实现
1. 数据预处理
在应用逻辑回归之前,需要对数据进行预处理,包括特征缩放、处理缺失值等,以确保模型能够更好地学习。
以下是如何使用SimpleImputer处理缺失值的示例:
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler# 假设X_train和X_test包含缺失值
imputer = SimpleImputer(strategy='mean')
X_train_imputed = imputer.fit_transform(X_train)
X_test_imputed = imputer.transform(X_test)# 特征缩放
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train_imputed)
X_test_scaled = scaler.transform(X_test_imputed)特征缩放是机器学习中的一个重要步骤,因为它可以加速学习算法的收敛,并提高模型的性能。StandardScaler通过减去平均值并除以标准差来标准化特征,使得每个特征的均值为0,标准差为1。
2. 模型初始化与训练
使用机器学习框架,如scikit-learn,可以方便地初始化和训练逻辑回归模型。以下是使用scikit-learn实现逻辑回归的简单示例:
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix# 加载数据集
iris = load_iris()
X, y = iris.data, iris.target# 数据集划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建逻辑回归模型
model = LogisticRegression()# 训练模型
model.fit(X_train, y_train)# 预测
y_pred = model.predict(X_test)# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")# 显示分类报告
print(classification_report(y_test, y_pred))# 显示混淆矩阵
print(confusion_matrix(y_test, y_pred))在这个例子中,我们首先从scikit-learn库中加载了鸢尾花(Iris)数据集,这是一个经典的多类分类数据集。然后,我们使用train_test_split函数将数据集分为训练集和测试集。接着,我们创建了一个LogisticRegression模型,并使用训练集上的数据来训练它。最后,我们在测试集上评估模型的性能,并打印出准确率、分类报告和混淆矩阵。
3. 模型评估与调优
使用验证集或测试集评估模型性能,并根据评估结果调整模型参数或结构,以优化模型性能。例如,我们可以通过调整正则化强度来防止过拟合:
# 创建带有不同正则化强度的逻辑回归模型
model_with_regularization = LogisticRegression(C=0.1, penalty='l2')# 训练模型
model_with_regularization.fit(X_train, y_train)# 预测
y_pred_regularized = model_with_regularization.predict(X_test)# 评估模型
accuracy_regularized = accuracy_score(y_test, y_pred_regularized)
print(f"Accuracy with L2 regularization: {accuracy_regularized:.2f}")在这个例子中,我们创建了一个新的逻辑回归模型,并设置了不同的正则化强度(C=0.1)。这个参数控制了模型的正则化程度,较小的值表示更强的正则化,可以帮助防止过拟合。通过比较不同正则化强度下的模型性能,我们可以找到最佳的正则化参数。
4. 特征缩放
特征缩放是提高模型性能的重要步骤,尤其是在使用梯度下降算法时。以下是如何使用StandardScaler进行特征缩放的示例:
from sklearn.preprocessing import StandardScaler# 特征缩放
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)# 使用缩放后的特征训练模型
model.fit(X_train_scaled, y_train)# 预测
y_pred_scaled = model.predict(X_test_scaled)# 评估模型
accuracy_scaled = accuracy_score(y_test, y_pred_scaled)
print(f"Accuracy with feature scaling: {accuracy_scaled:.2f}")在这个例子中,我们使用了StandardScaler来标准化特征。标准化后,每个特征的均值为0,标准差为1,这有助于梯度下降算法更快地收敛。我们首先在训练集上拟合StandardScaler,然后将训练集和测试集的特征都进行标准化。接着,我们使用标准化后的特征来训练逻辑回归模型,并在测试集上评估模型的性能。
逻辑回归的应用
逻辑回归因其简单性和有效性,在多个领域有着广泛的应用,包括但不限于:
- 信用评分:预测个人或企业的信用风险。
- 医疗诊断:如预测疾病的发展或患者的生存概率。
- 垃圾邮件识别:在电子邮件服务中识别和过滤垃圾邮件。
- 推荐系统:预测用户对特定产品或服务的偏好。
信用评分
在信用评分领域,逻辑回归可以帮助银行和金融机构评估客户的信用风险。信用评分模型的目标是预测借款人是否会违约。以下是如何使用逻辑回归进行信用评分的详细示例:
# 假设credit_data包含客户的信用信息
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, roc_auc_score
from sklearn.preprocessing import StandardScaler# 加载数据集
credit_data = load_credit_data()
X_credit, y_credit = credit_data.data, credit_data.target# 数据集划分
X_train_credit, X_test_credit, y_train_credit, y_test_credit = train_test_split(X_credit, y_credit, test_size=0.2, random_state=42)# 特征缩放
scaler = StandardScaler()
X_train_credit_scaled = scaler.fit_transform(X_train_credit)
X_test_credit_scaled = scaler.transform(X_test_credit)# 创建逻辑回归模型
model_credit = LogisticRegression()# 训练模型
model_credit.fit(X_train_credit_scaled, y_train_credit)# 预测概率
y_pred_prob_credit = model_credit.predict_proba(X_test_credit_scaled)[:, 1]# 预测
y_pred_credit = model_credit.predict(X_test_credit_scaled)# 评估模型
accuracy_credit = accuracy_score(y_test_credit, y_pred_credit)
roc_auc_credit = roc_auc_score(y_test_credit, y_pred_prob_credit)
print(f"Credit Scoring Accuracy: {accuracy_credit:.2f}")
print(f"Credit Scoring ROC AUC: {roc_auc_credit:.2f}")在这个例子中,我们首先加载了信用数据集,并将数据集分为训练集和测试集。然后,我们使用StandardScaler对特征进行缩放,以确保所有特征都在相同的尺度上。接着,我们创建了一个逻辑回归模型,并使用缩放后的训练集数据来训练它。我们还预测了测试集上的概率,并使用这些概率来计算接收者操作特征(ROC AUC)得分,这是一个衡量模型性能的指标,特别是在信用评分领域。
医疗诊断
在医疗诊断领域,逻辑回归可以帮助医生预测疾病的发展或患者的生存概率。以下是如何使用逻辑回归进行医疗诊断的示例:
# 假设medical_data包含患者的医疗信息
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 加载数据集
medical_data = load_medical_data()
X_medical, y_medical = medical_data.data, medical_data.target# 数据集划分
X_train_medical, X_test_medical, y_train_medical, y_test_medical = train_test_split(X_medical, y_medical, test_size=0.2, random_state=42)# 创建逻辑回归模型
model_medical = LogisticRegression()# 训练模型
model_medical.fit(X_train_medical, y_train_medical)# 预测
y_pred_medical = model_medical.predict(X_test_medical)# 评估模型
accuracy_medical = accuracy_score(y_test_medical, y_pred_medical)
print(f"Medical Diagnosis Accuracy: {accuracy_medical:.2f}")在这个例子中,我们首先加载了医疗数据集,并将数据集分为训练集和测试集。然后,我们创建了一个逻辑回归模型,并使用训练集上的数据来训练它。最后,我们在测试集上评估模型的性能,并打印出准确率。
垃圾邮件识别
在垃圾邮件识别领域,逻辑回归可以帮助电子邮件服务识别和过滤垃圾邮件。以下是如何使用逻辑回归进行垃圾邮件识别的示例:
# 假设spam_data包含邮件信息
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 加载数据集
spam_data = load_spam_data()
X_spam, y_spam = spam_data.data, spam_data.target# 数据集划分
X_train_spam, X_test_spam, y_train_spam, y_test_spam = train_test_split(X_spam, y_spam, test_size=0.2, random_state=42)# 创建逻辑回归模型
model_spam = LogisticRegression()# 训练模型
model_spam.fit(X_train_spam, y_train_spam)# 预测
y_pred_spam = model_spam.predict(X_test_spam)# 评估模型
accuracy_spam = accuracy_score(y_test_spam, y_pred_spam)
print(f"Spam Detection Accuracy: {accuracy_spam:.2f}")在这个例子中,我们首先加载了垃圾邮件数据集,并将数据集分为训练集和测试集。然后,我们创建了一个逻辑回归模型,并使用训练集上的数据来训练它。最后,我们在测试集上评估模型的性能,并打印出准确率。
推荐系统
在推荐系统领域,逻辑回归可以帮助预测用户对特定产品或服务的偏好。以下是如何使用逻辑回归进行推荐系统的示例:
# 假设recommendation_data包含用户和产品信息
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 加载数据集
recommendation_data = load_recommendation_data()
X_recommendation, y_recommendation = recommendation_data.data, recommendation_data.target# 数据集划分
X_train_recommendation, X_test_recommendation, y_train_recommendation, y_test_recommendation = train_test_split(X_recommendation, y_recommendation, test_size=0.2, random_state=42)# 创建逻辑回归模型
model_recommendation = LogisticRegression()# 训练模型
model_recommendation.fit(X_train_recommendation, y_train_recommendation)# 预测
y_pred_recommendation = model_recommendation.predict(X_test_recommendation)# 评估模型
accuracy_recommendation = accuracy_score(y_test_recommendation, y_pred_recommendation)
print(f"Recommendation System Accuracy: {accuracy_recommendation:.2f}")在这个例子中,我们首先加载了推荐系统数据集,并将数据集分为训练集和测试集。然后,我们创建了一个逻辑回归模型,并使用训练集上的数据来训练它。最后,我们在测试集上评估模型的性能,并打印出准确率。
结论
逻辑回归作为一种经典的分类算法,不仅在理论上具有坚实的基础,而且在实际应用中也表现出色。通过现代机器学习框架,我们可以轻松地实现和优化逻辑回归模型,以解决各种分类问题。随着技术的不断进步,逻辑回归仍然是机器学习领域中一个不可忽视的工具。
相关文章:
基于框架的逻辑回归:原理、实现与应用
目录 编辑 逻辑回归原理 损失函数与优化 正则化 基于框架的实现 1. 数据预处理 2. 模型初始化与训练 3. 模型评估与调优 4. 特征缩放 逻辑回归的应用 信用评分 医疗诊断 垃圾邮件识别 推荐系统 结论 在机器学习领域,逻辑回归是一种基础且强大的分类…...

Charts 教程:创建交互式图表的基础
ECharts 是一个开源的、基于 JavaScript 的数据可视化库,它可以帮助你快速创建交互式的图表。无论是简单的柱状图、折线图,还是复杂的地图和关系图,ECharts 都能够轻松应对。本文将带你了解如何在你的网页中使用 ECharts 创建图表,…...

VTK知识学习(20)- 数据的存储与表达
1、数据的存储 1)、vtkDataArray VTK中的内存分配采用连续内存,可以快速地创建、删除和遍历,称之为数据数组(DataArray),用类 vtkDataArray 实现。数组数据的访问是基于索引的,从零开始计数。 以 vtkFloatArray 类来说明如何在 …...

springboot网站开发-使用redis作为定时器控制手机号每日注册次数
springboot网站开发-使用redis作为定时器控制手机号每日注册次数!为了避免,某些手机号,频繁的申请注册,开启了redis数据库配置的定时器模式。下面是设计代码的案例展示。 1: package com.blog.utils;import org.slf4…...
IntelliJ+SpringBoot项目实战(28)--整合Beetl模板框架
在前面的文章里介绍过freemarker,thymeleaf模板引擎,本文介绍另一个性能超高的模板引擎---Beetl,据说此模板引擎的性能远超Freemarker。官网的说法是,Beetl 远超过主流java模板引擎性能(引擎性能5-6倍于FreeMarker,2倍…...

Kafka-Connect源码分析
一、上下文 《Kafka-Connect自带示例》中我们尝试了零配置启动producer和consumer去生产和消费数据,那么它内部是如何实现的呢?下面我们从源码来揭开它神秘的面纱。 二、入口类有哪些? 从启动脚本(connect-standalone.sh&#…...

项目五 李白个人生平(资源)
本项目旨在能够灵活运用整章知识点设计页面。本项目创建了“唐朝诗人群像”网站的第三个页面——即李白个人生平页面,主要完成其 HTML部分。 【项目目的】 灵活运用HTML 基本标记。掌握在 HTML页面中嵌入多媒体对象的方法。【项目内容】 利用HTML标记对网页进行结…...

计算机视觉与各个学科融合:探索新方向
目录 引言计算机视觉与其他学科的结合 与医学的结合与机械工程的结合与土木工程的结合与艺术与人文的结合发文的好处博雅知航的辅导服务 引言 计算机视觉作为人工智能领域的重要分支,正迅速发展并渗透到多个学科。通过与其他领域的结合,计算机视觉不仅…...
)
数据分析类论文通过stata进行数据预处理(一)
一:导入数据 打开Stata命令窗口,输入以下命令: use "文件路径\数据文件名.dta", clear其中,.dta是Stata的数据文件格式。clear选项用于在打开新数据文件前关闭当前数据集。 以下是一些导入不同格式数据的方法&#x…...

力扣——1.返回字符串中第一个唯一的字符;2.把字符串转换成整数(C++)
1.返回字符串中第一个唯一的字符 1.1题目描述 给定一个字符串s ,找到它的第一个不重复的字符,并返回它的索引 。如果不存在,则返回 -1 。 示例: 1.2思路 这里提供两种思路:第一种是利用哈希表,先遍历一…...
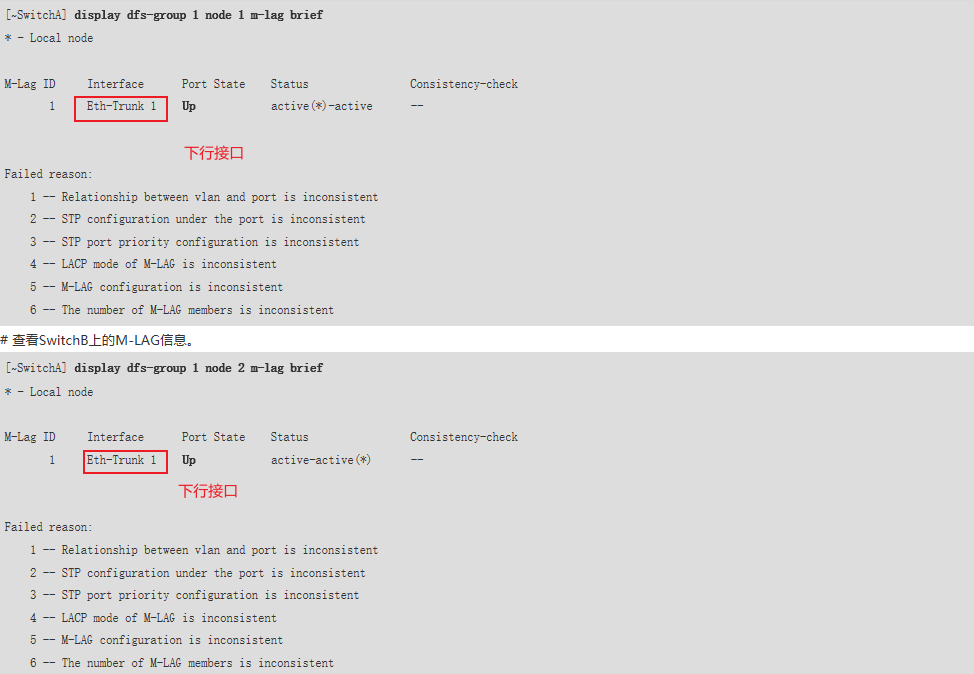
M-LAG【根桥方式】
1.M-LAG不是有单向隔离机制天然防环吗,为什么还要使用STP? 答:因为M-LAG设备下面不是只接服务器,也不是和所有下联设备组成M-LAG,和没有组成M-LAG的设备可能会造成环路。 2.为什么要关闭peer-link接口的生成树计算&a…...

新书速览|循序渐进Node.js企业级开发实践
《循序渐进Node.js企业级开发实践》 1 本书内容 《循序渐进Node.js企业级开发实践》结合作者多年一线开发实践,系统地介绍了Node.js技术栈及其在企业级开发中的应用。全书共分5部分,第1部分基础知识(第1~3章)…...

Xlsxwriter生成Excel文件时TypeError异常处理
在使用 XlsxWriter 生成 Excel 文件时,如果遇到 TypeError,通常是因为尝试写入的值或格式与 XlsxWriter 的限制或要求不兼容。 1、问题背景 在使用 Xlsxwriter 库生成 Excel 文件时,出现 TypeError: “expected string or buffer” 异常。此…...

【NLP高频面题 - LLM架构篇】大模型使用SwiGLU相对于ReLU有什么好处?
【NLP高频面题 - LLM架构篇】大模型使用SwiGLU相对于ReLU有什么好处? 重要性:★★★ 💯 NLP Github 项目: NLP 项目实践:fasterai/nlp-project-practice 介绍:该仓库围绕着 NLP 任务模型的设计、训练、优化…...

2021 年“泰迪杯”数据分析技能赛B 题肥料登记数据分析
2021 年“泰迪杯”数据分析技能赛B 题肥料登记数据分析 完整代码请私聊 博主 # 一、背景 肥料是农业生产中一种重要的生产资料,其生产销售必须遵循《肥料登记管理办法》,依法在农业行政管理部门进行登记。各省、自治区、直辖市人民政府农业行政主管部门主…...

网络原理之 IP 协议
目录 1. IP 协议报文格式 2. 网段划分 3. 地址管理 1) 动态分配 2) NAT 机制 (网络地址转换) 3) IPv6 4. 路由选择 1. IP 协议报文格式 IP 协议是网络层的重点协议。 网络层要做的事情,主要就是两方面: 1) 地址管理 制定一系列的规则ÿ…...
来在开发过程中更快速地看到页面的变化。)
在 Spring Boot 项目中使用 Thymeleaf 时,通常情况下,你需要配置热加载(Hot Reload)来在开发过程中更快速地看到页面的变化。
配置步骤: 1. 添加 DevTools 依赖 在 pom.xml 中添加 spring-boot-devtools 依赖。DevTools 提供了自动重启、LiveReload、模板热加载等功能。 <dependencies><!-- Spring Boot DevTools (用于热加载) --><dependency><groupId>org.spri…...

arm-linux GPIO控制-脚本及shell格式
以下是针对BCM编号27, 28, 29, 30, 31的shell命令 shell方式 导出GPIO引脚 echo 27 > /sys/class/gpio/export echo 28 > /sys/class/gpio/export echo 29 > /sys/class/gpio/export echo 30 > /sys/class/gpio/export echo 31 > /sys/class/gpio/export 设…...

Go 语言基础知识语法
很早听人说过一句话:“每年学习(接触)一门新的编程语言”,这听起来可能有点不太现实,但是其实很多种语言都是相通的。掌握新的编程语言不仅仅是增加职业工具箱中的工具,更是一种扩展我们思维方式、解决问题…...

贪心算法part05
文章参考来源代码随想录 (programmercarl.com) 56. 合并区间 本题和前几题类似,都是判断上一个元素的右边界与当前元素的左边界大小关系 但是需要注意是:本题需要更新结果数组元素的右边界,因此比较的是数组最后一个元素右边界与当前元素左…...

终极GTA5安全增强菜单:YimMenu完全使用指南
终极GTA5安全增强菜单:YimMenu完全使用指南 【免费下载链接】YimMenu YimMenu, a GTA V menu protecting against a wide ranges of the public crashes and improving the overall experience. 项目地址: https://gitcode.com/GitHub_Trending/yi/YimMenu Y…...

对比直接使用厂商 API 通过 Taotoken 聚合调用的账单清晰度差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用厂商 API 与通过 Taotoken 聚合调用的账单清晰度差异 在集成多个大语言模型到业务中时,开发者通常会面临一…...

38岁大厂P9被裁后卖保险:成年人的职场,没有铁饭碗
来自:推荐一个程序员编程资料站:http://cxyroad.com副业赚钱专栏:https://xbt100.top2024年IDEA最新激活方法后台回复:激活码CSDN免登录复制代码插件下载:CSDN复制插件以下是正文。01 | P9也不是免死金牌最近在网上看到…...

多线程渲染与路径算法重构:HiveWE如何革新魔兽争霸III地图编辑
多线程渲染与路径算法重构:HiveWE如何革新魔兽争霸III地图编辑 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 技术痛点:二十年技术债务下的地图创作瓶颈 魔兽争霸III地图编辑器自2…...

Obsidian Image Toolkit:终极图像管理解决方案
Obsidian Image Toolkit:终极图像管理解决方案 【免费下载链接】obsidian-image-toolkit An Obsidian plugin for viewing an image. 项目地址: https://gitcode.com/gh_mirrors/ob/obsidian-image-toolkit Obsidian Image Toolkit 是一款专为 Obsidian 用户…...

开源智能激活方案:KMS_VL_ALL_AIO如何彻底解决Windows和Office激活难题
开源智能激活方案:KMS_VL_ALL_AIO如何彻底解决Windows和Office激活难题 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 你是否曾为Windows系统或Office办公软件未激活而烦恼…...

ClawX:基于RAG的智能代码助手,实现项目级上下文感知编程
1. 项目概述:ClawX,一个面向开发者的智能代码助手最近在GitHub上看到一个挺有意思的项目,叫ClawX。乍一看这个名字,可能会联想到“爪子”或者“抓取”,但它的定位其实是一个AI驱动的代码助手。作为一个在开发一线摸爬滚…...

Qt程序图标设置全攻略:从.ico文件到任务栏显示,一个坑都不踩
Qt程序图标设置全攻略:从资源文件到系统缓存的完整解决方案 第一次用Qt打包发布程序时,我盯着任务栏上那个丑陋的默认图标发呆了十分钟——明明在代码里设置了图标,为什么还是显示不出来?相信很多Qt开发者都遇到过类似问题。图标…...

基于Wasp全栈框架的SaaS启动模板:快速构建多租户应用
1. 项目概述:一个为独立开发者量身定制的开源SaaS蓝图 如果你是一名独立开发者,或者是一个小团队的创始人,心里揣着一个SaaS产品的想法,却总在技术选型、架构设计和持续交付的迷宫里打转,那么 wasp-lang/open-saas …...

LVGUI字体瘦身实战:如何为你的IoT设备定制一个超小的中文字体库
LGVUI字体瘦身实战:为IoT设备定制超小中文字体库的工程化解决方案 在嵌入式物联网设备开发中,每一KB的Flash和RAM都弥足珍贵。当你的智能温控器需要显示"当前温度:25℃"或者电子秤要呈现"净重:0.5kg"时&#…...