【Lambda】java之lambda表达式stream流式编程操作集合
java之lambda表达式&stream流式编程操作集合
- 1 stream流概念
- 1.1 中间操作
- 1.1.1 无状态操作
- 1.1.2 有状态操作
- 1.2 终端操作
- 1.2.1 非短路操作
- 1.2.2 短路操作
- 2 steam流的生成
- 2.1 方式一:数组转为stream流
- 2.2 方式二:集合转为steam流
- 2.3 方式三:Stream.builder创建stream流
- 2.4 方式四:使用 Stream.of 方法
- 2.5 方式五:从文件创建流
- 2.6 方式六:生成无限流
- 3 无状态的中间操作
- 3.1 distinct
- 3.2 limit
- 3.3 skip
- 3.4 sorted
- 3.5 组合使用
- 4 有状态的中间操作
- 4.1 filter(重要)
- 4.2 map(重要)
- 4.3 flatMap
- 4.4 peek
- 4.5 组合使用
- 5 非短路的终端操作
- 5.1 forEach
- 5.2 toArray
- 5.3 reduce(重要)
- 5.4 collect(重要)
- 5.5 min、max、count
- 5.6 组合使用
- 6 短路的终端操作
- 6.1 anyMatch
- 6.2 allMatch
- 6.3 noneMatch
- 6.4 findFirst
- 6.5 findAny
- 6.6 组合使用
- 7 并行流
- 8 总结
1 stream流概念
简单来讲,Stream流是一种用于处理数据集合的高级迭代器,它可以对集合中的元素进行各种操作,如过滤、映射、排序等。通过使用Stream API,我们可以以声明式的方式处理数据,而无需显式地编写循环和条件语句。
Stream流的操作分为两种,中间操作和终端操作。
1.1 中间操作
是指对每个元素独立进行操作,不依赖于其他元素的状态。它们不会改变流中的元素本身,而是创建一个新的Stream对象来表示转换后的结果。常见的无状态中间操作有map、filter、flatMap等。
1.1.1 无状态操作
无状态操作不会改变流中的元素,也不会改变流的状态;这些操作可以并行执行,因为它们不依赖于流中的其他元素。例如:
- distinct:返回去重的Stream。
- limit:限制从流中获得前n个数据,返回前n个元素数据组成的Stream流。
- skip:跳过前n个数据,返回第n个元素后面数据组成的Stream。sorted:返回一个排序的Stream。
1.1.2 有状态操作
有状态操作会改变流的状态,或者依赖于流中的其他元素。这些操作不能并行执行,因为它们需要访问或修改流的状态。
例如:
- filter:过滤流,过滤流中的元素,返回一个符合条件的Stream
- map:转换流,将一种类型的流转换为另外一种流。(mapToInt、mapToLong、mapToDouble 返回int、long、double基本类型对应的Stream)
- peek:主要用来查看流中元素的数据状态,该方法主要用于调试,方便debug查看Stream内进行处理的每个元素。仅在对流内元素进行操作时,peek才会被调用,当不对元素做任何操作时,peek自然也不会被调用了
- flatMap:简单的说,就是一个或多个流合并成一个新流。
1.2 终端操作
是对数据进行最终处理的操作,它们会消耗掉Stream并产生一个结果或者副作用(如输出到控制台)。一旦执行了终端操作,Stream就不能再被使用。常见的终端操作有collect、forEach、reduce等。
1.2.1 非短路操作
非短路操作会处理流中的所有元素,并返回一个结果。
如:
- forEach:循环操作Stream中数据。
- toArray:返回流中元素对应的数组对象。
- reduce:聚合操作,用来做统计,将流中元素反复结合起来统计计算,得到一个值.。
- collect:聚合操作,封装目标数据,将流转换为其他形式接收,如:List、Set、Map、Array。
- min、max、count:聚合操作,最小值,最大值,总数量。
1.2.2 短路操作
短路操作会在满足某个条件时提前结束处理,并返回一个结果。例如:
- anyMatch:短路操作,有一个符合条件返回true。
- allMatch:所有数据都符合条件返回true。
- noneMatch:所有数据都不符合条件返回true。
- findFirst:短路操作,获取第一个元素。
- findAny:短路操作,获取任一元素。
2 steam流的生成
2.1 方式一:数组转为stream流
int [] arr = {1,2,3,4,5,6,7,8,9,10};
Arrays.stream(arr).forEach(System.out::println);
2.2 方式二:集合转为steam流
List<Integer> list = Arrays.asList(1,2,3,4,5,6,7,8,9,10);
list.stream().forEach(System.out::println);
2.3 方式三:Stream.builder创建stream流
Stream.builder创建stream流,允许你逐步构建一个流
Stream.Builder<Integer> builder = Stream.builder();// 添加元素到流中
builder.add(1);
builder.add(2);
builder.add(3);// 构建流
Stream<Integer> stream = builder.build();// 使用流
stream.forEach(System.out::println);
2.4 方式四:使用 Stream.of 方法
Stream.of 方法可以接受一系列元素并返回一个包含这些元素的流。
Stream<String> words = Stream.of("apple", "banana", "orange");
words.forEach(System.out::println);
2.5 方式五:从文件创建流
可以使用 Files.lines 方法从文件中创建流。
try (Stream<String> stream = Files.lines(Paths.get("file.txt"))) {stream.forEach(System.out::println);
} catch (IOException e) {e.printStackTrace();
}
2.6 方式六:生成无限流
可以使用 Stream.generate 或 Stream.iterate 方法来生成无限流。
Stream<Double> randomNumbers = Stream.generate(Math::random);
randomNumbers.forEach(System.out::println);
Stream<Integer> oddNumbers = Stream.iterate(1, n -> n + 2);
oddNumbers.forEach(System.out::println);
3 无状态的中间操作
3.1 distinct
返回一个去重的流,即去除重复的元素
Stream<Integer> distinctStream = Stream.of(1, 2, 2, 3, 4, 4, 5).distinct();
distinctStream.forEach(System.out::println);
//输出结果:12345
3.2 limit
限制从流中获得前n个数据,返回前n个元素数据组成的流
Stream<Integer> limitedStream = Stream.of(1, 2, 3, 4, 5).limit(3);
limitedStream.forEach(System.out::println);
//输出结果:123
3.3 skip
Stream<Integer> skippedStream = Stream.of(1, 2, 3, 4, 5).skip(2);
skippedStream.forEach(System.out::println);
//输出结果:345
3.4 sorted
//正序排序从小到大
Stream<Integer> sortedStream = Stream.of(5, 3, 1, 4, 2).sorted();
sortedStream.forEach(System.out::println);
//输出结果:12345//逆序排序从大到小,Comparator.reverseOrder() 创建了一个逆序比较器,然后传递给 sorted 方法,从而实现了逆序排序
Stream<Integer> sortedStream = Stream.of(5, 3, 1, 4, 2).sorted(Comparator.reverseOrder());
sortedStream.forEach(System.out::println);
//输出结果:54321
3.5 组合使用
这段代码首先去重,然后排序,跳过第一个元素,最后限制结果流只包含前三个元素
Stream<Integer> stream = Stream.of(1, 2, 2, 3, 4, 4, 5).distinct().sorted().skip(1).limit(3);
stream.forEach(System.out::println);
//输出结果:234
测试实体类:
@Data
public class Person {private int id;private String name; // 姓名private int salary; // 薪资private int age; // 年龄private String sex; //性别private String area; // 地区private List<Person> employeeList; //下属public Person() {}// 构造方法public Person(String name, int salary, int age,String sex,String area) {this.name = name;this.salary = salary;this.age = age;this.sex = sex;this.area = area;}// 构造方法public Person(int id, String name, int salary, int age, String sex, String area) {this.id = id;this.name = name;this.salary = salary;this.age = age;this.sex = sex;this.area = area;}@Overridepublic String toString() {return "Person{" +"name='" + name + '\'' +", salary=" + salary +", age=" + age +", sex='" + sex + '\'' +", area='" + area + '\'' +'}';}
}
// 创建一个List来存储Person对象
List<Person> personList = new ArrayList<>();// 创建8个Person对象并添加到列表中
personList.add(new Person(1, "Alice", 5000, 30, "Female", "New York"));
personList.add(new Person(2, "Bob", 6000, 35, "Male", "Los Angeles"));
personList.add(new Person(3, "Charlie", 5500, 28, "Male", "Chicago"));
personList.add(new Person(4, "Diana", 7000, 40, "Female", "Miami"));
personList.add(new Person(5, "Ethan", 4800, 25, "Male", "Houston"));
personList.add(new Person(6, "Fiona", 5300, 32, "Female", "Seattle"));
personList.add(new Person(7, "George", 6200, 38, "Male", "Boston"));
personList.add(new Person(8, "Hannah", 5900, 29, "Female", "San Francisco"));
4 有状态的中间操作
4.1 filter(重要)
// 1. 筛选出所有女性
List<Person> females = personList.stream().filter(person -> person.getSex().equalsIgnoreCase("female")).collect(Collectors.toList());
System.out.println("女性列表: " + females);// 2. 筛选出薪资高于5000的人员
List<Person> highSalary = personList.stream().filter(person -> person.getSalary() > 5000).collect(Collectors.toList());
System.out.println("薪资高于5000的人员: " + highSalary);// 3. 筛选出年龄在30岁及以上的人员
List<Person> ageAbove30 = personList.stream().filter(person -> person.getAge() >= 30).collect(Collectors.toList());
System.out.println("年龄在30岁及以上的人员: " + ageAbove30);// 4. 筛选出居住在特定城市(例如"New York")的人员
List<Person> livingInNewYork = personList.stream().filter(person -> person.getArea().equalsIgnoreCase("New York")).collect(Collectors.toList());
System.out.println("居住在纽约的人员: " + livingInNewYork);// 5. 筛选出名字以"A"开头的人员
List<Person> namesStartingWithA = personList.stream().filter(person -> person.getName().startsWith("A")).collect(Collectors.toList());
System.out.println("名字以A开头的人员: " + namesStartingWithA);
4.2 map(重要)
// 1. 提取所有人的名字
List<String> names = personList.stream().map(Person::getName).collect(Collectors.toList());
System.out.println("所有人的名字: " + names);// 2. 提取所有人的薪资
List<Integer> salaries = personList.stream().map(Person::getSalary).collect(Collectors.toList());
System.out.println("所有人的薪资: " + salaries);// 3. 提取所有人的地区
List<String> cities = personList.stream().map(Person::getArea).collect(Collectors.toList());
System.out.println("所有人的城市: " + cities);// 4. 提取所有人的年龄,并加上10
List<Integer> agesPlus10 = personList.stream().map(person -> person.getAge() + 10).collect(Collectors.toList());
System.out.println("所有人的年龄加十: " + agesPlus10);// 5. 提取薪资信息并格式化为字符串
List<String> salaryInfo = personList.stream().map(person -> person.getName() + "的薪资为: " + person.getSalary()).collect(Collectors.toList());
System.out.println("薪资信息: " + salaryInfo);
4.3 flatMap
flatMap 是 Java Stream API 中的一个非常有用的方法,通常用于将多个流扁平化为一个流。在处理 Person 对象时,我们可以使用 flatMap 来进行一些复杂的数据结构操作。以下是一些示例,展示如何在你的 personList 上使用 flatMap。
List<String> flatMappedList = personList.stream().map(person -> person.getName()) // 将Person对象转换为名字.flatMap(name -> Stream.of(name, name.toUpperCase())) // 将名字转换为名字和名字的大写形式.collect(Collectors.toList());
4.4 peek
personList.stream().peek(person -> System.out.println("Before filter: " + person)) // 打印每个Person对象.filter(person -> person.getAge() > 30) // 过滤年龄大于30的Person对象.peek(person -> System.out.println("After filter: " + person)) // 打印过滤后的Person对象.collect(Collectors.toList());
4.5 组合使用
// 使用Stream API处理personList
List<String> combinedList = personList.stream().filter(person -> person.getAge() > 30) // 过滤年龄大于30的Person对象.map(person -> person.getName()) // 将Person对象转换为名字.flatMap(name -> Stream.of(name, name.toUpperCase())) // 将名字转换为名字和名字的大写形式.peek(System.out::println) // 打印每个名字.collect(Collectors.toList()); // 收集结果到一个List中5 非短路的终端操作
5.1 forEach
personList.stream().forEach(person -> System.out.println(person.getName()));personList.stream().forEachOrdered(person -> System.out.println(person.getName()));
5.2 toArray
Object[] array = personList.stream().toArray();
5.3 reduce(重要)
// 1. 计算总薪资
int totalSalary = personList.stream().map(Person::getSalary).reduce(0, Integer::sum);
System.out.println("总薪资: " + totalSalary);// 2. 计算平均薪资
Optional<Double> averageSalary = personList.stream().map(Person::getSalary).reduce((a, b) -> a + b).map(sum -> sum / (double) personList.size());
System.out.println("平均薪资: " + averageSalary.orElse(0.0));// 3. 查找最高薪资
Optional<Integer> maxSalary = personList.stream().map(Person::getSalary).reduce(Integer::max);
System.out.println("最高薪资: " + maxSalary.orElse(0));// 4. 查找最低薪资
Optional<Integer> minSalary = personList.stream().map(Person::getSalary).reduce(Integer::min);
System.out.println("最低薪资: " + minSalary.orElse(0));// 5. 计算年龄之和
int totalAge = personList.stream().map(Person::getAge).reduce(0, Integer::sum);
System.out.println("总年龄: " + totalAge);
5.4 collect(重要)
//收集到 List集合
List<String> names = personList.stream().map(Person::getName).collect(Collectors.toList());
//收集到 Set集合
Set<String> cities = personList.stream().map(Person::getArea).collect(Collectors.toSet());
//收集到 Map集合
Map<Integer, String> idToNameMap = personList.stream().collect(Collectors.toMap(Person::getId, Person::getName));Map<Integer, Person> idToPersonMap = personList.stream().collect(Collectors.toMap(Person::getId, v -> v));
//收集到自定义集合
List<Person> sortedList = personList.stream().sorted(Comparator.comparing(Person::getAge)).collect(Collectors.toList());
//使用 Collectors.joining 连接字符串
String namesString = personList.stream().map(Person::getName).collect(Collectors.joining(", "));
//Collectors.groupingBy
Map<String, List<Person>> cityToPeopleMap = personList.stream().collect(Collectors.groupingBy(Person::getArea));
//使用 Collectors.partitioningBy 分区
Map<Boolean, List<Person>> isAdultMap = personList.stream().collect(Collectors.partitioningBy(person -> person.getAge() >= 18));
//使用 Collectors.summarizingInt 计算统计信息
IntSummaryStatistics salarySummary = personList.stream().collect(Collectors.summarizingInt(Person::getSalary));
double average = salarySummary.getAverage();//平均值
int max = salarySummary.getMax();//最大值
long count = salarySummary.getCount();//计数
int min = salarySummary.getMin();//最小值
long sum = salarySummary.getSum();//求和
5.5 min、max、count
Optional<Person> maxSalaryPerson = personList.stream().max(Comparator.comparing(Person::getSalary));
Optional<Person> minAgePerson = personList.stream().min(Comparator.comparing(Person::getAge));
long count = personList.stream().count();
5.6 组合使用
这段代码首先计算所有 Person 对象的工资总和,然后找到年龄最大的 Person 对象,最后将所有 Person 对象的名字收集到一个 List 中。
int totalSalary = personList.stream().mapToInt(Person::getSalary).reduce(0, Integer::sum);Optional<Person> oldestPerson = personList.stream().max(Comparator.comparing(Person::getAge));List<String> names = personList.stream().map(Person::getName).collect(Collectors.toList());6 短路的终端操作
6.1 anyMatch
boolean hasFemale = personList.stream().anyMatch(person -> "Female".equals(person.getGender()));
6.2 allMatch
boolean allAdults = personList.stream().allMatch(person -> person.getAge() >= 18);
6.3 noneMatch
boolean noRetired = personList.stream().noneMatch(person -> person.getAge() >= 65);
6.4 findFirst
Optional<Person> firstPerson = personList.stream().findFirst();
6.5 findAny
Optional<Person> anyPerson = personList.stream().findAny();
6.6 组合使用
这段代码首先检查是否存在女性,然后找到第一个成年人,最后将所有成年人的名字收集到一个 List 中。
boolean hasFemale = personList.stream().anyMatch(person -> "Female".equals(person.getGender()));Optional<Person> firstAdult = personList.stream().filter(person -> person.getAge() >= 18).findFirst();List<String> names = personList.stream().filter(person -> person.getAge() >= 18).map(Person::getName).collect(Collectors.toList());
7 并行流
并行流可以提高处理大数据集时的性能。Java Stream API 的并行处理是基于 Java 的 Fork/Join 框架实现的。Fork/Join 框架是 Java 7 引入的一种并行计算框架,它可以将一个大任务拆分成多个小任务,然后在多个处理器上并行执行这些小任务,最后将结果合并。
在 Stream API 中,并行流是通过 parallelStream() 方法创建的。当你调用 parallelStream() 方法时,Stream API 会创建一个 ForkJoinTask,并将其提交给 ForkJoinPool 执行。ForkJoinPool 是一个特殊的线程池,它使用工作窃取算法来平衡任务执行,从而提高并行处理效率。
String allNames = personList.parallelStream().map(Person::getName).collect(Collectors.joining(", "));
System.out.println("All Names (Parallel): " + allNames);
8 总结
Stream API 的主要特点包括:
- 简洁性:Stream API 提供了一种简洁的方式来处理集合数据,使得代码更加易读、易写。
- 可读性:Stream API 的操作可以链式调用,使得代码更加清晰、易读。并行处理:Stream API 支持
- 并行处理,可以充分利用多核处理器的能力。
- 惰性求值:Stream API 的操作是惰性求值的,即只有在需要结果时才会执行操作。
- 无状态操作:Stream API 的无状态操作不会改变流中的元素,也不会改变流的状态。
- 有状态操作:Stream API 的有状态操作会改变流的状态,或者依赖于流中的其他元素。
- 短路操作:Stream API 的短路操作会在满足某个条件时提前结束处理,并返回一个结果。
- 终端操作:Stream API 的终端操作会处理流中的所有元素,并返回一个结果。
创作不易,不妨点赞、收藏、关注支持一下,各位的支持就是我创作的最大动力❤️

相关文章:
【Lambda】java之lambda表达式stream流式编程操作集合
java之lambda表达式&stream流式编程操作集合 1 stream流概念1.1 中间操作1.1.1 无状态操作1.1.2 有状态操作 1.2 终端操作1.2.1 非短路操作1.2.2 短路操作 2 steam流的生成2.1 方式一:数组转为stream流2.2 方式二:集合转为steam流2.3 方式三…...
家具购物小程序+php
基于微信小程序的家具购物小程序的设计与实现 摘要 随着信息技术在管理上越来越深入而广泛的应用,管理信息系统的实施在技术上已逐步成熟。本文介绍了基于微信小程序的家具购物小程序的设计与实现的开发全过程。通过分析基于微信小程序的家具购物小程序的设计与实…...

【GIS教程】使用GDAL-Python将tif转为COG并在ArcGIS Js前端加载-附完整代码
目录 一、数据格式 二、COG特点 三、使用GDAL生成COG格式的数据 四、使用ArcGIS Maps SDK for JavaScript加载COG格式数据 一、数据格式 COG(Cloud optimized GeoTIFF)是一种GeoTiff格式的数据。托管在 HTTP 文件服务器上,可以代替geose…...
与cad交互)
VB.net进行CAD二次开发(二)与cad交互
开发过程遇到了一个问题:自制窗口与控件与CAD的交互。 启动类,调用非模式窗口 Imports Autodesk.AutoCAD.Runtime Public Class Class1 //CAD启动界面 <CommandMethod("US")> Public Sub UiStart() Dim myfrom As Form1 New…...

【NLP 11、Adam优化器】
祝你先于春天, 翻过此间铮铮山峦 —— 24.12.8 一、Adam优化器的基本概念 定义 Adam(Adaptive Moment Estimation)是一种基于梯度的优化算法,用于更新神经网络等机器学习模型中的参数。它结合了动量法(Momentum&…...
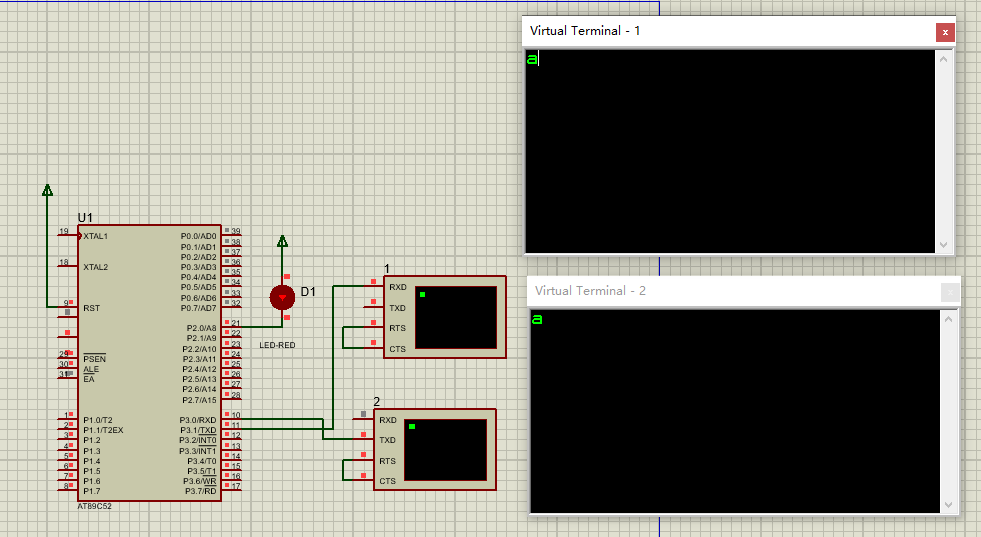
51单片机应用开发(进阶)---串口接收字符命令
实现目标 1、巩固UART知识; 2、掌握串口接收字符数据; 3、具体实现目标:(1)上位机串口助手发送多字符命令,单片机接收命令作相应的处理(如:openled1 即打开LED1;closeled1 即关…...

redis 怎么样删除list
在 Redis 中,可以使用以下方法删除列表或列表中的元素: 1. 删除整个列表 使用 DEL 命令删除一个列表键: DEL mylist这个命令会删除键 mylist 及其值(无论 mylist 是一个列表还是其他类型的键)。 2. 删除列表中的部分…...

【数据结构——内排序】快速排序(头歌实践教学平台习题)【合集】
目录😋 任务描述 测试说明 我的通关代码: 测试结果: 任务描述 本关任务:实现快速排序算法。 测试说明 平台会对你编写的代码进行测试: 测试输入示例: 10 6 8 7 9 0 1 3 2 4 5 (说明:第一行是元素个数&a…...
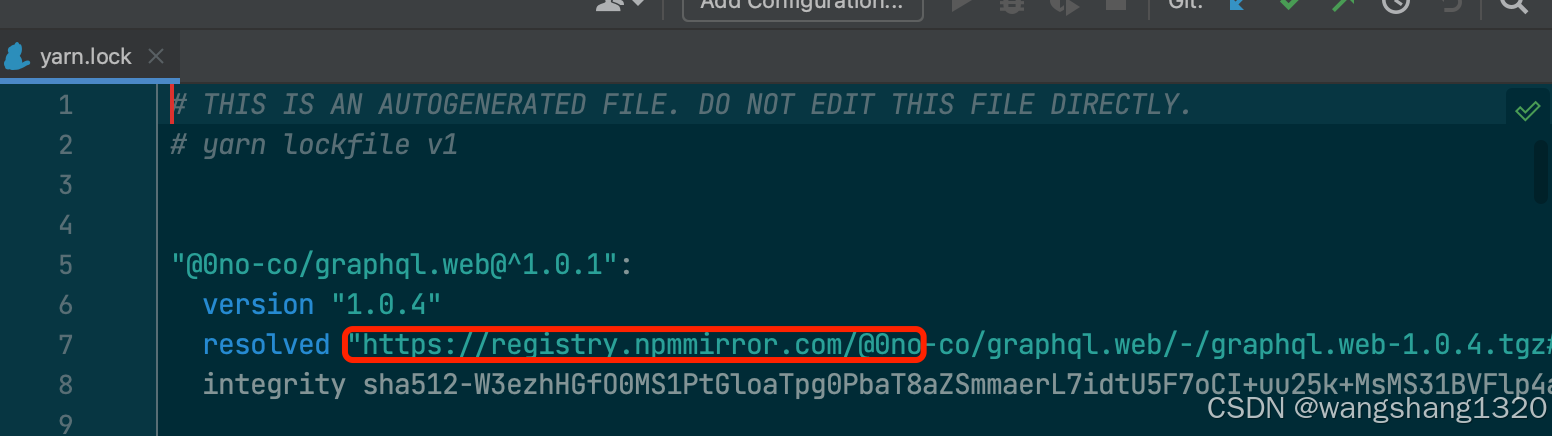
npm或yarn包配置地址源
三种方法 1.配置.npmrc 文件 在更目录新增.npmrc文件 然后写入需要访问的包的地址 2.直接yarn.lock文件里面修改地址 简单粗暴 3.yarn install 的时候添加参数 设置包的仓库地址 yarn config set registry https://registry.yarnpkg.com 安装:yarn install 注意…...

STUN服务器用于内网NAT的方案
在内网中部署 STUN 服务器的场景通常用于处理多层 NAT 或内网客户端之间的通信需求,尤其是在大企业或学校等复杂网络环境下。通过 STUN 服务器,可以帮助客户端设备检测和适配 NAT 转换规则,进而支持 WebRTC 或其他实时通信技术的正常运行。 …...
Linux 简单命令总结
1. 简单命令 1.1. ls 列出该目录下的所有子目录与文件,后面还可以跟上一些选项 常用选项: ・-a 列出目录下的所有文件,包括以。开头的隐含文件。 ・-d 将目录象文件一样显示,而不是显示其下的文件。如:ls -d 指定目…...

Vue.js组件开发:提升你的前端工程能力
Vue.js 是一个用于构建用户界面的渐进式框架,它允许开发者通过组件化的方式创建可复用且易于管理的代码。在 Vue.js 中开发组件是一个直观且高效的过程,下面我将概述如何创建和使用 Vue 组件,并提供一些最佳实践。 1. 创建基本组件 首先&am…...

使用 Pandas 读取 JSON 数据的五种常见结构解析
文章目录 引言JSON 数据的五种常见结构1. split 结构2. records 结构3. index 结构4. columns 结构5. values 结构 引言 在日常生活中,我们经常与各种数据打交道,无论是从网上购物的订单信息到社交媒体上的动态更新。JSON(JavaScript Object…...

C++鼠标轨迹算法(鼠标轨迹模拟真人移动)
一.简介 鼠标轨迹算法是一种模拟人类鼠标操作的程序,它能够模拟出自然而真实的鼠标移动路径。 鼠标轨迹算法的底层实现采用C/C语言,原因在于C/C提供了高性能的执行能力和直接访问操作系统底层资源的能力。 鼠标轨迹算法具有以下优势: 模拟…...
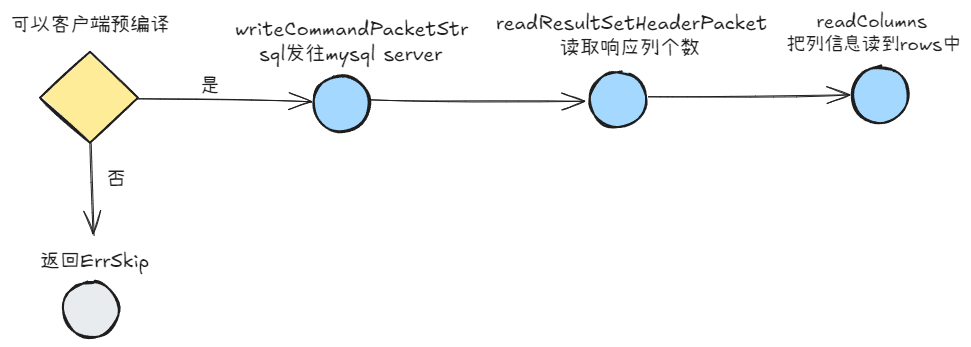
Go mysql驱动源码分析
文章目录 前言注册驱动连接器创建连接交互协议读写数据读数据写数据 mysqlConncontext超时控制 查询发送查询请求读取查询响应 Exec发送exec请求读取响应 预编译客户端预编译服务端预编译生成prepareStmt执行查询操作执行Exec操作 事务读取响应query响应exec响应 总结 前言 go…...
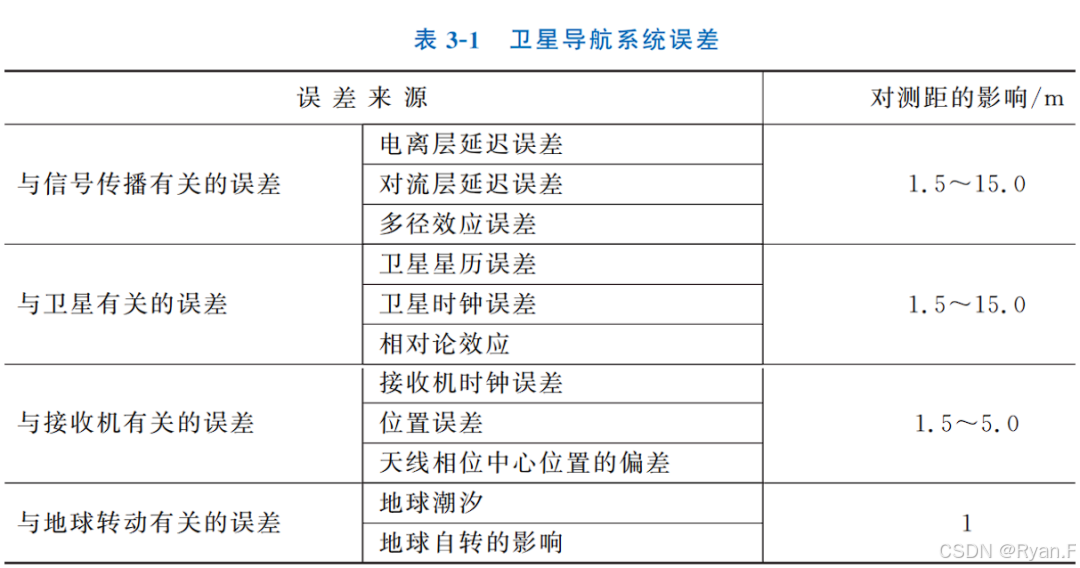
GNSS误差源及差分定位
GNSS误差源: (一)卫星星历误差 由星历信息所得出的卫星位置坐标与实际位置坐标的偏差就是星历误差。星历信息是由 GPS 地面部分测量计算后传入空间部分的。由于卫星在运动中要受到各种摄动力的作用, 而地面部分又很难精确测量这些作用力,…...

pg数据类型
1、数值类型: smallint 2 字节 小范围整数 -32768 到 32767 integer 4 字节 常用的整数 -2147483648 到 2147483647 bigint 8 字节 大范围整数 -9223372036854775808 到 9223372036854775807 decimal 可变长 用户指定的精度&#x…...

【java】finalize方法
目录 1. 说明2. 调用过程3. 注意事项 1. 说明 1.finalize方法是Java中Object类的一个方法。2.finalize方法用于在对象被垃圾回收之前执行一些清理工作。3.当JVM(Java虚拟机)确定一个对象不再被引用、即将被回收时,会调用该对象的finalize方法…...

HNU_多传感器(专选)_作业4(构建单层感知器实现分类)
1. (论述题)(共1题,100分) 假设平面坐标系上有四个点,要求构建单层感知器实现分类。 (3,3),(4,3) 两个点的标签为1; (1,1),(0,2) 两个点的标签为-1。 思路:要分类的数据是2维数据,需要2个输入…...

以太网链路详情
文章目录 1、交换机1、常见的概念1、冲突域2、广播域3、以太网卡1、以太网卡帧 4、mac地址1、mac地址表示2、mac地址分类3、mac地址转换为二进制 2、交换机的工作原理1、mac地址表2、交换机三种数据帧处理行为3、为什么会泛洪4、转发5、丢弃 3、mac表怎么获得4、同网段数据通信…...

使用Taotoken CLI工具一键配置团队开发环境与统一模型端点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken CLI工具一键配置团队开发环境与统一模型端点 当团队需要统一接入多个大模型时,为每位成员手动配置API密钥…...

三维多孔介质催化反应Fluent仿真:从模型构建到关键参数调优的实战解析
1. 三维多孔介质催化反应仿真入门指南 第一次接触Fluent做多孔介质催化反应仿真时,我被复杂的参数设置搞得晕头转向。记得当时为了复现一篇文献结果,整整折腾了两周才摸清门道。这种仿真本质上是通过数值方法模拟流体在多孔催化剂内部的流动、传质和化学…...
:从失效到秒响应的8大关键参数设置)
ChatGPT联网功能深度调优手册(2024实测版):从失效到秒响应的8大关键参数设置
更多请点击: https://intelliparadigm.com 第一章:ChatGPT联网搜索功能失效的典型归因分析 ChatGPT 的联网搜索能力(如通过 Bing 或插件调用实时 Web API)并非内置原生特性,而是依赖外部服务集成与用户端配置协同生效…...

LinkSwift:九大网盘直链下载的技术革新与优雅突围
LinkSwift:九大网盘直链下载的技术革新与优雅突围 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘…...

StreamCap:如何一站式解决40+直播平台录制难题?
StreamCap:如何一站式解决40直播平台录制难题? 【免费下载链接】StreamCap Multi-Platform Live Stream Automatic Recording Tool | 多平台直播流自动录制客户端 基于FFmpeg 支持监控/定时/转码 项目地址: https://gitcode.com/gh_mirrors/st/Strea…...
精准选声公式大公开)
ElevenLabs声音库实战速配:7类行业场景(播客/教育/游戏)精准选声公式大公开
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs声音库核心能力全景图解 ElevenLabs 声音库并非传统意义上的静态音频集合,而是一套基于深度神经语音合成(DNNS)的实时可编程语音基础设施。其核心能力围绕…...

如何快速掌握多尺度地理加权回归:面向数据分析师的完整指南
如何快速掌握多尺度地理加权回归:面向数据分析师的完整指南 【免费下载链接】mgwr Multiscale Geographically Weighted Regression (MGWR) 项目地址: https://gitcode.com/gh_mirrors/mg/mgwr **多尺度地理加权回归(MGWR)**是空间统计…...

如何快速定制ydata-profiling报告模板:CSS样式修改完全指南
如何快速定制ydata-profiling报告模板:CSS样式修改完全指南 【免费下载链接】fg-data-profiling 1 Line of code data quality profiling & exploratory data analysis for Pandas and Spark DataFrames. 项目地址: https://gitcode.com/gh_mirrors/yd/fg-da…...

【AI面试临阵磨枪-56】大模型服务部署:Docker、K8s、GPU 调度、推理加速
一、 面试题目在生产环境中部署大模型服务时,你是如何结合 Docker 和 K8s 实现高效治理的?特别是在 GPU 调度(如共享、切分) 和 推理加速(如 vLLM, TensorRT-LLM) 方面有哪些实战经验?二、 知识…...

算法联盟·全域数学公理体系下黑洞标量毛发与LVK引力波O4全维理论、求导、证明、计算、验证、分析
算法联盟全域数学公理体系下黑洞标量毛发与LVK引力波O4全维理论、求导、证明、计算、验证、分析 算法联盟 全域数学公理体系下黑洞标量毛发与 LVK 引力波O4 全维理论、求导、证明、计算、验证、分析 所属体系:算法联盟 ROOT 全域数学网格第一性原理(AI科…...