深度学习基础--将yolov5的backbone模块用于目标识别会出现怎么效果呢??
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
前言
yolov5网络结构比较复杂,上次我们简要介绍了yolov5网络模块,并且复现了C3模块,深度学习基础–yolov5网络结构简介,C3模块构建;- 这一次我们将复现backbone模块,将目标检测网络结构用到目标识别上,会是怎样的效果呢???;
- 这周是考试周,周一到周四一直都在准备考试和去考试,昨天开始又发高烧,更新较慢;
- 欢迎收藏加关注,本人将会持续更新。
文章目录
- 案例
- 1、数据处理
- 1、导入库
- 2、查看数据类别
- 3、导入数据
- 4、数据集划分
- 5、展示一批数据
- 2、模型构建
- 3、模型训练
- 1、构建训练集
- 2、构建测试集
- 3、设置超参数
- 4、模型正式训练
- 5、结果显示和评估
- 1、结果显示
- 2、评估
案例
将backbone模块用于识别天气分类
1、数据处理
1、导入库
import torch
import torchvision
import torch.nn as nn
import torchvision.transforms as transforms
from torchvision import datasets, transformsdevice = "cuda" if torch.cuda.is_available() else "cpu"device
'cuda'
2、查看数据类别
import os, pathlib data_dir = './data/'
data_dir = pathlib.Path(data_dir)classnames = [str(path).split("\\")[0] for path in os.listdir(data_dir)]
classnames
['cloudy', 'rain', 'shine', 'sunrise']
3、导入数据
data_transforms = transforms.Compose([transforms.Resize([224, 224]),transforms.ToTensor(),transforms.Normalize( # 数据标准化处理---> 转化为 标准状态分布,使模型更容易收敛mean=[0.485, 0.456, 0.406], # rgb,均值std=[0.229, 0.224, 0.225] # rgb,标准差,这两个从数据集中随机抽样得到的)
])total_data = datasets.ImageFolder("./data/", data_transforms)
total_data
Dataset ImageFolderNumber of datapoints: 1125Root location: ./data/StandardTransform
Transform: Compose(Resize(size=[224, 224], interpolation=bilinear, max_size=None, antialias=True)ToTensor()Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]))
4、数据集划分
训练集 :测试集 = 8 :2
train_size = int(len(total_data) * 0.8)
test_size = len(total_data) - train_size
train_data, test_data = torch.utils.data.random_split(total_data, [train_size, test_size])
print("train_size", len(train_data))
print("test_size", len(test_data))
train_size 900
test_size 225
# 动态加载数据集
batch_size = 4train_dl = torch.utils.data.DataLoader(train_data,batch_size=batch_size,shuffle=True
)test_dl = torch.utils.data.DataLoader(test_data,batch_size=batch_size,shuffle=True
)
# 查看数据格式
temp_data, temp_label = next(iter(train_dl))print("data: ", temp_data.shape)
print("data_labels: ", temp_label)
data: torch.Size([4, 3, 224, 224])
data_labels: tensor([3, 2, 0, 0])
5、展示一批数据
这里一批次大小:4
import matplotlib.pyplot as plt temp_images, temp_labels = next(iter(test_dl))plt.figure(figsize=(20, 10))for i in range(4):plt.subplot(5, 5, i + 1)plt.imshow(temp_images[i].cpu().numpy().transpose(1, 2, 0)) # (C, H, W) ==> (H, W, C)plt.title(classnames[temp_labels[i]])plt.axis('off')plt.show()

2、模型构建
整体网络:

C3网络参考:深度学习基础–yolov5网络结构简介,C3模块构建
SPPF网络模块图结构如下:

import torch.nn.functional as F
import warnings # 确保导入 warnings 模块# 自动计算p(填充)
def autop(k, p=None):if p is None:p = k // 2 if isinstance(k, int) else [i // 2 for i in k]return p # Conv模块搭建
'''
卷积层 + 标准化 + 激活函数
'''
class Conv(nn.Module):def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True):super().__init__()'''groups: 1: 标准卷积c1: 深度卷积1 ~ c1: 分组卷积bias:false: 不使用偏置'''self.conv = nn.Conv2d(c1, c2, kernel_size=k, stride=s, padding=autop(k, p), groups=g, bias=False) self.bn = nn.BatchNorm2d(c2)'''act:true: silu激活函数否则: 如果是nn.Mudule(如: nn.Relu), 则调用本身否则: Identity, 什么都不做'''self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module()) else nn.Identity())def forward(self,x):return self.act(self.bn(self.conv(x)))# Bottleneck模块, 用于特征提取和用于防止梯度消失、梯度爆炸问题
class Bottleneck(nn.Module):def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # shortcut: 是否需要残差连接, e: 模型深度super().__init__()c_ = int(c1 * 2)self.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c_, c2, 3, 1, g=g)self.add = shortcut and c1 == c2 def forward(self, x):return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))# 搭建C3模块
class C3(nn.Module):def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):super().__init__()'''刚开始: 卷积层2层后面: n层bottlenck后 concat后 conv'''c_ = int(c1 * e)self.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c1, c_, 1, 1) # 用于拼接self.cv3 = Conv(2 * c_, c2, 1)self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n))) # * 解包def forward(self, x):# 拼接,按照 dim=1维进行拼接,故列要相同return self.cv3(torch.cat([self.m(self.cv1(x)), self.cv2(x)], dim=1)) # 结合图就知道了结构# 搭建SPPF模块,用于特征融合
class SPPF(nn.Module):def __init__(self, c1, c2, k=5):super().__init__()c_ = c1 // 2 self.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c_ * 4, c2, 1, 1) # 模型融合,这个时候模型通道扩大4倍,套用池化层公式,发现通过.m 通道数数不变self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2) # 套用卷积层、池化层公式,发现输出通道不变def forward(self, x):x = self.cv1(x)with warnings.catch_warnings():warnings.simplefilter('ignore')y1 = self.m(x)y2 = self.m(y1)y3 = self.m(y2)return self.cv2(torch.cat([x, y1, y2, y3], 1)) # 结合图# 搭建backbone模块
class Yolov5_backbone(nn.Module):def __init__(self):super(Yolov5_backbone, self).__init__()# 采用常规卷积, kernel_size, stride 与 yolov5.yaml配置文件一致self.conv_1 = Conv(3, 64, 3, 2, 2) self.conv_2 = Conv(64, 128, 3, 2)self.c3_3 = C3(128, 128)self.conv_4 = Conv(128, 256, 3, 2)self.c3_5 = C3(256, 256)self.conv_6 = Conv(256, 512, 3, 2)self.c3_7 = C3(512, 512)self.conv_8 = Conv(512, 1024, 3, 2)self.c3_9 = C3(1024, 1024)self.SPPF_10 = SPPF(1024, 1024, 5)self.classifiler = nn.Sequential(nn.Linear(in_features=65536, out_features=100),nn.ReLU(),nn.Linear(in_features=100, out_features=len(classnames)))def forward(self, x):x = self.conv_1(x)x = self.conv_2(x)x = self.c3_3(x)x = self.conv_4(x)x = self.c3_5(x)x = self.conv_6(x)x = self.c3_7(x)x = self.conv_8(x)x = self.c3_9(x)x = self.SPPF_10(x)x = torch.flatten(x, start_dim=1)x = self.classifiler(x)return x
# 输出参数
model = Yolov5_backbone().to(device)
model
Yolov5_backbone((conv_1): Conv((conv): Conv2d(3, 64, kernel_size=(3, 3), stride=(2, 2), padding=(2, 2), bias=False)(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(conv_2): Conv((conv): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(c3_3): C3((cv1): Conv((conv): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(cv2): Conv((conv): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(cv3): Conv((conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(m): Sequential((0): Bottleneck((cv1): Conv((conv): Conv2d(64, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(cv2): Conv((conv): Conv2d(128, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU()))))(conv_4): Conv((conv): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(c3_5): C3((cv1): Conv((conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(cv2): Conv((conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(cv3): Conv((conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(m): Sequential((0): Bottleneck((cv1): Conv((conv): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(cv2): Conv((conv): Conv2d(256, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU()))))(conv_6): Conv((conv): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(c3_7): C3((cv1): Conv((conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(cv2): Conv((conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(cv3): Conv((conv): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(m): Sequential((0): Bottleneck((cv1): Conv((conv): Conv2d(256, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(cv2): Conv((conv): Conv2d(512, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU()))))(conv_8): Conv((conv): Conv2d(512, 1024, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(c3_9): C3((cv1): Conv((conv): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(cv2): Conv((conv): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(cv3): Conv((conv): Conv2d(1024, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(m): Sequential((0): Bottleneck((cv1): Conv((conv): Conv2d(512, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(cv2): Conv((conv): Conv2d(1024, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU()))))(SPPF_10): SPPF((cv1): Conv((conv): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(cv2): Conv((conv): Conv2d(2048, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)(bn): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(act): SiLU())(m): MaxPool2d(kernel_size=5, stride=1, padding=2, dilation=1, ceil_mode=False))(classifiler): Sequential((0): Linear(in_features=65536, out_features=100, bias=True)(1): ReLU()(2): Linear(in_features=100, out_features=4, bias=True))
)
import torchsummary as summary
summary.summary(model, (3, 224, 224))
----------------------------------------------------------------Layer (type) Output Shape Param #
================================================================Conv2d-1 [-1, 64, 113, 113] 1,728BatchNorm2d-2 [-1, 64, 113, 113] 128SiLU-3 [-1, 64, 113, 113] 0Conv-4 [-1, 64, 113, 113] 0Conv2d-5 [-1, 128, 57, 57] 73,728BatchNorm2d-6 [-1, 128, 57, 57] 256SiLU-7 [-1, 128, 57, 57] 0Conv-8 [-1, 128, 57, 57] 0Conv2d-9 [-1, 64, 57, 57] 8,192BatchNorm2d-10 [-1, 64, 57, 57] 128SiLU-11 [-1, 64, 57, 57] 0Conv-12 [-1, 64, 57, 57] 0Conv2d-13 [-1, 128, 57, 57] 8,192BatchNorm2d-14 [-1, 128, 57, 57] 256SiLU-15 [-1, 128, 57, 57] 0Conv-16 [-1, 128, 57, 57] 0Conv2d-17 [-1, 64, 57, 57] 73,728BatchNorm2d-18 [-1, 64, 57, 57] 128SiLU-19 [-1, 64, 57, 57] 0Conv-20 [-1, 64, 57, 57] 0Bottleneck-21 [-1, 64, 57, 57] 0Conv2d-22 [-1, 64, 57, 57] 8,192BatchNorm2d-23 [-1, 64, 57, 57] 128SiLU-24 [-1, 64, 57, 57] 0Conv-25 [-1, 64, 57, 57] 0Conv2d-26 [-1, 128, 57, 57] 16,384BatchNorm2d-27 [-1, 128, 57, 57] 256SiLU-28 [-1, 128, 57, 57] 0Conv-29 [-1, 128, 57, 57] 0C3-30 [-1, 128, 57, 57] 0Conv2d-31 [-1, 256, 29, 29] 294,912BatchNorm2d-32 [-1, 256, 29, 29] 512SiLU-33 [-1, 256, 29, 29] 0Conv-34 [-1, 256, 29, 29] 0Conv2d-35 [-1, 128, 29, 29] 32,768BatchNorm2d-36 [-1, 128, 29, 29] 256SiLU-37 [-1, 128, 29, 29] 0Conv-38 [-1, 128, 29, 29] 0Conv2d-39 [-1, 256, 29, 29] 32,768BatchNorm2d-40 [-1, 256, 29, 29] 512SiLU-41 [-1, 256, 29, 29] 0Conv-42 [-1, 256, 29, 29] 0Conv2d-43 [-1, 128, 29, 29] 294,912BatchNorm2d-44 [-1, 128, 29, 29] 256SiLU-45 [-1, 128, 29, 29] 0Conv-46 [-1, 128, 29, 29] 0Bottleneck-47 [-1, 128, 29, 29] 0Conv2d-48 [-1, 128, 29, 29] 32,768BatchNorm2d-49 [-1, 128, 29, 29] 256SiLU-50 [-1, 128, 29, 29] 0Conv-51 [-1, 128, 29, 29] 0Conv2d-52 [-1, 256, 29, 29] 65,536BatchNorm2d-53 [-1, 256, 29, 29] 512SiLU-54 [-1, 256, 29, 29] 0Conv-55 [-1, 256, 29, 29] 0C3-56 [-1, 256, 29, 29] 0Conv2d-57 [-1, 512, 15, 15] 1,179,648BatchNorm2d-58 [-1, 512, 15, 15] 1,024SiLU-59 [-1, 512, 15, 15] 0Conv-60 [-1, 512, 15, 15] 0Conv2d-61 [-1, 256, 15, 15] 131,072BatchNorm2d-62 [-1, 256, 15, 15] 512SiLU-63 [-1, 256, 15, 15] 0Conv-64 [-1, 256, 15, 15] 0Conv2d-65 [-1, 512, 15, 15] 131,072BatchNorm2d-66 [-1, 512, 15, 15] 1,024SiLU-67 [-1, 512, 15, 15] 0Conv-68 [-1, 512, 15, 15] 0Conv2d-69 [-1, 256, 15, 15] 1,179,648BatchNorm2d-70 [-1, 256, 15, 15] 512SiLU-71 [-1, 256, 15, 15] 0Conv-72 [-1, 256, 15, 15] 0Bottleneck-73 [-1, 256, 15, 15] 0Conv2d-74 [-1, 256, 15, 15] 131,072BatchNorm2d-75 [-1, 256, 15, 15] 512SiLU-76 [-1, 256, 15, 15] 0Conv-77 [-1, 256, 15, 15] 0Conv2d-78 [-1, 512, 15, 15] 262,144BatchNorm2d-79 [-1, 512, 15, 15] 1,024SiLU-80 [-1, 512, 15, 15] 0Conv-81 [-1, 512, 15, 15] 0C3-82 [-1, 512, 15, 15] 0Conv2d-83 [-1, 1024, 8, 8] 4,718,592BatchNorm2d-84 [-1, 1024, 8, 8] 2,048SiLU-85 [-1, 1024, 8, 8] 0Conv-86 [-1, 1024, 8, 8] 0Conv2d-87 [-1, 512, 8, 8] 524,288BatchNorm2d-88 [-1, 512, 8, 8] 1,024SiLU-89 [-1, 512, 8, 8] 0Conv-90 [-1, 512, 8, 8] 0Conv2d-91 [-1, 1024, 8, 8] 524,288BatchNorm2d-92 [-1, 1024, 8, 8] 2,048SiLU-93 [-1, 1024, 8, 8] 0Conv-94 [-1, 1024, 8, 8] 0Conv2d-95 [-1, 512, 8, 8] 4,718,592BatchNorm2d-96 [-1, 512, 8, 8] 1,024SiLU-97 [-1, 512, 8, 8] 0Conv-98 [-1, 512, 8, 8] 0Bottleneck-99 [-1, 512, 8, 8] 0Conv2d-100 [-1, 512, 8, 8] 524,288BatchNorm2d-101 [-1, 512, 8, 8] 1,024SiLU-102 [-1, 512, 8, 8] 0Conv-103 [-1, 512, 8, 8] 0Conv2d-104 [-1, 1024, 8, 8] 1,048,576BatchNorm2d-105 [-1, 1024, 8, 8] 2,048SiLU-106 [-1, 1024, 8, 8] 0Conv-107 [-1, 1024, 8, 8] 0C3-108 [-1, 1024, 8, 8] 0Conv2d-109 [-1, 512, 8, 8] 524,288BatchNorm2d-110 [-1, 512, 8, 8] 1,024SiLU-111 [-1, 512, 8, 8] 0Conv-112 [-1, 512, 8, 8] 0MaxPool2d-113 [-1, 512, 8, 8] 0MaxPool2d-114 [-1, 512, 8, 8] 0MaxPool2d-115 [-1, 512, 8, 8] 0Conv2d-116 [-1, 1024, 8, 8] 2,097,152BatchNorm2d-117 [-1, 1024, 8, 8] 2,048SiLU-118 [-1, 1024, 8, 8] 0Conv-119 [-1, 1024, 8, 8] 0SPPF-120 [-1, 1024, 8, 8] 0Linear-121 [-1, 100] 6,553,700ReLU-122 [-1, 100] 0Linear-123 [-1, 4] 404
================================================================
Total params: 25,213,112
Trainable params: 25,213,112
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 149.98
Params size (MB): 96.18
Estimated Total Size (MB): 246.74
----------------------------------------------------------------
3、模型训练
1、构建训练集
def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset) # 总数目num_batch = len(dataloader) # 批次数目train_acc, train_loss = 0, 0for X, y in dataloader:X, y = X.to(device), y.to(device) predict = model(X)loss = loss_fn(predict, y)# 梯度清0、求导、重新设置参数optimizer.zero_grad()loss.backward()optimizer.step()train_acc += (predict.argmax(1) == y).type(torch.float).sum().item()train_loss += loss.item()train_acc /= sizetrain_loss /= num_batchreturn train_acc, train_loss
2、构建测试集
def test(dataloader, model, loss_fn):size = len(dataloader.dataset)num_batch = len(dataloader)test_acc, test_loss = 0, 0with torch.no_grad():for X, y in dataloader:X, y = X.to(device), y.to(device)predict = model(X)loss = loss_fn(predict, y)test_acc += (predict.argmax(1) == y).type(torch.float).sum().item()test_loss += loss.item()test_acc /= size test_loss /= num_batchreturn test_acc, test_loss
3、设置超参数
learn_rate = 1e-4
optimizer = torch.optim.Adam(model.parameters(), lr=learn_rate)
loss_fn = nn.CrossEntropyLoss()
4、模型正式训练
import copy epochs = 60train_acc, train_loss, test_acc, test_loss = [], [], [], []best_acc = 0for epoch in range(epochs):model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, optimizer)model.eval()epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)# 保存最佳模型到 best_modelif epoch_test_acc > best_acc:best_acc = epoch_test_accbest_model = copy.deepcopy(model)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)# 获取当前的学习率lr = optimizer.state_dict()['param_groups'][0]['lr']template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}, Lr:{:.2E}')print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss, lr))# 保存最佳模型到文件中
PATH = './best_model.pth' # 保存的参数文件名
torch.save(model.state_dict(), PATH)print('Done')
Epoch: 1, Train_acc:59.0%, Train_loss:1.106, Test_acc:71.1%, Test_loss:0.740, Lr:1.00E-04
Epoch: 2, Train_acc:70.0%, Train_loss:0.776, Test_acc:83.1%, Test_loss:0.468, Lr:1.00E-04
Epoch: 3, Train_acc:75.2%, Train_loss:0.661, Test_acc:84.0%, Test_loss:0.461, Lr:1.00E-04
Epoch: 4, Train_acc:77.4%, Train_loss:0.605, Test_acc:88.4%, Test_loss:0.396, Lr:1.00E-04
Epoch: 5, Train_acc:80.3%, Train_loss:0.529, Test_acc:82.7%, Test_loss:0.415, Lr:1.00E-04
Epoch: 6, Train_acc:83.8%, Train_loss:0.422, Test_acc:83.6%, Test_loss:0.416, Lr:1.00E-04
Epoch: 7, Train_acc:85.8%, Train_loss:0.423, Test_acc:87.1%, Test_loss:0.343, Lr:1.00E-04
Epoch: 8, Train_acc:85.6%, Train_loss:0.393, Test_acc:87.6%, Test_loss:0.306, Lr:1.00E-04
Epoch: 9, Train_acc:86.3%, Train_loss:0.354, Test_acc:89.3%, Test_loss:0.338, Lr:1.00E-04
Epoch:10, Train_acc:86.6%, Train_loss:0.340, Test_acc:92.9%, Test_loss:0.276, Lr:1.00E-04
Epoch:11, Train_acc:88.8%, Train_loss:0.317, Test_acc:90.2%, Test_loss:0.290, Lr:1.00E-04
Epoch:12, Train_acc:87.9%, Train_loss:0.327, Test_acc:88.0%, Test_loss:0.338, Lr:1.00E-04
Epoch:13, Train_acc:89.2%, Train_loss:0.315, Test_acc:92.0%, Test_loss:0.337, Lr:1.00E-04
Epoch:14, Train_acc:91.1%, Train_loss:0.230, Test_acc:92.0%, Test_loss:0.369, Lr:1.00E-04
Epoch:15, Train_acc:93.3%, Train_loss:0.182, Test_acc:89.8%, Test_loss:0.278, Lr:1.00E-04
Epoch:16, Train_acc:91.6%, Train_loss:0.229, Test_acc:90.2%, Test_loss:0.290, Lr:1.00E-04
Epoch:17, Train_acc:90.9%, Train_loss:0.230, Test_acc:91.6%, Test_loss:0.272, Lr:1.00E-04
Epoch:18, Train_acc:93.9%, Train_loss:0.152, Test_acc:92.0%, Test_loss:0.280, Lr:1.00E-04
Epoch:19, Train_acc:94.7%, Train_loss:0.159, Test_acc:92.0%, Test_loss:0.262, Lr:1.00E-04
Epoch:20, Train_acc:95.9%, Train_loss:0.124, Test_acc:91.1%, Test_loss:0.260, Lr:1.00E-04
Epoch:21, Train_acc:95.7%, Train_loss:0.102, Test_acc:88.9%, Test_loss:0.342, Lr:1.00E-04
Epoch:22, Train_acc:95.9%, Train_loss:0.113, Test_acc:92.4%, Test_loss:0.275, Lr:1.00E-04
Epoch:23, Train_acc:96.1%, Train_loss:0.130, Test_acc:92.9%, Test_loss:0.308, Lr:1.00E-04
Epoch:24, Train_acc:94.8%, Train_loss:0.161, Test_acc:86.7%, Test_loss:0.456, Lr:1.00E-04
Epoch:25, Train_acc:95.2%, Train_loss:0.139, Test_acc:89.3%, Test_loss:0.428, Lr:1.00E-04
Epoch:26, Train_acc:96.0%, Train_loss:0.103, Test_acc:92.9%, Test_loss:0.313, Lr:1.00E-04
Epoch:27, Train_acc:96.0%, Train_loss:0.098, Test_acc:88.9%, Test_loss:0.520, Lr:1.00E-04
Epoch:28, Train_acc:97.2%, Train_loss:0.079, Test_acc:91.1%, Test_loss:0.404, Lr:1.00E-04
Epoch:29, Train_acc:98.6%, Train_loss:0.037, Test_acc:92.0%, Test_loss:0.270, Lr:1.00E-04
Epoch:30, Train_acc:98.8%, Train_loss:0.033, Test_acc:88.4%, Test_loss:0.520, Lr:1.00E-04
Epoch:31, Train_acc:95.6%, Train_loss:0.139, Test_acc:91.6%, Test_loss:0.370, Lr:1.00E-04
Epoch:32, Train_acc:96.7%, Train_loss:0.116, Test_acc:89.3%, Test_loss:0.376, Lr:1.00E-04
Epoch:33, Train_acc:96.4%, Train_loss:0.102, Test_acc:91.6%, Test_loss:0.342, Lr:1.00E-04
Epoch:34, Train_acc:98.6%, Train_loss:0.049, Test_acc:87.1%, Test_loss:0.417, Lr:1.00E-04
Epoch:35, Train_acc:97.9%, Train_loss:0.068, Test_acc:90.7%, Test_loss:0.423, Lr:1.00E-04
Epoch:36, Train_acc:98.3%, Train_loss:0.048, Test_acc:89.3%, Test_loss:0.492, Lr:1.00E-04
Epoch:37, Train_acc:98.0%, Train_loss:0.054, Test_acc:91.1%, Test_loss:0.355, Lr:1.00E-04
Epoch:38, Train_acc:98.6%, Train_loss:0.060, Test_acc:92.4%, Test_loss:0.402, Lr:1.00E-04
Epoch:39, Train_acc:97.9%, Train_loss:0.065, Test_acc:86.7%, Test_loss:0.498, Lr:1.00E-04
Epoch:40, Train_acc:98.0%, Train_loss:0.055, Test_acc:88.4%, Test_loss:0.514, Lr:1.00E-04
Epoch:41, Train_acc:99.1%, Train_loss:0.029, Test_acc:90.7%, Test_loss:0.381, Lr:1.00E-04
Epoch:42, Train_acc:98.0%, Train_loss:0.069, Test_acc:92.4%, Test_loss:0.377, Lr:1.00E-04
Epoch:43, Train_acc:99.4%, Train_loss:0.021, Test_acc:90.2%, Test_loss:0.403, Lr:1.00E-04
Epoch:44, Train_acc:98.0%, Train_loss:0.055, Test_acc:85.3%, Test_loss:0.686, Lr:1.00E-04
Epoch:45, Train_acc:98.0%, Train_loss:0.074, Test_acc:91.1%, Test_loss:0.321, Lr:1.00E-04
Epoch:46, Train_acc:98.6%, Train_loss:0.038, Test_acc:91.6%, Test_loss:0.426, Lr:1.00E-04
Epoch:47, Train_acc:97.4%, Train_loss:0.075, Test_acc:87.1%, Test_loss:0.604, Lr:1.00E-04
Epoch:48, Train_acc:99.6%, Train_loss:0.027, Test_acc:91.6%, Test_loss:0.379, Lr:1.00E-04
Epoch:49, Train_acc:99.8%, Train_loss:0.007, Test_acc:92.4%, Test_loss:0.381, Lr:1.00E-04
Epoch:50, Train_acc:100.0%, Train_loss:0.007, Test_acc:92.9%, Test_loss:0.361, Lr:1.00E-04
Epoch:51, Train_acc:99.8%, Train_loss:0.018, Test_acc:90.7%, Test_loss:0.446, Lr:1.00E-04
Epoch:52, Train_acc:99.0%, Train_loss:0.032, Test_acc:89.8%, Test_loss:0.588, Lr:1.00E-04
Epoch:53, Train_acc:97.7%, Train_loss:0.060, Test_acc:90.7%, Test_loss:0.456, Lr:1.00E-04
Epoch:54, Train_acc:97.7%, Train_loss:0.059, Test_acc:89.8%, Test_loss:0.506, Lr:1.00E-04
Epoch:55, Train_acc:98.6%, Train_loss:0.046, Test_acc:90.7%, Test_loss:0.350, Lr:1.00E-04
Epoch:56, Train_acc:99.7%, Train_loss:0.010, Test_acc:91.6%, Test_loss:0.349, Lr:1.00E-04
Epoch:57, Train_acc:99.6%, Train_loss:0.012, Test_acc:91.6%, Test_loss:0.369, Lr:1.00E-04
Epoch:58, Train_acc:98.9%, Train_loss:0.053, Test_acc:88.9%, Test_loss:0.666, Lr:1.00E-04
Epoch:59, Train_acc:98.2%, Train_loss:0.054, Test_acc:87.1%, Test_loss:0.509, Lr:1.00E-04
Epoch:60, Train_acc:98.7%, Train_loss:0.037, Test_acc:90.2%, Test_loss:0.513, Lr:1.00E-04
Done
5、结果显示和评估
1、结果显示
import matplotlib.pyplot as plt #隐藏警告和显示中文
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率x = range(epochs)
# 创建画板
plt.figure(figsize=(12, 3))
# 子图一
plt.subplot(1, 2, 1)
plt.plot(x, train_acc, label='Train Accurary')
plt.plot(x, test_acc, label='Test Accurary')
plt.legend(loc='lower right')
plt.title("Train and test Accurary")
# 子图二
plt.subplot(1, 2, 2)
plt.plot(x, train_loss, label='Train loss')
plt.plot(x, test_loss, label='Test loss')
plt.legend(loc='upper right')
plt.title("Train and test Loss")plt.show()

👀 解释:
- 总体效果还是不错的,损失率低于1,但是测试集的损失率有点小小不稳定;
- 准确率:刚开始出现了欠拟合的现象,但是后面好了,训练准确率稳定在100%附件(98%、99%等),测试集稳定在90%附件;
- 整体:yolov5这个用于目标检测的网络用语目标识别也是有不错的效果。
2、评估
best_model.load_state_dict(torch.load(PATH, map_location=device))
epoch_test_acc, epoch_test_loss = test(test_dl, best_model, loss_fn)epoch_test_acc, epoch_test_loss
(0.9022222222222223, 0.5129974257313852)
- 准确率在0.9左右,效果良好,且损失率为0.5,低于1.0。
相关文章:
深度学习基础--将yolov5的backbone模块用于目标识别会出现怎么效果呢??
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 前言 yolov5网络结构比较复杂,上次我们简要介绍了yolov5网络模块,并且复现了C3模块,深度学习基础–yolov5网络结构简介&a…...

操作系统(16)I/O软件
前言 操作系统I/O软件是负责管理和控制计算机系统与外围设备(例如键盘、鼠标、打印机、存储设备等)之间交互的软件。 一、I/O软件的定义与功能 定义:I/O软件,也称为输入/输出软件,是计算机系统中用于管理和控制设备与主…...

leetcode437.路径总和III
标签:前缀和 问题:给定一个二叉树的根节点 root ,和一个整数 targetSum ,求该二叉树里节点值之和等于 targetSum 的 路径 的数目。路径 不需要从根节点开始,也不需要在叶子节点结束,但是路径方向必须是向下…...

WebGPU、WebGL 和 OpenGL/Vulkan对比分析
WebGPU、WebGL 和 OpenGL/Vulkan 都是用于图形渲染和计算的图形API,但它们的设计理念、功能和适用场景有所不同。以下是它们的总结和对比分析: 1. WebGPU WebGPU 是一个新的、现代化的图形和计算API,设计目的是为Web平台提供更接近硬件的性…...

不可重入锁与死锁
不可重入锁确实可能导致死锁,特别是在同一线程尝试多次获取同一把锁时。如果锁是不可重入的,那么线程在第二次尝试获取锁时会永远阻塞,从而导致死锁。 不可重入锁与死锁的关系 不可重入锁不允许同一个线程多次获取同一把锁。在以下情况下&am…...

XXE-Lab靶场漏洞复现
1.尝试登录 输入账号admin/密码admin进行登录,并未有页面进行跳转 2.尝试抓包分析请求包数据 我们可以发现页面中存在xml请求,我们就可以构造我们的xml请求语句来获取想要的数据 3.构造语句 <?xml version"1.0" ?> <!DOCTYPE fo…...

从Windows到Linux:跨平台数据库备份与还原
数据库的备份与还原 目录 引言备份 2.1 备份所有数据库2.2 备份单个数据库2.3 备份多个指定数据库 传输备份文件还原 4.1 还原所有数据库4.2 还原单个数据库4.3 还原多个指定数据库 注意事项拓展 1. 引言 在不同的操作系统间进行数据库迁移时,命令行工具是我们的…...
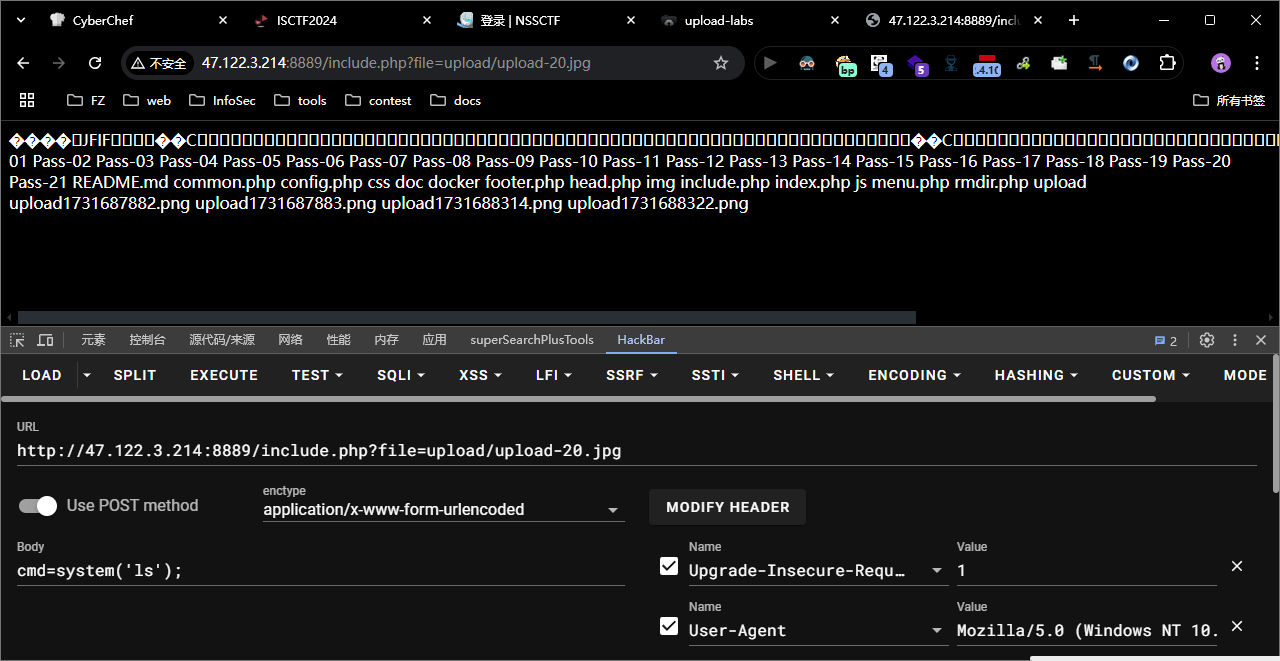
upload-labs
Win平台靶场 靶场2 教程 教程 教程 pass-01 bash 本pass在客户端使用js对不合法图片进行检查!前端绕过, 禁用前端js代码, 或者上传图片, 抓包改后缀为 php , 后端没有校验 bash POST /Pass-01/index.php HTTP/1.1 Host: 47.122.3.214:8889 Content-Length: 49…...

【西门子PLC.博途】——面向对象编程及输入输出映射FC块
当我们做面向对象编程的时候,需要用到输入输出的映射。这样建立的变量就能够被复用,从而最大化利用了我们建立的udt对象。 下面就来讲讲映射是什么。 从本质上来说,映射就是拿实际物理对象对应程序虚拟对象,假设程序对象是I0.0&…...

牛客周赛 Round 72 题解
本次牛客最后一个线段树之前我也没碰到过,等后续复习到线段树再把那个题当例题发出来 小红的01串(一) 思路:正常模拟,从前往后遍历一遍去统计即可 #include<bits/stdc.h> using namespace std; #define int lo…...

Flux Tools 结构简析
Flux Tools 结构简析 BFL 这次一共发布了 Canny、Depth、Redux、Fill 四个 Tools 模型系列,分别对应我们熟悉的 ControlNets、Image Variation(IP Adapter)和 Inpainting 三种图片条件控制方法。虽然实现功能是相同的,但是其具体…...

0 前言
ArCS作为一个基于Rust的CAD(计算机辅助设计)开源系统,尽管已经有四年未更新,但其设计理念和技术实现仍然具有很高的学习和参考价值。以下是对ArCS项目的进一步分析和解读: 一、项目亮点与技术优势 高效与安全的Rust语…...

ARM嵌入式学习--第八天(PWM)
PWM -PWM介绍 PWM(pulse Width Modulation)简称脉宽调制,是利用微处理器的数字输出来对模拟电路进行控制的一种非常有效的技术,广泛应用在测量,通信,工控等方面 PWM的频率 是指在1秒钟内,信号从…...

遇到“REMOTE HOST IDENTIFICATION HAS CHANGED!”(远程主机识别已更改)的警告
连接虚拟机时提示报错: [insocoperhq-soc-cap-raw3 ~]$ ssh root10.99.141.104WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED! IT IS POSSIBLE THAT SOMEONE IS DOING SOMETHING NASTY! Someone could be eavesdropping on you right now (man-in-the-midd…...

vue3前端组件库的搭建与发布(一)
前言: 最近在做公司项目中,有这么一件事情,很是头疼,就是同一套代码,不同项目,要改相同bug,改好多遍,改的都想吐,于是就想做一个组件库,这样更新一下就全都可…...

COMSOL快捷键及内置函数
文章目录 COMSOL快捷键使用COMSOL算子求最大值和最小值COMSOL内置函数3.1 解析函数3.2 插值函数3.3 分段函数3.4 高斯脉冲函数3.5 斜坡函数3.6 矩形函数3.7 波形函数3.8 随机函数3.9 Matlab函数3.10 SWITCH函数 COMSOL快捷键 Ctrl+/ 可快速打开预定义的物理量列表。…...
HUAWEI-eNSP交换机链路聚合(手动负载分担模式)
配置思路:HUAWEI交换机链路聚合有LACP模式跟手动负载分担模式,本文主打手动负载分担模式:首先交换机-PC之间划分基本vlan,交换机-交换机之间创建链路聚合组,划分端口至链路聚合分组(缺省模式为手动负载分担模式)。结果验证要求同vlan可以ping通,关闭某个聚合端口后仍可…...

番外篇 | Hyper-YOLO:超图计算与YOLO架构相结合成为目标检测新的SOTA !
前言:Hello大家好,我是小哥谈。Hyper-YOLO,该方法融合了超图计算以捕捉视觉特征之间复杂的高阶关联。传统的YOLO模型虽然功能强大,但其颈部设计存在局限性,限制了跨层特征的融合以及高阶特征关系的利用。Hyper-YOLO在骨干和颈部的联合增强下,成为一个突破性的架构。在COC…...

【MATLAB第109期】基于MATLAB的带置信区间的RSA区域敏感性分析方法,无目标函数
【MATLAB第108期】基于MATLAB的带置信区间的RSA区域敏感性分析方法,无目标函数 参考第64期文章【MATLAB第64期】【保姆级教程】基于MATLAB的SOBOL全局敏感性分析模型运用(含无目标函数,考虑代理模型) 创新点: 1、采…...

Bootstrap 表格
Bootstrap 表格 引言 Bootstrap 是一个流行的前端框架,它提供了一套丰富的工具和组件,用于快速开发响应式和移动设备优先的网页。在本文中,我们将重点讨论 Bootstrap 中的表格组件,包括其基本结构、样式以及如何使用 Bootstrap …...

sguard_limit:如何彻底解决腾讯游戏反作弊系统导致的电脑卡顿问题
sguard_limit:如何彻底解决腾讯游戏反作弊系统导致的电脑卡顿问题 【免费下载链接】sguard_limit 限制ACE-Guard Client EXE占用系统资源,支持各种腾讯游戏 项目地址: https://gitcode.com/gh_mirrors/sg/sguard_limit 你是否在玩腾讯游戏时遇到过…...

如何高效实现金融核心系统客户证件影像预览?kkFileView完整解决方案
如何高效实现金融核心系统客户证件影像预览?kkFileView完整解决方案 【免费下载链接】kkFileView Universal File Online Preview Project based on Spring-Boot 项目地址: https://gitcode.com/GitHub_Trending/kk/kkFileView 在金融行业日常运营中…...

华硕笔记本终极优化指南:用GHelper彻底释放硬件潜能
华硕笔记本终极优化指南:用GHelper彻底释放硬件潜能 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Strix, Scar…...

原神帧率解锁工具进程管理实战:解决启动冲突的3个鲜为人知的解决技巧
原神帧率解锁工具进程管理实战:解决启动冲突的3个鲜为人知的解决技巧 【免费下载链接】genshin-fps-unlock unlocks the 60 fps cap 项目地址: https://gitcode.com/gh_mirrors/ge/genshin-fps-unlock 问题现象:启动失败的常见场景 当你双击原神…...

AI 时代做自媒体,他从方法论上就赢了绝大部分人
AI 时代做自媒体,他从方法论上就赢了绝大部分人 昨天刷到卡兹克的一篇文章,他分享了自己做内容三年总结的 10 条方法论。 看完之后我的感受是:这哥们从方法论上就赢了。 简单介绍一下卡兹克。他的公众号「数字生命卡兹克」是 AIGC 领域的头部 IP,新榜 AI 行业公众号排名…...

intv_ai_mk11应用场景:金融从业者用其生成监管政策要点摘要、投研报告初稿框架
intv_ai_mk11在金融领域的应用实践:政策摘要与投研报告生成 1. 金融从业者的AI助手需求 金融行业每天需要处理海量的监管政策和市场信息,传统人工处理方式面临三大挑战: 时效性压力:新政策发布后需要快速理解要点信息过载&…...

分布式系统CAP理论之如何取舍
在分布式系统中,CAP 理论 是一个基石性、指导性的理论,它告诉我们:在设计分布式系统时,无法同时满足三个核心特性,只能在三者之间做权衡。🌐 一、CAP 理论的三个字母代表什么?字母含义说明CCons…...

Apache Mesos vs Kubernetes:如何选择最适合你的容器编排平台 [特殊字符]
Apache Mesos vs Kubernetes:如何选择最适合你的容器编排平台 🚀 【免费下载链接】mesos apache/mesos: 这是一个开源的集群管理框架,用于在异构资源池上部署和管理应用程序。它允许开发者使用高效的资源隔离和共享机制,构建高度可…...

OpenClaw自动化边界:gemma-3-12b-it不适合处理的5类任务分析
OpenClaw自动化边界:gemma-3-12b-it不适合处理的5类任务分析 1. 为什么需要明确自动化边界? 上周我在本地部署了OpenClawgemma-3-12b-it组合,本想让它帮我完成一些重复性工作。结果在测试过程中,一个简单的"整理桌面截图并…...

杰理之进入ANC模式播歌,ANC效果变通透【篇】
需与工具ANC配置中dac_gain参数保持一致...