ElasticSearch 数据聚合与运算
1、数据聚合
聚合(aggregations)可以让我们极其方便的实现数据的统计、分析和运算。实现这些统计功能的比数据库的 SQL 要方便的多,而且查询速度非常快,可以实现近实时搜索效果。
注意: 参加聚合的字段必须是 keyword、日期、数值和布尔类型
1.1 聚合的种类
常见的聚合类型:
1.1.1 桶聚合(Bucket):对文档分组,类似 MySQL的 group by 功能
| 类型 | 描述 |
|---|---|
| TermAggregation | 按照文档字段值分组,如:品牌分组 |
| Date Histogram | 按照日期阶梯分组,如:按月分组 |
1.1.2 度量聚合(Metric):值计算,如:最大值、最小值、平均值等等
| 类型 | 描述 |
|---|---|
| Avg | 求平均值 |
| Max | 求最大值 |
| Min | 求最小值 |
| Stats | 同时求max、min、avg、sum等 |
1.1.3 管道聚合(pipeline): 对已聚合的结果为基础做聚合
1.2 聚合示例测试1
需求:从所有酒店数据中,查询酒店金额不大于300的所有酒店品牌的种类,并按照品牌的数量进行逆序排序,筛选出前5个数量最多的品牌。
分析:① 限制酒店金额 ② 根据酒店的品牌做聚合(Bucket)查询 ③ 逆序排序
1.2.1 定义 DSL 语法
GET /hotel/_search
{"query": {"range": {"price": {"lte": 300}}},"size": 0,"aggs": {"brandAggs": {"terms": {"field": "brand","size": 5,"order": {"_count": "desc"}}}}
}
1.2.2 参数说明
- size: 设置为0,结果中不需要包含文档,只返回聚合结果
- aggs:定义聚合,固定值
- brandAgg:聚合名称,自定义语义化即可
- terms: 聚合类型,brand 是一个 keyword 类型的字符串,所以用 terms
- field:参与聚合的字段
- size:希望获取的聚合结果数量
- order:指定排序,按照 _count 逆序排序
- brandAgg:聚合名称,自定义语义化即可
1.2.3 测试结果

1.3 聚合示例测试2
需求: 对酒店的品牌分组,并计算每个品牌的用户评分的最大值、最小值和平均值等,并按照酒店评分的平均值逆序排序
分析:① 对品牌进行桶(Bucket)聚合 ② 对桶聚合的结果进行(Metric)聚合运算
1.3.1 定义 DSL 语法
GET /hotel/_search
{"size": 0,"aggs": {"brandAgg": {"terms": {"field": "brand","size": 10,"order": {"scoreAgg.avg": "desc"}},"aggs": {"scoreAgg": {"stats": {"field": "score"}}}}}
}
1.3.2 参数说明
- size: 设置为0,结果中不需要包含文档,只返回聚合结果
- aggs:定义聚合,固定值
- brandAgg:聚合名称,自定义语义化即可
- terms: 聚合类型,brand 是一个 keyword 类型的字符串,所以用 terms
- field:参与聚合的字段
- size:希望获取的聚合结果数量
- order:指定排序,这里按照 “scoreAgg.avg” 逆序排序
- terms: 聚合类型,brand 是一个 keyword 类型的字符串,所以用 terms
- aggs:对 brandAggs 的子聚合,也就是说多聚合后的结果分别计算,固定值
- scoreAgg:聚合名称,自定义语义化即可
- stats:Metric 聚合计算,这里的 stats 可以计算 min、max、avg、sum的值
- field:聚合字段
- scoreAgg:聚合名称,自定义语义化即可
- brandAgg:聚合名称,自定义语义化即可
1.3.3 测试结果

1.4 聚合示例测试3
需求:对酒店的品牌分组,累加品牌评分,按累计评分逆序排序,筛选出前5名,计算每个品牌评分占总评分的比率
分析:① 对品牌进行桶(Bucket)聚合 ② 对桶聚合的结果进行(Metric)聚合运算 ③ 聚合计算(Pipeline)④ 逻辑运算
1.4.1 定义 DSL 语法
GET /hotel/_search
{"size": 0,"aggs": {"brandAgg": {"terms": {"field": "brand","size": 5,"order": {"singleBrandTotalScore": "desc"}},"aggs": {"singleBrandTotalScore": {"sum": {"field": "score"}}}},"allBrandTotalScore": {"sum_bucket": {"buckets_path": "brandAgg>singleBrandTotalScore"}}}
}
1.4.2 参数说明
- size: 设置为0,结果中不需要包含文档,只返回聚合结果
- aggs:定义聚合,固定值
-
brandAgg:聚合名称,自定义语义化即可
- terms: 聚合类型,brand 是一个 keyword 类型的字符串,所以用 terms
- field:参与聚合的字段
- size:希望获取的聚合结果数量
- order:指定排序,这里按照 “singleBrandTotalScore.value” 逆序排序,sum 聚合运算 value 可省略
- terms: 聚合类型,brand 是一个 keyword 类型的字符串,所以用 terms
-
aggs:对 brandAggs 的子聚合,也就是说多聚合后的结果分别计算,固定值
- singleBrandTotalScore: 多单一品牌的所有评分进行累加
- sum: 对 score 字段求和
- singleBrandTotalScore: 多单一品牌的所有评分进行累加
-
allBrandTotalScore:聚合名称,自定义语义化即可,每个品牌的得分总和再次求和,以获得所有品牌的总得分
- sum_bucket: 管道聚合
- buckets_path:指定了数据来源路径,即来自brandAgg聚合中 singleBrandTotalScore 的结果
- sum_bucket: 管道聚合
-
1.4.3 测试结果

1.4.4 说明:是否可以直接将 allBrandTotalScore 计算值,传入 aggs 中直接参与计算还有待探索,若有好的方法,希望留言反馈,感谢!!!

相关文章:
ElasticSearch 数据聚合与运算
1、数据聚合 聚合(aggregations)可以让我们极其方便的实现数据的统计、分析和运算。实现这些统计功能的比数据库的 SQL 要方便的多,而且查询速度非常快,可以实现近实时搜索效果。 注意: 参加聚合的字段必须是 keywor…...
科研学习|论文解读——智能体最新研究进展
从2024-12-13到2024-12-18的45篇文章中精选出5篇优秀的工作分享 Can Modern LLMs Act as Agent Cores in Radiology~Environments? Achieving Collective Welfare in Multi-Agent Reinforcement Learning via Suggestion Sharing A systematic review of norm emergence in …...

面试小札:Java后端闪电五连鞭_8
1. Kafka消息模型及其组成部分 - 消息(Message):是Kafka中最基本的数据单元。消息包含一个键(key)、一个值(value)和一个时间戳(timestamp)。键可以用于对消息进行分区等…...
保存时间带时分秒,回显时分秒变成00:00:00)
java error(2)保存时间带时分秒,回显时分秒变成00:00:00
超简单,顺带记录一下 1.入参实体类上使用注释:JsonFormat(pattern “yyyy-MM-dd”) 导致舍弃了 时分秒的部分。 2.数据库字段对应的类型是 date。date就是日期,日期就不带时分秒。 3.返参实体类使用了JsonFormat(pattern “yyyy-MM-dd”) 导…...

计算机毕业设计python+spark+hive动漫推荐系统 漫画推荐系统 漫画分析可视化大屏 漫画爬虫 漫画推荐系统 漫画爬虫 知识图谱 大数据毕设
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 作者简介:Java领…...
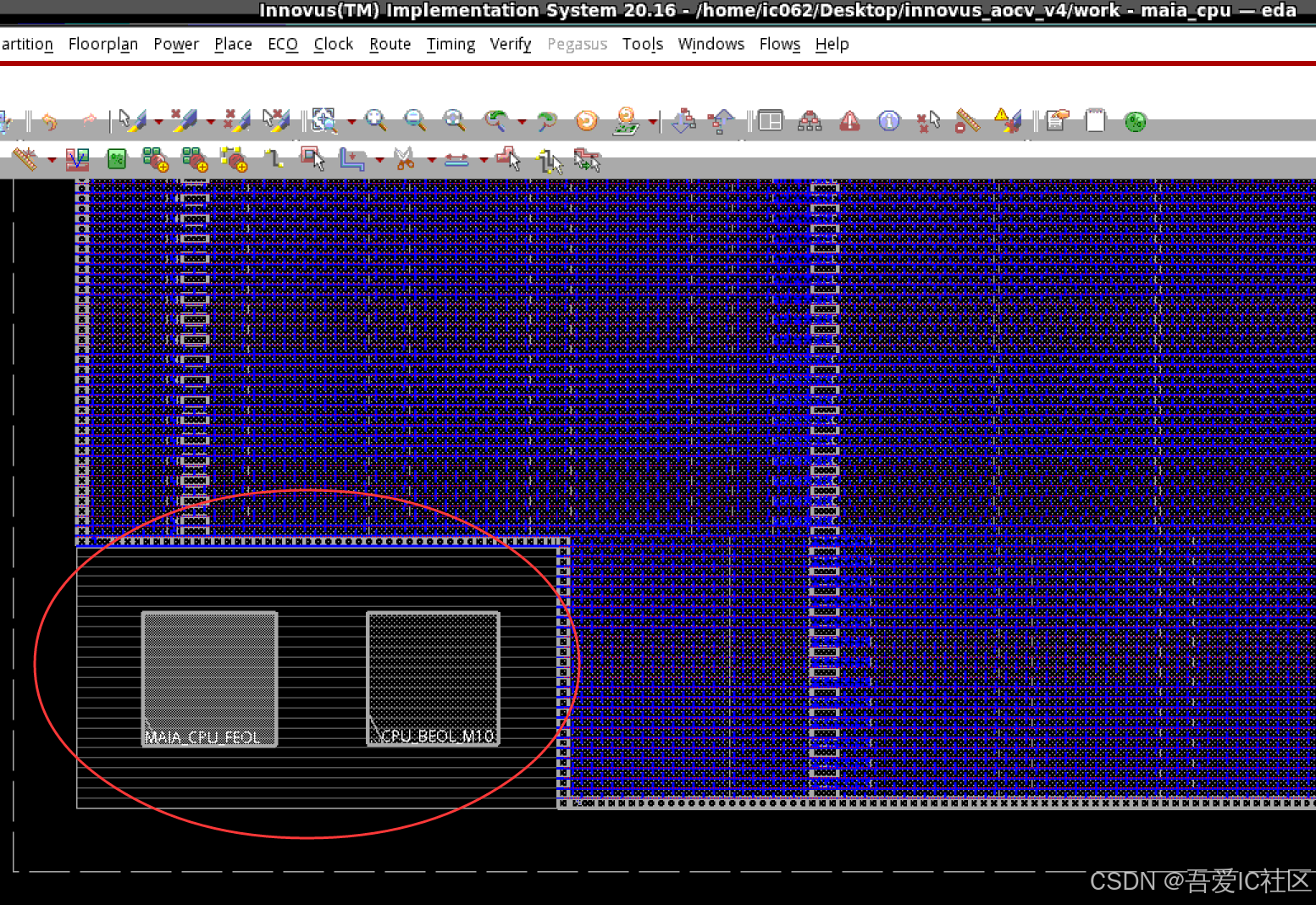
数字IC后端设计实现篇之TSMC 12nm TCD cell(Dummy TCD Cell)应该怎么加?
TSMC 12nm A72项目我们需要按照foundary的要求提前在floorplan阶段加好TCD Cell。这个cell是用来做工艺校准的。这个dummy TCD Cell也可以等后续Calibre 插dummy自动插。但咱们项目要求提前在floorplan阶段就先预先规划好位置。 TSCM12nm 1P9M的metal stack结构图如下图所示。…...
(8)YOLOv6算法基本原理
一、YOLOv6 模型原理 发布日期:2022年6月 作者:美团技术团队 骨干网络:参考了 RepVGG 的设计,将重参数化能力进行补强,增强了模型结构的重参数化能力。使用了深度可分离卷积和跨阶段连接等技术,旨在提升…...
LNMP+discuz论坛
0.准备 文章目录 0.准备1.nginx2.mysql2.1 mysql82.2 mysql5.7 3.php4.测试php访问mysql5.部署 Discuz6.其他 yum源: # 没有wget,用这个 # curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo[rootlocalhost ~]#…...
在linux系统的docker中安装GitLab
一、安装GitLab: 在安装了docker之后就是下载安装GitLab了,在linux系统中输入命令:docker search gitlab就可以看到很多项目,一般安装第一个,它是英文版的,如果英文不好可以安装twang2218/gitlab-ce-zh。 …...

Python面试常见问题及答案12
问题: 请解释Python中的GIL(全局解释器锁)是什么? ○ 答案: GIL是Python解释器中的一种机制,用于确保任何时候只有一个线程在执行Python字节码。这在多线程场景下可能影响性能优化,但对于单线程…...
从0-1开发一个Vue3前端系统页面-9.博客页面布局
本节主要实现了博客首页界面的基本布局并完善了响应式布局,因为完善了响应式布局故对前面的页面布局有所改动,这里会将改动后的源码同步上传。 1.对页面头部的用户信息进行设计和美化 布局设计参考 :通常初级前端的布局会通过多个div划分区域…...

[手机Linux] 六,ubuntu18.04私有网盘(NextCloud)安装
一,LNMP介绍 LNMP一键安装包是一个用Linux Shell编写的可以为CentOS/RHEL/Fedora/Debian/Ubuntu/Raspbian/Deepin/Alibaba/Amazon/Mint/Oracle/Rocky/Alma/Kali/UOS/银河麒麟/openEuler/Anolis OS Linux VPS或独立主机安装LNMP(Nginx/MySQL/PHP)、LNMPA(Nginx/MySQ…...

白话java设计模式
创建模式 单例模式(Singleton Pattern): 就是一次创建多次使用,它的对象不会重复创建,可以全局来共享状态。 工厂模式(Factory Method Pattern): 可以通过接口来进行实例化创建&a…...
助力 Tuanjie OpenHarmony 开发:如何使用工具包 Hilog 和 SDK Kits Package?
随着团结引擎从 1.0.0 迭代至 1.3.0,越来越多的开发者开始使用团结引擎开发 OpenHarmony 应用。 在开发的过程中,我们也收到了大量反馈,尤其是在日志、堆栈和性能数据方面,这些信息对开发和调试过程至关重要。同时,我…...

NSDT 3DConvert:高效实现大模型文件在线预览与转换
NSDT 3DConvert 作为一个 WebGL 展示平台,能够实现多种模型格式免费在线预览,并支持大于1GB的OBJ、STL、GLTF、点云等模型进行在线查看与交互,这在3D模型展示领域是一个相当强大的功能。 平台特点 多格式支持 NSDT 3DConvert兼容多种3D模型…...
电商数据采集电商,行业数据分析,平台数据获取|稳定的API接口数据
电商数据采集可以通过多种方式完成,其中包括人工采集、使用电商平台提供的API接口、以及利用爬虫技术等自动化工具。以下是一些常用的电商数据采集方法: 人工采集:人工采集主要是通过基本的“复制粘贴”的方式在电商平台上进行数据的收集&am…...

VUE+Node.js+mysq实现响应式个人博客|项目初始化+路由配置+基础组件搭建
Day 1 开发文档:项目初始化与基础架构搭建 一、项目初始化 1. 创建项目 首先,我们使用 Vite 创建一个基于 Vue 3 的项目: # 创建项目 npm create vitelatest my-blog -- --template vue # 这条命令会创建一个名为 my-blog 的新项目&#…...
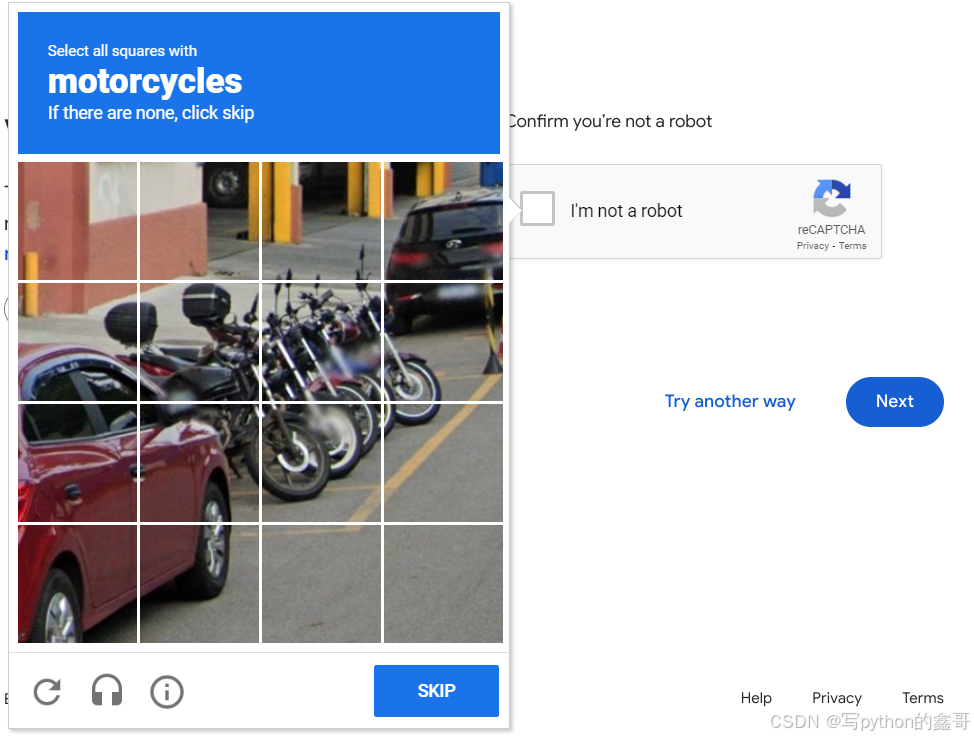
Python如何正确解决reCaptcha验证码(9)
前言 本文是该专栏的第73篇,后面会持续分享python爬虫干货知识,记得关注。 我们在处理某些国内外平台项目的时候,相信很多同学或多或少都见过,如下图所示的reCaptcha验证码。 而本文,笔者将重点来介绍在实战项目中,遇到上述中的“reCaptcha验证码”,如何正确去处理并解…...
web3跨链预言机协议-BandProtocol
项目简介 Band Protocol 项目最初于 2017年成立并建立在 ETH 之上。后于2020年转移到了 Cosmos 网络上,基于 Cosmos SDK 搭建了一条 Band Chain 。这是一条 oracle-specific chain,主要功能是提供跨链预言机服务。Cosmos生态上第一个,也是目…...
JAVA将集合切分成指定份数(简易)
JAVA将集合切分成指定份数 主要方法 /** * 主要方法* param list 切分的集合* param count 切成的份数* return*/ public static List<List> splitList(List list,int count){if(count <0 ){return Lists.newArrayList();}List<List> result Lists.newArrayL…...

Claude API密钥自动化同步工具:架构设计与实战部署指南
1. 项目概述与核心价值最近在折腾一个挺有意思的自动化项目,起因是我发现团队里不同成员在使用Claude API时,经常遇到一个挺烦人的问题:每个人手里的API密钥状态不一致。有的同事的密钥突然失效了,有的配额用完了自己还不知道&…...
)
【实用小程序】超轻量级文件上传下载中心 (File Download Server)
站内源码及jar包下载 一、项目概述 文件下载中心一个基于 Java 内置 HTTP 服务器(com.sun.net.httpserver)构建的轻量级文件管理服务。它零第三方依赖,单 JAR 包即可运行,适合在内网环境或临时场景中快速搭建文件共享站点。 你的团队需要临时共享一批日志文件或交付物,…...
2026最新版免费下载(看到请立即转存 资源随时失效)pc手机通用)
植物大战僵尸 (废物版 杂交版 融合版)2026最新版免费下载(看到请立即转存 资源随时失效)pc手机通用
废物版下载链接 杂交版 融合版 《植物大战僵尸》同人模组生态解析:杂交版、融合版与废物版机制及竞品对比 《植物大战僵尸》(Plants vs. Zombies,简称PVZ)作为塔防游戏史上的经典之作,其官方作品的更新迭代虽然逐渐…...

源代码论文分享|基于Spring Boot的装饰工程管理系统!
做工程管理系统的同学,真的别一开始就硬啃空白项目。 尤其是装饰工程这种题目,看起来只是“管理系统”,但真写起来会发现:客户信息、工程项目、材料、施工进度、人员安排、费用统计……每一块都能展开。如果没有一个完整项目做参…...

ElevenLabs语音克隆合规红线速查手册,2024最新GDPR+CCPA+中国《生成式AI服务管理暂行办法》三重适配指南
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs语音克隆合规性认知总览 语音克隆技术正以前所未有的精度重塑人机交互边界,但其法律与伦理风险亦同步升级。ElevenLabs 作为行业领先者,明确将《服务条款》第5.2条与《…...

国产多模态大模型如何“看懂”三维世界?3D场景理解深度解析
国产多模态大模型如何“看懂”三维世界?3D场景理解深度解析 引言 在人工智能向物理世界进军的浪潮中,让机器理解我们身处的三维空间,已成为核心挑战与前沿阵地。与依赖二维图像的视觉识别不同,3D场景理解要求模型能融合视觉、几何…...

地平线X3M平台sensor点亮故障排查实战指南
1. 地平线X3M平台sensor点亮常见问题概述 第一次接触地平线X3M平台的开发者,在点亮sensor时经常会遇到各种"拦路虎"。我刚开始接触这个平台时,光是调试一个imx415 sensor就花了整整三天时间。现在回想起来,大部分问题其实都有规律可…...

Taotoken用量看板如何帮助团队管理大模型API成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板如何帮助团队管理大模型API成本 作为团队的技术负责人,在引入大模型能力支持多个项目时,一…...

上蔡假发定制亲测:这家2026年稳
在假发定制领域,用户普遍面临三大核心挑战:其一,传统假发产品在逼真度与舒适度之间难以平衡。数据显示,超过65%的消费者反映佩戴假发后出现头皮闷热、出汗不适等问题,尤其在夏季或运动场景下,透气性与防水性…...

完全掌握Adobe软件激活:5个实用技巧深度解析
完全掌握Adobe软件激活:5个实用技巧深度解析 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP 你是否曾经为Adobe Creative Cloud的订阅费用感到困扰&…...