Docker 入门:如何使用 Docker 容器化 AI 项目(二)
四、将 AI 项目容器化:示例实践 - 完整的图像分类与 API 服务
让我们通过一个更完整的 AI 项目示例,展示如何将 AI 项目容器化。我们以一个基于 TensorFlow 的图像分类模型为例,演示如何将训练、推理、以及 API 服务过程容器化。
4.1 创建 AI 项目文件
首先,创建一个 Python 项目目录结构,包含以下文件:
/my-ai-project├── Dockerfile├── requirements.txt├── main.py├── model.py└── app.py
requirements.txt:列出项目的所有 Python 依赖。
tensorflow==2.6.0
numpy==1.19.5
matplotlib==3.4.3
flask==2.0.2
main.py:包含模型训练和保存的逻辑代码。
import tensorflow as tf
from tensorflow.keras.datasets import mnist# 加载数据
(x_train, y_train), (x_test, y_test) = mnist.load_data()# 数据预处理
x_train = x_train / 255.0
x_test = x_test / 255.0# 构建模型
model = tf.keras.Sequential([tf.keras.layers.Flatten(input_shape=(28, 28)),tf.keras.layers.Dense(128, activation='relu'),tf.keras.layers.Dropout(0.2),tf.keras.layers.Dense(10)
])# 编译模型
model.compile(optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy'])# 训练模型
model.fit(x_train, y_train, epochs=5)# 评估模型
model.evaluate(x_test, y_test)# 保存模型
model.save('saved_model/my_model')
model.py: 包含模型加载和推理的逻辑。
import tensorflow as tf
import numpy as npdef load_model():model = tf.keras.models.load_model('saved_model/my_model')return modeldef predict(model, image):img_array = np.expand_dims(image, axis=0)predictions = model.predict(img_array)score = tf.nn.softmax(predictions[0])class_id = np.argmax(score)return class_id
app.py:使用 Flask 构建一个简单的 API 服务,接收图片进行预测。
from flask import Flask, request, jsonify
import numpy as np
import tensorflow as tf
from model import load_model, predict
from PIL import Image
import ioapp = Flask(__name__)
model = load_model()@app.route('/predict', methods=['POST'])
def predict_api():if 'file' not in request.files:return jsonify({'error': 'No file part'}), 400file = request.files['file']if file.filename == '':return jsonify({'error': 'No selected file'}), 400try:img = Image.open(io.BytesIO(file.read())).convert('L').resize((28, 28)) # Convert to grayscale and resizeimg_array = np.array(img) / 255.0result = predict(model, img_array)return jsonify({'prediction': int(result)})except Exception as e:return jsonify({'error': str(e)}), 500if __name__ == '__main__':app.run(host='0.0.0.0', port=5000, debug=True)
4.2 创建 Dockerfile
接下来,创建一个优化的 Dockerfile 来容器化这个项目,示例如下:
# 使用 TensorFlow 官方的 Python 3 镜像作为基础镜像, 选择更轻量级的版本
FROM tensorflow/tensorflow:2.6.0-py3# 设置工作目录
WORKDIR /app# 复制 requirements.txt
COPY requirements.txt /app/# 安装依赖, 使用 --no-cache-dir 减小镜像大小
RUN pip install --no-cache-dir -r requirements.txt# 复制项目文件到容器中
COPY . /app# 暴露 API 服务的端口
EXPOSE 5000# 运行训练脚本并保存模型
RUN python main.py# 启动 API 服务
CMD ["python", "app.py"]
Dockerfile 优化说明:
- 基础镜像选择: 使用
tensorflow/tensorflow:2.6.0-py3比tensorflow/tensorflow:2.6.0更轻量级。如果需要 GPU 支持,可以选择tensorflow/tensorflow:2.6.0-gpu-py3。 .dockerignore: 可以在项目根目录下创建一个.dockerignore文件,排除不必要的文件或目录被复制到镜像中,例如:
.git
__pycache__
saved_model
- 多阶段构建 (可选):如果你的项目需要编译或其他构建步骤,可以使用多阶段构建来减小最终镜像大小。例如,先在一个包含完整构建工具链的镜像中构建应用,然后将构建产物复制到一个更轻量级的运行时镜像中。
4.3 构建并运行 Docker 容器
- 构建镜像:
docker build -t my-ai-tensorflow .
- 启动容器并运行 API 服务:
docker run -it -p 5000:5000 my-ai-tensorflow
-p 5000:5000 将容器的 5000 端口映射到主机的 5000 端口,这样你就可以通过 http://localhost:5000 访问 API 服务了。
4.4 测试 API 服务

你可以使用 curl 或 Postman 等工具来测试 API 服务。例如,使用 curl 发送一个 POST 请求:
curl -X POST -F "file=@<your_image.png>" http://localhost:5000/predict
将 <your_image.png> 替换为你本地的一张 MNIST 手写数字图片。
五、使用 Docker Compose 编排多容器应用 (可选)
如果你的 AI 项目需要多个容器协同工作,例如数据库、Web 服务器、消息队列等,可以使用 Docker Compose 来简化多容器应用的部署和管理。
创建一个 docker-compose.yml 文件,例如:
version: '3.8'
services:web:build: .ports:- "5000:5000"depends_on:- dbdb:image: postgres:13-alpineenvironment:- POSTGRES_PASSWORD=example
这个示例定义了两个服务:web 和 db。web 服务使用当前目录的 Dockerfile 构建镜像,并将容器的 5000 端口映射到主机的 5000 端口。db 服务使用 PostgreSQL 数据库镜像。
使用 docker-compose up 命令启动所有服务:
docker-compose up -d
-d 表示后台运行。
六、Docker 安全性最佳实践 (简要)
- 使用非 root 用户: 默认情况下,容器内的进程以 root 用户身份运行。为了提高安全性,可以在 Dockerfile 中创建一个非 root 用户,并使用
USER指令切换到该用户。 - 限制容器资源: 使用 Docker 的资源限制功能(例如
--memory、--cpus)来限制容器可以使用的资源,防止容器耗尽主机资源。 - 定期更新镜像: 及时更新基础镜像和应用程序依赖,修复已知的安全漏洞。
- 最小化镜像: 只安装必要的软件包,避免安装不必要的组件,减小攻击面。
- 使用安全扫描工具: 使用 Clair、Anchore 等工具扫描镜像中的安全漏洞。
七、总结
在本文中,我们介绍了如何使用 Docker 容器化 AI 项目。通过 Docker,我们能够将 AI 项目的环境和依赖打包成一个容器,从而简化了项目的部署和管理。Docker 不仅提升了开发者的效率,还确保了项目在不同环境中的一致性。
最佳实践:
- 保持镜像简洁:在 Dockerfile 中,尽量选择合适的基础镜像,避免冗余的安装和配置。
- 多阶段构建:对于需要构建和编译的项目,可以使用 Docker 的多阶段构建来减少最终镜像的体积。
- 数据持久化:在生产环境中,确保使用 Docker 的数据卷(Volumes)来持久化数据。
- 优化镜像大小:通过清理不必要的文件,减小镜像的体积,提升部署效率。
附:Docker安装流程图:

流程图说明:
- 开始: 安装流程开始。
- 选择操作系统: 根据你的操作系统选择相应的安装步骤。
- Windows:
- 访问 Docker 官网下载 Docker Desktop for Windows。
- 启用 Hyper-V 或 WSL 2?: 选择使用 Hyper-V 或 WSL 2 作为 Docker 的后端。
- Hyper-V: 启用 Hyper-V。
- WSL 2 (推荐): 启用 WSL 2 (性能更好)。
- 双击安装文件并按照向导安装。
- 启动 Docker Desktop。
- 验证安装:
docker --version。
- macOS:
- 访问 Docker 官网下载 Docker Desktop for macOS。
- 双击 .dmg 文件并将 Docker 拖入应用程序文件夹。
- 启动 Docker。
- 验证安装:
docker --version。
- Linux:
- 选择 Linux 发行版: 选择你使用的 Linux 发行版 (Ubuntu 或 CentOS)。
- Ubuntu:
sudo apt-get updatesudo apt-get install apt-transport-https ca-certificates curl software-properties-commoncurl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"sudo apt-get updatesudo apt-get install docker-ce- 验证安装:
docker --version。
- CentOS:
sudo yum install -y yum-utilssudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.reposudo yum install docker-cesudo systemctl start dockersudo systemctl enable docker(设置开机自启)- 验证安装:
docker --version。
- 安装完成。
关键步骤说明:
- WSL 2 和 Hyper-V (D, E, W) 使用不同的填充色,表示这是 Windows 安装中两个重要的选项,WSL 2 通常是更好的选择。
- Ubuntu 和 CentOS 安装步骤 分别使用蓝色和橙色填充,方便区分不同发行版的安装命令。
这个流程图清晰地展示了在不同操作系统上安装 Docker 的步骤,希望对你有所帮助!
附:AI 项目容器化流程图:
以下是一个更详细的、包含模型训练、API 服务构建以及 Docker Compose 编排的 AI 项目容器化流程图:

流程图说明:
- 开始: 项目开始。
- 准备 AI 项目代码: 准备好包含模型训练、推理和 API 服务 (例如 Flask 或 FastAPI) 的代码。
- 创建 requirements.txt: 列出项目所有 Python 依赖。
- 项目是否需要多容器?: 判断项目是否需要使用 Docker Compose。
- 是: 创建
docker-compose.yml文件,定义各个服务及其依赖关系。 - 否: 继续创建 Dockerfile。
- 是: 创建
- 创建 Dockerfile: 编写 Dockerfile 文件。
- 选择基础镜像 FROM: 根据项目需求选择合适的基础镜像,例如
tensorflow/tensorflow:2.6.0-py3。 - 设置工作目录 WORKDIR /app: 设置容器内的工作目录。
- 复制项目文件 COPY . /app: 将项目代码复制到容器中。
- 安装依赖 RUN pip install -r requirements.txt: 安装
requirements.txt中列出的依赖。 - 项目是否包含训练步骤?:
- 是:
RUN python main.py执行训练脚本并保存模型 (例如到/app/saved_model目录)。 - 否: 跳过训练步骤。
- 是:
- 暴露端口 EXPOSE 5000: 如果有 API 服务,暴露相应的端口。
- 设置启动命令 CMD [“python”, “app.py”]: 设置容器启动时执行的命令,例如启动 API 服务。
- 构建 Docker 镜像 docker build -t my-ai-project .: 构建 Docker 镜像。
- 是否使用 Docker Compose?:
- 是: 使用
docker-compose up -d命令启动所有服务。 - 否: 使用
docker run -it -p 5000:5000 my-ai-project命令运行容器,-p参数进行端口映射。
- 是: 使用
- 访问 API 服务 例如: http://localhost:5000: 通过映射的端口访问 API 服务。
- 测试 API 服务: 使用 curl 或 Postman 等工具测试 API。
- 部署到生产环境: 将构建好的镜像部署到生产环境 (例如 Kubernetes 集群)。
- 结束: 项目部署完成。
关键步骤说明:
- 训练步骤 (J) 使用虚线边框和不同的填充色,表示这是一个可选步骤,取决于项目中是否包含模型训练逻辑。
- 使用 Docker Compose 启动 (O) 和直接运行容器 (Q) 使用不同的填充色,表示这是两种不同的启动方式。
这个流程图更详细地展示了 AI 项目容器化的各个步骤,并考虑了模型训练、API 服务构建和 Docker Compose 编排等情况,希望能更好地帮助你理解整个流程。
点击进入:AI 项目实战:从原理到落地
点击进入:Docker 入门:如何使用 Docker 容器化 AI 项目(一)
本文为原创内容,未经许可不得转载。
相关文章:
Docker 入门:如何使用 Docker 容器化 AI 项目(二)
四、将 AI 项目容器化:示例实践 - 完整的图像分类与 API 服务 让我们通过一个更完整的 AI 项目示例,展示如何将 AI 项目容器化。我们以一个基于 TensorFlow 的图像分类模型为例,演示如何将训练、推理、以及 API 服务过程容器化。 4.1 创建 …...

MVVM、MVC、MVP 的区别
MVVM(Model-View-ViewModel)、MVC(Model-View-Controller)和MVP(Model-View-Presenter)是三种常见的软件架构模式,它们在客户端应用开发中被广泛使用。每种模式都有其特定的设计理念和应用场景&…...

【Verilog】期末复习
数字逻辑电路分为哪两类?它们各自的特点是什么? 组合逻辑电路:任意时刻的输出仅仅取决于该时刻的输入,而与电路原来的状态无关 没有记忆功能,只有从输入到输出的通路,没有从输出到输入的回路 时序逻辑电路&…...

C#都可以找哪些工作?
在国内学习C#,可以找的工作主要是以下4个: 1、游戏开发 需要学习C#编程、Unity引擎操作、游戏设计和3D图形处理等。 2、PC桌面应用开发 需要学习C#编程、WinForm框架/WPF框架、MVVM设计模式和UI/UX设计等。 3、Web开发 需要学习C#编程、ASP.NET框架…...

机器学习Python使用scikit-learn工具包详细介绍
一、简介 Scikit-learn是一个开源的机器学习库,用于Python编程语言。它建立在NumPy、SciPy和matplotlib这些科学计算库之上,提供了简单有效的数据挖掘和数据分析工具。Scikit-learn库包含了许多用于分类、回归、聚类和降维的算法,包括支持向量…...

蓝桥杯真题 - 扫雷 - 题解
题目链接:https://www.lanqiao.cn/problems/549/learning/ 个人评价:难度 1 星(满星:5) 前置知识:无 整体思路 按题意模拟;为了减少不必要的“数组越界”判断,让数组下标从 1 1 1…...

vue3项目结合Echarts实现甘特图(可拖拽、选中等操作)
效果图: 图一:选中操作 图二:上下左右拖拽操作 本案例在echarts示例机场航班甘特图的基础上修改 封装ganttEcharts组件,测试数据 airport-schedule.jsonganttEcharts代码: 直接复制粘贴可测…...

Log4j2 插件的简单使用
代码: TestPlugin.java package com.chenjiacheng.webapp.plugins;import org.apache.logging.log4j.core.LogEvent; import org.apache.logging.log4j.core.config.plugins.Plugin; import org.apache.logging.log4j.core.lookup.StrLookup;/*** Created by chenjiacheng on …...

Linux之RPM和YUM命令
一、RPM命令 1、介绍 RPM(RedHat Package Manager).,RedHat软件包管理工具,类似windows里面的setup,exe是Liux这系列操作系统里而的打包安装工具。 RPMI包的名称格式: Apache-1.3.23-11.i386.rpm “apache’” 软件名称“1.3.23-11” 软件的版本号&am…...

读取硬件板子上的数据
SSCOM工具,先要安装一个插件 这样就可以读到设备数据...

Cesium 实例化潜入潜出
Cesium 实例化潜入潜出 1、WebGL Instance 的原理 狭义的的WebGL 中说使用 Instance, 一般指使用 glDrawArraysInstanced 用于实例化渲染的函数。它允许在一次绘制调用中渲染多个相同的几何体实例,而无需为每个实例发起单独的绘制调用。 Three.js 就是使用这种方…...
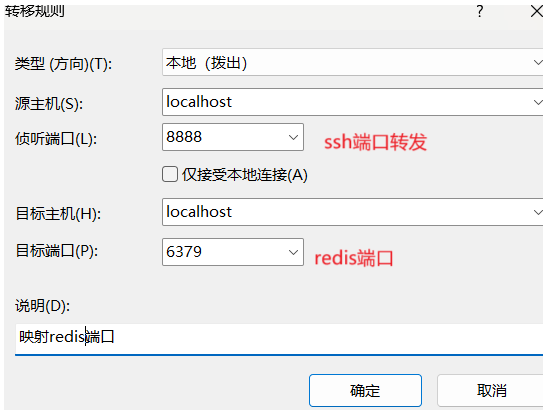
java引入jedis并且关于开放redis端口问题
博主主页: 码农派大星. 数据结构专栏:Java数据结构 数据库专栏:数据库 JavaEE专栏:JavaEE 软件测试专栏:软件测试 关注博主带你了解更多知识 目录 1. 引入jedis 编辑 2. 关于java客户端开放redis端口问题 3. 连接redis服务器 redis服务器在官网公开了使用的协议: resp…...

【人工智能】用Python实现情感分析:从简单词典到深度学习方法的演进
《Python OpenCV从菜鸟到高手》带你进入图像处理与计算机视觉的大门! 解锁Python编程的无限可能:《奇妙的Python》带你漫游代码世界 情感分析是自然语言处理(NLP)中的一个重要任务,其目的是通过分析文本内容,识别出其中的情感极性,如正面、负面或中性。随着技术的不断…...

关系型数据库的完整性和一致性
完整性 1.实体完整性 - 每一个实体都是独一无二的,没有冗余 --主键/唯一索引 2.参照完整性 - 外键 3.域完整性 - 存储的数据都是有效的数据 --数据类型/数据长度/非空约束/检查约束/ 检查约束: alter table tb_score add constraint ck_score_scmar…...

设计模式の命令访问者迭代器模式
文章目录 前言一、命令模式二、访问者模式三、迭代器模式 前言 本篇是关于设计模式中命令模式、访问者模式、以及迭代器模式的学习笔记。 一、命令模式 命令模式是一种行为型设计模式,其核心目的在于将命令的发送者和接受者解耦,提供一个中间层对命令进行…...

信息系统项目管理 -冲突管理
信息系统项目管理题 冲突管理: 项目管理信息系统包括()软件,用于监督资源的使用情况,协助确保合适的资源适时、适地的用于合适活动。 A资源管理或进度计划 BCRM系统 C采购系统或智能分析 DBOM系统 答案:A …...

Gmsh有限元网格剖分(Python)---点、直线、平面的移动
Gmsh有限元网格剖分(Python)—点、直线、平面的移动和旋转 最近在学习有限元的网格剖分算法,主要还是要参考老外的开源Gmsh库进行,写一些博客记录下学习过程,方便以后回忆嘞。 Gmsh的官方英文文档可以参考:gmsh.pdf 但咋就说&a…...

山景BP1048增加AT指令,实现单片机串口控制播放音乐(一)
1、设计目的 山景提供的SDK是蓝牙音箱demo,用户使用ADC按键或者IR遥控器,进行人机交互。然而现实很多场景,需要和单片机通信,不管是ADC按键或者IR接口都不适合和单片机通信。这里设计个AT指令用来和BP1048通信。AT指令如下图所示…...

SMMU软件指南SMMU编程之全局错误和最小配置
安全之安全(security)博客目录导读 目录 一、全局错误 二、最小配置 一、全局错误 与编程接口相关的全局错误会报告到适当的 SMMU_(*_)GERROR 寄存器,而不是通过基于内存的事件队列。这些错误通常是严重的,例如导致 SMMU 停止向前推进。例如…...

CPU条件下Pytorch、jupyter环境配置
一、创建虚拟环境 查看虚拟环境 conda env list 创建python虚拟环境 conda create -n minist python3.11 激活虚拟环境 conda activate minist 查看虚拟环境下有哪些包 pip list 二、安装pytorch 切换清华源 conda config --add channels https://mirrors.tuna.tsing…...

掌握 Skills 技术引爆 Agent 开发!像装 App 一样让 AI 变“超人”!
本文介绍了 AI Skills 的概念,将其描述为可像人类一样动态加载和使用的“能力模块”,用于解决传统 Agent 开发的痛点,如重复造轮子、能力边界模糊和难以规模化。文章详细阐述了 Skills 的核心特征(模块化、可组合、热插拔、标准化…...
:模型量化、蒸馏、微调的核心逻辑(通俗解读))
5. 大模型核心基础概念(三):模型量化、蒸馏、微调的核心逻辑(通俗解读)
001、开篇:为什么大模型需要“瘦身”与“调教”?——量化、蒸馏、微调的必要性 上周在产线调试一个端侧部署的视觉模型,设备跑着跑着就内存溢出了。同事盯着日志问我:“模型在服务器上明明跑得好好的,怎么一到嵌入式板子上就崩了?” 我看了眼那 2GB 的 RAM 和板载的 8GB …...

告别手速焦虑:Python大麦网自动抢票脚本终极指南
告别手速焦虑:Python大麦网自动抢票脚本终极指南 【免费下载链接】Automatic_ticket_purchase 大麦网抢票脚本 项目地址: https://gitcode.com/GitHub_Trending/au/Automatic_ticket_purchase 还在为心仪演出门票秒光而烦恼吗?每次热门演唱会开票…...

别再手动下载了!教你用Python+Schedule库打造个人YouTube视频自动下载工具
Python自动化神器:用Schedule库打造智能视频下载系统 每次手动下载YouTube视频不仅耗时耗力,还容易错过更新。作为Python开发者,我们完全可以用代码解放双手,打造一个全自动的视频下载系统。今天要分享的这套方案,结合…...

seo页面优化公司如何进行网站内容优化
SEO页面优化公司如何进行网站内容优化 在当今数字化时代,网站内容优化已经成为了每个企业在SEO(搜索引擎优化)中的关键步骤。SEO页面优化公司通过一系列策略和技术,帮助企业提高网站在搜索引擎中的排名,从而吸引更多的…...

Win11Debloat:让你的Windows系统重获新生的终极优化指南
Win11Debloat:让你的Windows系统重获新生的终极优化指南 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter and …...

Linux服务器日志爆满?5个实用命令快速定位并清理大日志文件
Linux服务器日志爆满?5个实用命令快速定位并清理大日志文件 当服务器磁盘空间告急时,日志文件往往是罪魁祸首。作为系统管理员,我们需要快速定位问题并安全清理,避免服务中断。本文将分享5个核心命令的组合使用技巧,帮…...

Stable Diffusion 2.0超分实战:4倍放大图片还能保持清晰度的秘密
Stable Diffusion 2.0超分实战:4倍放大图片还能保持清晰度的秘密 在数字图像处理领域,超分辨率技术一直是设计师和开发者关注的焦点。传统放大方法往往导致图像模糊、细节丢失,而基于深度学习的超分方案正在改变这一局面。Stable Diffusion 2…...

30天小白进阶AI大神:收藏这份路线图,免费工具玩转大模型!
本文为AI学习新手提供了30天的系统学习路线图,涵盖了AI技术栈的三个层次:应用层、模型层和基础设施层。文章建议从应用层入手,逐步向下理解,并推荐了主流AI工具的对比及免费工具的入门使用。此外,还提供了给初学者的五…...

ClawdBot代码实例:修改clawdbot.json实现模型热切换实操
ClawdBot代码实例:修改clawdbot.json实现模型热切换实操 1. 引言:你的个人AI助手,想换模型就换模型 想象一下,你有一个24小时在线的AI助手,它能帮你写代码、回答问题、整理文档。但用久了,你可能会想&…...