[python]使用flask-caching缓存数据
简介
Flask-Caching 是 Flask 的一个扩展,为任何 Flask 应用程序添加了对各种后端的缓存支持。它基于 cachelib 运行,并通过统一的 API 支持 werkzeug 的所有原始缓存后端。开发者还可以通过继承 flask_caching.backends.base.BaseCache 类来开发自己的缓存后端。
安装
pip install Flask-Caching
设置
缓存通过缓存实例来管理
from flask import Flask
from flask_caching import Cacheconfig = {"DEBUG": True, # some Flask specific configs"CACHE_TYPE": "SimpleCache", # Flask-Caching related configs"CACHE_DEFAULT_TIMEOUT": 300
}
app = Flask(__name__)
# tell Flask to use the above defined config
app.config.from_mapping(config)
cache = Cache(app)
也可以使用init_app来延后配置缓存实例
cache = Cache(config={'CACHE_TYPE': 'SimpleCache'})app = Flask(__name__)
cache.init_app(app)
还可以提供一个备用的配置字典,如果有多个Cache缓存实例,每个实例使用不同的后端,这将非常有用。
#: Method A: During instantiation of class
cache = Cache(config={'CACHE_TYPE': 'SimpleCache'})
#: Method B: During init_app call
cache.init_app(app, config={'CACHE_TYPE': 'SimpleCache'})
缓存视图函数
使用cached()装饰器缓存视图函数,默认使用path作为缓存的key
@app.route("/")
@cache.cached(timeout=50)
def index():return render_template('index.html')
cached 装饰器还有另一个可选参数叫做 unless。这个参数接受一个可调用对象,它返回 True 或 False。如果 unless 返回 True,那么将完全跳过缓存机制。
为了在视图中动态确定超时时间,可以返回 CachedResponse,这是 flask.Response 的子类。
@app.route("/")
@cache.cached()
def index():return CachedResponse(response=make_response(render_template('index.html')),timeout=50,)
缓存插拔式视图类
from flask.views import Viewclass MyView(View):@cache.cached(timeout=50)def dispatch_request(self):return 'Cached for 50s'
缓存其它函数
使用相同的 @cached 装饰器,还可以缓存其他非视图相关的函数的结果。需要注意替换 key_prefix,否则它将使用 request.path 作为 cache_key。键控制从缓存中获取什么内容。例如,如果一个键在缓存中不存在,将会在缓存中创建一个新的键值对条目。否则,将会返回该键的值(即缓存的结果)。
@cache.cached(timeout=50, key_prefix='all_comments')
def get_all_comments():comments = do_serious_dbio()return [x.author for x in comments]cached_comments = get_all_comments()
自定义缓存键
有时您希望为每个路由定义自己的缓存键。使用 @cached 装饰器,您可以指定如何生成这个键。当缓存键不应仅仅是默认的 key_prefix,而是必须从请求中的其他参数派生时,这可能会非常有用。例如,在缓存 POST 路由时,缓存键应该根据请求中的数据而不仅仅是路由或视图本身来确定,这时就可以使用这个功能。
def make_key():"""A function which is called to derive the key for a computed value.The key in this case is the concat value of all the json requestparameters. Other strategy could to use any hashing function.:returns: unique string for which the value should be cached."""user_data = request.get_json()return ",".join([f"{key}={value}" for key, value in user_data.items()])@app.route("/hello", methods=["POST"])
@cache.cached(timeout=60, make_cache_key=make_key)
def some_func():....
记忆化
在记忆化中,函数参数也会包含在cache_key中
注意:对于不接收参数的函数来说,cached() 和 memoize() 实际上是相同的。
Memoize 也适用于方法,因为它会将 self或 cls 参数的身份作为缓存键的一部分。
记忆化背后的理论是,如果你有一个函数需要在一次请求中多次调用,那么它只会在第一次使用这些参数调用该函数时进行计算。例如,一个 sqlalchemy 对象用来确定一个用户是否具有某个角色。在一次请求中,你可能需要多次调用这个函数。为了避免每次需要这些信息时都访问数据库,你可能会做如下操作:
class Person(db.Model):@cache.memoize(50)def has_membership(self, role_id):return Group.query.filter_by(user=self, role_id=role_id).count() >= 1
将可变对象(类等)作为缓存键的一部分可能会变得棘手。建议不要将对象实例传递给记忆化函数。然而,memoize 会对传入的参数执行 repr(),因此如果对象有一个返回唯一标识字符串的 __repr__ 函数,该字符串将被用作缓存键的一部分。
例如,一个 sqlalchemy 的 person 对象,返回数据库 ID 作为唯一标识符的一部分:
class Person(db.Model):def __repr__(self):return "%s(%s)" % (self.__class__.__name__, self.id)
删除记忆化缓存
您可能需要按函数删除缓存。使用上述示例,假设您更改了用户的权限并将其分配给某个角色,但现在您需要重新计算他们是否拥有某些成员资格。您可以使用 delete_memoized() 函数来实现这一点:
cache.delete_memoized(user_has_membership)
如果仅将函数名称作为参数提供,那么该函数的所有记忆化版本都将失效。然而,您可以通过提供与缓存时相同的参数值来删除特定的缓存。在下面的示例中,只有用户角色的缓存被删除:
user_has_membership('demo', 'admin')
user_has_membership('demo', 'user')cache.delete_memoized(user_has_membership, 'demo', 'user')
如果一个类方法被记忆化,您必须将类作为第一个 *args 参数提供。
class Foobar(object):@classmethod@cache.memoize(5)def big_foo(cls, a, b):return a + b + random.randrange(0, 100000)cache.delete_memoized(Foobar.big_foo, Foobar, 5, 2)
缓存Jinja2模板
基本使用
{% cache [timeout [,[key1, [key2, ...]]]] %}
...
{% endcache %}
默认情况下,“模板文件路径” + “块开始行”的值被用作缓存键。此外,键名也可以手动设置。键会连接成一个字符串,这样可以避免在不同模板中评估相同的块。
将超时设置为 None 以表示没有超时,但可以使用自定义键。
{% cache None, "key" %}
...
{% endcache %}
设置timeout为del来删除缓存值
{% cache 'del', key1 %}
...
{% endcache %}
如果提供了键,您可以轻松生成模板片段的键,并在模板上下文外部删除它。
from flask_caching import make_template_fragment_key
key = make_template_fragment_key("key1", vary_on=["key2", "key3"])
cache.delete(key)
考虑使用render_form_field和render_submit
{% cache 60*5 %}
<div><form>{% render_form_field(form.username) %}{% render_submit() %}</form>
</div>
{% endcache %}
清空缓存
清空应用缓存的简单示例
from flask_caching import Cachefrom yourapp import app, your_cache_configcache = Cache()def main():cache.init_app(app, config=your_cache_config)with app.app_context():cache.clear()if __name__ == '__main__':main()
某些后端实现不支持完全清除缓存。此外,如果您不使用键前缀,一些实现(例如 Redis)会清空整个数据库。请确保您没有在缓存数据库中存储任何其他数据。
显式缓存数据
数据可以通过直接使用代理方法如 Cache.set() 和 Cache.get() 来显式缓存。通过 Cache 类还有许多其他可用的代理方法。
@app.route("/html")
@app.route("/html/<foo>")
def html(foo=None):if foo is not None:cache.set("foo", foo)bar = cache.get("foo")return render_template_string("<html><body>foo cache: {{bar}}</body></html>", bar=bar)
基本使用示例
from flask import Flask
from flask_caching import Cache
import timeflask_cache = Cache(config={'CACHE_TYPE': 'SimpleCache'})app = Flask(__name__)fake_db = {"zhangsan": "qwerty"
}def do_io(username: str):time.sleep(0.01)return fake_db.get(username, "")@app.get("/user/<username>")
def get_user(username):if data := flask_cache.get(username):print(f"getting data from cache, username: {username}")return dataelse:print("data not found in cache")db_data = do_io(username)flask_cache.set(username, db_data, timeout=10)return db_dataif __name__ == "__main__":flask_cache.init_app(app)app.run("127.0.0.1", 8000)
- 测试
wrk -t1 -c10 -d30s http://127.0.0.1:8000/user/zhangsan
SimpleCache在gunicorn中的问题
gunicorn会创建多个子进程,子进程之间是否共享simplecache?
先写一个普通的service,暴露两个api
GET /cache/<key_name>: 根据key name获取缓存值POST /cache: 添加缓存
from flask import Flask, request
from flask_caching import Cache
from typing import Optionalflask_config = {"CACHE_TYPE": "SimpleCache","CACHE_DEFAULT_TIMEOUT": 300
}app = Flask(__name__)
app.config.from_mapping(flask_config)
cache = Cache(app)@app.get("/cache/<foo>")
def get_cached_data(foo: Optional[str]):if not foo:return "foo is None\n"cache_rst = cache.get(foo)if not cache_rst:return f"key {foo} is not in cache\n"return f"find key {foo} in cache, value is {cache_rst}\n"@app.post("/cache")
def set_cached_data():try:req_body = request.get_json()except Exception as e:raise Exception(f"request body is not json format, error: {e}\n") from ekey = req_body.get("key", None)value = req_body.get("value", None)if not key or not value:return "key or value is None\n"if cached_data := cache.get(key):return f"key {key} is already in cache, value is {cached_data}\n"cache.set(key, value)return f"set key {key} in cache, value is {value}\n"if __name__ == "__main__":app.run(host="0.0.0.0", port=5000)
先用flask默认运行方式运行,测试接口是否正常
# 添加键值对缓存
curl -X POST http://127.0.0.1:5000/cache -H 'Content-Type: application/json' -d '{"key": "k1", "value": "v1"}'# 获取缓存
curl http://127.0.0.1:5000/cache/k1
如果响应正常的话,再用gunicorn启动。如下命令将启动4个工作子进程
gunicorn demo:app -b 0.0.0.0:5000 -w 4 -k gevent --worker-connections 2000
请求测试。第一个请求设置缓存,后面四个获取缓存,可见工作进程之间并不共享flask_cache。如果用gunicorn或多个flask service实例,最好换其他cache type,比如RedisCache。
$ curl -X POST http://127.0.0.1:5000/cache -H 'Content-Type: application/json' -d '{"key": "k1", "value": "v1"}'
set key k1 in cache, value is v1$ curl http://127.0.0.1:5000/cache/k1
key k1 is not in cache$ curl http://127.0.0.1:5000/cache/k1
key k1 is not in cache$ curl http://127.0.0.1:5000/cache/k1
find key k1 in cache, value is v1$ curl http://127.0.0.1:5000/cache/k1
key k1 is not in cache关注灵活就业新业态,关注公账号:贤才宝(贤才宝https://www.51xcbw.com)
相关文章:

[python]使用flask-caching缓存数据
简介 Flask-Caching 是 Flask 的一个扩展,为任何 Flask 应用程序添加了对各种后端的缓存支持。它基于 cachelib 运行,并通过统一的 API 支持 werkzeug 的所有原始缓存后端。开发者还可以通过继承 flask_caching.backends.base.BaseCache 类来开发自己的…...

裸机按键输入实验
一、硬件原理分析 按键就两个状态:按下或弹起,将按键连接到一个 IO 上,通过读取这个 IO 的值就知道按 键是按下的还是弹起的。至于按键按下的时候是高电平还是低电平要根据实际电路来判断。前 面几章我们都是讲解 I.MX6U 的 GPIO 作为输出使用…...
)
GaussDB运维管理工具(二)
GaussDB运维管理工具(二) 集群管理组件cm_ctl工具介绍cm_ctl工具使用查询集群状态启停集群主备切换重建备DN检测进程运行查看实例配置文件手动剔除故障CNCM参数获取和配置停止仲裁 Cluster Manager(缩写为CM)是GaussDB的集群管理工…...

【HarmonyOS之旅】HarmonyOS开发基础知识(一)
目录 1 -> 应用基础知识 1.1 -> 用户应用程序 1.2 -> 用户应用程序包结构 1.3 -> Ability 1.4 -> 库文件 1.5 -> 资源文件 1.6 -> 配置文件 1.7 -> pack.info 1.8 -> HAR 2 -> 配置文件简介 2.1 -> 配置文件的组成 3 -> 配置文…...

Mysql数据究竟是如何存储的
Mysql行列式 开篇 笔者这几日在学习mysql是这么运行的这本书,感觉书中的内容受益匪浅,想整理成自己的话分享给大家,平时大家工作和生活中可能没有时间去专心投入读取一本书,而mysql是这么运行的这本书需要投入大量的时间的学…...

STM32单片机使用CAN协议进行通信
CAN总线(控制器局域网总线) 理论知识 CAN总线是由BOSCH公司开发的一种简洁易用、传输速度快、易扩展、可靠性高的串行通信总线 CAN总线特征 两根通信线(CAN_H、CAN_L),线路少,无需共地差分信号通信&…...

Docker 入门:如何使用 Docker 容器化 AI 项目(二)
四、将 AI 项目容器化:示例实践 - 完整的图像分类与 API 服务 让我们通过一个更完整的 AI 项目示例,展示如何将 AI 项目容器化。我们以一个基于 TensorFlow 的图像分类模型为例,演示如何将训练、推理、以及 API 服务过程容器化。 4.1 创建 …...

MVVM、MVC、MVP 的区别
MVVM(Model-View-ViewModel)、MVC(Model-View-Controller)和MVP(Model-View-Presenter)是三种常见的软件架构模式,它们在客户端应用开发中被广泛使用。每种模式都有其特定的设计理念和应用场景&…...

【Verilog】期末复习
数字逻辑电路分为哪两类?它们各自的特点是什么? 组合逻辑电路:任意时刻的输出仅仅取决于该时刻的输入,而与电路原来的状态无关 没有记忆功能,只有从输入到输出的通路,没有从输出到输入的回路 时序逻辑电路&…...

C#都可以找哪些工作?
在国内学习C#,可以找的工作主要是以下4个: 1、游戏开发 需要学习C#编程、Unity引擎操作、游戏设计和3D图形处理等。 2、PC桌面应用开发 需要学习C#编程、WinForm框架/WPF框架、MVVM设计模式和UI/UX设计等。 3、Web开发 需要学习C#编程、ASP.NET框架…...

机器学习Python使用scikit-learn工具包详细介绍
一、简介 Scikit-learn是一个开源的机器学习库,用于Python编程语言。它建立在NumPy、SciPy和matplotlib这些科学计算库之上,提供了简单有效的数据挖掘和数据分析工具。Scikit-learn库包含了许多用于分类、回归、聚类和降维的算法,包括支持向量…...

蓝桥杯真题 - 扫雷 - 题解
题目链接:https://www.lanqiao.cn/problems/549/learning/ 个人评价:难度 1 星(满星:5) 前置知识:无 整体思路 按题意模拟;为了减少不必要的“数组越界”判断,让数组下标从 1 1 1…...

vue3项目结合Echarts实现甘特图(可拖拽、选中等操作)
效果图: 图一:选中操作 图二:上下左右拖拽操作 本案例在echarts示例机场航班甘特图的基础上修改 封装ganttEcharts组件,测试数据 airport-schedule.jsonganttEcharts代码: 直接复制粘贴可测…...

Log4j2 插件的简单使用
代码: TestPlugin.java package com.chenjiacheng.webapp.plugins;import org.apache.logging.log4j.core.LogEvent; import org.apache.logging.log4j.core.config.plugins.Plugin; import org.apache.logging.log4j.core.lookup.StrLookup;/*** Created by chenjiacheng on …...

Linux之RPM和YUM命令
一、RPM命令 1、介绍 RPM(RedHat Package Manager).,RedHat软件包管理工具,类似windows里面的setup,exe是Liux这系列操作系统里而的打包安装工具。 RPMI包的名称格式: Apache-1.3.23-11.i386.rpm “apache’” 软件名称“1.3.23-11” 软件的版本号&am…...

读取硬件板子上的数据
SSCOM工具,先要安装一个插件 这样就可以读到设备数据...

Cesium 实例化潜入潜出
Cesium 实例化潜入潜出 1、WebGL Instance 的原理 狭义的的WebGL 中说使用 Instance, 一般指使用 glDrawArraysInstanced 用于实例化渲染的函数。它允许在一次绘制调用中渲染多个相同的几何体实例,而无需为每个实例发起单独的绘制调用。 Three.js 就是使用这种方…...
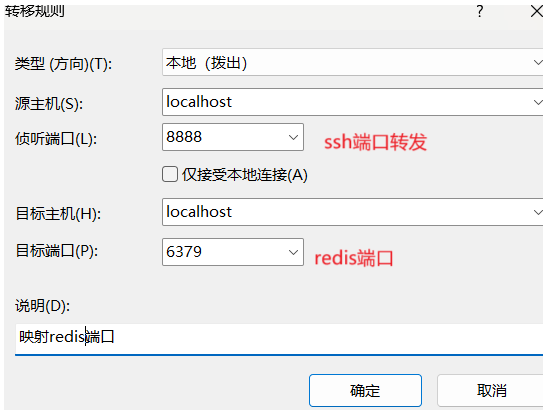
java引入jedis并且关于开放redis端口问题
博主主页: 码农派大星. 数据结构专栏:Java数据结构 数据库专栏:数据库 JavaEE专栏:JavaEE 软件测试专栏:软件测试 关注博主带你了解更多知识 目录 1. 引入jedis 编辑 2. 关于java客户端开放redis端口问题 3. 连接redis服务器 redis服务器在官网公开了使用的协议: resp…...

【人工智能】用Python实现情感分析:从简单词典到深度学习方法的演进
《Python OpenCV从菜鸟到高手》带你进入图像处理与计算机视觉的大门! 解锁Python编程的无限可能:《奇妙的Python》带你漫游代码世界 情感分析是自然语言处理(NLP)中的一个重要任务,其目的是通过分析文本内容,识别出其中的情感极性,如正面、负面或中性。随着技术的不断…...

关系型数据库的完整性和一致性
完整性 1.实体完整性 - 每一个实体都是独一无二的,没有冗余 --主键/唯一索引 2.参照完整性 - 外键 3.域完整性 - 存储的数据都是有效的数据 --数据类型/数据长度/非空约束/检查约束/ 检查约束: alter table tb_score add constraint ck_score_scmar…...
)
告别setData!用mobx-miniprogram+miniprogram-computed重构你的小程序状态管理(保姆级避坑指南)
重构小程序状态管理:mobx-miniprogram与miniprogram-computed实战指南 如果你正在开发一个功能逐渐复杂的中大型微信小程序,大概率已经遇到了这样的困境:页面间状态共享越来越混乱,setData调用遍布各个角落,视图更新性…...

Chandra AI企业知识管理方案:文档智能检索与摘要生成
Chandra AI企业知识管理方案:文档智能检索与摘要生成 1. 引言 企业每天都在产生海量文档——合同、报告、PPT、技术文档...这些宝贵的知识资产往往散落在各处,查找困难,利用率低。传统的关键词搜索就像在黑暗中摸索,找到的文档可…...

如何通过Nucleus Co-Op实现创新无缝的本地多人游戏体验
如何通过Nucleus Co-Op实现创新无缝的本地多人游戏体验 【免费下载链接】nucleuscoop Starts multiple instances of a game for split-screen multiplayer gaming! 项目地址: https://gitcode.com/gh_mirrors/nu/nucleuscoop 你是否曾经希望在同一台电脑上与朋友共同体…...

QMC解码器终极指南:3步实现加密音乐格式转换的高效解决方案
QMC解码器终极指南:3步实现加密音乐格式转换的高效解决方案 【免费下载链接】qmc-decoder Fastest & best convert qmc 2 mp3 | flac tools 项目地址: https://gitcode.com/gh_mirrors/qm/qmc-decoder QQ音乐下载的加密音频文件格式限制跨平台播放&#…...

ICLR 2026 | 告别Top-K检索!RF-Mem在嵌入空间逐步重构证据链,实现长记忆渐进式唤醒
今天分享一篇来自大连理工大学、香港城市大学、华为和中国科学技术大学的最新工作 RF-Mem,发表于ICLR 2026。这篇工作关注个性化大模型中的一个关键问题:当用户历史越来越长时,模型到底该怎样从海量记忆里,准确找回“此时此刻最相…...

SM4算法在嵌入式平台的轻量化移植与优化实践
1. SM4算法与嵌入式平台适配挑战 SM4作为我国自主设计的商用分组密码标准,在物联网设备安全领域应用广泛。但直接将OpenSSL中的SM4实现移植到STM32等嵌入式平台时,开发者常会遇到三大难题: 代码体积膨胀:OpenSSL的SM4实现依赖大量…...

基于鲸鱼优化算法改进XGBoost在MATLAB中的时间序列预测性能(迭代次数、最大深度和学习...
基于鲸鱼优化算法优化XGBoost(WOA-XGBoost)的时间序列预测 WOA-XGBoost时间序列 采用交叉验证抑制过拟合问题 优化参数为迭代次数、最大深度和学习率 matlab代码,注:暂无Matlab版本要求 -- 推荐 2016B 版本及以上 注:采用 XGBoost 工具箱&…...

Windows环境下coturn服务器部署与配置实战
1. Windows下coturn服务器部署全攻略 最近在做一个WebRTC项目时,发现很多开发者卡在了TURN服务器搭建这个环节。特别是需要在Windows环境下部署coturn的场景,网上的资料要么太零散,要么直接照搬Linux的教程。今天我就把自己在Windows 10上通过…...

使用MATLAB进行DeOldify结果的后处理与定量分析
使用MATLAB进行DeOldify结果的后处理与定量分析 如果你是一位习惯在MATLAB环境中工作的研究人员或工程师,当你想对DeOldify这类AI图像上色工具的输出结果进行更深入的评估时,可能会觉得缺少趁手的分析工具。直接看效果图固然直观,但如何量化…...

工业以太网双雄:从协议原理到选型落地,EtherCAT与PROFINET实战解析
1. 工业以太网的双雄之争:为什么选型这么难? 第一次接触工业以太网协议选型时,我盯着EtherCAT和PROFINET的参数表发呆了整整一上午。就像面对两个各有所长的武林高手,一个轻功了得,一个内力深厚,实在难以抉…...