R机器学习:决策树算法的理解与实操
今天继续给大家介绍决策树算法,决策树本身是一种非常简单直观的机器学习算法,用于做分类或回归任务。它就像我们平常做决定时的过程,通过逐步排除可能的选项,最终得出结论。
A decision tree is a flowchart-like structure used to make decisions or predictions. It consists of nodes representing decisions or tests on attributes, branches representing the outcome of these decisions, and leaf nodes representing final outcomes or predictions.
一个典型的决策树的决策过程如下图:

从上图可以看到一个树的结构包括:
- 根节点(Root Node): 代表决策过程要问的第一个问题。
- 内部节点(Internal Nodes): 代表依据特征决策的后续过程,每一个节点根据结果有不同的分支。
- 分支(Branches): 代表决策的结果,通常会指向下一个节点。
- 叶节点(Leaf Nodes): 代表最终决策结果,叶节点不会出现分支。
可以看出来决策树至少有两个优点:一是直观易懂: 决策树的结构就像一棵树,每个节点代表一个属性测试,每条边代表一个测试结果,叶子节点代表最终的分类结果。这种结构非常符合人类的思维方式,让我们很容易理解模型是如何做出决策的。二是可解释性强: 通过观察决策树,我们可以清晰地看到哪些特征对分类结果影响最大,从而帮助我们更好地理解数据。
理解决策树
决策树有一连串的节点,所有的特征属性其实都可以用来划分支,这个时候至少有两个问题需要弄明白:选择哪些特征作为节点?如何对相应特征进行划分?
选择哪个特征作为节点的时候有一个原则就是先用对模型贡献最大的特征来划分节点,贡献的评估标准有很多:
第一个熵值Entropy:这个熵值是度量数据的不纯度的amount of uncertainty or impurity,我们记住熵值越大数据越不纯就好。那么按照熵值的标准我们希望通过节点后形成的分支数据越纯越好,对应的就是熵值越小越好。
第二个信息增益Information Gain:这个是数据划分前的熵值和通过节点划分后的平均熵值的差,刚刚说了熵值越小越好,那么这个差值应该是越大越好,也就是信息增益越大越好。
it is calculated by computing the total difference between the entropy before split and average entropy after the split of dataset based on the given attribute values.
第三个的基尼纯度Gini Impurity:
Gini Index is a metric to measure how often a randomly chosen element would be incorrectly identified.
可以用以上三个标准决定使用哪个特征以及特征使用的先后顺序,具体标准总结如图:

不同的模型贡献评估标准又形成了不同的算法比如,ID3算法就是用信息增益作为贡献标准: 选择信息增益最大的属性作为划分属性。C4.5算法用信息增益率,CART算法用基尼指数: CART算法采用基尼指数作为划分属性的选择标准。
那么决策树的整个划分过程又是怎么样的呢?
我们依然来看个例子:想象一下,我们想根据天气情况决定是否去打篮球。 我们可以用决策树来表示这个决策过程,步骤如下:
第一步收集数据,首先,我们收集了一些历史天气数据以及是否打篮球的,包括:

第二步选择根节点,假设我们是用ID3算法:
- 信息增益最大化原则(ID3算法): 我们选择能提供最多信息、最能区分不同决策的属性作为根节点。
- 在这个例子中, 我们计算每个属性(天气、温度、风力、是否下雨)的信息增益,假设计算结果是“是否下雨”的信息增益最大。
- 所以, 我们将“是否下雨”作为根节点。
第三步划分数据集
- 根据根节点的取值, 将数据集分成两个子集:下雨和不下雨。
第四步继续划分子集
- 对于每个子集, 我们再次计算每个属性的信息增益,选择信息增益最大的属性作为划分属性。
- 假设对于“不下雨”这个子集, “温度”的信息增益最大。
- 那么, 我们将“不下雨”这个子集根据“温度”划分成“温度高”和“温度不高”两个子集。
- 对于“下雨”这个子集, 由于样本太少或其他原因,我们可能直接将其作为叶子节点,即“不下篮球”。
就这么一个思考过程决策树就出来了,决策树也就相应出来了:

所以一个常规的树的生成总结起来就是下面四步
- 计算每个属性的信息增益、信息增益率或基尼指数。
- 选择增益最大的属性作为划分属性。
- 根据该属性的不同取值,将数据集划分成若干个子集。
- 对每个子集递归地重复上述过程,直到满足停止条件。
决策树的剪枝
大家也可以想想按照上面决策树的生成流程我一直划分一直划分下去,总是可以非常精确的,这就会产生过拟合问题,为了防止过拟合,通常需要对决策树进行剪枝。剪枝的方法主要分为预剪枝和后剪枝。
- 预剪枝: 在树生成过程中提前停止分支生长。比如我们可以设置最大深度、设置节点包含的最小样本数、设置信息增益阈值。
- 后剪枝: 先生成一棵完整的树,然后自底向上地剪掉一些分支。比如错误率降低剪枝 (Reduced-Error Pruning, REP) *代价复杂度剪枝 (Cost-Complexity Pruning, CCP)都属于后剪枝。
决策树实操
我们依然用iris数据集进行演示,上篇讲朴素贝叶斯的文章也是用的这个数据集,大家可以对比着看下结果。以Species作为因变量,其余变量作为自变量构建决策树代码如下:
tree_model<- ctree(Species ~ ., iris_train)
plot(tree_model)运行代码得到决策树如图:

训练好的模型在验证集中的表现如下:

针对连续特征的回归树
刚刚讲的决策树都是针对分类结局的,决策树也可以用于连续结局,叫做回归树。
比如我现在有数据集,结局是年薪(连续变量),两个预测变量,一个是工作年限,一个是工作经验HmRun,通过数据可以形成一个如下图所示的决策树:

那么对于一个工作年限为8年,工作经验为10的个体来说,模型预测其年薪结果就为577.6

上面过程也有两个问题,一个是特征分割的条件标准,另一个问题是叶节点的值是如何来的。
选择最佳划分特征和划分点: 对于每个特征,遍历所有可能的划分点,计算划分后的子节点的均方误差(或其他指标),选择使均方误差最小的特征和划分点作为特征以及对应特征的划分点,回归树的叶节点输出的是该节点包含的所有训练样本目标值的平均值或中位数。
When the dependent variable is continuous, its value can be predicted using regression trees. These predict using the average values of ȳ within each subset
看一个回归树的例子,我现在有数据如下:

我想用数据集中的特征来预测medv: 房价中位数,做一个回归树,代码如下:
fit <- rpart(medv ~ ., data = Boston, method = "anova")
rpart.plot(fit, type = 4, extra = 101)运行代码后输出结果如下:

这个是没有剪枝前的模型,我们看下模型的效果:
predictions <- predict(fit, newdata = Boston)
mse <- mean((predictions - Boston$medv)^2)
print(mse)运行后可以得到模型的mse是16.24467,我们对模型进行剪枝过后再看变成下图:

相应的模型的mse也变成了10.3362。说明剪枝确实提高了拟合效果。
通过上面的叙述相信大家对剪枝带来的直观效果有印象了,继续带大家捋捋这个剪枝到底怎么减的。
Pruning剪枝实操
如果回归决策树的分支过多,容易造成过拟合。剪枝主要分为两种方法:预剪枝和后剪枝。
1. 预剪枝(Pre-Pruning):
预剪枝是在树的构建过程中进行的。它通过提前停止树的生长来达到剪枝的目的。具体方法包括:
- 限制树的深度(max_depth): 设置树的最大深度,当树达到指定深度时就停止生长。例如,设置max_depth=3意味着树最多有3层。
- 限制节点包含的最小样本数(min_samples_split): 规定一个节点如果要分裂,至少需要包含多少个样本。如果一个节点包含的样本数少于这个阈值,则该节点不再分裂。
- 限制叶节点包含的最小样本数(min_samples_leaf): 规定一个叶节点至少需要包含多少个样本。如果一个节点分裂后,某个子节点包含的样本数少于这个阈值,则该分裂不进行。
- 限制叶节点的最小权重总和(min_weight_fraction_leaf): 与min_samples_leaf类似,但使用样本权重的总和而不是样本数。
- 设定分裂的阈值(如信息增益、基尼指数的阈值): 当分裂带来的增益小于设定的阈值时,停止分裂。
举例说明预剪枝:假设我们设置min_samples_split=10。这意味着只有当一个节点包含至少10个样本时,它才会被考虑分裂。如果一个节点只包含8个样本,即使它可以被分裂成更“纯”的子节点,也不会进行分裂,从而避免了树的过度生长。
2. 后剪枝(Post-Pruning):
后剪枝是先让树完整地生长,然后再自底向上地对树进行修剪。它通过删除一些子树或将子树替换为叶节点来简化树的结构。常用的后剪枝方法包括:
- 降低错误剪枝(Reduced Error Pruning): 将数据集分成训练集和验证集。首先使用训练集构建完整的树,然后从底向上遍历每个非叶节点,尝试将其子树替换为叶节点。如果替换后在验证集上的错误率降低或保持不变,则进行替换;否则,不进行替换。
- 代价复杂度剪枝(Cost-Complexity Pruning): 为树的每个非叶节点定义一个代价复杂度因子(α),它衡量了剪枝带来的误差减少量与剪掉的叶节点数量之间的权衡。通过调整α的值,可以得到一系列不同复杂度的树。然后使用交叉验证等方法选择最佳的α值,并根据该值对树进行剪枝。
举例说明后剪枝:假设我们构建了一棵完整的树,其中一个非叶节点A有两个子节点B和C。我们尝试将节点A的子树(包括B和C)替换为一个叶节点,该叶节点的值为B和C包含的所有样本目标值的平均值。如果替换后在验证集上的均方误差降低了,则进行替换;否则,保留原来的子树。
故决策树剪枝的主要思想是防止模型在训练集中出现过拟合现象,使模型在测试集中的表现更好。预剪枝的逻辑我们其实很清楚了,现在我们以代价复杂度剪枝为例子看看后剪枝到底是如何操作的:
首先我们得有一个代价函数,如下图:

代价函数通常由两部分组成: 误差项SSR: 反映模型在训练集上的预测误差。 复杂度项: 反映决策树的复杂度,通常用叶子节点的数量来表示。通过调整这两项的权重,α是调节参数,可以控制模型的拟合程度和复杂度。
剪枝过程:
- 从底向上遍历决策树的内部节点。
- 对于每个内部节点,计算剪枝前后的代价。
- 如果剪枝后代价降低,则进行剪枝,将该节点及其子树替换为一个叶子节点。
- 叶子节点的类别通常由该子树中样本最多的类别决定。
通常我们会使用交叉验证法求解最佳α取值,α约小决策树越长。不同的α取值将影响我们选择哪种亚决策树的决策。
交叉验证剪枝实操
我们依然是用鸢尾花数据集进行展示如何用交叉验证得到最优cp(代价复杂度因子(α))值从而完成剪枝提高模型的准确度。
下面的代码做了决策树模型,绘制cp值与交叉验证误差的关系图。并展示了剪枝前的模型:
fit <- rpart(Species ~ ., data = iris)
plotcp(fit)
rpart.plot(fit, type = 4, extra = 101)代码运行结果如下:


接下来进行剪枝,并输出剪枝后的模型评估结果:
# 使用1-SE规则选择cp值
bestcp <- fit$cptable[which.min(fit$cptable[,"xerror"] + fit$cptable[,"xstd"]), "CP"]
# 剪枝
fit.pruned <- prune(fit, cp = bestcp)
predicted.classes <- fit.pruned %>% predict(iris,type = "class")
tab_tree <- table(predicted.classes, iris$Species)
caret::confusionMatrix(tab_tree) 运行代码输出结果如下:

可以看到模型整体的正确性变成了96,这可确实比前面的算法提升了嘞,之前可是只有93哦。
相关文章:
R机器学习:决策树算法的理解与实操
今天继续给大家介绍决策树算法,决策树本身是一种非常简单直观的机器学习算法,用于做分类或回归任务。它就像我们平常做决定时的过程,通过逐步排除可能的选项,最终得出结论。 A decision tree is a flowchart-like structure used …...

解锁高效学习之道:从认知升级到实践突破
目录 学习之困:探寻低效的根源 (一)迷茫之境:目标缺失的困扰 (二)表象之迷:浅尝辄止的学习 (三)行动之阻:执行力的短板 认知重塑:明晰学习的本…...

2024年12月CCF-GESP编程能力等级认证Python编程三级真题解析
本文收录于专栏《Python等级认证CCF-GESP真题解析》,专栏总目录:点这里,订阅后可阅读专栏内所有文章。 一、单选题(每题 2 分,共 30 分) 第 1 题 2024年10月8日,诺贝尔物理学奖“意外地”颁给了两位计算机科学家约翰霍普菲尔德(John J. Hopfield)和杰弗里辛顿(Geof…...

.NET Core 中使用 C# 获取Windows 和 Linux 环境兼容路径合并
在 .NET Core 中使用 C# 处理路径合并并确保在 Windows 和 Linux 环境中都能正常工作,可以使用 System.IO.Path 和 System.IO.Path.Combine 方法。它们是跨平台的,能够根据操作系统自动处理路径分隔符。可以通过 System.Runtime.InteropServices.Runtime…...
【SH】Ubuntu Server 24服务器搭建MySQL数据库研发笔记
文章目录 搭建服务器在线安装1. 更新软件包列表2. 安装MySQL3. 检查MySQL状态4. 修改密码5. 新增用户6. 设置局域网访问 离线安装下载安装包 常用命令参考文档在线安装日志 搭建服务器 作者羊大侠搭建的是 Ubuntu Server 24.04 LTS 服务器环境 搭建参考文档:【SH】…...
编译原理复习---正则表达式+有穷自动机
适用于电子科技大学编译原理期末考试复习。 1. 正则表达式 正则表达式(Regular Expression,简称regex或regexp)是一种用于描述、匹配和操作文本模式的强大工具。它由一系列字符和特殊符号组成,这些字符和符号定义了一种搜索模式…...
知识图谱+RAG学习
GraphRAG(Graph-based Retrieval-Augmented Generation)是微软在2024年推出的一项开源技术,旨在通过结合知识图谱和检索增强生成(RAG)方法,为大型语言模型(LLM)的数据处理提供全新解…...
消息队列技术的发展历史
消息队列技术的演进历程宛如一幅波澜壮阔的科技画卷,历经多个标志性阶段,各阶段紧密贴合不同的技术需求与市场风向,下面为您详细道来。 第一阶段:消息中间件的起源(1970 年代末期 - 1980 年代中期) 在计算…...
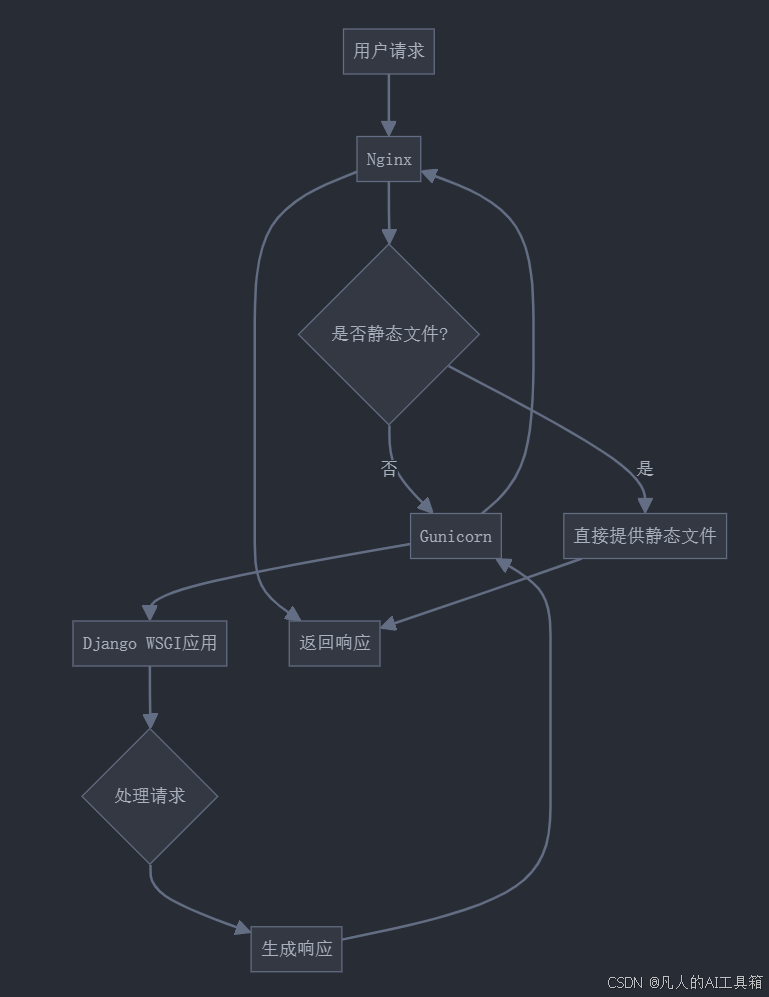
每天40分玩转Django:Django部署
Django部署 一、今日学习内容概述 学习模块重要程度主要内容生产环境配置⭐⭐⭐⭐⭐settings配置、环境变量WSGI服务器⭐⭐⭐⭐⭐Gunicorn配置、性能优化Nginx配置⭐⭐⭐⭐反向代理、静态文件安全设置⭐⭐⭐⭐⭐SSL证书、安全选项 二、生产环境配置 2.1 项目结构调整 mypr…...
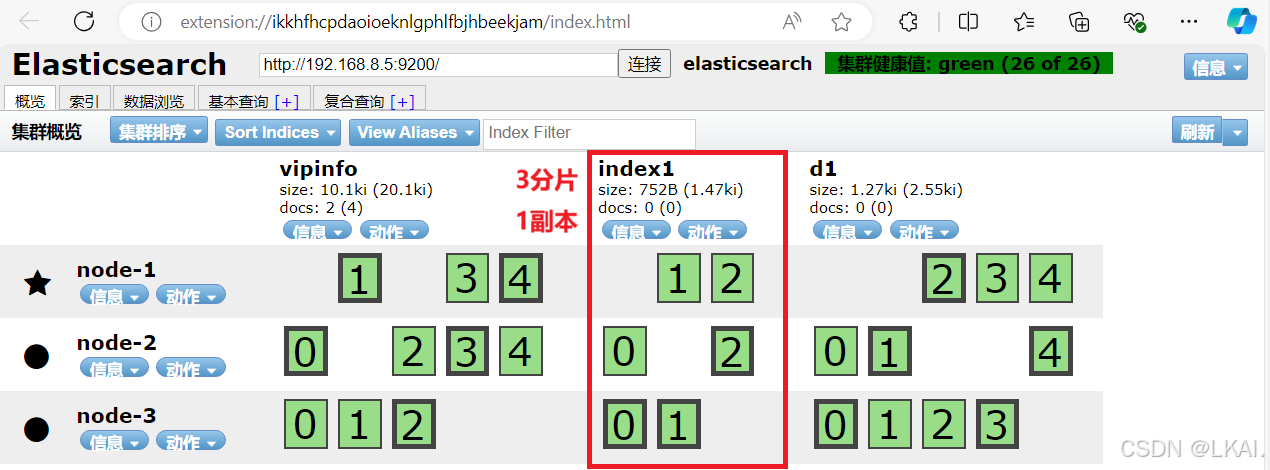
搭建Elastic search群集
一、实验环境 二、实验步骤 Elasticsearch 是一个分布式、高扩展、高实时的搜索与数据分析引擎Elasticsearch目录文件: /etc/elasticsearch/elasticsearch.yml#配置文件 /etc/elasticsearch/jvm.options#java虚拟机 /etc/init.d/elasticsearch#服务启动脚本 /e…...
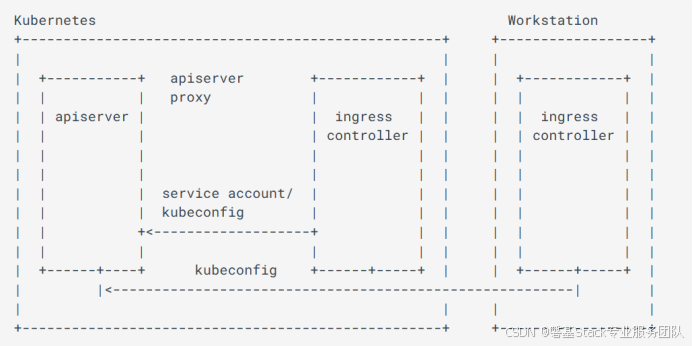
解析 Ingress-Nginx 故障:排查思路与方法
文章目录 一、什么是Ingress-Nginx二、故障排除1.1Ingress-Controller日志和事件检查 Ingress 资源事件检查 Nginx 配置检查使用的服务是否存在调试日志 1.2对 Kubernetes API 服务器的认证服务认证服务账户Kube-Config 1.3使用GDB和Nginx1.4在 Nginx 4.2.5 或其他版本…...

2024 楚慧杯 re wp
go_bytes 附件拖入ida 输入长度为0x28,每两位字符的4bit拼接 与一个常量值经过运算后的值进行异或,并且判断是否相等 脚本 bouquet 附件拖入ida。简单去一下花 构建了一个二叉树,然后递归调用函数 重新排列一下再层序遍历读出即可 zistel 附件…...

【物联网技术与应用】实验10:蜂鸣器实验
实验10 蜂鸣器实验 【实验介绍】 蜂鸣器是音频信号装置。蜂鸣器可分为有源蜂鸣器和无源蜂鸣器。 【实验组件】 ● Arduino Uno主板* 1 ● USB数据线* 1 ● 有源蜂鸣器* 1 ● 无源蜂鸣器* 1 ● 面包板* 1 ● 9V方型电池* 1 ● 跳线若干 【实验原理】 如图所示&#x…...
)
单片机:实现矩阵键盘控制LCD屏幕(附带源码)
单片机实现矩阵键盘控制LCD屏幕 矩阵键盘(Matrix Keypad)是一种常用的输入设备,广泛应用于嵌入式系统中。在许多嵌入式应用中,我们常常需要通过按键输入来控制系统的功能。结合LCD显示屏,我们可以实现一个简单的界面&…...

鸿蒙Next之包体积极限优化
鸿蒙应用包大小优化全解析 在鸿蒙应用开发中,减小应用包大小对于提升应用下载和安装体验起着关键作用。通过压缩、精简或复用应用中的代码与资源,能有效降低包体积,减少空间占用并加快下载与安装速度。下面详细介绍一下鸿蒙应用包大小优化的…...
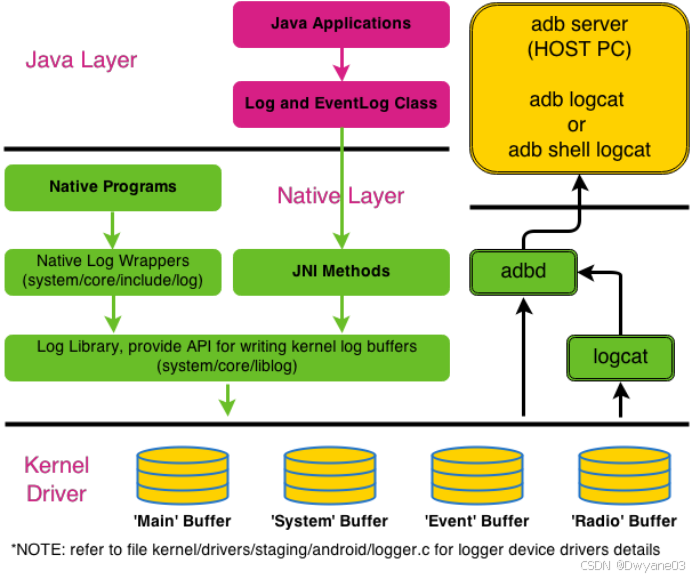
Android实战经验篇-log工具
详细代码实现及系列文章请转如下链接 Android实战经验篇-系列文章汇总 Android Display Graphics系列文章-汇总 一、基础知识 1.1 Logging简述 我们写的第一个计算机C程序一般是printf(“Hello world!”);这就是一个log输出。Linux内核有Kernel log以及配套的Log工具&#x…...

DPU编程技术解析与实践应用
一、引言 1.1 研究背景与目的 随着信息技术的飞速发展,数据中心在现代社会中的地位日益凸显,成为支撑各行业数字化转型的关键基础设施。在数据中心内部,数据的处理速度、效率和安全性成为了影响整体性能的核心要素。为了应对不断增长的数据…...
红帽认证的含金量和价值如何?怎么报名红帽认证考试?
红帽企业 Linux(RHEL)是由红帽公司提供的一款商业支持、专为生产环境设计的Linux发行版。随着IT系统和工作负载日益复杂化,底层基础设施及操作系统必须兼具可靠性、可扩展性,并能有效促进性能提升。红帽认证在全球范围享有盛誉&am…...

VS Code Copilot 与 Cursor 对比
选手简介 VS Code Copilot:算是“老牌”编程助手了,虽然Copilot在别的编辑器上也有扩展,不过体验最好的还是VS Code,毕竟都是微软家的所以功能集成更好一些;主要提供的是Complete和Chat能力,也就是代码补全…...

蓝桥杯嵌入式备赛教程(1、led,2、lcd,3、key)
一、工程模版创建流程 第一步 创建新项目 第二步 选择型号和管脚封装 第三步 RCC使能 外部时钟,高速外部时钟 第四步晶振时钟配置 由数据手册7.1可知外部晶振频率为24MHz 最后一项设置为80 按下回车他会自动配置时钟 第五步,如果不勾选可能程序只会…...

微生物组数据分析难题如何解决?curatedMetagenomicData实战指南深度解析
微生物组数据分析难题如何解决?curatedMetagenomicData实战指南深度解析 【免费下载链接】curatedMetagenomicData Curated Metagenomic Data of the Human Microbiome 项目地址: https://gitcode.com/gh_mirrors/cu/curatedMetagenomicData 在人类微生物组研…...

树莓派4推出3GB内存版,我却不再推荐它了
2026年4月1日,树莓派官方发布了一款新品——树莓派4 3GB内存版,定价83.75美元。这条消息刚出来时,我还以为是愚人节玩笑,毕竟日期太巧了。结果不是玩笑,而是真实产品,而且伴随而来的是又一轮内存驱动的涨价…...

3步解密Navicat密码:技术原理与实战应用完整指南
3步解密Navicat密码:技术原理与实战应用完整指南 【免费下载链接】navicat_password_decrypt 忘记navicat密码时,此工具可以帮您查看密码 项目地址: https://gitcode.com/gh_mirrors/na/navicat_password_decrypt 作为数据库开发者和管理员,你是否…...

QKeyMapper:你的Windows按键魔法师,无需重启即可重塑输入体验
QKeyMapper:你的Windows按键魔法师,无需重启即可重塑输入体验 【免费下载链接】QKeyMapper [按键映射工具] QKeyMapper,Qt开发Win10&Win11可用,不修改注册表、不需重新启动系统,可立即生效和停止。支持游戏手柄映射…...

Daz to Blender终极转换指南:7个专业技巧解决95%的转换难题
Daz to Blender终极转换指南:7个专业技巧解决95%的转换难题 【免费下载链接】DazToBlender Daz to Blender Bridge 项目地址: https://gitcode.com/gh_mirrors/da/DazToBlender Daz to Blender桥接插件是连接Daz Studio和Blender这两个顶尖3D创作工具的关键桥…...

Face3D.ai Pro实战手册:基于ModelScope cv_resnet50_face-reconstruction管道调用
Face3D.ai Pro实战手册:基于ModelScope cv_resnet50_face-reconstruction管道调用 1. 项目概述与核心价值 Face3D.ai Pro 是一个将前沿AI视觉算法与现代化工业UI设计相结合的Web应用。这个系统最大的亮点在于,它能从你上传的一张普通2D照片中ÿ…...

影视工业革命:SDXL 1.0在分镜设计中的应用
影视工业革命:SDXL 1.0在分镜设计中的应用 如果你在影视行业待过,或者哪怕只是参与过一个小视频的制作,你肯定知道前期筹备有多磨人。导演脑子里有画面,编剧笔下有故事,但怎么让整个剧组都“看见”同一个画面…...

Qwen3.5-9B:高性能GPU算力下的代码生成效果实测
Qwen3.5-9B:高性能GPU算力下的代码生成效果实测 1. 开篇:当大模型遇上高性能GPU 最近在星图GPU平台上测试了Qwen3.5-9B的代码生成能力,结果确实让人眼前一亮。作为一款专注于代码生成的大模型,Qwen3.5-9B在高性能GPU算力的加持下…...

SiameseUIE开源大模型教程:中文信息抽取领域的轻量级SOTA方案
SiameseUIE开源大模型教程:中文信息抽取领域的轻量级SOTA方案 无需复杂配置,10分钟上手中文信息抽取的最强轻量方案 1. 为什么选择SiameseUIE? 信息抽取是自然语言处理中的核心任务,它能够从非结构化文本中自动识别和提取关键信息…...

Z-Image-Turbo-辉夜巫女辅助JDK新特性学习:为抽象概念生成可视化示例
Z-Image-Turbo-辉夜巫女辅助JDK新特性学习:为抽象概念生成可视化示例 对于Java开发者来说,学习新版JDK引入的特性,比如虚拟线程、模式匹配这些概念,有时候就像是在读一本没有插图的说明书。文字描述很详细,但脑子里就…...