[OpenGL]使用 Compute Shader 实现矩阵点乘
一、简介
本文介绍了如何使用 OpenGL 中的 compute shader 进行矩阵相乘的并行运算。代码目标是,输入两个大小为 10*10 的矩阵 A 和 B,计算 A*B 的结果并存储到矩阵 C 中。
二、代码
0. 代码逻辑
1. 初始化 glfw, glad, 窗口
2. 初始化 compute shader
3. 准备输入数据
4. 运行 compute shader
5. 读取结果并打印
6. 释放资源
1. main.cpp
#include <glad/glad.h>
#include <GLFW/glfw3.h>
#include "ComputeShader.hpp"#include <cstdint>
#include <iostream>
#include <iostream>// 用于处理窗口大小改变的回调函数
void framebuffer_size_callback(GLFWwindow *window, int width, int height);
void window_close_callback(GLFWwindow *window);// 用于处理用户输入的函数
void processInput(GLFWwindow *window);// 指定窗口默认width和height像素大小
unsigned int SCR_WIDTH = 800;
unsigned int SCR_HEIGHT = 600;/************************************/int main()
{/****** 1. 初始化 glfw, glad, 窗口 *******/// glfw 初始化 + 配置 glfw 参数glfwInit();glfwWindowHint(GLFW_CONTEXT_VERSION_MAJOR, 4);glfwWindowHint(GLFW_CONTEXT_VERSION_MINOR, 3);glfwWindowHint(GLFW_OPENGL_PROFILE, GLFW_OPENGL_CORE_PROFILE);// glfw 生成窗口GLFWwindow *window = glfwCreateWindow(SCR_WIDTH, SCR_HEIGHT, "LearnOpenGL", NULL, NULL);if (window == NULL){// 检查是否成功生成窗口,如果没有成功打印出错信息并且退出std::cout << "Failed to create GLFW window" << std::endl;glfwTerminate();return -1;}// 设置窗口window的上下文glfwMakeContextCurrent(window);// 配置window变化时的回调函数glfwSetFramebufferSizeCallback(window, framebuffer_size_callback);// 设置窗口关闭回调glfwSetWindowCloseCallback(window, window_close_callback);// 使用 glad 加载 OpenGL 中的各种函数if (!gladLoadGLLoader((GLADloadproc)glfwGetProcAddress)){std::cout << "Failed to initialize GLAD" << std::endl;return -1;}/************************************//****** 2. 初始化 compute shader ******/ComputeShader computeShader("../resources/Compute.comp");/************************************//****** 3. 准备输入数据 ******/// 输入矩阵 Afloat A[100];for (int i = 0; i < 10; i++){for (int j = 0; j < 10; j++){A[i * 10 + j] = 1.0f * i;}}// 输入矩阵 Bfloat B[100];for (int i = 0; i < 10; i++){for (int j = 0; j < 10; j++){B[i * 10 + j] = 1.0f * i;}}// 输出矩阵 Cfloat C[100];GLuint SSBO_A, SSBO_B, SSBO_C;glGenBuffers(1, &SSBO_A);glGenBuffers(1, &SSBO_B);glGenBuffers(1, &SSBO_C);glBindBuffer(GL_SHADER_STORAGE_BUFFER, SSBO_A);glBufferData(GL_SHADER_STORAGE_BUFFER, sizeof(A), A, GL_STATIC_READ);glBindBufferBase(GL_SHADER_STORAGE_BUFFER, 0, SSBO_A);glBindBuffer(GL_SHADER_STORAGE_BUFFER, SSBO_B);glBufferData(GL_SHADER_STORAGE_BUFFER, sizeof(B), B, GL_STATIC_READ);glBindBufferBase(GL_SHADER_STORAGE_BUFFER, 1, SSBO_B);glBindBuffer(GL_SHADER_STORAGE_BUFFER, SSBO_C);glBufferData(GL_SHADER_STORAGE_BUFFER, sizeof(C), C, GL_DYNAMIC_DRAW);glBindBufferBase(GL_SHADER_STORAGE_BUFFER, 2, SSBO_C);/************************************//****** 4. 运行 compute shader ******/// 运行 compute shader, 分为 10*10*1 个 workgroup, 每个 workgroup 计算 C 矩阵中的一个元素值computeShader.use();glDispatchCompute((unsigned int)10, (unsigned int)10, 1);glMemoryBarrier(GL_SHADER_STORAGE_BARRIER_BIT);/************************************//****** 5. 读取结果并打印 ******/glBindBuffer(GL_SHADER_STORAGE_BUFFER, SSBO_C);glGetBufferSubData(GL_SHADER_STORAGE_BUFFER, 0, sizeof(C), C);for (int row = 0; row < 10; ++row){for (int col = 0; col < 10; ++col){printf("%0.3f ", C[row * 10 + col]);}printf("\n");}/************************************//****** 6.释放资源 ******/// glfw 释放 glfw使用的所有资源glfwTerminate();/************************************/return 0;
}// 用于处理用户输入的函数
void processInput(GLFWwindow *window)
{// 当按下 Esc 按键时调用 glfwSetWindowShouldClose() 函数,关闭窗口if (glfwGetKey(window, GLFW_KEY_ESCAPE) == GLFW_PRESS){glfwSetWindowShouldClose(window, true);}
}// 在使用 OpenGL 和 GLFW 库时,处理窗口大小改变的回调函数
// 当窗口大小发生变化时,确保 OpenGL 渲染的内容能够适应新的窗口大小,避免图像被拉伸、压缩或出现其他比例失真的问题
void framebuffer_size_callback(GLFWwindow *window, int width, int height)
{SCR_WIDTH = width;SCR_HEIGHT = height;glViewport(0, 0, width, height);
}
void window_close_callback(GLFWwindow *window)
{// 这里可以做一些额外的清理工作// 例如释放资源、记录日志等std::cout << "Window is closing..." << std::endl;
}2. ComputeShader 类
#ifndef COMPUTESHADER_H
#define COMPUTESHADER_H#include <glad/glad.h>
#include <glm/glm.hpp>#include <string>
#include <fstream>
#include <sstream>
#include <iostream>class ComputeShader
{public:unsigned int ID;// constructor generates the shader on the fly// ------------------------------------------------------------------------ComputeShader() {};ComputeShader(const char *computePath){// 1. retrieve the vertex/fragment source code from filePathstd::string computeCode;std::ifstream cShaderFile;// ensure ifstream objects can throw exceptions:cShaderFile.exceptions(std::ifstream::failbit | std::ifstream::badbit);try{// open filescShaderFile.open(computePath);std::stringstream cShaderStream;// read file's buffer contents into streamscShaderStream << cShaderFile.rdbuf();// close file handlerscShaderFile.close();// convert stream into stringcomputeCode = cShaderStream.str();}catch (std::ifstream::failure &e){std::cout << "ERROR::SHADER::FILE_NOT_SUCCESSFULLY_READ: " << e.what() << std::endl;}const char *cShaderCode = computeCode.c_str();// 2. compile shadersunsigned int compute;// compute shadercompute = glCreateShader(GL_COMPUTE_SHADER);glShaderSource(compute, 1, &cShaderCode, NULL);glCompileShader(compute);checkCompileErrors(compute, "COMPUTE");// shader ProgramID = glCreateProgram();glAttachShader(ID, compute);glLinkProgram(ID);checkCompileErrors(ID, "PROGRAM");// delete the shaders as they're linked into our program now and no longer necessaryglDeleteShader(compute);}// activate the shader// ------------------------------------------------------------------------void use() const{glUseProgram(ID);}// ------------------------------------------------------------------------void setInt(const std::string &name, int value) const{glUniform1i(glGetUniformLocation(ID, name.c_str()), value);}private:// utility function for checking shader compilation/linking errors.// ------------------------------------------------------------------------void checkCompileErrors(GLuint shader, std::string type){GLint success;GLchar infoLog[1024];if (type != "PROGRAM"){glGetShaderiv(shader, GL_COMPILE_STATUS, &success);if (!success){glGetShaderInfoLog(shader, 1024, NULL, infoLog);std::cout << "ERROR::SHADER_COMPILATION_ERROR of type: " << type << "\n"<< infoLog << "\n -- --------------------------------------------------- -- " << std::endl;}}else{glGetProgramiv(shader, GL_LINK_STATUS, &success);if (!success){glGetProgramInfoLog(shader, 1024, NULL, infoLog);std::cout << "ERROR::PROGRAM_LINKING_ERROR of type: " << type << "\n"<< infoLog << "\n -- --------------------------------------------------- -- " << std::endl;}}}
};
#endif3. compute shader (Compute.comp)
#version 430layout(std430, binding = 0) buffer inputMatrixA { float A[]; };
layout(std430, binding = 1) buffer inputMatrixB { float B[]; };
layout(std430, binding = 2) buffer OnputData { float C[]; };layout(local_size_x = 1,local_size_y = 1) in; // 每个 workgroup item 计算 C 的一个元素void main() {// 获取当前 workgroup item 的全局位置uint row = gl_GlobalInvocationID.x;uint col = gl_GlobalInvocationID.y;// 确保不会越界if (row >= 10 || col >= 10) {return;}// 从矩阵 A 和矩阵 B 中读取数据float valueA = 0.0f;float valueB = 0.0f;// 计算矩阵 C 中对应的元素float result = 0.0;for (int k = 0; k < 10; k++) {valueA = A[row * 10 + k];valueB = B[k * 10 + col];result += valueA * valueB; // 矩阵乘法}C[row * 10 + col] = result;
}4. 运行结果
0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000
45.000 45.000 45.000 45.000 45.000 45.000 45.000 45.000 45.000 45.000
90.000 90.000 90.000 90.000 90.000 90.000 90.000 90.000 90.000 90.000
135.000 135.000 135.000 135.000 135.000 135.000 135.000 135.000 135.000 135.000
180.000 180.000 180.000 180.000 180.000 180.000 180.000 180.000 180.000 180.000
225.000 225.000 225.000 225.000 225.000 225.000 225.000 225.000 225.000 225.000
270.000 270.000 270.000 270.000 270.000 270.000 270.000 270.000 270.000 270.000
315.000 315.000 315.000 315.000 315.000 315.000 315.000 315.000 315.000 315.000
360.000 360.000 360.000 360.000 360.000 360.000 360.000 360.000 360.000 360.000
405.000 405.000 405.000 405.000 405.000 405.000 405.000 405.000 405.000 405.000
三、参考
[1]LearnOpenGL-Guest Articles-2022-Compute Shaders
相关文章:

[OpenGL]使用 Compute Shader 实现矩阵点乘
一、简介 本文介绍了如何使用 OpenGL 中的 compute shader 进行矩阵相乘的并行运算。代码目标是,输入两个大小为 10*10 的矩阵 A 和 B,计算 A*B 的结果并存储到矩阵 C 中。 二、代码 0. 代码逻辑 1. 初始化 glfw, glad, 窗口 2. 初始化 compute shad…...

jangow-01-1.0.1靶机
靶机 ip:192.168.152.155 把靶机的网络模式调成和攻击机kali一样的网络模式,我的kali是NAT模式, 在系统启动时(长按shift键)直到显示以下界面 ,我们选第二个,按回车。 继续选择第二个,这次按 e 进入编辑页面 接下来,…...

MySQL 查询大偏移量(LIMIT)问题分析
大偏移量查询缓慢?LIMIT: 会进行两步操作 性能消耗在哪里了?OFFSET操作问题 2 LIMIT 操作 如何优化? 大偏移量查询缓慢? 示例:(假设age字段有索引) SELECT * FROM test WHERE age>18 LIMIT 10000000 ,10;分析MySQL的 LIMIT 10000000 , 10 LIMIT: 会进行两步操作 OFF…...

Docker、containerd、安全沙箱、社区Kata Containers运行对比
大家看了解决有意义、有帮助记得点赞加关注!!! containerd、安全沙箱和Docker三种运行对比。 本文通过对比三种运行时的实现和使用限制、部署结构,帮助您根据需求场景了解并选择合适的容器运行。 一、容器运行时实现和使用限制…...

使用npm包的工程如何引入mapboxgl-enhance/maplibre-gl-enhance扩展包
作者:刘大 前言 在使用iClient for MapboxGL/MapLibreGL项目开发中,往往会对接非EPSG:3857坐标系的地图,由于默认不支持,因此需引入mapboxgl-enhance/maplibre-gl-enhance扩展包。 在使用Vue等其他框架,通过npm包下载…...

【NIFI】实现ORACLE->ORACLE数据同步
【NIFI】实现ORACLE->ORACLE数据同步 需求 使用nifi实现 oracle->oracle 不同数据库之间的数据同步, 如果想实现 oracle->oracle技术有很多,例如使用oracle golden gate或者是kettle等,或者是使用oralce的dblink技术也能实现。当让…...

单例模式的写法
单例模式(Singleton Pattern)是一种设计模式,确保一个类只有一个实例,并提供一个全局访问点。常用于管理共享资源(如数据库连接、配置文件、线程池等)。在实际编码中,有多种实现单例模式的方法&…...

Selenium实践总结
1.使用显示等待而不是隐式等待 隐式等待可能会导致不可预测的测试行为,尤其是在动态 Web 应用程序中。显式等待,它允许您 等待特定条件发生后再继续测试,这种方法提供了更多的控制和可靠性。 WebDriverWait wait new WebDriverWait(drive…...

Python数据可视化小项目
英雄联盟S14世界赛选手数据可视化 由于本学期有一门数据可视化课程,课程结课作业要求完成一个数据可视化的小Demo,于是便有了这个小项目,课程老师要求比较简单,只要求熟练运用可视化工具展示数据,并不要求数据来源&am…...

Python毕业设计选题:基于python的白酒数据推荐系统_django+hive
开发语言:Python框架:djangoPython版本:python3.7.7数据库:mysql 5.7数据库工具:Navicat11开发软件:PyCharm 系统展示 管理员登录 管理员功能界面 用户管理 白酒管理 系统管理 看板展示 系统首页 白酒详情…...

SQL-leetcode-180. 连续出现的数字
180. 连续出现的数字 表:Logs -------------------- | Column Name | Type | -------------------- | id | int | | num | varchar | -------------------- 在 SQL 中,id 是该表的主键。 id 是一个自增列。 找出所有至少连续出现三次的数字。 返回的…...

Unity中如何修改Sprite的渲染网格
首先打开SpriteEditor 选择Custom OutLine,点击Genrate 则在图片边缘会出现边缘线,调整白色小方块可以调整边缘 调整后,Sprite就会按照调整后的网格渲染了。 如何在UI中使用? 只要在UI的Image组件中选择Use Sprite Mesh 即可 结果࿱…...

跟着 8.6k Star 的开源数据库,搞 RAG!
过去 9 年里,HelloGitHub 月刊累计收录了 3000 多个开源项目。然而,随着项目数量的增加,不少用户反馈:“搜索功能不好用,找不到想要的项目!” 这让我意识到,仅仅收录项目是不够的,还…...

每日一题 345. 反转字符串中的元音字母
345. 反转字符串中的元音字母 简单 class Solution { public:string reverseVowels(string s) {int l 0;int r s.size() - 1;unordered_set<char> st {a,A,E,e,i,I,O,o,U,u};while(l < r){while(l<r && !st.count(s[l]) ){l;}while(l<r &&…...

Stream API 的设计融合了多个经典设计模式
Stream API 的设计融合了多个经典设计模式: 1. 策略模式(Strategy Pattern) 策略模式定义了一个算法的家族,将每个算法封装起来,并使它们可以互换。Stream API 中的每个操作(如 filter(), map()ÿ…...

jmeter混合场景测试,设置多业务并发比例(吞吐量控制器)
jmeter混合场景测试,设置多业务并发比例(吞吐量控制器) 测试目的 为了验证需求提出的性能要求,结合实际可能的高压力场景,较全面的检测系统的性能表现。 测试方法 根据需求调研的业务模型和交易占比,设置不…...

直流有刷电机多环控制(PID闭环死区和积分分离)
直流有刷电机多环控制 提高部分-第8讲 直流有刷电机多环控制实现(1)_哔哩哔哩_bilibili PID模型 外环的输出作为内环的输入,外环是最主要控制的效果,主要控制电机的位置。改变位置可以改变速度,改变速度是受电流控制。 实验环境 【 !】功能简介: 按下KEY1使能电机,按下…...

vue-axios+springboot实现文件流下载
前端vue代码: <template><div class"app-container documentation-container"><div><el-button type"primary" click"downloadFile(test.xlsx)">下载test.xlsx</el-button></div></div> …...

selenium执行js
JS知识 获取元素 document.getElement 移除属性:removeAttribute("xx") 窗口移动:window.scrollTo(0, document.body.scrollHeight)方法 drivier.execute_script(js)场景: 日期选择框,不能输入,只能设置…...
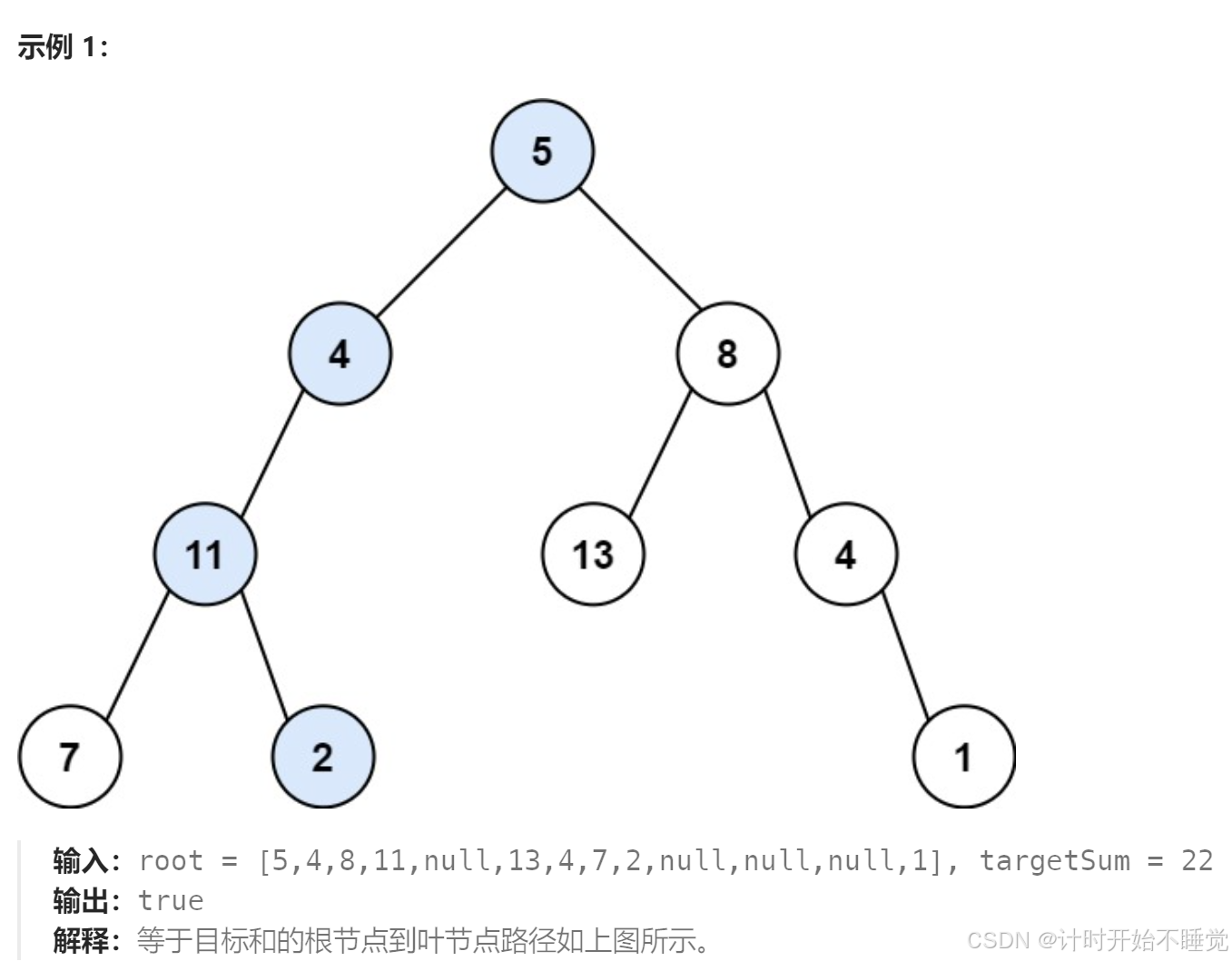
每日算法Day11【左叶子之和、找树左下角的值、路径总和】
404.左叶子之和 算法链接: 404. 左叶子之和 - 力扣(LeetCode) 类型: 二叉树 难度: 简单 思路:要判断一个节点是否为左叶子节点,只能通过其父节点进行判断。 题解: /*** Definition for a binary tree node.* public class Tr…...

2026专业护眼产品深度评测:告别眼干涩疲劳,哪款才是“医用级“长效养护的选择?
屏幕时代,眼睛正在为我们的工作和生活"买单"。从早起看手机的那一刻,到深夜关灯前最后一次刷屏,多数人每天面对电子屏幕的时间早已超过10小时。干涩、疲劳、视力模糊、异物感……这些曾经只出现在中老年人身上的困扰,正…...

2026好用的企业内网通讯软件:哪家更适合你?
2026年,企业数字化办公的浪潮已进入深水区。随着《数据安全法》等法规的深度落地,以及企业对核心数字资产掌控权的重视,一个显著的趋势正在发生:企业通讯市场正在经历一场深刻的“向内回归”——私有化部署正从传统行业的无奈之选…...

即时通讯私有化,BeeWorks让每一次内网沟通都安全、安心、高效
BeeWorks以全维度安全防护体系为支撑,将安全设计深度融入每一项核心功能,让员工在日常办公中既能享受高效协同,又能全程守护企业核心数据安全。同时,规范的使用操作是发挥安全优势的关键,本文将重点介绍BeeWorks核心功…...

告别插件切换!一款满足你所有挖洞需求的浏览器插件助力高效挖洞
0x01 工具介绍 由于目前网上流通的插件功能都各有千秋,每个插件都有他自己的亮点,每次使用都得按场景去选择插件,为了能够有一款属于自己的完美插件,不用来回倒腾切换,由此GodEyes 诞生了。 它是一款可以帮助安全研究…...

新手零基础入门:在快马平台用AI生成你的首个龙虾部署项目
新手零基础入门:在快马平台用AI生成你的首个龙虾部署项目 作为一个刚接触容器化开发的新手,第一次听说"龙虾部署"这个概念时,我完全摸不着头脑。后来才知道,这其实就是Docker容器化部署的一种形象说法。今天我想分享一…...

浦语灵笔2.5-7B精彩案例分享:手写体题目识别+解题逻辑生成全过程
浦语灵笔2.5-7B精彩案例分享:手写体题目识别解题逻辑生成全过程 1. 引言:当AI“看懂”你的手写作业 想象一下这个场景:你正在辅导孩子做数学作业,他遇到一道难题,不仅把题目抄了下来,还在旁边画了辅助线、…...

Cursor Pro功能持续访问解决方案:系统化AI编程助手权限管理方法论
Cursor Pro功能持续访问解决方案:系统化AI编程助手权限管理方法论 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reach…...

Labelme标注神器:从安装到实战,手把手教你打造自己的图像分割数据集
Labelme图像标注实战:从入门到生产级数据集构建 在计算机视觉项目中,数据标注往往是决定模型效果的关键因素。不同于常见的矩形框标注工具,Labelme以其灵活的多边形标注能力和丰富的输出格式支持,成为语义分割任务的首选工具。但很…...

从零复现DeepSDF:环境配置与数据集生成全攻略
1. 环境准备:从零搭建DeepSDF复现基础 复现DeepSDF的第一步就是搭建合适的环境。这个环节看似简单,实则暗藏玄机。我最初尝试在云服务器上配置环境,结果因为权限问题踩了一堆坑。后来改用本地Ubuntu 16.04系统,整个过程才变得顺畅…...

Python 批量导出数据库数据至 Excel 文件
简介 langchain专门用于构建LLM大语言模型,其中提供了大量的prompt模板,和组件,通过chain(链)的方式将流程连接起来,操作简单,开发便捷。 环境配置 安装langchain框架 pip install langchain langchain-community 其中…...