Python爬虫教程——7个爬虫小案例(附源码)_爬虫实例
本文介绍了7个Python爬虫小案例,包括爬取豆瓣电影Top250、猫眼电影Top100、全国高校名单、中国天气网、当当网图书、糗事百科段子和新浪微博信息,帮助读者理解并实践Python爬虫基础知识。

-
包含编程资料、学习路线图、源代码、软件安装包等!【[点击这里]】!
在文章开始之前先给大家简单介绍一下python爬虫
一、什么是爬虫?
1.简单介绍爬虫
爬虫的全称为网络爬虫,简称爬虫,别名有网络机器人,网络蜘蛛等等。
网络爬虫是一种自动获取网页内容的程序,为搜索引擎提供了重要的数据支撑。搜索引擎通过网络爬虫技术,将互联网中丰富的网页信息保存到本地,形成镜像备份。我们熟悉的谷歌、百度本质上也可理解为一种爬虫。
如果形象地理解,爬虫就如同一只机器蜘蛛,它的基本操作就是模拟人的行为去各个网站抓取数据或返回数据。
2.爬虫的工作原理
下图是一个网络爬虫的基本框架:

二、python爬虫能干什么?
python爬虫就是模拟浏览器打开网页,获取网页中想要的那部分数据。利用爬虫我们可以抓取商品信息、评论及销量数据;可以抓取房产买卖及租售信息;可以抓取各类职位信息等。
利用爬虫我们可以获取大量的价值数据,从而获得感性认识中不能得到的信息,比如:爬取知乎优质答案,为你筛选出各话题下最优质的内容。抓取淘宝、京东商品、评论及销量数据,对各种商品及用户的消费场景进行分析。
抓取房产买卖及租售信息,分析房价变化趋势、做不同区域的房价分析。爬取各类职位信息,分析各行业人才需求情况及薪资水平。爬虫的本质:爬虫的本质就是模拟浏览器打开网页,获取网页中我们想要的那部分数据。
三、Python7个爬虫小案例
下面我将分享7个Python爬虫的小案例,帮助大家更好地学习和了解Python爬虫的基础知识。以下是每个案例的简介和源代码:
1. 爬取豆瓣电影Top250
这个案例使用BeautifulSoup库爬取豆瓣电影Top250的电影名称、评分和评价人数等信息,并将这些信息保存到CSV文件中。
import requests
from bs4 import BeautifulSoup
import csv
# 请求URL
url = '<https://movie.douban.com/top250>'
# 请求头部
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
# 解析页面函数
def parse_html(html):
soup = BeautifulSoup(html, 'lxml')
movie_list = soup.find('ol', class_='grid_view').find_all('li')
for movie in movie_list:
title = movie.find('div', class_='hd').find('span', class_='title').get_text()
rating_num = movie.find('div', class_='star').find('span', class_='rating_num').get_text()
comment_num = movie.find('div', class_='star').find_all('span')[-1].get_text()
writer.writerow([title, rating_num, comment_num])
# 保存数据函数``def save_data():
f = open('douban_movie_top250.csv', 'a', newline='', encoding='utf-8-sig')
global writer
writer = csv.writer(f)
writer.writerow(['电影名称', '评分', '评价人数'])
for i in range(10):
url = '<https://movie.douban.com/top250?start=>' + str(i*25) + '&filter='
response = requests.get(url, headers=headers)
parse_html(response.text)
f.close()
if __name__ == '__main__':
save_data()
2. 爬取猫眼电影Top100
这个案例使用正则表达式和requests库爬取猫眼电影Top100的电影名称、主演和上映时间等信息,并将这些信息保存到TXT文件中。
import requests
import re
# 请求URL
url = '<https://maoyan.com/board/4>'
# 请求头部
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
# 解析页面函数
def parse_html(html):
pattern = re.compile('<p class="name"><a href=".*?" title="(.*?)" data-act="boarditem-click" data-val="{movieId:\\d+}">(.*?)</a></p>.*?<p class="star">(.*?)</p>.*?<p class="releasetime">(.*?)</p>', re.S)
items = re.findall(pattern, html)
for item in items:
yield {
'电影名称': item[1],
'主演': item[2].strip(),
'上映时间': item[3]
}
# 保存数据函数
def save_data():
f = open('maoyan_top100.txt', 'w', encoding='utf-8')
for i in range(10):
url = '<https://maoyan.com/board/4?offset=>' + str(i*10)
response = requests.get(url, headers=headers)
for item in parse_html(response.text):
f.write(str(item) + '\
')
f.close()
if name == ‘main’:
save_data()
3. 爬取全国高校名单
这个案例使用正则表达式和requests库爬取全国高校名单,并将这些信息保存到TXT文件中。
import requests
import re
# 请求URL
url = '<http://www.zuihaodaxue.com/zuihaodaxuepaiming2019.html>'
# 请求头部
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
# 解析页面函数
def parse_html(html):
pattern = re.compile('<tr class="alt">.*?<td>(.*?)</td>.*?<td><div align="left">.*?<a href="(.*?)" target="_blank">(.*?)</a></div></td>.*?<td>(.*?)</td>.*?<td>(.*?)</td>.*?</tr>', re.S)
items = re.findall(pattern, html)
for item in items:
yield {
'排名': item[0],
'学校名称': item[2],
'省市': item[3],
'总分': item[4]
}
# 保存数据函数
def save_data():
f = open('university_top100.txt', 'w', encoding='utf-8')
response = requests.get(url, headers=headers)
for item in parse_html(response.text):
f.write(str(item) + '\
')
f.close()
if name == ‘main’:
save_data()
4. 爬取中国天气网城市天气
这个案例使用xpath和requests库爬取中国天气网的城市天气,并将这些信息保存到CSV文件中。
4. 爬取中国天气网城市天气``这个案例使用xpath和requests库爬取中国天气网的城市天气,并将这些信息保存到CSV文件中。
5. 爬取当当网图书信息
这个案例使用xpath和requests库爬取当当网图书信息,并将这些信息保存到CSV文件中。
import requests
from lxml import etree
import csv
# 请求URL
url = '<http://search.dangdang.com/?key=Python&act=input>'
# 请求头部
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
# 解析页面函数``def parse_html(html):
selector = etree.HTML(html)
book_list = selector.xpath('//*[@id="search_nature_rg"]/ul/li')
for book in book_list:
title = book.xpath('a/@title')[0]
link = book.xpath('a/@href')[0]
price = book.xpath('p[@class="price"]/span[@class="search_now_price"]/text()')[0]
author = book.xpath('p[@class="search_book_author"]/span[1]/a/@title')[0]
publish_date = book.xpath('p[@class="search_book_author"]/span[2]/text()')[0]
publisher = book.xpath('p[@class="search_book_author"]/span[3]/a/@title')[0]
yield {
'书名': title,
'链接': link,
'价格': price,
'作者': author,
'出版日期': publish_date,
'出版社': publisher
}
# 保存数据函数
def save_data():
f = open('dangdang_books.csv', 'w', newline='', encoding='utf-8-sig')
writer = csv.writer(f)
writer.writerow(['书名', '链接', '价格', '作者', '出版日期', '出版社'])
response = requests.get(url, headers=headers)
for item in parse_html(response.text):
writer.writerow(item.values())
f.close()
if __name__ == '__main__':
save_data()
6. 爬取糗事百科段子
这个案例使用xpath和requests库爬取糗事百科的段子,并将这些信息保存到TXT文件中。
import requests
from lxml import etree
# 请求URL
url = '<https://www.qiushibaike.com/text/>'
# 请求头部
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
# 解析页面函数``def parse_html(html):
selector = etree.HTML(html)
content_list = selector.xpath('//div[@class="content"]/span/text()')
for content in content_list:
yield content
# 保存数据函数
def save_data():
f = open('qiushibaike_jokes.txt', 'w', encoding='utf-8')
for i in range(3):
url = '<https://www.qiushibaike.com/text/page/>' + str(i+1) + '/'
response = requests.get(url, headers=headers)
for content in parse_html(response.text):
f.write(content + '\
')
f.close()
if name == ‘main’:
save_data()
7. 爬取新浪微博
这个案例使用selenium和requests库爬取新浪微博,并将这些信息保存到TXT文件中。
import time
from selenium import webdriver
import requests
# 请求URL
url = '<https://weibo.com/>'
# 请求头部
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
# 解析页面函数
def parse_html(html):
print(html)
# 保存数据函数
def save_data():
f = open('weibo.txt', 'w', encoding='utf-8')
browser = webdriver.Chrome()
browser.get(url)
time.sleep(10)
browser.find_element_by_name('username').send_keys('username')
browser.find_element_by_name('password').send_keys('password')
browser.find_element_by_class_name('W_btn_a').click()
time.sleep(10)
response = requests.get(url, headers=headers, cookies=browser.get_cookies())
parse_html(response.text)
browser.close()
f.close()
if __name__ == '__main__':
save_data()
希望这7个小案例能够帮助大家更好地掌握Python爬虫的基础知识!
最后
如果你也想学习Python,可以关注我,我会把自己知道的,曾经走过的弯路都告诉你,让你在学习Python的路上更加顺畅。
我自己也整理了一套最新的Python系统学习教程,包括从基础的python脚本到web开发、爬虫、数据分析、数据可视化、机器学习等。如果你也喜欢编程,想通过学习Python转行、做副业或者提升工作效率,这份【最新全套Python学习资料】 一定对你有用!
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、机器学习、Python量化交易等学习教程。带你从零基础系统性的学好Python!编程资料、学习路线图、源代码、软件安装包等!
-
包含编程资料、学习路线图、源代码、软件安装包等!【[点击这里]】!
① Python所有方向的学习路线图,清楚各个方向要学什么东西
② 100多节Python课程视频,涵盖必备基础、爬虫和数据分析
③ 100多个Python实战案例,学习不再是只会理论
④ 华为出品独家Python漫画教程,手机也能学习
⑤ 历年互联网企业Python面试真题,复习时非常方便****

相关文章:
Python爬虫教程——7个爬虫小案例(附源码)_爬虫实例
本文介绍了7个Python爬虫小案例,包括爬取豆瓣电影Top250、猫眼电影Top100、全国高校名单、中国天气网、当当网图书、糗事百科段子和新浪微博信息,帮助读者理解并实践Python爬虫基础知识。 包含编程资料、学习路线图、源代码、软件安装包等!【…...

Log4j2的Policies详解、SizeBasedTriggeringPolicy、TimeBasedTriggeringPolicy
文章目录 一、Policies二、SizeBasedTriggeringPolicy:基于文件大小的滚动策略2.1、文件达到指定大小就归档 三、TimeBasedTriggeringPolicy:基于时间间隔的滚动策略3.1、验证秒钟归档场景3.2、验证分钟场景3.3、验证小时场景 四、多策略组合使用五、扩展知识5.1、S…...

ES中查询中参数的解析
目录 query中参数match参数match_allmatch:匹配指定参数match_phrase query中其他的参数query_stringprefix前缀查询:wildcard通配符查询:range范围查询:fuzzy 查询: 组合查询bool参数mustmust_notshould条件 其他参数 query中参数 词条查询term:它仅匹配在给定字段…...
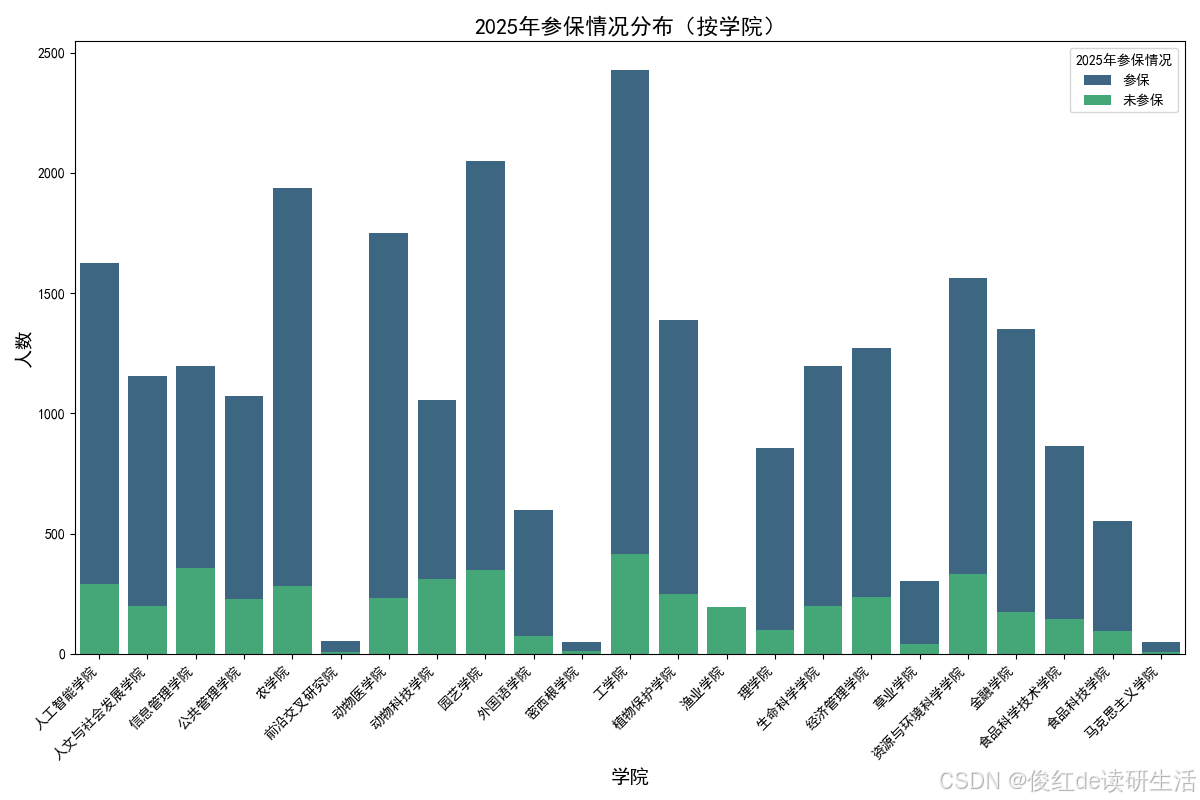
学习笔记:使用 pandas 和 Seaborn 绘制柱状图
学习笔记:使用 pandas 和 Seaborn 绘制柱状图 前言 今天在使用 pandas 对数据进行处理并在 Python 中绘制可视化图表时,遇到了一些关于字体设置和 Seaborn 主题覆盖的小问题。这里将学习到的方法和注意事项做个总结,以便之后的项目中可以快…...

【每日学点鸿蒙知识】placement设置top、组件携带自定义参数、主动隐藏输入框、Web设置字体、对话框设置全屏宽
1、popup组件placement设置top没有生效? 可以用offset属性将popup往下边偏移一下 来规避 2、组件携带自定义参数的接口是哪个? 参考链接:https://developer.huawei.com/consumer/cn/doc/harmonyos-references-V5/ts-universal-attributes-…...
后端开发-Maven
环境说明: windows系统:11版本 idea版本:2023.3.2 Maven 介绍 Apache Maven 是一个 Java 项目的构建管理和理解工具。Maven 使用一个项目对象模型(POM),通过一组构建规则和约定来管理项目的构建…...

自动化办公-合并多个excel
在日常的办公自动化工作中,尤其是处理大量数据时,合并多个 Excel 表格是一个常见且繁琐的任务。幸运的是,借助 Python 语言中的强大库,我们可以轻松地自动化这个过程。本文将带你了解如何使用 Python 来合并多个 Excel 表格&#…...

mavlink移植到单片机stm32f103c8t6,实现接收和发送数据
前言: 好久没更新博客了,这两个月真的是异常的忙,白天要忙着公司里的事,晚上还要忙着修改小论文,一点自己的时间都没有了,不过确确实实是学到了很多东西,对无人机的技术研究也更深了一些。不过好…...

小程序基础 —— 08 文件和目录结构
文件和目录结构 一个完整的小程序项目由两部分组成:主体文件、页面文件: 主体文件:全局文件,能够作用于整个小程序,影响小程序的每个页面,主体文件必须放到项目的根目录下; 主体文件由三部分组…...

FIR数字滤波器设计——窗函数设计法——滤波器的时域截断
与IIR数字滤波器的设计类似,设计FIR数字滤波器也需要事先给出理想滤波器频率响应 H ideal ( e j ω ) H_{\text{ideal}}(e^{j\omega}) Hideal(ejω),用实际的频率响应 H ( e j ω ) H(e^{j\omega}) H(ejω)去逼近 H ideal ( e j ω ) H_{\text{ideal}}…...

MySQLOCP考试过了,题库很稳,经验分享。
前几天,本人参加了Oracle认证 MySQLOCP工程师认证考试 ,先说下考这个证书的初衷: 1、首先本人是从事数据库运维的,今年开始单位逐步要求DBA持证上岗。 2、本人的工作是涉及数据库维护,对这块的内容比较熟悉ÿ…...

WPF 绘制过顶点的圆滑曲线 (样条,贝塞尔)
在一个WPF项目中要用到样条曲线,必须过顶点,圆滑后还不能太走样,捣鼓一番,发现里面颇有玄机,于是把我多方抄来改造的方法发出来,方便新手: 如上图,看代码吧: ----------…...

Kafka 幂等性与事务
文章目录 幂等性实现机制配置使用局限性 事务使用场景配置使用实现机制事务过程事务初始化事务开始事务提交事务取消事务消费 幂等性 Producer 无论向 Broker 发送多少次重复的数据,Broker 端只会持久化一条,保证数据不丢失且不重复。 实现机制 通过引…...

day2 Linux操作系统指令
思维导图 在家目录下创建目录文件,dir 1、dir下创建dir1和dir2 2、把当前目录下的所有文件拷贝到dir1中, 3、把当前目录下的所有脚本文件拷贝到dir2中 4、把dir2打包并压缩为dir2.tar.xz 5、再把dir2.tar.xz移动到dir1中 6、解压dir1中的压缩包 7、使用…...

AI一周重要会议和活动概览
一、小模型的曙光和机会之思辨高峰论坛 会议介绍:小模型的曙光和机会之思辨”高峰论坛暨第32期CSIG图像图形学科前沿讲习班于2025年1月3—4日在杭州举办,会议由中国图象图形学学会主办,中国图象图形学学会前沿科技论坛委员会承办。本次论坛设…...

重启ubuntu服务器,如何让springboot服务自动运行
文章目录 1. 使用 systemd 服务步骤: 2. 使用 cron 的 reboot 任务步骤: 3. 使用 init.d 脚本(适用于较旧版本)步骤: 推荐方案 为了确保在重启Ubuntu服务器后,让springboot的服务test.jar象 nohup java -ja…...

python系列教程237——启动扩展功能
朋友们,如需转载请标明出处:https://blog.csdn.net/jiangjunshow 声明:在人工智能技术教学期间,不少学生向我提一些python相关的问题,所以为了让同学们掌握更多扩展知识更好地理解AI技术,我让助理负责分享…...

U盘格式化工具合集:6个免费的U盘格式化工具
在日常使用中,U盘可能会因为文件系统不兼容、数据损坏或使用需求发生改变而需要进行格式化。一个合适的格式化工具不仅可以清理存储空间,还能解决部分存储问题。本文为大家精选了6款免费的U盘格式化工具,并详细介绍它们的功能、使用方法、优缺…...

循环神经网络(RNN)入门指南:从原理到实践
目录 1. 循环神经网络的基本概念 2. 简单循环网络及其应用 3. 参数学习与优化 4. 基于门控的循环神经网络 4.1 长短期记忆网络(LSTM) 4.1.1 LSTM的核心组件: 4.2 门控循环单元(GRU) 5 实际应用中的优化技巧 5…...

马原复习笔记
文章目录 前言导论物质实践人类社会资本主义社会主义共产主义后记 前言 一月二号下午四点多考试,很友好,不是早八,哈哈哈。之前豪言壮语和朋友说这次马原要全对,多做了几次测试之后,发现总有一些知识点是自己不知道的…...
)
无人车避障新思路:手把手教你用MATLAB实现贝塞尔曲线路径规划(含完整代码)
无人车避障新思路:手把手教你用MATLAB实现贝塞尔曲线路径规划(含完整代码) 在自动驾驶和机器人导航领域,路径规划的核心挑战之一是如何在复杂环境中生成既安全又符合车辆运动学的轨迹。传统方法如A*或Dijkstra算法虽然能找出最短路…...

2024年流浪星球比赛
2024年暑假,我去到河北参加流浪星球比赛现场人很多,调试的人排队很长,不过调试很快60分钟的时间13分钟就弄完了。拿了国一比完赛后,我又去北京爬长城,长城的确难爬,道路已有些坑坑洼洼很多人不讲文明在墙上…...

什么是redis数据库?要会哪些基础知识
Redis(Remote Dictionary Server)是一个开源的内存数据结构存储系统,可用作数据库、缓存、消息中间件和实时分析引擎。它支持丰富的数据结构(如字符串、哈希、列表、集合、有序集合等),并提供高可用性、持久化、集群扩展等功能,常用于解决高并发、低延迟场景下的数据存储问…...

vibe coding实战:利用快马平台为诗歌朗诵会打造沉浸式互动网页
最近帮朋友策划了一场线上诗歌朗诵会,需要制作一个能实时互动的沉浸式网页。这个项目最有趣的地方在于,它不仅要展示诗歌内容,还要通过视觉和交互传递诗歌的情感氛围。这种强调"氛围编码"(vibe coding)的场景…...
)
保姆级避坑指南:用Anaconda和Xinference在Windows上部署LangChain-Chatchat(附解决httpx报错)
Windows系统下LangChain-Chatchat本地化部署全流程避坑手册 最近在帮几个朋友部署LangChain-Chatchat时,发现即便是按照官方文档操作,Windows环境下依然会遇到各种"坑"。特别是当Anaconda、Xinference和LangChain-Chatchat这几个组件混在一起…...
)
GPCC数据不止看趋势:手把手教你用MATLAB做降水信号的谐波分析(附周年振幅相位代码)
GPCC数据不止看趋势:手把手教你用MATLAB做降水信号的谐波分析(附周年振幅相位代码) 长江流域的降水变化对农业生产、水资源管理和生态保护都具有重要意义。当我们拿到GPCC的月尺度降水数据时,除了绘制时间序列图观察趋势外&#x…...

Elasticsearch RTF安全配置终极指南:X-Pack安装与免费License申请教程
Elasticsearch RTF安全配置终极指南:X-Pack安装与免费License申请教程 【免费下载链接】elasticsearch-rtf elasticsearch中文发行版,针对中文集成了相关插件,方便新手学习测试. 项目地址: https://gitcode.com/gh_mirrors/el/elasticsearc…...

语义分割骨干网络选型指南:MobileNet与Xception实战决策手册
语义分割骨干网络选型指南:MobileNet与Xception实战决策手册 【免费下载链接】deeplabv3-plus-pytorch 这是一个deeplabv3-plus-pytorch的源码,可以用于训练自己的模型。 项目地址: https://gitcode.com/gh_mirrors/de/deeplabv3-plus-pytorch 在…...

Java SpringBoot+Vue3+MyBatis 信息化在线教学平台系统源码|前后端分离+MySQL数据库
摘要 随着信息技术的快速发展,教育行业正逐步向数字化、智能化转型。传统的线下教学模式受限于时间和空间,难以满足现代教育的高效性和灵活性需求。在线教学平台通过整合互联网技术与教育资源,为师生提供了便捷的交互渠道,有效提升…...

你的代码为什么跑不满GPU?从Cache命中率和指令集角度拆解Roofline下的性能损失
你的代码为什么跑不满GPU?从Cache命中率和指令集角度拆解Roofline下的性能损失 当你在AI训练或高性能计算任务中发现程序性能远低于GPU的理论峰值时,Roofline模型往往能直观揭示问题所在——但真正的挑战在于,如何从那些落在屋顶线之下的数据…...