mysql系列7—Innodb的redolog
背景
本文涉及的内容较为底层,做了解即可,是以前学习《高性能Mysql》和《mysql是怎样运行的》的笔记整理所得。
redolog(后续使用redo日志表示)的核心作用是保证数据库的持久性。
在mysql系列5—Innodb的缓存中介绍过:数据和索引保存在磁盘上,为提高效率读写时需从磁盘将数据加载到内存(Buffer Pool)中,并基于内存进行读写。内存中的数据不稳定,当系统断电或者崩溃时数据会丢失,因此所有修改最终都要刷入磁盘。
数据库事务具有持久性:事务提交成功后,无论数据库环境如何(数据库或者操作系统崩溃),已提交事务涉及的修改都会被保存下来。
最简单的实现方法是每次事务提交都将Buffer Pool中的脏页刷入磁盘,然后返回事务提交成功。这意味着每次事务提交时都进行刷盘,会带来如下三个问题:
[1] 刷盘相比内存操作的速度慢太多,会严重影响mysql整体性能;
[2] SQL可能只修改了一个字节,然而需要以页为单位进行刷盘;
[3] SQL可能影响多行记录,这些行可以位于不同的页中,涉及随机IO,效率较低。
mysql引入redo日志为其提供了一个解决方案。redo日志通过特殊的格式设计从而占据较小的空间,且redo日志的顺序写入相对随机IO效率较高。因此,相对于直接将更新刷入磁盘,将修改记录(redo日志)刷入磁盘可以在保证数据库持久性的前提下最大可能降低对数据库性能的影响。
1.redo文件介绍
本章先从整体上对redo文件的格式进行认识,为后续章节作准备。内容包括对redo日志文件组、文件格式、块和每条redo日志格式的介绍,泛泛了解即可。

整体结构图如上所示,以下分别进行介绍。
1.1 redo文件组
redo文件以文件组的形式存在,文件组首尾串联。先写向第一个文件,写满后再转向下一个,循环复用,如下图所示:

redo日志文件组的实现在mysql8和mysql5中有所区别。
mysql5
(1) 存放路径
由innodb_log_group_home_dir变量确定日志的存储路径,默认与mysql的数据目录同一路径;
mysql> SHOW VARIABLES LIKE 'innodb_log_group_home_dir';
+---------------------------+-------+
| Variable_name | Value |
+---------------------------+-------+
| innodb_log_group_home_dir | ./ |
+---------------------------+-------+
(2) 文件个数
由innodb_log_files_in_group变量确定文件组中文件的个数,默认为2;
mysql> SHOW VARIABLES LIKE 'innodb_log_files_in_group';
+---------------------------+-------+
| Variable_name | Value |
+---------------------------+-------+
| innodb_log_files_in_group | 2 |
+---------------------------+-------+
(3) 文件大小
由innodb_log_file_size变量确定每个文件的大小,默认为50331648比特,即48M.
mysql> SHOW VARIABLES LIKE 'innodb_log_file_size';
+----------------------+----------+
| Variable_name | Value |
+----------------------+----------+
| innodb_log_file_size | 50331648 |
+----------------------+----------+
进入对应目录查询实际文件:
[root@124 mysql]# cd /var/lib/mysql
[root@124 mysql]# ls -al | grep ib_logfile
-rw-r-----. 1 mysql mysql 50331648 12月 15 09:46 ib_logfile0
-rw-r-----. 1 mysql mysql 50331648 10月 29 00:00 ib_logfile1
mysql8
(1) 存放路径:
存放路径位于datadir的#innodb_redo文件夹相下,即默认为/var/lib/mysql/#innodb_redo.
(2) 文件个数和文件大小
由变量innodb_redo_log_capacity控制文件组的整体大小,默认为100M;文件个数固定为32个,因此每个文件大小为3276800比特.
[root@localhost #innodb_redo]# cd /var/lib/mysql/#innodb_redo
[root@localhost #innodb_redo]# ll -t
总用量 102400
-rw-r-----. 1 mysql mysql 3276800 12月 15 10:11 #ib_redo13030
-rw-r-----. 1 mysql mysql 3276800 12月 12 16:29 #ib_redo13029
-rw-r-----. 1 mysql mysql 3276800 12月 11 07:31 #ib_redo13028
-rw-r-----. 1 mysql mysql 3276800 12月 5 17:19 #ib_redo13059_tmp
-rw-r-----. 1 mysql mysql 3276800 12月 5 17:19 #ib_redo13058_tmp
-rw-r-----. 1 mysql mysql 3276800 12月 5 17:19 #ib_redo13057_tmp
...
-rw-r-----. 1 mysql mysql 3276800 12月 5 17:19 #ib_redo13033_tmp
-rw-r-----. 1 mysql mysql 3276800 12月 5 17:19 #ib_redo13032_tmp
-rw-r-----. 1 mysql mysql 3276800 12月 5 17:19 #ib_redo13031_tmp
1.2 redo文件和redo块
对文件组有概念后,再看一下redo文件。
每个redo文件由两部分组成: 文件头+数据部分;

文件头占据2048个字节,存储当前redo文件的管理信息;数据部分存储redo日志。
redo文件也以页为单位进行管理,不过一个redo页占据512K, 后面用log block表示(与前面介绍的数据页进行区分)。其中文件头占据前4个log block, 数据部分由多个log block(redo页)组成,数据部分用于存放实际的redo数据。
再看一下log block的结构,由头部、主体和尾部组成, 如下图所示:

header和tailer存储log block的管理信息和校验信息,body中存放redo数据。
其中,header字段中有两个属性比较重要:
[1] log_block_hdr_no: 表示log block的唯一ID;
[2] log_block_hdr_data_len: 表示当前log block已使用了多少字节;初始值为12(header长度),当496个body全部写完后,log_block_hdr_data_len为512.[后面用到]
还有个地方需要注意一下(可先跳过,看第5章时再折回):
尽管redo日志文件组的每个文件都有一个文件头且占据了2048个字节的管理信息;仅第一个文件管理信息中使用两个log block(checkpoint1和chekpoint2)记录了checkpoint信息,包括checkpoint_no(checkpoint编号)和checkpoint_lsn(checkpoint时的lsn); 每次checkpoint时,checkpoint_no会递增,根据奇偶性依次写入checkpoint1和checkpoint2,以防止某次写错导致数据无法恢复。[后面用到]
1.3 redo日志格式
每条redo日志包含的信息有"在哪个表空间的哪个页上做什么",如: “将第10号表空间的100号页面的偏移量为1000处的值更新为10000”。
redo日志的格式设计如下:

[1] type表示redo日志的类型,决定了data的数据组成和解析过程,type字段主要是为了节省空间;
[2] spaceId和pageId表示表空间ID和数据页ID,用于定位数据变更发生的的位置;
[3] data记录改动的具体内容。
2.mini-transaction单元
上述redo日志格式中包含了表空间、页序号、修改数据等信息,记录了一个修改操作的所有信息。mini-transaction(以下用mtr表示)是将一组相关联的redo日志组合成一个组,mysql将一个mtr设计为一个原子操作。mtr的原子性设计为redo日志的持久化功能提供了基础,以下结合案例进行说明。
假设B+树索引的页A、B、C位于同一个表空间(tablespace001),页B比较空闲(只有一条记录),当插入一行主键为50的记录时,索引树的变化如下图所示:

此时涉及一个改动,在tablespace001的页B中添加一条记录50;对应的redo日志只有一条记录,近似表示为:
在tablespace001表空间的页B中添加一条记录50;
然而,如果页b已存满记录,50通过计算需要存储在页b中,此时需要经历页裂过程:

将页B裂解为页B和页D,涉及的步骤有:
[1] 创建一个页D;
[2] 将页B的51和90记录前移到页D;
[3] 在页A中新增一个目录记录项,指向页D;
[4] 将记录50添加到页B中.
此时,对应的redo日志有多条记录, 近似表示为:
在tablespace001表空间创建一个页D;
在tablespace001表空间的页A中添加一个目录项指向页D;
向tablespace001表空间的页D中添加记录51;
向tablespace001表空间的页D中添加记录90;
删除tablespace001表空间的页B的51记录;
删除tablespace001表空间的页B的90记录;
修改tablespace001表空间中页B的后驱节点为页D;
修改tablespace001表空间中页D的前驱节点为页B;
修改tablespace001表空间中页C的前驱节点为页D;
修改tablespace001表空间中页D的后驱节点为页C;
在tablespace001表空间的页B中添加一条记录50;
...
# 此外,此时页A页的空间也不足够添加新的目录项记录,则对页A需要进行裂解,页A如果还有上级...
插入一条记录对一个索引树的修改对应多条记录,这些redo日志需要具备原子性以保证B+树的正确性,如不能仅仅完成了页的裂解而没有拷贝数据,不能仅创建了叶子节点而未在父节点新增目录项记录等。
上述这些redo日志被标记为一个mtr,一个mtr内的redo日志必须完整。mtr的设计为日志的崩溃后恢复提供了较好的设计基础,将在第5章中介绍。
上述一条INSERT语句仅仅是针对一个索引树,一般一个表有多个索引,因此一条INSERT语句一般对应多个mtr, 如自增主键也是一个mtr. 所以可用下图表示SQL与mtr与redo日志的关系:

3.log buffer
与Buffer Pool类似,mysql引入log buffer作为redo日志的内存缓存以加快IO速度、提高系统性能。mysql启动时在内存中划出一块区域用于缓存redo日志,这部分区域叫做log buffer. log buffer也是以log block为单元进行管理, 即redo日志先写入到log buffer再刷新到磁盘。
log buffer内存大小由innodb_log_buffer_size变量确定,默认为16777216比特,即16M.
mysql> SHOW VARIABLES LIKE 'innodb_log_buffer_size';
+------------------------+----------+
| Variable_name | Value |
+------------------------+----------+
| innodb_log_buffer_size | 16777216 |
+------------------------+----------+
对于log buffer的理解可以从两个角度进行,数据写入到log buffer以及log buffer刷盘到redo日志文件; 将redo日志写到缓冲区是以mtr为单元进行,而将缓存写到磁盘是以redo页(log block)为单位进行。
3.1 写入log buffer
mysql将redo日志写入log buffer是以mtr为单位进行,以下结合案例介绍写入过程。
假设有两个事物A和B,事务A和B分别包括两个mtr, 按照时间的先后的执行顺序依次为mtr-a-1, mtr-b-1, mtr-a-2,mtr-a-2:

将mtr写入log buffer的流程图如下所示:

说明:每个mtr都有一个唯一标识lsn,即每个mtr内的所有redo日志具有相同的lsn。
3.2 log buffer写入磁盘
考虑到机器断电异常会导致内存数据丢失,而redo日志本身就是为了保证数据库事务的持久性而引入,因此何时对log buffer进行刷盘很重要。涉及到什么时候将log buffer刷入到磁盘。

log buffer的刷盘时机有以下几种:
[1] log buffer空间不足时(占据了总容量的一半),需要刷盘以预留出足够的内存空间缓存新的redo日志;
[2] 事务提交时刷盘;
[3] 后台线程每隔1秒触发一次刷盘;
[4] 正常关闭服务器时,为了保证redo日志持久化,需要刷盘;
[5] checkpoint时,将在第四章中介绍;
其中,当事务提交时立即刷盘log buffer,刷盘完成后上报事务提交成功,保证了redo日志的持久性。
根据业务对持久性的要求不同,mysql提供了一个调优参数innodb_flush_log_at_trx_commit.
mysql> SHOW VARIABLES LIKE 'innodb_flush_log_at_trx_commit';
+--------------------------------+-------+
| Variable_name | Value |
+--------------------------------+-------+
| innodb_flush_log_at_trx_commit | 1 |
+--------------------------------+-------+
[1] innodb_flush_log_at_trx_commit默认为1,表示事务提交时立即将事务涉及的log buffer刷盘,确保了事务的持久性;
[2] 0表示不主动刷盘,由后台线程异步刷盘(1s一次),如果数据库宕机会导致部分数据丢失;
[3] 2表示将输入拷贝到操作系统缓冲区,由操作系统刷盘; 数据库宕机不影响数据的持久性,但操作系统宕机会导致数据丢失。
本文后续以默认的刷盘机制(innodb_flush_log_at_trx_commit=1)进行介绍。
3.3 log buffer清理
在理解log buffer清理问题前,需要先理解两个变量: lsn和flushed_to_disk_lsn。
lsn是个全局变量,表示日志序列号(Log Sequeue Number),用于记录生成的redo日志量,从8704开始不断递增。由于redo日志是以mtr为单位写入log buffer的,所以整个mtr内的redo日志具有相同的lsn;不同的mtr具备不同的lsn, 且lsn越小对表示redo日志生成的越早。

如上图所示,mtr1对应的lsn是8704, mtr2对应的日志是8804(9704+100),下一个mtr的lsn对应8954(8804+150),后续lsn取决于上一个mtr的长度。
flushed_to_disk_lsn表示已被刷新到磁盘的lsn,即lsn小于flushed_to_disk_lsn的redo日志已经被刷入磁盘,这部分log buffer内存可被清理:

图中最左侧的log buffer区域可被清理和重复利用。当flushed_to_disk_lsn与LSN相同时,表示所有的redo日志已刷入磁盘。
说明:flushed_to_disk_lsn表示的是log buffer日志被刷入到磁盘,还有一个write_lsn表示记录刷到了操作系统缓存。
4.redo日志文件清理
前面已经介绍了redo日志写入log buffer以及log buffer刷入磁盘的过程。flushed_to_disk_lsn变量表示已经写到磁盘的redo日志量,lsn超出flushed_to_disk_lsn的redo日志可以从log buffer中被清理出。
本章需要思考对于已刷入磁盘的redo日志何时可以被清理。redo日志文件整体大小是固定的,且redo日志组会循环使用;因此需要一个合理的清理机制,并需要考虑两个问题:
[1] 确认哪些redo日志可以被清理,数据被清理后不能影响持久性功能;
[2] 何时清理,需要有足够的空间保障log buffer的redo日志记录可以被刷入redo日志文件。
flush链表和lsn
对于flush链表的介绍在[mysql系列6—Innodb的缓存]中已详细介绍。
修改数据库时,页的改动信息会以redo日志的形式记录下,然后将涉及的改动页对应的控制块添加到flush链表中,控制块之间形成双向链表。
flush链的控制块中保存了两个修改信息oldest_modification和newest_modification,分别表示第一次修改时的lsn和最近一次修改结束后的lsn.
使用第三章中的案例,从mysql启动后,分别执行了两个mtr, mtr1占据100字节,mtr2占据150字节:

假设mtr1修改了两个页面,两个页面对应的控制块分别为"控制块1"和"控制块2";mtr2修改了一个页面,页面控制块为"控制块3", 则flush链表可以表示为:

图中O_M表示oldest_modification, N_M表示newest_modification.
页面被修改时,页面对应的控制块会加入flush链的队列头部,oldest_modification记录下当时的lsn, newest_modification会记录所在mtr结束时的lsn; 当后续这个页面再次被修改时,仅修改newest_modification的值,oldest_modification和位置不会发生变化,即控制块是按照第一次修改的时间按从大到小的顺序排列的。
因此,位于队列尾部的控制块的oldest_modification是整个flush链中最小的lsn(后续用最小LSN表示).
另外,当脏页(修改过的数据页)被写入到磁盘后,数据页对应的控制块会从flush链中删除,因此redo日志文件中lsn小于**"最小LSN"可以被直接删除。
由此可以得出一个结论:判断redo日志文件中日志是否可被删除的条件是,脏页是否已经刷到磁盘了,即redo日志的lsn是否小于最小LSN**。
由于全局LSN根据写入log buffer的mtr大小进行递增,且log buffer与redo日志文件以log block为单位进行存储;因此可根据lsn计算出对应redo日志在文件组中的偏移量。
checkpoint
上一节提到了一个**“最小LSN"的概念,mysql使用checkpiont_lsn表示。刷新一次checkpiont_lsn的操作被称为一次chekpoint操作,会计算出当前系统的最小LSN并赋值给checkpiont_lsn:
[1] 取出redo文件组的第一个文件的管理信息, 得到较大的checkpoint_no和对应的checkpoint_lsn;
[2] 对checkpoint_no加1,并写入文件;
[3] 将当前"最小LSN”**赋值给checkpoint_lsn,并写入到文件中。
经历checkpoint后,redo日志文件中可被清理的部分会被标记出,清理操作由后台线程完成。
5.崩溃恢复
从崩溃中恢复是redo日志保证持久性的关键所在。数据库崩溃后,根据redo日志进行数据库恢复可分为三个步骤:确定恢复起点、确定恢复终点、执行恢复流程。
5.1 确认恢复起始点
章节1.2中介绍过,redo日志文件组中第一个文件的管理信息中在两个block都存储了checkpoint_no和checkpoint_lsn的信息。其中较大的checkpoint_lsn表示上一次checkpoint操作对应的lsn,即最小LSN.
由于lsn小于checkpoint_lsn的脏页已经被刷盘,可通过checkpoint_lsn可以计算出在redo日志组中的偏移量,使用该偏移量作为数据恢复的起点。

上图中控制块3表示未刷盘的最早被修改的页的控制块,其oldest_modification是最小的lsn, 用作数据恢复的起点。
5.2 确认恢复终点
章节1.2中介绍过每个log block的header存储了log_block_hdr_data_len属性,记录当前页使用的字节数。如果log_block_hdr_data_len等于512,说明当前页已满,小于512说明当前页未满,未满的block表示最新的数据。通过未满的block的log_block_hdr_no可计算出在redo日志组中的偏移量,作为数据恢复的终点。

上图中redo日志文件的第100个log block已满,而第101个未满,101最后一个redo日志的lsn作为日志恢复终点的lsn.
5.3 恢复流程
恢复的时候需要注意一个问题:checkpoint_lsn之前的redo日志对应的脏页已经刷入磁盘了,但checkpoint_lsn之后的可能已刷盘也可能没有,需要区分对待。
每个数据页都有一个File Header文件头,通过file_page_lsn属性记录了最近一次修改页面时的lsn值(对应flush链中的newest_modification)。在checkpoint之后刷入磁盘的脏页,file_page_lsn大于checkpoint_lsn;对于这部分数据页,恢复时直接跳过;file_page_lsn和数据页的内容可参考mysql系列5—Innodb的缓存。
通过redo日志组的恢复起点偏移量和终点偏移量可以得到一段redo日志,再根据file_page_lsn过滤掉一部分,得到一个redo日志数组。
这些redo日志数组可能涉及不同表空间的不同数据页的修改操作,如redo-1日志修改表空间1-数据页1,redo-2修改表空间100-数据页100,redo-3修改表空间1-数据页1,redo-4修改表空间100-数据页100,… 随机写的概率比较大,可根据(表空间ID, 数据页页号)通过哈希算法对redo日志进行映射分组,然后按照组依次执行,将随机IO转为多个连续IO从而提高系统效率。
相关文章:
mysql系列7—Innodb的redolog
背景 本文涉及的内容较为底层,做了解即可,是以前学习《高性能Mysql》和《mysql是怎样运行的》的笔记整理所得。 redolog(后续使用redo日志表示)的核心作用是保证数据库的持久性。 在mysql系列5—Innodb的缓存中介绍过:数据和索引保存在磁盘上…...

静态时序分析:线负载模型的选择机制
相关阅读 静态时序分析https://blog.csdn.net/weixin_45791458/category_12567571.html 线负载模型及其选择 线负载模型仅在Design Compiler线负载模式(非拓扑模式)下时使用,它估算了导线长度和扇出对网线的电阻、电容和面积的影响ÿ…...

git 中 工作目录 和 暂存区 的区别理解
比喻解释 可以把工作目录和暂存区想象成两个篮子: 工作目录是你把所有东西(文件和更改)扔进去的地方。你正在修改的东西都放在这里。暂存区则是你整理好的东西放进第二个篮子,准备提交给老板(提交到仓库)…...

C++ 变量:深入理解与应用
C 变量:深入理解与应用 一、引言 C作为一种强大且广泛应用的编程语言,变量是其程序设计的基础构建块之一。变量允许我们在程序中存储、操作和访问数据,对于实现各种复杂的功能至关重要。正确地理解和使用变量,能够编写出高效、可…...

http报头解析
http报文 http报文主要有两类是常见的,第一类是请求报文,第二类是响应报文,每个报头除了第一行,都是采用键值对进行传输数据,请求报文的第一行主要包括http方法(GET,PUT, POST&#…...

数据库的概念和操作
目录 1、数据库的概念和操作 1.1 物理数据库 1. SQL SERVER 2014的三种文件类型 2. 数据库文件组 1.2 逻辑数据库 2、数据库的操作 2.1 T-SQL的语法格式 2.2 创建数据库 2.3 修改数据库 2.4 删除数据库 3、数据库的附加和分离 1、数据库的概念和操作 1.1 物理数据库…...

《XML Schema 字符串数据类型》
《XML Schema 字符串数据类型》 1. 引言 XML Schema 是一种用于描述和验证 XML 文档结构和内容的语言。在 XML Schema 中,字符串数据类型是一种基本的数据类型,用于表示文本数据。本文将详细介绍 XML Schema 中的字符串数据类型,包括其定义…...

idea 开发Gradle 项目
在Mac上安装完Gradle后,可以在IntelliJ IDEA中配置并使用Gradle进行项目构建和管理。以下是详细的配置和使用指南: 1. 验证Gradle是否已安装 在终端运行以下命令,确保Gradle安装成功: gradle -v如果输出Gradle版本信息ÿ…...

Keepalived + LVS 搭建高可用负载均衡及支持 Websocket 长连接
一、项目概述 本教程旨在助力您搭建一个基于 Keepalived 和 LVS(Linux Virtual Server)的高可用负载均衡环境,同时使其完美适配 Websocket 长连接场景,确保您的 Web 应用能够高效、稳定地运行,从容应对高并发访问&…...

产品经理2025年展望
产品经理作为连接技术、设计与市场需求的桥梁,在快速变化的商业环境中扮演着至关重要的角色。展望2025年,随着技术的不断进步和消费者需求的日益多样化,产品经理的工作将面临更多挑战与机遇。 一、人工智能与自动化深化应用: 到…...

【信息系统项目管理师】第14章:项目沟通管理过程详解
更多内容请见: 备考信息系统项目管理师-专栏介绍和目录 文章目录 一、规划沟通管理1、输入2、工具与技术3、输出二、管理沟通1、输入2、工具与技术3、输出三、监督沟通1、输入2、工具与技术3、输出一、规划沟通管理 定义:规划沟通管理是基于每个干系人或干系人群体的信息需求…...

串口DMA接收数据基本思路
串口DMA接收基本思路 串口DMA接收数据基本思路一、串口处理使用背景及常用处理方法二、串口DMA接收相关思路三、串口DMA发送相关思路 串口DMA接收数据基本思路 一、串口处理使用背景及常用处理方法 单片机经常有串口处理大量数据的场景,常用的串口处理数据方式有如…...

数据结构复习 (二叉查找树,高度平衡树AVL)
1.二叉查找树: 为了更好的实现动态的查找(可以插入/删除),并且不超过logn的时间下达成目的 定义: 二叉查找树(亦称二叉搜索树、二叉排序树)是一棵二叉树,其各结点关键词互异,且中根序列按其关键词递增排列。 等价描述: 二叉查找…...

FreeSWITCH 简单图形化界面39 - Windows安装FreeSWITCH For IPPBX(WSL环境)
FreeSWITCH 简单图形化界面39 - Windows安装FreeSWITCH For IPPBX(WSL环境) 0、界面预览1、部署WSL1.1 安装WSL1.2 安装Windows Terminal1.3 安装WSL配置工具 2、安装Ubuntu24.043、安装FreeSWITCH4、登录Web4.1 80端口占用了 5、测试6、卸载 0、界面预览…...

uniapp - 小程序实现摄像头拍照 + 水印绘制 + 反转摄像头 + 拍之前显示时间+地点 + 图片上传到阿里云服务器
前言 uniapp,碰到新需求,反转摄像头,需要在打卡的时候对上传图片加上水印,拍照前就显示当前时间日期地点,拍摄后在呈现刚才拍摄的图加上水印,最好还需要将图片上传到阿里云。 声明 水印部分代码是借鉴的…...
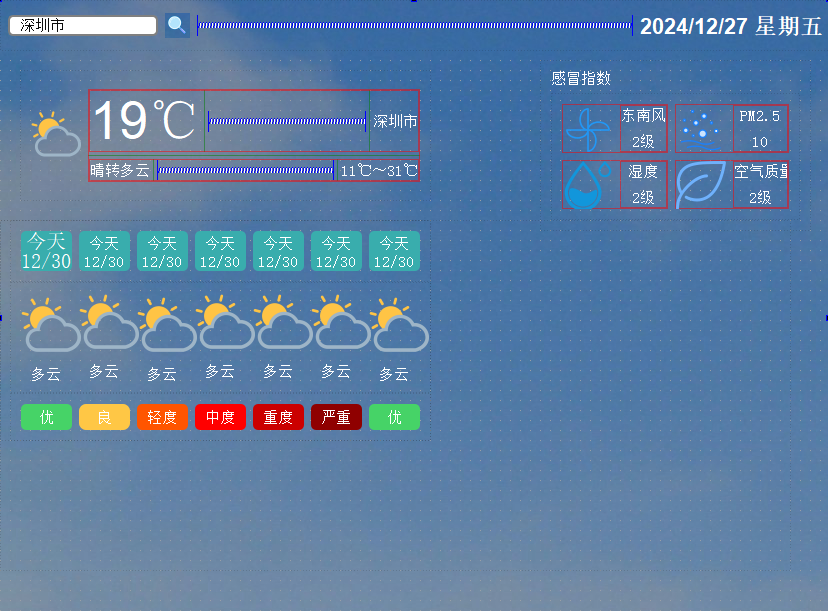
Qt天气预报系统设计界面布局第四部分左边
Qt天气预报系统设计 1、第四部分左边的第一部分1.1添加控件1.2修改控件名字 2、第四部分左边的第二部分2.1添加控件2.2修改控件名字 3、第四部分左边的第三部分3.1添加控件3.2修改控件名字 4、对整个widget04l调整 1、第四部分左边的第一部分 1.1添加控件 拖入一个widget&…...
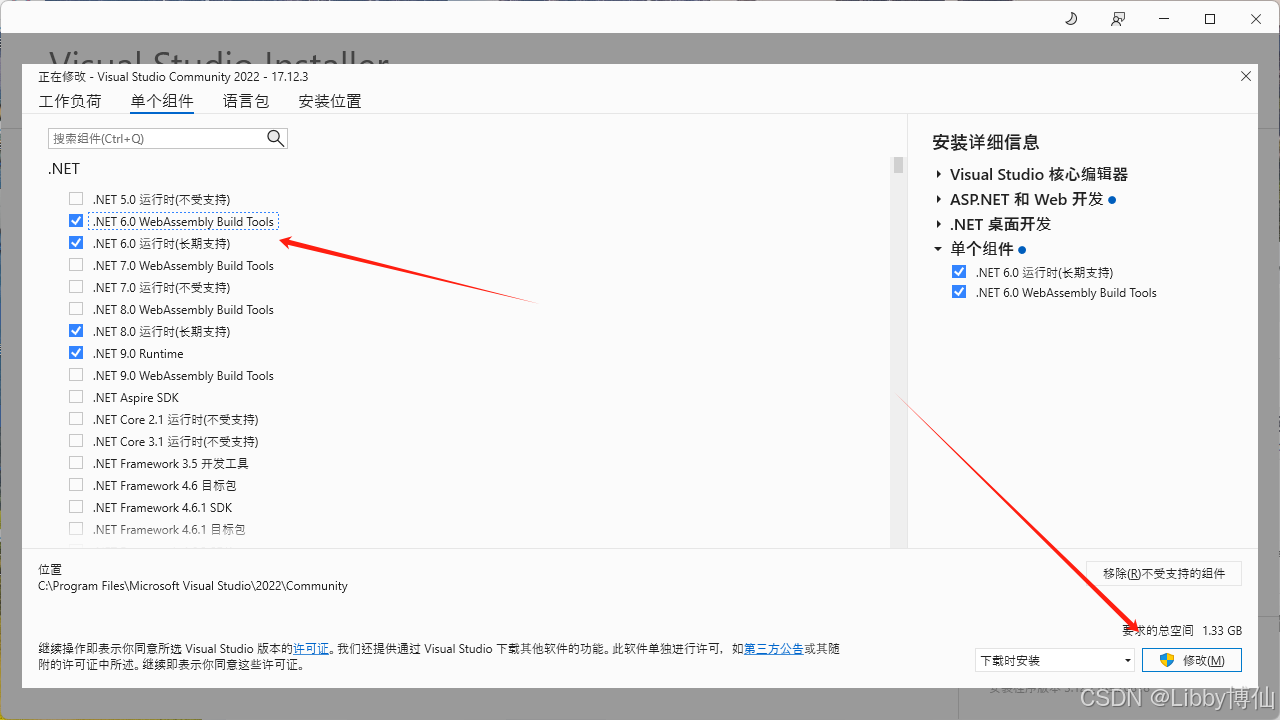
VS无法找到低版本的.net,vs2022创建不了.net6的项目
很多人会遇到安装完vs最新版(目前是2022)之后,创建不了旧版本的.net项目了,比如我在学习.net core 6,我的2022无法创建,只能创建.netcore8的项目,以及又安装了2019,同样无法创建,接下来介绍怎么…...

C++软件设计模式之解释器模式
解释器模式的目的和意图 解释器模式(Interpreter Pattern)是一种行为设计模式,主要用于定义一种语言的文法,并通过该文法解释语言中的句子(表达式)。解释器模式的核心思想是将一个特定的语言表示为其文法规…...
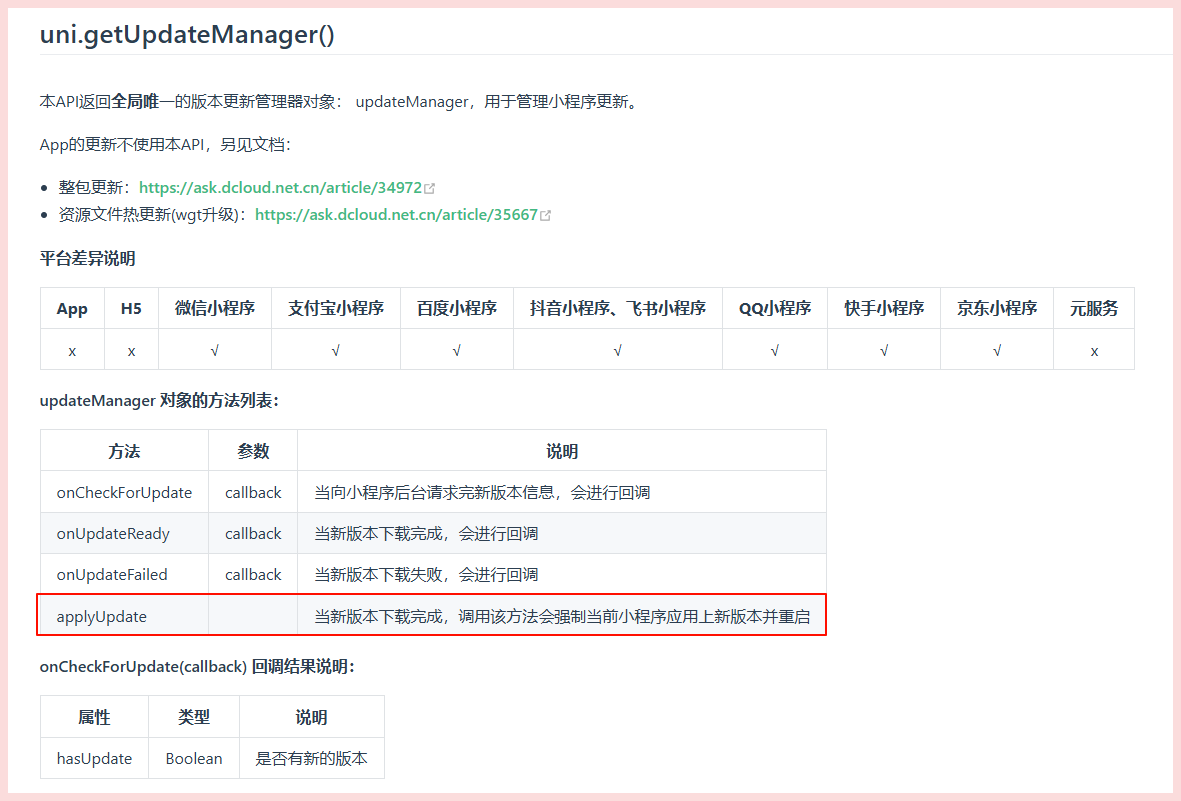
小程序发版后,用户使用时,强制更新为最新版本
为什么要强制更新为最新版本? 在小程序的开发和运营过程中,强制用户更新到最新版本是一项重要的策略,能够有效提升用户体验并保障系统的稳定性与安全性。以下是一些主要原因: 1. 功能兼容 新功能或服务通常需要最新版本的支持&…...
如何使用AI工具cursor(内置ChatGPT 4o+claude-3.5)
⚠️温馨提示: 禁止商业用途,请支持正版,充值使用,尊重知识产权! 免责声明: 1、本教程仅用于学习和研究使用,不得用于商业或非法行为。 2、请遵守Cursor的服务条款以及相关法律法规。 3、本…...
)
告别Python环境混乱!用virtualenv为每个项目创建独立开发空间(附常用命令速查表)
告别Python环境混乱!用virtualenv为每个项目创建独立开发空间(附常用命令速查表) 你是否经历过这样的场景:刚在项目A中完美运行的代码,迁移到项目B就报错;或是系统Python被意外升级导致所有项目崩溃&#x…...

麦当劳中国启动2026全国招聘周招募新生代人才
美通社消息:麦当劳中国正式启动2026年全国招聘周。今年,首批年满16周岁的10后将步入职场,与00后共同构成新生代主力军。在AI的变革时代,麦当劳以"有保障、有福利、有发展"的薪酬福利成长体系,以及长期、系统…...

程序员AI大模型转型:从入门到精通,轻松掌握大模型开发,高薪职位等你来拿!
在人工智能(AI)迅速发展的背景下,从传统的编程领域如Java程序员转向大模型开发是一个既充满挑战也充满机遇的过程。对于 Java 程序员来说,这也是一个实现职业转型、提升薪资待遇的绝佳机遇。 一、明确大模型概念 简单来说…...
:技能配置)
OpenClaw从入门到应用——工具(Tools):技能配置
通过OpenClaw实现副业收入:《OpenClaw赚钱实录:从“养龙虾“到可持续变现的实践指南》 所有与技能相关的配置都位于 ~/.openclaw/openclaw.json 中的 skills 字段下。 {skills: {allowBundled: ["gemini", "peekaboo"],load: {ext…...

ARM Trace Buffer架构与调试优化实践
1. ARM Trace Buffer架构解析Trace Buffer是ARM处理器中用于实时捕获指令执行轨迹的专用硬件模块,它通过独立的缓冲区和控制逻辑实现低开销的程序流监控。在ARMv8/v9架构中,Trace Buffer Extension(TRBE)作为可选的硬件扩展&#…...

枚举进阶:从常量集合到业务逻辑承载者的实战扩展技巧
1. 项目概述:从“能用”到“好用”的枚举进阶之路在软件开发中,枚举(Enum)是我们再熟悉不过的基础工具了。它把一组有限的、具名的常量组织在一起,让代码意图更清晰,避免“魔法数字”满天飞。但不知道你有没…...

UVM验证中的迭代模式:从寄存器遍历到配置组合的实战应用
1. 项目概述:为什么要在UVM中谈迭代模式?如果你做过芯片验证,尤其是用SystemVerilog和UVM搭过测试平台,那你肯定对“遍历”这个概念不陌生。比如,你需要检查一个存储阵列里每一个地址的读写是否正确,或者需…...

别再只称重了!用HX711和STM32做个简易气压计,成本不到50块
从称重到测压:HX711传感器的跨界应用实战指南 1. 重新认识HX711:不只是称重那么简单 在嵌入式开发领域,HX711常被视为称重传感器的标配芯片。但鲜为人知的是,这颗24位高精度ADC芯片的潜力远不止于此。通过简单的硬件改造和巧妙的系…...

Perplexity图标搜索效率提升300%:从零配置到精准获取的5步实战工作流
更多请点击: https://kaifayun.com 第一章:Perplexity图标资源搜索 在构建与 Perplexity AI 集成的前端应用或开发调试工具时,获取其官方图标资源是品牌一致性与用户体验的关键环节。Perplexity 官方未提供公开的图标下载中心,但…...

Kettle 9.3 下载安装全攻略:从官网变动的坑到Hadoop Shims的正确配置
Kettle 9.3 下载安装全攻略:从官网变动的坑到Hadoop Shims的正确配置 如果你最近尝试下载Kettle 9.3,可能会发现一个令人困惑的现象:按照老教程访问SourceForge上的Pentaho项目页面,却找不到熟悉的下载按钮。这不是你的问题&#…...