检索增强生成(RAG)

检索增强生成(Retrieval-Augmented Generation, RAG)是一种结合了检索机制和生成模型的先进技术,旨在提高自然语言处理系统的准确性和上下文相关性。本文将详细介绍如何从零开始构建一个RAG系统,包括数据处理、检索、生成以及部署等各个环节。
💢RAG系统的核心组件
一个完整的RAG系统通常由以下几个核心组件构成:
- 索引管道:负责数据的摄取和预处理,创建向量嵌入,并将其存储在快速访问的向量数据库中。
- 检索管道:根据用户的查询从已索引的数据库中检索最相关的信息,使用检索策略和重排序方法来优化结果。
- 生成管道:将检索到的数据与用户的查询结合,生成准确、相关且连贯的响应。
💢构建RAG系统的步骤
1. 数据摄取与预处理
在构建RAG系统之前,需要准备好用于训练和检索的数据。这通常包括以下步骤:
- 数据收集:选择合适的数据源,例如文档库、API或数据库,以确保信息的相关性和时效性。
- 数据清洗:去除冗余信息,处理缺失值,并确保数据格式一致,以便后续处理。
- 文本分块:将长文本分割成较小的块,以便于后续的嵌入和检索。
2. 向量嵌入生成
向量嵌入是RAG系统的基础,它将文本数据转换为数值表示,使得计算机能够理解其语义。可以使用以下方法生成嵌入:
- 选择嵌入模型:使用如BERT、SentenceTransformers等预训练模型来生成文本嵌入。根据应用场景,可以对模型进行微调以提高特定领域的准确性。
- 存储向量:将生成的向量存储在高性能向量数据库中,如Pinecone或Weaviate,以支持快速相似性搜索。
3. 检索过程
在用户提交查询后,RAG系统会执行以下步骤:
- 查询预处理:对用户输入进行清洗和标准化,例如去除停用词、词形还原等,以提高检索效果。
- 生成查询嵌入:将预处理后的查询转换为向量表示,以便与数据库中的文档进行比较。
- 执行检索:利用向量数据库执行相似性搜索,从中获取与用户查询最相关的文档片段。
4. 上下文整合与生成响应
一旦获得相关文档,RAG系统将执行以下操作:
- 上下文整合:将检索到的信息与用户查询结合,形成一个丰富的上下文提示,这一步骤对于生成准确响应至关重要。
- 调用生成模型:使用大模型(如GPT系列)来生成最终响应。此时,模型会依据整合后的信息生成更加准确且上下文相关的答案。
💥常用RAG工具
- Haystack
- Haystack是一个强大的开源框架,支持多种文档存储方案(如Elasticsearch、FAISS等),并与多种语言模型无缝集成。
- LangChain
- LangChain提供了一个灵活的框架,允许开发者快速构建和管理链式应用程序,适合用于RAG系统的构建。
- RAGFlow
- RAGFlow是一个用户友好的框架,专注于简化RAG应用程序的开发过程,适合初学者和有经验的开发者。
使用LangChain构建RAG演示
from langchain import hub
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_openai import ChatOpenAI# 加载文档并创建向量存储
loader = WebBaseLoader("https://example.com")
documents = loader.load()
vectorstore = Chroma.from_documents(documents)# 创建检索器
retriever = vectorstore.as_retriever(search_type="similarity", search_kwargs={"k": 5})# 创建生成模型
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)# 定义RAG链
def format_docs(docs):return "\n\n".join(doc.page_content for doc in docs)rag_chain = ({"context": retriever | format_docs, "question": "What is the role of Microsoft?"}| llm
)
response = rag_chain.invoke("What does Microsoft do?")
print(response)
💫构建一个简单的问答系统
pip install langchain openai创建知识库
创建一个简单的知识库,包含一些常见问题及其对应答案。可以使用Python字典来存储这些信息:
knowledge_base = {"What is LangChain?": "LangChain is an open-source framework for developing applications powered by large language models.","What is the capital of France?": "The capital of France is Paris.","Who is the CEO of OpenAI?": "As of 2023, Sam Altman is the CEO of OpenAI."
}
创建提示模板
接下来,我们创建一个提示模板,用于格式化用户输入并生成查询:
from langchain import PromptTemplatetemplate = "Answer the following question based on the knowledge base: {question}"
prompt = PromptTemplate(template=template, input_variables=["question"])
创建大型模型实例
import os
from langchain.llms import OpenAIos.environ["OPENAI_API_KEY"] = "*******" # 替换为自己的API密钥
llm = OpenAI(model_name="gpt-3.5-turbo")
创建问答链
创建一个问答链,将提示和语言模型结合起来:
from langchain.chains import LLMChain# 创建问答链
qa_chain = LLMChain(llm=llm, prompt=prompt)
实现查询功能
def answer_question(question):# 检查知识库中是否有答案if question in knowledge_base:answer = knowledge_base[question]else:answer = "I'm sorry, I don't know the answer to that question."# 使用LLM生成回答result = qa_chain.run(question)return result
🍺测试:
if __name__ == "__main__":user_question = input("Please ask a question: ")response = answer_question(user_question)print(response)
相关文章:
检索增强生成(RAG)
检索增强生成(Retrieval-Augmented Generation, RAG)是一种结合了检索机制和生成模型的先进技术,旨在提高自然语言处理系统的准确性和上下文相关性。本文将详细介绍如何从零开始构建一个RAG系统,包括数据处理、检索、生成以及部署…...
【第二部分--Python之基础】03 容器类型的数据
Python内置的数据类型如序列(列表、元组等)、集合和字典等可以容纳多项数据,我们称它们为容器类型的数据。 序列 序列(sequence)是一种可迭代的、元素有序的容器类型的数据。 序列包括列表(listÿ…...
、循环神经网络(RNN)、生成对抗网络(GAN)等概念及原理)
【人工智能机器学习基础篇】——深入详解深度学习之复杂网络结构:卷积神经网络(CNN)、循环神经网络(RNN)、生成对抗网络(GAN)等概念及原理
深入详解深度学习之复杂网络结构:卷积神经网络(CNN)、循环神经网络(RNN)、生成对抗网络(GAN) 深度学习作为人工智能的重要分支,通过复杂的网络结构实现对数据的高级抽象和理解。本文…...

MySQL 入门教程
MySQL是最流行的关系型数据库管理系统,在WEB应用方面MySQL是最好的RDBMS(Relational Database Management System:关系数据库管理系统)应用软件之一。 在本教程中,会让大家快速掌握MySQL的基本知识,并轻松使用MySQL数据库。 什么…...
)实现一对多对象json输出)
【sql】CAST(GROUP_CONCAT())实现一对多对象json输出
数据库:mysql 5.7版本以上 问题:一对多数据,实现输出一条数据,并将多条数据转换成json对象输出,可以实现一对多个字段。 项目中关系较为复杂,以下简化数据关系如下: t1是数据表,t…...

QT:控件属性及常用控件(1)------核心控件及属性
一个图形化界面上的内容,不需要我们直接从零去实现 QT中已经提供了很多的内置控件: 按钮,文本框,单选按钮,复选按钮,下拉框等等。。。。。 文章目录 1.常用控件属性1.1 enabled1.2 geometry1.2.1 geometry…...

使用 Python结合ffmpeg 实现单线程和多线程推流
一、引言 在本文中,我们将详细介绍如何使用 Python 进行视频的推流操作。我们将通过两个不同的实现方式,即单线程推流和多线程推流,来展示如何利用 cv2(OpenCV)和 subprocess 等库将视频帧推送到指定的 RTMP 地址。这…...
Linux一些问题
修改YUM源 Centos7将yum源更换为国内源保姆级教程_centos使用中科大源-CSDN博客 直接安装包,走链接也行 Index of /7.9.2009/os/x86_64/Packages 直接复制里面的安装包链接,在命令行直接 yum install https://vault.centos.org/7.9.2009/os/x86_64/Pa…...

在 Ubuntu 24.04.1 LTS | Python 3.12 环境下部署 Crypto 库
测试一些密码学方案需要用到 Crypto 库,网上教程大多针对 Windows 和 Python 3.10 或以下的环境,所以写下了这篇博文。 部署与使用 首先执行 su 输入密码进入超级用户,部署完 Python 3.12 环境后,执行以下命令进行安装ÿ…...

HTML5实现好看的二十四节气网页源码
HTML5实现好看的新年春节元旦网站源码 前言一、设计来源1.1 主界面1.2 关于我们界面1.3 春季节气界面1.4 夏季节气界面1.5 秋季节气界面1.6 冬季节气界面 二、效果和源码2.1 动态效果2.2 源代码 源码下载结束语 HTML5实现好看的二十四节气网页源码,春季节气…...
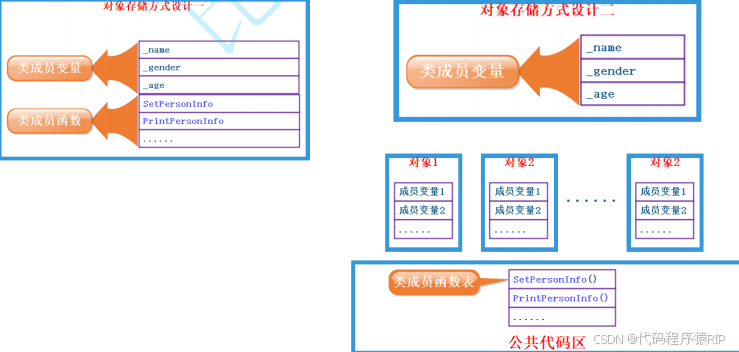
C++(9)—类和对象(上) ②实例化
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、实例化概念二、对象大小 1.对象存储2.内存对齐规则总结 前言 提示:以下是本篇文章正文内容,下面案例可供参考 一、实例化概念 • …...
)
Effective C++读书笔记——item2(const,enum,inlines取代#define)
关于用常量取代 #define 的总体原则 在编程中,应尽量减少预处理器(特别是 #define)的使用,可通过合适的替代方式来避免 #define 带来的诸多问题,虽然不能完全消除预处理器相关指令(如 #include、#ifdef/#i…...

如何科学评估与选择新版本 Python 编程语言和工具
文章目录 摘要引言评估新版本的关键因素适用性评估成本与收益分析 新版本功能的实际应用示例代码模块详细解析示例代码模块代码模块解析实际应用场景如何运行与配图 QA环节总结参考资料 摘要 随着技术的快速发展,编程语言和软件工具不断推出新版本,带来…...

第十届“挑战杯”大学生课外学术科技作品竞赛解析及资料
“挑战杯”被誉为大学生科技创新创业的“奥林匹克”盛会,它汇聚了来自各个学科、各个年级的精英人才。在这里,同学们带着对未知的好奇和对知识的渴望,组成一个个团队,向难题发起挑战。现在,第十届“挑战杯”大学生课外…...

【门铃工作原理】2021-12-25
缘由关于#门铃工作原理#的问题,如何解决?-嵌入式-CSDN问答 4 RST(复位)当此引脚接高电平时定时器工作,当此引脚接地时芯片复位,输出低电平。 按钮按下给电容器充电并相当与短路了R1改变了频率,按…...

Chain of Agents(COA):大型语言模型在长文本任务中的协作新范式
随着人工智能技术的飞速发展,大型语言模型(LLM)在自然语言处理领域的应用日益广泛。然而,LLM在处理长文本任务时仍面临诸多挑战。传统的解决方案,如截断输入上下文或使用基于检索增强生成(RAG)的…...

业务模型与UI设计
业务数据模型的设计、UI设计这应该是程序设计中不可缺少的部分。做程序设计的前提应该先把这两块设计好,那么,来一个实际案例,看看这2块的内容。 汽车保养记录业务模型与UI设计: 一、【车辆清单】 记录车辆相关的数据࿰…...

Apache SeaTunnel深度优化:CSV字段分割能力的增强
Apache SeaTunnel深度优化:CSV字段分割能力的增强 一、Apache SeaTunnel与CSV处理 1.1 Apache SeaTunnel简介 Apache SeaTunnel(原名Waterdrop)是一个分布式、高性能的数据集成平台,支持海量数据的实时同步。它允许用户通过配置…...

免费下载 | 2024年具身大模型关键技术与应用报告
这份报告的核心内容涉及具身智能的关键技术与应用,主要包括以下几个方面: 具身智能的定义与重要性: 具身智能是基于物理身体进行感知和行动的智能系统,通过与环境的交互获取信息、理解问题、做出决策并实现行动,产生智…...

SSM-Spring-AOP
目录 1 AOP实现步骤(以前打印当前系统的时间为例) 2 AOP工作流程 3 AOP核心概念 4 AOP配置管理 4-1 AOP切入点表达式 4-1-1 语法格式 4-1-2 通配符 4-2 AOP通知类型 五种通知类型 AOP通知获取数据 获取参数 获取返回值 获取异常 总结 5 …...

大模型长对话记忆难题:LightMem轻量记忆系统原理与实战
1. 项目概述:当大模型遇上“记忆”瓶颈 最近在折腾大语言模型应用时,我遇到了一个挺典型的问题:想让模型记住更多、更长的对话历史,但无论是直接增加上下文窗口,还是用传统的向量数据库做检索增强,都感觉差…...

别再替换同义词!2026实测论文降AIGC工具:一次降至10%以下的排版保护指南
自从央视公开探讨初稿写作的AI味儿现象:据相关数据显示,近六成师生习惯使用生成式辅助,其中近三成学生将其用于核心初稿的撰写,各高校针对AIGC的审查便日益严格。 正是因为这种大背景,四月一到,定稿通知刚…...

终极指南:如何用Snipe-IT免费开源系统解决企业IT资产追踪难题
终极指南:如何用Snipe-IT免费开源系统解决企业IT资产追踪难题 【免费下载链接】snipe-it A free open source IT asset/license management system 项目地址: https://gitcode.com/GitHub_Trending/sn/snipe-it 想象一下,你的公司有500台笔记本电…...

通过环境变量管理多个 Taotoken API Key 以实现访问控制
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过环境变量管理多个 Taotoken API Key 以实现访问控制 在开发过程中,我们常常需要为不同的应用、不同的环境…...

DDrawCompat:如何在现代Windows上为经典DirectX游戏注入新生命?
DDrawCompat:如何在现代Windows上为经典DirectX游戏注入新生命? 【免费下载链接】DDrawCompat DirectDraw and Direct3D 1-7 compatibility, performance and visual enhancements for Windows Vista, 7, 8, 10 and 11 项目地址: https://gitcode.com/…...

从无监督到半监督:利用scVI与scANVI在Python中实现单细胞数据的精准批次整合
1. 单细胞数据批次整合的挑战与解决方案 单细胞RNA测序技术(scRNA-seq)已经成为研究细胞异质性的重要工具。但在实际研究中,我们常常会遇到一个棘手的问题:不同实验批次之间的技术变异。这种批次效应就像是在显微镜镜头上蒙了一层…...

TortoiseGit重置与还原功能详解:除了‘后悔药’,还能当‘时光机’和‘后悔药解药’?
TortoiseGit重置与还原功能深度解析:从版本控制到历史重构的艺术 在代码开发的漫长旅途中,每个开发者都曾有过"如果当时..."的瞬间。与大多数版本控制系统不同,Git提供的不仅是一个简单的"撤销"按钮,而是一套…...

5个技巧快速掌握Happy Island Designer:免费在线岛屿设计工具终极指南
5个技巧快速掌握Happy Island Designer:免费在线岛屿设计工具终极指南 【免费下载链接】HappyIslandDesigner "Happy Island Designer (Alpha)",是一个在线工具,它允许用户设计和定制自己的岛屿。这个工具是受游戏《动物森友会》(A…...

为什么MASA全家桶汉化包能彻底改变你的Minecraft模组体验?
为什么MASA全家桶汉化包能彻底改变你的Minecraft模组体验? 【免费下载链接】masa-mods-chinese 一个masa mods的汉化资源包 项目地址: https://gitcode.com/gh_mirrors/ma/masa-mods-chinese 还在为MASA模组复杂的英文界面而头疼吗?作为中文Minec…...

HiveWE魔兽地图编辑器:5分钟快速上手指南,告别卡顿创作新时代
HiveWE魔兽地图编辑器:5分钟快速上手指南,告别卡顿创作新时代 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为《魔兽争霸III》原版地图编辑器缓慢的加载速度和繁琐的操作而烦恼…...