Apache SeaTunnel深度优化:CSV字段分割能力的增强
Apache SeaTunnel深度优化:CSV字段分割能力的增强
一、Apache SeaTunnel与CSV处理
1.1 Apache SeaTunnel简介
Apache SeaTunnel(原名Waterdrop)是一个分布式、高性能的数据集成平台,支持海量数据的实时同步。它允许用户通过配置文件来描述数据流,从而实现数据从一个源到另一个目的地的传输和转换。
1.2 CSV文件处理的重要性
CSV(逗号分隔值)文件是一种常见的数据交换格式。在数据集成任务中,经常需要读取CSV文件,将其内容转换为结构化数据,然后进行进一步的处理和分析。因此,增强CSV文件的读取和字段分割能力对于Apache SeaTunnel来说至关重要。
二、CSV字段分割的技术挑战
2.1 字段分割的复杂性
CSV文件的字段可能包含逗号、换行符或其他特殊字符,这使得字段分割成为一个复杂的问题。此外,字段可能被引号包围,使得字段内部的逗号不再是字段分隔符。
2.2 分割策略的选择
为了准确地分割CSV字段,需要选择合适的分割策略。这包括确定字段分隔符、引号字符以及转义规则。Apache SeaTunnel通过配置来灵活定义这些规则,以适应不同的CSV文件格式。
三、Apache SeaTunnel的CSV读取增强
3.1 分割字段的实现
Apache SeaTunnel通过CsvDeserializationSchema类来实现CSV文件的读取和字段分割。这个类允许用户自定义分隔符、日期格式化器等,以适应不同的CSV格式。
public class CsvDeserializationSchema {private SeaTunnelRowType seaTunnelRowType;private String[] separators;private DateUtils.Formatter dateFormatter;private DateTimeUtils.Formatter dateTimeFormatter;private TimeUtils.Formatter timeFormatter;public static Builder builder() {return new Builder();}public SeaTunnelRow deserialize(byte[] message) throws IOException {String content = new String(message);ObjectMapper objectMapper = new ObjectMapper();Map<Integer, String> splitsMap = objectMapper.readValue(content, getTypeReference());Object[] objects = new Object[seaTunnelRowType.getTotalFields()];for (int i = 0; i < objects.length; i++) {objects[i] = convert(splitsMap.get(i), seaTunnelRowType.getFieldType(i), 0);}return new SeaTunnelRow(objects);}private Map<Integer, String> splitLineBySeaTunnelRowType(String line, SeaTunnelRowType seaTunnelRowType, int level) {String[] splits = splitLineWithCsvMethod(line, separators[level].charAt(0));LinkedHashMap<Integer, String> splitsMap = new LinkedHashMap<>();SeaTunnelDataType<?>[] fieldTypes = seaTunnelRowType.getFieldTypes();for (int i = 0; i < splits.length; i++) {splitsMap.put(i, splits[i]);}if (fieldTypes.length > splits.length) {for (int i = splits.length; i < fieldTypes.length; i++) {splitsMap.put(i, null);}}return splitsMap;}private String[] splitLineWithCsvMethod(String line, char sep) {CSVParser csvParser = new CSVParserBuilder().withSeparator(sep).build();try (CSVReader reader = new CSVReaderBuilder(new StringReader(line)).withCSVParser(csvParser).build()) {Iterator<String[]> iterator = reader.iterator();if (iterator.hasNext()) {return iterator.next();}return new String[0];} catch (Exception e) {return new String[]{line};}}
}3.2 配置灵活性
用户可以通过Builder模式灵活配置CSV读取器,包括设置字段分隔符、日期和时间格式化器等。
public class CsvDeserializationSchema.Builder {private SeaTunnelRowType seaTunnelRowType;private String[] separators = new String[]{","}; // 默认逗号分隔private DateUtils.Formatter dateFormatter;private DateTimeUtils.Formatter dateTimeFormatter;private TimeUtils.Formatter timeFormatter;public Builder seaTunnelRowType(SeaTunnelRowType seaTunnelRowType) {this.seaTunnelRowType = seaTunnelRowType;return this;}public Builder delimiter(String delimiter) {this.separators[0] = delimiter;return this;}public Builder separators(String[] separators) {this.separators = separators;return this;}public Builder dateFormatter(DateUtils.Formatter dateFormatter) {this.dateFormatter = dateFormatter;return this;}public Builder dateTimeFormatter(DateTimeUtils.Formatter dateTimeFormatter) {this.dateTimeFormatter = dateTimeFormatter;return this;}public Builder timeFormatter(TimeUtils.Formatter timeFormatter) {this.timeFormatter = timeFormatter;return this;}public CsvDeserializationSchema build() {return new CsvDeserializationSchema(seaTunnelRowType, separators, dateFormatter, dateTimeFormatter, timeFormatter);}
}四、性能优化与最佳实践
4.1 并行处理
对于大型CSV文件,Apache SeaTunnel可以利用并行处理来提高读取效率。通过将文件分割成多个部分并行处理,可以显著减少处理时间。
4.2 内存管理
在读取和解析CSV文件时,需要注意内存的使用。Apache SeaTunnel通过优化数据结构和减少不必要的对象创建,有效地管理内存使用。
4.3 I/O优化
使用NIO(New I/O)库进行文件读取,可以进一步提高I/O效率。Apache SeaTunnel可以配置为使用NIO来处理文件I/O,从而提高性能。
五、总结
Apache SeaTunnel通过增强对CSV文件的读取和字段分割能力,提供了一个灵活且高效的数据集成解决方案。通过自定义分隔符、格式化器等配置,用户可以轻松适应不同的CSV文件格式。此外,性能优化措施如并行处理、内存管理和I/O优化,使得Apache SeaTunnel能够高效地处理大规模数据集。这些增强功能不仅提升了数据处理的性能,也扩展了Apache SeaTunnel在各种数据集成场景中的应用范围。
相关文章:

Apache SeaTunnel深度优化:CSV字段分割能力的增强
Apache SeaTunnel深度优化:CSV字段分割能力的增强 一、Apache SeaTunnel与CSV处理 1.1 Apache SeaTunnel简介 Apache SeaTunnel(原名Waterdrop)是一个分布式、高性能的数据集成平台,支持海量数据的实时同步。它允许用户通过配置…...

免费下载 | 2024年具身大模型关键技术与应用报告
这份报告的核心内容涉及具身智能的关键技术与应用,主要包括以下几个方面: 具身智能的定义与重要性: 具身智能是基于物理身体进行感知和行动的智能系统,通过与环境的交互获取信息、理解问题、做出决策并实现行动,产生智…...

SSM-Spring-AOP
目录 1 AOP实现步骤(以前打印当前系统的时间为例) 2 AOP工作流程 3 AOP核心概念 4 AOP配置管理 4-1 AOP切入点表达式 4-1-1 语法格式 4-1-2 通配符 4-2 AOP通知类型 五种通知类型 AOP通知获取数据 获取参数 获取返回值 获取异常 总结 5 …...

jenkins修改端口以及开机自启
修改Jenkins端口 方式一:通过配置文件修改(以CentOS为例) 找到配置文件:在CentOS系统中,通常可以在/etc/sysconfig/jenkins文件中修改Jenkins的配置。如果没有这个文件,也可以查看/etc/default/jenkins&…...

按照人们阅读Excel习惯来格式化BigDecimal
1、环境/问题描述 使用springboot发送邮件(附件)的方式将月度报表发送给领导查阅,数据是准确的,领导基本满意。 就是对一些数字的格式化提出了改进建议,比如不要让大数字自动转为科学计数法、浮点数小数点后都是0就不要带出来,根…...

IDEA开发Java应用的初始化设置
一、插件安装 如下图所示: 1、Alibaba Java Coding Guidelines 2.1.1 阿里开发者规范,可以帮忙本地自动扫描出不符合开发者规范的代码,甚至是代码漏洞提示。 右击项目,选择《编码规约扫描》,可以进行本地代码规范扫…...

Java网络套接字
在Java的开发中,有一个很重要!很重要!很重要!的东西,叫做网络套接字,它被广泛的用来二次开发服务,比如大数据中台的服务链路调用等。 它的实现原理是依靠三次握手来完成通信的建立,…...

2025差旅平台推荐:一体化降本30%
医药行业因其高度专业化的特点,同时在运营过程中又极为依赖供应链和销售网络,因此差旅管理往往成为成本控制的重要环节。本期,我们以差旅平台分贝通签约伙伴——某知名药企为例,探讨企业如何通过差旅一体化管理,在全流…...

多个DataV遍历生成
DataV是数据可视化工具 与Echart类似 相对Echart图标边框 装饰可选官网DataV 安装 npm install kjgl77/datav-vue3main.ts import DataVVue3 from kjgl77/datav-vue3 app.use(DataVVue3)多个DataV遍历生成 Vue3viteDataV为例:<template><div w50rem h25rem flex&qu…...

mysql_real_connect的概念和使用案例
mysql_real_connect 是 MySQL C API 中的一个函数,用于建立一个到 MySQL 数据库服务器的连接。这个函数尝试建立一个连接,并根据提供的参数进行连接设置。 概念 以下是 mysql_real_connect 函数的基本概念: 函数原型:MYSQL *my…...

Python性能分析深度解析:从`cProfile`到`line_profiler`的优化之路
《Python OpenCV从菜鸟到高手》带你进入图像处理与计算机视觉的大门! 解锁Python编程的无限可能:《奇妙的Python》带你漫游代码世界 在软件开发过程中,性能优化是提升应用质量和用户体验的关键环节。Python作为广泛应用的高级编程语言,其性能分析工具为开发者提供了强大的…...

Momentum Contrast for Unsupervised Visual Representation Learning论文笔记
文章目录 论文地址动量队列对比学习的infoNCE loss为什么需要动量编码器对比学习moco方法中的动量Encoder为什么不能与梯度Encoder完全相同为什么动量编码器和梯度编码器不能完全相同?总结: 我理解,正负样本应该经过同一个encoder,…...

用户界面的UML建模07
4.2 抽象表示层的行为(Abstract Presentation Behaviour) AbstractForm 类定义了一组如下所示的四种操作: showForm() , getData() , sendConfirmation() 和sendCancellation()。在该阶段的设计过程(desig…...

Node.js中使用Joi 和 express-joi-validation进行数据验证和校验
在进行项目开发的过程中,很多时候系统对用户输入的数据会进行严格校验的,通常我们会以“前端校验为辅,后端校验为主”的思想进行校验处理。 后端接口校验的时候,是只能一直使用if进行逻辑判断呢,还是有更加方便的方法…...

InstructGPT:基于人类反馈训练语言模型遵从指令的能力
大家读完觉得有意义记得关注和点赞!!! 大模型进化树,可以看到 InstructGPT 所处的年代和位置。来自 大语言模型(LLM)综述与实用指南(Amazon,2023) 目录 摘要 1 引言 …...

jrc水体分类对水体二值掩码修正
使用deepwatermap生成的水体二值掩码中有部分区域由于被云挡住无法识别,造成水体不连续是使用jrc离线数据进行修正,jrc数据下载连接如下:https://global-surface-water.appspot.com/download 选择指定区域的数据集合下载如图: 使…...
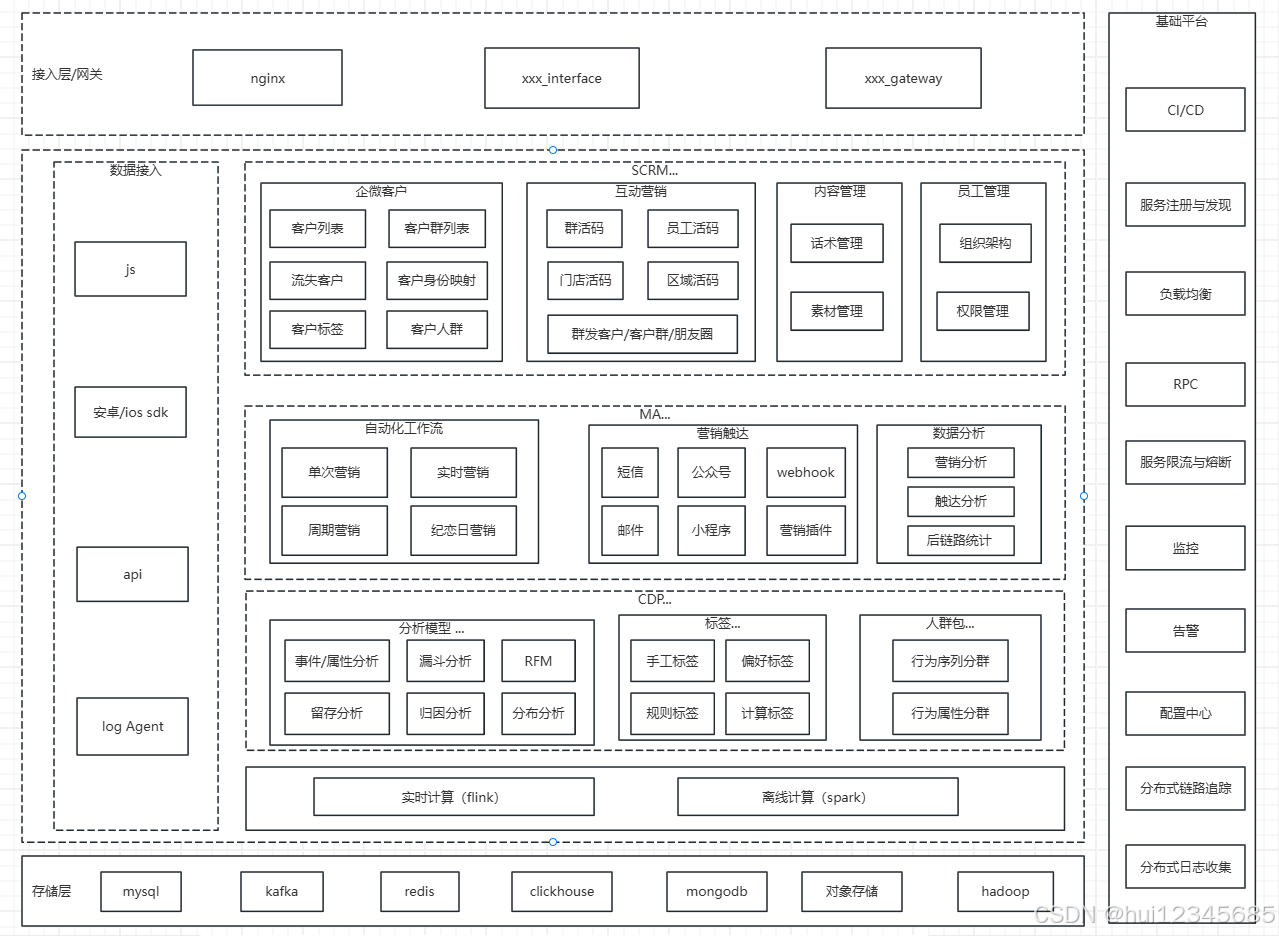
营销/CDP/MA/SCRM
最近几年面向企业用户的营销系统,cdp,ma,scrm等发展迅速,下面就简单介绍一下这些系统。 架构图 架构图中显示了CDP,MA,SCRM的核心功能,其实还有基础底座的功能。 比如统一登录,权限…...

免费CDN加速,零成本提升网站速度!
1. 起因 免备案的服务器要么在海外,要么是国内通过内网穿透才能访问,这两种方法好处是免费,坏处是延迟太高,有的地区延迟能到四五百甚至超时,这样明显是不行的。 所以需套一个cdn来加速,在2024年࿰…...

2024-12-29-sklearn学习(25)无监督学习-神经网络模型(无监督) 烟笼寒水月笼沙,夜泊秦淮近酒家。
文章目录 sklearn学习(25) 无监督学习-神经网络模型(无监督)25.1 限制波尔兹曼机25.1.1 图形模型和参数化25.1.2 伯努利限制玻尔兹曼机25.1.3 随机最大似然学习 sklearn学习(25) 无监督学习-神经网络模型(无监督) 文章参考网站&a…...

RSA e与phi不互质(AMM算法进行有限域开根)
e与phi不互质 这一部分学习来自trup师傅的博客 针对CTFer的e与phi不互素的问题 - 跳跳糖 1:m^t<n from Crypto.Util.number import * from secret import flag flag bflag{*********} m bytes_to_long(flag) p getPrime(1024) q getPrime(1024) n p * q …...

【无人机路径规划】基于K-means 聚类和遗传算法实现多架无人机任务区域进行划分,并优化各区域内的访问路径附matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、程序设计科研仿真。🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室👇 关注我领取海量matlab电子书和数学建模资料 dz…...

免费开源AMD Ryzen处理器调试工具:5分钟掌握SMUDebugTool终极指南
免费开源AMD Ryzen处理器调试工具:5分钟掌握SMUDebugTool终极指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址:…...

Grasscutter命令生成器终极指南:如何5分钟上手原神私服管理
Grasscutter命令生成器终极指南:如何5分钟上手原神私服管理 【免费下载链接】GrasscutterCommandGenerator Command Generator and Gacha Banner Editor 项目地址: https://gitcode.com/gh_mirrors/gr/GrasscutterCommandGenerator Grasscutter命令生成器是一…...

毫秒算网的光通信技术——从“东数西算“到“毫秒用算“
引言:从"算力在哪"到"算力怎么到" 2021年启动的"东数西算"工程回答了一个根本问题:算力应该布局在哪里。通过在西部建设8大枢纽、10大集群,国家将算力基础设施与绿色能源禀赋深度耦合,开启了算力地…...

Claude技能库开发指南:工具调用原理与模块化实践
1. 项目概述:一个为Claude模型量身定制的技能库最近在探索如何让Claude这类大型语言模型更好地融入我的日常工作流时,我遇到了一个非常有意思的项目——DhanushNehru/claude-skills。简单来说,这是一个专门为Anthropic的Claude模型设计的“技…...

Linux驱动调试利器:debugfs接口设计与实现详解
1. 项目概述:为什么我们需要debugfs?在Linux内核驱动的开发与调试过程中,我们常常面临一个核心痛点:如何在不重启系统、不重新编译驱动、甚至不借助复杂外部工具的情况下,实时地窥探驱动内部的状态、修改关键参数&…...

SMARC嵌入式模块规范解析:从标准化接口到硬件设计实战
1. 项目概述:从“黑盒子”到标准化接口的进化在嵌入式系统开发领域,尤其是工业控制、边缘计算和物联网设备中,我们经常会遇到一个核心矛盾:如何平衡设计的灵活性与开发效率?早些年,很多项目都是从零开始&am…...

在Windows上安装安卓应用的终极指南:告别模拟器,享受原生体验
在Windows上安装安卓应用的终极指南:告别模拟器,享受原生体验 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾梦想在Windows电脑上直接…...

从碎片到体系:如何用Obsidian Weread插件打造你的个人读书知识库
从碎片到体系:如何用Obsidian Weread插件打造你的个人读书知识库 【免费下载链接】obsidian-weread-plugin Obsidian Weread Plugin is a plugin to sync Weread(微信读书) hightlights and annotations into your Obsidian Vault. 项目地址: https://gitcode.com…...

Obsidian笔记AI化:AnythingLLM带来的知识管理革新
Obsidian笔记AI化:AnythingLLM带来的知识管理革新 【免费下载链接】anything-llm The all-in-one AI productivity accelerator. On device and privacy first with no annoying setup or configuration. 项目地址: https://gitcode.com/GitHub_Trending/an/anyth…...