Momentum Contrast for Unsupervised Visual Representation Learning论文笔记
文章目录
- 论文地址
- 动量队列
- 对比学习的infoNCE loss
- 为什么需要动量编码器
- 对比学习moco方法中的动量Encoder为什么不能与梯度Encoder完全相同
- 为什么动量编码器和梯度编码器不能完全相同?
- 总结:
- 我理解,正负样本应该经过同一个encoder,才能进行损失计算。为什么moco中正负样本可以经过两个不同的encoder
- 为什么 MoCo 中正负样本可以通过两个不同的编码器处理?
- 1. **动量编码器和梯度编码器的不同作用**:
- 2. **为什么正负样本可以通过不同的编码器?**
- 3. **如何保证正负样本的关系不受影响?**
- 4. **总结:**
- 我理解是因为同一批次中,正样本与其他的负样本差异很大,即使MoCo的动量编码器的参数落后于梯度编码器,他们的表征依然可以被学习
- 关键点总结:
- 为什么需要动量更新的平滑效果?如果动量编码器的更新不平滑,会导致什么后果
- 1. **动量更新的平滑效果的作用**
- 平滑更新的好处:
- 2. **如果动量编码器的更新不平滑,会带来什么后果?**
- 1. **负样本表示的剧烈波动**
- 2. **对比损失的计算不稳定**
- 3. **梯度编码器和动量编码器之间的协调性差**
- 4. **学习目标的迷失**
- 3. **总结:动量更新平滑的必要性**
- 如果动量编码器频繁更新会使训练不稳定,那么梯度编码器频繁更新为什么不会使训练不稳定?
- 1. **梯度编码器的更新机制**
- 2. **动量编码器的特殊性**
- 3. **为什么梯度编码器频繁更新不影响稳定性?**
- 4. **动量编码器频繁更新为什么会导致不稳定?**
- 5. **总结**
- 实验结果
论文地址
MOCO V1
MOCO V2
动量队列


对比学习的infoNCE loss

为什么需要动量编码器

从论文的描述看,主要是两个原因:
- 不使用动量编码器,直接复制 f q f_q fq,实验效果不好
- f k f_k fk的快速变化将降低key表示的一致性,即队列中的key差异很大,因为生成他们的模型一直在快速变化。
对比学习moco方法中的动量Encoder为什么不能与梯度Encoder完全相同
在 对比学习(Contrastive Learning) 中,MoCo (Momentum Contrast) 是一种非常流行的方法,特别是在无监督学习中。MoCo 引入了动量编码器(Momentum Encoder)来更新目标表示,这与普通的梯度编码器(Gradient Encoder)有所不同。其背后的核心思想是利用动量编码器的稳定性来提升训练的效果,避免梯度编码器的更新过快,从而造成表示的震荡或不稳定。
为什么动量编码器和梯度编码器不能完全相同?
-
动量编码器的目标是稳定表示:
-
在 MoCo 中,动量编码器(Momentum Encoder) 是通过 动量更新规则 来更新的。与常规的梯度编码器(Gradient Encoder)不同,动量编码器不直接使用反向传播的梯度进行更新,而是采用一个指数衰减的方式,即:
θ k ← m ⋅ θ k + ( 1 − m ) ⋅ θ q \theta_k \leftarrow m \cdot \theta_k + (1 - m) \cdot \theta_q θk←m⋅θk+(1−m)⋅θq
其中, θ k \theta_k θk 是动量编码器的参数, θ q \theta_q θq 是当前的梯度编码器的参数, m m m 是动量系数(通常接近 1)。 -
原因:动量编码器的目的是保持一个稳定的表示,使得目标表示不会因为梯度编码器参数的频繁更新而发生剧烈的波动。由于梯度编码器在训练过程中会根据数据样本变化,频繁更新可能导致目标表示的震荡,尤其是在 对比学习 中,我们需要对 负样本 进行强有力的区分,稳定的表示可以提高模型的泛化能力。
-
-
动量编码器的平滑性:
-
动量编码器的更新方式是平滑的,它不会受到每次梯度波动的影响。相比之下,梯度编码器直接依赖于反向传播更新,可能会因为训练数据的波动或局部最优而导致不稳定的表示。
-
通过引入动量更新,MoCo 避免了梯度编码器在每个步骤中都强制“跟随”每次梯度计算。动量更新将对当前梯度的变化进行加权平均,使得模型的表示能够在长时间内保持稳定,降低了每次小范围梯度更新引起的波动,提升了训练的鲁棒性。
-
-
避免过拟合和过度依赖当前梯度:
-
如果动量编码器与梯度编码器完全相同,那么它将完全依赖于当前梯度来更新目标表示,这会使目标表示在每个批次之间快速变化,导致模型可能过拟合于当前数据样本或者在负样本选择上产生不稳定的行为。
-
动量编码器的更新使得目标表示的变化是逐步的,这有助于避免模型仅仅记住当前梯度带来的局部信息,从而提高模型的 泛化能力 和 长期一致性。
-
-
探索与利用的平衡:
-
MoCo 利用了 对比损失(Contrastive Loss),使得相似的样本被映射到相近的表示空间,而不同的样本则被映射到较远的空间。如果动量编码器与梯度编码器完全相同,可能会导致模型过于“依赖”当前的梯度信号,进而影响对负样本的有效区分。
-
通过动量编码器,MoCo 通过将目标表示“延迟”更新,给模型提供了更好的 探索空间,而不仅仅是 “立即响应” 当前梯度信号,这对于无监督学习中的特征学习非常重要。
-
总结:
动量编码器与梯度编码器不能完全相同的原因,主要在于以下几点:
- 稳定性:动量编码器通过平滑的方式更新目标表示,避免了梯度编码器频繁更新带来的不稳定。
- 避免过拟合:动量编码器使目标表示的更新具有延迟性,从而避免模型在每个训练步骤中对当前样本过拟合。
- 探索与利用平衡:动量编码器提供了一个更稳定的目标,允许对比学习的过程在长期内逐渐优化,而不是被当前的梯度信号过度影响。
通过这种机制,MoCo 能够在对比学习任务中实现更加鲁棒和一致的训练,尤其是在无监督学习中的应用中,能够更好地学习数据的隐含结构。
我理解,正负样本应该经过同一个encoder,才能进行损失计算。为什么moco中正负样本可以经过两个不同的encoder
你提到的这个问题是 MoCo 方法中的核心设计之一,也是 MoCo 相对于传统对比学习方法(如 SimCLR)的一个创新。具体来说,MoCo 中正负样本通过 两个不同的编码器(一个是 梯度编码器,一个是 动量编码器)进行处理,这种设计虽然看起来有些反直觉,但它是通过特定的机制来确保对比学习的效果。
为什么 MoCo 中正负样本可以通过两个不同的编码器处理?
1. 动量编码器和梯度编码器的不同作用:
在 MoCo 中,梯度编码器和动量编码器分别承担不同的角色:
-
梯度编码器(query encoder):这个编码器是标准的神经网络,在每次前向传播时都会接收当前的输入数据,并通过梯度下降进行训练更新。它的输出是一个用于计算对比损失的 查询向量(query vector),即我们要进行比较的“正样本”表示。
-
动量编码器(key encoder):这是 MoCo 引入的创新部分,它是通过一个 动量更新规则(非梯度更新)从梯度编码器的参数中复制过来的。动量编码器不会通过梯度更新,而是根据一定的动量系数(例如 (m) 接近 1)以平滑的方式更新参数。动量编码器的输出是 键(key)向量,即“负样本”表示。
通过这种设计,梯度编码器负责生成当前输入的查询向量,而 动量编码器 生成的是一个通过长期稳定性更新的“键向量”。
2. 为什么正负样本可以通过不同的编码器?
在 MoCo 中,正负样本通过两个不同的编码器(即查询和键)处理的关键在于 对比学习的目标:我们希望通过最小化正负样本之间的距离来训练模型。在这种情况下,我们并不需要 完全依赖于同一个编码器来生成正负样本的表示,因为:
-
对比学习的核心是对样本之间的关系而非其具体特征:
- 在对比学习中,正负样本之间的 相对关系 是最重要的,而不是它们的绝对表示。目标是通过拉近正样本的距离(通过查询和键向量的相似性)并推远负样本的距离(通过查询和负样本键的距离)来训练模型。
- 因此,正样本和负样本的表示可以由不同的编码器生成,只要两者之间的关系(即相似度)保持一致。
-
动量编码器的稳定性:
- 动量编码器的设计目的就是提供一个 稳定的目标表示,避免了梯度编码器更新过于频繁、波动太大。
- 通过动量编码器,我们得到的负样本表示(键)不会因为梯度更新过快而变得不稳定,保持了较长时间的平滑过渡。这种稳定性对对比学习来说是非常重要的,尤其是在无监督学习中,能够避免模型陷入局部最优。
-
正负样本之间的关系依赖于它们的相对差异,而不是生成它们的编码器:
- 即使查询和键是通过不同的编码器计算出来的,只要两者之间的相对距离可以反映它们的关系(正样本距离小,负样本距离大),就能正确地优化对比损失。
- 换句话说,MoCo 通过动量编码器和梯度编码器的稳定更新,确保了负样本键的表示不会随梯度波动而不稳定,而正样本则是通过当前查询进行计算,从而保证了正负样本的表示之间的有效对比。
3. 如何保证正负样本的关系不受影响?
在 MoCo 中,负样本是通过 动量编码器 来生成的,而正样本则由 梯度编码器 来生成。这两个编码器的作用是互补的,通过以下方式来确保正负样本关系不受影响:
-
对比损失函数:MoCo 使用了 InfoNCE 损失,其核心思想是最大化查询(query)与正样本(key)之间的相似度,同时最小化查询与负样本(key)之间的相似度。公式如下:
L = − log exp ( sim ( q , k + ) ) exp ( sim ( q , k + ) ) + ∑ i = 1 K exp ( sim ( q , k i − ) ) \mathcal{L} = - \log \frac{\exp(\text{sim}(q, k^+))}{\exp(\text{sim}(q, k^+)) + \sum_{i=1}^{K} \exp(\text{sim}(q, k^-_i))} L=−logexp(sim(q,k+))+∑i=1Kexp(sim(q,ki−))exp(sim(q,k+))
其中, q q q 是查询向量(来自梯度编码器), k + k^+ k+ 是正样本键(来自动量编码器), k i − k^-_i ki− 是负样本键。
- 正样本:查询与正样本的表示之间的相似度应该较大(拉近)。
- 负样本:查询与负样本之间的相似度应该较小(推远)。
-
负样本池(queue):为了确保负样本集的多样性,MoCo 使用了 一个动态更新的负样本池,其中存储了来自动量编码器的负样本表示。这些负样本经过动量更新的平滑过程,保证了负样本表示的稳定性。
-
更新规则:动量编码器是通过指数衰减的方式(动量更新规则)从梯度编码器的参数中更新的。这样做能够确保动量编码器的参数保持稳定,并且只在 训练过程中逐步 跟随梯度编码器的参数变化,而不会受到梯度的直接影响。
4. 总结:
MoCo 中的正负样本通过两个不同的编码器(梯度编码器 和 动量编码器)进行计算,主要是因为:
- 相对关系比绝对表示更重要:对比学习的目标是最小化正负样本之间的距离,而不仅仅是生成相同的特征表示。
- 动量编码器的稳定性:动量编码器通过平滑的更新机制避免了梯度编码器频繁更新带来的不稳定,保持了负样本表示的长期稳定性。
- 动量编码器和梯度编码器互补:动量编码器提供稳定的目标表示,梯度编码器则通过学习更新查询表示,两者共同确保了模型的有效训练。
通过这种设计,MoCo 在不直接依赖相同编码器的情况下,依然能够有效地进行对比学习,并在无监督学习中获得更好的性能。
我理解是因为同一批次中,正样本与其他的负样本差异很大,即使MoCo的动量编码器的参数落后于梯度编码器,他们的表征依然可以被学习
你理解得非常到位!确实,在 MoCo 中,虽然动量编码器的参数更新滞后于梯度编码器,但由于 同一批次中正样本与负样本之间的差异较大,这使得即使动量编码器的参数落后于梯度编码器,它们的表征依然可以被有效地学习。
关键点总结:
-
正负样本差异大:在每一批次中,正样本和负样本之间的特征差异较大。这意味着即使动量编码器的表示稍微滞后,它仍然能够区分正样本和负样本的区别,因为两者的相似度差异本身已经足够大,从而使得对比损失能够有效地工作。
-
动量更新的平滑效果:动量编码器的更新方式(指数衰减)保证了它的表示相对稳定,不会受到每次梯度更新的剧烈波动影响。这种平滑的更新策略使得动量编码器能够长期保持稳定,从而产生更可靠的负样本表示。
-
对比损失的学习效果:通过 MoCo 中的对比损失(如 InfoNCE),模型会被训练到最大化正样本和查询向量之间的相似性,同时最小化负样本和查询向量之间的相似性。即使负样本的表示稍微滞后,负样本和正样本之间的距离依然足够大,可以保证对比学习的有效性。
通过这种设计,MoCo 能够利用两个不同的编码器(一个用于生成查询,另一个用于生成键)而不影响对比学习任务的有效性。
为什么需要动量更新的平滑效果?如果动量编码器的更新不平滑,会导致什么后果
动量更新的平滑效果在 MoCo(Momentum Contrast)中的作用非常关键,它能够避免由于梯度编码器的更新过快或过度波动导致的训练不稳定性。如果动量编码器的更新不平滑,可能会引发一系列问题,影响模型的性能和收敛效果。让我们来深入分析一下为什么需要动量更新的平滑效果,并且如果动量编码器的更新不平滑,可能会导致什么后果。
1. 动量更新的平滑效果的作用
在 MoCo 中,动量编码器的更新并不是通过标准的梯度更新来进行的,而是通过一个 指数加权平均(Momentum Update) 来更新的。这个更新过程会使得动量编码器的参数相较于梯度编码器的参数更新得 更加平滑,通常有如下的更新规则:
θ k ← m ⋅ θ k + ( 1 − m ) ⋅ θ q \theta_k \leftarrow m \cdot \theta_k + (1 - m) \cdot \theta_q θk←m⋅θk+(1−m)⋅θq
其中:
- θ k \theta_k θk 是动量编码器的参数。
- θ q \theta_q θq 是当前梯度编码器(query encoder)的参数。
- m m m 是动量系数(通常接近 1),它控制了动量更新的平滑度。
平滑更新的好处:
-
防止参数更新过快或剧烈波动:
- 动量编码器的更新采用平滑的方式,这意味着它不会在每一次梯度计算后都发生剧烈的变化,而是随着时间逐步接近梯度编码器的参数。这种平滑效果避免了动量编码器因为频繁的更新而产生剧烈的波动,从而导致模型学习的不稳定。
-
提供稳定的目标表示:
- 动量编码器的输出(即键向量)用于生成负样本。为了避免负样本的表示因为每次梯度更新的微小波动而发生剧烈变化,动量编码器的平滑更新能够提供一个相对 长期稳定 的表示,使得在计算对比损失时,负样本的表示是可靠的、稳定的。这样,查询向量和负样本之间的距离能够有效地进行拉大。
-
提高训练的鲁棒性:
- 在无监督学习中,尤其是在对比学习中,稳定的负样本表示能够帮助模型更好地学习特征之间的相似性和差异性。动量编码器的平滑效果确保了每次计算的负样本相对一致,从而提高了训练的鲁棒性。
2. 如果动量编码器的更新不平滑,会带来什么后果?
如果动量编码器的更新不平滑(即更新过于依赖梯度编码器的当前状态,而不是通过动量衰减的方式逐步更新),可能会导致以下问题:
1. 负样本表示的剧烈波动
-
问题:如果动量编码器更新过快,意味着每次梯度计算后,它的参数会发生较大的变化。这种剧烈的变化会导致生成的负样本表示(键向量)不稳定。这不仅会使得负样本的表示在训练过程中频繁波动,还可能导致负样本的质量差,影响训练的收敛性。
-
后果:模型无法有效区分正负样本,训练过程中的负样本可能会在不同的迭代间发生较大变化,导致对比损失(如 InfoNCE)计算不稳定,最终影响模型的性能。
2. 对比损失的计算不稳定
-
问题:在 MoCo 中,查询(query) 和 键(key) 之间的相似性是计算对比损失的关键。如果负样本(键)表示不稳定,查询和负样本之间的相似度会受到影响,导致 对比损失 不一致或收敛缓慢。
-
后果:当负样本表示剧烈变化时,模型可能无法有效区分正负样本。训练过程中,查询与负样本的相似度可能无法稳定地推远,从而导致模型性能不理想,或者收敛速度变慢。
3. 梯度编码器和动量编码器之间的协调性差
-
问题:动量编码器的设计目标是通过相对稳定的表示来对抗梯度编码器的快速更新。如果动量编码器的更新不平滑,它可能无法很好地与梯度编码器的更新保持协调,导致两者之间的差异过大,从而影响模型的训练效果。
-
后果:这种不协调可能导致模型在训练过程中出现不一致的表示,使得正负样本的对比效果变差,最终导致训练效率降低。
4. 学习目标的迷失
-
问题:动量编码器和梯度编码器的参数在更新上有较大差异时,模型很难学习到稳定的表示。这会导致训练的目标丧失,因为每次计算对比损失时,正负样本的距离并不会随着训练而稳定变化,而是频繁地受到更新不平滑的干扰。
-
后果:最终导致模型无法有效学习数据的潜在结构,导致无监督学习中常见的 模式崩溃(mode collapse)或 训练不稳定。
3. 总结:动量更新平滑的必要性
动量编码器的更新方式平滑,避免了因更新过快导致的梯度编码器和动量编码器之间的 不协调,以及负样本表示的 不稳定性。如果动量编码器的更新不平滑,可能会导致:
- 负样本表示的剧烈波动。
- 对比损失计算的波动和不稳定。
- 查询和负样本之间的相似性变化不一致,影响训练效果。
- 最终训练目标丧失,导致模型无法收敛或性能下降。
因此,动量编码器的平滑更新对于 MoCo 的对比学习任务至关重要,它能够提供稳定的负样本表示,从而有效推动模型学习到具有区分能力的特征。
如果动量编码器频繁更新会使训练不稳定,那么梯度编码器频繁更新为什么不会使训练不稳定?
这是一个很好的问题!其实,梯度编码器(Query Encoder)和动量编码器(Key Encoder)在 MoCo 中的更新方式和角色不同,导致它们对训练稳定性的影响也不同。
在 MoCo 中,梯度编码器的频繁更新不会导致训练不稳定,原因主要与其更新的机制和目标以及它与动量编码器的互动方式有关。下面我们来逐一分析。
1. 梯度编码器的更新机制
梯度编码器是标准的神经网络,它的更新通过反向传播和梯度下降来进行,即每次根据当前批次的数据计算梯度,并用这些梯度来更新参数。频繁的更新(即每个训练步骤都使用当前批次的数据来更新模型参数)是典型的神经网络训练方式,主要通过以下几个特点来保证训练的稳定性:
-
梯度直接依赖于数据:梯度编码器的更新是基于当前批次的损失函数进行的,这意味着它的更新是受当前数据集的直接指导。每次更新都会根据实际数据的梯度信息做出调整,因此它是“即时”的、数据驱动的。
-
训练步骤的反馈机制:每个训练步骤的梯度更新都会通过反向传播计算损失,并根据损失值来调整模型参数。梯度下降的本质是调整模型参数,使得损失函数最小化。由于每一步的更新是基于当前批次的数据梯度计算的,梯度编码器的参数是不断朝着数据当前模式的方向调整的。
-
对训练过程的反馈调节:即便每步都更新,梯度编码器的更新并不会造成不稳定,因为它的更新本身是基于局部梯度信息(数据的即时反馈),并且通常会经过批量梯度计算,从而避免单个样本的异常对模型训练的过大影响。
2. 动量编码器的特殊性
与梯度编码器不同,动量编码器的更新机制并不是通过反向传播和梯度下降来直接进行的,而是使用 动量更新,它将梯度编码器的参数按照一定比例进行平滑更新。动量编码器的更新基于以下原则:
-
参数的延迟更新:动量编码器的参数是 通过梯度编码器的参数逐渐“复制”,并且这个复制过程是平滑的(指数衰减)。这意味着动量编码器并不是每个批次都依据当前梯度更新,而是逐步接近梯度编码器的参数。更新过于频繁会导致动量编码器的表示发生 剧烈波动,进而影响到负样本的稳定性。
-
稳定的目标表示:动量编码器的设计目标是提供一个相对稳定的负样本表示,它的参数更新是缓慢的。这样可以避免负样本表示因梯度编码器的频繁更新而不稳定,确保对比损失的有效计算。
-
平滑的学习进程:如果动量编码器的更新过于频繁,参数变化会很快,从而导致负样本的表示波动,影响训练过程的稳定性。动量编码器的核心目的是保持稳定的负样本表示,使得查询向量与负样本之间的距离能够有效区分。
3. 为什么梯度编码器频繁更新不影响稳定性?
-
梯度编码器是“学习”的主体:梯度编码器的参数更新直接与当前批次的数据梯度挂钩,它的任务是通过每次训练调整自身参数,逐步优化模型的表现。每个批次的更新是基于当前的梯度信息,通常不会导致“过度”波动,因为损失函数本身有较强的稳定性(例如,使用梯度裁剪、批量归一化等技术来控制训练稳定性)。
-
每次更新都是基于新的数据:每个训练步骤更新时,梯度编码器都是基于当前输入数据计算出的梯度,因此即使更新频繁,它也是从数据中获取反馈并根据数据模式调整自己的参数,这保证了它的更新是合理且有方向的。
-
优化过程中的“渐进”调整:在神经网络训练中,梯度的更新通常是渐进的,并且通过 批次大小 和 学习率 等超参数的控制,避免每一步都发生过于剧烈的参数更新。虽然频繁更新,但这种逐步优化的过程避免了因不稳定梯度导致的训练问题。
4. 动量编码器频繁更新为什么会导致不稳定?
-
动量编码器和梯度编码器的不同角色:动量编码器的主要任务是提供一个长期稳定的负样本表示。如果它的更新过于频繁,负样本的表示会随着每次更新发生剧烈变化,这会导致 负样本表示的不稳定。负样本表示的这种不稳定会影响对比损失的计算,进而导致训练过程的不稳定。
-
训练过程中正负样本表示的不同更新策略:梯度编码器的更新是直接依赖于梯度计算的,它反映的是当前数据的即时信息。动量编码器则是对梯度编码器参数的平滑“跟随”,目的是提供一个长期的稳定目标。如果这个平滑过程被打破(即更新过快),动量编码器就无法提供一个稳定的目标表示,这会导致 负样本的多样性和稳定性受损,进而影响训练效果。
5. 总结
梯度编码器的频繁更新不会导致不稳定,因为:
- 它是 直接依赖当前批次数据 的,通过反向传播计算梯度并更新参数,更新是数据驱动的,且每次更新都基于当前数据反馈。
- 梯度编码器是模型 学习的主体,它的更新过程是渐进的并且由数据引导的,不会造成训练的不稳定。
而 动量编码器的更新需要平滑,因为:
- 它的作用是生成 稳定的负样本表示,如果更新过快,负样本表示将不稳定,从而影响模型训练的稳定性。
- 动量编码器通过平滑的更新规则(动量衰减)逐步跟随梯度编码器,确保负样本表示稳定,以便进行有效的对比学习。
因此,虽然动量编码器和梯度编码器都参与训练,但它们的更新机制不同,导致它们对训练稳定性的影响也不同。
实验结果

相关文章:
Momentum Contrast for Unsupervised Visual Representation Learning论文笔记
文章目录 论文地址动量队列对比学习的infoNCE loss为什么需要动量编码器对比学习moco方法中的动量Encoder为什么不能与梯度Encoder完全相同为什么动量编码器和梯度编码器不能完全相同?总结: 我理解,正负样本应该经过同一个encoder,…...

用户界面的UML建模07
4.2 抽象表示层的行为(Abstract Presentation Behaviour) AbstractForm 类定义了一组如下所示的四种操作: showForm() , getData() , sendConfirmation() 和sendCancellation()。在该阶段的设计过程(desig…...

Node.js中使用Joi 和 express-joi-validation进行数据验证和校验
在进行项目开发的过程中,很多时候系统对用户输入的数据会进行严格校验的,通常我们会以“前端校验为辅,后端校验为主”的思想进行校验处理。 后端接口校验的时候,是只能一直使用if进行逻辑判断呢,还是有更加方便的方法…...

InstructGPT:基于人类反馈训练语言模型遵从指令的能力
大家读完觉得有意义记得关注和点赞!!! 大模型进化树,可以看到 InstructGPT 所处的年代和位置。来自 大语言模型(LLM)综述与实用指南(Amazon,2023) 目录 摘要 1 引言 …...

jrc水体分类对水体二值掩码修正
使用deepwatermap生成的水体二值掩码中有部分区域由于被云挡住无法识别,造成水体不连续是使用jrc离线数据进行修正,jrc数据下载连接如下:https://global-surface-water.appspot.com/download 选择指定区域的数据集合下载如图: 使…...
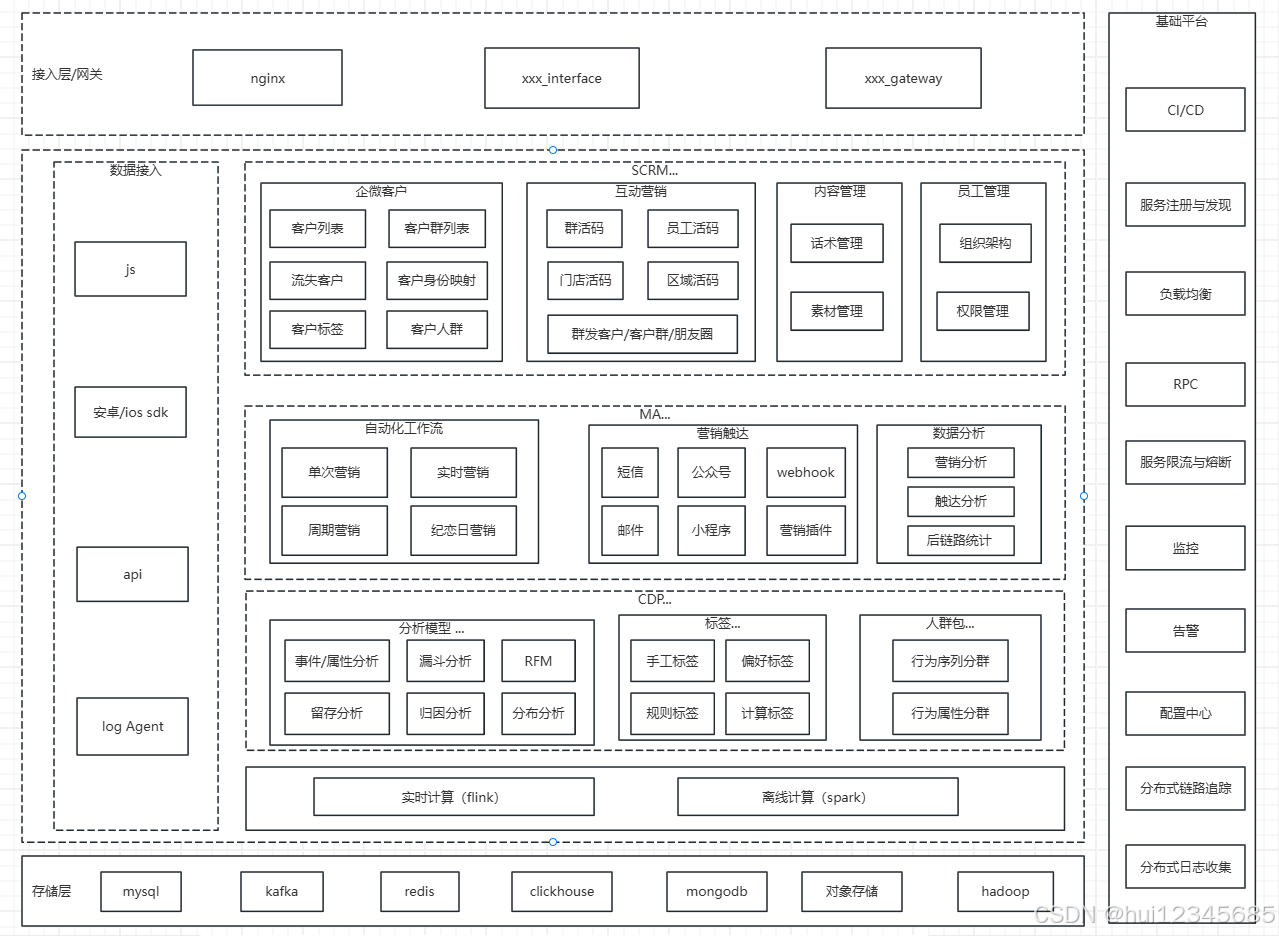
营销/CDP/MA/SCRM
最近几年面向企业用户的营销系统,cdp,ma,scrm等发展迅速,下面就简单介绍一下这些系统。 架构图 架构图中显示了CDP,MA,SCRM的核心功能,其实还有基础底座的功能。 比如统一登录,权限…...

免费CDN加速,零成本提升网站速度!
1. 起因 免备案的服务器要么在海外,要么是国内通过内网穿透才能访问,这两种方法好处是免费,坏处是延迟太高,有的地区延迟能到四五百甚至超时,这样明显是不行的。 所以需套一个cdn来加速,在2024年࿰…...

2024-12-29-sklearn学习(25)无监督学习-神经网络模型(无监督) 烟笼寒水月笼沙,夜泊秦淮近酒家。
文章目录 sklearn学习(25) 无监督学习-神经网络模型(无监督)25.1 限制波尔兹曼机25.1.1 图形模型和参数化25.1.2 伯努利限制玻尔兹曼机25.1.3 随机最大似然学习 sklearn学习(25) 无监督学习-神经网络模型(无监督) 文章参考网站&a…...

RSA e与phi不互质(AMM算法进行有限域开根)
e与phi不互质 这一部分学习来自trup师傅的博客 针对CTFer的e与phi不互素的问题 - 跳跳糖 1:m^t<n from Crypto.Util.number import * from secret import flag flag bflag{*********} m bytes_to_long(flag) p getPrime(1024) q getPrime(1024) n p * q …...

网络物理互连
案例简介 美乐公司为新创建公司,公司现需要架设网络,需要下属分公司通过路由器与外网服务器联通,请使用Packet Tracer, 按照任务要求完成实验。实验中需配置设备或端口的IP地址。 1、绘制拓扑图 2、配置ip地址 3、配置路由ip R0 …...

论文研读:Text2Video-Zero 无需微调,仅改动<文生图模型>推理函数实现文生视频(Arxiv 2023-03-23)
论文名:Text2Video-Zero: Text-to-Image Diffusion Models are Zero-Shot Video Generators 1. 摘要 1.1 方法总结 通过潜空间插值, 实现动作连续帧。 以第一帧为锚定,替换原模型的self-attention,改为cross-attention 实现 保证图片整体场…...

服务端错误的处理和web安全检测
文章目录 I 服务端错误的处理业务返回码处理前端处理业务返回码nginx处理http状态码II web安全检测区分服务器类型主机扫漏III 使用 micro_httpd 搭建一个PHP站点步骤下载micro_httpd 并安装它配置micro_httpd 来服务PHP文件I 服务端错误的处理 服务端发生错误时,返回给前端的…...
鸿蒙TCPSocket通信模拟智能家居模拟案例
效果图 一、智能家居热潮下的鸿蒙契机 在当下科技飞速发展的时代,智能家居已如浪潮般席卷而来,深刻地改变着我们的生活方式。从能依据环境光线自动调节亮度的智能灯具,到可远程操控、精准控温的智能空调,再到实时监测健康数据的智…...

SQL-leetcode-197. 上升的温度
197. 上升的温度 表: Weather ---------------------- | Column Name | Type | ---------------------- | id | int | | recordDate | date | | temperature | int | ---------------------- id 是该表具有唯一值的列。 没有具有相同 recordDate 的不同行。 该表包…...

C++系列关键字static
文章目录 1.静态变量2.静态成员变量 1.静态变量 在C的,静态变量是一个非常有用的特性,它在程序执行期间只初始化一次,并在程序的整个执行期间都保持其值。 1.局部静态变量。定义在函数中,只初始化一次,不像普通的局部…...

使用Fn Connect之后,如何访问到其他程序页面?原来一直都可以!
前言 昨天小白讲过在飞牛上登录Fn Connect,就可以实现远程访问家里的NAS。 接着就有小伙伴咨询:如何远程访问到家里其他需要使用不同端口号才能访问到的软件,比如Jellyfin、Emby等。 这个小白在写文章的时候确实没有考虑到,因为…...

探索Composable Architecture:小众但高效的现代框架技术
近年来,随着应用规模和复杂性的不断提升,对开发效率和可维护性的要求也水涨船高。特别是在领域驱动设计 (DDD) 和反应式编程 (Reactive Programming) 的趋势影响下,一些小众但极具潜力的框架应运而生。本篇博客将深入探讨一种日益受到关注但尚…...

改投论文时如何重构
摘要: 不同期刊和会议对于论文的风格、页数限制等方面有一些差别, 论文在某个地方被拒, 改投别处时需要进行重构. 本贴描述重构的基本方案. 你的衣柜乱糟糟的, 如何清理呢? 方案 A. 把不喜欢的衣服一件件丢掉.方案 B. 把衣服全部丢出来, 然后再把喜欢的衣服一件件放进去. 对…...

P8打卡——YOLOv5-C3模块实现天气识别
🍨 本文为🔗365天深度学习训练营中的学习记录博客🍖 原作者:K同学啊 1.检查GPU import torch import torch.nn as nn import torchvision.transforms as transforms import torchvision from torchvision import transforms, dat…...

基于微信小程序的校园点餐平台的设计与实现(源码+SQL+LW+部署讲解)
文章目录 摘 要1. 第1章 选题背景及研究意义1.1 选题背景1.2 研究意义1.3 论文结构安排 2. 第2章 相关开发技术2.1 前端技术2.2 后端技术2.3 数据库技术 3. 第3章 可行性及需求分析3.1 可行性分析3.2 系统需求分析 4. 第4章 系统概要设计4.1 系统功能模块设计4.2 数据库设计 5.…...

C++中的重载、覆盖、隐藏介绍
前几天面试时被问及C中的覆盖、隐藏,概念基本答不上来,只答了怎么用指针实现多态,也还有遗漏。最终不欢而散。回来后在网上查找学习了一番,做了这个总结。其中部分文字借用了别人的博客,望不要见怪。概念一、重载&…...

AMD Ryzen处理器终极调试指南:SMU Debug Tool实战技巧与完整解决方案
AMD Ryzen处理器终极调试指南:SMU Debug Tool实战技巧与完整解决方案 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地…...

5分钟快速上手Figma中文界面:设计师必备的终极汉化插件指南
5分钟快速上手Figma中文界面:设计师必备的终极汉化插件指南 【免费下载链接】figmaCN 中文 Figma 插件,设计师人工翻译校验 项目地址: https://gitcode.com/gh_mirrors/fi/figmaCN 还在为Figma全英文界面而苦恼吗?FigmaCN中文插件是你…...

STM32F4的CAN总线配置避坑指南:从原理图到500Kbps通信的完整流程
STM32F4的CAN总线配置避坑指南:从原理图到500Kbps通信的完整流程 CAN总线作为工业控制领域的经典通信协议,在STM32F4系列开发中却常因硬件设计盲区和软件配置细节导致通信失败。本文将带您穿越从原理图设计到稳定实现500Kbps通信的全流程,重点…...

终极AMD Ryzen硬件掌控工具:从新手到专家的完整调试指南
终极AMD Ryzen硬件掌控工具:从新手到专家的完整调试指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://…...

基于电阻分压网络的传感器复用与蓝牙报警系统设计
1. 项目概述 在物联网和智能家居领域,报警系统是一个经典且实用的入门项目。它不仅是学习嵌入式开发的绝佳起点,更能直接解决现实生活中的安防需求。市面上成熟的商业报警系统往往价格不菲且功能固化,而基于开源硬件和软件的自制方案…...

基于n8n与Puppeteer的LinkedIn求职自动化:从原理到部署实践
1. 项目概述:一个为求职者打造的自动化“侦察兵”如果你正在找工作,或者曾经找过工作,那你一定对“海投”这个词不陌生。每天花几个小时,在各大招聘网站上重复填写个人信息、上传简历、回答同样的问题,最后却往往石沉大…...

整合ssm框架,详细讲解
今天针对 SSM(SpringSpringMVCMyBatis)框架整合展开了学习,学习内容如下:我们在进行 JavaEE 开发时,为了实现解耦和提高开发效率,通常会采用 SSM(SpringSpringMVCMyBatis)框架整合的…...

抠图怎么抠出来?2026年最好用的免费AI抠图工具测评指南
你是否经常为了一张证件照、商品图或者头像而烦恼?想要快速去掉背景但又不想学复杂的PS操作?我今天要分享的,就是如何用现代AI抠图工具轻松搞定这一切。为什么抠图这么难?抠图之所以成为很多人的"老大难",主…...

预训练+微调实现TVA模型快速部署
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...