线性回归模型的构建与训练
1.基本的导入与配置
# To support both python 2 and python 3
from __future__ import division, print_function, unicode_literals# Common imports
import numpy as np
import pandas as pd
import os# to make this notebook's output stable across runs
np.random.seed(42)# To plot pretty figures
%matplotlib inline
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rc('axes', labelsize=14)
mpl.rc('xtick', labelsize=12)
mpl.rc('ytick', labelsize=12)# Where to save the figures
PROJECT_ROOT_DIR = "."
CHAPTER_ID = "training_linear_models"# Ignore useless warnings (see SciPy issue #5998)
import warnings
warnings.filterwarnings(action="ignore", message="^internal gelsd")
2.正规方程处理线性回归
用y=4+3x+高斯噪声来生成100个数据点(x0为1)
# 首先构造X,维度X中所有点的范围在0-2之间,可利用np.random.rand生成符合均匀分布的0-1之间的点。
X = 2 * np.random.rand(100, 1)
# 构造y, 可用np.random.randn构造高斯噪声
y = 4 + 3 * X + np.random.randn(100, 1)
用matplotlib查看生成的点
#2
plt.plot(X, y, "b.")
plt.xlabel("$x_1$", fontsize=18)
plt.ylabel("$y$", rotation=0, fontsize=18)
plt.axis([0, 2, 0, 15])
# save_fig("generated_data_plot")
plt.show()

通过求解MSE(均方误差)的最小值^θ=(XT⋅X)−1⋅XT⋅y 求解θ值(这就是一个模型的训练过程)
# add x0 = 1 to each instance
X_b = np.c_[np.ones((100, 1)), X]
# 通过正规方程求解最佳theta值
theta_best = np.linalg.inv(X_b.T.dot(X_b)).dot(X_b.T).dot(y)
theta_best
说明:
X_b = np.c_[np.ones((100, 1)), X]这行代码创建了一个新矩阵X_b,它是原始特征矩阵X的扩展。np.ones((100, 1))生成了一个100行1列的全1矩阵,这在线性代数中常用来表示截距项(也就是当所有特征值为0时的偏置项)。np.c_是NumPy中的一个函数,用于沿着第二轴(列)连接两个数组。所以,X_b实际上是将全1列向量添加到X的每一行前面,以便在模型中包含截距项。
theta_best:
![]()
用matplotlib查看拟合的回归函数(的预测结果)
plt.plot(X_new, y_predict, "r-", linewidth=2, label="Predictions")
plt.plot(X, y, "b.")
plt.xlabel("$x_1$", fontsize=18)
plt.ylabel("$y$", rotation=0, fontsize=18)
plt.legend(loc="upper left", fontsize=14)
plt.axis([0, 2, 0, 15])
plt.show()

LinearRegression是基于最小二乘方法的线性模型(训练过程使用正规方程求解)
因此使用LinearRegression求解的theta和y值应该与前面正规方程求出的结果一致。
LinearRegression(
*, # 后面参数都是可选参数
fit_intercept=True, # bool值,指定是否应该计算截距项(即线性方程中的常数项)
copy_X=True, # 指定是否应该复制 X
n_jobs=None, # 指定用于计算的作业数,-1表示使用所有可用的CPU核心,1表示不使用并行计算,None,则作业数由底层实现决定(通常是一个合理的默认值,取决于是否安装了支持并行计算的库,如 joblib
positive=False, # 仅在 fit_intercept=False 时有效,False,则不对系数的符号进行限制,True,则强制系数为正数
)
from sklearn.linear_model import LinearRegression
# Step1:构建LinearRegression()估计器的实例对象lin_reg
lin_reg = LinearRegression()
# Step2:调用实例对象lin_reg的fit方法进行训练
lin_reg.fit(X, y)
# Step2:通过intercept_和coef_查看训练得到的参数值,即线性方程的截断和系数
lin_reg.intercept_, lin_reg.coef_
intercept_属性存储了模型的截距项,coef_属性存储了模型的系数。
说明:
array([4.21509616])这是一个只包含一个元素的数组,表示线性回归模型的截距(intercept)。截距是线性方程中的常数项,也就是当所有特征变量(x值)都为0时,因变量(y值)的预测值。在这个例子中,截距是4.21509616。
array([[2.77011339])这是一个二维数组,包含一个元素的一维数组,表示线性回归模型的系数(coefficients)。系数是线性方程中特征变量的系数,表示每个特征变量对因变量的影响程度。在这个例子中,只有一个特征变量,其系数是2.77011339。
所以,这两个参数定义了一个简单的线性回归方程:
y=4.21509616+2.77011339⋅x
其中,x 是特征变量,y 是因变量。这个方程可以用来预测给定特征变量 x 值的因变量 y 值。
![]()
# Step3:调用估计器的predict方法对X_new进行预测
lin_reg.predict(X_new)
![]()
第二值是预测的结果y
3.梯度下降训练线性回归
![]()
# 学习率
eta = 0.1
n_iterations = 1000# 有100个数据点
m = 100# 随机初始化参数theta,模型有两个参数(包括截距项),因此theta是一个2x1的向量
theta = np.random.randn(2,1)for iteration in range(n_iterations):# 计算梯度,这里使用了批量梯度下降(BGD)方法 # 2/m是归一化因子,确保梯度是平均梯度 # X_b.T是扩展特征矩阵的转置,它包含了截距项 # X_b.dot(theta) - y计算了模型预测与真实标签之间的误差 # 整个表达式计算了损失函数关于theta的梯度
gradients = 2/m * X_b.T.dot(X_b.dot(theta) - y)# 使用梯度下降法更新参数theta # eta * gradients计算了参数应该更新的量(方向和大小) # theta - eta * gradients则是更新后的参数值
theta = theta - eta * gradients
解释:
1.初始化参数:
eta = 0.1:这是学习率,它控制着在每次迭代中参数更新的步长。较小的学习率意味着更新步长较小,可能需要更多的迭代次数来收敛;较大的学习率可能导致更新步长过大,从而越过最优解或导致训练不稳定。
n_iterations = 1000:这是迭代次数,即梯度下降算法将执行1000次迭代。
m = 100:这是数据点的数量,表示训练集中有100个样本。
theta = np.random.randn(2,1):这是参数theta的初始化,theta是一个2x1的向量,包含两个参数(一个是截距项,另一个是特征的系数)。这里使用正态分布随机初始化参数。
2.迭代过程:
for iteration in range(n_iterations):开始1000次迭代的循环。
gradients = 2/m * X_b.T.dot(X_b.dot(theta) - y):计算梯度。
X_b.dot(theta):计算模型预测值,即线性组合X_b(扩展特征矩阵)和theta(参数向量)的点积。
X_b.dot(theta) - y:计算预测值和真实值之间的误差。
X_b.T.dot(...):计算误差与特征矩阵X_b的点积,得到梯度向量。
2/m * ...:将梯度向量除以样本数量m,得到平均梯度,这是批量梯度下降的关键步骤。
theta = theta - eta * gradients:更新参数theta。
eta * gradients:计算参数更新的量,即学习率eta乘以梯度向量gradients。
theta - ...:根据梯度下降的方向更新参数theta,减去计算出的更新量。
3.结果:
经过1000次迭代后,theta将收敛到最小化损失函数的值,即找到了最佳拟合参数。
# 查看梯度下降训练之后的theta
theta
![]()
X_new_b.dot(theta)
![]()
绘制不同学习率下的学习过程
# 设置随机种子以保证结果的可重复性
np.random.seed(42)
# 随机初始化参数theta(模型有两个参数,包括截距项,所以维度为(2,1))
theta = np.random.randn(2,1) # 设置绘图的大小
plt.figure(figsize=(10,4))
# 绘制三个子图,分别对应不同的学习率eta
plt.subplot(131); plot_gradient_descent(theta, eta=0.02) # 学习率0.02
plt.ylabel("$y$", rotation=0, fontsize=18) # 设置y轴标签
plt.subplot(132); plot_gradient_descent(theta, eta=0.1, theta_path=theta_path_bgd) # 学习率0.1,并记录theta路径
plt.subplot(133); plot_gradient_descent(theta, eta=0.5) # 学习率0.5 # 显示图表
plt.show()

这里面绘制了前10次迭代的情况,可以看到第一幅图,由于学习率很小,梯度下降进展很慢。第二幅图,可以看到当学习率适中时,梯度下降可以快速开始寻找最优解。第三幅图,当学习率比较大时,梯度下降很可能永远找不到最优解。
所以我们就记录了效果比较好的学习率0.1的theta变化过程,用来与其他方法的theta变化过程进行比较
4.随机梯度下降
# 初始化一个空列表,用于存储随机梯度下降过程中theta的路径
theta_path_sgd = []
# 获取数据点的数量
m = len(X_b)
np.random.seed(42)# 设置训练的轮数(epoch)
n_epochs = 50
# 定义学习率调度(learning schedule)的超参数 ,这些参数用于调整学习率随时间下降的速度
t0, t1 = 5, 50 # 定义一个函数,用于根据当前的迭代次数计算学习率
def learning_schedule(t):return t0 / (t + t1)# 随机初始化参数theta
theta = np.random.randn(2,1) # random initializationfor epoch in range(n_epochs):for i in range(m):# 以下4行代码仅用于在第一个epoch的前20次迭代中绘制预测线if epoch == 0 and i < 20: # not shown in the book
y_predict = X_new_b.dot(theta) # not shown
style = "b-" if i > 0 else "r--" # not shown
plt.plot(X_new, y_predict, style) # not shown# 随机选择一个数据点的索引
random_index = np.random.randint(m)# 获取随机选择的数据点xi及其对应的标签yi
xi = X_b[random_index:random_index+1]
yi = y[random_index:random_index+1]# 计算梯度(注意这里由于只考虑了一个数据点,所以梯度是基于单个样本的)
gradients = 2 * xi.T.dot(xi.dot(theta) - yi)# 根据当前的迭代次数(epoch * m + i)计算学习率
eta = learning_schedule(epoch * m + i)# 更新参数theta
theta = theta - eta * gradients# 将更新后的theta添加到路径列表中
theta_path_sgd.append(theta) plt.plot(X, y, "b.")
plt.xlabel("$x_1$", fontsize=18)
plt.ylabel("$y$", rotation=0, fontsize=18) plt.axis([0, 2, 0, 15])
plt.show()
说明:
初始化和设置:
theta_path_sgd = []:初始化一个空列表,用于存储随机梯度下降过程中theta的路径,即每次更新后的参数值。
m = len(X_b):获取数据点的数量。
np.random.seed(42):设置随机数种子,确保结果的可重复性。
n_epochs = 50:设置训练的轮数(epoch),即遍历整个数据集的次数。
t0, t1 = 5, 50:定义学习率调度的超参数,用于调整学习率随时间下降的速度。
学习率调度函数:
def learning_schedule(t)::定义一个函数,根据当前的迭代次数t计算学习率。这里的学习率随着迭代次数的增加而减小,这是一种常见的学习率衰减策略。
参数初始化:
theta = np.random.randn(2,1):随机初始化参数theta,这是一个2x1的向量,包含两个参数(一个是截距项,另一个是特征的系数)。
训练过程:
for epoch in range(n_epochs)::开始50轮的训练过程。
for i in range(m)::在每个epoch中,遍历每个数据点。
random_index = np.random.randint(m):随机选择一个数据点的索引,这是SGD中“随机”的由来。
xi = X_b[random_index:random_index+1]:获取随机选择的数据点xi。
yi = y[random_index:random_index+1]:获取对应的标签yi。
gradients = 2 * xi.T.dot(xi.dot(theta) - yi):计算梯度,这里只针对一个数据点计算。
eta = learning_schedule(epoch * m + i):根据当前的迭代次数计算学习率。
theta = theta - eta * gradients:更新参数theta。
theta_path_sgd.append(theta):将更新后的theta添加到路径列表中。
绘图:
plt.plot(X, y, "b."):绘制原始数据点。
plt.xlabel("$x_1$", fontsize=18):设置x轴标签。
plt.ylabel("$y$", rotation=0, fontsize=18):设置y轴标签。
plt.axis([0, 2, 0, 15]):设置坐标轴的范围。
plt.show():显示图表。
这段代码通过随机梯度下降算法训练线性回归模型,并在训练过程中记录参数的更新路径。学习率随着迭代次数的增加而减小,这有助于模型在训练初期快速收敛,在训练后期进行微调。最终,代码绘制了原始数据点和训练后的预测线。

# 观察经过随机梯度下降之后最后的theta
theta
![]()
sklearn下可以使用函数SGDRegressor实现随机梯度下降
SGDRegressor(
loss='squared_error', # 损失函数类型。可选的有 'squared_error', 'huber', 'epsilon_insensitive', 或 'squared_epsilon_insensitive'
*,
penalty='l2', # 惩罚(正则化)类型。可选的有 'none', 'l2', 'l1', 'elasticnet'。有助于防止模型过拟合。
alpha=0.0001, # 正则化强度的倒数(越大表示正则化强度越低)。仅在 penalty 不为 'none' 时使用。
l1_ratio=0.15, # 当 penalty 为 'elasticnet' 时,L1 和 L2 惩罚项之间的比例。仅在 penalty='elasticnet' 时使用
fit_intercept=True, # 是否计算截距项。如果为 False,则假定数据已经中心化
max_iter=1000, # 最大迭代次数。迭代将在达到最大迭代次数或满足其他停止条件时停止
tol=0.001, # 优化的容差。当损失或分数在 tol 内没有改进时,停止训练
shuffle=True, # 是否在每个迭代中随机打乱训练样本,有助于减少收敛到局部最小值的风险。
verbose=0, # 是否打印进度消息到 stdout。0 表示不打印,1 表示偶尔打印,>=2 表示对每个迭代都打印。
epsilon=0.1, # epsilon_insensitive 和 squared_epsilon_insensitive 损失函数的参数。仅当 loss 为这些类型之一时使用。
random_state=None, # 控制伪随机数生成器的种子
learning_rate='invscaling', # 学习率策略。可选的有 'constant', 'optimal', 'invscaling', 'adaptive'。
eta0=0.01, # 初始学习率。仅在 learning_rate='constant' 或 'invscaling' 时使用。
power_t=0.25, # 逆尺度学习率的指数。仅在 learning_rate='invscaling' 时使用。
early_stopping=False, # 是否使用早停来终止训练。如果为 True,则使用验证集上的性能来提前停止训练
validation_fraction=0.1, # 保留作为验证集的数据比例。仅在 early_stopping=True 时使用。
n_iter_no_change=5, # 在早停之前,验证分数在没有改进的情况下需要保持的迭代次数。仅在 early_stopping=True 时使用。
warm_start=False, # 当设置为 True 时,重用上一次调用的解决方案作为初始化,否则,重新分配并拟合一个新的模型
average=False, # 当设置为 True 时,计算所有迭代的平均系数。如果是一个整数,则计算最后 average 次迭代的平均系数。
)
from sklearn.linear_model import SGDRegressor
# Step1:构建SGDRegressor()估计器的实例对象sgd_reg
sgd_reg = SGDRegressor(max_iter=50, tol=None, penalty=None, eta0=0.1, random_state=42)
# Step2:调用实例对象sgd_reg的fit方法进行训练
sgd_reg.fit(X, y.ravel())

# Step2:通过intercept_和coef_查看训练得到的参数值,即线性方程的截断和系数
sgd_reg.intercept_, sgd_reg.coef_
![]()
第一个参数是截距b,第二个参数是系数k
5.小批量梯度下降
在迭代的每一步,批量梯度使用整个训练集,随机梯度使用仅仅一个实例,在小批量梯度下降中,它则使用一个随机的小型实例集。它比随机梯度的主要优点在于你可以通过矩阵运算的硬件优化得到一个较好的训练表现,尤其当你使用 GPU 进行运算的时候
# 初始化一个空列表,用于存储小批量梯度下降过程中theta的路径
theta_path_mgd = []# 设置迭代次数以及每个小批量(minibatch)的大小
n_iterations = 50
minibatch_size = 20np.random.seed(42)
theta = np.random.randn(2,1) # random initializationt0, t1 = 200, 1000
def learning_schedule(t):return t0 / (t + t1)# 初始化时间步t(用于学习率调度)
t = 0
for epoch in range(n_iterations):# 在每一个迭代开始时,随机打乱数据点的索引
shuffled_indices = np.random.permutation(m)# 根据打乱后的索引,重新排列数据X_b和标签y
X_b_shuffled = X_b[shuffled_indices]
y_shuffled = y[shuffled_indices]# 使用小批量梯度下降,遍历数据(以minibatch_size为步长) for i in range(0, m, minibatch_size):# 更新时间步t
t += 1# 获取当前小批量的数据点和对应的标签
xi = X_b_shuffled[i:i+minibatch_size]
yi = y_shuffled[i:i+minibatch_size]# 计算当前小批量的梯度(注意这里要除以minibatch_size进行归一化)
gradients = 2/minibatch_size * xi.T.dot(xi.dot(theta) - yi)# 根据当前的时间步计算学习率
eta = learning_schedule(t)# 更新参数theta
theta = theta - eta * gradients# 将更新后的theta添加到路径列表中
theta_path_mgd.append(theta)
# 观察经过小批量梯度下降之后最后的theta
theta
![]()
theta在此处是线性方程的两个参数b和k
6.三个方法的训练过程数据
# 转化为np.array数据类型
theta_path_bgd = np.array(theta_path_bgd)
theta_path_sgd = np.array(theta_path_sgd)
theta_path_mgd = np.array(theta_path_mgd)
plt.figure(figsize=(7,4))
plt.plot(theta_path_sgd[:, 0], theta_path_sgd[:, 1], "r-s", linewidth=1, label="Stochastic")
plt.plot(theta_path_mgd[:, 0], theta_path_mgd[:, 1], "g-+", linewidth=2, label="Mini-batch")
plt.plot(theta_path_bgd[:, 0], theta_path_bgd[:, 1], "b-o", linewidth=3, label="Batch")
plt.legend(loc="upper left", fontsize=16)
plt.xlabel(r"$\theta_0$", fontsize=20)
plt.ylabel(r"$\theta_1$ ", fontsize=20, rotation=0)
plt.axis([2.5, 4.5, 2.3, 3.9])
plt.show()

小结:全量梯度下降法的收敛效果是最好的,因为它将所有的情况都进行了考虑;随机梯度下降法的效果从图中也可以看出‘随机’的特点,收敛不稳定,可能并不能得到比较好的解;小批量梯度下降法则是两者的折中,在减少计算资源消耗的同时也在一定程度上确保了模型的收敛。
相关文章:
线性回归模型的构建与训练
1.基本的导入与配置 # To support both python 2 and python 3 from __future__ import division, print_function, unicode_literals# Common imports import numpy as np import pandas as pd import os# to make this notebooks output stable across runs np.random.seed(4…...
)
【JavaWeb后端学习笔记】MySQL的常用函数(字符串函数,数值函数,日期函数,流程函数)
MySQL函数 1、字符串函数2、数值函数3、日期函数4、流程函数 1、字符串函数 函数说明concat(s1, s2, …, sn)字符串拼接,将 s1, s2, …, sn 拼接成一个字符串lower(str)将字符串 str 全部转为小写upper(str)将字符串 str 全部转为大写lpad(str, n, pad)左填充&…...

【推送】主流的服务端推送技术的对比
推送技术的对比 以下是主流的服务端推送技术的对比表格,涵盖WebSocket、Server-Sent Events (SSE)、Long Polling、HTTP/2 Push和Comet: 特性WebSocketServer-Sent Events (SSE)Long PollingHTTP/2 PushComet通信方向双向单向(服务器到客户…...

直观解读 JuiceFS 的数据和元数据设计(一)
大家读完觉得有意义和帮助记得关注和点赞!!! 1 JuiceFS 高层架构与组件2 搭建极简 JuiceFS 集群 2.1 搭建元数据集群2.2 搭建对象存储(MinIO) 2.2.1 启动 MinIO server2.2.2 创建 bucket2.3 下载 juicefs 客户端2.4 创…...
nginx配置文件没有语法颜色
第一种办法: nginx-1.26.2这个目录是通过解压 nginx-1.26.2.tar.gz,nginx官网下的 将这四个目录复制到/usr/share/vim/vimfiles/目录下 cp -ar ./* /usr/share/vim/vimfiles/ 再次进入nginx配置文件可以看到已经有颜色了 第二种方法: …...

PCB层叠结构设计
PCB层叠结构设计 层叠结构设计不合理完整性相关案例:在构成回流路径时,由于反焊盘的存在,使高速信号回流路径增长,造成信号回流路径阻抗不连续,对信号质量造成影响。 PCB层叠结构实物:由Core 和 Prepreg&a…...

电子应用设计方案83:智能 AI 打印机系统设计
智能 AI 打印机系统设计 一、引言 智能 AI 打印机系统旨在提供更高效、便捷和个性化的打印服务,融合了人工智能技术,以满足不断变化的用户需求。 二、系统概述 1. 系统目标 - 实现自动纸张检测、调整打印参数,适应不同纸张类型和尺寸。 - 具…...

windows安装rsync Shell语句使用rsync
sh脚本里使用 rsync功能,需要提前布置rsync环境 第一步,下载 libxxhash-0.8.2-1-x86_64.pkg.tar 下载压缩包地址 Index of /msys/x86_64/https://repo.msys2.org/msys/x86_64/ 下载对应版本,没特殊需求下载最高版本就行了 解压缩压缩包 …...

Django 模型
Django 模型 Django 模型是 Django 框架的核心组件之一,它用于定义应用程序的数据结构。在 Django 中,模型是 Python 类,通常继承自 django.db.models.Model。每个模型类代表数据库中的一个表,模型类的属性对应表中的字段。 1. 创建模型 创建 Django 模型非常简单。首先…...

CentOS — 压缩解压
文章目录 一、tar二、zip、unzip三、gzip、gunzip四、bzip2、bunzip2 一、tar 文件格式:.tar 压缩格式:tar [-参数] *.tar 目录|文件 解压格式:tar [-参数] *.tar [-C 目标目录] 参数 -c:create,创建,创…...
OpenGL变换矩阵和输入控制
在前面的文章当中我们已经成功播放了动画,让我们的角色动了起来,这一切变得比较有意思了起来。不过我们发现,角色虽然说是动了起来,不过只是在不停地原地踏步而已,而且我们也没有办法通过键盘来控制这个角色来进行移动…...

LCS最长公共子序列C++实现
算法思路:动态规划 版本1:只输出公共长度 #include <iostream> #include <string> using namespace std;int c[1000][1000]; //c[i][j]用来存储 Xi到Yj的最长公共子序列长度 void MaxLength(int m, int n, string x, string y) { //m&#x…...

深入刨析数据结构之排序(上)
目录 1.内部排序 1.1概述 1.2插入排序 1.2.1其他插入排序 1.2.1.1 折半插入排序 1.2.1.2 2-路插入排序 1.3希尔排序 1.4快速排序 1.4.1起泡排序 1.4.2快速排序 1.4.2.1hoare版本 1.4.2.2挖坑版本 1.4.2.3前后指针版本 1.4.2.4优化版本 1.4.2.4.1小区间插入排序优…...

【无重复字符的最长子串】
一、题目 给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串的长度。示例 1: 输入: s "abcabcbb" 输出: 3 解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。示例 2: 输入: s "bbbbb" 输出: 1 解释: …...

Vue3+Element Plus的表格分页实战
Element Plus 是一个基于 Vue 3 的现代化 UI 组件库,旨在帮助开发者快速构建美观且功能丰富的 Web 应用程序。它提供了大量的 UI 组件,如按钮、表单、表格、弹出框、标签页、树形控件等,涵盖了 Web 应用开发中常见的大多数场景。本文通过一个实例来说明vue3+elementplus查询…...

vue项目搭建规范
项目搭建规范 一. 代码规范1.1. 集成editorconfig配置1.2. 使用prettier工具1.3. 使用ESLint检测1.4. git Husky和eslint1.5. git commit规范1.5.1. 代码提交风格1.5.2. 代码提交验证 二. 第三方库集成2.1. vue.config.js配置2.2. vue-router集成2.3. vuex集成2.4. element-plu…...
Mac iTerm2集成DeepSeek AI
1. 去deepseek官网申请api key,DeepSeek 2. 安装iTerm2 AI Plugin插件,https://iterm2.com/ai-plugin.html,插件解压后直接放到和iTerms相同的位置,默认就在/Applications 下 3. 配置iTerm2 4. 重启iTerm2,使用快捷键呼出AI对话…...

检索增强生成(RAG)
检索增强生成(Retrieval-Augmented Generation, RAG)是一种结合了检索机制和生成模型的先进技术,旨在提高自然语言处理系统的准确性和上下文相关性。本文将详细介绍如何从零开始构建一个RAG系统,包括数据处理、检索、生成以及部署…...
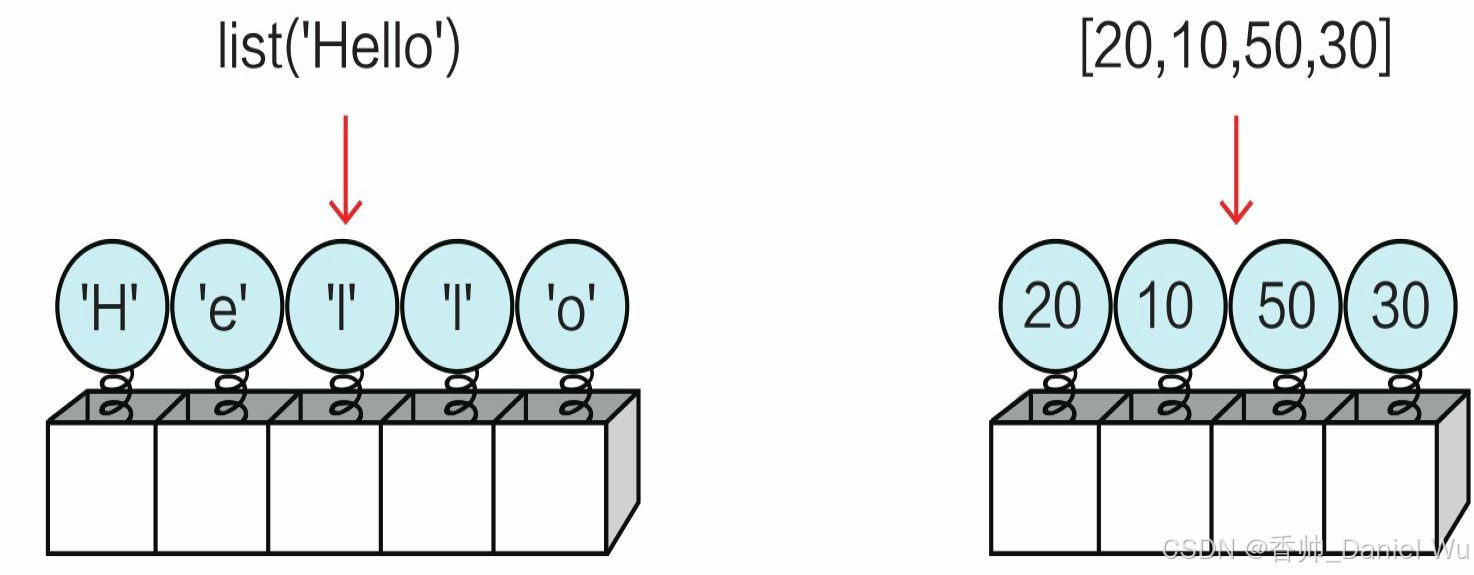
【第二部分--Python之基础】03 容器类型的数据
Python内置的数据类型如序列(列表、元组等)、集合和字典等可以容纳多项数据,我们称它们为容器类型的数据。 序列 序列(sequence)是一种可迭代的、元素有序的容器类型的数据。 序列包括列表(listÿ…...
、循环神经网络(RNN)、生成对抗网络(GAN)等概念及原理)
【人工智能机器学习基础篇】——深入详解深度学习之复杂网络结构:卷积神经网络(CNN)、循环神经网络(RNN)、生成对抗网络(GAN)等概念及原理
深入详解深度学习之复杂网络结构:卷积神经网络(CNN)、循环神经网络(RNN)、生成对抗网络(GAN) 深度学习作为人工智能的重要分支,通过复杂的网络结构实现对数据的高级抽象和理解。本文…...

Codex自主规划开发工作流实践 Codex CLI、AI编程、自动规划开发、Agent工作流、长任务AI开发、CodexLoop
Codex自主规划开发工作流实践 Codex CLI、AI编程、自动规划开发、Agent工作流、长任务AI开发、CodexLoop 老规矩 先放最新地址: Codex 最新官方客户端下载地址 https://codexdown.cn/ 最近在折腾一件很有意思的事情: 不再给 Codex 写“超详细步骤”&…...

Leantime:为神经多样性团队设计的现代项目管理解决方案
Leantime:为神经多样性团队设计的现代项目管理解决方案 【免费下载链接】leantime Leantime is a goals focused project management system for non-project managers. Building with ADHD, Autism, and dyslexia in mind. 项目地址: https://gitcode.com/GitHub…...

Windows终极优化神器:WinUtil - 一键解决系统安装、优化、修复的完整指南
Windows终极优化神器:WinUtil - 一键解决系统安装、优化、修复的完整指南 【免费下载链接】winutil Chris Titus Techs Windows Utility - Install Programs, Tweaks, Fixes, and Updates 项目地址: https://gitcode.com/GitHub_Trending/wi/winutil 你是否厌…...

WinFlexBison:构建高性能Windows平台词法语法分析器的专业解决方案
WinFlexBison:构建高性能Windows平台词法语法分析器的专业解决方案 【免费下载链接】winflexbison Main winflexbision repository 项目地址: https://gitcode.com/gh_mirrors/wi/winflexbison 在Windows平台开发编译器、解释器或复杂配置文件解析器时&#…...

从ChatGPT插件到自主Agent工作流:2026年AI工具栈跃迁的4个关键断点及突破路径
更多请点击: https://codechina.net 第一章:2026年AI工具栈搭建完整指南 构建面向生产环境的AI工具栈,需兼顾前沿性、稳定性与可扩展性。2026年主流实践已从单点模型调用转向模块化、可观测、可编排的智能工作流基础设施。以下为推荐技术选型…...

3个常见视频下载难题,猫抓扩展如何帮你一键解决?浏览器资源嗅探实战指南
3个常见视频下载难题,猫抓扩展如何帮你一键解决?浏览器资源嗅探实战指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你…...

告别单调终端:250+ Xshell配色方案让你的命令行焕然一新
告别单调终端:250 Xshell配色方案让你的命令行焕然一新 【免费下载链接】Xshell-ColorScheme 250 Xshell Color Schemes 项目地址: https://gitcode.com/gh_mirrors/xs/Xshell-ColorScheme 每天面对单调的黑白终端界面,是否感到视觉疲劳ÿ…...

瑞芯微-I2S | 音频驱动调试实战:从寄存器分析到音频环路测试
1. 瑞芯微I2S音频驱动调试全景指南 第一次接触瑞芯微平台的音频驱动调试时,我被各种专业术语和复杂的寄存器配置搞得晕头转向。经过多个项目的实战积累,我发现只要掌握正确的调试方法,音频驱动问题都能迎刃而解。本文将带你从底层寄存器分析开…...

3分钟掌握DeepMosaics:AI智能马赛克处理与图像修复的终极指南
3分钟掌握DeepMosaics:AI智能马赛克处理与图像修复的终极指南 【免费下载链接】DeepMosaics Automatically remove the mosaics in images and videos, or add mosaics to them. 项目地址: https://gitcode.com/gh_mirrors/de/DeepMosaics 在数字时代&#x…...

HiveWE魔兽地图编辑器:5分钟快速上手指南,告别卡顿创作新时代
HiveWE魔兽地图编辑器:5分钟快速上手指南,告别卡顿创作新时代 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为《魔兽争霸III》原版地图编辑器缓慢的加载速度和繁琐的操作而烦恼…...