专家混合(MoE)大语言模型:免费的嵌入模型新宠
专家混合(MoE)大语言模型:免费的嵌入模型新宠
今天,我们深入探讨一种备受瞩目的架构——专家混合(Mixture-of-Experts,MoE)大语言模型,它在嵌入模型领域展现出了独特的魅力。
一、MoE 架构揭秘
(一)MoE 是什么?
MoE 是一种包含多个被称为“专家”子网的架构,每个子网专注于不同的数据任务或方面。其优势显著,在保持甚至提升模型质量的同时,能够以比相同或更大规模的传统模型更少的计算量进行预训练。例如,Mixtral 8x7B 在众多评估数据集上就超越了 LLaMA 2 70B。
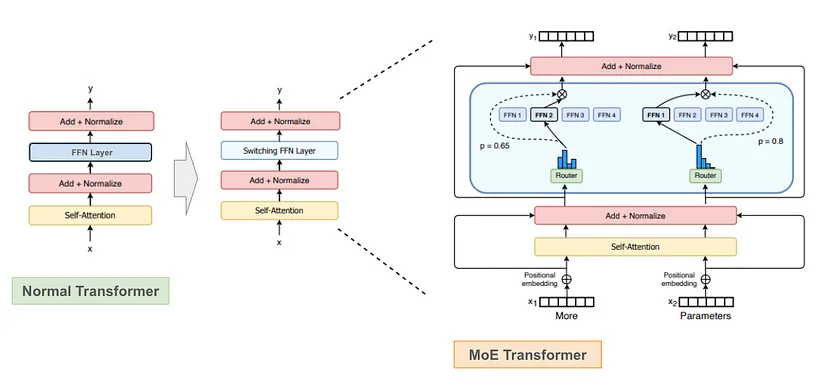
在基于变压器的 MoE 架构中,主要有两个关键组件。一是 MoE 层,它取代了变压器架构中的前馈网络(FFN)层。每个 MoE 层包含若干专家(如上图示例中有 4 个专家),每个专家由简单的 FFN 层构成。需要注意的是,变压器的其他组件,如自注意力层,在不同专家间共享相同权重,这使得 MoE 的权重数量并非简单的累加。像 Mixtral 8x7B 的权重并非 8x7 = 56B,而是 47B,原因就在于此。
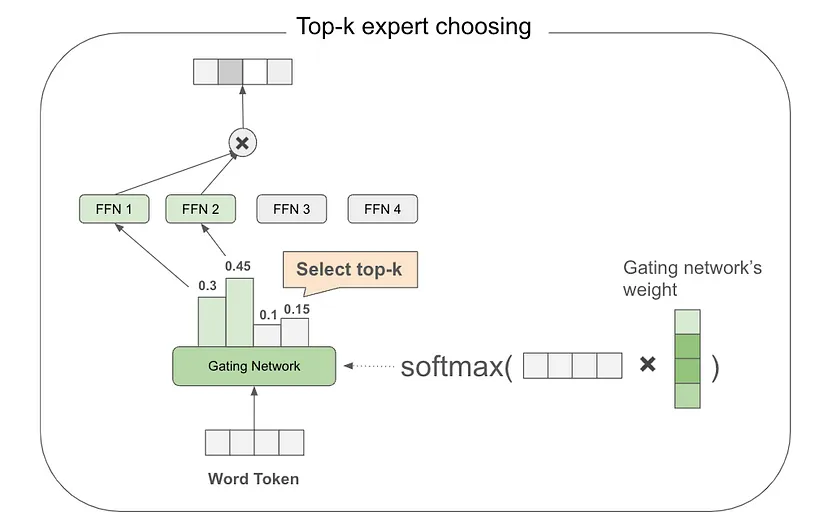
另一个重要组件是门控网络(gating network)或路由器(router)。它负责接收输入令牌,并为每个令牌选择最相关的专家。比如,在示例中,路由器左侧会选择第二个专家来处理“more”令牌,而对于“Parameters”令牌则选择第一个专家。通常,门控网络会选择与给定令牌最相关的 top - k 个专家,并将令牌发送给选定的专家(如 Mixtral 8x7B 选择 top - 2 专家)。
其选择过程是通过将输入单词令牌与门控网络权重进行点积运算,再应用 softmax 函数来计算专家的重要概率,从而依据概率选取 top - k 相关专家。具有这种门控网络的 MoE 被称为稀疏 MoE。
(二)MoE 如何作为嵌入模型工作?
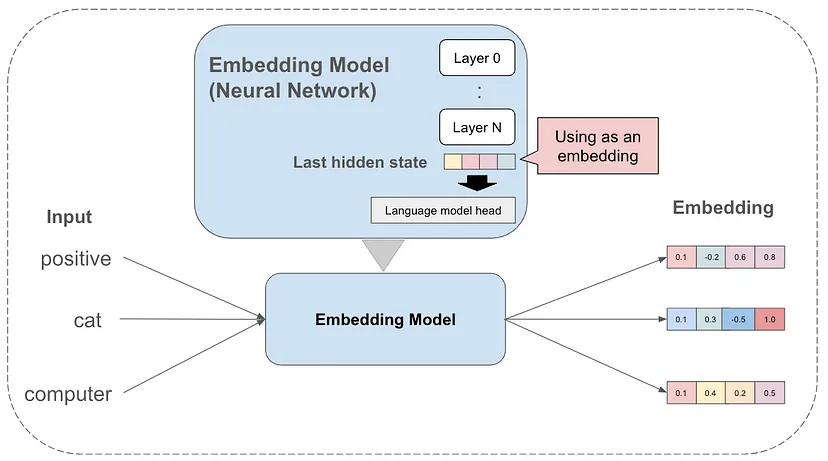
在深入探讨 MoE 作为嵌入模型的工作原理之前,先来回顾一下嵌入(embeddings)的相关知识。在深度学习模型中,嵌入是输入数据的内部表示,蕴含语义和浓缩的数据信息。通常,我们会提取神经网络的最后隐藏状态作为嵌入。一般而言,基于编码器的模型在提取嵌入方面表现出色,因为它们能够通过双向注意力捕捉语义,而仅解码器模型常使用因果注意力,只能与前一个单词令牌交互,无法像编码器 - 解码器模型那样捕获丰富的语义(如上下文信息)。
以往人们普遍认为解码器模型不能用于嵌入提取,但研究发现 MoE 中的路由权重为解码器嵌入提供了补充信息。MoE 每层的路由权重反映了对输入令牌的推理选择,包含了隐藏状态嵌入可能丢失的输入语义信息。从数学公式上看,如公式 (g) 为 softmax 函数,(H) 表示隐藏状态,我们通过连接所有 MoE 层的路由权重来避免丢失模型的推理选择。
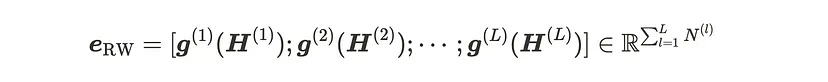
为了充分利用路由权重和解码器嵌入,研究者提出了 MoE 嵌入(MoEE)方法以形成更全面的嵌入表示。MoEE 主要有两种类型:
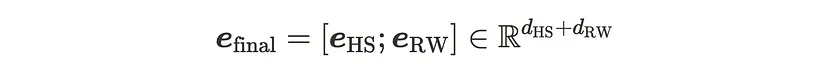
- 基于连接的组合(MoEE(concat)):此方法较为简单,直接将路由权重和解码器嵌入进行连接,如公式所示。它能够保留每个路由权重捕获的独特信息,同时使下游任务能够利用组合后的表示。
- 加权和集成(MoEE(sum)):该方法对由路由权重和隐藏状态(HS)嵌入计算出的相似度分数进行加权求和,记为 MoEE(sum)。其中,(\alpha) 是一个超参数,用于控制路由权重的贡献。在计算每对的相似度分数后,还需计算其与真实相似度之间的等级相关性(如 Spearman 等级相关性)。这种方法适用于比较两个句子的任务,如语义文本相似度任务。

在实际应用中,MoEE(concat) 较为易用。并且,研究者还利用 PromptEOL 技术来增强 MoEE。PromptEOL 技术通过提示特定模板来约束大语言模型预测下一个令牌中的语义信息,如在嵌入任务中使用的特定提示。从性能表现来看,MoEE 结合 PromptEOL 能够比有监督和自监督方法取得更好的效果。虽然其在排行榜上并非最新的最优结果,但它的价值在于无需进一步训练就能在嵌入任务中获得不错的结果。

二、MoEE 与 BERTopic 的实践应用
在这部分,我们将展示如何从预训练的 MoE 大语言模型中提取嵌入,并结合 BERTopic 使用 20 - news - group 数据集进行主题聚类。
(一)环境准备
我们采用 Python 3.10 的 conda 环境,在 Ubuntu 20.04 系统上进行实验,显卡配置为 cuda 12.4,16 GB VRAM。需要注意的是,下载模型权重可能需要 32 GB 内存。具体的环境搭建命令如下:
conda create -n moee python=3.10 -y
conda activate moee
pip install transformers torch bitsandbytes bertopic accelerate
由于 MoE 模型通常需要较高的 VRAM,我们需要使用 bitsandbytes 这个量化包来节省 VRAM 内存。同时,还需克隆官方 GitHub 仓库:
git clone https://github.com/tianyi-lab/MoE-Embedding.git
(二)利用 MoEE 进行主题聚类
这里我们以 OLMoE - 1B - 7B 模型为例,它在 16 GB VRAM 上运行推理较为可行。首先加载模型:
kwargs = {"base_model": 'allenai/OLMoE-1B-7B-0924',"normalized": False,"torch_dtype": torch.bfloat16,"mode": "embedding","pooling_method": "mean","attn_implementation": "sdpa","attn": "bbcc"
}
config = {'embed_method': 'prompteol','emb_info': 'MoEE'
}
embedding_model = MOEE(model_name_or_path='allenai/OLMoE-1B-7B-0924', **kwargs)
接着,计算 20 - news - group 数据集的嵌入并传递给 BERTopic:
from sklearn.datasets import fetch_20newsgroups
docs = fetch_20newsgroups(subset='all', remove=('headers', 'footers', 'quotes'))['data']
dataset = MyDataset(docs)
dataloader = DataLoader(dataset=dataset, batch_size=8)
embeddings = None
for batch in tqdm(dataloader):with torch.no_grad():embedding = embedding_model.encode(batch, **config)if embeddings is None:embeddings = embedding[0]else:embeddings = np.vstack((embeddings, embedding[0]))
torch.cuda.empty_cache()
在计算嵌入时,我们使用 torch.utils.data.DataLoader 作为迭代器,并对每个批次的文档进行编码。需要注意的是,传递给 BERTopic 的嵌入必须是 np.asarray 类型。
如果要使用自己的 MoE 模型,需要实现从每个 MoE 层获取路由权重的功能,而对于隐藏状态嵌入,则可以利用 HuggingFace 变压器函数,在推理时只需传递 output_hidden_states=True 参数即可。
完成嵌入计算后,就可以运行主题建模了:
umap_model = UMAP(n_neighbors=15, n_components=5, min_dist=0.0, metric='cosine')
hdbscan_model = HDBSCAN(min_cluster_size=15, metric='euclidean', cluster_selection_method='eom', prediction_data=True)
vectorizer_model = CountVectorizer(stop_words="english")
ctfidf_model = ClassTfidfTransformer()
representation_model = KeyBERTInspired()
topic_model = BERTopic(embedding_model=embedding_model,umap_model=umap_model,hdbscan_model=hdbscan_model,vectorizer_model=vectorizer_model,ctfidf_model=ctfidf_model,representation_model=representation_model
)
topics, probs = topic_model.fit_transform(docs, embeddings)
通过默认设置,我们得到了 42 个主题,从随机抽取的样本来看,能够很好地捕捉语义。同时,通过主题聚类可视化,我们可以清晰地看到不同主题之间的关联,如红色圆圈标记的主题 0 与计算机相关,其附近的主题也与机械相关词汇(如图形、数字、打印机等)有关。

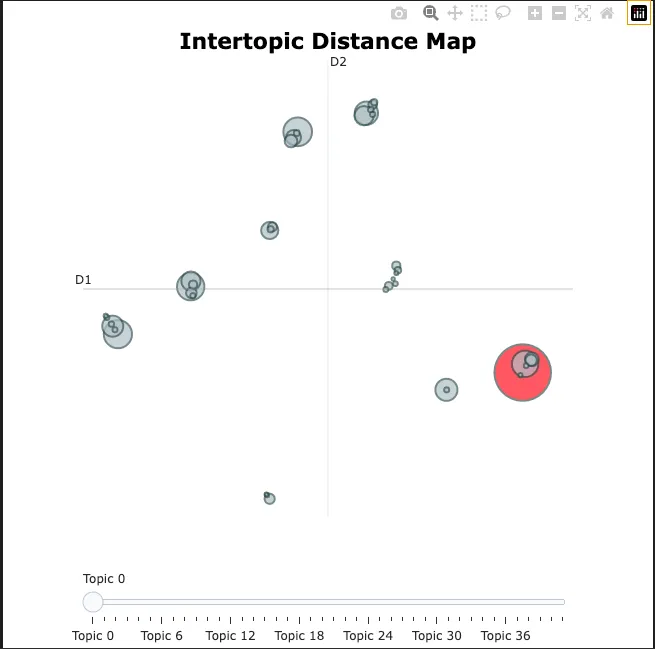
这种方法表明,我们无需额外训练就能获得不错的嵌入效果。尽管与当前最优的有监督模型相比,在质量上还有提升空间,但这一研究成果无疑为无训练的嵌入提取方法的进一步改进迈出了重要一步。
以上就是今天的全部内容,如果您对人工智能技术感兴趣,欢迎关注我们的公众号,获取更多精彩内容!
[参考文献]
[1] Ziyue Li, Tianyi Zhou, YOUR MIXTURE - OF - EXPERTS LLM IS SECRETLY AN EMBEDDING MODEL FOR FREE (2024), Arxiv
[2] Omar S., et.al., Mixture of Experts Explained (2023), Hugging Face
[3] William Fedus, Barret Zoph., et.al., Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity (2021), Arxiv
[4] Ting Jiang, et.al., Scaling Sentence Embeddings with Large Language Models (2023), Arxiv
本文由mdnice多平台发布
相关文章:
专家混合(MoE)大语言模型:免费的嵌入模型新宠
专家混合(MoE)大语言模型:免费的嵌入模型新宠 今天,我们深入探讨一种备受瞩目的架构——专家混合(Mixture-of-Experts,MoE)大语言模型,它在嵌入模型领域展现出了独特的魅力。 一、M…...

《柴油遗产-无耻时代》V98375官方版
靠近你所在赛道上的另一名玩家进行攻击或防守,跳到另一条赛道上进行恢复,或闪到对手背后打他个措手不及。与队友合作,充分利用每个角色的独特玩法来控制战斗走向! 《柴油遗产-无耻时代》官方版 https://pan.xunlei.com/s/VODW7xDX…...

科技云报到:洞见2025年科技潮流,技术大融合开启“智算时代”
科技云报到原创。 随着2024年逐渐接近尾声,人们不禁开始展望即将到来的2025年。这一年,被众多科技界人士视为开启新纪元的关键节点。站在新的起点上,我们将亲眼目睹未来科技如何改变我们的世界。从人工智能到量子计算,从基因编辑…...
【openwrt】OpenWrt 路由器的 802.1X 动态 VLAN
参考链接 [OpenWrt Wiki] Wi-Fi /etc/config/wirelesshttps://openwrt.org/docs/guide-user/network/wifi/basic#wpa_enterprise_access_point 介绍 基于802.1X 无线网络身份验证...

[coredump] 生成管理
在 Linux 系统中,core dump 文件的生成路径和文件名可以通过几个方面来控制: 系统默认路径: 默认情况下,core dump 文件通常生成在程序的工作目录,即程序运行时的当前目录。文件名通常为 core,或者在某些系…...

CSS——5. 外部样式
<!DOCTYPE html> <html><head><meta charset"UTF-8"><title>方法3:外部样式</title><link rel"stylesheet" href"a.css" /><link rel"stylesheet" href"b.css"/&g…...

检查字符是否相同
给你一个字符串 s ,如果 s 是一个 好 字符串,请你返回 true ,否则请返回 false 。 如果 s 中出现过的 所有 字符的出现次数 相同 ,那么我们称字符串 s 是 好 字符串。 输入:s "abacbc" 输出:t…...

casaos安装最新版homeassistant-arm
进入cosOS界面点自定义安装 Docker镜像:homeassistant/armv7-homeassistant Tag:2024.12.2 标题:Home Assistant 图片路径:https://cdn.jsdelivr.net/gh/IceWhaleTech/CasaOS-AppStoremain/Apps/HomeAssistant/icon.png Web UI:http&…...

openwrt host方式编译ffmpeg尝试及问题分析
openwrt host方式编译ffmpeg尝试及问题分析 configure错误分析编译错误一: ERROR: gnutls not found using pkg-config编译错误2: ERROR: libdrm not found using pkg-config编译错误3: ERROR: libmp3lame >= 3.98.3 not found编译错误4: ERROR: x264 not found using pkg…...

【three.js】搭建环境
一、安装Node.js和npm 下载与安装: 访问Node.js官方网站(nodejs.org),根据你的操作系统下载并安装最新稳定版(LTS版本)的Node.js。安装过程中,npm(Node包管理器)会随No…...

SQLite AND/OR 运算符
SQLite AND/OR 运算符 SQLite 的 AND 和 OR 运算符用于基于一个以上的条件来过滤记录。这些运算符在 WHERE 子句中与 SELECT、UPDATE 和 DELETE 语句一起使用。理解这些运算符的工作方式对于有效地查询数据库至关重要。 AND 运算符 AND 运算符允许我们在 WHERE 子句中指定多…...

《普通逻辑》学习记录——命题的判定与自然推理
目录 一、真值 1.1、真值联结词 1.2、真值联结词与逻辑联结词的区别 1.3、真值形式 1.3.1、真值符号的优先级和结合性规则 1.4、真值规则 1.4.1、条件式(蕴含式) P → Q 的真值规则 1.4.2、双条件式(等值式) P ↔ Q 的真值规则 1.…...

道可云人工智能元宇宙每日资讯|崂山区政务服务虚拟大厅启用
道可云元宇宙每日简报(2024年12月31日)讯,今日元宇宙新鲜事有: 崂山区政务服务虚拟大厅启用 近日,崂山区政务服务“虚拟大厅”在青岛正式上线,成为该市首个采用虚拟现实、人工智能、大数据及3D虚拟数字人…...

高并发写利器-组提交,我的Spring组件实战
高并发写优化理论 对于高并发的读QPS优化手段较多,最经济简单的方式是上缓存。但是对于高并发写TPS该如何提升?业界常用的有分库分表、异步写入等技术手段。但是分库分表对于业务的改造十分巨大,涉及迁移数据的麻烦工作,不会作为…...

音视频入门基础:MPEG2-PS专题(4)——FFmpeg源码中,判断某文件是否为PS文件的实现
一、引言 通过FFmpeg命令: ./ffmpeg -i XXX.ps 可以判断出某个文件是否为PS文件: 所以FFmpeg是怎样判断出某个文件是否为PS文件呢?它内部其实是通过mpegps_probe函数来判断的。从《FFmpeg源码:av_probe_input_format3函数和AVI…...
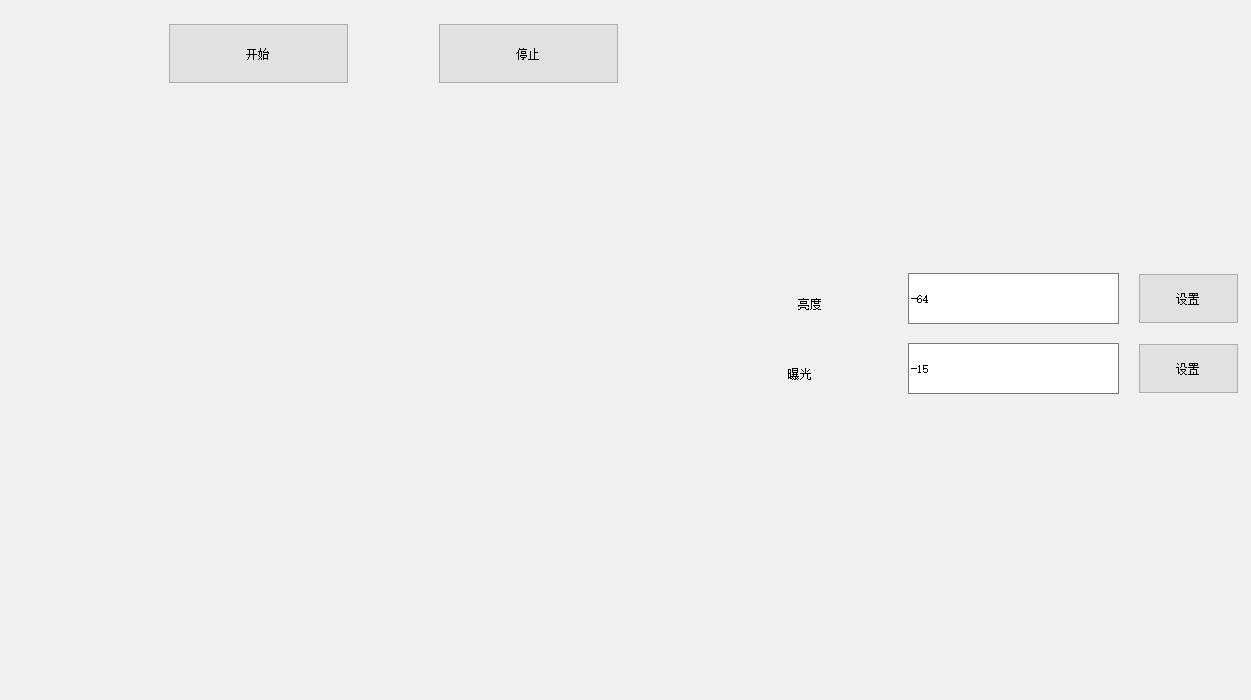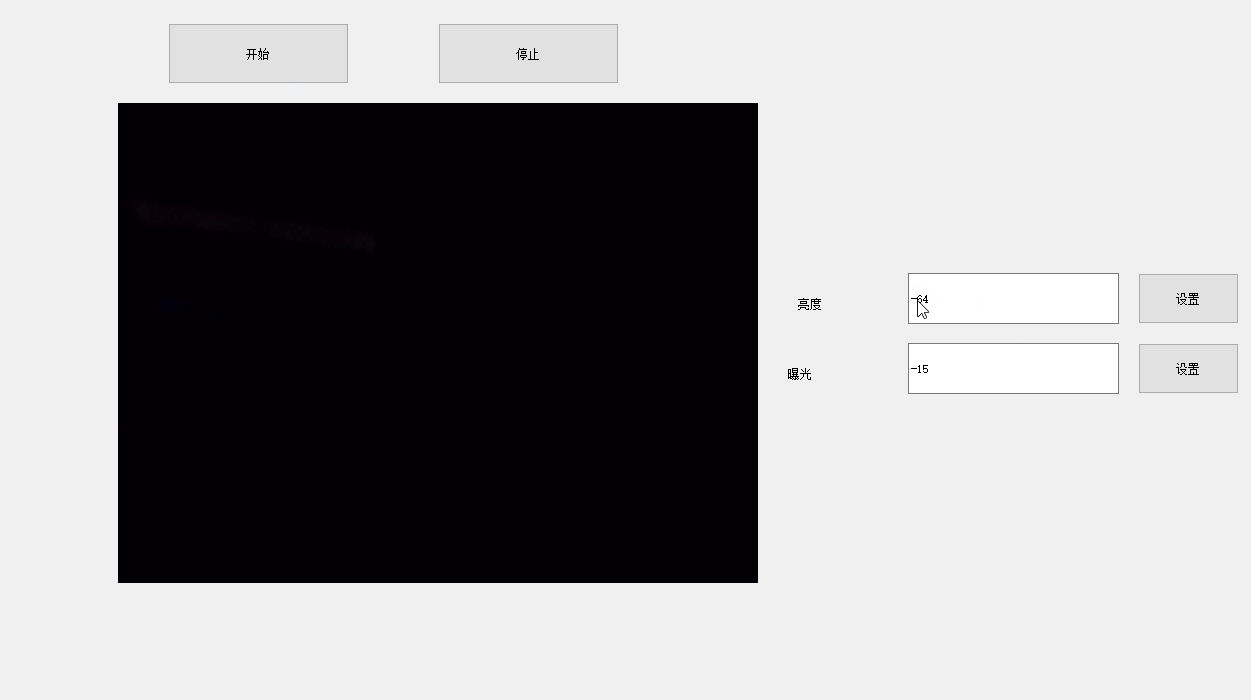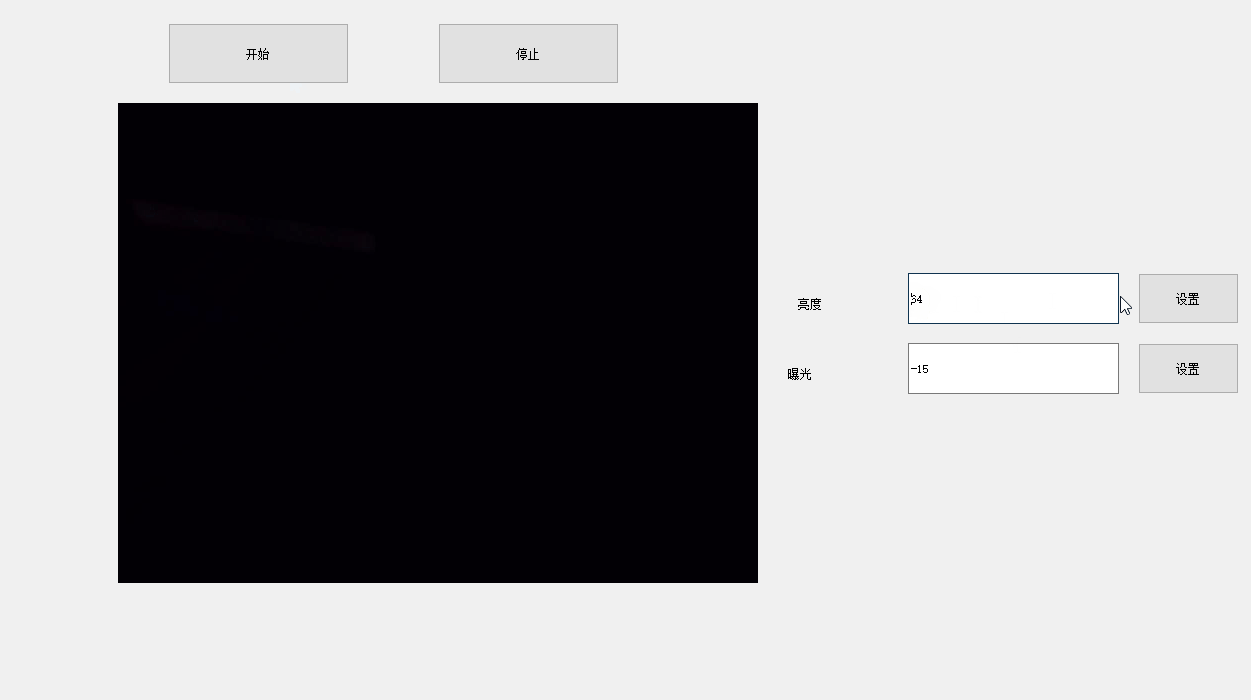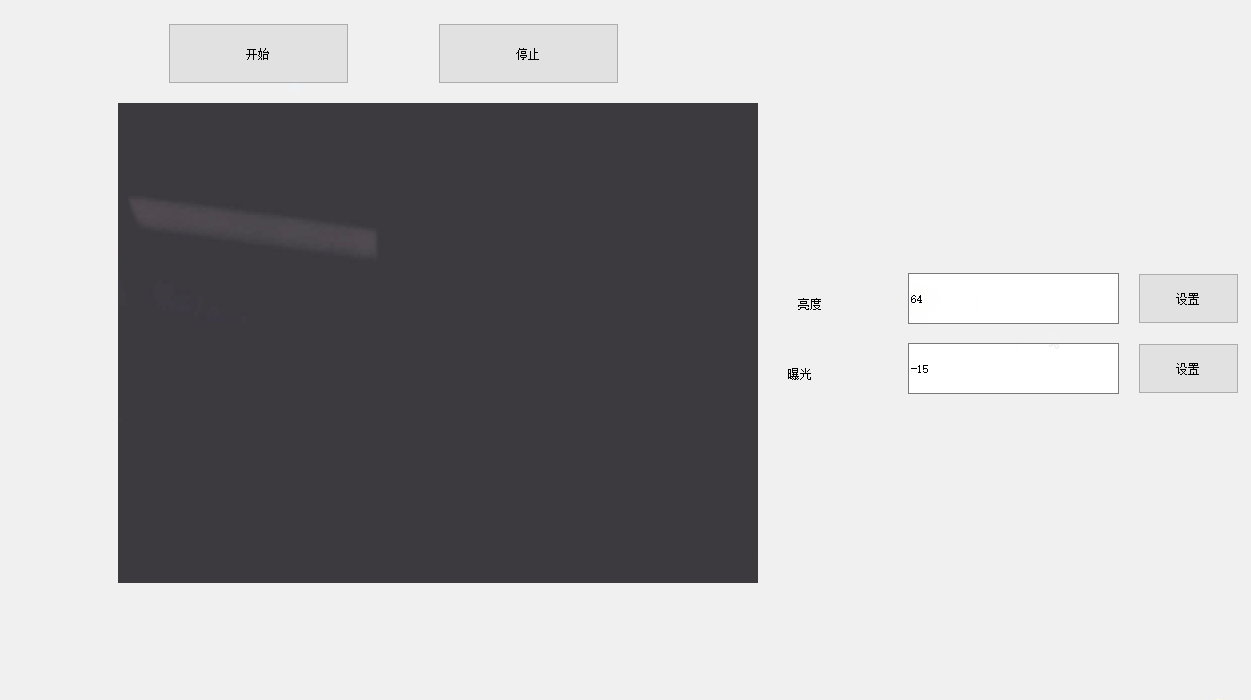
如何使用OpenCV进行抓图-多线程
前言 需求: 1、如何使用OpenCV捕抓Windows电脑上USB摄像头的流、 2、采用多线程 3、获知当前摄像头的帧率。 这个需求,之前就有做了,但是由于出现了一个问题,人家摄像头的帧率目前都可以达到60帧/s 了,而我的程序…...

电子应用设计方案86:智能 AI背景墙系统设计
智能 AI 背景墙系统设计 一、引言 智能 AI 背景墙系统旨在为用户创造一个动态、个性化且具有交互性的空间装饰体验,通过融合先进的技术和创意设计,提升室内环境的美观度和功能性。 二、系统概述 1. 系统目标 - 提供多种主题和风格的背景墙显示效果&…...

【《python爬虫入门教程11--重剑无峰168》】
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 【《python爬虫入门教程11--selenium的安装与使用》】 前言selenium就是一个可以实现python自动化的模块 一、Chrome的版本查找?-- 如果用edge也是类似的1.chrome…...

.net core 线程锁,互斥锁,自旋锁,混合锁
线程锁、互斥锁、自旋锁和混合锁是多线程编程中的重要概念,它们用于控制对共享资源的访问,避免数据竞争和不一致性。每种锁有其特定的适用场景和特点。我们来逐一解释它们,并进行比较。 1. 线程锁(Thread Lock) 线程…...
【DevOps】Jenkins项目发布
Jenkins项目发布 文章目录 Jenkins项目发布前言资源列表基础环境一、Jenkins发布静态网站1.1、项目介绍1.2、部署Web1.3、准备gitlab1.4、配置gitlab1.5、创建项目1.6、推送代码 二、Jenkins中创建gitlab凭据2.1、创建凭据2.2、在Jenkins中添加远程主机2.3、获取gitlab项目的UR…...

Obsidian终极B站视频插件:3步实现笔记内高清播放
Obsidian终极B站视频插件:3步实现笔记内高清播放 【免费下载链接】mx-bili-plugin 项目地址: https://gitcode.com/gh_mirrors/mx/mx-bili-plugin 想在Obsidian知识库中直接观看B站视频内容吗?Media Extended B站插件为您提供了完美的解决方案。…...

Magpie深度解析:3大技术突破重构Windows窗口放大体验
Magpie深度解析:3大技术突破重构Windows窗口放大体验 【免费下载链接】Magpie A general-purpose window upscaler for Windows 10/11. 项目地址: https://gitcode.com/gh_mirrors/mag/Magpie 在Windows系统中,窗口放大工具长期面临"清晰度与…...
)
别再死磕‘Solving environment: failed’了!手把手教你配置Conda的.condarc文件(附清华/中科大源完整配置)
深度解析Conda环境配置:从原理到实践的.condarc文件终极指南 当你在终端看到"Solving environment: failed"这个刺眼的红色报错时,是否感到一阵无力?作为Python开发者,我们或多或少都经历过这种挫败感——明明按照教程…...

5G NR测量配置全解析:从SSB波束管理到CSI-RS,一篇讲透与LTE的十大区别
5G NR测量配置全解析:从SSB波束管理到CSI-RS,一篇讲透与LTE的十大区别 当5G网络开始在全球范围内铺开,许多通信工程师和技术爱好者发现,从LTE到5G NR的过渡并非简单的技术迭代,而是一次彻底的架构革新。特别是在测量配…...
)
STM32定时器TIMx实战:从更新中断到PWM输出,一个实验搞定三种玩法(附源码)
STM32定时器实战:从基础配置到电机控制的一站式开发指南 在嵌入式开发领域,定时器堪称微控制器的"心脏"——它不仅负责精确计时,还能实现PWM输出、事件触发等复杂功能。但对于初学者来说,面对STM32丰富的定时器资源和复…...
---论文)
【GUI-Agent】阶跃星辰 GUI-MCP 解读---()---论文
一、 什么是 AI Skills:从工具级到框架级的演化 AI Skills(AI 技能) 的概念最早在 Claude Code 等前沿 Agent 实践中被强化。最初,Skills 被视为“工具级”的增强,如简单的文件读写或终端操作,方便用户快速…...

面试官视角:从操作系统到机器学习,计算机研究生复试常问的10个“送命题”及避坑指南
计算机研究生复试十大高频技术难题解析与应对策略 在计算机专业研究生复试中,技术问题的回答质量往往决定了面试的成败。作为面试官,我们不仅考察知识储备,更关注思维深度和问题解决能力。本文将剖析操作系统、数据结构、机器学习三大核心领域…...

智慧树视频自动学习插件:3步告别手动刷课的烦恼
智慧树视频自动学习插件:3步告别手动刷课的烦恼 【免费下载链接】zhihuishu 智慧树刷课插件,自动播放下一集、1.5倍速度、无声 项目地址: https://gitcode.com/gh_mirrors/zh/zhihuishu 还在为智慧树平台上一节接一节的视频课程感到疲惫吗&#x…...

Wan2.2-I2V-A14B生成效果深度评测:对比YOLOv5的目标运动模拟
Wan2.2-I2V-A14B生成效果深度评测:对比YOLOv5的目标运动模拟 1. 开场:当静态图片"活"起来 想象一下这样的场景:你手头有一张普通的办公室照片,桌面上摆着咖啡杯、笔记本电脑和几本书。通过Wan2.2-I2V-A14B模型&#x…...

Supabase 异步与同步客户端对比:如何选择最适合你的开发模式
Supabase 异步与同步客户端对比:如何选择最适合你的开发模式 【免费下载链接】supabase-py Python Client for Supabase. Query Postgres from Flask, Django, FastAPI. Python user authentication, security policies, edge functions, file storage, and realtim…...