Diffusers 使用 LoRA
使用diffusers 加载 LoRA,实现文生图功能。摘自 diffusers文档。
模型可以根据名称去modelscope找对应资源下载。使用的时候需要替换成具体路径。虽然modelscope和diffusers都使用了模型id,但是并不能通用。
不同的LoRA对应了不同的“trigger” words,在prompt中加入这个“trigger” words才能生成正确的结果。
比如使用了toy-face的LoRA模型,那么就要在prompt加入“toy face”。
from diffusers import DiffusionPipeline
import torchpipe_id = "stabilityai/stable-diffusion-xl-base-1.0"
pipe = DiffusionPipeline.from_pretrained(pipe_id, torch_dtype=torch.float16).to("cuda")#模型下载
#from modelscope import snapshot_download
#model_dir = snapshot_download('SDXL-LoRA/CiroN2022-toy-face')
#加载lora
pipe.load_lora_weights("CiroN2022/toy-face", weight_name="toy_face_sdxl.safetensors", adapter_name="toy")
# 加入 “toy face”
prompt = "toy_face of a hacker with a hoodie"
lora_scale = 0.9
image = pipe(prompt, num_inference_steps=30, cross_attention_kwargs={"scale": lora_scale}, generator=torch.manual_seed(0)
).images[0]
image
也可以再加载另一个模型,pipe.set_adapters() 函数确定使用哪个模型。不同的模型根据adapter_name来区分。
pipe.load_lora_weights("nerijs/pixel-art-xl", weight_name="pixel-art-xl.safetensors", adapter_name="pixel")
pipe.set_adapters("pixel")prompt = "a hacker with a hoodie, pixel art"
image = pipe(prompt, num_inference_steps=30, cross_attention_kwargs={"scale": lora_scale}, generator=torch.manual_seed(0)
).images[0]
image
也可以同时使用,adapter_weights设置不同的权重,prompt也应该包括全部的“trigger” words。
pipe.set_adapters(["pixel", "toy"], adapter_weights=[0.5, 1.0])
prompt = "toy_face of a hacker with a hoodie, pixel art"
image = pipe(prompt, num_inference_steps=30, cross_attention_kwargs={"scale": 1.0}, generator=torch.manual_seed(0)
).images[0]
image

更准确的控制LoRA的影响强度。unet一般包括down、mid、up,不同的部分对图片的细节、纹理、风格等影响不同。
pipe.enable_lora() # enable lora again, after we disabled it above
prompt = "toy_face of a hacker with a hoodie, pixel art"
adapter_weight_scales = { "unet": { "down": 1, "mid": 0, "up": 0} }
pipe.set_adapters("pixel", adapter_weight_scales)
image = pipe(prompt, num_inference_steps=30, generator=torch.manual_seed(0)).images[0]
image
从左到右分别对应{ “down”: 1, “mid”: 0, “up”: 0},{ “down”: 0, “mid”: 1, “up”: 0},{ “down”: 0, “mid”: 0, “up”: 1}

更细粒度的控制。要根据具体的模型结构,不同的模型结构不同。
adapter_weight_scales_toy = 0.5
adapter_weight_scales_pixel = {"unet": {"down": 0.9, # all transformers in the down-part will use scale 0.9# "mid" # because, in this example, "mid" is not given, all transformers in the mid part will use the default scale 1.0"up": {"block_0": 0.6, # all 3 transformers in the 0th block in the up-part will use scale 0.6"block_1": [0.4, 0.8, 1.0], # the 3 transformers in the 1st block in the up-part will use scales 0.4, 0.8 and 1.0 respectively}}
}
pipe.set_adapters(["toy", "pixel"], [adapter_weight_scales_toy, adapter_weight_scales_pixel])
image = pipe(prompt, num_inference_steps=30, generator=torch.manual_seed(0)).images[0]
image

常用函数
#不使用
pipe.disable_lora()
#使用
pipe.enable_lora()
#正在使用的
pipe.get_active_adapters()
#列表
pipe.get_list_adapters()
#删除
pipe.delete_adapters("toy")
相关文章:
Diffusers 使用 LoRA
使用diffusers 加载 LoRA,实现文生图功能。摘自 diffusers文档。 模型可以根据名称去modelscope找对应资源下载。使用的时候需要替换成具体路径。虽然modelscope和diffusers都使用了模型id,但是并不能通用。 不同的LoRA对应了不同的“trigger” words&am…...

云安全博客阅读(二)
2024-05-30 Cloudflare acquires BastionZero to extend Zero Trust access to IT infrastructure IT 基础设施的零信任 不同于应用安全,基础设置的安全的防护紧急程度更高,基础设施的安全防护没有统一的方案IT基础设施安全的场景多样,如se…...

SpringCloud系列教程:微服务的未来(六)docker教程快速入门、常用命令
对于开发人员和运维工程师而言,掌握 Docker 的基本概念和常用命令是必不可少的。本篇文章将带你快速入门 Docker,并介绍一些最常用的命令,帮助你更高效地进行开发、测试和部署。 目录 前言 快速入门 docker安装 配置镜像加速 部署Mysql …...

Vue 快速入门:开启前端新征程
在当今的 Web 开发领域,Vue.js 作为一款极具人气的 JavaScript 前端框架,正被广泛应用于各类项目之中。它以简洁的语法、高效的数据绑定机制以及强大的组件化开发模式,为开发者们带来了前所未有的开发体验。如果你渴望踏入前端开发的精彩世界…...

UVM:uvm_component methods configure
topic UVM component base class uvm_config_db 建议使用uvm_config_db代替uvm_resource_db uvm factory sv interface 建议:uvm_config_db 以下了解 建议打印error...

LLM 训练中存储哪些矩阵:权重矩阵,梯度矩阵,优化器状态
LLM 训练中存储哪些矩阵 目录 LLM 训练中存储哪些矩阵深度学习中梯度和优化器是什么在 LLM 训练中通常会存储以下矩阵: 权重矩阵:这是模型的核心组成部分。例如在基于 Transformer 架构的 LLM 中,每一层的多头注意力机制和前馈神经网络都会有相应的权重矩阵。以 BERT 模型为…...
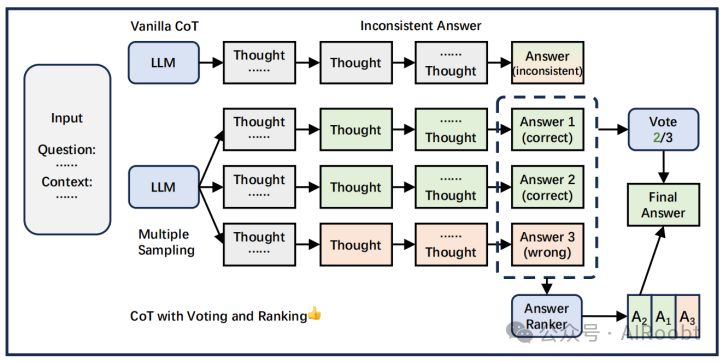
大模型思维链推理的进展、前沿和未来分析
大模型思维链推理的综述:进展、前沿和未来 "Chain of Thought Reasoning: A State-of-the-Art Analysis, Exploring New Horizons and Predicting Future Directions." 思维链推理的综述:进展、前沿和未来 摘要:思维链推理&#…...
NLP 技术的突破与未来:从词嵌入到 Transformer
在过去的十年中,自然语言处理(NLP)经历了深刻的技术变革。从早期的统计方法到深度学习的应用,再到如今Transformer架构的普及,NLP 的发展不仅提高了模型的性能,还扩展了其在不同领域中的应用边界。 1. 词嵌…...

嵌入式中QT实现文本与线程控制方法
第一:利用QT进行文件读写实现 利用QT进行读写文本的时候进行读写,读取MP3歌词的文本,对这个文件进行读写操作。 实例代码,利用Qfile,对文件进行读写。 //读取对应文件文件,头文件的实现。 #ifndef MAINWINDOW_H #define MAINWINDOW_H#include <QMainWindow> #incl…...

云备份项目--服务端编写
文章目录 7. 数据管理模块7.1 如何设计7.2 完整的类 8. 热点管理8.1 如何设计8.2 完整的类 9. 业务处理模块9.1 如何设计9.2 完整的类9.3 测试9.3.1 测试展示功能 完整的代码–gitee链接 7. 数据管理模块 TODO: 读写锁?普通锁? 7.1 如何设计 需要管理…...

Node.js——fs(文件系统)模块
个人简介 👀个人主页: 前端杂货铺 🙋♂️学习方向: 主攻前端方向,正逐渐往全干发展 📃个人状态: 研发工程师,现效力于中国工业软件事业 🚀人生格言: 积跬步…...

SAP BC 同服务器不同client之间的传输SCC1
源配置client不需要释放 登录目标client SCC1...

CentOS: RPM安装、YUM安装、编译安装(详细解释+实例分析!!!)
目录 1.什么是RPM 1.1 RPM软件包命名格式 1.2RPM功能 1.3查询已安装的软件:rpm -q 查询已安装软件的信息 1.4 挂载:使用硬件(光驱 硬盘 u盘等)的方法(重点!!!) 1…...

linux音视频采集技术: v4l2
简介 在 Linux 系统中,视频设备的支持和管理离不开 V4L2(Video for Linux 2)。作为 Linux 内核的一部分,V4L2 提供了一套统一的接口,允许开发者与视频设备(如摄像头、视频采集卡等)进行交互。无…...

MySQL使用navicat新增触发器
找到要新增触发器的表,然后点击设计,找到触发器标签。 根据实际需要,填写相关内容,操作完毕,点击保存按钮。 在右侧的预览界面,可以看到新生成的触发器脚本...

voice agent实现方案调研
前言 目前语音交互主要的实现大体有两种: 级联方案,指的是,大规模语言模型 (LLM)、文本转语音 (TTS) 和语音转文本 (STT),客户的话通过vad断句到STT的语音转文本,经过大模型进行生成文本,生成文本后通过TTS进行回复给用户。(主流方案)端到端的方案,开发者无需再…...

TCP通信原理学习
TCP三次握手和四次挥手以及为什么_哔哩哔哩_bilibili...

Three.js 基础概念:构建3D世界的核心要素
文章目录 前言一、场景(Scene)二、相机(Camera)三、渲染器(Renderer)四、物体(Object)五、材质(Material)六、几何体(Geometry)七、光…...

如何用代码提交spark任务并且获取任务权柄
在国内说所有可能有些绝对,因为确实有少数大厂技术底蕴确实没的说能做出自己的东西,但其他的至少95%数据中台平台研发方案,都是集群中有一个持久化的程序,来接收任务信息,并向集群提交任务同时获取任务的权柄ÿ…...
关于Mac中的shell
1 MacOS中的shell 介绍: 在 macOS 系统中,Shell 是命令行与系统交互的工具,用于执行命令、运行脚本和管理系统。macOS 提供了多种 Shell,主要包括 bash 和 zsh。在 macOS Catalina(10.15)之前,…...

数据分析三件套:Numpy、Pandas、Matplotlib
目录 一、 环境准备与安装 1.1 确认Python环境 1.2 使用pip一键安装 1.3 验证安装是否成功 二、 NumPy:数组计算的基石 2.1 什么是NumPy? 2.2 创建数组的四种方式 2.3 数组的常用操作 2.3.1 形状操作 2.3.2 数学运算 2.3.3 索引与切片 2.4 Nu…...

Profinet协议在工业自动化中的无线通信应用解析
1. Profinet协议:工业自动化的"神经系统" 如果把工业自动化系统比作人体,那么Profinet协议就是这套系统的"神经系统"。它负责在控制器(大脑)、执行器(四肢)和传感器(感官&a…...

LVM磁盘扩容实战:如何在已有逻辑卷上直接扩展存储空间
1. LVM磁盘扩容的核心场景与原理 想象一下你的手机存储空间快满了,但你又不想删除珍贵的照片和视频。这时候最直接的办法就是买一张更大容量的存储卡,把数据迁移过去。但在服务器环境中,这种"换卡"操作往往意味着停机、数据迁移等一…...

从停车场管理系统看STM32项目开发:如何规划你的第一个物联网硬件Demo?
从停车场管理系统看STM32项目开发:如何规划你的第一个物联网硬件Demo? 在嵌入式开发领域,STM32系列单片机因其出色的性能和丰富的外设资源,成为物联网硬件原型的首选平台。停车场管理系统作为一个典型的物联网应用场景,…...

一个简洁易用的 Delphi JSON 封装库,基于 System.JSON`单元封装,提供更直观的 API行
一、前言:什么是 OFA VQA 模型? OFA(One For All)是字节跳动提出的多模态预训练模型,支持视觉问答、图像描述、图像编辑等多种任务,其中视觉问答(VQA)是最常用的功能之一——输入一张…...

Visualized BGE批量推理实战:如何用Python代码将图片编码速度提升3倍
Visualized BGE批量推理实战:如何用Python代码将图片编码速度提升3倍 在当今多模态AI应用爆炸式增长的时代,高效处理图像嵌入已成为开发者面临的普遍挑战。Visualized BGE作为支持中文的多模态嵌入模型,其性能优化直接关系到实际业务落地的可…...
)
华为政务云时空信息平台PPT(37页)
在这个日新月异的数字时代,智慧城市不再是遥不可及的未来图景,而是正一步步走进我们的生活。今天,就让我们一起踏上这场探索之旅,揭开智慧政务新引擎——时空信息云平台的神秘面纱。一、传统GIS的困境与突破1.1 重复建设的迷宫你是…...

Phi-4-mini-reasoning实战案例:从数学计算到商业分析,小白也能用的AI大脑
Phi-4-mini-reasoning实战案例:从数学计算到商业分析,小白也能用的AI大脑 1. 认识你的AI推理助手 1.1 什么是Phi-4-mini-reasoning Phi-4-mini-reasoning是一款专为推理任务优化的轻量级AI模型,它就像你随身携带的数学老师和商业顾问。这个…...

如何快速掌握PDF差异对比工具:diff-pdf终极指南
如何快速掌握PDF差异对比工具:diff-pdf终极指南 【免费下载链接】diff-pdf A simple tool for visually comparing two PDF files 项目地址: https://gitcode.com/gh_mirrors/di/diff-pdf 你是否曾为PDF文档的版本管理而头疼?面对两份相似的PDF文…...
)
告别官方API:手把手教你从零封装YOLOv8-Pose的推理代码(附完整Python脚本)
深度解构YOLOv8-Pose:从底层实现自主可控的推理引擎 在计算机视觉领域,姿态估计技术正经历着前所未有的发展浪潮。作为YOLO系列的最新力作,YOLOv8-Pose凭借其卓越的性能和高效的推理速度,迅速成为工业界和学术界的热门选择。然而&…...