Kafka优势剖析-幂等性和事务
目录
1. 幂等性(Idempotence)
1.1 什么是幂等性?
1.2 幂等性的实现
1.2.1 生产者 ID 和序列号
1.2.2 重复消息检测
1.2.3 幂等性的优势
1.3 幂等性的配置
2. 事务支持(Transactions)
2.1 什么是事务支持?
2.2 事务的支持范围
2.3 事务的工作原理
2.3.1 初始化事务
2.3.2 添加操作到事务
2.3.3 提交或回滚事务
2.3.4 事务协调器
2.3.5 事务隔离级别
2.4 事务的优势
2.5 事务的配置
3. 幂等性与事务支持的区别
4. 实际应用中的表现
5. 总结
Kafka 通过 幂等性 和 事务支持 提供了更强的消息传递保证,确保在生产者重试发送消息或多个操作需要原子性时,不会出现重复消息或不一致的情况。这两种机制对于构建可靠、一致性的分布式系统至关重要。下面我们将详细解释 Kafka 的幂等性和事务支持的工作原理及其应用场景。
1. 幂等性(Idempotence)
1.1 什么是幂等性?
幂等性是指一个操作可以被多次执行,但结果始终相同。换句话说,无论该操作执行多少次,最终的状态都不会发生变化。在 Kafka 中,幂等性确保即使生产者重试发送消息,也不会导致重复消息的产生。
1.2 幂等性的实现
Kafka 通过 幂等生产者(Idempotent Producer)来实现幂等性。幂等生产者的配置参数是 enable.idempotence=true,启用后,Kafka 会为每个生产者分配一个唯一的 生产者 ID(Producer ID, PID),并为每条消息分配一个 序列号(Sequence Number)。Kafka broker 使用这些信息来检测和丢弃重复的消息。
1.2.1 生产者 ID 和序列号
-
生产者 ID (PID):当生产者第一次连接到 Kafka broker 时,broker 会为其分配一个唯一的 PID。这个 PID 在生产者的生命周期内保持不变,即使生产者断开连接并重新连接,它仍然会使用相同的 PID。
-
序列号 (Sequence Number):每个生产者为每个分区维护一个递增的序列号。每次生产者发送一条消息时,序列号会递增,并与消息一起发送给 Kafka broker。Kafka broker 使用 PID 和序列号来跟踪每个生产者发送的消息。
1.2.2 重复消息检测
-
消息去重:当 Kafka broker 收到一条消息时,它会检查该消息的 PID 和序列号。如果 broker 发现已经收到了相同 PID 和序列号的消息,它会认为这是一条重复消息,并将其丢弃。否则,broker 会将消息写入日志,并更新序列号。
-
超时机制:为了防止生产者长时间未发送消息导致序列号过期,Kafka 引入了 会话超时(Session Timeout)机制。如果生产者在超时时间内没有发送任何消息,Kafka 会认为该生产者的会话已结束,并重新分配新的 PID 和序列号。默认的会话超时时间为 60 秒。
1.2.3 幂等性的优势
-
避免重复消息:幂等性确保即使生产者重试发送消息,也不会导致重复消息的产生。这对于需要严格消息顺序的应用场景非常重要,例如金融交易系统、订单处理系统等。
-
简化重试逻辑:由于 Kafka 自动处理了重复消息的检测和去重,生产者不再需要手动实现复杂的重试逻辑,简化了开发工作。
-
提高可靠性:幂等性提高了消息传递的可靠性,特别是在网络不稳定或生产者故障的情况下,确保了消息的完整性和一致性。
1.3 幂等性的配置
要启用幂等生产者,只需在生产者的配置中设置以下参数:
enable.idempotence=true此外,Kafka 还提供了一些与幂等性相关的配置参数,用于控制生产者的重试行为和超时机制:
-
retries:指定生产者在发送失败时的最大重试次数。默认值为 2147483647(即无限重试),但在实际应用中应根据业务需求合理设置。 -
retry.backoff.ms:指定生产者在两次重试之间的等待时间。默认值为 100 毫秒。 -
max.in.flight.requests.per.connection:指定每个连接上最多允许的未确认请求数量。对于幂等生产者,默认值为 5。为了避免消息乱序,建议将此值设置为 1。
2. 事务支持(Transactions)
2.1 什么是事务支持?
事务支持是指 Kafka 提供了一种机制,允许多个操作作为一个整体进行提交或回滚,确保这些操作要么全部成功,要么全部失败。Kafka 的事务支持主要用于实现 精确一次语义(Exactly-Once Semantics, EOS),确保消息在生产、消费和处理过程中不会丢失或重复。
2.2 事务的支持范围
Kafka 的事务支持不仅适用于生产者发送消息的操作,还支持跨多个主题和分区的事务性操作。具体来说,Kafka 事务可以包括以下几种操作:
-
消息生产:生产者可以将多条消息作为同一个事务的一部分发送到不同的主题和分区。
-
消息消费:消费者可以将多个消息的偏移量提交作为同一个事务的一部分,确保这些消息的消费是原子性的。
-
流处理:Kafka Streams API 支持事务性操作,允许开发者在流处理过程中保证数据的一致性和完整性。
2.3 事务的工作原理
Kafka 的事务支持基于 两阶段提交协议(Two-Phase Commit Protocol),确保事务中的所有操作要么全部成功,要么全部失败。以下是 Kafka 事务的典型工作流程:
2.3.1 初始化事务
-
生产者调用
initTransactions()方法,初始化一个事务上下文。Kafka 为该事务分配一个唯一的 事务 ID(Transaction ID),并记录事务的开始时间。
2.3.2 添加操作到事务
-
生产者可以通过
send()方法将消息添加到事务中。这些消息会被暂存起来,直到事务提交为止。 -
生产者还可以通过
addOffsetsToTransaction()方法将消费者的偏移量提交操作添加到事务中,确保消息的消费和处理是原子性的。
2.3.3 提交或回滚事务
-
当所有操作完成后,生产者可以调用
commitTransaction()方法提交事务。Kafka 会确保事务中的所有操作都成功完成,并将消息写入日志。 -
如果某个操作失败,生产者可以调用
abortTransaction()方法回滚事务,确保事务中的所有操作都被取消。
2.3.4 事务协调器
-
Kafka 为每个事务分配了一个 事务协调器(Transaction Coordinator),负责管理事务的状态和协调多个 broker 之间的同步。事务协调器会跟踪事务的进度,并在适当的时候通知其他 broker 提交或回滚事务。
2.3.5 事务隔离级别
Kafka 提供了两种事务隔离级别:
-
读已提交(Read Committed):消费者只能读取已经被提交的消息,不能读取正在处理中的事务消息。这是 Kafka 默认的隔离级别,适用于大多数场景。
-
读未提交(Read Uncommitted):消费者可以读取尚未提交的事务消息。这种隔离级别适用于对一致性要求较低的场景,但可能会导致消费者读取到未提交的消息。
2.4 事务的优势
-
精确一次语义:通过事务支持,Kafka 可以实现 精确一次语义,确保消息在生产、消费和处理过程中不会丢失或重复。这对于需要强一致性的应用场景非常重要,例如金融交易系统、订单处理系统等。
-
跨主题和分区的原子性:Kafka 的事务支持允许多个操作跨越多个主题和分区,确保这些操作要么全部成功,要么全部失败。这种方式提供了更高的灵活性和可靠性。
-
流处理的一致性:Kafka Streams API 支持事务性操作,允许开发者在流处理过程中保证数据的一致性和完整性。这对于构建复杂的实时数据处理管道非常有用。
2.5 事务的配置
要启用 Kafka 的事务支持,生产者需要配置以下参数:
enable.idempotence=true # 启用幂等性
transactional.id=<unique_transaction_id> # 设置唯一的事务 ID此外,Kafka 还提供了一些与事务相关的配置参数,用于控制事务的超时和隔离级别:
-
transaction.timeout.ms:指定事务的最大持续时间。如果事务在超时时间内未完成,Kafka 会自动回滚该事务。默认值为 60000 毫秒(60 秒)。 -
transaction.state.log.replication.factor:指定事务状态日志的副本数。默认值为 3,建议根据集群的规模和可靠性需求进行调整。 -
isolation.level=read_committed:指定消费者的隔离级别为“读已提交”,确保消费者只能读取已经被提交的消息。
3. 幂等性与事务支持的区别
-
幂等性:幂等性主要解决了生产者重试发送消息时可能导致的重复消息问题。它确保每条消息只会被写入一次,但不保证多个操作的原子性。
-
事务支持:事务支持不仅解决了重复消息的问题,还提供了多个操作的原子性保证。通过事务,Kafka 可以确保一组操作要么全部成功,要么全部失败,适用于需要强一致性的场景。
-
适用场景:
-
幂等性:适用于单条消息的发送,特别是当生产者需要重试发送消息时,确保不会出现重复消息。
-
事务支持:适用于需要跨多个主题和分区的原子性操作,或者需要精确一次语义的应用场景,例如流处理、订单处理等。
-
4. 实际应用中的表现
-
高可靠性:通过幂等性和事务支持,Kafka 确保了消息传递的可靠性和一致性,特别是在网络不稳定或生产者故障的情况下,避免了重复消息或数据丢失。
-
精确一次语义:事务支持使得 Kafka 可以实现精确一次语义,确保消息在生产、消费和处理过程中不会丢失或重复。这对于需要强一致性的应用场景非常重要。
-
流处理的一致性:Kafka Streams API 的事务支持使得开发者可以在流处理过程中保证数据的一致性和完整性,适用于构建复杂的实时数据处理管道。
5. 总结
Kafka 的 幂等性 和 事务支持 是其处理高并发、高吞吐量消息传递的关键机制。幂等性确保了即使生产者重试发送消息,也不会导致重复消息的产生;而事务支持则提供了多个操作的原子性保证,确保这些操作要么全部成功,要么全部失败。这两种机制的结合使得 Kafka 在构建可靠、一致性的分布式系统时表现出色,成为许多金融、电商、实时数据处理等领域的首选。
相关文章:

Kafka优势剖析-幂等性和事务
目录 1. 幂等性(Idempotence) 1.1 什么是幂等性? 1.2 幂等性的实现 1.2.1 生产者 ID 和序列号 1.2.2 重复消息检测 1.2.3 幂等性的优势 1.3 幂等性的配置 2. 事务支持(Transactions) 2.1 什么是事务支持&…...

MyBatis深入了解
目录 xml 映射文件中,除了常见的select、insert、update、delete 标签之外,还有哪些标签? Dao 接口的工作原理是什么?Dao 接口里的方法,参数不同时,方法能重载吗? MyBatis 是如何进行分页的?分页插件的原理是什么? 简述 …...
语音技术与人工智能:智能语音交互的多场景应用探索
引言 近年来,智能语音技术取得了飞速发展,逐渐渗透到日常生活和各行各业中。从语音助手到智能家居控制,再到企业客服和教育辅导,语音交互正以前所未有的速度改变着人机沟通的方式。这一变革背后,人工智能技术无疑是关键…...

Openwrt @ rk3568平台 固件编译实践(二)- ledeWRT版本
目录 ledeWRT介绍固件编译下载代码修改feed源更新并安装编译第三方软件包制作用于eMMC烧写的rootfs基于lede发行版验证烧写rk3568.img, LEDE wrt启动成功refhttps://blog.csdn.net/zc21463071/article/details/106751361介绍rk3568平台下, lede 大神版 openwrt固件的下载、编译…...
--前端Web)
Windows下调试Dify相关组件(1)--前端Web
1. 什么是Dify? 官方介绍:Dify 是一款开源的大语言模型(LLM) 应用开发平台。它融合了后端即服务(Backend as Service)和 LLMOps 的理念,使开发者可以快速搭建生产级的生成式 AI 应用。 这是个组件式框架,即使是非技…...

对话|企业如何构建更完善的容器供应链安全防护体系
对话|企业如何构建更完善的容器供应链安全防护体系 云布道师 随着云计算和 DevOps 的兴起,容器技术和自动化成为软件开发中的必要手段,软件供应链也进入了自动化及 CI/CD 阶段。然而,容器技术和自动化虽然提升了软件的更新速度&…...
详解)
HTML5 缩放动画(Zoom In/Out)详解
HTML5 缩放动画(Zoom In/Out)详解 缩放动画是一种常见的视觉效果,用于使网页元素逐渐放大或缩小,从而吸引用户的注意力。下面将介绍如何使用 CSS 和 JavaScript 实现这种动画效果。 1. 使用 CSS 实现缩放动画 可以通过 CSS 的 …...

C语言——文件IO 【文件IO和标准IO区别,操作文件IO】open,write,read,dup2,access,stat
1.思维导图 2.练习 1:使用C语言编写一个简易的界面,界面如下 1:标准输出流 2:标准错误流 3:文件流 要求:按1的时候,通过printf输出数据,按2的时候,通过p…...

【C++习题】22.随机链表的复制
文章目录 题目:138. 随机链表的复制 - 力扣(LeetCode)代码: 题目:138. 随机链表的复制 - 力扣(LeetCode) 链接🔗:138. 随机链表的复制 - 力扣(LeetCode&…...

备考蓝桥杯:数据结构概念浅谈
目录 1数据结构的概念 什么是数据结构: 为什么要有数据结构 2.数据结构的三个组成要素 1.逻辑结构 2.存储结构 3.数据运算 3。算法好坏的度量(时间复杂度和空间复杂度) 时间复杂度计算 最优和平均和最差时间复杂度 计算时间复杂度例子 空间复…...

【TI毫米波雷达】DCA1000不使用mmWave Studio的数据采集方法,以及自动化实时数据采集
【TI毫米波雷达】DCA1000不使用mmWave Studio的数据采集方法,以及自动化实时数据采集 mmWave Studio提供的功能完全够用了 不用去纠结用DCA1000低延迟、无GUI传数据 速度最快又保证算力无非就是就是Linux板自己写驱动做串口和UDP 做雷达产品应用也不会采用DCA1000的…...

创建型模式3.建造者模式
创建型模式 工厂方法模式(Factory Method Pattern)抽象工厂模式(Abstract Factory Pattern)建造者模式(Builder Pattern)原型模式(Prototype Pattern)单例模式(Singleto…...

【集成学习】Boosting算法详解
文章目录 1. 集成学习概述2. Boosting算法详解3. Gradient Boosting算法详解3.1 基本思想3.2 公式推导 4. Python实现 1. 集成学习概述 集成学习(Ensemble Learning)是一种通过结合多个模型的预测结果来提高整体预测性能的技术。相比于单个模型…...

【Orca】Orca - Graphlet 和 Orbit 计数算法
Orca(ORbit Counting Algorithm)是一种用于对网络中的小图进行计数的有效算法。它计算网络中每个节点的节点和边缘轨道(4 节点和 5 节点小图)。 orca是一个用于图形网络分析的工具,主要用于计算图中的 graphlets&#…...

58. Three.js案例-创建一个带有红蓝配置的半球光源的场景
58. Three.js案例-创建一个带有红蓝配置的半球光源的场景 实现效果 本案例展示了如何使用Three.js创建一个带有红蓝配置的半球光源的场景,并在其中添加一个旋转的球体。通过设置不同的光照参数,可以观察到球体表面材质的变化。 知识点 WebGLRenderer …...
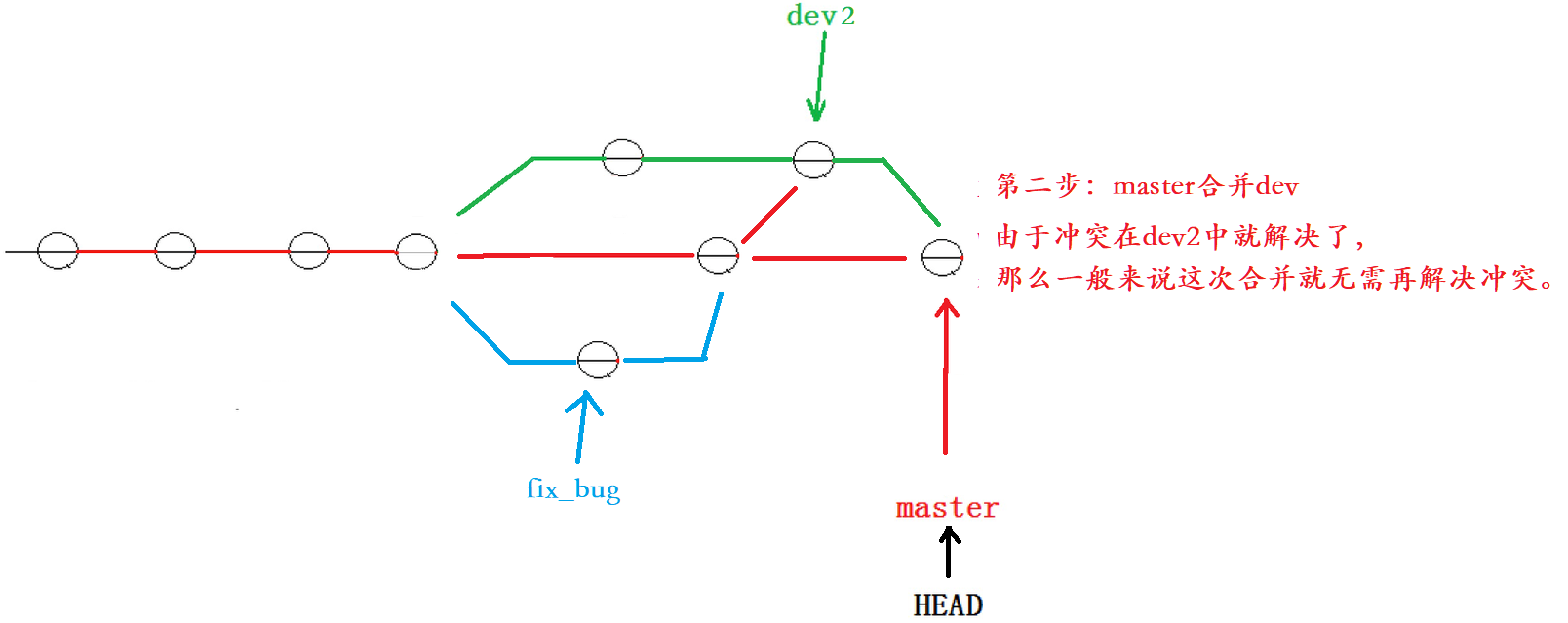
【Git原理和使用】Git 分支管理(创建、切换、合并、删除、bug分支)
一、理解分支 我们可以把分支理解为一个分身,这个分身是与我们的主身是相互独立的,比如我们的主身在这个月学C,而分身在这个月学java,在一个月以后我们让分身与主身融合,这样主身在一个月内既学会了C,也学…...

义乌购的反爬虫机制怎么应对?
在面对义乌购的反爬虫机制时,可以采取以下几种策略来应对: 1. 使用代理IP 义乌购可能会对频繁访问的IP地址进行限制,因此使用代理IP可以有效地隐藏爬虫的真实IP地址,避免被封禁。可以构建一个代理IP池,每次请求时随机…...

消息中间件面试
RabbitMQ 如何保证消息不丢失 消息重复消费 死信交换机 消息堆积怎么解决 高可用机制 Kafka 如何保证消息不丢失 如何保证消息的顺序性 高可用机制 数据清理机制 实现高性能的设计...

基于CLIP和DINOv2实现图像相似性方面的比较
概述 在人工智能领域,CLIP和DINOv2是计算机视觉领域的两大巨头。CLIP彻底改变了图像理解,而DINOv2为自监督学习带来了新的方法。 在本文中,我们将踏上一段旅程,揭示定义CLIP和DINOv2的优势和微妙之处。我们的目标是发现这些模型…...

利用Python爬虫获取API接口:探索数据的力量
引言 在当今数字化时代,数据已成为企业、研究机构和个人获取信息、洞察趋势和做出决策的重要资源。Python爬虫作为一种高效的数据采集工具,能够帮助我们自动化地从互联网上获取大量的数据。而API接口作为数据获取的重要途径之一,为我们提供了…...

告别复杂命令:3步搞定M3U8视频下载的终极指南
告别复杂命令:3步搞定M3U8视频下载的终极指南 【免费下载链接】N_m3u8DL-CLI-SimpleG N_m3u8DL-CLIs simple GUI 项目地址: https://gitcode.com/gh_mirrors/nm3/N_m3u8DL-CLI-SimpleG 你是否曾经遇到过这样的困扰?在网上找到了心仪的视频教程或精…...
)
Perplexity名言警句搜索深度解析(2024年Q2最新API行为逆向实测报告)
更多请点击: https://intelliparadigm.com 第一章:Perplexity名言警句搜索深度解析(2024年Q2最新API行为逆向实测报告) Perplexity 在 2024 年第二季度对 /search 端点实施了细粒度的请求签名验证与上下文指纹绑定机制࿰…...
)
告别实车测试!手把手教你用Vector VT平台搭建OBC/DCDC的HIL测试环境(附避坑指南)
新能源汽车OBC/DCDC控制器HIL测试环境搭建实战指南 在新能源汽车三电系统开发中,车载充电机(OBC)和DC/DC变换器的功能验证一直是工程师面临的挑战。传统实车测试不仅成本高昂,而且难以覆盖所有边界条件。硬件在环(HIL)测试技术通过将真实控制器接入虚拟车…...

Seraphine:英雄联盟玩家的终极智能助手,5分钟快速上手教程
Seraphine:英雄联盟玩家的终极智能助手,5分钟快速上手教程 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 你是否曾在英雄联盟对局中因为不了解队友对手的实力而输掉比赛?是…...

Windows进程注入技术深度解析:从DLL注入到反射式加载
1. 项目概述与核心价值在Windows安全研究、恶意软件分析乃至一些高级的软件开发场景中,“进程注入”是一个绕不开的核心技术点。简单来说,它指的是将一个代码模块(通常是DLL)或一段代码(Shellcode)加载到另…...

解决Service broker not enable. Please activete it using ‘ALTER DATABASE My Database SET ENABLE BROKER
目录 1.问题 2.解决办法 3.说明 1.问题 网站运行报错:Service broker not enable. Please activete it using ALTER DATABASE My Database SET ENABLE BROKER 2.解决办法 服务代理(Service Broker)未启用。请使用 ALTER DATABASE [数据库…...

OpenClaw小龙虾 Windows10一键部署包|小白友好10分钟搞定本地AI智能体
适配系统:Windows10 64 位(纯小白友好版) 核心优势:免命令行、免环境配置、解压即装,内置所有运行依赖,全程可视化操作,新手也能一次成功部署 2026 爆火的开源 AI 智能体! 本文专属&…...
)
C语言编程实战:用ASCII码表玩转字符大小写转换(附完整代码)
C语言编程实战:用ASCII码表玩转字符大小写转换(附完整代码) 在编程的世界里,字符处理是最基础却又最容易被忽视的技能之一。很多C语言初学者在学习过程中,往往对字符和字符串的操作感到困惑——为什么a和A是不同的&…...

终极指南:5分钟实现直播实时操作可视化
终极指南:5分钟实现直播实时操作可视化 【免费下载链接】input-overlay Show keyboard, gamepad and mouse input on stream 项目地址: https://gitcode.com/gh_mirrors/in/input-overlay 你是否曾在直播游戏时,观众好奇地问:"你…...
)
保姆级教程:在S32G274ARDB2上,用IPCF点亮RGB LED(附源码解析)
从零玩转S32G2核间通信:手把手实现IPCF控制RGB灯效 拿到S32G274A开发板的第一天,我就被那个三色RGB LED吸引了——这不仅是硬件调试的指示灯,更是验证核间通信的绝佳媒介。作为多核异构处理器,S32G2的A53与M7核心如何协同工作&…...