Python 数据建模完整流程指南
在数据科学和机器学习中,建模是一个至关重要的过程。通过有效的数据建模,我们能够从原始数据中提取有用的洞察,并为预测或分类任务提供支持。在本篇博客中,我们将通过 Python 展示数据建模的完整流程,包括数据准备、建模、评估和优化等步骤。
1. 导入必要的库
在进行任何数据分析或建模之前,首先需要导入必需的 Python 库。这些库提供了各种工具和算法,帮助我们更高效地完成任务。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
numpy和pandas用于数据处理。matplotlib和seaborn用于数据可视化。scikit-learn提供了用于数据预处理、模型训练和评估的工具。
2. 数据加载与查看
第一步是加载数据,通常数据存储在 CSV 文件、Excel 文件或者数据库中。在此示例中,我们假设数据存储在一个 CSV 文件中。
# 加载数据
df = pd.read_csv('your_dataset.csv')# 查看数据的基本信息
print(df.head())
print(df.info())
head()用于显示数据的前几行。info()可以查看数据的类型和缺失情况。
3. 数据清洗与预处理
数据清洗是数据分析中非常重要的一步。我们需要处理缺失值、重复值和异常值,确保数据的质量。
处理缺失值
# 查看缺失值
print(df.isnull().sum())# 用均值填充缺失值(对于数值型数据)
df.fillna(df.mean(), inplace=True)# 或者用中位数、最频繁值填充
# df.fillna(df.median(), inplace=True)
# df.fillna(df.mode().iloc[0], inplace=True)
删除重复值
# 删除重复行
df.drop_duplicates(inplace=True)
数据类型转换
# 将某一列转换为数值类型
df['column_name'] = pd.to_numeric(df['column_name'], errors='coerce')
4. 数据探索与可视化
在开始建模之前,我们需要对数据进行一些初步的分析和可视化,以便了解数据的分布、相关性以及潜在问题。
描述性统计
# 查看数值型数据的统计信息
print(df.describe())
数据可视化
# 绘制相关性热图
plt.figure(figsize=(10, 6))
sns.heatmap(df.corr(), annot=True, cmap='coolwarm')
plt.title('Correlation Heatmap')
plt.show()# 绘制特征分布
sns.histplot(df['feature_column'], kde=True)
plt.title('Feature Distribution')
plt.show()
这些图表帮助我们了解数据的基本分布、特征之间的关系以及可能需要进一步处理的部分。
5. 特征选择与数据分割
在机器学习建模中,我们需要选择合适的特征,并将数据分为训练集和测试集。
# 特征选择
X = df.drop('target_column', axis=1) # 删除目标列,选择特征列
y = df['target_column'] # 目标列# 数据分割:70% 用于训练,30% 用于测试
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
6. 数据标准化
有些机器学习算法对数据的尺度非常敏感,因此需要对数据进行标准化或归一化处理。
# 标准化数据
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
7. 选择合适的模型并训练
此步骤是数据建模的核心,选择一个适合问题的模型并训练它。在本例中,我们将使用一个简单的随机森林分类器。
# 创建随机森林分类器模型
model = RandomForestClassifier(n_estimators=100, random_state=42)# 训练模型
model.fit(X_train_scaled, y_train)
8. 模型评估
训练完成后,我们需要对模型进行评估,以判断它的性能。我们通常使用准确率、混淆矩阵、F1 分数等评估指标。
预测
# 对测试集进行预测
y_pred = model.predict(X_test_scaled)
评估准确率
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy * 100:.2f}%")
混淆矩阵和分类报告
# 混淆矩阵
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', xticklabels=['Class 0', 'Class 1'], yticklabels=['Class 0', 'Class 1'])
plt.title('Confusion Matrix')
plt.show()# 分类报告
print(classification_report(y_test, y_pred))
9. 模型优化与调参
为了提高模型的性能,可以进行超参数调优,或者选择不同的模型进行比较。我们可以使用 GridSearchCV 或 RandomizedSearchCV 来自动调整模型的超参数。
from sklearn.model_selection import GridSearchCV# 定义参数范围
param_grid = {'n_estimators': [100, 200, 300],'max_depth': [10, 20, 30],'min_samples_split': [2, 5, 10]
}# 创建 GridSearchCV 对象
grid_search = GridSearchCV(estimator=model, param_grid=param_grid, cv=3, verbose=2, n_jobs=-1)# 训练并调参
grid_search.fit(X_train_scaled, y_train)# 输出最佳参数
print("Best parameters:", grid_search.best_params_)
10. 模型部署
一旦我们得到了一个性能良好的模型,可以将它部署到生产环境中,供实际应用使用。常见的部署方法包括将模型保存到文件中,或者将其集成到 API 中供其他应用调用。
保存模型
import joblib# 保存模型
joblib.dump(model, 'random_forest_model.pkl')# 加载模型
loaded_model = joblib.load('random_forest_model.pkl')
结语
以上就是使用 Python 进行数据建模的完整流程。从数据加载、清洗到模型训练和评估,我们涵盖了常见的步骤。在实际工作中,你可能需要根据具体的数据集和问题进行调整,选择不同的算法和工具。希望本文能够帮助你理解和掌握数据建模的基本流程,提升你在机器学习项目中的实践能力。
相关文章:

Python 数据建模完整流程指南
在数据科学和机器学习中,建模是一个至关重要的过程。通过有效的数据建模,我们能够从原始数据中提取有用的洞察,并为预测或分类任务提供支持。在本篇博客中,我们将通过 Python 展示数据建模的完整流程,包括数据准备、建…...

深入学习RocketMQ
参考:RocketMQ从从入门到精通_rocketmq入门到精通-CSDN博客 1、消息的类型 普通消息 顺序消息 延时消息 批量消息 事务消息 2、在java中使用 2.1、pom.xml中加入依赖 <dependency><groupId>org.apache.rocketmq</groupId><artifactId…...

国产编辑器EverEdit - 扩展脚本:关闭所有未修改文档
1 扩展脚本:关闭所有未修改文档 1.1 应用场景 当用户打开过多文档时,部分文档已经修改,而大部分没有修改,为了减少在众多已打开文档中来回跳转的不便,可以将没有修改的文档全部关闭,但目前提供的快速关闭窗…...

数据结构二叉树-C语言
数据结构二叉树-C语言 1.树1.1树的概念与结构1.2树的相关术语1.3树的表示1.4树形结构实际运用场景 2.二叉树2.1概念与结构2.2特殊的二叉树2.2.1满二叉树2.2.2完全二叉树 2.3二叉树存储结构2.3.1顺序结构2.3.2链式结构 3.实现顺序结构的二叉树4.实现链式结构二叉树4.1前中后序遍…...

Python基于YOLOv8和OpenCV实现车道线和车辆检测
使用YOLOv8(You Only Look Once)和OpenCV实现车道线和车辆检测,目标是创建一个可以检测道路上的车道并识别车辆的系统,并估计它们与摄像头的距离。该项目结合了计算机视觉技术和深度学习物体检测。 1、系统主要功能 车道检测&am…...

代码随想录算法训练营第六十天|KM94.城市间货物运输Ⅰ|KM95.城市间货物运输Ⅱ|KM96.城市间货物运输Ⅲ
94. 城市间货物运输 I 2、Bellman_ford队列优化算法(又名SPFA) SPFA是对Bellman_ford算法的优化,由于Bellman_ford 算法 每次都是对所有边进行松弛,其实是多做了一些无用功。其实只需要对 上一次松弛的时候更新过的节点作为出发节…...

人工智能学习路线全链路解析
一、基础准备阶段(预计 2-3 个月) (一)数学知识巩固与深化 线性代数(约 1 个月): 矩阵基础:回顾矩阵的定义、表示方法、矩阵的基本运算(加法、减法、乘法)&…...

C++语言的学习路线
C语言的学习路线 C是一种强大的高级编程语言,广泛应用于系统软件、游戏开发、嵌入式系统和高性能应用等多个领域。由于其丰富的功能和灵活性,C是一门值得深入学习的语言。本文旨在为初学者制定一条系统的学习路线,帮助他们循序渐进地掌握C语…...
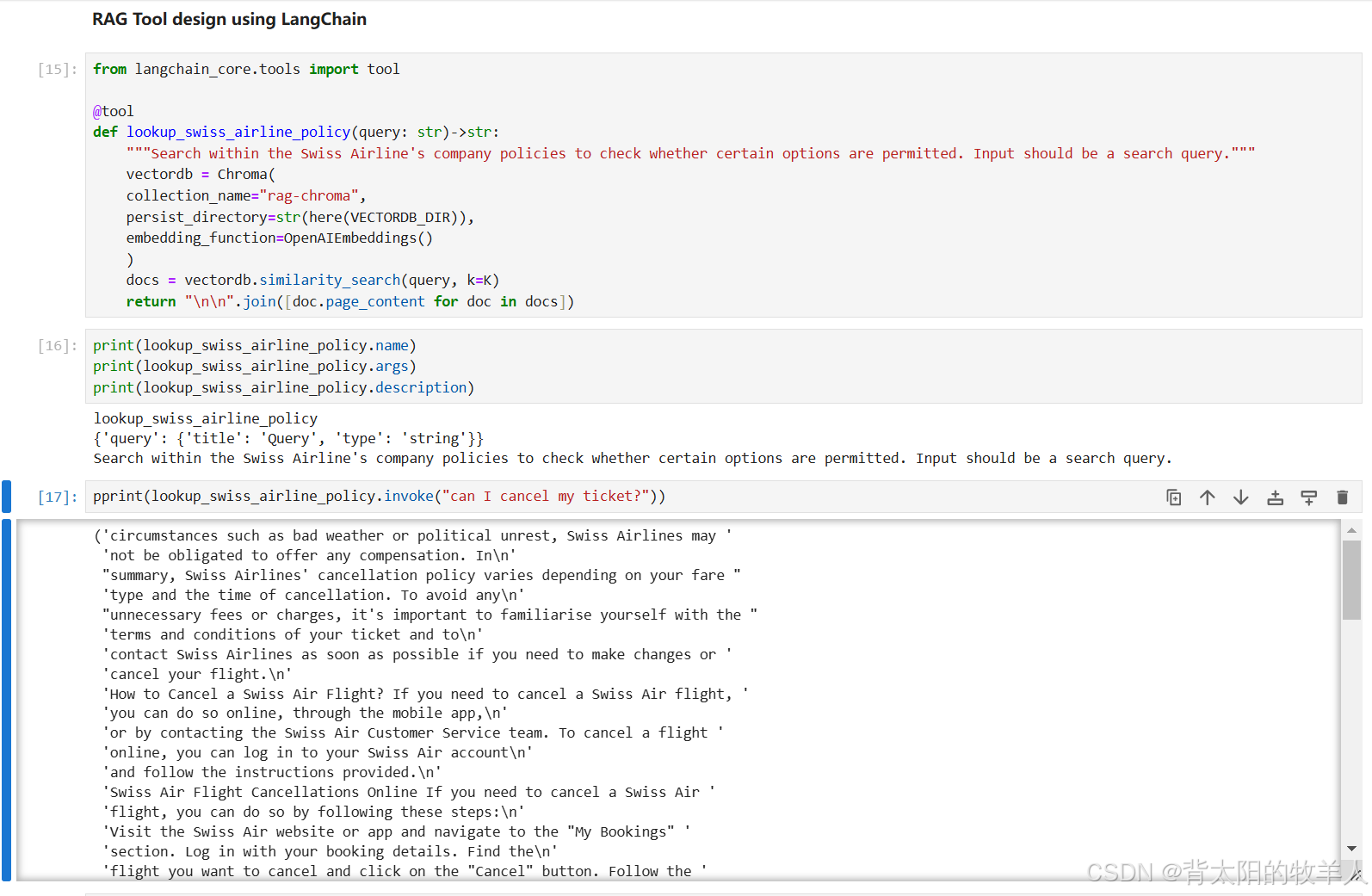
用于与多个数据库聊天的智能 SQL 代理问答和 RAG 系统(3) —— 基于 LangChain 框架的文档检索与问答功能以及RAG Tool的使用
介绍基于 LangChain 框架的文档检索与问答功能,目标是通过查询存储的向量数据库(VectorDB),为用户的问题检索相关内容,并生成自然语言的答案。以下是代码逻辑的详细解析: 代码结构与功能 初始化环境与加载…...
20250110doker学习记录
1.本机创建tts环境。用conda. 0.1安装。我都用的默认,你也可以。我安装过一次,如果修复,后面加 -u bash Anaconda3-2024.10-1-Linux-x86_64.sh等待一会。 (base) ktkt4028:~/Downloads$ conda -V conda 24.9.2学习资源 Conda 常用命令大…...

MPU6050: 卡尔曼滤波, 低通滤波
对于MPU6050(一种集成了三轴加速度计和三轴陀螺仪的惯性测量单元),对加速度值进行卡尔曼滤波,而对角速度进行低通滤波的选择是基于这两种传感器数据的不同特性和应用需求。以下是详细解释: 加速度值与卡尔曼滤波 为什么使用卡尔曼滤波? 噪声抑制: 加速度计信号通常包含…...

C++的标准和C++的编译版本
C的标准和C的编译版本:原理和概念 理解 C标准 和 C编译版本 的关系是学习 C 的一个重要部分。这两者虽然看似相关,但实际上分别涉及了不同的概念和技术。下面将通过层次清晰的解释,帮助新手理解这两个概念的差异、特点及其相互关系。 一、C标…...
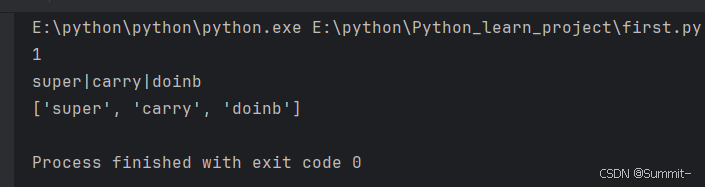
python学习笔记—17—数据容器之字符串
1. 字符串 (1) 字符串能通过下标索引来获取其中的元素 (2) 旧字符串无法修改特定下标的元素 (3) index——查找字符串中任意元素在整个字符串中的起始位置(单个字符或字符串都可以) tmp_str "supercarrydoinb" tmp_position1 tmp_str.index("s") tmp_p…...
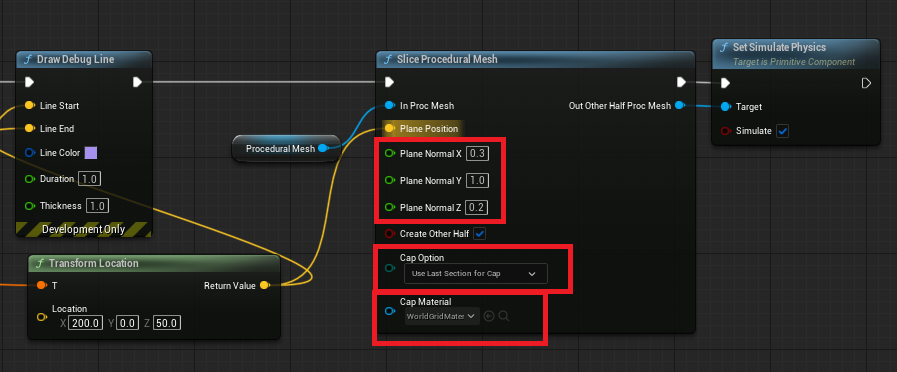
UE5 使用内置组件进行网格切割
UE引擎非常强大,直接内置了网格切割功能并封装为蓝图节点,这项功能在UE4中就存在,并且无需使用Chaos等模块。那么就来学习下如何使用内置组件实现网格切割。 1.配置测试用StaticMesh 对于被切割的模型,需要配置一些参数。以UE5…...
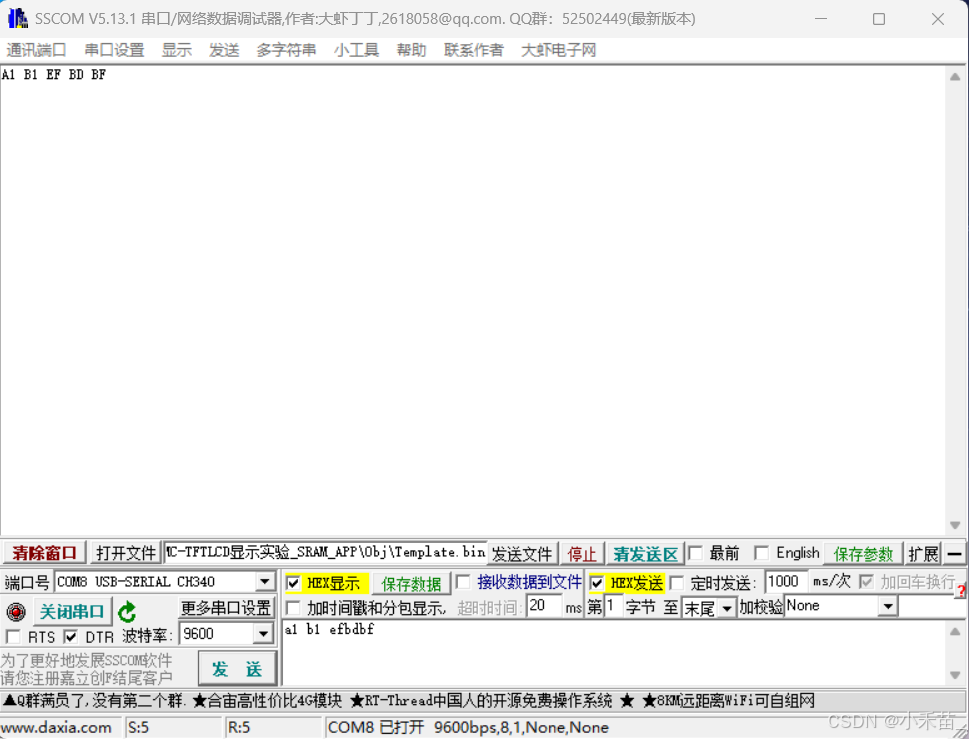
51单片机——串口通信(重点)
1、通信 通信的方式可以分为多种,按照数据传送方式可分为串行通信和并行通信; 按照通信的数据同步方式,可分为异步通信和同步通信; 按照数据的传输方向又可分为单工、半双工和全双工通信 1.1 通信速率 衡量通信性能的一个非常…...

Taro+Vue实现图片裁剪组件
cropper-image-taro-vue3 组件库 介绍 cropper-image-taro-vue3 是一个基于 Vue 3 和 Taro 开发的裁剪工具组件,支持图片裁剪、裁剪框拖动、缩放和输出裁剪后的图片。该组件适用于 Vue 3 和 Taro 环境,可以在网页、小程序等平台中使用。 源码 https:…...
PHP民宿酒店预订系统小程序源码
🏡民宿酒店预订系统 基于ThinkPHPuniappuView框架精心构建的多门店民宿酒店预订管理系统,能够迅速为您搭建起专属的、功能全面且操作便捷的民宿酒店预订小程序。 该系统不仅涵盖了预订、退房、WIFI连接、用户反馈、周边信息展示等核心功能,更…...
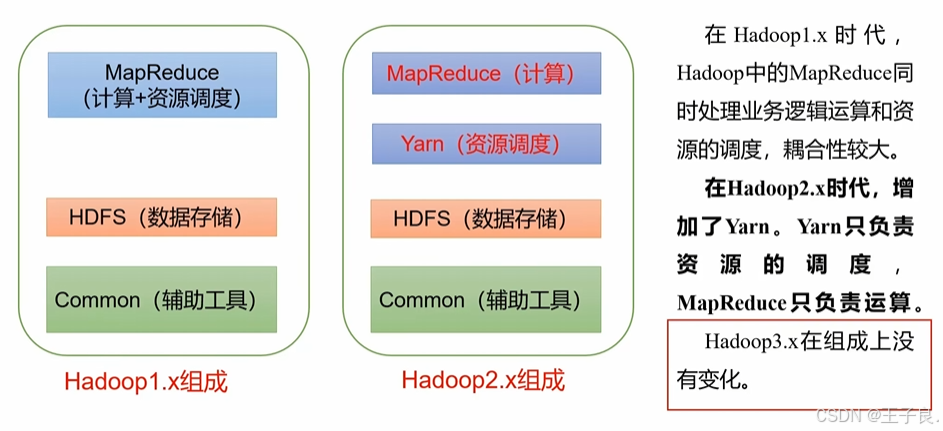
Hadoop3.x 万字解析,从入门到剖析源码
💖 欢迎来到我的博客! 非常高兴能在这里与您相遇。在这里,您不仅能获得有趣的技术分享,还能感受到轻松愉快的氛围。无论您是编程新手,还是资深开发者,都能在这里找到属于您的知识宝藏,学习和成长…...

VUE3 常用的组件介绍
Vue 组件简介 Vue 组件是构建 Vue 应用程序的核心部分,组件帮助我们将 UI 分解为独立的、可复用的块,每个组件都有自己的状态和行为。Vue 组件通常由模板、脚本和样式组成。组件的脚本部分包含了各种配置选项,用于定义组件的逻辑和功能。 组…...

deepin-Wine 运行器合并打包器和添加从镜像提取 DLL 的功能
Wine 运行器是一个图形化工具,旨在简化 Wine 环境的管理和使用。它不仅提供了运行和管理 Wine 容器的功能,还增加了打包器和从镜像提取 DLL 的功能。以下是该工具的详细介绍和使用方法。 一、工具概述 Wine 运行器是一个使用 Python3 的 tkinter 构建的图…...

360T7路由器无线中继保姆级教程:5分钟搞定信号扩展,告别WiFi死角
360T7路由器无线中继保姆级教程:5分钟搞定信号扩展,告别WiFi死角 你是否经常遇到这样的困扰:客厅WiFi信号满格,但卧室却时断时续;刷剧正到精彩处突然卡顿;游戏团战时延迟飙升...这些恼人的网络死角问题&…...

振弦采集模块设计:从传感器选型到数字信号处理的完整指南
1. 振弦采集读数模块:从物理振动到数字信号的完整旅程在工程测量、结构健康监测以及乐器数字化等领域,我们常常需要精确地捕捉一根弦或类似结构的振动信息。比如,监测桥梁拉索的张力变化、分析古筝琴弦的声学特性,或者检测工业设备…...

单词拆分----dp
思路:刚开始看的时候没有思路,但我看给的样例,可以多次遍历wordDict看。。。好像不太对准备看看题解。首先需要知道这道题的dp的公式代表这什么,dp[i]表示 字符串s从起始位置到位置i,能否被被拆分成字典中的单词&#…...

基于AVR单片机的无线图像侦检系统:从硬件选型到软件实现
1. 项目概述与核心价值最近在整理过去的项目资料,翻到了一个挺有意思的老项目——基于Atmel AVR单片机的无线图像侦检系统。虽然现在STM32、ESP32满天飞,各种高性能MCU和无线模块层出不穷,但这个项目在当年(以及现在某些特定场景下…...

STM32图像识别实战:从传统CV到TinyML的边缘AI部署
1. 项目概述:当STM32遇上图像识别在嵌入式开发领域,STM32系列微控制器因其出色的性能、丰富的外设和极高的性价比,早已成为工程师和爱好者的“瑞士军刀”。从简单的LED闪烁到复杂的电机控制、通信协议栈,STM32几乎无所不能。但提到…...

Agentic RAG的实现方式?
文档智能体开发正迎来“低门槛时代”。基于PaddleOCR与LangChain社区的集成合作,文心飞桨开发者进一步搭建了可视化管理工具ClawMaster——让开发者无需从零部署模型或编写复杂调用逻辑,10分钟即可跑通文档智能体工作流。与此同时,X-AnyLabel…...

Scarab空洞骑士模组管理器:5个步骤掌握现代模组管理艺术
Scarab空洞骑士模组管理器:5个步骤掌握现代模组管理艺术 【免费下载链接】Scarab An installer for Hollow Knight mods written with Avalonia. 项目地址: https://gitcode.com/gh_mirrors/sc/Scarab 还在手动解压、复制、配置空洞骑士模组吗?Sc…...

如何快速搭建微信智能机器人:7步实现多AI服务自动回复
如何快速搭建微信智能机器人:7步实现多AI服务自动回复 【免费下载链接】wechat-bot 🤖一个基于 WeChaty 结合 ChatGPT / Claude / Kimi / DeepSeek / Ollama等Ai服务实现的微信机器人 ,可以用来帮助你自动回复微信消息,或者社群分…...

革命性3步实现黑苹果自动化:OpCore Simplify智能化配置完全指南
革命性3步实现黑苹果自动化:OpCore Simplify智能化配置完全指南 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 还在为复杂的OpenCore配置…...

CANN/asc-devkit Erfc接口文档
Erfc 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/cann/…...