JSON.stringify 实现深度克隆的缺陷
在前端开发中,深克隆(Deep Clone)和浅克隆(Shallow Clone)是常见的操作。浅克隆和深克隆的区别主要体现在对象内部嵌套对象的处理方式上。
1. 浅克隆(Shallow Clone)
浅克隆是指创建一个新对象,但对于原对象中嵌套的对象,浅克隆只复制它们的引用,而不是创建新的对象。换句话说,浅克隆只是“浅复制”了对象的属性,嵌套的对象还是共享相同的引用。
🌰:
// 浅克隆
const shallowClone = (obj) => {return { ...obj };
};// 或者使用 Object.assign
const shallowClone2 = (obj) => {return Object.assign({}, obj);
};const obj1 = { name: 'John', address: { city: 'NY' } };
const obj2 = shallowClone(obj1);obj2.address.city = 'LA';console.log(obj1.address.city); // 输出 'LA'
console.log(obj2.address.city); // 输出 'LA'
2. 深克隆(Deep Clone)
深克隆是指创建一个新对象,并且递归地复制原对象中的所有属性,包括嵌套的对象(嵌套对象也会被克隆为新的对象)。这样,修改新对象不会影响到原对象,反之亦然。
1. 递归实现
// 深克隆实现(递归)
const deepClone = (obj) => {if (obj === null || typeof obj !== 'object') return obj;const newObj = Array.isArray(obj) ? [] : {}; // 判断是数组还是对象for (let key in obj) {if (obj.hasOwnProperty(key)) {newObj[key] = deepClone(obj[key]); // 递归克隆}}return newObj;
};
const obj1 = { name: 'John', address: { city: 'NY' }, hobbies: ['reading', 'gaming'] };
const obj2 = deepClone(obj1);
obj2.address.city = 'LA';
obj2.hobbies[0] = 'traveling';
console.log(obj1.address.city); // 输出 'NY'
console.log(obj2.address.city); // 输出 'LA'
console.log(obj1.hobbies[0]); // 输出 'reading'
console.log(obj2.hobbies[0]); // 输出 'traveling'
2. JSON 方法
JSON.parse(JSON.stringify(...)) :是前端开发中常用的一种快速实现深克隆的方法,但它也有一些缺陷。
const deepCloneUsingJSON = (obj) => {return JSON.parse(JSON.stringify(obj));
};const obj1 = { name: 'John', address: { city: 'NY' }, hobbies: ['reading', 'gaming'] };
const obj2 = deepCloneUsingJSON(obj1);obj2.address.city = 'LA';
obj2.hobbies[0] = 'traveling';console.log(obj1.address.city); // 输出 'NY'
console.log(obj2.address.city); // 输出 'LA'
console.log(obj1.hobbies[0]); // 输出 'reading'
console.log(obj2.hobbies[0]); // 输出 'traveling'
3. JSON.stringify 的缺陷
尽管其是一种快速且简单的深克隆方法,但它也有几个明显的缺陷:
1、无法克隆函数:JSON 序列化过程会丢失对象中的函数。例如:
const obj1 = { name: 'John', greet: () => console.log('Hello') };
const obj2 = JSON.parse(JSON.stringify(obj1));
console.log(obj2); // { name: 'John' }
obj2.greet(); // 报错:obj2.greet is not a function
2、无法处理 undefined:对象中的 undefined 值会被丢失,并且会在序列化过程中变成 null。
const obj1 = { value: undefined };
const obj2 = JSON.parse(JSON.stringify(obj1));console.log(obj2.value); // 输出: undefined
3、无法处理特殊对象:某些 JavaScript 特殊对象(如 Date、RegExp、Map、Set、Promise 等)无法正确克隆,变成普通的对象或丢失其原有属性。
const obj1 = { date: new Date(), map: new Map() };
const obj2 = JSON.parse(JSON.stringify(obj1));console.log(obj2); // { date: '2025-01-08T06:39:12.842Z', map: {} }
console.log(obj2.date instanceof Date); // 输出: false
console.log(obj2.map instanceof Map); // 输出: false4、循环引用无法处理:如果对象包含循环引用(即一个对象的属性引用了它自身),JSON.stringify 会抛出错误。
const obj1 = {};
obj1.self = obj1;const obj2 = JSON.parse(JSON.stringify(obj1));
// 报错:TypeError: Converting circular structure to JSON 无法转换递归结构
4. 深度克隆的缺陷和完善
在实际开发中,基于 JSON.stringify 的深克隆方法需要处理一下。
1、处理 undefined 和 null:在序列化之前,进行预处理,避免 undefined 变成 null,或者在反序列化时进行特殊处理。
2、处理循环引用:为防止循环引用导致的错误,可以使用 WeakMap 来存储已访问的对象,并在遇到已访问的对象时直接返回,避免无限递归。
3、支持 Date、RegExp 等特殊对象:在克隆过程中判断对象的类型,使用 Object.prototype.toString.call() 来判断,进行相应的处理。
5. 更健壮的深克隆代码
// 考虑循环引用
const cache = new WeakMap(); // 确保对象在外层销毁时,Map结构自动销毁,防止内存泄露
const deepClone = (obj) => {if (obj === null || typeof obj !== 'object') return obj;// obj是对象if (cache.has(obj)) {return cache.get(obj);}const newObj = Array.isArray(obj) ? [] : {}; // 判断是数组还是对象cache.set(obj, newObj);// 考虑原型if (Object.getPrototypeOf(obj) !== Object.prototype) {// newObj.__proto__ = Object.getPrototypeOf(obj);// orObject.setPrototypeOf(newObj, Object.getPrototypeOf(obj));}for (let key in obj) {// 考虑继承属性if (obj.hasOwnProperty(key)) {newObj[key] = deepClone(obj[key]); // 递归克隆}}return newObj;
};
class Person {constructor(name, age) {this.name = name;this.age = age;}eat() {console.log('eat');}
}
Person.prototype.hobby = 'game';
Person.prototype.say = function () {console.log('say');
};
const obj = new Person('张三', 18);
// 循环引用
obj.h = obj;
console.log(obj);
console.log(deepClone(obj)); // <ref *1> Person { name: '张三', age: 18, h: [Circular *1] }
总结
1、浅克隆:只复制对象的第一层,嵌套对象还是共享引用。
2、深克隆:递归复制整个对象,包括嵌套对象。
相关文章:

JSON.stringify 实现深度克隆的缺陷
在前端开发中,深克隆(Deep Clone)和浅克隆(Shallow Clone)是常见的操作。浅克隆和深克隆的区别主要体现在对象内部嵌套对象的处理方式上。 1. 浅克隆(Shallow Clone) 浅克隆是指创建一个新对象…...

深度解析如何使用Linux中的git操作
1.如何理解版本控制 →Git&&gitee||github 多版本控制面对善变的甲方 版本控制是一种用于管理文件或代码变更的系统,帮助团队或个人追踪项目的历史记录,并支持多方协作开发。它在软件开发和文档管理中尤为重要,但也适用于其他需要追…...

el-table 合并单元格
参考文章:vue3.0 el-table 动态合并单元格 - flyComeOn - 博客园 <el-table :data"tableData" border empty-text"暂无数据" :header-cell-style"{ background: #f5f7fa }" class"parent-table" :span-method"obj…...

Redis 三大问题:缓存穿透、缓存击穿、缓存雪崩
Redis 作为高性能的内存数据库,广泛应用于缓存场景。然而,在实际使用中,可能会遇到三大经典问题:缓存穿透、缓存击穿 和 缓存雪崩。这些问题如果不加以解决,可能会导致系统性能下降甚至崩溃。 1. 缓存穿透 问题描述 …...

常用字符串处理函数
常用字符串处理函数 strcspn函数原型参数说明返回值使用示例注意事项 strpbrk函数原型参数说明返回值使用示例 strcasecmp函数原型参数说明返回值使用示例注意事项 strcspn strcspn 是一个 C 和 C 标准库函数,用于计算一个字符串中不包含任何指定字符的最长前缀的长…...

Pathview包:整合表达谱数据可视化KEGG通路
Pathview是一个用于整合表达谱数据并用于可视化KEGG通路的一个R包,其会先下载KEGG官网上的通路图,然后整合输入数据对通路图进行再次渲染,从而对KEGG通路图进行一定程度上的个性化处理,并且丰富其信息展示。(KEGG在线数…...

seleniun 自动化程序,python编程 我监控 chrome debug数据后 ,怎么获取控制台的信息呢
python 好的,使用 Python 来监控 Chrome 的调试数据并获取控制台信息,可以使用 websocket-client 库来连接 Chrome 的 WebSocket 接口。以下是一个详细的示例: 1. 安装必要的库 首先,你需要安装 websocket-client 库。可以使用…...

SQL中的数据库对象
视图:VIEW 概念 ① 虚拟表,本身不存储数据,可以看做是存储起来的SELECT语句 ② 视图中SELECT语句中涉及到的表,称为基表 ③ 针对视图做DML操作,对影响到基表中的数据,反之亦然 ④ 创建、删除视图本身&#…...

DeepSeek:性能强劲的开源模型
deepseek 全新系列模型 DeepSeek-V3 首个版本上线并同步开源。登录官网 chat.deepseek.com 即可与最新版 V3 模型对话。 性能对齐海外领军闭源模型 DeepSeek-V3 为自研 MoE 模型,671B 参数,激活 37B,在 14.8T token 上进行了预训练。 论…...

医疗可视化大屏 UI 设计新风向
智能化交互 借助人工智能与机器学习技术,实现更智能的交互功能。如通过语音指令或手势控制来操作大屏,医护人员无需手动输入,可更便捷地获取和处理信息。同时,系统能根据用户的操作习惯和数据分析,自动推荐相关的医疗…...

从企业级 RAG 到 AI Assistant , Elasticsearch AI 搜索技术实践
文章目录 01 AI 搜索落地的挑战02 Elasticsearch 向量性能 5 倍提升03 Elasticsearch 企业版 AI 能力全面解读04 阿里云 Elasticsearch 将准确率提升至 95%05 AI Assistant 集成通义千问大模型实现 AI Ops01 AI 搜索落地的挑战 在过去一年中,基座大模型技术的快速迭代推动了 …...

TypeScript语言的并发编程
TypeScript语言的并发编程 引言 随着现代应用程序的复杂性不断增加,性能和用户体验的重要性显得尤为突出。在这种背景下,并发编程应运而生,成为提升应用程序效率的重要手段。在JavaScript及其超集TypeScript中,尽管语言本身是单…...

benchANT 性能榜单技术解读 Part 1:写入吞吐
近期,国际权威数据库性能测试榜单 benchANT 更新了 Time Series: Devops(时序数据库)场景排名,KaiwuDB 数据库在 xsmall 和 small 两类规格下的时序数据写入吞吐、查询吞吐、查询延迟、成本效益等多项指标刷新榜单原有数据纪录。在…...

虚拟机防火墙管理
虚拟机防火墙管理 在网络防护方面,PVE提供了相当良好的防火墙管理功能,并且可以适用于节点实体机、客体机、让客体机内不需要另外再安装软体防火墙,对于效能与统一管理大有助益,管理者可以方便一次管理所有的防火墙规则࿰…...

Nginx反向代理请求头有下划线_导致丢失问题处理
后端发来消息说前端已经发了但是后端没收到请求。 发现是下划线的都没收到,搜索之后发现nginx默认request的header中包含’_’时,会自动忽略掉。 解决方法是:在nginx里的nginx.conf配置文件中的http部分中添加如下配置: unders…...
【STM32+CubeMX】 新建一个工程(STM32F407)
相关文章: 【HAL库】 STM32CubeMX 教程 1 --- 下载、安装 目录 第一部分、新建工程 第二部分、工程文件解释 第三部分、编译验证工程 友情约定:本系列的前五篇,为了方便新手玩家熟悉CubeMX、Keil的使用,会详细地截图每一步Cu…...
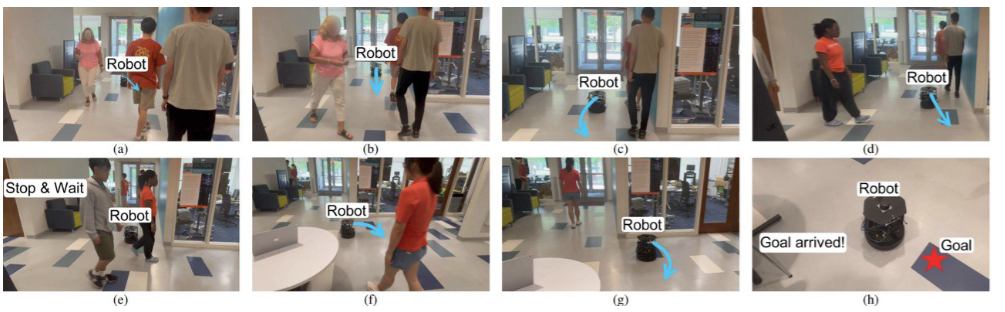
机器人避障不再“智障”:HEIGHT——拥挤复杂环境下机器人导航的新架构
导读: 由于环境中静态障碍物和动态障碍物的约束,机器人在密集且交互复杂的人群中导航,往往面临碰撞与延迟等安全与效率问题。举个简单的例子,商城和车站中的送餐机器人往往在人流量较大时就会停在原地无法运作,因为它不…...

H2数据库在单元测试中的应用
H2数据库特征 用比较简洁的话来介绍h2数据库,就是一款轻量级的内存数据库,支持标准的SQL语法和JDBC API,工业领域中,一般会使用h2来进行单元测试。 这里贴一下h2数据库的主要特征 Very fast database engineOpen sourceWritten…...

部署HugeGraph
部署HugeGraph 这里以hugegraph1.2.0为例子,演示一下如何安装部署hugegraph 一、下载并安装JDK11 下载JDK11 https://www.oracle.com/java/technologies/downloads/#java11 使用scp命令将安装包上传到服务器 scp /path/to/local/file usernameserver_ip:/path/…...
)
2025年第三届“华数杯”国际赛A题解题思路与代码(Matlab版)
游泳竞技策略优化模型代码详解(MATLAB版) 第一题:速度优化模型 本部分使用MATLAB实现游泳运动员在不同距离比赛中的速度分配策略优化。 1. 模型概述 模型包含三个主要文件: speed_optimization.m: 核心优化类plot_speeds.m: …...

3个核心功能+5个实战技巧:用B站神奇弹幕彻底解放你的直播双手
3个核心功能5个实战技巧:用B站神奇弹幕彻底解放你的直播双手 【免费下载链接】MagicalDanmaku 本仓库及所有相关项目已永久停止开发、维护和任何形式的分发。 项目地址: https://gitcode.com/gh_mirrors/bi/MagicalDanmaku 你是否还在直播时手忙脚乱地回复弹…...

通过curl命令快速测试Taotoken接口连通性与返回格式
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令快速测试Taotoken接口连通性与返回格式 在集成大模型服务时,直接使用curl命令进行接口测试是一种高效、轻…...

垂直搜索选型避坑指南,为什么83%的企业在DeepSeek V2.1升级后节省了67%标注成本?
更多请点击: https://codechina.net 第一章:垂直搜索选型避坑指南,为什么83%的企业在DeepSeek V2.1升级后节省了67%标注成本? 垂直搜索系统选型绝非简单替换关键词引擎——它直击领域知识建模、语义对齐与标注闭环三大痛点。Deep…...

模板 ID 配置化: “公众号路由 + 模板消息发送” 封装成一个干净的业务 Service
文章目录 引言 I “公众号路由 + 模板消息发送” 多公众号 同模板不同 ID 公众号实例 公众号路由 模板消息发送 Service(业务层 ✅) 异步调用 II 公众号账号配置【升级版】 账号配置 启用配置 模板 ID 解析器 公众号 Router(升级版 ✅) III 路由(Redis 版本) WxRedisOps…...

如何在5分钟内掌握VSCode Mermaid图表实时预览:开发者终极指南
如何在5分钟内掌握VSCode Mermaid图表实时预览:开发者终极指南 【免费下载链接】vscode-mermaid-preview Previews Mermaid diagrams 项目地址: https://gitcode.com/gh_mirrors/vs/vscode-mermaid-preview 还在为编写技术文档时需要在代码编辑器与图表预览工…...

毕业设计别再只做温度计了!用STM32打造多功能测量仪,让你的毕设脱颖而出
突破传统:用STM32打造智能测量仪器的毕业设计实战指南 当毕业设计季来临,许多电子工程专业的学生陷入了选题困境——温度计、蓝牙小车、智能家居控制...这些被无数前辈重复实现的项目早已失去了新意。如何在众多相似作品中脱颖而出?本文将带你…...

体验Taotoken多模型路由带来的高稳定性与低延迟响应
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 体验Taotoken多模型路由带来的高稳定性与低延迟响应 在构建依赖大模型能力的应用时,开发者最关心的两个核心指标往往是…...

避开这些坑:Tessent Shell中MBIST流程的DRC检查与调试指南
避开这些坑:Tessent Shell中MBIST流程的DRC检查与调试指南 在芯片设计领域,可测试性设计(DFT)是确保产品质量的关键环节。而作为DFT的重要组成部分,存储器内建自测试(MBIST)的实现质量直接影响着…...

华硕笔记本终极控制工具G-Helper:如何用免费轻量软件完全替代臃肿的Armoury Crate?
华硕笔记本终极控制工具G-Helper:如何用免费轻量软件完全替代臃肿的Armoury Crate? 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Stri…...

Sunshine终极指南:8步搭建你的个人游戏串流服务器
Sunshine终极指南:8步搭建你的个人游戏串流服务器 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 想要在任何设备上流畅玩PC游戏吗?Sunshine是一款免费开源…...