KGA:AGeneral Machine Unlearning Framework Based on Knowledge Gap Alignment
文章目录
- 摘要
- 1 引言
- 2 相关工作
- 3 符号与定义
- 4 我们的 KGA 框架
- 4.1 KGA框架
- 知识差距对齐
- 目标
- 4.2 KGA在自然语言处理任务中的应用
- 文本分类
- 机器翻译
- 响应生成
- 5 实验设置
- 数据集
- 评估指标
- 参数设置
- 比较方法
- 6 实验结果
- 6.1 主要比较结果
- 6.2 KGA 的优越性分析
- 降低语言模型概率比较
- 6.3 NLP 中去学习的分析
- 删除不同难度级别的实例
- 去学习包含特定词语的实例
- 进一步分析
- 删除数量的影响
- 基模型的影响
- 7 结论
摘要
最近关于“被遗忘权”的立法引发了对机器去学习的关注,其中训练模型具备忘记特定训练实例信息的功能,就好像这些实例从未存在于训练集中一样。之前的研究主要集中在计算机视觉场景上,较少关注自然语言处理(NLP)领域的去学习要点,而文本数据中包含比图像更明确和敏感的个人信息。在本文中,我们提出了一种称为KGA的通用去学习框架,以引导模型的遗忘。与之前的研究试图恢复梯度或强迫模型接近某一特定分布不同,KGA保持了分布差异(即知识差距),这放宽了分布假设。此外,我们首次将去学习方法应用于各种NLP任务(即分类、翻译、响应生成),并提出了一些具有针对性的去学习评估指标。在大规模数据集上的实验表明,KGA在基准测试中表现出全面的改进,广泛的分析进一步验证了KGA的有效性,并为NLP任务的去学习提供了见解。
1 引言
如今,机器学习模型通常使用大量从个人用户收集的数据进行训练。这些个人数据本质上是敏感的,因为它可能包含个人地址和医疗记录等信息。训练好的模型可能无意中侵犯用户隐私,因为其参数永久编码了个人信息及其衍生信息。因此,机器去学习(Machine Unlearning,MU)(Romero et al., 2007;Karasuyama和Takeuchi, 2009;Cao和Yang, 2015)在研究和工业界越来越受到关注,其目标是使模型能够忘记训练集中某些特定的数据,同时保持现有模型的性能。除了隐私方面的好处,MU还可以解决忘记有害和不良数据的问题(Welbl et al., 2021)。
虽然从后端数据库中删除数据是直接的,但对于机器学习模型来说,删除它们对数据的知识却是一个挑战。一种直观的去学习方法是从头开始重新训练模型,同时将“待遗忘”的数据从训练集中删除。然而,鉴于大型模型的繁荣,这种重新训练方法在计算上是昂贵的;在实际应用中,频繁的数据删除请求使得持续重新训练变得不切实际。此外,深度学习模型是基于大规模数据训练的黑箱函数。由于模型权重与数据之间的关系不明确,知道在去学习中应该修正哪些权重部分是困难的。因此,迫切需要开发一种高效的去学习方法。
现有的机器去学习研究主要集中在计算机视觉应用上,例如图像分类(Golatkar et al., 2020a,b;Mehta et al., 2022),而对自然语言处理(NLP)领域的去学习关注较少,而文本数据中包含比图像更明确和敏感的个人信息(例如,家庭地址、电话号码、社交关系等)。此外,目前的去学习方法仅能高效处理少量的数据删除请求(Bourtoule et al., 2021),而NLP应用中的删除请求可能达到数百个。此外,当前基于梯度计算的去学习方法(Mehta et al., 2022)难以应用于通常基于Seq2Seq框架的NLP生成模型,这些模型在不同的时间戳之间包含复杂的注意力机制。考虑到去学习在NLP中的重要性和挑战,我们提出了KGA——一种基于知识差距对齐的通用机器去学习方法,并将KGA应用于NLP任务。KGA的灵感来自于一项通用的知识适应工作(Khan和Swaroop, 2021),其中采用权重和函数空间先验来重构模型的梯度。与Khan和Swaroop(2021)针对包括数据删除在内的适应任务的通用解决方案相比,但难以扩展到复杂神经网络,我们的方法KGA从知识差距对齐的角度专注于数据删除,且易于推广到深度网络。本文中的知识差距定义为用不同数据训练的两个结构上相同模型的预测分布之间的距离。通过对齐知识差距,我们迫使两组模型的行为相似。此外,与只能处理少量删除请求(Bourtoule et al., 2021)、对模型输出持有强假设(Chundawat et al., 2022),或者不适用于复杂生成任务(Mehta et al., 2022)的现有去学习方法不同,KGA能够高效处理大量删除请求,同时保持准确性,并且易于适用于各种模型和任务,前提假设较为宽松。此外,我们将KGA应用于各种NLP任务(即分类、翻译和响应生成),并定制特定于文本的评估指标。来自各方面的实验结果和进一步分析表明,我们的KGA在性能维护和去学习效率方面通常优于基准,同时在不同场景和模型之间保持一致性。为了更好地验证和分析去学习的有效性,提供了模型在去学习前后如何将德语翻译成英语的有趣探索。
简而言之,本文的主要贡献包括:
- 我们提出了一种基于知识差距对齐的NLP任务去学习解决方案(即KGA),可以高效和有效地执行去学习。
- 在三个大规模数据集上进行的实验以及新制定的特定于文本的评估指标验证了KGA的有效性。
- 我们进行了广泛的实验和分析,以确认KGA在不同场景下的去学习效果。
2 相关工作
当前的去学习研究可以分为两类:精确去学习和近似去学习。我们简要介绍如下。
精确去学习:精确去学习能够确保从模型中删除的数据的影响被彻底去除。Cao和Yang(2015)通过统计查询方法探讨了朴素贝叶斯分类器的精确去学习,而Ginart等人(2019)研究了k-means聚类的删除算法,但这些方法无法扩展到可能拥有数百万参数的深度神经网络。至于最近在神经模型去学习方面的努力,Bourtoule等人(2021)提出了一种名为SISA的通用方法,该方法首先将原始数据集划分为多个不重叠的部分,然后设计有效的机制来聚合使用这些部分训练的模型。在处理数据删除时,该方法只需重新训练受影响部分训练的模型。然而,研究表明,当删除请求数量较大时,基于SISA的方法效果不佳,并且我们必须在训练和去学习过程中维护整个数据集,这在实际操作中是不可行的。
近似去学习:这一类别的方法试图使模型的行为尽可能接近精确去学习模型。近似去学习的受欢迎程度源于对更高效和成本更低的去学习的需求,因此牺牲了精确性。Golatkar等人(2020a);Guo等人(2019);Koh和Liang(2017);Mehta等人(2022)主要通过计算模型在剩余数据上的正则化经验风险的扰动来处理去学习请求。然而,这种方法需要计算训练数据上的海森矩阵和删除数据的梯度,这仍然是耗时的。(Chundawat等人,2022)假设去学习后的模型在遗忘数据上的表现应与随机初始化的模型相似,这不恰当,因为去学习的目标是去除遗忘数据的影响(充当未见数据),而不是让模型无法处理遗忘数据。然而,现有的知识适应方法要么要求强假设,要么在基于神经网络的模型上表现不佳(Khan和Swaroop,2021)。
与上述工作不同,KGA并不强制模型在遗忘数据上接近某一特定分布,而是保持两个模型对之间的分布差异(即知识差距)。这减弱了假设,因为它适用于任何分布的遗忘数据,从而也适用于更现实的场景,同时仍然确保模型的性能。
3 符号与定义
符号:我们用 Z Z Z表示示例空间,即数据实例或样本的空间。所有可能训练数据集的集合可以表示为 Z = 2 Z Z = 2^Z Z=2Z。训练数据集 D ⊆ Z D \subseteq Z D⊆Z 被给定为输入。给定 D D D,我们从假设空间 ( H ) 中训练一个机器学习模型。训练模型的过程是通过学习算法来实现的,记作函数 A : Z → H A: Z \rightarrow H A:Z→H。训练好的模型记作 A ( D ) A(D) A(D)。接下来,我们用函数 ( U ) 表示去学习机制,它接受训练数据集 D ⊆ Z D \subseteq Z D⊆Z、一个遗忘集 D f ⊆ D D_f \subseteq D Df⊆D(包含需要删除的数据)以及模型 A ( D ) A(D) A(D)作为输入,并返回一个去学习后的模型 U ( D ∖ D f , A ( D ) ) ∈ H U(D \setminus D_f, A(D)) \in H U(D∖Df,A(D))∈H。
近似去学习定义:接下来,我们给出近似去学习的一个代表性定义,特别是基于 Guo 等人(2019)的定义。给定 ϵ > 0 \epsilon > 0 ϵ>0,如果去学习机制 U U U 对学习算法 A A A 执行了认证删除,那么对于所有 T ⊆ D T \subseteq D T⊆D 和 D f ⊆ D D_f \subseteq D Df⊆D都有:
Pr ( U ( D ∖ D f , A ( D ) ) ∈ T ) Pr ( A ( D ∖ D f ) ∈ T ) ≤ ϵ , \frac{\text{Pr}(U(D \setminus D_f, A(D)) \in T)}{\text{Pr}(A(D \setminus D_f) \in T)} \leq \epsilon, Pr(A(D∖Df)∈T)Pr(U(D∖Df,A(D))∈T)≤ϵ,
近似去学习的目标可以总结为:遗忘需要遗忘的数据,同时保持模型的性能。
4 我们的 KGA 框架
KGA去学习方法受到一般知识适应工作的启发(Khan和Swaroop,2021),在该工作中,采用权重和函数空间先验来重构模型的梯度。与Khan和Swaroop(2021)不同的是,如果将其应用于神经网络等非线性模型时,无法准确恢复梯度,而KGA可以从知识差距对齐的角度处理各种神经网络的数据删除请求。
4.1 KGA框架
KGA的输入可以分为两个部分:数据和模型。输入数据包括之前的训练数据 ( D )、需要遗忘的数据 ( D_f ),以及一小部分额外的数据 ( D_n ) 来协助去学习,其中 D n ∩ D = ∅ D_n \cap D = \emptyset Dn∩D=∅。除了数据外,我们还有模型 A ( D ) A(D) A(D) 作为输入,它是用数据 ( D ) 训练的原始模型,该模型需要进行去学习(在本文后续部分简写为 ( A_D ))。KGA的输出是一个模型 ( A ),其参数以 ( A_D ) 初始化,并通过我们KGA去学习机制进一步更新,以删除 ( D_f )。
为了执行去学习,我们首先分别基于数据 ( D_n ) 和 ( D_f ) 训练两个模型 ( A_n ) 和 ( A_f )。( A_D )、( A_n ) 和 ( A_f ) 的架构应该相同。( A_n )(( A_f ))可以通过将 ( D_n )(( D_f ))与一小部分 ( D_r = D \setminus D_f ) 结合或者基于一些预训练的语言模型进行微调来确保性能,因为在某些情况下,需要遗忘的数据 ( D_f ) 可能很少。
我们重新框定并总结了两个目标,以实现第3节定义的近似去学习。这两个目标是:目标1:使输出模型 ( A ) 在 ( D_f ) 上的行为类似于其在任何看不见的数据(即未用于训练的数据)上的行为;目标2:维持模型 ( A ) 在 ( D_r ) 上的性能。
知识差距对齐
在本工作中,知识差距被定义为两个具有相同架构但用不同数据训练的模型的预测分布之间的距离。通过对齐两个知识差距,我们使得两组模型的性能相似。
为了实现目标1,我们期望目标模型 ( A ) 在数据 ( D_f ) 上的输出分布(记作 ( A(D_f) ))类似于 ( A_D(D_n) ),其中 ( D_n ) 应该是与 ( D ) 外部的集合,但具有相似的分布。由于 ( D_n ) 中的实例可能与 ( D_f ) 具有不同的标签和特征,因此直接推导 ( A(D_f) ) 与 ( A_D(D_n) ) 的输出分布是困难的。因此,我们转而模仿两组模型之间的知识差距:
A = arg min A dis ( D n ) ( A D A n ) + dis ( D f ) ( A A f ) A = \arg\min_{A} \text{dis}(D_n)(A_D A_n) + \text{dis}(D_f)(A A_f) A=argAmindis(Dn)(ADAn)+dis(Df)(AAf)
其中, dis ( D ) ( A 1 A 2 ) \text{dis}(D)(A_1 A_2) dis(D)(A1A2) 表示模型 A 1 A_1 A1 和 A 2 A_2 A2 在数据 ( D ) 上输出分布的差异,可以通过KL散度、Bregman散度或其他分布距离测量来评估。
由于 ( A_n ) 和 ( A_f ) 分别在 ( D_n ) 和 ( D_f ) 上训练,我们期望在将 ( D_f ) 输入到 ( A ) 和 ( A_f ) 时,知识差距应与将 ( D_n ) 输入到 ( A_D ) 和 ( A_n ) 时相似。这个假设是基于相同架构在处理具有相似分布的已知(即用于训练)和未知数据时可以观察到相似的知识缺失。我们认为,成功的去学习方法应使目标模型 ( A ) 将 ( D_f ) 视为未见数据。
对于目标2,我们在处理剩余数据 ( D_r ) 时保持模型 ( A ) 的能力。我们将原始模型 ( A_D ) 视为老师,直接最小化在 ( D_r ) 中输入样本到 ( A ) 和 ( A_D ) 时输出分布的距离。
目标
在我们的实现中,我们使用KL散度来测量两个模型输出之间的分布距离。因此,知识差距对齐目标定义为:
L a = ∑ ( y , z ) ∈ ( D f , D n ) K L [ P r ( A ) ( y ) ∣ ∣ P r ( A f ) ( y ) ] + ∑ ( y , z ) ∈ ( D f , D n ) K L [ P r ( A D ) ( z ) ∣ ∣ P r ( A n ) ( z ) ] L_a = \sum_{(y,z) \in (D_f, D_n)} KL[Pr(A)(y) || Pr(A_f)(y)] + \sum_{(y,z) \in (D_f, D_n)} KL[Pr(A_D)(z) || Pr(A_n)(z)] La=(y,z)∈(Df,Dn)∑KL[Pr(A)(y)∣∣Pr(Af)(y)]+(y,z)∈(Df,Dn)∑KL[Pr(AD)(z)∣∣Pr(An)(z)]
其中 ( Pr(A)(z) ) 是给定输入 ( z ) 的模型 ( A ) 的输出分布,( KL(a || b) ) 测量分布 ( a ) 和 ( b ) 之间的KL散度。( y ) 和 ( z ) 分别来自 ( D_n ) 和 ( D_f )。我们随机抽样实例对 ( (y, z) ) 作为更新批次,以减轻对特定样本的过拟合。
保持 ( D_r ) 上性能的目标是另一个KL散度,测量 ( A ) 和 ( A_D ) 在 ( D_r ) 上的输出分布:
L r = ∑ x ∈ D r K L [ P r ( A ) ( x ) ∣ ∣ P r ( A D ) ( x ) ] L_r = \sum_{x \in D_r} KL[Pr(A)(x) || Pr(A_D)(x)] Lr=x∈Dr∑KL[Pr(A)(x)∣∣Pr(AD)(x)]
这两个目标在去学习期间共同优化,以同时实现目标1和目标2。因此,最终目标定义为:
L = L a + L r L = L_a + L_r L=La+Lr
为了提高去学习效率,我们需要找到模型 ( A ) 在去学习过程中达到所需性能的最早时间。然而,与传统的机器学习算法不同,我们很难找到合适的验证集来验证性能,因为 ( D_f ) 也包含在训练过程中。为了解决这个问题,我们使用一个超参数 ( 0 < \beta < 1 ) 来控制训练。具体来说,我们将首先评估在训练前 ( \text{dis}(D_n)(A_D A_n) ) 和 ( \text{dis}(D_f)(A_D A_f) ) 之间的平均知识差距,记作 ( G )。如果对应的平均知识差距达到 ( G ),则训练停止。我们在算法1中总结了KGA。
4.2 KGA在自然语言处理任务中的应用
我们并不限制模型 ( A() ) 的格式,因为我们提出的去学习方法是通用的,可以应用于各种神经网络架构。我们选择了三个自然语言处理任务(即文本分类、机器翻译和响应生成)来展示我们去学习方法的有效性。
文本分类
文本分类任务将文本句子作为输入,并输出在预定义类别上的概率分布。我们遵循 Mehta 等人(2022)的研究,对预训练模型 DistilBERT(Sanh 等人,2019)进行微调,以完成文本分类。DistilBERT 是 BERT(Devlin 等人,2019)模型的蒸馏版本,包含多个 Transformer 编码器层以提取特征。其输入形式为 w c = [ [ C L S ] ; w 1 ; w 2 ; … ; w C ] wc = [[CLS]; w_1; w_2; \ldots; w_C] wc=[[CLS];w1;w2;…;wC]。 C L S CLS CLS 标记的输出表示进一步馈入分类器,以推导每个类别的概率。
机器翻译
机器翻译任务将一种语言中的句子作为输入,并输出相应的翻译到另一种语言。我们遵循基于 Transformer 的一般编码器-解码器框架,其中编码器总结源句子,解码器将基于源表示以自回归的方式生成目标句子。除了 Transformer,我们还验证了我们的去学习方法在其他架构中的有效性,包括 LSTM 和预训练语言模型 BART(Lewis 等人,2020)。
响应生成
响应生成和机器翻译都是生成任务,其目标是根据给定的源内容生成文本。在响应生成中,给定的源内容是两个对话者之间的对话,期望预测下一个响应的内容。生成的模型与机器翻译的模型相似,我们将上下文中的发言连接起来作为输入。
5 实验设置
数据集
我们在三个数据集上进行实验,分别是 LEDGAR(Tuggener 等人,2020)、IWSLT14 德英翻译(Cettolo 等人,2014)(以下简称 IWSLT)和 PersonaChat(Zhang 等人,2018)。LEDGAR 是一个多标签文本分类数据集,包含合同中的法律条款,我们遵循 Mehta 等人(2022)的方法使用了 LEDGAR 的一个原型子集。IWSLT 来源于一个流行的翻译活动,涵盖多种翻译方向,我们选择了代表性的德英翻译方向。PersonaChat 是一个众包数据集,包含基于给定个性信息的轮流对话。我们使用官方的训练/验证/测试划分来进行所有三个数据集的实验。这些数据集的统计信息列在表 1 中。
评估指标
对于每个数据集,我们报告一个代表性的任务相关评分(LEDGAR 的 Micro F1,IWSLT 的 BLEU42 和 PersonaChat 的 PPL),并附加去学习评估指标,具体如下:
-
Jensen–Shannon 散度(JSD):给定两个分布 ( p(x) ) 和 ( q(x) ),其计算公式为 ( \text{JSD}(p(x) || q(x)) = 0.5 , \text{KL}(p(x) || q(x)) + 0.5 , \text{KL}(q(x) || p(x)) )。
-
语言模型概率距离(LPD):给定两个语言概率(即每个模型生成的目标句子的困惑度)( x ) 和 ( y ),其计算方式为 ( \text{LPD}(x, y) = x - y )。
-
语言模型概率下降(PDLP):计算在去学习后,语言模型概率下降的实例所占的百分比。
参数设置
对于 LEDGAR,我们对 DistilBERT 进行微调。对于 IWSLT 和 PersonaChat,我们均使用通用的编码器-解码器 Transformer 架构。我们使用 Adam(Kingma 和 Ba,2015)优化器,并结合逆平方根学习率调度器进行模型训练。在 KGA 去学习过程中,我们为所有三个数据集保持 16 的批量大小和 5e-5 的学习率,并在公式 5 中设置 ( \beta ) 为 0.1。有关更多参数和训练细节,请参见附录 A。
比较方法
我们将 KGA 方法在测试集和遗忘集上的性能与以下模型进行比较:
-
ORIGINAL:在完整训练集 ( D ) 上训练的原始模型,没有进行任何遗忘。
-
RETRAIN:使用保留数据 ( D_r )(( D_r = D \setminus D_f ))重新训练模型。
-
SISA(Bourtoule 等人,2021):首先将数据集划分为多个不重叠的部分,然后汇总用不同部分训练的模型的输出。当处理数据删除时,仅重新训练受影响部分的模型,然后进行汇总。在我们的实验中,我们随机将训练集划分为 5 个部分。
-
LCODEC(Mehta 等人,2022):它与 Hessian 去学习一致(基于损失函数的 Hessian 更新模型权重),并识别一部分模型参数以降低计算成本。它适用于分类任务,在生成任务中可能需要修改。
-
BADTEACHER(Chundawat 等人,2022):它强迫去学习模型在遗忘集 ( D_f ) 上的表现尽可能接近随机初始化的模型,同时保持在剩余数据 ( D_r ) 上的性能。
6 实验结果
在本节中,我们首先在 6.1 节中比较 KGA 和基线模型的主要去学习分数。然后在 6.2 节中报告时间成本、成员推断攻击和语言模型概率比较结果,以检验 KGA 的优越性。接着,在 6.3 节深入探讨去学习对 NLP 任务的影响。最后在 6.4 节中进行更多分析。
6.1 主要比较结果
我们探讨了测试集和遗忘集上的代表性分数,以检验以下两个问题:(i)去学习模型在测试集上的性能维持得如何?(ii)在原始训练集中曾经存在的遗忘集上的性能变化如何?我们在表 2 中报告了相应的分数,可以得到以下观察结果:
-
我们的去学习方法能够更好地维持测试集上的性能。可以看出,KGA 在三个数据集上的 F1、BLEU4 和 PPL 分数均优于其他去学习基线,无论是精确方法还是近似方法。这表明 KGA 相较于其他方法的一个优越性。
-
我们的 KGA 去学习模型在遗忘集上的表现和预测分布更接近 RETRAIN 模型。我们可以看到,在遗忘集上,KGA 方法得到的 F1(BLEU4 和 PPL)分数与 RETRAIN 模型的分数更接近,并且维持了更小的 JSD(LPD)分数,这意味着在遗忘集上实例的输出分布也与 RETRAIN 模型更加接近。这表明 KGA 在所有基线中实现了最佳的遗忘效果,符合公式 1 的定义。
-
从原始模型中遗忘数据并不意味着去学习模型无法处理这些实例。我们发现 RETRAIN 在遗忘集上的性能相较于 ORIGINAL 模型有所下降,但仍表现出良好的性能(接近测试集的结果)。这与我们的假设一致,成功的去学习模型在遗忘集上的性能应该与未见数据(例如,测试集)相似。我们的 KGA 方法的表现与 RETRAIN 一致,而 BADT 完全丧失了分类和生成的能力,这不符合定义。
6.2 KGA 的优越性分析
在本小节中,我们考察去学习的效率(即时间成本)和效果(即成员推断攻击和语言模型概率检查)。
-
时间成本:我们在图 1(a) 中报告了去学习模型的时间成本。可以看出,尽管重新训练和精确去学习方法(如 SISA)可以保证完美的去学习,但它们的时间成本远超其他近似去学习方法(如 LCODEC、BADT、KGA)。
-
成员推断攻击(MiA):在机器学习环境中,MiA 出现于对手试图找出目标数据实例是否被用于训练模型的情况。我们遵循 Salem 等人(2018)和 Golatkar 等人(2020b)的研究,进行黑箱 MiA,其中对手只能访问模型输出分布。我们以 IWSLT 数据集为例,首先训练一个与原始训练集同分布的浅层翻译模型(实际上简化为使用原始训练集的 30% 实例)。浅层模型的训练集数据标记为“1”,而其他未见数据(即原始训练集的其余部分)标记为“0”。然后,我们使用带有“1/0”标签的数据训练攻击模型,以训练的浅层模型的输出分布作为输入。之后,我们将无学习模型(即 RETRAIN、KGA 等)的输出馈入攻击者模型,并检查 MiA 结果。
我们在图 1(b) 中报告了 MiA 结果,其中更高的 F1 分数和更低的假阴性率(FNR)表示攻击者能更好地推断实例的成员身份。可以看出,攻击者在 ORIGINAL 上的表现最佳,而在去学习后表现较差,这是我们所期望的。在所有无学习模型中,我们也发现攻击者在经历精确去学习(即 RETRAIN 和 SISA)后无法很好地推测成员身份。作为一种近似去学习方法,KGA 的结果接近精确去学习,显示了其有效性。
降低语言模型概率比较
除了在 6.1 节中报告的语言模型距离外,我们还评估了一种新的去学习评估分数,称为相对于原始模型的语言模型概率下降比例(PDLP)。目标序列的语言模型概率下降意味着去学习模型倾向于不生成需要遗忘的句子,这与去学习的目标一致。我们在表 3 中报告了测试集和遗忘集的 PDLP 比较结果。从 RETRAIN 模型的结果来看,我们可以看到测试集中的实例在 RETRAIN 去学习后保持稳定波动(即约 50% 的 PDLP),而遗忘集中的实例则显示出较大的语言模型概率下降(即 96% 的 PDLP),这表明遗忘集的去学习效果良好。我们很容易发现,我们的 KGA 去学习方法与 RETRAIN 模型的表现最为接近,这验证了 KGA 相较于其他比较模型的优越性。
6.3 NLP 中去学习的分析
以往关于去学习的大多数研究主要集中在计算机视觉任务上,对 NLP 任务,尤其是生成任务关注较少。在这里,我们设计了两个针对 NLP 的特定实验,并提出了一些有趣的讨论。
删除不同难度级别的实例
在这里,我们研究我们的去学习方法是否能够处理翻译任务中不同难度级别的遗忘实例。我们使用 BLEU 分数来衡量实例的难度,较高的 BLEU 分数表示该实例对当前模型来说更容易。为了准备 5 组不同难度的实例,我们采用 ORIGINAL 模型对训练集中的实例进行推断,然后根据生成句子的 BLEU 分数对它们进行排序。我们根据 BLEU 将训练集分成 5 个部分,每部分选择 100 个实例作为遗忘集。之后,我们分别对这些实例应用我们的 KGA 去学习。我们在图 2 中报告了去学习结果。
图 2(a) 显示了 ORIGINAL 模型和去学习模型(即 RETRAIN 和 KGA)在遗忘集(5 组不同 BLEU 范围)上的 BLEU 分数。我们可以很容易地发现,去学习导致 RETRAIN 在遗忘集上的某些性能下降,而我们的 KGA 在 R1 和 R2 组上却获得了性能提升。这可能是因为 KGA 倾向于强迫遗忘数据的性能接近未见数据,而不管 BLEU 的范围。因此,在 KGA 去学习之后,表现较差的实例可能会得到提升,而高表现的实例则可能会下降。从图 2(b) 中,我们意外地发现 RETRAIN 后在测试集上的性能甚至比 ORIGINAL 模型更好,尤其是在遗忘极易实例的情况下(即 R5),虽然 R1 略微更高,这可能是由于随机效应。这可能是因为极易的实例对模型性能的提升影响较小。这一观察结果也激发了去学习的进一步应用——去学习某些特定数据点可能会带来性能提升。我们将其留待未来探索。
去学习包含特定词语的实例
与分类任务不同,我们无法删除某个特定标签的所有数据以探索去学习的有效性,翻译任务和大多数生成任务并不包含如此简单的标签来精确分类实例。因此,我们转向选择在翻译任务中包含某些特定词语的实例,以分析去学习前后的输出。
例如,我们删除目标序列中包含“sister”一词的所有实例,从而得到一个去学习模型,预期它会遗忘“sister”一词。表 4 展示了原始模型和去学习模型在三种情况下的输出。我们可以看到,在从训练集中删除所有包含“sister”的实例后,去学习模型不再能够生成“sister”。然而,去学习模型仍然能够生成其他内容。
进一步分析
删除数量的影响
我们研究了去学习模型在处理不同删除数量时如何维持测试集上的性能以及遗忘集上的信息,结果如图 3 所示。从图 3(a) 可以看出,RETRAIN 模型在处理不同数量的删除时能够维持在测试集上的性能,这意味着它对删除数据的规模不敏感。而 KGA 在删除不超过 200 个对话(约 2000 个实例)时能够维持性能,而 SISA 即使在删除数量较少的情况下也表现不佳。图 3(b) 显示了 RETRAIN 和 KGA 在遗忘集上的 LPD。我们可以发现,随着删除数量的增加,KGA 维持了较低的 LPD,这表明 KGA 在遗忘选定数据时表现始终良好。
基模型的影响
我们进一步展示了 KGA 应用于不同模型结构时的去学习结果。除了传统的 Transformer 结构外,这里我们还对 LSTM 和 BART(一个预训练的语言模型)进行了实验。表 5 显示了结果。可以看到,KGA 在使用不同结构时在测试集上的性能下降百分比保持相似,并且在遗忘集上的 LPD 和 PDLP 分数也相似,这表明 KGA 在不同模型结构下均有效。
7 结论
本文提出了 KGA,一种通用的近似机器去学习框架,并探讨其在多个 NLP 任务中的应用。KGA 利用两组模型之间的分布差异,使得去学习模型在遗忘数据上的表现类似于其在未见数据上的表现。对三个大规模数据集的实验以及进一步的实验验证了 KGA 的有效性。
相关文章:

KGA:AGeneral Machine Unlearning Framework Based on Knowledge Gap Alignment
文章目录 摘要1 引言2 相关工作3 符号与定义4 我们的 KGA 框架4.1 KGA框架知识差距对齐目标 4.2 KGA在自然语言处理任务中的应用文本分类机器翻译响应生成 5 实验设置数据集评估指标参数设置比较方法 6 实验结果6.1 主要比较结果6.2 KGA 的优越性分析降低语言模型概率比较 6.3 …...

GelSight Mini视触觉传感器凝胶触头升级:增加40%耐用性,拓展机器人与触觉AI 应用边界
马萨诸塞州沃尔瑟姆-2025年1月6日-触觉智能技术领军企业Gelsight宣布,旗下Gelsight Mini视触觉传感器迎来凝胶触头的更新。经内部测试,新Gel凝胶触头耐用性提升40%,外观与触感与原凝胶触头保持一致。此次升级有效满足了客户在机器人应用中对设…...

springboot整合admin
1. 添加依赖 首先,在你的admin服务端pom.xml文件中添加Spring Boot Admin的依赖: <dependency><groupId>de.codecentric</groupId><artifactId>spring-boot-admin-starter-server</artifactId><version>2.5.4<…...

OS--常见的网络模型(包含IO多路复用的原理)
网络模型 IO模型主要就是用户空间和内核空间数据交换的形式。 IO模型 阻塞 I/O 模型(Blocking I/O) 应用程序发起 I/O 请求后,会被阻塞,直到 I/O 操作完成。 非阻塞 I/O 模型(Non-blocking I/O) 应用程序…...
预测模型和LSTM(Long Short-Term Memory)模型在效果和特点上存在显著差异)
LCE(Local Cascade Ensemble)预测模型和LSTM(Long Short-Term Memory)模型在效果和特点上存在显著差异
LCE(Local Cascade Ensemble)预测模型和LSTM(Long Short-Term Memory)模型在效果和特点上存在显著差异。以下是对两者的比较: 一、效果比较 LCE模型: 优势:LCE结合了随机森林和XGBoost的优势&a…...

【mysql】约束的基本使用
文章目录 1. PRIMARY KEY 约束1.1 作用1.2 关键字1.3 特点1.4 添加主键约束1.5 关于复合主键1.6 删除主键约束 2. 自增列:AUTO_INCREMENT2.1 作用2.2 关键字2.3 特点和要求2.4 如何指定自增约束2.5 如何删除自增约束2.6 MySQL 8.0新特性—自增变量的持久化 3. FOREI…...

EasyExcel(二)导出Excel表自动换行和样式设置
EasyExcel(一)导出Excel表列宽自适应 背景 在上一篇文章中解决导出列宽自适应,然后也解决了导出列宽不可超过255的问题。但是实际应用场景中仍然会有导出数据的长度超过列宽255。这时导出效果就会出现如下现象: 多出列宽宽度的内容会浮出来,影响后边列数据的显示。 解决…...

农产品直播带货方案拆解
作为一名经验丰富的营销策划人道叔,今天我来拆解一下咱们4A营销广告圈的这份《直播天府川农好物带货方案》,让你能学到很多实用的策略和技巧,直接应用到你的策划工作中去。 首先,咱们看看背景分析。 助农直播现在可是个大热门&a…...

“**H5**” 和 “**响应式**” 是前端开发中常见的术语,但它们的概念和使用场景有所不同
“H5” 和 “响应式” 是前端开发中常见的术语,但它们的概念和使用场景有所不同。以下是它们的区别以及为什么为移动端开发的页面通常被称为 “H5” 的解释: 1. 为什么为移动端开发的叫 “H5”? “H5” 是 HTML5 的简称,HTML5 是…...
基于EasyExcel实现通用版一对一、一对多、多层嵌套结构数据导出并支持自动合并单元格
接口功能 通用 支持一对一数据结构导出 支持一对多数据结构导出 支持多层嵌套数据结构导出 支持单元格自动合并 原文来自:https://blog.csdn.net/qq_40980205/article/details/136564176 新增及修复 基于我自己的使用场景,新增并能修复一下功能&#x…...

Java堆内存分析
(一)、线上查看堆内存统计 # 命令用于打印堆内存中每个类的实例数量及其占用的内存,并且只包括活动对象(即存活的对象) jmap -histo:live <pid># 输出到文件方便查看 jmap -histo:live 12345 > aaa.txt(二)、下载dump文件࿰…...
maven高级(day15)
Maven 是一款构建和管理 Java 项目的工具 分模块设计与开发 所谓分模块设计,顾名思义指的就是我们在设计一个 Java 项目的时候,将一个 Java 项目拆分成多 个模块进行开发。 分模块设计我们在进行项目设计阶段,就可以将一个大的项目拆分成若干…...
:乘法器)
计算机组成原理(九):乘法器
乘法器原理 乘法器的工作原理可以用二进制乘法来说明。二进制乘法和十进制乘法类似,通过部分积的累加得到结果。 部分积的生成 在二进制乘法中,每一位的乘积是两个二进制数位的 与运算(0 0 0,1 0 0,0 1 0&…...

python【输入和输出】
Python 有三种输出值的方式: 表达式语句print() 函数使用文件对象的 write() 方法,标准输出文件可以用 sys.stdout 引用。 ① 将输出的值转成字符串,可以使用 repr() 或 str() 函数来实现: str(): 函数返回一个用户易…...
)
2024年华为OD机试真题-判断一组不等式是否满足约束并输出最大差-Python-OD统一考试(E卷)
最新华为OD机试考点合集:华为OD机试2024年真题题库(E卷+D卷+C卷)_华为od机试题库-CSDN博客 每一题都含有详细的解题思路和代码注释,精编c++、JAVA、Python三种语言解法。帮助每一位考生轻松、高效刷题。订阅后永久可看,发现新题及时跟新。 题目描述: 给定一组不等式…...
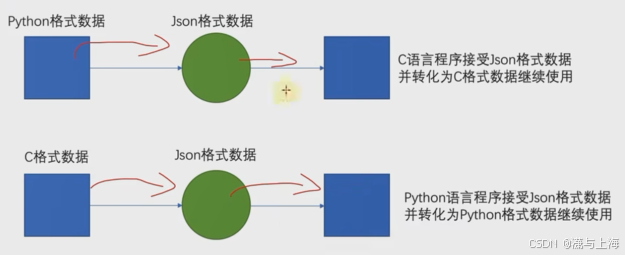
【json】
JSON JSON是一种轻量级的,按照指定的格式去组织和封装数据的数据交互格式。 本质上是一个带有特定格式的字符串(py打印json时认定为str类型) 在各个编程语言中流通的数据格式,负责不同编程语言中的数据传递和交互,类似于计算机普通话 python与json关系及相互转换…...
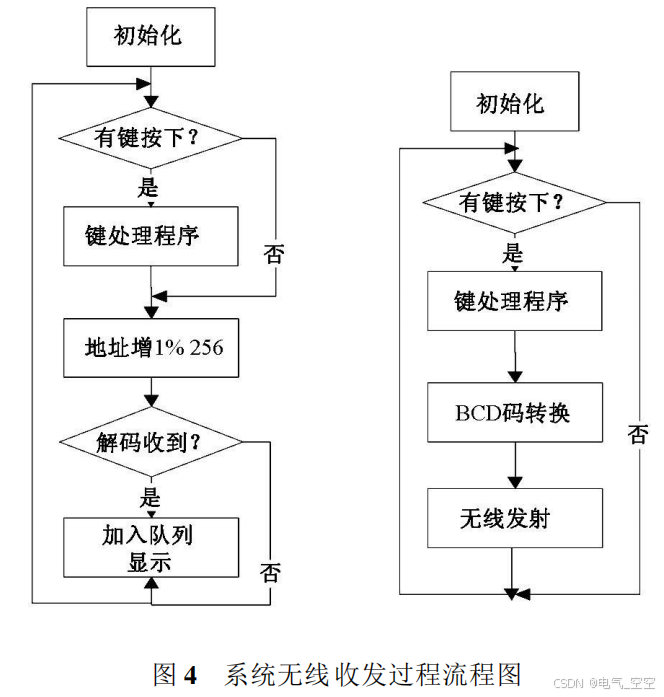
基于单片机的无线智能窗帘控制器的设计
摘 要 : 本文以单片机为控制核心 , 基于 PT2262/ 2272 无线收发模块 , 实现了窗帘的无线远程智能控制 . 该控制器通过高频无线收发模块实现了遥控窗帘的开合控制; 根据外部光线强弱实现自动开关窗帘 ; 根据设定时间自动完成开关过程; 通过语音播报当前环境温湿度信息以…...
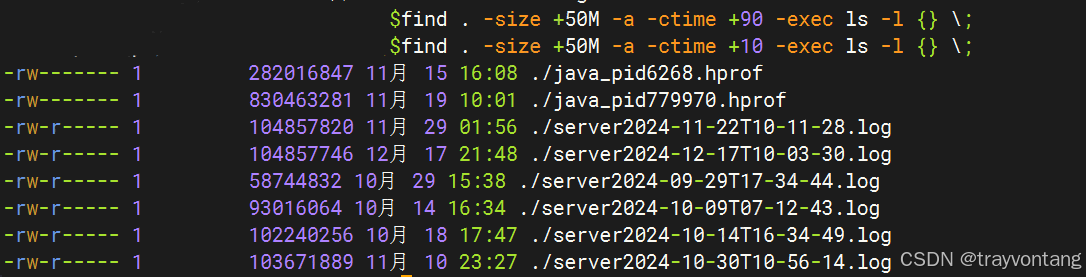
磁盘满造成业务异常问题排查
最近遇到一个因为磁盘满导致的问题,分享一下,希望能够帮助到以后遇到同样问题的朋友。 早上突然收到业务老师反馈说:上传文件不能正常上传了。 想想之前都好好的,最近又没有更新,为什么突然不能使用了呢?…...
)
C++例程:使用I/O模拟IIC接口(6)
完整的STM32F405代码工程I2C驱动源代码跟踪 一)myiic.c #include "myiic.h" #include "delay.h" #include "stm32f4xx_rcc.h" //初始化IIC void IIC_Init(void) { GPIO_InitTypeDef GPIO_InitStructure;RCC_AHB1PeriphCl…...
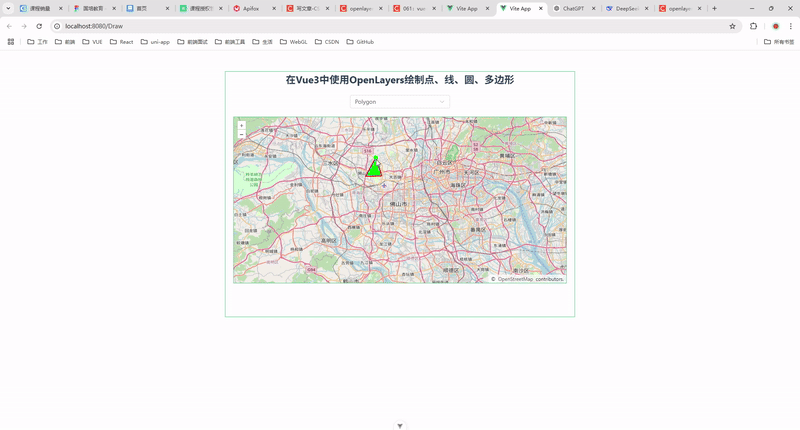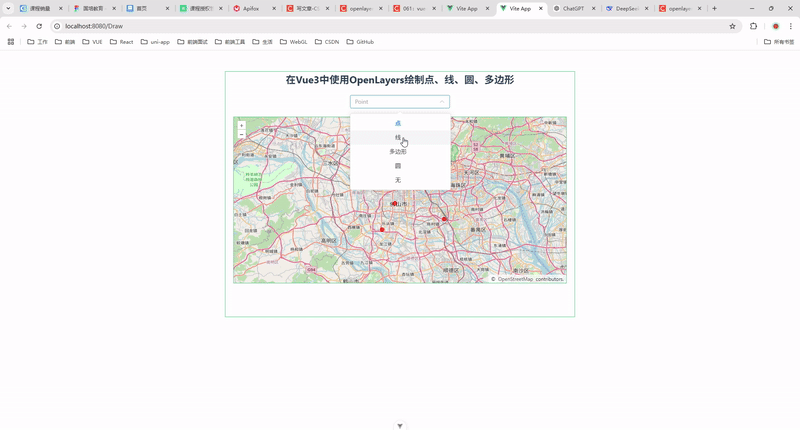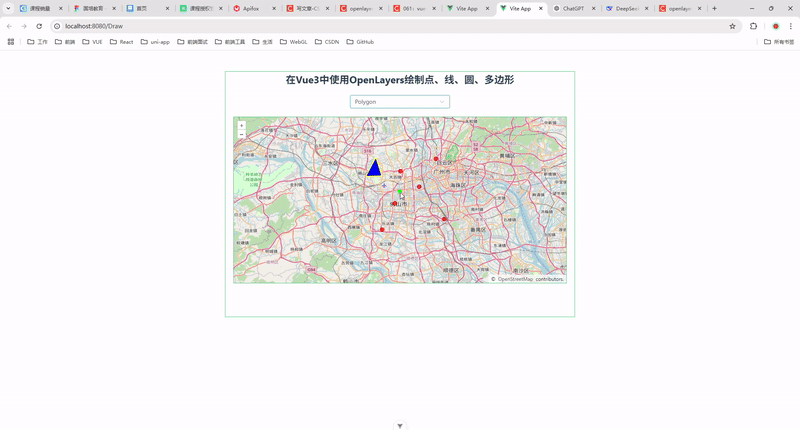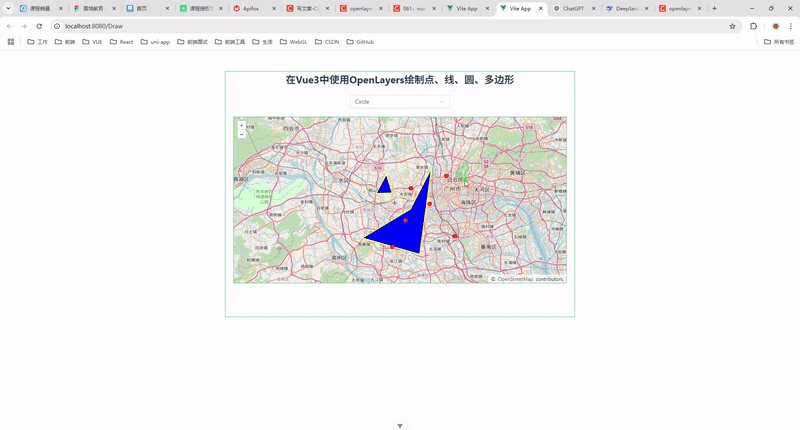
58.在 Vue 3 中使用 OpenLayers 绘制点、线、圆、多边形
前言 在现代 Web 开发中,地图功能已经成为许多应用的重要组成部分。OpenLayers 是一个强大的开源地图库,支持多种地图源和地图操作。结合 Vue 3 的响应式特性,我们可以轻松实现地图的交互功能。本文将详细介绍如何在 Vue 3 中使用 OpenLayer…...

Redis沙盒体验:在浏览器中零门槛掌握NoSQL核心技能
Redis沙盒体验:在浏览器中零门槛掌握NoSQL核心技能 【免费下载链接】try.redis A demonstration of the Redis database. 项目地址: https://gitcode.com/gh_mirrors/tr/try.redis 当你第一次听说Redis时,是否被那些晦涩的技术术语吓退࿱…...
:支持Anthropic API兼容、流式响应、模型热切换与RBAC权限隔离)
Claude本地化部署终极方案(企业级容器化全栈手册):支持Anthropic API兼容、流式响应、模型热切换与RBAC权限隔离
更多请点击: https://codechina.net 第一章:Claude本地化部署的架构全景与企业级价值定位 Claude本地化部署并非简单地将模型权重下载后运行,而是一套融合推理引擎优化、安全沙箱隔离、API网关治理与可观测性集成的端到端架构体系。其核心目…...
)
放弃编码器!纯靠MPU6050和PID算法,手把手教你用TT马达实现平衡小车稳定控制(STM32F103C8T6实战)
纯MPU6050STM32F103的TT马达平衡车实战:无编码器PID控制全解析当大多数平衡小车方案都在强调编码器对速度反馈的不可或缺性时,我们决定挑战一个更极简的配置:仅用5美元的TT马达、9轴的MPU6050和STM32F103C8T6最小系统板,完全舍弃编…...

Burp Suite证书安装全解:HTTPS抓包失败的根源与跨平台命令行方案
1. 为什么必须亲手安装Burp Suite证书——不是“点一下就完事”的操作很多人第一次在手机或测试设备上配置Burp Suite代理时,会下意识认为:只要把电脑上的Burp监听地址填进Wi-Fi代理设置,再用浏览器访问http://burp,点击那个绿色的…...

转行网络安全运维:从0到1的可落地指南
转行网络安全运维:从0到1的可落地指南 一、 「3个核心技能:从零起步也能会」 网上学习资料多到爆炸,不用纠结“哪个最好”,记住一句话:**能学会、能上手的就是好的**!不管是免费视频还是付费课,…...

OpenIPC开源固件:5分钟解锁网络摄像头的终极控制权
OpenIPC开源固件:5分钟解锁网络摄像头的终极控制权 【免费下载链接】firmware Alternative IP Camera firmware from an open community 项目地址: https://gitcode.com/gh_mirrors/fir/firmware 还在为网络摄像头的封闭系统而烦恼吗?想要完全掌控…...

OpenRASP原理与实战:Java应用层实时防护技术详解
1. 为什么我宁愿花三天部署OpenRASP,也不愿再写第五个自定义WAF过滤器去年冬天,我在给一家做在线教育SaaS平台做安全加固时,连续踩了三个坑:第一次用NginxLua写了套SQL注入规则,结果学生提交的“SELECT * FROM courses…...

Elden Ring帧率解锁终极指南:从60帧到144+的完整教程
Elden Ring帧率解锁终极指南:从60帧到144的完整教程 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/Elden…...
)
保姆级教程:手把手教你为ESXi 6.7配置主板BIOS(VT-x/VT-d/AES全开)
从零开始:ESXi 6.7主板BIOS设置完全指南当你第一次接触企业级虚拟化平台时,那种既兴奋又忐忑的心情我完全理解。作为过来人,我清楚地记得自己第一次为ESXi配置BIOS时的迷茫——那些专业术语像天书一样,生怕设置错误导致服务器无法…...

麒麟桌面CVE-2024-1086漏洞深度修复指南
1. 这个漏洞不是“修个补丁就完事”:麒麟桌面系统CVE-2024-1086的真实威胁图谱你可能刚在安全通告里看到“麒麟桌面系统修复CVE-2024-1086”,顺手点了个更新,心里想着“又一个内核提权漏洞,打上补丁不就完了?”——我去…...