LCE(Local Cascade Ensemble)预测模型和LSTM(Long Short-Term Memory)模型在效果和特点上存在显著差异
LCE(Local Cascade Ensemble)预测模型和LSTM(Long Short-Term Memory)模型在效果和特点上存在显著差异。以下是对两者的比较:
一、效果比较
-
LCE模型:
- 优势:LCE结合了随机森林和XGBoost的优势,并采用互补的多样化方法来获得更好的泛化预测器。它增强了预测性能,尤其适用于处理具有复杂关系的数据集。此外,LCE模型对缺失值具有一定的鲁棒性,能够排除预测干扰因素,提高预测值的精确度。
- 应用实例:在电力交易领域,LCE算法被用于短期电价预测,结合CNN-LSTM模型和其他神经网络模型,能够获取更准确的电价预测值。
-
LSTM模型:
- 优势:LSTM是一种特殊的循环神经网络,能够记住长期依赖关系,擅长处理长时序列数据中的复杂依赖关系。它支持非线性关系,适合处理复杂的非线性数据关系。在时间序列预测方面,LSTM表现出色,尤其适用于股票价格、长期能源消耗等复杂的长周期预测。
- 局限性:LSTM模型结构复杂,训练时间较长,且参数调优较为困难。此外,LSTM模型需要较大的数据集支持,在小数据集上容易出现过拟合问题。同时,其预测稳定性相对一般,可能在验证集和预测集上表现差异较大。
二、区别与优劣
-
模型结构:
- LCE模型结合了随机森林和XGBoost的方法,通过改变训练数据分布和学习训练数据的不同部分来生成不同的预测变量。
- LSTM模型则通过引入门控机制(遗忘门、输入门、输出门)来解决传统RNN中的梯度消失和梯度爆炸问题。
-
适用场景:
- LCE模型更适用于处理具有复杂关系的数据集,尤其是当数据集中存在缺失值或异常值时,LCE模型能够表现出更强的鲁棒性。
- LSTM模型则更适用于复杂的长时序列预测场景,如股票价格预测、长期能源消耗预测等。在这些场景中,LSTM模型能够捕捉到长时间序列中的复杂依赖关系,提供准确的预测结果。
-
计算资源需求:
- LCE模型在计算资源需求上相对适中,因为它结合了两种已有的机器学习算法。
- LSTM模型则需要更多的计算资源,因为其模型结构复杂,训练和预测时计算开销较大。
综上所述,LCE预测模型和LSTM模型在效果和特点上各有千秋。在实际应用中,应根据具体的数据特性和预测需求选择合适的模型。对于具有复杂关系的数据集,可以考虑使用LCE模型;而对于复杂的长时序列预测场景,LSTM模型则是一个更好的选择。
由于LCE(Local Cascade Ensemble)并不是一个标准的、广泛认可的模型名称,且在我所了解的知识库中并未直接对应到一个具体的、广泛使用的机器学习模型,因此我将提供一个基于LSTM(Long Short-Term Memory)网络的Python代码示例,并简要说明一个假设性的LCE方法的思路(尽管实际的LCE实现可能需要根据具体应用场景进行定制)。
LSTM Python代码示例
以下是一个使用Keras库(TensorFlow后端)实现的LSTM模型,用于时间序列预测的示例代码:
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense# 假设我们有一个时间序列数据集
# 这里我们使用一个简单的正弦波数据作为示例
time_steps = 100
data = np.sin(np.linspace(0, 10 * np.pi, time_steps)) # 生成正弦波数据# 数据预处理
scaler = MinMaxScaler(feature_range=(0, 1))
data_scaled = scaler.fit_transform(data.reshape(-1, 1)).flatten()# 创建训练和测试数据集
def create_dataset(dataset, time_step=1):X, Y = [], []for i in range(len(dataset) - time_step - 1):a = dataset[i:(i + time_step), 0]X.append(a)Y.append(dataset[i + time_step, 0])return np.array(X), np.array(Y)time_step = 10 # 使用最近10个时间点来预测下一个时间点
X, y = create_dataset(data_scaled.reshape(-1, 1), time_step)# 将数据集划分为训练集和测试集
train_size = int(len(X) * 0.8)
test_size = len(X) - train_size
trainX, testX = X[0:train_size], X[train_size:len(X)]
trainY, testY = y[0:train_size], y[train_size:len(y)]# 将数据重塑为LSTM所需的3D形状 [samples, time steps, features]
trainX = trainX.reshape(trainX.shape[0], trainX.shape[1], 1)
testX = testX.reshape(testX.shape[0], testX.shape[1], 1)# 创建LSTM模型
model = Sequential()
model.add(LSTM(50, return_sequences=True, input_shape=(time_step, 1)))
model.add(LSTM(50, return_sequences=False))
model.add(Dense(25))
model.add(Dense(1))model.compile(optimizer='adam', loss='mean_squared_error')# 训练模型
model.fit(trainX, trainY, batch_size=1, epochs=1)# 预测并逆归一化数据
train_predict = model.predict(trainX)
test_predict = model.predict(testX)
train_predict = scaler.inverse_transform(train_predict)
test_predict = scaler.inverse_transform(test_predict)
trainY = scaler.inverse_transform([trainY])
testY = scaler.inverse_transform([testY])# 可视化结果
import matplotlib.pyplot as pltplt.figure(figsize=(10, 6))
plt.plot(data, label='Original Data')
train_predict_plot = np.empty_like(data)
train_predict_plot[:, :] = np.nan
train_predict_plot[time_step:len(train_predict) + time_step, :] = train_predict
plt.plot(train_predict_plot, label='Train Predict')test_predict_plot = np.empty_like(data)
test_predict_plot[:, :] = np.nan
test_predict_plot[len(train_predict) + (time_step * 2) + 1:len(data) - 1, :] = test_predict
plt.plot(test_predict_plot, label='Test Predict')plt.legend()
plt.show()
假设性LCE方法思路
虽然没有一个标准的LCE模型,但基于“局部级联集成”的概念,我们可以设想一个方法,该方法结合多个局部模型(如决策树、随机森林等),并在每个局部区域内进行集成学习。以下是一个简化的思路:
- 数据划分:将数据划分为多个局部区域,每个区域包含连续的时间点。
- 局部模型训练:在每个局部区域内,训练一个或多个基模型(如决策树、随机森林)。
- 集成学习:使用某种集成策略(如投票、加权平均等)将局部模型的预测结果结合起来,形成最终的预测。
- 预测:对于新的时间点,首先确定其所属的局部区域,然后使用该区域内的集成模型进行预测。
请注意,实际的LCE实现将需要更多的细节设计和实验验证,以确保其有效性和鲁棒性。
以下是一个使用PyTorch实现的LSTM(Long Short-Term Memory)模型代码示例,该模型用于时间序列预测。这个示例代码包括数据预处理、模型定义、训练和预测等步骤。
import torch
import torch.nn as nn
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from torch.utils.data import DataLoader, TensorDataset, random_split# 假设我们有一个时间序列数据集
# 这里我们使用一个简单的正弦波数据作为示例
time_steps = 100
data = np.sin(np.linspace(0, 10 * np.pi, time_steps)) # 生成正弦波数据# 数据预处理
scaler = MinMaxScaler(feature_range=(0, 1))
data_scaled = scaler.fit_transform(data.reshape(-1, 1)).flatten()# 创建训练和测试数据集
def create_dataset(dataset, time_step=1):X, Y = [], []for i in range(len(dataset) - time_step - 1):a = dataset[i:(i + time_step), np.newaxis] # 注意这里要添加一个新的维度X.append(a)Y.append(dataset[i + time_step, 0])return np.array(X), np.array(Y)time_step = 10 # 使用最近10个时间点来预测下一个时间点
X, y = create_dataset(data_scaled, time_step)# 将数据集划分为训练集和测试集
train_size = int(len(X) * 0.8)
test_size = len(X) - train_size
X_train, X_test = X[:train_size], X[train_size:]
y_train, y_test = y[:train_size], y[train_size:]# 转换为PyTorch张量
X_train = torch.tensor(X_train, dtype=torch.float32)
y_train = torch.tensor(y_train, dtype=torch.float32).view(-1, 1)
X_test = torch.tensor(X_test, dtype=torch.float32)
y_test = torch.tensor(y_test, dtype=torch.float32).view(-1, 1)# 创建数据加载器
train_dataset = TensorDataset(X_train, y_train)
test_dataset = TensorDataset(X_test, y_test)
train_size = int(0.8 * len(train_dataset))
val_size = len(train_dataset) - train_size
train_dataset, val_dataset = random_split(train_dataset, [train_size, val_size])
train_loader = DataLoader(train_dataset, batch_size=16, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=16, shuffle=False)
test_loader = DataLoader(test_dataset, batch_size=16, shuffle=False)# 定义LSTM模型
class LSTMModel(nn.Module):def __init__(self, input_size=1, hidden_size=50, num_layers=1, output_size=1):super(LSTMModel, self).__init__()self.hidden_size = hidden_sizeself.num_layers = num_layersself.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)self.fc = nn.Linear(hidden_size, output_size)def forward(self, x):h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)out, _ = self.lstm(x, (h0, c0))out = self.fc(out[:, -1, :])return out# 初始化模型、损失函数和优化器
model = LSTMModel()
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)# 训练模型
num_epochs = 100
for epoch in range(num_epochs):model.train()for i, (inputs, targets) in enumerate(train_loader):outputs = model(inputs)loss = criterion(outputs, targets)optimizer.zero_grad()loss.backward()optimizer.step()if (i + 1) % 10 == 0:print(f'Epoch [{epoch + 1}/{num_epochs}], Step [{i + 1}/{len(train_loader)}], Loss: {loss.item():.4f}')# 验证模型
model.eval()
with torch.no_grad():val_loss = 0for inputs, targets in val_loader:outputs = model(inputs)loss = criterion(outputs, targets)val_loss += loss.item()val_loss /= len(val_loader)print(f'Validation Loss: {val_loss:.4f}')# 测试模型
model.eval()
predictions = []
targets = []
with torch.no_grad():for inputs, target in test_loader:output = model(inputs)predictions.extend(output.numpy())targets.extend(target.numpy())# 逆归一化预测结果和目标值
predictions = scaler.inverse_transform(np.array(predictions).reshape(-1, 1))
targets = scaler.inverse_transform(np.array(targets).reshape(-1, 1))# 可视化结果
import matplotlib.pyplot as pltplt.figure(figsize=(10, 6))
plt.plot(data, label='Original Data')
test_predict_plot = np.empty_like(data)
test_predict_plot[:] = np.nan
test_predict_plot[time_step + (time_step * (train_size // len(X_train))):len(predictions) + time_step + (time_step * (train_size // len(X_train))), :] = predictions
plt.plot(test_predict_plot, label='Test Predict')plt.legend()
plt.show()
注意:
- 数据预处理部分将时间序列数据转换为模型所需的输入格式,并进行了归一化处理。
create_dataset函数用于生成训练和测试数据集,其中time_step参数指定了用于预测的时间步长。- 使用了
TensorDataset和DataLoader来加载数据,以便在训练过程中进行批量处理和打乱数据。 - LSTM模型定义在
LSTMModel类中,包括LSTM层和全连接层。 - 训练过程包括前向传播、计算损失、反向传播和优化步骤。
- 在测试阶段,模型对测试数据集进行了预测,并逆归一化了预测结果和目标值。
- 最后,使用Matplotlib可视化了原始数据和预测结果。
请确保您的环境中已安装了PyTorch和其他必要的库,如NumPy、Pandas和Matplotlib。运行此代码将训练一个LSTM模型,并对测试数据集进行预测,然后可视化结果。
相关文章:
预测模型和LSTM(Long Short-Term Memory)模型在效果和特点上存在显著差异)
LCE(Local Cascade Ensemble)预测模型和LSTM(Long Short-Term Memory)模型在效果和特点上存在显著差异
LCE(Local Cascade Ensemble)预测模型和LSTM(Long Short-Term Memory)模型在效果和特点上存在显著差异。以下是对两者的比较: 一、效果比较 LCE模型: 优势:LCE结合了随机森林和XGBoost的优势&a…...

【mysql】约束的基本使用
文章目录 1. PRIMARY KEY 约束1.1 作用1.2 关键字1.3 特点1.4 添加主键约束1.5 关于复合主键1.6 删除主键约束 2. 自增列:AUTO_INCREMENT2.1 作用2.2 关键字2.3 特点和要求2.4 如何指定自增约束2.5 如何删除自增约束2.6 MySQL 8.0新特性—自增变量的持久化 3. FOREI…...

EasyExcel(二)导出Excel表自动换行和样式设置
EasyExcel(一)导出Excel表列宽自适应 背景 在上一篇文章中解决导出列宽自适应,然后也解决了导出列宽不可超过255的问题。但是实际应用场景中仍然会有导出数据的长度超过列宽255。这时导出效果就会出现如下现象: 多出列宽宽度的内容会浮出来,影响后边列数据的显示。 解决…...

农产品直播带货方案拆解
作为一名经验丰富的营销策划人道叔,今天我来拆解一下咱们4A营销广告圈的这份《直播天府川农好物带货方案》,让你能学到很多实用的策略和技巧,直接应用到你的策划工作中去。 首先,咱们看看背景分析。 助农直播现在可是个大热门&a…...

“**H5**” 和 “**响应式**” 是前端开发中常见的术语,但它们的概念和使用场景有所不同
“H5” 和 “响应式” 是前端开发中常见的术语,但它们的概念和使用场景有所不同。以下是它们的区别以及为什么为移动端开发的页面通常被称为 “H5” 的解释: 1. 为什么为移动端开发的叫 “H5”? “H5” 是 HTML5 的简称,HTML5 是…...
基于EasyExcel实现通用版一对一、一对多、多层嵌套结构数据导出并支持自动合并单元格
接口功能 通用 支持一对一数据结构导出 支持一对多数据结构导出 支持多层嵌套数据结构导出 支持单元格自动合并 原文来自:https://blog.csdn.net/qq_40980205/article/details/136564176 新增及修复 基于我自己的使用场景,新增并能修复一下功能&#x…...

Java堆内存分析
(一)、线上查看堆内存统计 # 命令用于打印堆内存中每个类的实例数量及其占用的内存,并且只包括活动对象(即存活的对象) jmap -histo:live <pid># 输出到文件方便查看 jmap -histo:live 12345 > aaa.txt(二)、下载dump文件࿰…...
maven高级(day15)
Maven 是一款构建和管理 Java 项目的工具 分模块设计与开发 所谓分模块设计,顾名思义指的就是我们在设计一个 Java 项目的时候,将一个 Java 项目拆分成多 个模块进行开发。 分模块设计我们在进行项目设计阶段,就可以将一个大的项目拆分成若干…...
:乘法器)
计算机组成原理(九):乘法器
乘法器原理 乘法器的工作原理可以用二进制乘法来说明。二进制乘法和十进制乘法类似,通过部分积的累加得到结果。 部分积的生成 在二进制乘法中,每一位的乘积是两个二进制数位的 与运算(0 0 0,1 0 0,0 1 0&…...

python【输入和输出】
Python 有三种输出值的方式: 表达式语句print() 函数使用文件对象的 write() 方法,标准输出文件可以用 sys.stdout 引用。 ① 将输出的值转成字符串,可以使用 repr() 或 str() 函数来实现: str(): 函数返回一个用户易…...
)
2024年华为OD机试真题-判断一组不等式是否满足约束并输出最大差-Python-OD统一考试(E卷)
最新华为OD机试考点合集:华为OD机试2024年真题题库(E卷+D卷+C卷)_华为od机试题库-CSDN博客 每一题都含有详细的解题思路和代码注释,精编c++、JAVA、Python三种语言解法。帮助每一位考生轻松、高效刷题。订阅后永久可看,发现新题及时跟新。 题目描述: 给定一组不等式…...
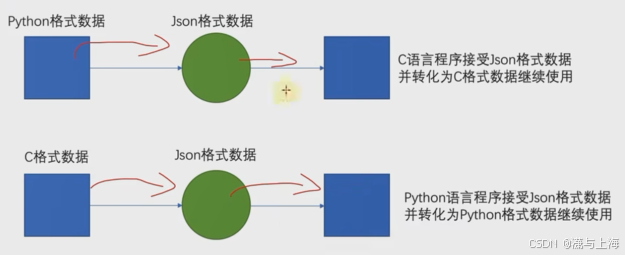
【json】
JSON JSON是一种轻量级的,按照指定的格式去组织和封装数据的数据交互格式。 本质上是一个带有特定格式的字符串(py打印json时认定为str类型) 在各个编程语言中流通的数据格式,负责不同编程语言中的数据传递和交互,类似于计算机普通话 python与json关系及相互转换…...
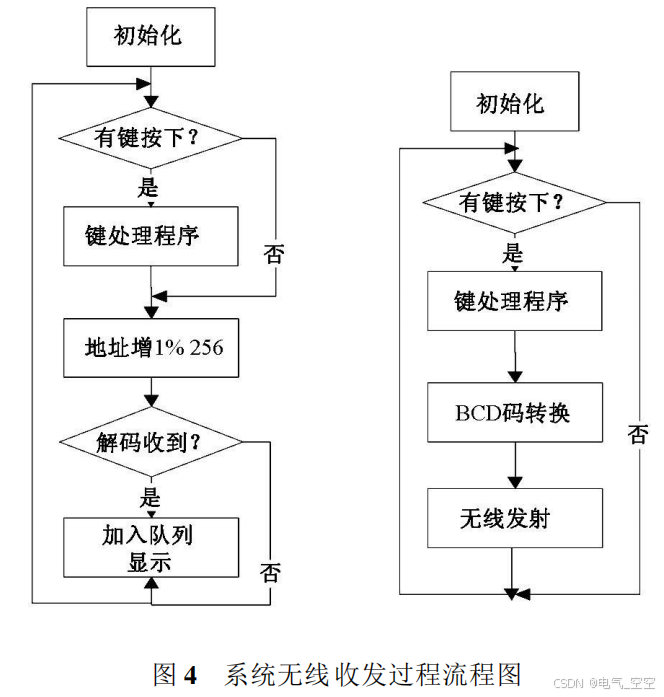
基于单片机的无线智能窗帘控制器的设计
摘 要 : 本文以单片机为控制核心 , 基于 PT2262/ 2272 无线收发模块 , 实现了窗帘的无线远程智能控制 . 该控制器通过高频无线收发模块实现了遥控窗帘的开合控制; 根据外部光线强弱实现自动开关窗帘 ; 根据设定时间自动完成开关过程; 通过语音播报当前环境温湿度信息以…...
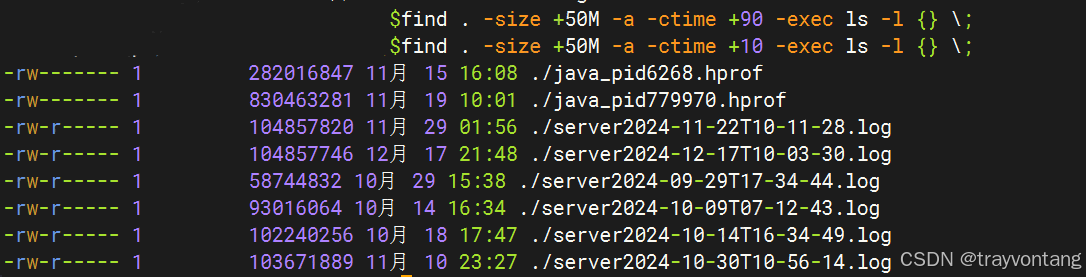
磁盘满造成业务异常问题排查
最近遇到一个因为磁盘满导致的问题,分享一下,希望能够帮助到以后遇到同样问题的朋友。 早上突然收到业务老师反馈说:上传文件不能正常上传了。 想想之前都好好的,最近又没有更新,为什么突然不能使用了呢?…...
)
C++例程:使用I/O模拟IIC接口(6)
完整的STM32F405代码工程I2C驱动源代码跟踪 一)myiic.c #include "myiic.h" #include "delay.h" #include "stm32f4xx_rcc.h" //初始化IIC void IIC_Init(void) { GPIO_InitTypeDef GPIO_InitStructure;RCC_AHB1PeriphCl…...
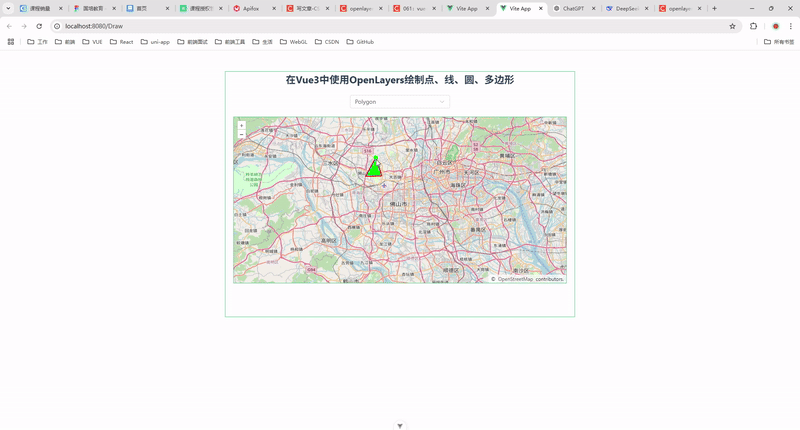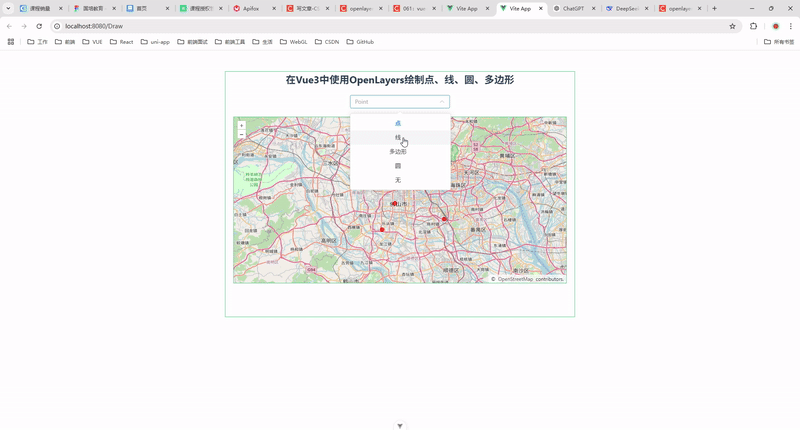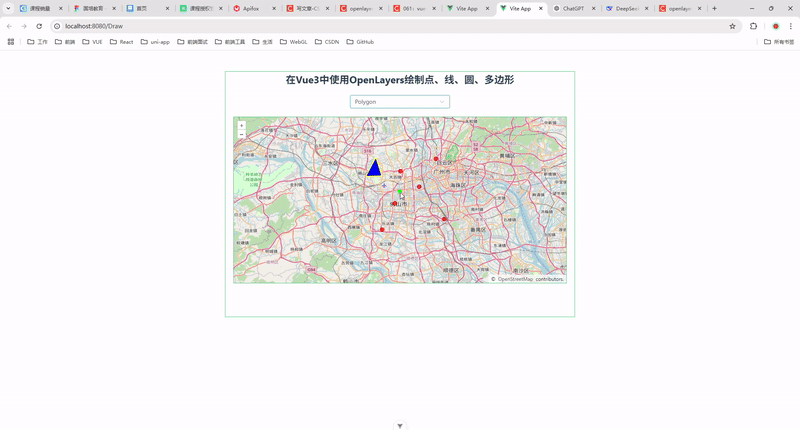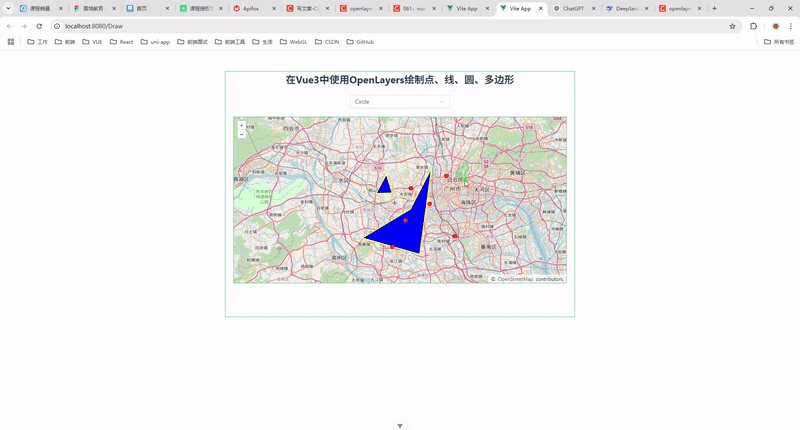
58.在 Vue 3 中使用 OpenLayers 绘制点、线、圆、多边形
前言 在现代 Web 开发中,地图功能已经成为许多应用的重要组成部分。OpenLayers 是一个强大的开源地图库,支持多种地图源和地图操作。结合 Vue 3 的响应式特性,我们可以轻松实现地图的交互功能。本文将详细介绍如何在 Vue 3 中使用 OpenLayer…...
如何快速上手一个鸿蒙工程
作为一名鸿蒙程序猿,当你换了一家公司,或者被交接了一个已有的业务。前辈在找你之前十分钟写了一个他都看不懂的交接文档,然后把一个鸿蒙工程交接给你了,说以后就是你负责了。之后几天你的状态大概就是下边这样的,一堆…...
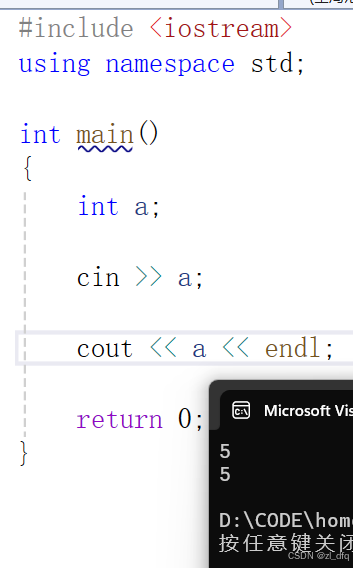
c++入门之 命名空间与输入输出
1、命名空间 1.1使用命名空间的原因 先看一个例子: #include <iostream>int round 0;int main() {printf("%d", round);return 0; }请问,这个程序能跑起来吗? 答案是否定的 原因是,当我们想创建一个全局变量 …...

GRE技术的详细解释
GRE(Generic Routing Encapsulation,通用路由封装)是一种隧道协议,主要用于在不同网络之间封装和传输其他网络层协议的数据包。它最常用于在IP网络上建立虚拟点到点的隧道连接,是实现VPN的一项关键技术。 下面从原理、…...
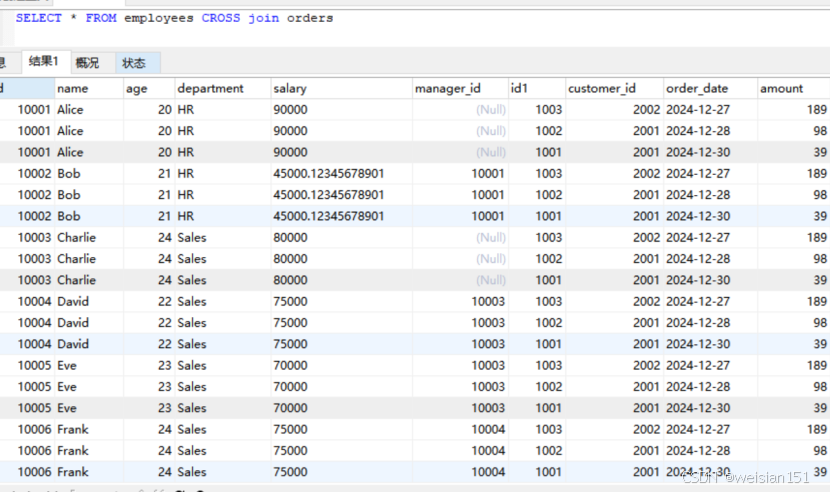
Mysql--基础篇--多表查询(JOIN,笛卡尔积)
在MySQL中,多表查询(也称为联表查询或JOIN操作)是数据库操作中非常常见的需求。通过多表查询,你可以从多个表中获取相关数据,并根据一定的条件将它们组合在一起。MySQL支持多种类型的JOIN操作,每种JOIN都有…...

Stitches项目架构分析:RequireJS模块化设计与Grunt构建流程完全指南 [特殊字符]
Stitches项目架构分析:RequireJS模块化设计与Grunt构建流程完全指南 🚀 【免费下载链接】stitches HTML5 Sprite Sheet Generator 项目地址: https://gitcode.com/gh_mirrors/sti/stitches Stitches是一个基于HTML5的雪碧图生成器,它采…...

CVPR 2023反无人机数据集实战:用ModelScope上的开源模型快速上手目标检测
CVPR 2023反无人机数据集实战:用ModelScope上的开源模型快速上手目标检测无人机技术的普及带来了新的安全挑战,从隐私侵犯到关键设施威胁,反无人机技术正成为计算机视觉领域的热点。CVPR 2023反无人机竞赛提供的开源数据集和基线模型…...

全链路压测实战:双十一级别的流量,我是这样扛住的
作为一名在质量保障领域摸爬滚打多年的测试工程师,我深知传统的单接口压测在如今分布式架构下的无力感。当业务流量达到双十一这种脉冲式、高并发的级别时,任何一个非核心链路上的“短板”都可能引发系统性的雪崩。全链路压测不再是选择题,而…...

【MySQL数据库 | 第一篇】 概述
数据库相关概念: 数据库(Database):数据库是指一组有组织的数据的集合,通过计算机程序进行管理和访问。数据库管理系统:操纵和管理数据库的大型软件SQL:操作关系型数据库的编程语言,定义了一套操作关系型数…...

电信运营商每月处理海量工单,如何不再出错?基于AI Agent的端到端自动化解决方案
在2026年的电信行业,海量工单处理已不再仅仅是效率问题,而是合规与生存的底线。随着2026年5月20日《电信和互联网服务 基础电信企业网上营业厅服务规范》国家标准的正式实施,监管层对“信息透明、流程闭环、计费精准”的要求达到了前所未有的…...
)
告别杂乱!用FileMenu Tools 8.4.2一键清理Windows 11右键菜单(附隐藏技巧)
Windows 11右键菜单精简指南:用FileMenu Tools打造高效工作流每次在文件上点击右键时,那个缓慢弹出的冗长菜单是否让你感到烦躁?随着安装的软件越来越多,Windows的右键菜单往往会变得臃肿不堪,严重影响工作效率。今天&…...

PS5 NOR Modifier深度解析:如何通过Windows工具修复PS5硬件故障与实现光驱版转数字版
PS5 NOR Modifier深度解析:如何通过Windows工具修复PS5硬件故障与实现光驱版转数字版 【免费下载链接】PS5NorModifier The PS5 Nor Modifier is an easy to use Windows based application to rewrite your PS5 NOR file. This can be useful if your NOR is corru…...

机器学习的最佳实践:这7个原则让你的模型更稳定
对于软件测试从业者而言,机器学习技术正在快速融入测试流程:从自动化测试用例生成、缺陷预测到测试环境异常检测,机器学习模型的稳定性直接决定了测试结果的可靠性——如果模型在测试环境波动、输入数据变化时性能骤降,不仅无法提…...

Hermes Agent工具如何自定义接入Taotoken提供商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Hermes Agent工具如何自定义接入Taotoken提供商 Hermes Agent 是一款功能强大的AI智能体开发框架,它支持通过自定义提供…...

从《吃豆人》到开放世界:聊聊Unity Navigation里Agent Radius和Cost的那些‘潜规则’
从《吃豆人》到开放世界:Unity Navigation中Agent Radius与Cost的隐藏逻辑1980年诞生的《吃豆人》用简单的迷宫路径定义了早期游戏AI的移动规则——幽灵们沿着固定路线巡逻,遇到转角时随机选择方向。这种设计在当时堪称革命性,但以今天的标准…...