CamemBERT:一款出色的法语语言模型
摘要
预训练语言模型在自然语言处理中已无处不在。尽管这些模型取得了成功,但大多数可用模型要么是在英语数据上训练的,要么是在多种语言数据拼接的基础上训练的。这使得这些模型在除英语以外的所有语言中的实际应用非常有限。本文探讨了为其他语言训练基于Transformer的单语语言模型的可行性,并以法语为例,评估了我们的语言模型在词性标注、依存句法分析、命名实体识别和自然语言推理任务上的表现。我们表明,使用网络爬取的数据优于使用维基百科数据。更令人惊讶的是,我们发现,相对较小的网络爬取数据集(4GB)能够带来与使用更大数据集(130+GB)相当的结果。我们表现最好的模型CamemBERT在所有四个下游任务中达到或改进了现有技术水平。
1 引言
预训练词表示在自然语言处理(NLP)中有着悠久的历史,从非上下文相关的表示(Brown等,1992;Ando和Zhang,2005;Mikolov等,2013;Pennington等,2014)到上下文相关的词嵌入(Peters等,2018;Akbik等,2018)。词表示通常通过在大规模文本数据上训练语言模型架构获得,然后作为输入提供给更复杂的任务特定架构。最近,这些专门的架构已被大规模预训练语言模型完全取代,这些模型针对每个应用进行微调。这一转变使得在广泛任务中的性能得到了大幅提升(Devlin等,2019;Radford等,2019;Liu等,2019;Raffel等,2019)。
这些迁移学习方法相较于传统的任务特定方法具有明显的优势。特别是,它们可以以无监督的方式进行训练,从而利用大量原始文本中的信息。然而,它们也带来了实施上的挑战,即预训练所需的数据量和计算资源,可能需要数百GB的文本和数百个GPU(Yang等,2019;Liu等,2019)。这限制了这些最先进模型在单语环境中的可用性,尤其是英语以外的语言。这尤其不便,因为它阻碍了它们在NLP系统中的实际应用,也阻止了我们研究它们的语言建模能力,例如在形态丰富的语言中的表现。
尽管多语言模型取得了显著成果,但它们通常更大,并且其结果(如我们将在法语中观察到的)在高资源语言上可能落后于单语模型。为了复现和验证迄今为止仅在英语中获得的结果,我们利用新发布的多语言语料库OSCAR(Ortiz Suárez等,2019)训练了一个法语单语语言模型,称为CamemBERT。我们还训练了不同版本的CamemBERT,使用不同规模和风格多样性的较小语料库,以评估这些参数对下游任务性能的影响。CamemBERT使用了RoBERTa架构(Liu等,2019),这是高性能且广泛使用的BERT架构(Devlin等,2019)的改进版本。
我们在法语的四个不同下游任务上评估了我们的模型:词性标注(POS)、依存句法分析、命名实体识别(NER)和自然语言推理(NLI)。CamemBERT在所有四个任务中相比之前的单语和多语言方法(包括mBERT、XLM和XLM-R)改进了现有技术水平,这证实了大规模预训练语言模型在法语中的有效性。
我们的贡献可以总结如下:
• 首次发布了基于RoBERTa架构的法语单语模型,使用了最近引入的大规模开源语料库OSCAR,并且是BERT原作者之外首次为英语以外的语言发布如此大规模的模型。该模型在MIT开源许可证下公开发布。
• 我们在四个下游任务上取得了最先进的结果:词性标注、依存句法分析、命名实体识别和自然语言推理,证实了基于BERT的语言模型在法语中的有效性。
• 我们证明了小型且多样化的训练集可以达到与大规模语料库相似的性能,通过分析预训练语料库在规模和领域方面的重要性。
2 相关工作
2.1 上下文语言模型
从非上下文到上下文词嵌入
最早的神经词向量表示是非上下文化的词嵌入,最著名的是word2vec(Mikolov等,2013)、GloVe(Pennington等,2014)和fastText(Mikolov等,2018),它们被设计为任务特定神经架构的输入。上下文词表示(如ELMo(Peters等,2018)和flair(Akbik等,2018))通过考虑上下文提高了词嵌入的表示能力。它们通过处理词语的多义性,在许多任务上提高了模型性能。这为更大规模的上下文模型铺平了道路,这些模型在大多数任务中完全取代了下游架构。这些方法以语言建模为目标进行训练,范围从基于LSTM的架构(如Dai和Le,2015)到成功的基于Transformer的架构,如GPT2(Radford等,2019)、BERT(Devlin等,2019)、RoBERTa(Liu等,2019)以及最近的ALBERT(Lan等,2019)和T5(Raffel等,2019)。
非英语上下文模型
随着大规模预训练语言模型的成功,它们被扩展到多语言环境中,如多语言BERT(以下简称mBERT)(Devlin等,2018),这是一个针对104种不同语言的单一多语言模型,基于维基百科数据训练;以及后来的XLM(Lample和Conneau,2019),它显著改进了无监督机器翻译。最近的XLM-R(Conneau等,2019)通过在2.5TB数据上训练扩展了XLM,并在多语言基准测试中超越了之前的分数。研究表明,多语言模型可以通过利用其他语言的高质量数据,在特定下游任务上获得与单语模型竞争的结果。
一些非英语单语模型已经发布:日文、葡萄牙文、德文和巴斯克文的ELMo模型,以及简体中文、繁体中文(Devlin等,2018)和德文(Chan等,2019)的BERT模型。
然而,据我们所知,尚未有针对英语以外的语言训练与最新英语模型(如RoBERTa在超过100GB数据上训练)规模相当的模型的特别努力。
BERT和RoBERTa
我们的方法基于RoBERTa(Liu等,2019),而RoBERTa本身基于BERT(Devlin等,2019)。BERT是一个多层双向Transformer编码器,通过掩码语言建模(MLM)目标进行训练,灵感来自Cloze任务(Taylor,1953)。它有两种规模:BERTBASE架构和BERTLARGE架构。BERTBASE架构规模较小,因此更快且更易于使用,而BERTLARGE在下游任务中实现了更高的性能。RoBERTa通过识别关键设计选择改进了BERT的原始实现,使用动态掩码、移除下一句预测任务、以更大的批次训练、在更多数据上训练以及训练更长时间。
3 下游评估任务
在本节中,我们介绍了用于评估CamemBERT的四个下游任务,即:词性标注(POS)、依存句法分析、命名实体识别(NER)和自然语言推理(NLI)。我们还介绍了用于比较的基线方法。
任务 词性标注是一项低级别的句法任务,旨在为每个词分配其对应的语法类别。依存句法分析则是预测带标签的句法树,以捕捉词之间的句法关系。
对于这两项任务,我们使用通用依存关系(UD)框架及其对应的UD词性标注集(Petrov等,2012)和UD树库集合(Nivre等,2018)进行实验,这些数据被用于CoNLL 2018共享任务(Seker等,2018)。我们在UD v2.2中的四个免费法语UD树库上进行评估:GSD(McDonald等,2013)、Sequoia(Candito和Seddah,2012;Candito等,2014)、Spoken(Lacheret等,2014;Bawden等,2014)和ParTUT(Sanguinetti和Bosco,2015)。表1简要概述了每个树库的规模和内容。

我们还在命名实体识别(NER)任务上评估了我们的模型,NER是一项序列标注任务,旨在预测哪些词指代现实世界中的对象,如人物、地点、物品和组织。我们使用了2008年版本的法国树库(FTB)(Abeillé等,2003),该版本由Candito和Crabbé(2009)引入,并由Sagot等(2012)添加了NER标注。FTB包含超过1.1万个实体提及,分布在7种不同的实体类型中。表1中还简要概述了FTB的内容。
最后,我们使用XNLI数据集(Conneau等,2018)的法语部分在自然语言推理(NLI)任务上评估了我们的模型。NLI任务旨在预测一个假设句子是否与前提句子存在蕴含、中立或矛盾的关系。XNLI数据集是Multi-Genre NLI(MultiNLI)语料库(Williams等,2018)的扩展,通过将验证集和测试集手动翻译成15种语言。英语训练集则通过机器翻译为其他语言。该数据集包含每种语言的12.2万条训练样本、2490条开发样本和5010条测试样本。通常,NLI任务的性能通过准确率进行评估。
基线方法
在依存句法分析和词性标注任务中,我们将我们的模型与以下方法进行比较:
- mBERT:BERT的多语言版本(见第2.1节)。我们在与CamemBERT相同的条件下,对每个树库微调mBERT,并添加额外的层用于词性标注和依存句法分析。
- XLMMLM-TLM:来自Lample和Conneau(2019)的多语言预训练语言模型,在NLI任务上表现优于mBERT。我们使用Hugging Face的transformer库(Wolf等,2019)中的版本,并在与我们的模型相同的条件下进行微调。
- UDify(Kondratyuk,2019):基于mBERT的多任务多语言模型,UDify同时在124个不同的UD树库上训练,创建了一个适用于75种语言的单一词性标注和依存句法分析模型。我们报告了Kondratyuk(2019)论文中的分数。
- UDPipe Future(Straka,2018):基于LSTM的模型,在CoNLL 2018共享任务(Seker等,2018)中在依存句法分析中排名第3,在词性标注中排名第6。我们报告了Kondratyuk(2019)论文中的分数。
- UDPipe Future + mBERT + Flair(Straka等,2019):原始的UDPipe Future实现,使用mBERT和Flair作为基于特征的上下文词嵌入。我们报告了Straka等(2019)论文中的分数。
在法语中,由于标注语料库的有限性,NER任务的研究较少。因此,我们将我们的模型与Dupont(2017)设定的最新基线进行比较,他在FTB上训练了CRF(Lafferty等,2001)和BiLSTM-CRF(Lample等,2016)架构,并使用启发式方法和预训练词嵌入进行了增强。此外,与词性标注和依存句法分析一样,我们还比较了针对NER任务微调的mBERT版本。
对于XNLI任务,我们提供了Wu和Dredze(2019)报告的法语mBERT分数。我们还报告了XLMMLM-TLM(如上所述)的分数,这是Lample和Conneau(2019)的最佳模型。此外,我们还报告了XLM-R(Conneau等,2019)的结果。
4 CamemBERT:法语语言模型
在本节中,我们描述了用于CamemBERT的预训练数据、架构、训练目标和优化设置。
4.1 训练数据
预训练语言模型受益于在大规模数据集上训练(Devlin等,2018;Liu等,2019;Raffel等,2019)。因此,我们使用了OSCAR语料库(Ortiz Suárez等,2019)的法语部分,这是Common Crawl的预过滤和预分类版本。
OSCAR是从Common Crawl快照中提取的单语语料库集合。它采用了与Grave等(2018)相同的方法,使用基于fastText线性分类器(Grave等,2017;Joulin等,2016)的语言分类模型,该分类器在维基百科、Tatoeba和SETimes上预训练,支持176种语言。未进行其他过滤。我们使用了未打乱的法语数据版本,其原始文本大小为138GB,经过子词分词后包含327亿个词元。
4.2 预处理
我们使用SentencePiece(Kudo和Richardson,2018)将输入文本数据分割为子词单元。SentencePiece是字节对编码(BPE)(Sennrich等,2016)和WordPiece(Kudo,2018)的扩展,不需要预分词(在词或词元级别),从而消除了对语言特定分词器的需求。我们使用32k个子词词元的词汇表。这些子词是从预训练数据集中随机采样的107个句子中学习的。为了简化,我们没有使用子词正则化(即从多个可能的分割中采样)。
4.3 语言建模
Transformer
与RoBERTa和BERT类似,CamemBERT是一个多层双向Transformer(Vaswani等,2017)。鉴于Transformer的广泛使用,我们在此不详细描述,读者可参考(Vaswani等,2017)。CamemBERT使用了BERTBASE(12层,768隐藏维度,12个注意力头,1.1亿参数)和BERTLARGE(24层,1024隐藏维度,12个注意力头,3.4亿参数)的原始架构。
CamemBERT与RoBERTa非常相似,主要区别在于使用了全词掩码(whole-word masking)以及SentencePiece分词(Kudo和Richardson,2018)而非WordPiece(Schuster和Nakajima,2012)。
预训练目标
我们在掩码语言建模(MLM)任务上训练模型。给定由N个词元组成的输入文本序列x1, …, xN,我们选择15%的词元进行可能的替换。在这些被选中的词元中,80%被替换为特殊的标记,10%保持不变,10%被替换为随机词元。然后,模型通过交叉熵损失预测初始被掩码的词元。
遵循RoBERTa的方法,我们动态掩码词元,而不是在预处理期间为整个数据集静态固定掩码。这提高了多样性,并使模型在多次训练时更具鲁棒性。
由于我们使用SentencePiece对语料库进行分词,模型的输入词元是完整词和子词的混合。BERT的升级版本和Joshi等(2019)表明,掩码整个词而不是单个子词可以提高性能。全词掩码(WWM)使训练任务更加困难,因为模型必须预测整个词,而不是在给定其余部分的情况下仅预测词的一部分。我们通过在初始未分词的文本中使用空格作为词分隔符来训练模型。
WWM的实现方式是首先随机采样序列中15%的词,然后将这15%中每个词的所有子词词元作为候选替换。这相当于接近原始15%的选中词元比例。这些词元随后被替换为标记(80%)、保持不变(10%)或被替换为随机词元。
后续研究表明,BERT最初使用的下一句预测(NSP)任务并未提高下游任务性能(Lample和Conneau,2019;Liu等,2019),因此我们也将其移除。
优化
遵循(Liu等,2019),我们使用Adam优化器(Kingma和Ba,2014)( β 1 = 0.9 , β 2 = 0.98 \beta_{1}=0.9,\beta_{2}=0.98 β1=0.9,β2=0.98)对模型进行优化,训练100k步,批量大小为8192个序列,每个序列最多包含512个词元。我们强制每个序列仅包含完整段落(对应于预训练数据集中的行)。
预训练
我们使用fairseq库(Ott等,2019)中的RoBERTa实现。我们的学习率在前10k步预热至峰值0.0007(由于批量较大,而非原始的0.0001),然后通过多项式衰减降至零。除非另有说明,我们的模型使用BASE架构,并在256个Nvidia V100 GPU(每个32GB)上预训练100k次反向传播步骤,耗时一天。出于实际考虑,我们没有训练更长时间,尽管性能似乎仍在提升。
4.4 使用CamemBERT进行下游任务
我们以两种方式使用预训练的CamemBERT。
第一种称为微调(fine-tuning),我们以端到端的方式在特定任务上微调模型。
第二种称为基于特征的嵌入(feature-based embeddings)或简称为嵌入(embeddings),我们从CamemBERT中提取冻结的上下文嵌入向量。这两种互补的方法揭示了CamemBERT捕获的预训练隐藏表示的质量。
微调
对于每个任务,我们在CamemBERT架构的顶部附加相关的预测层。遵循BERT的工作(Devlin等,2019),对于序列标注和序列标记任务,我们附加一个线性层,分别以特殊标记的最后隐藏表示和每个词的第一个子词词元的最后隐藏表示作为输入。对于依存句法分析,我们插入一个双仿射图预测头,灵感来自Dozat和Manning(2017)。我们建议读者参考该文章以获取有关此模块的更多细节。
我们在XNLI上微调时,添加一个分类头,由一个带非线性的隐藏层和一个线性投影层组成,并对两者进行输入dropout。
我们为每个任务和每个数据集独立微调CamemBERT。我们使用Adam优化器(Kingma和Ba,2014)以固定学习率优化模型。我们对学习率和批量大小的组合进行网格搜索。我们从前30个epoch中选择在验证集上表现最佳的模型。对于NLI,我们使用RoBERTa作者在MNLI任务上提供的默认超参数。尽管这可能进一步提高了性能,但我们没有应用任何正则化技术(如权重衰减、学习率预热或判别性微调),除了NLI。我们表明,以简单的方式微调CamemBERT可以在所有任务上取得最先进的结果,并在所有情况下优于现有的基于BERT的模型。
词性标注、依存句法分析和NER实验使用Hugging Face的Transformer库扩展以支持CamemBERT和依存句法分析(Wolf等,2019)。NLI实验使用fairseq库,遵循RoBERTa的实现。
嵌入
遵循Straková等(2019)和Straka等(2019)对mBERT和英语BERT的做法,我们在基于特征的嵌入设置中使用CamemBERT。为了获得给定词元的表示,我们首先计算Transformer最后四层中每个子词表示的平均值,然后对生成的子词向量进行平均。
我们在嵌入设置中评估CamemBERT的词性标注、依存句法分析和NER任务;使用Straka等(2019)和Straková等(2019)的开源实现。
5 CamemBERT的评估
在本节中,我们通过评估模型在四个任务上的表现来衡量其性能:词性标注(POS)、依存句法分析、命名实体识别(NER)和自然语言推理(NLI)。
词性标注和依存句法分析
对于词性标注和依存句法分析,我们在两种设置下将CamemBERT与其他模型进行比较:微调(fine-tuning)和基于特征的嵌入(feature-based embeddings)。结果如表2所示。

CamemBERT在所有树库和指标上均达到了最先进的分数。两种方法得分相近,微调版本的CamemBERT略占优势,这引发了对复杂任务特定架构(如UDPipe Future)需求的质疑。
尽管优化过程更简单且没有任务特定的架构,微调CamemBERT在所有树库上均优于UDify,有时优势显著(例如在Sequoia上LAS提高4.15%,在ParTUT上LAS提高5.37%)。CamemBERT在所有树库上的表现也优于其他多语言预训练模型(如mBERT和XLMMLM-TLM)。
CamemBERT总体上略优于之前的最先进任务特定架构UDPipe Future+mBERT+Flair,除了在Sequoia的词性标注和Spoken的词性标注上,CamemBERT分别落后0.03%和0.14%的UPOS分数。UDPipe Future+mBERT+Flair使用了Flair(Akbik等,2018)的上下文字符串嵌入,这些嵌入实际上是预训练的上下文字符级词嵌入,专门用于处理拼写错误以及前缀和后缀等子词结构。这种设计选择可能解释了CamemBERT在词性标注上的分数差异,尤其是在Spoken树库中,单词未大写,这可能对CamemBERT造成问题(因为其训练数据是大写的),但Flair在UDPipe Future+mBERT+Flair模型中可能能够正确处理。
命名实体识别
对于NER,我们同样在微调设置和作为任务特定架构LSTM+CRF的输入嵌入中评估CamemBERT。结果如表3所示。


在两种情况下,CamemBERT的F1分数均高于传统的基于CRF的架构(包括非神经网络和神经网络)以及微调的多语言BERT模型。将CamemBERT作为嵌入用于传统的LSTM+CRF架构时,得分略高于微调模型(89.08 vs. 89.55)。这表明,尽管CamemBERT可以在没有任何任务特定架构的情况下成功使用,但它仍然可以生成高质量的上下文嵌入,这在存在强大下游架构的场景中可能非常有用。
自然语言推理
在XNLI基准测试中,我们将CamemBERT与之前最先进的多语言模型在微调设置下进行比较。除了标准的BASE架构CamemBERT模型外,我们还训练了一个LARGE架构的模型,称为CamemBERTLARGE,以便与XLM-RLARGE进行公平比较。该模型使用第6节中描述的CCNet语料库训练了100k步。我们预计,更长时间的训练会带来更好的性能。
CamemBERT的准确率高于其BASE架构的同类模型,比mBERT高出5.6%,比XLMMLM-TLM高出2.3%,比XLM-RBASE高出2.4%。CamemBERT使用的参数数量仅为XLM-RBASE的一半(1.1亿 vs. 2.7亿)。
CamemBERTLARGE在XNLI基准测试中达到了85.7%的最先进准确率,而最近的XLM-RLARGE为85.2%。CamemBERT使用的参数比多语言模型少,主要是因为其词汇量较小(例如32k vs. XLM-R的250k)。有两个因素可能解释了CamemBERT优于XLM-R的原因。尽管XLM-R在2.5TB的数据上进行了训练,但其中只有57GB是法语数据,而我们使用了138GB的法语数据。此外,XLM-R还处理100种语言,作者表明,当将语言数量减少到7种时,他们的BASE架构可以在法语XNLI上达到82.5%的准确率。
CamemBERT结果总结
CamemBERT在考虑的4个下游任务中改进了现有技术水平,从而在法语上证实了基于Transformer模型的有效性。无论是将CamemBERT作为微调模型使用,还是将其作为上下文嵌入与任务特定架构结合使用,我们都取得了这些结果。这引发了对更复杂下游架构需求的质疑,类似于在英语中展示的结果(Devlin等,2019)。此外,这表明CamemBERT无需进一步调整即可生成高质量的表示。
6 语料库来源和规模的影响
在本节中,我们研究了预训练语料库的同质性和规模对下游任务性能的影响。为此,我们通过改变预训练数据集来训练不同版本的CamemBERT。在本实验中,我们将预训练步数固定为100k,并允许epoch数相应变化(数据集较小时epoch数更多)。所有模型均使用BASE架构。
为了研究是否需要同质的干净数据,还是更需要多样化且可能噪声较多的数据,我们除了使用OSCAR外,还使用了其他预训练数据来源:
- 维基百科:在文体和风格上具有同质性。我们使用2019年法文维基百科的官方数据,并使用Giuseppe Attardi的WikiExtractor去除HTML标签和表格。
- CCNet(Wenzek等,2019):从Common Crawl中提取的数据集,其过滤过程与OSCAR不同。它使用在维基百科上训练的语言模型来过滤低质量文本(如代码或表格)。由于这一过滤步骤将Common Crawl中的噪声数据偏向于更类似维基百科的文本,我们预计CCNet将作为未过滤的“噪声”OSCAR数据集和“干净”维基百科数据集之间的中间地带。由于不同的过滤过程,CCNet平均包含更长的文档,而OSCAR中的文档较短且通常噪声较多。
表6总结了这些不同语料库的统计数据。
为了比较这三种预训练数据来源,我们从OSCAR和CCNet中随机抽取4GB文本(以文档为单位),从而创建与法文维基百科规模相同的Common Crawl语料库样本。这些较小的4GB样本还为我们提供了一种研究预训练数据规模影响的方法。表5提供了不同版本CamemBERT的下游任务性能。上半部分报告了微调设置下的分数,下半部分报告了嵌入设置下的分数。


6.1 Common Crawl vs. 维基百科?
表5清楚地表明,在4GB版本的OSCAR和CCNet(Common Crawl)上训练的模型表现始终优于在法文维基百科上训练的模型。无论是在微调设置还是嵌入设置中,这一结论都成立。不出所料,在涉及与维基百科文体和风格差异较大的任务(如Spoken树库上的标注和解析)中,差距更大。在XNLI任务上,性能差距也非常大,这可能是由于基于Common Crawl的语料库在文体和主题上的多样性更大。XNLI基于multiNLI,涵盖了多种口语和书面文本的文体。
在4GB版本的CCNet和OSCAR上训练的模型在下游任务中的表现非常相似。
6.2 需要多少数据?
我们实验的一个意外结果是,仅在4GB OSCAR样本上训练的模型与在整个138GB OSCAR上训练的标准CamemBERT表现相似。唯一存在较大性能差距的任务是NER,其中“138GB”模型的F1分数高出0.9分。这可能是由于较大语料库中存在更多的命名实体,这对该任务有益。相反,其他任务似乎并未从额外数据中获益。
换句话说,当在OSCAR和CCNet等文体和风格多样化的语料库上训练时,4GB的未压缩文本足以作为预训练语料库,在使用BASE架构时达到最先进的结果,优于在60GB文本上预训练的mBERT。这引发了对训练单语Transformer语言模型(如BERT或RoBERTa)时是否需要使用OSCAR或CCNet等大型语料库的质疑。
这不仅意味着训练最先进语言模型的计算(以及环境)成本可以降低,还意味着可以为所有能够创建4GB或更大Common Crawl语料库的语言训练类似CamemBERT的模型。OSCAR支持166种语言,并为38种语言提供了这样的语料库。此外,稍小的语料库(例如低至1GB)也可能足以训练高性能的语言模型。
我们的结果是在BASE架构上获得的。需要进一步研究以验证我们的发现在更大架构和其他更复杂的自然语言理解任务中的有效性。然而,即使使用BASE架构和4GB训练数据,验证损失在100k步(400个epoch)后仍在下降。这表明我们仍然对4GB预训练数据集欠拟合,更长时间的训练可能会提高下游性能。
7 讨论
自本工作预发表以来(Martin等,2019),许多单语语言模型相继出现,例如(Le等,2019;Virtanen等,2019;Delobelle等,2020),涵盖了多达30种语言(Nozza等,2020)。在几乎所有测试配置中,这些模型的表现均优于多语言语言模型(如mBERT)(Pires等,2019)。有趣的是,Le等(2019)表明,将他们的FlauBert(一种基于RoBERTa的法语语言模型,训练数据较少但经过更多编辑)与CamemBERT结合使用,可以提高解析模型的性能,并在法语成分句法分析中建立了新的最先进水平,从而突出了两种模型的互补性。
与BERT首次发布时的英语情况类似,法语类似规模语言模型的可用性促进了有趣的应用,例如法律文本的大规模匿名化,其中基于CamemBERT的模型在该任务上建立了新的最先进水平(Benesty,2019),或最近发布的法语Squad数据集上的首次大规模问答实验(d’Hoffschmidt等,2020),作者使用CamemBERTLARGE达到了人类水平的表现。作为第一个使用开源Common Crawl Oscar语料库的预训练语言模型,CamemBERT对社区产生了重要影响,为后续许多单语语言模型的研究铺平了道路。此外,其所有训练数据的可用性促进了可重复性,并为更好地理解此类模型迈出了一步。本着这种精神,我们通过我们的网站以及huggingface和fairseq API提供了实验中使用的模型,包括基础的CamemBERT模型。
8 结论
在本工作中,我们探讨了为英语以外的语言训练基于Transformer的语言模型的可行性。以法语为例,我们训练了CamemBERT,这是一种基于RoBERTa的语言模型。我们在四个下游任务(词性标注、依存句法分析、命名实体识别和自然语言推理)上评估了CamemBERT,在这些任务中,我们的最佳模型达到或改进了所有任务的最先进水平,即使与强大的多语言模型(如mBERT、XLM和XLM-R)相比也是如此,同时参数数量更少。
我们的实验表明,使用具有高多样性的网络爬取数据优于基于维基百科的数据。此外,我们展示了我们的模型在仅使用4GB预训练数据的情况下可以达到惊人的高性能,从而质疑了大规模预训练语料库的必要性。这表明,只要有几千兆字节的数据可用,就可以为资源远少于英语的语言训练最先进的基于Transformer的语言模型。这为资源匮乏语言的单语上下文预训练语言模型的兴起铺平了道路。关于在小规模领域特定内容上进行预训练是否比微调等迁移学习技术更好的问题仍然开放,我们将其留给未来的工作。
CamemBERT基于纯开源语料库进行预训练,并通过MIT许可证免费提供,可通过流行的NLP库(fairseq和huggingface)以及我们的网站camembert-model.fr获取。
#附录
在附录中,我们分析了CamemBERT的不同设计选择(表8),包括全词掩码的使用、训练数据集、模型规模以及训练步数,并结合语料库来源和规模的影响分析(第6节)。在所有消融实验中,所有分数均来自至少4次运行的平均值。对于词性标注和依存句法分析,我们在4个树库上取平均分数。我们还在表7中报告了不同模型的所有平均测试分数。
A 全词掩码的影响
在表8中,我们比较了使用传统子词掩码和全词掩码训练的模型。全词掩码对自然语言推理(NLI)的下游性能有积极影响(尽管仅提高了0.5个准确率点)。令人惊讶的是,这种全词掩码方案对命名实体识别(NER)、词性标注和依存句法分析等较低层次任务的帮助不大。
B 模型规模的影响
表8比较了使用BASE和LARGE架构训练的模型。出于实际原因,这些模型使用CCNet语料库(135GB)进行训练。我们证实了较大模型对NLI和NER任务的积极影响。LARGE架构分别减少了19.7%和23.7%的错误率。令人惊讶的是,在词性标注和依存句法分析上,增加三倍的参数并未带来与BASE模型相比的显著差异。Tenney等(2019)和Jawahar等(2019)表明,BERT的低层已经学习了低层次的句法能力,而高层次的语义表示则存在于BERT的高层中。词性标注和依存句法分析可能不会从增加更多层中受益,因为BASE架构的低层已经捕捉到了完成这些任务所需的信息。
C 训练数据集的影响
表8比较了在CCNet和OSCAR上训练的模型。两个数据集的主要区别在于CCNet的额外过滤步骤偏向于类似维基百科的文本。在OSCAR上预训练的模型在词性标注和依存句法分析上表现略好,但在NER上提高了1.31分。CCNet模型在NLI上表现更好(提高了0.67分)。

D 训练步数的影响
图1展示了下游任务性能随训练步数的变化情况。本节中的所有分数均为至少4次不同随机种子运行的平均值。对于词性标注和依存句法分析,我们还在4个树库上取平均分数。
我们每个epoch(1个epoch等于8360步)评估一次模型,并报告掩码语言建模的困惑度以及下游任务的表现。图1表明,任务越复杂,训练步数的影响越大。我们观察到,依存句法分析和NER在大约22k步时达到早期平台期,而对于NLI,尽管随着预训练步数的增加,边际改善变小,但在100k步时性能仍在缓慢提升。
在表8中,我们比较了两个在CCNet上训练的模型,一个训练了100k步,另一个训练了500k步,以评估总训练步数的影响。训练500k步的模型在词性标注和解析任务上的分数相比100k步并没有显著提高。对于XNLI,提升略高(+0.84分)。
这些结果表明,低层次的句法表示在语言模型训练的早期阶段就被捕捉到,而提取NLI所需的复杂语义信息则需要更多的训练步数。


相关文章:
CamemBERT:一款出色的法语语言模型
摘要 预训练语言模型在自然语言处理中已无处不在。尽管这些模型取得了成功,但大多数可用模型要么是在英语数据上训练的,要么是在多种语言数据拼接的基础上训练的。这使得这些模型在除英语以外的所有语言中的实际应用非常有限。本文探讨了为其他语言训练…...

0基础跟德姆(dom)一起学AI 自然语言处理18-解码器部分实现
1 解码器介绍 解码器部分: 由N个解码器层堆叠而成每个解码器层由三个子层连接结构组成第一个子层连接结构包括一个多头自注意力子层和规范化层以及一个残差连接第二个子层连接结构包括一个多头注意力子层和规范化层以及一个残差连接第三个子层连接结构包括一个前馈全连接子层…...

我的创作纪念日——我与CSDN一起走过的365天
目录 一、机缘:旅程的开始 二、收获:沿路的花朵 三、日常:不断前行中 四、成就:一点小确幸 五、憧憬:梦中的重点 一、机缘:旅程的开始 最开始开始写博客是在今年一二月份的时候,也就是上一…...

C++:bfs解决多源最短路与拓扑排序问题习题
1. 多源最短路 其实就是将所有源头都加入队列, 01矩阵 LCR 107. 01 矩阵 - 力扣(LeetCode) 思路 求每个元素到离其最近0的距离如果我们将1当做源头加入队列的话,无法处理多个连续1的距离存储,我们反其道而行之&…...

【面试题】JVM部分[2025/1/13 ~ 2025/1/19]
JVM部分[2025/1/13 ~ 2025/1/19] 1. JVM 由哪些部分组成?2. Java 的类加载过程是怎样的?3. 请你介绍下 JVM 内存模型,分为哪些区域?各区域的作用是什么?4. JVM 垃圾回收调优的主要目标是什么?5. 如何对 Jav…...

文献综述相关ChatGPT提示词分享
文献综述 ChatGPT 可以帮助提高文献综述的有效性和全面性。ChatGPT可以高效搜索和审查与宝子们课题研究相关的文献资料来源。一些给力的插件工具还可以帮助您总结复杂的研究论文并提取信息以更快更好地消化信息。合理的运用ChatGPT和GPTs可以提高文献综述的清晰度和质量&#…...

Excel 技巧14 - 如何批量删除表格中的空行(★)
本文讲如何批量删除表格中的空行。 1,如何批量删除表格中的空行 要点就是按下F5,然后选择空值条件以定位所有空行,然后删除即可。 按下F5 点 定位条件 选 空值,点确认 这样就选中了空行 然后点右键,选 删除 选中 下方…...

图片生成Prompt编写技巧
1. 图片情绪(场景氛围) 一张图片一般都会有一个情绪基调,因为作画本质上也是在传达一些情绪,一般都会借助图片的氛围去转达。例如:比如家庭聚会一般是欢乐、喜乐融融。断壁残垣一般是悲凉。还有萧瑟、孤寂等。 2.补充细…...

【STM32-学习笔记-4-】PWM、输入捕获(PWMI)
文章目录 1、PWMPWM配置 2、输入捕获配置3、编码器 1、PWM PWM配置 配置时基单元配置输出比较单元配置输出PWM波的端口 #include "stm32f10x.h" // Device headervoid PWM_Init(void) { //**配置输出PWM波的端口**********************************…...
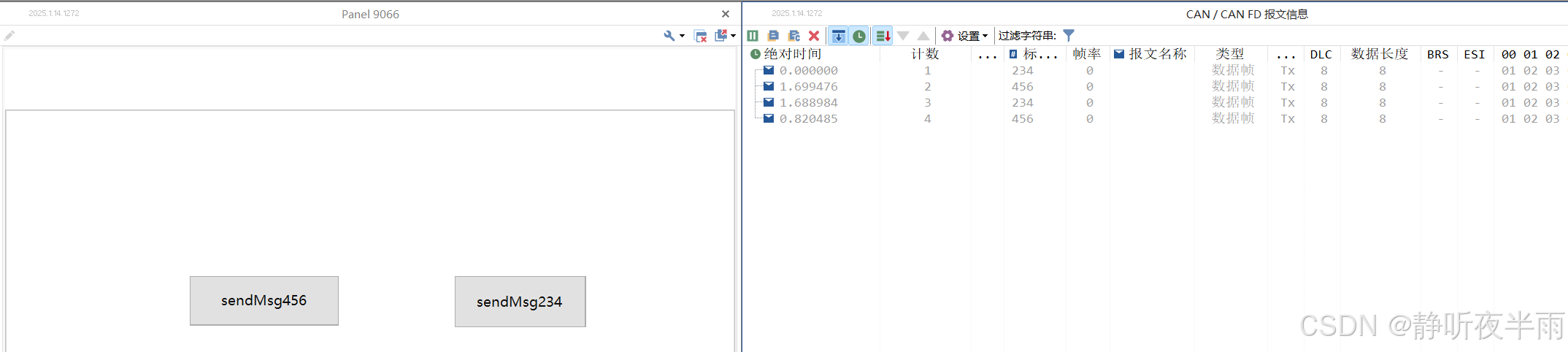
TOSUN同星TsMaster使用入门——3、使用系统变量及c小程序结合panel面板发送报文
本篇内容将介绍TsMaster中常用的Panel面板控件以及使用Panel控件通过系统变量以及c小程序来修改信号的值,控制报文的发送等。 目录 一、常用的Panel控件介绍 1.1系统——启动停止按钮 1.2 显示控件——文本框 1.3 显示控件——分组框 1.4 读写控件——按钮 1.…...

【Web】2025-SUCTF个人wp
目录 SU_blog SU_photogallery SU_POP SU_blog 先是注册功能覆盖admin账号 以admin身份登录,拿到读文件的权限 ./article?filearticles/..././..././..././..././..././..././etc/passwd ./article?filearticles/..././..././..././..././..././..././proc/1…...

React进阶之react.js、jsx模板语法及babel编译
React React介绍React官网初识React学习MVCMVVM JSX外部的元素props和内部的状态statepropsstate 生命周期constructorgetDerivedStateFromPropsrendercomponentDidMount()shouldComponentUpdategetSnapshotBeforeUpdate(prevProps, prevState) 创建项目CRA:create-…...

在Linux上如何让ollama在GPU上运行模型
之前一直在 Mac 上使用 ollama 所以没注意,最近在 Ubuntu 上运行发现一直在 CPU 上跑。我一开始以为是超显存了,因为 Mac 上如果超内存的话,那么就只用 CPU,但是我发现 Llama3.2 3B 只占用 3GB,这远没有超。看了一下命…...

R 语言科研绘图第 20 期 --- 箱线图-配对
在发表科研论文的过程中,科研绘图是必不可少的,一张好看的图形会是文章很大的加分项。 为了便于使用,本系列文章介绍的所有绘图都已收录到了 sciRplot 项目中,获取方式: R 语言科研绘图模板 --- sciRplothttps://mp.…...

suctf2025
Suctf2025 --2标识为看的wp,没环境复现了 所有参考资料将在文本末尾标明 WEB SU_photogallery 思路👇 构造一个压缩包,解压出我们想解压的部分,然后其他部分是损坏的,这样是不是就可以让整个解压过程是出错的从而…...

Quinlan C4.5剪枝U(0,6)U(1,16)等置信上限如何计算?
之前看到Quinlan中关于C4.5决策树算法剪枝环节中,关于错误率e置信区间估计,为啥 当E=0时,U(0,1)=0.75,U(0,6)=0.206,U(0,9)=0.143? 而当E不为0时,比如U(1,16)=0.157,如图: 关于C4.5决策树,Quinlan写了一本书,如下: J. Ross Quinlan (Auth.) - C4.5. Programs f…...

计算机组成原理--笔记二
目录 一.计算机系统的工作原理 二.计算机的性能指标 1.存储器的性能指标 2.CPU的性能指标 3.系统整体的性能指标(静态) 4.系统整体的性能指标(动态) 三.进制计算 1.任意进制 > 十进制 2.二进制 <> 八、十六进制…...

麒麟系统中删除权限不够的文件方法
在麒麟系统中删除权限不够的文件,可以尝试以下几种方法: 通过修改文件权限删除 打开终端:点击左下角的“终端”图标,或者通过搜索功能找到并打开终端 。定位文件:使用cd命令切换到文件所在的目录 。修改文件权限&…...

自定义提示确认弹窗-vue
最初可运行代码 弹窗组件代码: (后来发现以下代码可运行,但打包 typescript 类型检查出错,可打包的代码在文末) <template><div v-if"isVisible" class"dialog"><div class&quo…...

运行fastGPT 第五步 配置FastGPT和上传知识库 打造AI客服
运行fastGPT 第五步 配置FastGPT和上传知识库 打造AI客服 根据上一步的步骤,已经调试了ONE API的接口,下面,我们就登陆fastGPT吧 http://xxx.xxx.xxx.xxx:3000/ 这个就是你的fastGPT后台地址,可以在configer文件中找到。 账号是…...
)
从测速到配置:一套完整的cFosSpeed网络加速保姆级教程(适用于小白)
从零开始掌握cFosSpeed:网络加速全流程实战指南对于经常进行在线游戏、视频会议或大文件传输的用户来说,网络延迟和带宽利用率低下往往是影响体验的关键痛点。cFosSpeed作为一款专业的网络流量优化工具,能够显著改善这些问题,但许…...

硬件答辩问题总结
一、电源纹波是什么,为什么LDO的小,DCDC的大1.电源纹波电源纹波 是指直流电源输出电压上叠加的 交流波动成分,表现为电压在理想直流值附近上下波动。2.LDO 纹波小原理LDO 内部是一个 调整管(可变电阻) 串联在输入和输出…...

从电磁炉到户外电源:拆解单相SVPWM如何让你的逆变器更安静、更高效
从电磁炉到户外电源:单相SVPWM如何实现静音与高效的双重突破当你深夜用电磁炉煮面时,是否曾被突然的蜂鸣声吓一跳?或是发现户外电源给设备充电时,散热风扇的噪音盖过了山林鸟鸣?这些常见问题背后,隐藏着一个…...

从Office功能区的“局外人“到“掌控者“:Office RibbonX Editor深度指南
从Office功能区的"局外人"到"掌控者":Office RibbonX Editor深度指南 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/g…...
:数组排序、去重、查找)
数组专项(一):数组排序、去重、查找
大家好,欢迎来到《算法面试60讲(2026最新版全真题带解析)》第19篇!上一篇我们彻底吃透了字符串专项的核心难点——BF暴力匹配与KMP高效匹配算法,搞定了字符串模块面试最难的算法考点。从本节课开始,我们正式进入算法面试第一高频模块:数组专项。 在算法面试中,数组是出…...

光效崩坏?噪点泛滥?色温漂移?——Midjourney专业级光效渲染全流程校准协议,含ACEScg色彩空间适配模板
更多请点击: https://kaifayun.com 第一章:光效崩坏、噪点泛滥与色温漂移的系统性归因诊断 图像采集链路中出现的光效崩坏、噪点泛滥与色温漂移并非孤立现象,而是光学设计、传感器响应、ISP管线调度及环境耦合失配共同作用的结果。三者常呈现…...

我靠这个测试设计方法,把漏测率降低了80%
当“直觉测试”撞上南墙很长一段时间里,我和许多测试同行一样,测试用例的设计主要依靠两样东西:需求文档和“测试直觉”。这种模式在业务逻辑相对简单、迭代速度平缓时还能勉强应付。一旦面对复杂的企业级应用、高频的敏捷迭代,或…...
Transient、QuickEye、VerifyEye傻傻分不清?一文讲透Ansys里三种眼图仿真方法的适用场景与避坑指南
Transient、QuickEye、VerifyEye深度解析:Ansys眼图仿真技术选型实战指南 在高速数字系统设计中,眼图分析是评估信号完整性的黄金标准。面对Ansys工具链中三种截然不同的眼图生成方法,工程师常常陷入选择困境——是追求精确度的传统瞬态分析&…...

厨房空调技术白皮书:从风冷到水冷,制冷系统在厨房场景中的工程化演进
厨房空调是暖通行业近三年技术迭代最密集的细分品类。从最初的"凉霸"(本质是风扇),到风冷分体式,再到水冷一体式,每代技术都在解决上一代没有覆盖的用户痛点。本文以工程技术视角,梳理四代厨房制…...

深度解析DeTikZify:科研工作者的智能图表生成神器
深度解析DeTikZify:科研工作者的智能图表生成神器 【免费下载链接】DeTikZify Synthesizing Graphics Programs for Scientific Figures and Sketches with TikZ. 项目地址: https://gitcode.com/gh_mirrors/de/DeTikZify 在科研工作中,创建高质量…...