图像去雾数据集的下载和预处理操作
前言
目前,因为要做对比实验,收集了一下去雾数据集,并且建立了一个数据集的预处理工程。
这是以前我写的一个小仓库,我决定还是把它用起来,下面将展示下载的路径和数据处理的方法。
下面的代码均可以在此找到。Auorui/img-processing-techniques: Used for data set image processing
I-HAZE
下载地址:I-HAZE.zip
具有真实朦胧和无雾霾室内图像的去雾基准,包含 35 对朦胧和相应的无雾(地面实况)室内图像。实际下载下来只有30对。

这属于是一个小的室内数据集,下载之后,文件夹名为:I-HAZY NTIRE 2018, 这里我们手动改为I_HAZY_NTIRE_2018。避免出现路径找不到的问题。
# 下载之后,文件夹名为:I-HAZY NTIRE 2018, 这里我们手动改为I_HAZY_NTIRE_2018
""" https://github.com/Auorui/img-processing-techniques
I_HAZY_NTIRE_2018- GT- hazy请注意,在去雾当中我个人习惯使用png格式的图片,如果要保留原来格式的,请注意修改格式是否正确
01_indoor_hazy.jpg -----> 1.png
"""
import os
from pathlib import Path
from natsort import natsorted
import shutildef multi_makedirs(*args):"""该函数将会放入在https://github.com/Auorui/img-processing-techniques下的 utils 文件夹当中, 以后将会多次使用为给定的多个路径创建目录, 如果路径不存在, 则创建它"""for path in args:if not os.path.exists(path):os.makedirs(path)def batch_process_I_HAZY_NTIRE_2018(target_path,save_path,start_index=None,file_ext=None,preview=True,
):file_list = natsorted(os.listdir(target_path))nums_file = len(file_list)start_index = start_index if start_index is not None else 1for i in range(nums_file):file_extension = Path(file_list[i]).suffix if file_ext is None else file_extnew_file_name = f"{start_index}{file_extension}"start_index += 1new_file_path = os.path.join(save_path, new_file_name)file_path = os.path.join(target_path, file_list[i])if not preview:shutil.copy(file_path, new_file_path)print(f"Copied: {file_path} -> {new_file_path}")if __name__=="__main__":# 建议先进行预览 True, 避免出错, 确定没问题后改为Falsepreview = False# 起始数字, 如果为None, 默认从 1 开始start_index = 1# 后缀名, 如果为None, 就使用原来的后缀file_ext = '.png'# 目标文件夹路径target_path = r'F:\dataset\Dehazy\I_HAZY_NTIRE_2018'# 防止修改错误, 完成修改之后保存到其他文件夹当中,最后删除原来文件夹,复制到文件夹下(该操作建议手动)save_gt_path = r'F:\dataset\Dehazy\I_HAZY_NTIRE_2018\cache\GT'save_hazy_path = r'F:\dataset\Dehazy\I_HAZY_NTIRE_2018\cache\hazy'target_gt_path = os.path.join(target_path, 'GT')target_hazy_path = os.path.join(target_path, 'hazy')# os.makedirs(save_gt_path, exist_ok=True)# os.makedirs(save_hazy_path, exist_ok=True)multi_makedirs(save_gt_path, save_hazy_path)batch_process_I_HAZY_NTIRE_2018(target_gt_path, save_gt_path,start_index=start_index, file_ext=file_ext, preview=preview)batch_process_I_HAZY_NTIRE_2018(target_hazy_path, save_hazy_path,start_index=start_index,file_ext=file_ext,preview=preview)O-HAZE
下载地址:O-HAZE
该数据库由成对的真实朦胧和相应的无朦胧图像组成。在实践中,朦胧图像是在真实雾霾存在的情况下由专业雾霾机生成的,O-HAZE 包含 45 个不同的户外场景,描绘了在无雾和雾霾条件下、在相同照明参数下录制的相同视觉内容。
总计共45对,操作方式同I-HAZE相同,只用换个地址就可以了。
Dense_Haze_NTIRE19
下载地址:Dense_Haze_NTIRE19.zip
一种新的去雾数据集。Dense-Haze 以密集均匀的朦胧场景为特征,包含 33 对真实朦胧和对应的各种户外场景的无雾图像。朦胧场景是通过引入由专业雾霾机生成的真实雾霾来录制的。朦胧和无朦胧的相应场景包含在相同的照明参数下捕获的相同视觉内容。
下载下来实际一共为55对,是一个室外场景,可见度很低的数据集。

# 下载之后,文件夹名为:Dense_Haze_NTIRE19
""" https://github.com/Auorui/img-processing-techniques
Dense_Haze_NTIRE19- GT- hazy
请注意,在去雾当中我个人习惯使用png格式的图片,如果要保留原来格式的,请注意修改格式是否正确
01_GT.png -----> 1.png
"""
import os
from pathlib import Path
from natsort import natsorted
import shutil
from utils import multi_makedirsdef batch_process_Dense_Haze_NTIRE19(target_path,save_path,start_index=None,file_ext=None,preview=True,
):file_list = natsorted(os.listdir(target_path))nums_file = len(file_list)start_index = start_index if start_index is not None else 1for i in range(nums_file):file_extension = Path(file_list[i]).suffix if file_ext is None else file_extnew_file_name = f"{start_index}{file_extension}"start_index += 1new_file_path = os.path.join(save_path,new_file_name)file_path = os.path.join(target_path,file_list[i])if not preview:shutil.copy(file_path, new_file_path)print(f"Copied: {file_path} -> {new_file_path}")if __name__=="__main__" :# 建议先进行预览 True, 避免出错, 确定没问题后改为Falsepreview=False# 起始数字, 如果为None, 默认从 1 开始start_index=1# 后缀名, 如果为None, 就使用原来的后缀file_ext='.png'# 目标文件夹路径target_path=r'F:\dataset\Dehazy\Dense_Haze_NTIRE19'# 防止修改错误, 完成修改之后保存到其他文件夹当中,最后删除原来文件夹,复制到文件夹下(该操作建议手动)save_gt_path=r'F:\dataset\Dehazy\Dense_Haze_NTIRE19\cache\GT'save_hazy_path=r'F:\dataset\Dehazy\Dense_Haze_NTIRE19\cache\hazy'target_gt_path=os.path.join(target_path,'GT')target_hazy_path=os.path.join(target_path,'hazy')# os.makedirs(save_gt_path, exist_ok=True)# os.makedirs(save_hazy_path, exist_ok=True)multi_makedirs(save_gt_path,save_hazy_path)batch_process_Dense_Haze_NTIRE19(target_gt_path,save_gt_path,start_index=start_index,file_ext=file_ext,preview=preview)batch_process_Dense_Haze_NTIRE19(target_hazy_path,save_hazy_path,start_index=start_index,file_ext=file_ext,preview=preview)RS-Hazy
下载地址:data - Google Drive(百度云:RS-Hazy)
这是一个带有云雾的遥感图像,因为这部分很早之前就下载下来了,数据处理的部分已经找不到了,因为实在是太大了(40G左右),这里大家就慢慢下载吧。
实际上这个也是合成图像,原理应该还是用的是大气散射模型生成的(没怎么注意看)应该是根据这个遥感的内参生成的(不了解我自己猜测的)。但我其实有一套比他这个更好的生成云雾的方法。

RESIDE-standard
下载地址:李博义 - 对单张图像去雾及其他进行基准测试
RESIDE 突出显示了不同的数据源和图像内容,并分为五个子集,每个子集用于不同的训练或评估目的。
请一定一定注意,如果下方百度云链接打不开,请新开一个网页复制到地址栏再试试。
ITS (Indoor Training Set)
(Dropbox): https://bit.ly/3iwHmh0
(Baidu Yun):http://tinyurl.com/yaohd3yv Passward: g0s6
建议大家用百度云下载,我挂上Dropbox,但又太大了下载不下来。
这个我发现问题有点多啊,它这个是1399张清晰图像,但又有13990张有雾图像,相当于是每张清晰图像对应了10张模糊图像,但不管是写dataset还是将清晰图像每张复制10份都相当的麻烦。

并且我发现这10张图像的雾度都差不多,所幸就直接随机10抽1。并且由于这里的数量还算充足,我们就划分一下训练验证测试集。
# ITS (Indoor Training Set)
# 下载的时候文件夹名为 ITS_v2
""" https://github.com/Auorui/img-processing-techniques
ITS_v2- clear- hazy
请注意,在去雾当中我个人习惯使用png格式的图片,如果要保留原来格式的,请注意修改格式是否正确
hazy: 1_1_0.90179.png -----> 1_1.pngclear 是按照我们的目标格式来的
"""
# 先修改 ./ITS_v2/hazy下文件的命名格式, 直接在原有基础上修改
import os
from pathlib import Path
from natsort import natsorted
import shutil
from utils import multi_makedirs
from math import ceil
import randomdef SearchFileName(target_path, file_ext='.png'):"""该函数将会放入在https://github.com/Auorui/img-processing-techniques下的 utils 文件夹当中, 以后将会多次使用仅仅搜索目标文件夹下合适格式的文件名"""all_files = os.listdir(target_path)png_files = [file for file in all_files if file.lower().endswith(file_ext)]sorted_png_files = natsorted(png_files)return sorted_png_filesdef batch_process_ITS_v2_hazy(target_path,file_ext=None,preview=True,
):file_name_list = SearchFileName(target_path)nums_file = len(file_name_list)for i in range(nums_file):file_extension = Path(file_name_list[i]).suffix if file_ext is None else file_ext# 1399_8_0.74031 -----> 1399_8file_name_no_suffix = os.path.splitext(file_name_list[i])[0].split('_')new_name = file_name_no_suffix[0] + "_" + file_name_no_suffix[1]new_file_name = f"{new_name}{file_extension}"old_file_path=os.path.join(target_path, file_name_list[i])new_file_path=os.path.join(target_path, new_file_name)if not preview:os.rename(old_file_path, new_file_path)print(f"Renamed: {file_name_list[i]} -> {new_file_name}")def divide_ITS_v2_dataset(target_path,save_path,train_ratio,val_ratio,shuffle=True,preview=True,
) :original_gt_path = os.path.join(target_path, 'clear')original_hazy_path = os.path.join(target_path, 'hazy')save_train_path = os.path.join(save_path, "train")save_val_path = os.path.join(save_path, "val")save_test_path = os.path.join(save_path, "test")train_txt_path = os.path.join(save_path, "train.txt")val_txt_path = os.path.join(save_path, "val.txt")test_txt_path = os.path.join(save_path, "test.txt")multi_makedirs(os.path.join(save_train_path, "GT"), os.path.join(save_train_path, 'hazy'),os.path.join(save_val_path, "GT"), os.path.join(save_val_path, 'hazy'),os.path.join(save_test_path, "GT"), os.path.join(save_test_path, 'hazy'),)file_name_list = SearchFileName(original_gt_path)if shuffle:random.shuffle(file_name_list)nums_file = len(file_name_list)train_nums = ceil(nums_file * train_ratio)if train_ratio + val_ratio == 1.:val_nums = nums_file - train_numstest_nums = 0else:val_nums = ceil(nums_file * val_ratio)test_nums = nums_file-(train_nums+val_nums)print(f"划分数据集数量, 总数{nums_file}, train:{train_nums}, test:{val_nums}, test:{test_nums}")total = total1 = total2 = 1for i in range(train_nums):image_gt_name = file_name_list[i]image_hazy_name = f"{image_gt_name.split('.')[0]}_{random.randint(1, 10)}.{image_gt_name.split('.')[1]}"a_gt_path = os.path.join(original_gt_path, image_gt_name)a_hazy_path = os.path.join(original_hazy_path, image_hazy_name)save_new_path_gt = os.path.join(save_train_path, "GT", image_gt_name)save_new_path_hazy = os.path.join(save_train_path, "hazy", image_gt_name)if not preview:shutil.copy(a_gt_path, save_new_path_gt)shutil.copy(a_hazy_path, save_new_path_hazy)with open(train_txt_path, 'a') as train_txt_file:train_txt_file.write(image_gt_name.split('.')[0] +'\n')print(f"{total} train: {i + 1}\n"f"{a_gt_path} ----> {save_new_path_gt}\n"f"{a_hazy_path} ----> {save_new_path_hazy}")total += 1for i in range(train_nums, nums_file):if i < train_nums + val_nums:image_gt_name = file_name_list[i]image_hazy_name = f"{image_gt_name.split('.')[0]}_{random.randint(1,10)}.{image_gt_name.split('.')[1]}"a_gt_path = os.path.join(original_gt_path,image_gt_name)a_hazy_path = os.path.join(original_hazy_path,image_hazy_name)save_new_path_gt = os.path.join(save_train_path,"GT",image_gt_name)save_new_path_hazy = os.path.join(save_train_path,"hazy",image_gt_name)if not preview:shutil.copy(a_gt_path, save_new_path_gt)shutil.copy(a_hazy_path, save_new_path_hazy)with open(val_txt_path, 'a') as val_txt_file :val_txt_file.write(image_gt_name.split('.')[0]+'\n')print(f"{total} val: {i+1}\n"f"{a_gt_path} ----> {save_new_path_gt}\n"f"{a_hazy_path} ----> {save_new_path_hazy}")total1 += 1else:image_gt_name = file_name_list[i]image_hazy_name = f"{image_gt_name.split('.')[0]}_{random.randint(1,10)}.{image_gt_name.split('.')[1]}"a_gt_path = os.path.join(original_gt_path,image_gt_name)a_hazy_path = os.path.join(original_hazy_path,image_hazy_name)save_new_path_gt = os.path.join(save_train_path,"GT",image_gt_name)save_new_path_hazy = os.path.join(save_train_path,"hazy",image_gt_name)if not preview:shutil.copy(a_gt_path, save_new_path_gt)shutil.copy(a_hazy_path, save_new_path_hazy)with open(test_txt_path, 'a') as test_txt_file :test_txt_file.write(image_gt_name.split('.')[0]+'\n')print(f"{total2} test: {i+1}\n"f"{a_gt_path} ----> {save_new_path_gt}\n"f"{a_hazy_path} ----> {save_new_path_hazy}")total2 += 1if __name__=="__main__":def rename_ITS_v2_hazy() :# 建议先进行预览 True, 避免出错, 确定没问题后改为Falsepreview=True# 目标文件夹路径original_hazy_path=r'F:\dataset\Dehazy\ITS_v2\hazy'# 后缀名, 如果为None, 就使用原来的后缀file_ext='.png'batch_process_ITS_v2_hazy(original_hazy_path,file_ext,preview)# 先运行这个代码, 完了之后注释掉, 再运行下面代码, 参数直接在函数内部修改# rename_ITS_v2_hazy()# 建议先进行预览 True, 避免出错, 确定没问题后改为Falsepreview = False# 训练集比例train_ratio = 0.7# 验证集比例,剩下的就是测试集比例,如果train_ratio + val_ratio = 1. ,则不划分测试集val_ratio = 0.2# 是否打乱数据集划分顺序shuffle = Trueoriginal_path = r'F:\dataset\Dehazy\ITS_v2'save_path = r'F:\dataset\Dehazy\ITS_v2\cache'divide_ITS_v2_dataset(original_path, save_path, train_ratio, val_ratio,shuffle=shuffle, preview=preview)
HSTS(Hybrid Subjective Testing Set)
(Dropbox) :https://bit.ly/394pcAm
(Baidu Yun):https://pan.baidu.com/s/1cl1exWnaFXe3T5-Hr7TJIg Passward: vzeq
这个我简单的看了一下,只有十张图片而已,我感觉没必要单独弄,这里可以讲其放到室外场景当中去。

SOTS-indoor
(Dropbox): https://bit.ly/2XZH498
(Baidu Yun): https://pan.baidu.com/share/init?surl=SSVzR058DX5ar5WL5oBTLg Passward: s6tu
这个就又跟上面的十选一是一样的。但因为gt图像只有50张,对应的合成雾图总计500张,所以,这里我们就直接扩充一下(太让人头疼了)。

# SOTS 的 indoor, gt图像50张, hazy图像500张, 跟ITS一样, 一张 gt 对应十张合成 hazy
""" https://github.com/Auorui/img-processing-techniques
SOTS/indoor- gt- hazy
请注意,在去雾当中我个人习惯使用png格式的图片,如果要保留原来格式的,请注意修改格式是否正确
hazy: 1400.png -----> 1400_1.png、1400_2.png、1400_3.png...
"""
import os
from pathlib import Path
import shutil
from utils import multi_makedirs, SearchFileNamedef batch_process_SOTS_indoor(target_path,save_path,file_ext=None,preview=True,
):file_name_list = SearchFileName(target_path)nums_file = len(file_name_list)for i in range(nums_file):file_extension = Path(file_name_list[i]).suffix if file_ext is None else file_extimage_file_name = file_name_list[i]original_file_path = os.path.join(target_path, image_file_name)for j in range(1, 11): # 复制10份,从1到10new_file_name = f"{file_name_list[i].split('.')[0]}_{j}{file_extension}"new_file_path = os.path.join(save_path, new_file_name)if not preview:shutil.copy2(original_file_path, new_file_path)print(f"Copying {original_file_path} to {new_file_path}")if __name__=="__main__":# 后缀名, 如果为None, 就使用原来的后缀file_ext = '.png'# 建议先进行预览 True, 避免出错, 确定没问题后改为Falsepreview = Falseoriginal_path = r'F:\dataset\Dehazy\SOTS\indoor\gt'save_path = r'F:\dataset\Dehazy\SOTS\indoor\GT'multi_makedirs(save_path)batch_process_SOTS_indoor(original_path, save_path, file_ext=file_ext, preview=preview)SOTS-outdoor
下载地址同上。数据集中清晰图共492张,合成图共500张,合成图中有一些重合的,我一张一张找出来的。所以修正过后共计492对。

""" 数据集中清晰图共492张,合成图共500张,合成图中有一些重合的,我一张一张找出来的。所以修正过后共计492对。
SOTS/indoor- GT- hazy
"""
import os
from pathlib import Path
import shutil
from utils import multi_makedirs, SearchFileNamedef batch_process_SOTS_outdoor(target_path,save_path,start_index=1,file_ext=None,search='.jpg',preview=True,
):file_name_list = SearchFileName(target_path, search)nums_file = len(file_name_list)start_index=start_index if start_index is not None else 1for i in range(nums_file):file_extension = Path(file_name_list[i]).suffix if file_ext is None else file_extimage_file_name = file_name_list[i]original_file_path = os.path.join(target_path, image_file_name)new_file_name = f"{start_index}{file_extension}"new_file_path = os.path.join(save_path, new_file_name)if not preview :shutil.copy(original_file_path, new_file_path)print(f"Copied: {original_file_path} -> {new_file_path}")start_index += 1if __name__=="__main__":# 建议先进行预览 True, 避免出错, 确定没问题后改为Falsepreview = Falsetarget_path = r"F:\dataset\Dehazy\SOTS\outdoor"save_path = r'F:\dataset\Dehazy\SOTS\outdoor\cache'save_gt_path = os.path.join(save_path, 'GT')save_hazy_path = os.path.join(save_path, 'hazy')multi_makedirs(save_hazy_path, save_gt_path)target_gt_path=os.path.join(target_path, 'gt')target_hazy_path = os.path.join(target_path, 'hazy')batch_process_SOTS_outdoor(target_gt_path, save_gt_path, file_ext='.png',search='.png', preview=preview)batch_process_SOTS_outdoor(target_hazy_path, save_hazy_path, file_ext='.png',search='.jpg', preview=preview)
RESIDE-β
下载地址:RESIDE-β
这里面,只有OST可以使用,另外两个一个是下载不下来,一个是没有对比的标准图。所以这里只做了OST。
OTS (Outdoor Training Set)
(Dropbox): https://bit.ly/3k8a0Gf
(Baidu Yun): https://pan.baidu.com/s/1YMYUp5P6FpX_5b7emjgrvA Passward: w54h
这个更是重量级,一张清晰图对应35张,简直...
还有它hazy文件夹下不是放的全部,分成了4个文件夹,数据清洗真麻烦。
这里我将4个part文件夹都归到了hazy当中,clear每隔35命名一次
# 一张清晰图对应35张, hazy文件夹下不是放的全部,分成了4个part文件夹, 清洗数据很麻烦
"""
OTS_BETA- clear- hazy- part1- part2- part3- part4
4个part文件夹都归到hazy当中, 总计72135, clear每隔三十五进行一次命名, 若是每张扩充到35就太大了,
所以我准备还是将其写到dataset会更好
"""
import os
from pathlib import Path
from natsort import natsorted
import shutil
from utils import multi_makedirs, SearchFileNamedef batch_rename_hazy_file(target_path,save_path,start_index=None,file_ext=None,search='.jpg',preview=True,
):file_name_list = []for i in range(1, 5):target_part_path = os.path.join(target_path, f"part{i}")file_name_list.append(SearchFileName(target_part_path, search))# print(flattened_list, nums_file)start_index = start_index if start_index is not None else 1for i in range(1, 5):target_part_path = os.path.join(target_path, f"part{i}")flattened_list = file_name_list[i - 1]nums_file = len(flattened_list)for j in range(nums_file):file_extension = Path(flattened_list[j]).suffix if file_ext is None else file_extimage_file_name = flattened_list[j]original_file_path = os.path.join(target_part_path, image_file_name)new_file_name = f"{start_index}{file_extension}"new_file_path = os.path.join(save_path, new_file_name)if not preview:shutil.copy(original_file_path, new_file_path)print(f"Copied: {original_file_path} -> {new_file_path}")start_index += 1def batch_rename_GT_file(target_path,save_path,start_index=None,file_ext=None,search='.jpg',preview=True,
):file_name_list = SearchFileName(target_path, search)nums_file=len(file_name_list)print(nums_file)start_index=start_index if start_index is not None else 1for i in range(nums_file):file_extension=Path(file_name_list[i]).suffix if file_ext is None else file_extoriginal_file_path = os.path.join(target_path, file_name_list[i])new_file_name=f"{start_index}{file_extension}"new_file_path=os.path.join(save_path, new_file_name)if not preview :shutil.copy(original_file_path,new_file_path)print(f"{i+1} Copied: {original_file_path} -> {new_file_path}")start_index+=35if __name__=="__main__":def process_hazy():preview = Truefile_ext = '.png'search='.jpg'target_hazy_path = r'F:\dataset\Dehazy\OTS_BETA\haze'save_hazy_path = r'F:\dataset\Dehazy\OTS_BETA\hazy'multi_makedirs(save_hazy_path)batch_rename_hazy_file(target_hazy_path, save_hazy_path,file_ext=file_ext, search=search, preview=preview)def process_GT():preview = Falsefile_ext = '.png'search='.jpg'target_gt_path = r'F:\dataset\Dehazy\OTS_BETA\clear'save_gt_path = r'F:\dataset\Dehazy\OTS_BETA\GT'multi_makedirs(save_gt_path)batch_rename_GT_file(target_gt_path, save_gt_path,file_ext=file_ext, search=search, preview=preview)# process_hazy()process_GT()后面还有再更。
相关文章:
图像去雾数据集的下载和预处理操作
前言 目前,因为要做对比实验,收集了一下去雾数据集,并且建立了一个数据集的预处理工程。 这是以前我写的一个小仓库,我决定还是把它用起来,下面将展示下载的路径和数据处理的方法。 下面的代码均可以在此找到。Auo…...
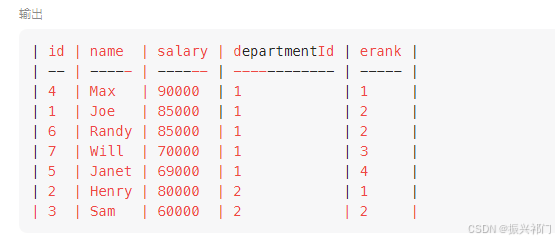
【LeetCode】--- MySQL刷题集合
1.组合两个表(外连接) select p.firstName,p.lastName,a.city,a.state from Person p left join Address a on p.personId a.personId; 以左边表为基准,去连接右边的表。取两表的交集和左表的全集 2.第二高的薪水 (子查询、if…...

基于Python的多元医疗知识图谱构建与应用研究(上)
一、引言 1.1 研究背景与意义 在当今数智化时代,医疗数据呈爆发式增长,如何高效管理和利用这些数据,成为提升医疗服务质量的关键。传统医疗数据管理方式存在数据孤岛、信息整合困难等问题,难以满足现代医疗对精准诊断和个性化治疗的需求。知识图谱作为一种知识表示和管理…...

小哆啦解题记:如何计算除自身以外数组的乘积
小哆啦开始力扣每日一题的第十二天 https://leetcode.cn/problems/product-of-array-except-self/description/ 《小哆啦解题记:如何计算除自身以外数组的乘积》 在一个清晨的阳光下,小哆啦坐在书桌前,思索着一道困扰已久的题目:…...

渐进式图片的实现原理
渐进式图片(Progressive JPEG)的实现原理与传统的基线 JPEG(Baseline JPEG)不同。它通过改变图片的编码和加载方式,使得图片在加载时能够逐步显示从模糊到清晰的图像。 1. 传统基线 JPEG 的加载方式 在传统的基线 JP…...
)
SQL刷题快速入门(三)
其他章节: SQL刷题快速入门(一) SQL刷题快速入门(二) 承接前两个章节,本系列第三章节主要讲SQL中where和having的作用和区别、 GROUP BY和ORDER BY作用和区别、表与表之间的连接操作(重点&…...

mybatis(19/134)
大致了解了一下工具类,自己手敲了一边,java的封装还是真的省去了很多麻烦,封装成一个工具类就可以不用写很多重复的步骤,一个工厂对应一个数据库一个environment就好了。 mybatis中调用sql中的delete占位符里面需要有字符…...

sqlmap 自动注入 -01
1: 先看一下sqlmap 的help: 在kali-linux 系统里面,可以sqlmap -h看一下: Target: At least one of these options has to be provided to define the target(s) -u URL, --urlURL Target URL (e.g. "Salesforce Platform for Application Development | Sa…...

3.8.Trie树
Trie树 Trie 树,又称字典树或前缀树,是一种用于高效存储和检索字符串数据的数据结构,以下是关于它的详细介绍: 定义与原理 定义:Trie 树是一种树形结构,每个节点可以包含多个子节点,用于存储…...

day 21
进程、线程、协程的区别 进程:操作系统分配资源的最小单位,其中可以包含一个或者多个线程,进程之间是独立的,可以通过进程间通信机制(管道,消息队列,共享内存,信号量,信…...

基于模板方法模式-消息队列发送
基于模板方法模式-消息队列发送 消息队列广泛应用于现代分布式系统中,作为解耦、异步处理和流量控制的重要工具。在消息队列的使用中,发送消息是常见的操作。不同的消息队列可能有不同的实现方式,例如,RabbitMQ、Kafka、RocketMQ…...

俄语画外音的特点
随着全球媒体消费的增加,语音服务呈指数级增长。作为视听翻译和本地化的一个关键方面,画外音在确保来自不同语言和文化背景的观众能够以一种真实和可访问的方式参与内容方面发挥着重要作用。说到俄语,画外音有其独特的特点、挑战和复杂性&…...

PyTorch使用教程(10)-torchinfo.summary网络结构可视化详细说明
1、基本介绍 torchinfo是一个为PyTorch用户量身定做的开源工具,其核心功能之一是summary函数。这个函数旨在简化模型的开发与调试流程,让模型架构一目了然。通过torchinfo的summary函数,用户可以快速获取模型的详细结构和统计信息࿰…...

亚博microros小车-原生ubuntu支持系列:5-姿态检测
MediaPipe 介绍参见:亚博microros小车-原生ubuntu支持系列:4-手部检测-CSDN博客 本篇继续迁移姿态检测。 一 背景知识 以下来自亚博官网 MediaPipe Pose是⼀个⽤于⾼保真⾝体姿势跟踪的ML解决⽅案,利⽤BlazePose研究,从RGB视频…...
C语言之高校学生信息快速查询系统的实现
🌟 嗨,我是LucianaiB! 🌍 总有人间一两风,填我十万八千梦。 🚀 路漫漫其修远兮,吾将上下而求索。 C语言之高校学生信息快速查询系统的实现 目录 任务陈述与分析 问题陈述问题分析 数据结构设…...

WPF基础 | WPF 基础概念全解析:布局、控件与事件
WPF基础 | WPF 基础概念全解析:布局、控件与事件 一、前言二、WPF 布局系统2.1 布局的重要性与基本原理2.2 常见布局面板2.3 布局的测量与排列过程 三、WPF 控件3.1 控件概述与分类3.2 常见控件的属性、方法与事件3.3 自定义控件 四、WPF 事件4.1 路由事件概述4.2 事…...

迷宫1.2
先发一下上次的代码 #include<bits/stdc.h> #include<windows.h> #include <conio.h> using namespace std; char a[1005][1005]{ " ", "################", "# # *#", "# # # #&qu…...

RabbitMQ---应用问题
(一)幂等性介绍 幂等性是本身是数学中的运算性质,他们可以被多次应用,但是不会改变初始应用的结果 1.应用程序的幂等性介绍 包括很多,有数据库幂等性,接口幂等性以及网络通信幂等性等 就比如数据库的sel…...

Unity自学之旅03
Unity自学之旅03 Unity自学之旅03📝 碰撞体 Collider 基础定义与作用常见类型OnCollisionEnter 事件碰撞触发器 🤗 总结归纳 Unity自学之旅03 📝 碰撞体 Collider 基础 定义与作用 定义:碰撞体是游戏中用于检测物体之间碰撞的组…...

pip 相关
一劳永逸法(pip怎么样都用不了也更新不了): 重下python(卸载旧版本):请输入访问密码 密码:7598 各版本python都有,下3.10.10 python路径建立,pip无法访问方式: 访问pip要…...

ARM指令追踪技术及TRCVICTLR寄存器详解
1. ARM指令追踪技术概述在嵌入式系统开发和调试过程中,指令追踪(Instruction Trace)是一项至关重要的技术。它通过硬件机制记录处理器的执行流程,为开发者提供程序运行的完整轨迹。ARM架构从v7开始引入嵌入式跟踪宏单元࿰…...

别再死记硬背SMO公式了!用Python手写一个SVM分类器,带你一步步拆解SMO核心逻辑
用Python手写SVM分类器:代码驱动理解SMO算法核心在机器学习领域,支持向量机(SVM)以其优秀的分类性能和坚实的数学基础著称。然而,许多学习者在理解其核心算法——序列最小优化(SMO)时,往往被复杂的数学推导所困扰。本文将采用一种…...

为什么鸿蒙 App 最终都会走向状态驱动?
子玥酱 (掘金 / 知乎 / CSDN / 简书 同名) 大家好,我是 子玥酱,一名长期深耕在一线的前端程序媛 👩💻。曾就职于多家知名互联网大厂,目前在某国企负责前端软件研发相关工作,主要聚…...

艾尔登法环存档迁移终极指南:3分钟解决角色转移难题
艾尔登法环存档迁移终极指南:3分钟解决角色转移难题 【免费下载链接】EldenRingSaveCopier 项目地址: https://gitcode.com/gh_mirrors/el/EldenRingSaveCopier 还在为《艾尔登法环》存档版本不兼容而烦恼吗?EldenRingSaveCopier 是你的终极解决…...

基于MAX78000与CNN的智能螺栓巡检小车:嵌入式AI实战解析
1. 项目概述与核心思路在轨道交通的日常运维中,螺栓的紧固状态检查是一项繁重且关键的任务。无论是轨道上的紧固螺栓,还是列车转向架、轮对轴承上的关键螺栓,其松动或失效都可能引发严重的安全事故。传统的人工巡检方式不仅效率低下ÿ…...

MeloTTS实战指南:解决多语言TTS部署中的核心挑战
MeloTTS实战指南:解决多语言TTS部署中的核心挑战 【免费下载链接】MeloTTS High-quality multi-lingual text-to-speech library by MyShell.ai. Support English, Spanish, French, Chinese, Japanese and Korean. 项目地址: https://gitcode.com/GitHub_Trendin…...

3大突破性功能:用HiveWE革新你的魔兽争霸III地图创作体验
3大突破性功能:用HiveWE革新你的魔兽争霸III地图创作体验 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为传统魔兽争霸III编辑器缓慢的加载速度和复杂的操作界面而烦恼吗?Hive…...

AI 如何改变软件工程:Martin Fowler 视角 + 实战洞见
AI 如何改变软件工程:Martin Fowler 视角 实战洞见 AI(尤其是 LLM)是软件工程自高级语言(从汇编到 C/Fortran)以来最大的转变。它引入了非确定性(Non-deterministic)编程,改变了从编…...

ThingLinks-IoT:一站式物联网平台解决方案
ThingLinks-IoT 物联网平台 | 多协议接入物模型告警联动视频接入AI 助手 一体化方案 一个面向项目交付与企业生产场景的国产物联网中台——把"设备接入 → 数据处理 → 告警联动 → 业务集成"这条链路上的通用能力一次性做完做稳,让你只关心自己的业务。 …...

MySQL全局ID生成实战:从自增主键到自定义Sequence的平滑升级方案与避坑指南
MySQL全局ID生成实战:从自增主键到自定义Sequence的平滑升级方案与避坑指南 当电商平台的日订单量突破百万时,技术团队突然发现系统开始频繁出现"Duplicate entry"错误——那些原本可靠的自增主键,在分库分表的环境下变成了数据一致…...