机器学习10-解读CNN代码Pytorch版
机器学习10-解读CNN代码Pytorch版
我个人是Java程序员,关于Python代码的使用过程中的相关代码事项,在此进行记录

文章目录
- 机器学习10-解读CNN代码Pytorch版
- 1-核心逻辑脉络
- 2-参考网址
- 3-解读CNN代码Pytorch版本
- 1-MNIST数据集读取
- 2-CNN网络的定义
- 1-无注释版
- 2-有注释版
- 3-CNN处理过程的几个问题
- 4-nn.Conv2d(1, 32, 3, 1)到底发生了什么变化?
- 5-经过Conv2d处理再经过relu函数又发生了什么变化?
- 1-验证代码
- 2-打印结果
- 6-为什么要用 nn.MaxPool2d(2)
- 1. 下采样程度
- 2. 保持一定空间信息
- 3. 计算效率
- 4. 模型设计和调参
- 结论
- 7-为什么要用 nn.LogSoftmax(dim=1),而不是SoftMax 作为输出层?
- 1. Softmax 的作用
- 2. 为什么使用 LogSoftmax?
- (1) 数值不稳定性
- (2) 计算交叉熵损失时的便利性
- 解决方案:LogSoftmax
- 3. LogSoftmax 的优点
- (1) 数值稳定性
- (2) 与交叉熵损失的结合
- (3) 数学上的便利性
- 4. dim=1 的含义
- 5. 为什么 LogSoftmax 是常用的输出层?
- 总结
- 8-nn.Conv2d之后一定要进行relu吗?
- 1. ReLU 的作用
- 2. 是否必须使用 ReLU?
- (1) 必须使用激活函数
- (2) ReLU 是默认选择
- (3) 其他激活函数的选择
- (4) 特定任务的需求
- (5) 架构设计的选择
- 3. 如何选择是否使用 ReLU?
- 4. `self.conv1(x)` 后面接什么?
- (1) 仅接 ReLU
- (2) 接其他激活函数
- (3) 接 BatchNorm 或其他层
- (4) 不接激活函数
- 5. 总结
- 9-什么时候使用self.dropout1(x)?
- 1. Dropout 的作用
- 2. 何时使用 Dropout?
- (1) 防止过拟合
- (2) 模型容量较大
- (3) 数据量较小
- (4) 特定任务的需求
- 3. Dropout 的使用位置
- (1) 全连接层之后
- (2) 卷积层之后
- (3) 嵌入层之后
- (4) 特定层的输出
- 4. Dropout 的参数设置
- 5. Dropout 的注意事项
- (1) 训练和测试阶段的区别
- (2) 与其他正则化方法的结合
- (3) Dropout 的替代方法
- 6. 示例代码
- 7. 总结
1-核心逻辑脉络
使用pytorch实现CNN卷积网络
-
1)数据集读取->CNN网络要求图像必须大小一致
-
2)构思神经网络,熟悉数据处理过程中每一步数据结构的变化
-
3)nn.Conv2d(1, 32, 3, 1)到底发生了什么变化?->【宽高】和【厚度】分别发生了什么变化?
-
4)经过nn.Conv2d处理后的张量,再经过relu又发生了什么变化?->真的是把参数为负数的数据全部置为0
-
5)为什么要用 nn.ReLU() 而不是 nn.Sigmoid() 或者 nn.Tanh() 作为激活函数?->计算简单
-
6)为什么要用 nn.MaxPool2d(2) 而不是 nn.MaxPool2d(3) 作为池化层?->避免特征丢失太厉害
-
7)为什么要用 nn.LogSoftmax(dim=1),而不是SoftMax 作为输出层?
-
8)nn.Conv2d之后一定要进行relu吗?
-
9)什么时候使用self.dropout1(x)?
2-参考网址
- 卷积神经网络(CNN)结构详解:https://blog.csdn.net/qq_40979103/article/details/143060425
3-解读CNN代码Pytorch版本
1-MNIST数据集读取
MNIST数据集中数据为28X28,通道为1的灰阶图片!CNN网络要求图像必须大小一致
import gzipimport matplotlib.pyplot as plt
import numpy as np# 定义MNIST文件对应的路径
MNIST_FILE_PATH = 'D:/TT_WORK+/PyCharm/20250109_1_CNN/MNIST/'# 进行本地MNIST文件的数据读取
def load_data():# 加载图像数据with gzip.open(MNIST_FILE_PATH + 'train-images-idx3-ubyte.gz', 'rb') as f: # 训练集X_train = np.frombuffer(f.read(), dtype=np.uint8, offset=16).reshape(-1, 28 * 28)with gzip.open(MNIST_FILE_PATH + 't10k-images-idx3-ubyte.gz', 'rb') as f: # 测试集标签X_test = np.frombuffer(f.read(), dtype=np.uint8, offset=16).reshape(-1, 28 * 28)# 加载标签数据with gzip.open(MNIST_FILE_PATH + 'train-labels-idx1-ubyte.gz', 'rb') as f: # 训练集标签y_train = np.frombuffer(f.read(), dtype=np.uint8, offset=8)with gzip.open(MNIST_FILE_PATH + 't10k-labels-idx1-ubyte.gz', 'rb') as f: # 测试集标签y_test = np.frombuffer(f.read(), dtype=np.uint8, offset=8)return (X_train, y_train), (X_test, y_test)# 加载MNIST数据集
(X_train, y_train), (X_test, y_test) = load_data()# 选择要显示的图像的索引
indices = [0, 1, 2, 3, 4] # 显示前5张图片# 设置画布和子图的尺寸
plt.figure(figsize=(10, 3))for i, index in enumerate(indices):# 每个子图显示一张图片plt.subplot(1, len(indices), i + 1) # 参数1, len(indices), i+1 分别表示:行数, 列数, 当前子图编号plt.imshow(X_train[index].reshape(28, 28), cmap='gray') # 将图像数据重塑为28x28,并使用灰度色图显示plt.title('Label: ' + str(y_train[index])) # 显示图像对应的标签plt.axis('off') # 不显示坐标轴# 调整子图间距
plt.subplots_adjust(hspace=0.5)# 显示整个画布
plt.show()
2-CNN网络的定义


1-无注释版
import torch
import torch.nn as nn# 定义CNN模型
class SimpleCNN(nn.Module):def __init__(self):super(SimpleCNN, self).__init__()self.conv1 = nn.Conv2d(1, 32, 3, 1)self.conv2 = nn.Conv2d(32, 64, 3, 1)self.dropout1 = nn.Dropout2d(0.25)self.dropout2 = nn.Dropout2d(0.5)self.fc1 = nn.Linear(9216, 128)self.fc2 = nn.Linear(128, 10)def forward(self, x):x = self.conv1(x)x = nn.ReLU()(x)x = self.conv2(x)x = nn.ReLU()(x)x = nn.MaxPool2d(2)(x)x = self.dropout1(x)x = torch.flatten(x, 1)x = self.fc1(x)x = nn.ReLU()(x)x = self.dropout2(x)x = self.fc2(x)output = nn.LogSoftmax(dim=1)(x)return output
2-有注释版
import torch.nn as nn
import torch
# 定义CNN模型
class SimpleCNN2(nn.Module):def __init__(self):# 调用父类 nn.Module 的初始化方法super(SimpleCNN2, self).__init__()# 定义第一个卷积层,输入通道数为1,输出通道数为32,卷积核大小为3x3,步幅为1。# 厚度变化:1->32# 宽高变化:28x28->26x26self.conv1 = nn.Conv2d(1, 32, 3, 1)# 定义第二个卷积层,输入通道数为32,输出通道数为64,卷积核大小为3x3,步幅为1。# 厚度变化:32->64# 宽高变化:26x26->24x24self.conv2 = nn.Conv2d(32, 64, 3, 1)# 定义第一个 dropout 层, dropout 比例为0.25,用于空间数据的 dropout。self.dropout1 = nn.Dropout2d(0.25)# 定义第二个 dropout 层, dropout 比例为0.5,用于空间数据的 dropout。self.dropout2 = nn.Dropout2d(0.5)# 定义第一个全连接层,输入维度为9216,输出维度为128。# 把 64x24x24 的特征图转换为 1D 向量(直接把特征图展平),所以输入维度为 9216,输出维度为 128。self.fc1 = nn.Linear(9216, 128)# 定义第二个全连接层,输入维度为128,输出维度为10。self.fc2 = nn.Linear(128, 10)"""核心处理逻辑:1)把【宽度】和【厚度】处理的结果要对上2)【宽度】变化之后,MaxPool2d(2)要减半,数据要是偶数3)nn.Linear(9216, 128)的输入维度要根据【宽度】和【厚度】变化后的结果来确定有几个问题:1)为什么要用 nn.ReLU() 而不是 nn.Sigmoid() 或者 nn.Tanh() 作为激活函数?2)为什么要用 nn.MaxPool2d(2) 而不是 nn.MaxPool2d(3) 作为池化层?3)为什么要用 nn.LogSoftmax(dim=1) 作为输出层?"""def forward(self, x):# self.conv1 = nn.Conv2d(1, 32, 3, 1)# 厚度变化:1->32# 宽高变化:28x28->26x26x = self.conv1(x)x = nn.ReLU()(x)# self.conv2 = nn.Conv2d(32, 64, 3, 1)# 厚度变化:32->64# 宽高变化:26x26->24x24x = self.conv2(x)x = nn.ReLU()(x)# 池化处理-数据宽度减半x = nn.MaxPool2d(2)(x)x = self.dropout1(x)# 深度神经网络-self.fc1 = nn.Linear(9216, 128)x = torch.flatten(x, 1)x = self.fc1(x)# 数据处理x = nn.ReLU()(x)x = self.dropout2(x)# 深度神经网络-self.fc2 = nn.Linear(128, 10)x = self.fc2(x)# 输出层使用 LogSoftmax 作为激活函数,输出概率分布output = nn.LogSoftmax(dim=1)(x)return output
3-CNN处理过程的几个问题
- 1)nn.Conv2d(1, 32, 3, 1)到底发生了什么变化?
- 2)一个经过nn.Conv2d处理后的张量,再经过relu函数又发生了什么变化?
- 3)为什么要用 nn.ReLU() 而不是 nn.Sigmoid() 或者 nn.Tanh() 作为激活函数?
- 4)为什么要用 nn.MaxPool2d(2) 而不是 nn.MaxPool2d(3) 作为池化层?
- 5)为什么要用 nn.LogSoftmax(dim=1) 作为输出层?
4-nn.Conv2d(1, 32, 3, 1)到底发生了什么变化?
- 尝试对一个张量进行Conv2d卷积变化
import torch
import torch.nn as nn# 输入矩阵
x = torch.tensor([[[[1, 2, 3, 4, 5],[6, 7, 8, 9, 10],[11, 12, 13, 14, 15],[16, 17, 18, 19, 20],[21, 22, 23, 24, 25]]]], dtype=torch.float32)print(x.shape) # 输出形状应该是 [1, 1, 5, 5]# 定义卷积层变化方式
conv1 = nn.Conv2d(1, 32, 3, 1)# 打印卷积后的输出
x_conv = conv1(x)
print(x_conv.shape) # 输出形状应该是 [1, 32, 3, 3]
print(x_conv)
- 结果打印
观察点1->经过Conv2d变化后的数据中有【负数】出现
观察点2->torch.Size([1, 1, 5, 5])含义:批量大小为1,特征图的数量为1,特征图的高度为3,特征图的宽度为3
观察点3->nn.Conv2d(1, 32, 3, 1)变化含义:把输入的数据变化->批量大小为1,特征图的数量为32,特征图的高度为3,特征图的宽度为3=(5+0x2-3)+1
思考点1->经过nn.Conv2d处理后的张量,再经过relu函数又发生了什么变化?
torch.Size([1, 1, 5, 5])torch.Size([1, 32, 3, 3])tensor([[[[ 2.3400e+00, 2.3984e+00, 2.4568e+00],[ 2.6320e+00, 2.6904e+00, 2.7488e+00],[ 2.9240e+00, 2.9824e+00, 3.0408e+00]],[[ 2.4495e+00, 2.7957e+00, 3.1419e+00],[ 4.1806e+00, 4.5268e+00, 4.8730e+00],[ 5.9116e+00, 6.2579e+00, 6.6041e+00]],[[-1.8168e+00, -1.7807e+00, -1.7446e+00],[-1.6364e+00, -1.6003e+00, -1.5643e+00],[-1.4561e+00, -1.4200e+00, -1.3839e+00]],[[ 8.6656e-01, 1.3478e+00, 1.8290e+00],[ 3.2727e+00, 3.7539e+00, 4.2351e+00],[ 5.6788e+00, 6.1601e+00, 6.6413e+00]],[[-3.9764e+00, -4.4626e+00, -4.9487e+00],[-6.4072e+00, -6.8933e+00, -7.3795e+00],[-8.8379e+00, -9.3240e+00, -9.8102e+00]],[[ 3.8094e+00, 4.3524e+00, 4.8953e+00],[ 6.5241e+00, 7.0671e+00, 7.6100e+00],[ 9.2389e+00, 9.7818e+00, 1.0325e+01]],[[-2.5623e+00, -2.2236e+00, -1.8848e+00],[-8.6853e-01, -5.2977e-01, -1.9101e-01],[ 8.2528e-01, 1.1640e+00, 1.5028e+00]],[[-3.8614e+00, -4.4056e+00, -4.9499e+00],[-6.5826e+00, -7.1269e+00, -7.6712e+00],[-9.3039e+00, -9.8482e+00, -1.0392e+01]],[[-7.1246e+00, -8.2975e+00, -9.4704e+00],[-1.2989e+01, -1.4162e+01, -1.5335e+01],[-1.8853e+01, -2.0026e+01, -2.1199e+01]],[[ 8.5972e+00, 9.4792e+00, 1.0361e+01],[ 1.3007e+01, 1.3889e+01, 1.4771e+01],[ 1.7417e+01, 1.8299e+01, 1.9181e+01]],[[ 2.2815e+00, 2.4593e+00, 2.6371e+00],[ 3.1706e+00, 3.3484e+00, 3.5262e+00],[ 4.0597e+00, 4.2375e+00, 4.4154e+00]],[[ 3.8726e-01, 3.4996e-01, 3.1266e-01],[ 2.0075e-01, 1.6345e-01, 1.2615e-01],[ 1.4249e-02, -2.3051e-02, -6.0352e-02]],[[-3.3017e+00, -3.2646e+00, -3.2274e+00],[-3.1160e+00, -3.0789e+00, -3.0417e+00],[-2.9303e+00, -2.8931e+00, -2.8560e+00]],[[ 5.9122e+00, 6.4637e+00, 7.0152e+00],[ 8.6697e+00, 9.2212e+00, 9.7727e+00],[ 1.1427e+01, 1.1979e+01, 1.2530e+01]],[[-1.7972e+00, -1.8587e+00, -1.9203e+00],[-2.1048e+00, -2.1664e+00, -2.2279e+00],[-2.4124e+00, -2.4740e+00, -2.5355e+00]],[[-3.7494e+00, -3.7197e+00, -3.6900e+00],[-3.6010e+00, -3.5714e+00, -3.5417e+00],[-3.4527e+00, -3.4231e+00, -3.3934e+00]],[[-8.7189e-01, -3.8283e-01, 1.0623e-01],[ 1.5734e+00, 2.0625e+00, 2.5515e+00],[ 4.0187e+00, 4.5078e+00, 4.9969e+00]],[[ 4.2018e+00, 4.1522e+00, 4.1025e+00],[ 3.9536e+00, 3.9040e+00, 3.8543e+00],[ 3.7054e+00, 3.6557e+00, 3.6061e+00]],[[ 4.1643e+00, 4.5711e+00, 4.9779e+00],[ 6.1984e+00, 6.6052e+00, 7.0120e+00],[ 8.2324e+00, 8.6392e+00, 9.0460e+00]],[[-3.4383e+00, -4.3284e+00, -5.2185e+00],[-7.8888e+00, -8.7788e+00, -9.6689e+00],[-1.2339e+01, -1.3229e+01, -1.4119e+01]],[[-1.8826e+00, -1.8305e+00, -1.7784e+00],[-1.6221e+00, -1.5700e+00, -1.5179e+00],[-1.3617e+00, -1.3096e+00, -1.2575e+00]],[[-2.5103e+00, -3.2022e+00, -3.8941e+00],[-5.9700e+00, -6.6619e+00, -7.3539e+00],[-9.4297e+00, -1.0122e+01, -1.0814e+01]],[[-1.5130e+00, -1.9660e+00, -2.4189e+00],[-3.7777e+00, -4.2306e+00, -4.6836e+00],[-6.0424e+00, -6.4953e+00, -6.9482e+00]],[[ 2.3745e-01, 6.6141e-01, 1.0854e+00],[ 2.3573e+00, 2.7812e+00, 3.2052e+00],[ 4.4771e+00, 4.9010e+00, 5.3250e+00]],[[ 9.3840e-01, 1.1580e+00, 1.3775e+00],[ 2.0363e+00, 2.2558e+00, 2.4754e+00],[ 3.1341e+00, 3.3537e+00, 3.5733e+00]],[[-3.8902e+00, -4.4967e+00, -5.1032e+00],[-6.9226e+00, -7.5291e+00, -8.1356e+00],[-9.9550e+00, -1.0562e+01, -1.1168e+01]],[[-2.7073e+00, -3.1963e+00, -3.6852e+00],[-5.1521e+00, -5.6411e+00, -6.1301e+00],[-7.5969e+00, -8.0859e+00, -8.5749e+00]],[[-4.9140e+00, -5.7220e+00, -6.5301e+00],[-8.9543e+00, -9.7624e+00, -1.0570e+01],[-1.2995e+01, -1.3803e+01, -1.4611e+01]],[[ 3.0557e+00, 3.3147e+00, 3.5737e+00],[ 4.3508e+00, 4.6098e+00, 4.8688e+00],[ 5.6458e+00, 5.9048e+00, 6.1638e+00]],[[-1.1789e-02, 3.9195e-01, 7.9569e-01],[ 2.0069e+00, 2.4107e+00, 2.8144e+00],[ 4.0256e+00, 4.4294e+00, 4.8331e+00]],[[-1.7682e+00, -2.2507e+00, -2.7332e+00],[-4.1808e+00, -4.6633e+00, -5.1458e+00],[-6.5933e+00, -7.0758e+00, -7.5584e+00]],[[ 2.6695e-01, 4.8650e-01, 7.0605e-01],[ 1.3647e+00, 1.5843e+00, 1.8038e+00],[ 2.4625e+00, 2.6820e+00, 2.9016e+00]]]],grad_fn=<ConvolutionBackward0>)5-经过Conv2d处理再经过relu函数又发生了什么变化?
一个经过nn.Conv2d处理后的张量,再经过relu函数又发生了什么变化?

1-验证代码
import torch
import torch.nn as nn# 输入矩阵
x = torch.tensor([[[[1, 2, 3, 4, 5],[6, 7, 8, 9, 10],[11, 12, 13, 14, 15],[16, 17, 18, 19, 20],[21, 22, 23, 24, 25]]]], dtype=torch.float32)
print(x.shape)# 定义卷积层变化方式
conv1 = nn.Conv2d(1, 32, 3, 1)# 卷积后的输出
x_conv = conv1(x)
print("卷积后的输出:\n", x_conv)# ReLU 激活后的输出
x_relu = nn.ReLU()(x_conv)
print("Relu后的输出:\n", x_relu)
2-打印结果
卷积后的输出:tensor([[[[ 6.9225e+00, 7.8138e+00, 8.7051e+00],[ 1.1379e+01, 1.2270e+01, 1.3162e+01],[ 1.5836e+01, 1.6727e+01, 1.7618e+01]],[[-6.8776e-01, -8.7886e-01, -1.0699e+00],[-1.6432e+00, -1.8343e+00, -2.0254e+00],[-2.5987e+00, -2.7898e+00, -2.9809e+00]],[[ 7.7753e+00, 8.9903e+00, 1.0205e+01],[ 1.3850e+01, 1.5066e+01, 1.6281e+01],[ 1.9926e+01, 2.1141e+01, 2.2356e+01]],[[-4.5856e+00, -4.7197e+00, -4.8537e+00],[-5.2560e+00, -5.3900e+00, -5.5241e+00],[-5.9263e+00, -6.0604e+00, -6.1945e+00]],[[ 1.1634e+00, 1.4868e+00, 1.8102e+00],[ 2.7804e+00, 3.1038e+00, 3.4273e+00],[ 4.3975e+00, 4.7209e+00, 5.0443e+00]],[[ 1.3615e+00, 2.0806e+00, 2.7997e+00],[ 4.9570e+00, 5.6761e+00, 6.3952e+00],[ 8.5525e+00, 9.2716e+00, 9.9907e+00]],[[ 4.7857e-01, 7.1624e-02, -3.3532e-01],[-1.5562e+00, -1.9631e+00, -2.3701e+00],[-3.5909e+00, -3.9978e+00, -4.4048e+00]],[[ 1.3034e-01, -1.1926e-01, -3.6886e-01],[-1.1177e+00, -1.3673e+00, -1.6169e+00],[-2.3657e+00, -2.6153e+00, -2.8648e+00]],[[-2.5643e+00, -2.5012e+00, -2.4381e+00],[-2.2489e+00, -2.1858e+00, -2.1227e+00],[-1.9335e+00, -1.8704e+00, -1.8073e+00]],[[-5.9628e-01, -3.1381e-01, -3.1331e-02],[ 8.1610e-01, 1.0986e+00, 1.3810e+00],[ 2.2285e+00, 2.5109e+00, 2.7934e+00]],[[ 3.2651e+00, 3.5390e+00, 3.8129e+00],[ 4.6346e+00, 4.9085e+00, 5.1823e+00],[ 6.0040e+00, 6.2779e+00, 6.5518e+00]],[[ 9.6249e+00, 1.0285e+01, 1.0946e+01],[ 1.2927e+01, 1.3588e+01, 1.4248e+01],[ 1.6230e+01, 1.6890e+01, 1.7551e+01]],[[-1.2424e+01, -1.4229e+01, -1.6035e+01],[-2.1450e+01, -2.3256e+01, -2.5061e+01],[-3.0477e+01, -3.2282e+01, -3.4087e+01]],[[ 5.4057e+00, 5.3818e+00, 5.3580e+00],[ 5.2865e+00, 5.2627e+00, 5.2389e+00],[ 5.1674e+00, 5.1436e+00, 5.1198e+00]],[[ 9.9779e-01, 1.5354e+00, 2.0731e+00],[ 3.6860e+00, 4.2236e+00, 4.7613e+00],[ 6.3742e+00, 6.9118e+00, 7.4495e+00]],[[-3.2944e+00, -3.5096e+00, -3.7248e+00],[-4.3702e+00, -4.5854e+00, -4.8005e+00],[-5.4460e+00, -5.6612e+00, -5.8763e+00]],[[ 1.2296e+00, 1.4838e+00, 1.7381e+00],[ 2.5008e+00, 2.7551e+00, 3.0093e+00],[ 3.7721e+00, 4.0263e+00, 4.2806e+00]],[[-1.7026e+00, -1.6612e+00, -1.6198e+00],[-1.4957e+00, -1.4543e+00, -1.4129e+00],[-1.2887e+00, -1.2473e+00, -1.2059e+00]],[[ 1.0922e+00, 1.0193e+00, 9.4637e-01],[ 7.2756e-01, 6.5462e-01, 5.8168e-01],[ 3.6286e-01, 2.8992e-01, 2.1698e-01]],[[ 1.5058e+00, 2.0980e+00, 2.6902e+00],[ 4.4667e+00, 5.0589e+00, 5.6511e+00],[ 7.4277e+00, 8.0199e+00, 8.6121e+00]],[[-4.5165e+00, -4.7796e+00, -5.0426e+00],[-5.8318e+00, -6.0949e+00, -6.3580e+00],[-7.1472e+00, -7.4103e+00, -7.6733e+00]],[[ 9.6662e+00, 1.0632e+01, 1.1597e+01],[ 1.4494e+01, 1.5459e+01, 1.6425e+01],[ 1.9321e+01, 2.0287e+01, 2.1252e+01]],[[ 1.3948e+00, 1.7578e+00, 2.1208e+00],[ 3.2097e+00, 3.5727e+00, 3.9356e+00],[ 5.0246e+00, 5.3875e+00, 5.7505e+00]],[[-6.8755e-01, -7.0281e-01, -7.1808e-01],[-7.6387e-01, -7.7914e-01, -7.9440e-01],[-8.4020e-01, -8.5546e-01, -8.7073e-01]],[[ 2.2234e+00, 2.7593e+00, 3.2952e+00],[ 4.9029e+00, 5.4388e+00, 5.9747e+00],[ 7.5824e+00, 8.1183e+00, 8.6542e+00]],[[ 4.0713e+00, 4.2167e+00, 4.3621e+00],[ 4.7981e+00, 4.9435e+00, 5.0888e+00],[ 5.5249e+00, 5.6703e+00, 5.8156e+00]],[[ 3.9256e+00, 4.4020e+00, 4.8784e+00],[ 6.3077e+00, 6.7841e+00, 7.2605e+00],[ 8.6898e+00, 9.1662e+00, 9.6427e+00]],[[ 2.6823e+00, 3.1461e+00, 3.6100e+00],[ 5.0016e+00, 5.4654e+00, 5.9293e+00],[ 7.3209e+00, 7.7847e+00, 8.2486e+00]],[[ 1.5454e+00, 1.7782e+00, 2.0110e+00],[ 2.7093e+00, 2.9421e+00, 3.1749e+00],[ 3.8732e+00, 4.1060e+00, 4.3388e+00]],[[ 1.2896e+00, 1.7742e+00, 2.2589e+00],[ 3.7128e+00, 4.1975e+00, 4.6821e+00],[ 6.1361e+00, 6.6207e+00, 7.1054e+00]],[[-4.0241e-01, -6.8238e-01, -9.6235e-01],[-1.8023e+00, -2.0822e+00, -2.3622e+00],[-3.2021e+00, -3.4821e+00, -3.7621e+00]],[[ 4.5071e+00, 4.5934e+00, 4.6797e+00],[ 4.9386e+00, 5.0249e+00, 5.1112e+00],[ 5.3700e+00, 5.4563e+00, 5.5426e+00]]]],grad_fn=<ConvolutionBackward0>)
Relu后的输出:tensor([[[[ 6.9225, 7.8138, 8.7051],[11.3790, 12.2703, 13.1616],[15.8355, 16.7268, 17.6181]],[[ 0.0000, 0.0000, 0.0000],[ 0.0000, 0.0000, 0.0000],[ 0.0000, 0.0000, 0.0000]],[[ 7.7753, 8.9903, 10.2054],[13.8505, 15.0655, 16.2806],[19.9257, 21.1407, 22.3557]],[[ 0.0000, 0.0000, 0.0000],[ 0.0000, 0.0000, 0.0000],[ 0.0000, 0.0000, 0.0000]],[[ 1.1634, 1.4868, 1.8102],[ 2.7804, 3.1038, 3.4273],[ 4.3975, 4.7209, 5.0443]],[[ 1.3615, 2.0806, 2.7997],[ 4.9570, 5.6761, 6.3952],[ 8.5525, 9.2716, 9.9907]],[[ 0.4786, 0.0716, 0.0000],[ 0.0000, 0.0000, 0.0000],[ 0.0000, 0.0000, 0.0000]],[[ 0.1303, 0.0000, 0.0000],[ 0.0000, 0.0000, 0.0000],[ 0.0000, 0.0000, 0.0000]],[[ 0.0000, 0.0000, 0.0000],[ 0.0000, 0.0000, 0.0000],[ 0.0000, 0.0000, 0.0000]],[[ 0.0000, 0.0000, 0.0000],[ 0.8161, 1.0986, 1.3810],[ 2.2285, 2.5109, 2.7934]],[[ 3.2651, 3.5390, 3.8129],[ 4.6346, 4.9085, 5.1823],[ 6.0040, 6.2779, 6.5518]],[[ 9.6249, 10.2853, 10.9458],[12.9273, 13.5878, 14.2483],[16.2298, 16.8903, 17.5508]],[[ 0.0000, 0.0000, 0.0000],[ 0.0000, 0.0000, 0.0000],[ 0.0000, 0.0000, 0.0000]],[[ 5.4057, 5.3818, 5.3580],[ 5.2865, 5.2627, 5.2389],[ 5.1674, 5.1436, 5.1198]],[[ 0.9978, 1.5354, 2.0731],[ 3.6860, 4.2236, 4.7613],[ 6.3742, 6.9118, 7.4495]],[[ 0.0000, 0.0000, 0.0000],[ 0.0000, 0.0000, 0.0000],[ 0.0000, 0.0000, 0.0000]],[[ 1.2296, 1.4838, 1.7381],[ 2.5008, 2.7551, 3.0093],[ 3.7721, 4.0263, 4.2806]],[[ 0.0000, 0.0000, 0.0000],[ 0.0000, 0.0000, 0.0000],[ 0.0000, 0.0000, 0.0000]],[[ 1.0922, 1.0193, 0.9464],[ 0.7276, 0.6546, 0.5817],[ 0.3629, 0.2899, 0.2170]],[[ 1.5058, 2.0980, 2.6902],[ 4.4667, 5.0589, 5.6511],[ 7.4277, 8.0199, 8.6121]],[[ 0.0000, 0.0000, 0.0000],[ 0.0000, 0.0000, 0.0000],[ 0.0000, 0.0000, 0.0000]],[[ 9.6662, 10.6317, 11.5972],[14.4936, 15.4591, 16.4246],[19.3211, 20.2865, 21.2520]],[[ 1.3948, 1.7578, 2.1208],[ 3.2097, 3.5727, 3.9356],[ 5.0246, 5.3875, 5.7505]],[[ 0.0000, 0.0000, 0.0000],[ 0.0000, 0.0000, 0.0000],[ 0.0000, 0.0000, 0.0000]],[[ 2.2234, 2.7593, 3.2952],[ 4.9029, 5.4388, 5.9747],[ 7.5824, 8.1183, 8.6542]],[[ 4.0713, 4.2167, 4.3621],[ 4.7981, 4.9435, 5.0888],[ 5.5249, 5.6703, 5.8156]],[[ 3.9256, 4.4020, 4.8784],[ 6.3077, 6.7841, 7.2605],[ 8.6898, 9.1662, 9.6427]],[[ 2.6823, 3.1461, 3.6100],[ 5.0016, 5.4654, 5.9293],[ 7.3209, 7.7847, 8.2486]],[[ 1.5454, 1.7782, 2.0110],[ 2.7093, 2.9421, 3.1749],[ 3.8732, 4.1060, 4.3388]],[[ 1.2896, 1.7742, 2.2589],[ 3.7128, 4.1975, 4.6821],[ 6.1361, 6.6207, 7.1054]],[[ 0.0000, 0.0000, 0.0000],[ 0.0000, 0.0000, 0.0000],[ 0.0000, 0.0000, 0.0000]],[[ 4.5071, 4.5934, 4.6797],[ 4.9386, 5.0249, 5.1112],[ 5.3700, 5.4563, 5.5426]]]], grad_fn=<ReluBackward0>)
6-为什么要用 nn.MaxPool2d(2)
为什么要用 nn.MaxPool2d(2) 而不是 nn.MaxPool2d(3) 作为池化层?
选择池化层的大小(如 nn.MaxPool2d(2) 或 nn.MaxPool2d(3))通常取决于几个因素,包括输入数据的大小、所需的下采样程度以及模型的设计目标。在本例中,使用 nn.MaxPool2d(2) 而不是 nn.MaxPool2d(3) 可能有以下原因:
1. 下采样程度
-
nn.MaxPool2d(2):使用2x2的池化核,步幅通常也为2,这会将输入的宽度和高度各减少一半。例如,一个3x3的特征图经过2x2的最大池化后,输出会是2x2。 -
nn.MaxPool2d(3):使用3x3的池化核,步幅为3,会更大幅度地减少特征图的尺寸。同样,3x3的特征图经过3x3的最大池化,输出会是1x1。
在本例中,输入特征图的大小是3x3,使用nn.MaxPool2d(2)后,输出是2x2,而使用nn.MaxPool2d(3)会直接输出1x1,这可能过于粗糙,损失了较多的空间信息。
2. 保持一定空间信息
在卷积神经网络中,特别是在早期层,保持一定的空间分辨率是很重要的,因为这有助于捕捉更多的空间特征。如果池化核太大,可能会导致信息损失过多,使得后续层难以学习到足够的特征。
3. 计算效率
-
nn.MaxPool2d(2):计算量相对较小,因为池化区域较小。 -
nn.MaxPool2d(3):计算量稍大,但差异不大。然而,由于池化核较大,可能会减少更多的参数,从而在某些情况下提高效率。
4. 模型设计和调参
模型设计者可能根据实验或经验选择2x2的池化核,以在下采样和保持特征之间取得平衡。不同的任务和数据集可能需要不同的池化核大小。
结论
在本例中,使用nn.MaxPool2d(2)可能是为了适度地减少特征图的尺寸,同时保留足够的空间信息供后续层使用。选择池化核的大小是一个超参数调优的过程,需要根据具体任务和数据集进行调整。
7-为什么要用 nn.LogSoftmax(dim=1),而不是SoftMax 作为输出层?
使用 nn.LogSoftmax(dim=1) 作为输出层的目的是为了在分类任务中实现数值稳定性和数学上的便利性。以下是详细解释:
1. Softmax 的作用
Softmax 是一种常用的激活函数,通常用于多分类任务的输出层。它的作用是将一个向量的数值转换为概率分布,使得每个类别的输出值范围在 [0, 1] 之间,且所有类别的概率之和为 1。
Softmax 的公式为:
Softmax ( z i ) = e z i ∑ j e z j \text{Softmax}(z_i) = \frac{e^{z_i}}{\sum_{j} e^{z_j}} Softmax(zi)=∑jezjezi
其中:
- $z_i $是第 $i $个类别的原始输出值。
- $e^{z_i} $是指数函数,用于增强数值差异。
- 分母是所有类别的指数值之和,用于归一化,确保概率之和为 1。
2. 为什么使用 LogSoftmax?
直接使用 Softmax 可能会带来两个问题:
(1) 数值不稳定性
- Softmax 中的指数运算 e z i e^{z_i} ezi 可能导致数值过大或过小,特别是在输出值 z i z_i zi 较大或较小时。
- 如果 z i z_i zi 很大, e z i e^{z_i} ezi 会趋近于无穷大,导致计算溢出(overflow)。
- 如果 z i z_i zi 很小, e z i e^{z_i} ezi 会趋近于 0,可能导致下溢(underflow)。
(2) 计算交叉熵损失时的便利性
-
在多分类任务中,通常使用交叉熵损失(Cross-Entropy Loss)来衡量模型预测的概率分布与真实标签的差异。
-
交叉熵损失的公式为:
Cross-Entropy Loss = − ∑ i y i log ( y ^ i ) \text{Cross-Entropy Loss} = -\sum_{i} y_i \log(\hat{y}_i) Cross-Entropy Loss=−i∑yilog(y^i)其中:
- y i y_i yi 是真实标签的概率分布(通常是独热编码 one-hot)。
- $\hat{y}_i $是模型预测的概率分布(Softmax 输出)。
-
如果直接使用 Softmax 输出 y ^ i \hat{y}_i y^i,计算交叉熵损失时需要同时计算 Softmax 和交叉熵,这会增加计算复杂度。
解决方案:LogSoftmax
LogSoftmax 是 Softmax 的对数版本,公式为:
LogSoftmax ( z i ) = log ( e z i ∑ j e z j ) \text{LogSoftmax}(z_i) = \log(\frac{e^{z_i}}{\sum_{j} e^{z_j}}) LogSoftmax(zi)=log(∑jezjezi)
通过将 Softmax 的输出取对数,可以解决数值不稳定性问题,并且在计算交叉熵损失时更加高效。
3. LogSoftmax 的优点
(1) 数值稳定性
- LogSoftmax 将 Softmax 的输出取对数,避免了 Softmax 中的指数运算导致的数值溢出或下溢问题。
- 例如,假设 $z_i 很大, 很大, 很大,e^{z_i} $可能会导致溢出,但 $\log(e^{z_i}) = z_i $不会。
(2) 与交叉熵损失的结合
-
LogSoftmax 与交叉熵损失的结合非常紧密,二者可以合并为一个操作,称为 负对数似然损失(Negative Log-Likelihood Loss, NLLLoss)。
-
公式为:
NLLLoss = − ∑ i y i ⋅ LogSoftmax ( z i ) \text{NLLLoss} = -\sum_{i} y_i \cdot \text{LogSoftmax}(z_i) NLLLoss=−i∑yi⋅LogSoftmax(zi)其中:
- $y_i $是真实标签(独热编码)。
- $\text{LogSoftmax}(z_i) $是模型的输出。
-
这种结合使得计算更加高效,且避免了多次计算 Softmax 和交叉熵。
(3) 数学上的便利性
- 在反向传播过程中,LogSoftmax 的梯度计算更简单,有助于加速模型的训练。
4. dim=1 的含义
dim=1 参数指定了在哪个维度上应用 LogSoftmax。具体含义如下:
dim=1:表示对第 1 维度(通常是特征维度)进行操作。- 例如,如果输入是一个形状为
[batch_size, num_classes]的张量,LogSoftmax 会在num_classes维度上计算。 - 对于每个样本(batch 中的每一个样本),LogSoftmax 会对
num_classes个类别计算对数值,输出仍然是[batch_size, num_classes]。
- 例如,如果输入是一个形状为
5. 为什么 LogSoftmax 是常用的输出层?
- 多分类任务的标准选择:在多分类任务中,LogSoftmax 是 Softmax 的自然延伸,既能避免数值不稳定问题,又能与交叉熵损失无缝结合。
- 与 PyTorch 的 NLLLoss 兼容:PyTorch 提供了
nn.NLLLoss损失函数,专门用于处理 LogSoftmax 的输出。通过这种组合,模型的训练更加高效。 - 数值稳定性:在深度学习模型的训练过程中,数值稳定性至关重要,LogSoftmax 是解决该问题的经典方法。
总结
nn.LogSoftmax(dim=1) 作为输出层的主要原因是:
- 数值稳定性:避免了 Softmax 中的指数运算导致的数值溢出或下溢。
- 与交叉熵损失的结合:LogSoftmax 与 NLLLoss 结合,简化了计算过程,提高了训练效率。
- 数学便利性:在反向传播中,LogSoftmax 的梯度计算更简单。
因此,在多分类任务中,nn.LogSoftmax(dim=1) 是一个常用且高效的输出层选择。
8-nn.Conv2d之后一定要进行relu吗?
在卷积神经网络(CNN)中,self.conv1(x) 并不一定必须立即接 ReLU 激活函数,是否使用 ReLU 以及何时使用 ReLU 取决于模型的架构设计目标和具体的任务需求。以下是详细分析:
1. ReLU 的作用
ReLU(Rectified Linear Unit,修正线性单元)是一种常用的激活函数,公式为:
ReLU ( x ) = max ( 0 , x ) \text{ReLU}(x) = \max(0, x) ReLU(x)=max(0,x)
它的作用是:
- 引入非线性:帮助神经网络学习更复杂的函数和特征。
- 稀疏激活:将负值置为 0,使得模型更容易学习特征并减少计算量。
- 避免梯度消失:相比传统的激活函数(如 sigmoid 或 tanh),ReLU 能够更好地避免梯度消失问题,从而加速训练。
2. 是否必须使用 ReLU?
不一定必须使用 ReLU。 以下是几种常见的情况:
(1) 必须使用激活函数
- 卷积层(
nn.Conv2d)本身是线性的(因为它是一个线性变换),如果不接激活函数,整个模型将是一个线性模型,无法学习到复杂的特征。 - 因此,卷积层之后通常需要接一个非线性激活函数,以引入非线性能力。
(2) ReLU 是默认选择
- 在大多数经典的 CNN 架构中(如 LeNet、AlexNet、VGG 等),卷积层之后通常会接一个 ReLU 激活函数。
- 这种设计是经验性的,ReLU 简单高效,且在大多数任务中表现良好。
(3) 其他激活函数的选择
- 如果不使用 ReLU,可以选择其他激活函数,如:
- LeakyReLU:在负值区域引入一个小的斜率,避免 ReLU 的“死亡 ReLU”问题(即某些神经元在训练过程中永远不会被激活)。
- ELU:在负值区域引入指数衰减,使得激活值更加平滑。
- Sigmoid 或 Tanh:这些激活函数在过去更常用,但由于梯度消失问题,目前在深度网络中较少使用。
- GELU:一种基于高斯误差线性单元的激活函数,近年来在 NLP 和 Transformer 模型中广泛使用。
- Swish:一种自门控激活函数,结合了 sigmoid 和 ReLU 的特点。
(4) 特定任务的需求
- 在某些任务中(如回归问题或特定类型的生成模型),可能不需要激活函数,或者使用其他更适合的激活函数。
- 例如:
- 在回归任务中,输出层通常不接激活函数,或者接
Tanh(如果是输出值在[-1, 1]范围内)。 - 在生成对抗网络(GAN)中,某些生成器的卷积层可能接
LeakyReLU或Tanh。
- 在回归任务中,输出层通常不接激活函数,或者接
(5) 架构设计的选择
- 在一些现代架构中,可能会省略某些层的激活函数,或者延迟激活函数的使用。
- 例如:
- ResNet:在残差块中,卷积层不直接接激活函数,而是在残差连接之后才接激活函数。
- DenseNet:在某些情况下,卷积层后面可能不接激活函数,直接传递给后续层。
3. 如何选择是否使用 ReLU?
- 默认情况下:如果任务是图像分类或目标检测等经典任务,且模型架构类似经典的 CNN,推荐在卷积层之后使用 ReLU。
- 根据任务需求:如果任务对激活函数的特性有特殊要求(如回归任务、生成任务等),可以根据需求选择其他激活函数。
- 实验验证:在实际应用中,可以通过实验比较不同激活函数的性能,选择最优的激活函数。
4. self.conv1(x) 后面接什么?
以下是几种常见的设计:
(1) 仅接 ReLU
x = self.conv1(x)
x = F.relu(x) # 或 x = nn.ReLU()(x)
这是最经典的设计。
(2) 接其他激活函数
x = self.conv1(x)
x = F.leaky_relu(x, negative_slope=0.1) # 使用 LeakyReLU
x = nn.GELU()(x) # 使用 GELU
(3) 接 BatchNorm 或其他层
有时候激活函数并不是立即使用,而是与其他层结合。例如:
x = self.conv1(x)
x = self.bn1(x) # BatchNorm
x = F.relu(x) # 激活函数
这种设计在现代架构中很常见。
(4) 不接激活函数
x = self.conv1(x)
# 不立即接激活函数
这种设计在一些特殊的架构中可能会出现,但需要具体分析任务需求。
5. 总结
self.conv1(x)不一定必须接 ReLU,是否使用 ReLU 取决于模型的架构设计和任务需求。- ReLU 是默认推荐的选择,因为它简单高效,且在大多数任务中表现良好。
- 如果不使用 ReLU,可以考虑其他激活函数(如 LeakyReLU、GELU 等),或者根据任务需求省略激活函数。
- 在实际应用中,可以通过实验验证不同激活函数的效果,选择最优的设计。
9-什么时候使用self.dropout1(x)?
在神经网络中使用 Dropout 是一种常见的正则化技术,用于防止模型过拟合。self.dropout1(x) 表示在模型的某个位置应用 Dropout 层。以下是关于何时使用 Dropout 的详细分析:
1. Dropout 的作用
Dropout 的核心思想是在训练过程中随机“丢弃”一部分神经元(即将它们的输出置为 0),从而减少神经元之间的共适应性(co-adaptation),增强模型的泛化能力。
-
训练阶段:
- 每次前向传播时,Dropout 会以概率 p p p(通常为 0.2 到 0.5)随机丢弃一部分神经元。
- 被丢弃的神经元的输出为 0,未被丢弃的神经元的输出会按比例放大(乘以 1 1 − p \frac{1}{1-p} 1−p1),以保持期望值不变。
-
测试阶段:
- Dropout 被关闭,所有神经元都参与计算,但输出值会乘以 1 − p 1-p 1−p,以保持与训练阶段的一致性。
2. 何时使用 Dropout?
Dropout 通常用于以下场景:
(1) 防止过拟合
- 当模型在训练集上表现很好,但在验证集或测试集上表现较差时,可能是模型过拟合了。
- Dropout 通过随机丢弃神经元,强制模型学习更鲁棒的特征,从而提高泛化能力。
(2) 模型容量较大
- 当模型的参数量较大(如深度神经网络)时,模型容易过拟合,Dropout 是一种有效的正则化手段。
(3) 数据量较小
- 当训练数据较少时,模型容易过拟合,Dropout 可以帮助缓解这一问题。
(4) 特定任务的需求
- 在某些任务中(如 NLP 中的语言模型、图像分类等),Dropout 是标准组件之一。
3. Dropout 的使用位置
Dropout 可以应用于模型的多个位置,具体取决于模型的设计。以下是常见的 Dropout 使用位置:
(1) 全连接层之后
- 在全连接层(
nn.Linear)之后使用 Dropout 是最常见的做法。 - 例如:
x = self.fc1(x) # 全连接层 x = self.dropout1(x) # Dropout x = F.relu(x) # 激活函数
(2) 卷积层之后
- 在卷积层(
nn.Conv2d)之后也可以使用 Dropout,但相对较少。 - 这是因为卷积层本身具有局部连接和参数共享的特性,过拟合的风险较低。
- 如果使用,通常是在较深的卷积层之后。
(3) 嵌入层之后
- 在 NLP 任务中,Dropout 可以应用于嵌入层(
nn.Embedding)之后,以减少过拟合。
(4) 特定层的输出
- 在某些架构中,Dropout 可以应用于特定层的输出,例如 Transformer 模型中的注意力机制之后。
4. Dropout 的参数设置
Dropout 的主要参数是丢弃概率 p p p,即每个神经元被丢弃的概率。常见的设置包括:
- $p = 0.2 $到 p = 0.5 p = 0.5 p=0.5:这是最常见的范围。
- 较小的 p p p(如 0.2)适用于较浅的网络或数据量较大的情况。
- 较大的 p p p(如 0.5)适用于较深的网络或数据量较小的情况。
- 实验调参:具体值可以通过实验调整,选择在验证集上表现最好的值。
5. Dropout 的注意事项
(1) 训练和测试阶段的区别
- 在训练阶段,Dropout 是激活的,随机丢弃神经元。
- 在测试阶段,Dropout 是关闭的,所有神经元都参与计算。
(2) 与其他正则化方法的结合
- Dropout 可以与其他正则化方法(如 L2 正则化、BatchNorm 等)结合使用,进一步增强模型的泛化能力。
(3) Dropout 的替代方法
- 在某些情况下,可以使用其他正则化方法替代 Dropout,例如:
- Batch Normalization:通过规范化激活值来减少过拟合。
- Weight Decay:通过 L2 正则化限制权重的大小。
6. 示例代码
以下是一个简单的示例,展示如何在模型中正确使用 Dropout:
import torch
import torch.nn as nn
import torch.nn.functional as Fclass MyModel(nn.Module):def __init__(self):super(MyModel, self).__init__()self.fc1 = nn.Linear(784, 256) # 全连接层self.dropout1 = nn.Dropout(p=0.5) # Dropout 层self.fc2 = nn.Linear(256, 10) # 输出层def forward(self, x):x = F.relu(self.fc1(x)) # 全连接层 + ReLUx = self.dropout1(x) # Dropoutx = self.fc2(x) # 输出层return x# 实例化模型
model = MyModel()# 训练阶段
model.train() # 启用 Dropout
output = model(torch.randn(32, 784)) # 输入数据# 测试阶段
model.eval() # 关闭 Dropout
output = model(torch.randn(32, 784)) # 输入数据
7. 总结
- Dropout 是一种有效的正则化方法,用于防止模型过拟合。
- 使用时机:当模型容量较大、数据量较小或任务容易过拟合时,可以使用 Dropout。
- 使用位置:通常在全连接层之后使用,也可以在卷积层或嵌入层之后使用。
- 参数设置:丢弃概率 $p $通常为 0.2 到 0.5,具体值可以通过实验调整。
- 注意事项:在训练阶段启用 Dropout,在测试阶段关闭 Dropout。
相关文章:
机器学习10-解读CNN代码Pytorch版
机器学习10-解读CNN代码Pytorch版 我个人是Java程序员,关于Python代码的使用过程中的相关代码事项,在此进行记录 文章目录 机器学习10-解读CNN代码Pytorch版1-核心逻辑脉络2-参考网址3-解读CNN代码Pytorch版本1-MNIST数据集读取2-CNN网络的定义1-无注释版…...

微服务学习-Gateway 统一微服务入口
1. 微服务为什么需要 API 网关? 1.1. 在微服务架构中,通常一个系统会被拆分为多个微服务,面对多个微服务客户端应该如何去调用呢? 如果根据每个微服务的地址发起调用,存在如下问题: 客户端多次请求不同的…...

2025寒假备战蓝桥杯02---朴素二分查找升级版本的学习+分别求解左右端点
文章目录 1.朴素二分查找的升级版2.查找左端点3.查找右端点4.代码的编写 1.朴素二分查找的升级版 和之前介绍的这个二分查找相比,我觉得这个区别就是我们的这个二分查找需要找到的是一个区间,而不是这个区间里面的某一个元素的位置; 2.查找…...

PHP语言的软件工程
PHP语言的软件工程 引言 软件工程是计算机科学中的一个重要分支,它涉及软件的规划、开发、测试和维护。在现代开发中,PHP作为一种流行的服务器端脚本语言,广泛应用于网页开发和各种企业应用中。本文将深入探讨PHP语言在软件工程中的应用&am…...

linux-FTP服务配置与应用
也许你对FTP不陌生,但是你是否了解FTP到底是个什么玩意? FTP 是File Transfer Protocol(文件传输协议)的英文简称,而中文简称为 “文传协议” 用于Internet上的控制文件的双向传输。同时,它也是一个应用程序…...

靠右行驶数学建模分析(2014MCM美赛A题)
笔记 题目 要求分析: 比较规则的性能,分为light和heavy两种情况,性能指的是 a.流量与安全 b. 速度限制等分析左侧驾驶分析智能系统 论文 参考论文 两类规则分析 靠右行驶(第一条)2. 无限制(去掉了第一条…...

(1)STM32 USB设备开发-基础知识
开篇感谢: 【经验分享】STM32 USB相关知识扫盲 - STM32团队 ST意法半导体中文论坛 单片机学习记录_桃成蹊2.0的博客-CSDN博客 USB_不吃鱼的猫丿的博客-CSDN博客 1、USB鼠标_哔哩哔哩_bilibili usb_冰糖葫的博客-CSDN博客 USB_lqonlylove的博客-CSDN博客 USB …...

Spring中如何动态的创建、监听MQ以及创建Exchange
文章目录 前言动态创建和管理Exchange、Queue动态消费Queue结论 前言 前面我们学习 RabbitMQ 的时候,都是在编译的时候就确定了Exchange、Queue,也就是说我们需要在程序启动之前就创建好需要的Exchange和Queue,但是实际使用的时候࿰…...

中国综合算力指数(2024年)报告汇总PDF洞察(附原数据表)
原文链接: https://tecdat.cn/?p39061 在全球算力因数字化技术发展而竞争加剧,我国积极推进算力发展并将综合算力作为数字经济核心驱动力的背景下,该报告对我国综合算力进行研究。 中国算力大会发布的《中国综合算力指数(2024年…...

【Python项目】小区监控图像拼接系统
【Python项目】小区监控图像拼接系统 技术简介:采用Python技术、B/S框架、MYSQL数据库等实现。 系统简介:小区监控拼接系统,就是为了能够让业主或者安保人员能够在同一时间将不同地方的图像进行拼接。这样一来,可以很大程度的方便…...

常用排序算法之插入排序
目录 前言 一、基本原理 1.算法步骤 2.动画演示 3.插入排序的实现代码 二、插入排序的时间复杂度 1. 时间复杂度 1.最优时间复杂度 2.最差时间复杂度 3.平均时间复杂度 2. 空间复杂度 三、插入排序的优缺点 1.优点 2.缺点 四、插入排序的改进与变种 五、插入排…...
基础查询语法的使用)
Elasticsearch(ES)基础查询语法的使用
1. Match Query (全文检索查询) 用于执行全文检索,适合搜索文本字段。 { “query”: { “match”: { “field”: “value” } } } match_phrase:精确匹配短语,适合用于短语搜索。 { “query”: { “match_phrase”: { “field”: “text” }…...

一篇文章学会Milvus【Docker 中运行 Milvus(Windows),Python实现对Milvus的操作,源代码案例,已经解决巨坑】【程序员猫爪】
一篇文章学会Milvus【Docker 中运行 Milvus(Windows),Python实现对Milvus的操作,源代码案例,已经解决巨坑】【程序员猫爪】 一、Milvus 是什么?【程序员猫爪】1、Milvus 是一种高性能、高扩展性的向量数据库…...

前端之移动端
视口 布局视口 layout viewport 视口(viewport)就是浏览器显示页面内容的屏幕区域。 视口可以分为布局视口、视觉视口和理想视口 一般移动设备的浏览器都默认设置了一个布局视口,用于解决早期的PC端页面在手机上显示的问题。 iOS, Androi…...
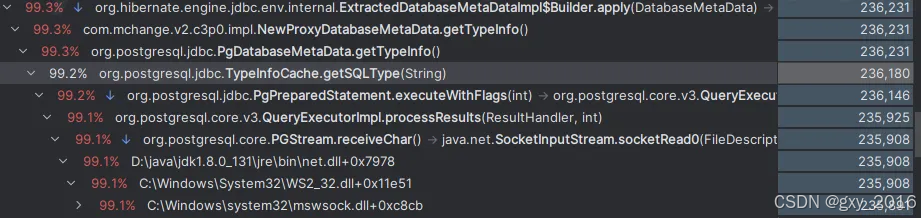
记一次 SpringBoot 启动慢的问题
记一次 SpringBoot 启动慢的问题 背景问题描述分析处理Flame Graph 火焰图Call Tree 调用树关键词检索尝试解决 为什么这样反向检索问题梳理 复盘处理流程为什么 Reference 背景 最近临时接了一个任务,就从一个旧 springboot 项目 copy 出来,临时写个服…...
高效安全文件传输新选择!群晖NAS如何实现无公网IP下的SFTP远程连接
文章目录 前言1. 开启群晖SFTP连接2. 群晖安装Cpolar工具3. 创建SFTP公网地址4. 群晖SFTP远程连接5. 固定SFTP公网地址6. SFTP固定地址连接 前言 随着远程办公和数据共享成为新常态,如何高效且安全地管理和传输文件成为了许多人的痛点。如果你正在寻找一个解决方案…...

如何在Python中进行JSON数据的序列化和反序列化?
在Python中,JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,易于人阅读和编写,同时也易于机器解析和生成。Python内置的json模块提供了简单易用的方法来实现数据的序列化和反序列化。下面将详细介绍如何…...

学习记录-统计记录场景下的Redis写请求合并优化实践
学习记录-使用Redis合并写请求来优化性能 1.业务背景 学习进度的统计功能:为了更精确的记录用户上一次播放的进度,采用的方案是:前端每隔15秒就发起一次请求,将播放记录写入数据库。但问题是,提交播放记录的业务太复杂了&#x…...

网站HTTP改成HTTPS
您不仅需要知道如何将HTTP转换为HTTPS,还必须在不妨碍您的网站自成立以来建立的任何搜索排名权限的情况下进行切换。 为什么应该从HTTP转换为HTTPS? 与非安全HTTP于不同,安全域使用SSL(安全套接字层)服务器上的加密代…...
上安装极狐GitLab?)
如何在龙蜥 OS(AliOS)上安装极狐GitLab?
本文分享如何在龙蜥操作系统(AliOS)(包括 RHCK 和 ANCK 两种,两种方式的安装流程一样)上安装极狐GitLab? 前提条件 一个安装了龙蜥操作系统的云服务器 可以查看 /etc/os-release中的信息,确认…...

新手村任务:成为一个架构师需要哪些装备?
新手村任务:成为一个架构师需要哪些装备? 一、前言 如果你刚入行不久,想成为一名架构师,那这篇文章就是为你写的。 我们把成为架构师比作一个RPG游戏,你是主角,需要收集各种装备、刷经验、升级技能。 新手村的第一个任务就是:了解你需要哪些装备。 二、架构师技能树…...

自制BLE112串口编程器:基于Bootloader的免调试器烧录方案
1. 项目概述:为BLE112模块打造一款免调试器的RS232编程器在嵌入式开发,特别是早期的蓝牙低功耗(BLE)模块应用中,我们常常会遇到一个棘手的问题:官方开发工具链的依赖和限制。以Silicon Labs(当时…...

Burp Suite证书安装全解:HTTPS抓包失败的根源与跨平台命令行方案
1. 为什么必须亲手安装Burp Suite证书——不是“点一下就完事”的操作很多人第一次在手机或测试设备上配置Burp Suite代理时,会下意识认为:只要把电脑上的Burp监听地址填进Wi-Fi代理设置,再用浏览器访问http://burp,点击那个绿色的…...

碧蓝航线自动化脚本终极指南:3小时学会全自动游戏管理
碧蓝航线自动化脚本终极指南:3小时学会全自动游戏管理 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript 还在为碧蓝…...

关于psthon问题
我想问问各位 我python可以查到 但是我的bit文件查不到python怎么回事...
)
手把手教你用Mind+和Blynk,让手机轻松遥控掌控板(含自建服务器避坑指南)
从零搭建物联网控制平台:Mind与Blynk深度整合实战 当你第一次尝试用手机控制硬件设备时,那种"隔空取物"的奇妙感总会让人兴奋不已。想象一下,躺在沙发上就能调节书桌上的智能台灯亮度,或者在外出时随时查看家中的温湿度…...

独立开发者如何利用Taotoken Token Plan,以更低成本启动AI项目
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用Taotoken Token Plan,以更低成本启动AI项目 对于独立开发者或小型团队而言,启动一个集成…...

3分钟开启PC游戏分屏派对:NucleusCoop让单机游戏秒变多人同屏神器
3分钟开启PC游戏分屏派对:NucleusCoop让单机游戏秒变多人同屏神器 【免费下载链接】nucleuscoop Starts multiple instances of a game for split-screen multiplayer gaming! 项目地址: https://gitcode.com/gh_mirrors/nu/nucleuscoop 还在为热门PC游戏不支…...

告别坐标点击!用Poco精准定位UI控件,让你的Airtest安卓自动化脚本更稳定
告别坐标点击!用Poco精准定位UI控件,让你的Airtest安卓自动化脚本更稳定每次UI微调就导致脚本大面积失效?分辨率变化让精心编写的自动化测试瞬间崩溃?作为从坐标点击转型到控件识别的实践者,我深刻理解这种挫败感。三年…...

国产麒麟系统上编译GDAL 3.2.1踩坑记:从PROJ6依赖缺失到Qt环境集成
麒麟系统GDAL 3.2.1编译实战:PROJ6依赖修复与Qt工程深度集成在国产操作系统生态中部署地理数据处理工具链,往往会遇到比常规Linux发行版更复杂的依赖问题。最近在麒麟系统上为北斗定位项目编译GDAL 3.2.1时,遭遇了经典的"PROJ 6 symbols…...