2024年博客之星主题创作|2024年度感想与新技术Redis学习
Redis工具深入了解
- 1.引言与感想
- 2.Redis工具了解
- 2.分布式系统了解
- 2.1单机架构
- 2.2分布式是什么
- 2.3应用服务和数据库服务分离
- 2.4引入更多的应用服务器
- 2.5理解负载均衡器
- 2.6数据库读写分离
- 2.7引入缓存
- 2.8数据库分库分表
- 2.9引入微服务
- 2.10分布式系统小结

1.引言与感想
2024学习了很多计算机知识,有C、数据结构、C++、Linux系统编程和网络编程、数据库、高阶数据结构、算法,虽然也学习到了很多让自己从计算机小白到掌握一点计算机知识,但是对于一个程序猿来说是远远不够的,我们应该不断学习新的前沿知识不至于让新型技术把自己淘汰,2025新的一年开始,就从Redis开始继续在CSDN记录自己学习到的知识。
2.Redis工具了解
Redis是一个在内存中存储数据的组件。谈到内存中存储数据可能会想到直接在内存定义一个变量不就是在内存中存储数据了吗?那为什么不直接这样而是搞一个Redis绕一个圈才在内存中存数据。这里我们要明确一点Redis是在分布式系统(分布式系统是一个由多个独立的计算机节点或服务器组成的系统,这些节点之间共享资源、数据和任务,并通过通信和协调来完成特定的功能。)中,才能发挥威力,如果只是单机程序,直接通过变量存储数据的方式,是比使用Redis更优的选择。 但是我们现在很多系统都是分布式系统,在分布式系统中我们要想能够让多个服务器都能共享同一份数据,又想让这个数据在内存里,那么此时我们选择Redis是一个可选的选择。
同样是在内存中存数据,存在变量中往往是更快速更方便的选择,但是如果在分布式系统里,直接定义变量是不行的。因为你定义的变量是在你当前服务器的进程中内存一块空间,我们学过系统知道进程具有独立性,让进程之间通信是不太方便的。换句话说进程A没法直接去读进程B内存中的数据,在这样前提之下,如果我们是一个分布式系统必定涉及到多个进程,这多个进程是在不同的主机上的,那么此时你想直接访问其他进程里内存中的变量,这件事就变得不那么简单了。
所以Redis就是针对上述的问题做了一个封装。让进程间互相通信其中最主流的方案就是网络,网络这种绕过进程间通信的方式,既可以让同一个主机上的不同进程间互相通信,而且还能跨主机让不同进程互相通信。因此Redis就是基于网络基础之上可以把自己内存中的变量给别的进程,甚至别的主机的进程进行使用。
总结一下:Redis是一个在内存中存储数据的组件,这个组件主要是为了给分布式系统使用的,分布式系统势必涉及到多个进程甚至是多个主机的多个进程,此时我们需要让这些进程之间通过网络进行通信,从而让我们任何一个应用程序可以访问到Redis里面的变量,让这个数据在分布式系统中达到共享使用的效果。
Redis使用非常广泛,常被用做于数据库,缓存,流式引擎,消息中间件。
说到数据库,我们常用的是MySQL,虽然MySQL可以在分布式系统中帮我们去存数据,但是它访问数据非常慢!! Redis也可以当作数据库来使用,它相对于MySQL速度就快了很多。为什么快很多呢?Redis它是用内存存数据,而MySQL存数据是在磁盘上。但是Redis和MySQL相比最大的劣势,存储空间是有限的!! 那有没有空间又大速度又快的?典型的方案,可以把Redis和MySQL结合起来使用。就是下面我们说的缓存。
将Redis作为MySQL的cache使用,这个意思就是把我们经常访问的热点数据用Redis存储,然后把我们全量数据都用MySQL存储。当前用户访问的是常用的热点数据直接读Redis这不就快了吗,同时全量数据还用MySQL存这不就大了吗。所以把这个两个东西结合在一起使用我们就可以做到又大又快!此时Redis起到的角色就是cache缓存。如果使用这种方案,系统的复杂程度大大提升,而且如果数据发生修改还涉及到Redis和MySQL之间的数据同步问题。
Redis的初心,最初就是用来作为一个"消息中间件"的(消息队列),消息队列是实现一个分布式系统下的生产者和消费者模型。但是随着发展发现把Redis作为一个数据库和缓存更香。当前很少直接使用Redis作为"消息中间件",因为我们有其他更多更专业消息中间件选择。
上面我们一直在说一个词"分布式",为了更好理解Redis我们必须要认识一下分布式系统。
2.分布式系统了解
在正式引入架构演进之前,为避免对架构中的概念完全不了解导致低效沟通,优先对其中一些比较重要的概念做前置介绍:
应用(Application)/ 系统(System)
为了完成一整套服务的一个程序或者一组相互配合的程序群。生活例子类比:为了完成一项任务,而搭建的由一个人或者一群相互配的人组成的团队。
一个应用/系统,就是一个/组服务器程序
模块(Module)/ 组件(Component)
当应用较复杂时,为了分离职责,将其中具有清晰职责的、内聚性强的部分,抽象出概念,便于理解(。生活例子类比:军队中为了进行某据点的攻克,将人员分为突击小组、爆破小组、掩护小组、通信小组等。
一个应用,里面有很多功能,每个独立的功能,就可以称为一个模块/组件
分布式(Distributed)
系统中的多个模块被部署于不同服务器之上,即可以将该系统称为分布式系统。如 Web 服务器与数据库分别共作在不同的服务器上,或者多台 Web 服务器被分别部署在不同服务器上。⽣活例子类比:为了更好的满足现实需要,一个在同一个办公场地的工作小组被分散到多个城市的不同工作场地中进行远程配合工作完成目标。跨主机之间的模块之间的通信基本要借助网络支撑完成。
引入多个主机/服务器,协同配合完成一系列工作
集群(Cluster)
被部署于多台服务器上的、为了实现特定目标的一个/组特定的组件,整个整体被为集群。比如多个 MySQL 工作在不同服务器上,共同提供数据库服务目标,可以被称为一组数据库集群。生活例子类比:为了解决军队攻克防守坚固的大城市的作战目标,指挥部将大批炮兵部队集中起来形成一个炮兵打击集群。
引入多个主机/服务器,协同配合完成一系列工作
分布式 vs 集群。通常不用太严格区分两者的细微概念,细究的话,分布式强调的是物理上的多个主机,即真的是引入多个服务器和硬件资源。而集群更在意逻辑上的多个主机,即一个主机部署多个服务器程序,多个服务器程序之间也是通过网络之间进行通信,看起来就好像和多个主机上没有区别,但是硬件上还是一个主机。当然也可以是在多个主机上。
主(Master)/ 从(Slave)
集群中,通常有一个程序需要承担更多的职责,被称为主;其他承担附属职责的称为从。比如MySQL 集群中,只有其中一台服务器上数据库允许进行数据的写入(增/删/改),其他数据库的数据修改全部要从这台数据库同步而来,则把那台数据库称为主库,其他数据库称为从库。
主从是分布式系统中一种典型的结构,多个服务器节点,其中一个是主,另外是从。从节点的数据要从主节点这里同步过来。
中间件(Middleware)
一类提供不同应用程序用于相互通信的软件,即处于不同技术、工具和数据库之间的桥梁。生活例子类比:一家饭店开始时,会每天去市场挑选买菜,但随着饭店业务量变大,成立一个采购部,由采购部专职于采买业务,称为厨房和菜市场之间的桥梁。
和业务无关的服务(功能更通用的服务),比如说大部分服务都需要数据库、缓存、消息队列…这样一些和业务无关的服务程序我们就可以称为中间件。
评价指标(Metric)
可用性(Availability)
考察单位时间段内,系统可以正常提供服务的概率/期望。例如: 年化系统性 = 系统正常提供服务时长 / ⼀年总时长。这里暗含着⼀个指标,即如何评价系统提供无法是否正常,我们就不深入了。平时我们常说的 4 个 9 即系统可以提供 99.99% 的可用性,5 个 9 是 99.999% 的可⽤性,以此类推。我们平时只是用高可用(High Availability HA)这个非量化目标简要表达我们系统的追求。
系统整体可用的时间/总的时间
响应时长(Response Time RT)
指用户完成输入到系统给出用户反应的时长。例如点外卖业务的响应时长 = 拿到外卖的时刻 - 完成点单的时刻。通常我们需要衡量的是最长响应时长、平均响应时长和中位数响应时长。这个指标原则上是越小越好,但很多情况下由于实现的限制,需要根据实际情况具体判断
衡量服务器的性能。处理一次请求需要多久时间(越小越好)。
吞吐(Throughput)vs 并发(Concurrent)
吞吐考察单位时间段内,系统可以成功处理的请求的数量。并发指系统同一时刻支持的请求最高量。例如一条高速公路,一分钟可以通过 20 辆车,则并发是一分钟的吞吐量是 20。实践中,并发量往往无法直接获取,很多时候都是用极短的时间段(比如 1 秒)的吞吐量做代替。我们平时用高并发(Hight Concurrnet)这个非量化目标简要表达系统的追求。
衡量服务器的处理请求的能力。是衡量性能的一种方式。
2.1单机架构
单机架构,只有一台服务器,这个服务器负责所有的工作。
此处假定是一个 电商网站。

虽有只有一台服务器,但是一个电商网站主要包含两部分,一个是应用服务,一个是数据库服务。应用服务就是对应我们写的服务器程序。数据库服务可以用我们典型的MySQL。MySQL是一个客户端服务器结构的程序!本体是MySQL服务器(存储和组织数据的部分)。用户通过网络发送一个http请求然后经过一系列内部转化为sql语句交给数据库服务器,处理之后在构成http响应给用户。
单机程序中,能不能把数据库服务器去掉,光一个应用服务器又负责业务,又负责数据存储?也不会不可以,但是就是比较麻烦。
目前绝大部分公司产品都是这种单机架构!!!现在计算机硬件发展速度很快,哪怕只有一台主机,这一台主机的性能也很高。可以支持非常高的并发和非常大的数据存储。
如果业务进一步增长,用户和数据量都随之增加,一台主机难以应付的时候,就需要引入更多的主机,引入更多的资源。
2.2分布式是什么
一台主机的硬件资源是有上限的。包括但不限于以下几种:CPU、内存、硬盘、网络… 而服务器每次收到一个请求,都是需要消耗上述的一些资源的。如果同一时刻处理请求多了,此时就可能会导致某个硬件资源不够用了!!无论是哪个方面不够用,都可能会导致服务器处理请求的时间变长,甚至于处理出错。
如果真的遇到这样的服务器不够用的情况,怎么处理呢?
1.开源(简单粗暴,增加更多的硬件资源)
2.节流(软件上针对程序进行优化,程序猿各凭本事)
但是一个主机上能增加硬件资源也是有限的。一台主机扩展到极限了,但还不够,只能引入多台主机了。不是说新的机器买来就可以直接解决问题了,也需要对软件上做出对应的调整和适配。
一旦引入多台主机了,咱们的系统就可以称为是"分布式系统"。引入分布式这是万不得已,这意味着系统的复杂程度会大大提高。
2.3应用服务和数据库服务分离
这里我们一种方案就是将应用服务和数据库服务分开部署到不同主机上,这是一个最简单的分布式系统。
现在我们系统就有两个服务器了,上面服务器只部署应用服务,下面服务器只部署数据库服务器。之前两个部署在一台服务器这意味着一份硬件资源分成两份用,现在不争不抢一人一份硬件资源。应用服务器里面可能会包含很多业务逻辑,可能会吃CPU和内存更多,因此我们给可以这台主机配置CPU比较好,内存也比较大的主机。数据库服务器需要更大的磁盘空间和更快的数据访问速度,我们就可以给这台机可以配置更大的磁盘,甚至还可以上SSD(固态)磁盘(机械硬盘:便宜、慢。固态硬盘:贵、快)。

2.4引入更多的应用服务器
上面是一个应用服务器和一个数据库服务器,现在随着请求进一步增加,可能一台应用服务器顶不住,应用服务器可能会比较吃CPU和内存,如果把CPU和内存吃完了,此时应用服务器就顶不住了,那我们就可以引入多个应用服务器就可以有效解决上诉问题。
用户的请求先访问负载均衡器/网关服务器(单独的服务器),然后由这个负载均衡器对我们的请求进行分发不同的应用服务器,这样每台应用服务器不就降低了负担了吗。这就好比说本来一份活一个人可以干完,现在同样是一份活现在多个人干,是不是就快了。

对于负载均衡器来说,有很多 负载均衡 具体的算法。
Round-Robin 轮询算法。即非常公平地将请求依次分给不同的应用服务器。
Weight-Round-Robin 轮询算法。为不同的服务器(比如性能不同)赋予不同的权重(weight),能者多劳。
一致哈希散列算法。通过计算用户的特征值(比如 IP 地址)得到哈希值,根据哈希结果做分发,优点是确保来自相同用户的请求总是被分给指定的服务器。也就是我们平时遇到的专项客户经理服务。
2.5理解负载均衡器

这里或许可能有个问题,假设我们有1w个请求,由于负载均衡器的存在让每个应用服务器负担降低了,但是对于负载均衡器来说它不就承担了这1w个请求吗承担了所有吗。它能顶住压力吗?这里我们要明确负载均衡器对于请求量的承担能力,要远超过应用服务器的。因为负载均衡器只负责分配,而应用服务器负责执行任务,它相对于应用服务器所花费的资源和时间要更低的。
那是否可能会出现,请求量大到负载均衡器也扛不住了呢??也是有可能的。这里也好解决,引入更多的负载均衡器(引入多个机房,每个机房都有自己的负载均衡器和应用服务器)。
2.6数据库读写分离
上面应用服务器是变的更多了,确实能够处理更多的请求了。但是数据库服务器就还是一个,所有应用服务器都要访问这个数据库,这样是不是就会对数据库服务器造成很大的压力。还是老办法开源或者节流。这里我们主要说的是开源。引入更多的机器。让数据库读写分离。

我们发现这里数据库分为了两种,一种是主数据库,一种是从数据库。也就是说从是主的跟班。其中我们就让主库就负责写(增、删、改),从库就负责读。上面的应用服务器如果要去读数据就去从数据库读数据,如果要写数据就往主数据库里写,同时主数据库会把数据定期或者实时把数据同步给从数据库。
实际的应用场景中,读的频率要比写的频率更高。主数据库服务器一般是一个,从数据库服务器可以有多个(一主多从)。同时从数据库可以通过负载均衡的方式让应用服务器进行访问。
2.7引入缓存
数据库天然有个问题,它的响应速度是更慢的!不管怎么进行分布最终还是要读硬盘,为了进一步提高访问效率,我们针对数据区分 “冷热”,热点数据放到缓存中,缓存的访问速度往往比数据库要快很多。
可以看到数据库在读写分离基础之上,又引入了缓存服务器,缓存服务器里只是放一小部分热点数据(会频繁被访问到的数据)。这里有一个二八原则,20%的数据,能够支持80%的访问量。从数据库里面存的仍然是完全的全量数据。缓存要想快就要付出代价就是小!其实这里的缓存服务器就是Redis所处的位置。
未来应用服务器先读缓存服务器,如果缓存中的缓存数据存在就不用读从数据库了,直接把数据从缓存中取走。如果缓存中不存在再去读从数据库。这样既可以使数据库压力降低并且读的又快。

2.8数据库分库分表
引入分布式系统,不光要能够去应对更高的请求量(并发量),同时也要能应对更大的数据量。
是否可能会出现,一台服务器以及存不下数据了呢?当然会存在!一台服务器存不下,就需要用多台服务器来存储。针对数据库进一步的拆分,分库分表。
本来一个数据库服务器,这个数据库服务器上有多个数据库(指的是逻辑上的数据集合,create database创建的那个东西),现在就可以引入多个数据库服务器,每个数据库服务器存储一个或者多个数据库。每个存储集群都是由一个主数据库多个从数据库。比如说请求访问商品,就可以访问第二个存储集群,从从数据库里面去读,往主数据库里去写,当然在去读之前都可以下去缓存服务器里先读缓存,这一点是和前面是一样的。

如果一个数据库某个表特别大,大到一台主机存不下,也可以针对表进行拆分。
具体如何分库分表如何实践,还是要结合实际的业务场景来展开。
2.9引入微服务
上面算是一个比较复杂的分布式系统,我们既可以处理更多的请求,也可以处理更多的数据。但是实际上往往还会对应用服务器做进一步拆分,比如应用服务器里面做的功能太多太复杂了,这个时候我们就可以把应用服务器拆分成更多部分,每个部分只负责一小部分的功能,我们把它叫做微服务。
以下就是微服务架构。

之前应用服务器,一个服务器程序里面做了很多的业务,这就可能会导致这一个服务器的代码变得越来越复杂。为了更方便代码的维护,我们就可以把这样的一个复杂的服务器拆分成更多的,功能更单一,但是更小的服务器。 这我们就称为微服务。
本来一个服务器干很多活,但是现在让一个服务器只干一个活,这势必会造成服务器种类和数量就增加了。
比如之前一个服务器要做用户、商品、交易相关的逻辑,现在把这三个功能拆分成三个微服务来实现。第一个微服务专门针对用户提供服务,第二个微服务专门针对商品提供服务,第三个微服务专门针对交易提供服务。每个微服务都有自己的应用集群,存储集群,缓存。

负载均衡解决请求多的问题,分库分表解决数据量多的问题,微服务本质上是在解决’人’的问题。
当应用服务器复杂了,势必就需要更多的人来维护了。当人多了就需要配置的管理,把这些人组织好,就需要划分组织结构,分成多个组,每个组分别配备领导进行管理。分成多个组就需要进行分工。按照功能拆分成多组微服务,这样就可以有利于上述人员的组织结构的分配了。
引入微服务,解决了人的问题,付出的代价?
- 系统的性能下降(拆出来更多的服务,多个功能之间要更依赖 网络通信,而网络通信的速度很可能是比访问硬盘还慢的!!)。要想保证性能不能下降太多,只能引入更多的机器,更多的硬件资源。
- 系统复杂程度提高,可用性受到影响(服务器更多了,出现问题的概率就更大了)。这就需要一系列的手段,来保证系统的可用性(更丰富监控报警,以及配套的运维人员)。
微服务的优势
- 解决了人的问题
- 使用微服务,可以更方便于功能的复用
- 可以给不同的服务进行不同的部署
2.10分布式系统小结
- 单机架构(应用程序+数据库服务器)。
- 数据库和应用分离(应用程序和数据库服务器分别放到不同主机上部署了)。
- 引入负载均衡,单个应用服务器->一组应用服务器(一个集群),通过负载均衡器,把请求比较均匀的分发给集群中的每个应用服务器。当集群中的某个主机挂了,其他的主机仍然可以承担服务,提高了整个系统的可用性。
- 引入读写分离(数据库总从结构)。一个数据库节点作为主节点,其他N个数据库节点作为从节点。其中主节点负责写数据,从节点负责读数据(一主多从)。主节点需要把修改过的数据同步给从节点。
- 引入缓存,冷热数据分离。进一步提升了服务器对请求的处理能力。Redis在一个分布式系统中,通常就扮演着缓存这样的角色。但是引入了数据库和缓存的数据一致性的问题。
- 引入分库分表,数据库能够进一步扩展存储空间。
- 引入微服务,从业务上进一步拆分应用服务器,从业务功能的角度,把应用服务器,拆分成更多的功能更单一、更简单、更小的服务器。
上述这样几个演化的步骤只是一个粗略的过程。实际上一个商业项目,真实的演化过程,都是和它的业务发展密切相关的。业务是更重要的,技术只是给业务提高支持的。
所谓的 分布式系统 就是想办法引入更多的硬件资源!!!
相关文章:
2024年博客之星主题创作|2024年度感想与新技术Redis学习
Redis工具深入了解 1.引言与感想2.Redis工具了解2.分布式系统了解2.1单机架构2.2分布式是什么2.3应用服务和数据库服务分离2.4引入更多的应用服务器2.5理解负载均衡器2.6数据库读写分离2.7引入缓存2.8数据库分库分表2.9引入微服务2.10分布式系统小结 1.引言与感想 2024学习了很…...
增强方案(理论+Python实战))
6. 马科维茨资产组合模型+政策意图AI金融智能体(DeepSeek-V3)增强方案(理论+Python实战)
目录 0. 承前1. 幻方量化 & DeepSeek1.1 What is 幻方量化1.2 What is DeepSeek 2. 重写AI金融智能体函数3. 汇总代码4. 反思4.1 不足之处4.2 提升思路 5. 启后 0. 承前 本篇博文是对上一篇文章,链接: 5. 马科维茨资产组合模型政策意图AI金融智能体(Qwen-Max)增…...

Unity自学之旅05
Unity自学之旅05 Unity学习之旅⑤📝 AI基础与敌人行为🥊 AI导航理论知识(基础)开始实践 🎃 敌人游戏机制追踪玩家攻击玩家子弹碰撞完善游戏失败条件 🤗 总结归纳 Unity学习之旅⑤ 📝 AI基础与敌…...

linux中关闭服务的开机自启动
引言 systemctl 是 Linux 系统中用于管理 systemd 服务的命令行工具。它可以用来启动、停止、重启服务,管理服务的开机自启动,以及查看服务的状态等。 什么是 systemd? systemd 是现代 Linux 发行版中默认的 初始化系统(init sys…...

Python----Python高级(文件操作open,os模块对于文件操作,shutil模块 )
一、文件处理 1.1、文件操作的重要性和应用场景 1.1.1、重要性 数据持久化: 文件是存储数据的一种非常基本且重要的方式。通过文件,我们可 以将程序运行时产生的数据永久保存下来,以便将来使用。 跨平台兼容性: 文件是一种通用…...

ubuntu黑屏问题解决
重启Ubuntu后,系统自动进入tty1,无法进入桌面。想到前几天安装了一些主题之类的,然后今天才重启,可能是这些主题造成冲突或者问题了把。 这里直接重新安装ubuntu-desktop解决: 更新源: sudo apt-get upd…...

Java如何实现反转义
Java如何实现反转义 前提 最近做的一个需求,是热搜词增加换一批的功能。功能做完自测后,交给了测试伙伴,但是测试第二天后就提了一个bug,出现了未知词 levis。第一眼看着像公司售卖的一个品牌-李维斯。然后再扒前人写的代码&…...

动态规划(路径问题)
62. 不同路径 62. 不同路径 - 力扣(LeetCode) 动态规划思想第一步:描述状态~ dp[i][j]:表示走到i,j位置时,一共有多少种方法~ 动态规划思想第二步:状态转移方程~ 动态规划思想第三步…...

python http调用视觉模型moondream
目录 一、什么是moondream 二、资源地址 三、封装了http进行接口请求 四、代码解析 解释 可能的改进 一、什么是moondream Moondream 是一个针对视觉生成任务的深度学习模型,专注于图像理解和生成,包括图像标注(captioning)、问题回答(Visual Question Answering,…...

Spark Streaming编程基础
文章目录 1. 流式词频统计1.1 Spark Streaming编程步骤1.2 流式词频统计项目1.2.1 创建项目1.2.2 添加项目依赖1.2.3 修改源目录1.2.4 添加scala-sdk库1.2.5 创建日志属性文件 1.3 创建词频统计对象1.4 利用nc发送数据1.5 启动应用,查看结果 2. 编程模型的基本概念3…...

深入 Flutter 和 Compose 的 PlatformView 实现对比,它们是如何接入平台控件
在上一篇《深入 Flutter 和 Compose 在 UI 渲染刷新时 Diff 实现对比》发布之后,收到了大佬的“催稿”,想了解下 Flutter 和 Compose 在 PlatformView 实现上的对比,恰好过去写过不少 Flutter 上对于 PlatformView 的实现,这次恰好…...

C# OpenCV机器视觉:红外体温检测
在一个骄阳似火的夏日,全球却被一场突如其来的疫情阴霾笼罩。阿强所在的小镇,平日里熙熙攘攘的街道变得冷冷清清,人们戴着口罩,行色匆匆,眼神中满是对病毒的恐惧。阿强作为镇上小有名气的科技达人,看着这一…...

FCA-FineDataLink认证
FCA-FineDataLink证书 Part.1:判断题 (总分:18分 得分:16) 第1题 判断题 数据同步只支持写入到已存在表,不支持自动建表(得分:2分 满分:2分) 正确答案:B 你的答案&…...

第19篇:python高级编程进阶:使用Flask进行Web开发
第19篇:python高级编程进阶:使用Flask进行Web开发 内容简介 在第18篇文章中,我们介绍了Web开发的基础知识,并使用Flask框架构建了一个简单的Web应用。本篇文章将深入探讨Flask的高级功能,涵盖模板引擎(Ji…...

js截取video视频某一帧为图片
1.代码如下 <template><div class"box"><div class"video-box"><video controls ref"videoRef" preload"true"src"https://qt-minio.ictshop.com.cn:9000/resource-management/2025/01/08/7b96ac9d957c45a…...

[云讷科技]Kerloud Falcon四旋翼飞车虚拟仿真空间发布
虚拟仿真环境作为一个独立的专有软件包提供给我们的客户,用于帮助用户在实际测试之前验证自身的代码,并通过在仿真引擎中添加新的场景来探索新的飞行驾驶功能。 环境要求 由于环境依赖关系,虚拟仿真只能运行在装有Ubuntu 18.04的Intel-64位…...

Jetson nano 安装 PCL 指南
本指南帮助 ARM64 架构的 Jetson Nano 安装 PCL(点云库)。 安装步骤 第一步:安装依赖 在终端中运行以下命令,安装 PCL 所需的依赖: sudo apt-get update sudo apt-get install git build-essential linux-libc-dev s…...

go-zero框架基本配置和错误码封装
文章目录 加载配置信息配置 env加载.env文件配置servicecontext 查询数据生成model文件执行查询操作 错误码封装配置拦截器错误码封装 接上一篇:《go-zero框架快速入门》 加载配置信息 配置 env 在项目根目录下新增 .env 文件,可以配置当前读取哪个环…...
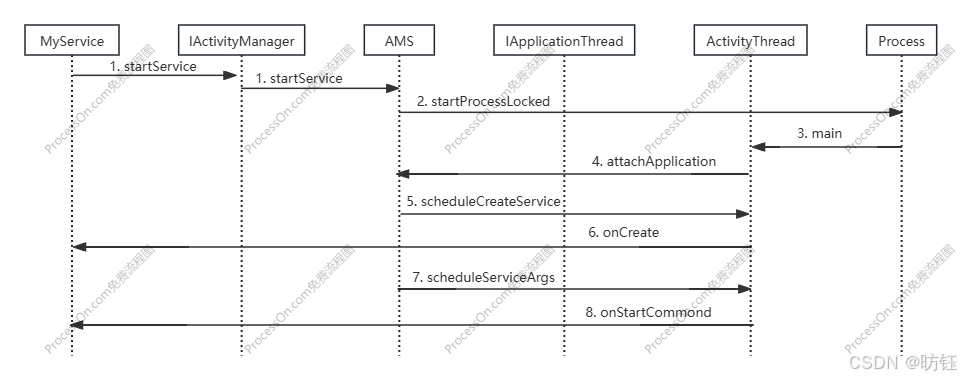
Android中Service在新进程中的启动流程2
目录 1、Service在客户端的启动入口 2、Service启动在AMS的处理 3、Service在新进程中的启动 4、Service与AMS的关系再续 上一篇文章中我们了解了Service在新进程中启动的大致流程,同时认识了与客户端进程交互的接口IApplicationThread以及与AMS交互的接口IActi…...
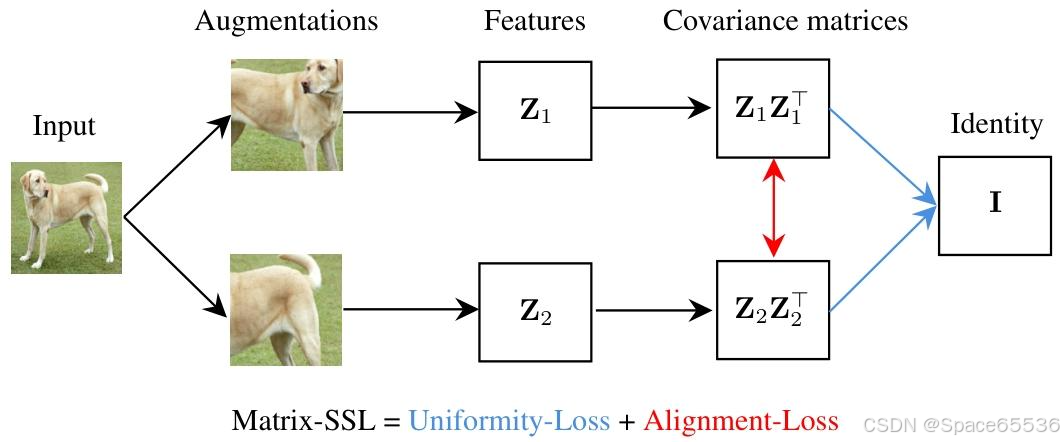
论文速读|Matrix-SSL:Matrix Information Theory for Self-Supervised Learning.ICML24
论文地址:Matrix Information Theory for Self-Supervised Learning 代码地址:https://github.com/yifanzhang-pro/matrix-ssl bib引用: article{zhang2023matrix,title{Matrix Information Theory for Self-Supervised Learning},author{Zh…...

终极鼠标连点器使用指南:3分钟掌握高效自动化技巧
终极鼠标连点器使用指南:3分钟掌握高效自动化技巧 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 ,操作…...

文件-语言-系统:基础IO-2.0——IO重定向接口,语言层缓冲区,系统级缓冲区。内核级分析!
bit::Shadow✧(≖ ◡ ≖✿ 目录 重定向接口dup2() ">" ">>" "<" 函数原型 输出重定向1和2的使用 文件描述符表 ./a.out运行: "./a.out >"默认重定向是fd 1 合并标准输入输出 缓冲区 什么是缓冲…...

转行网络安全运维:从0到1的可落地指南
转行网络安全运维:从0到1的可落地指南 一、 「3个核心技能:从零起步也能会」 网上学习资料多到爆炸,不用纠结“哪个最好”,记住一句话:**能学会、能上手的就是好的**!不管是免费视频还是付费课,…...

基于ESP32与MQTT的家庭环境监测系统:从传感器选型到数据可视化实战
1. 项目概述与核心价值最近几年,我身边越来越多的朋友开始关注家里的空气质量、温湿度这些看不见摸不着,但又实实在在影响生活舒适度和健康的环境指标。从新装修的房子担心甲醛,到有老人小孩的家庭在意PM2.5和二氧化碳浓度,再到南…...

轻量化部署,异地机房快速接入,多机房管理不用再大动干戈
随着业务拓展,不少企业、单位陆续建起异地分部机房、多区域节点机房。传统资产管理系统部署复杂、对接困难,异地机房接入成本高、周期长,改造繁琐,让很多运维团队望而却步,只能继续沿用分散人工管理,资产混…...

uWSGI目录穿越漏洞CVE-2018-7490深度利用与防御实战
1. 这不是“读文件”那么简单:uWSGI目录穿越在真实攻防链中的定位与误判代价你刚在Vulfocus靶场里跑通了CVE-2018-7490的PoC,用curl "http://target:8080/?p../../../../etc/passwd"成功读出了root:x:0:0:root:/root:/bin/bash,截…...

2026论文顶级降AI率工具大曝光:一键把AIGC率降至安全线!
步入2026年,学术圈的规则已经彻底变了味。过去那种只盯着查重率的“降重焦虑”早就被更可怕的“降AI焦虑”取代了。AI检测算法越来越聪明,高校审核标准也越来越严苛,光是把重复率压下去已经完全不够用了。现在摆在学生和科研人员面前的难题是…...

天文时序数据分析:机器学习评估、半监督学习与无监督方法实战
1. 项目概述:当机器学习遇见星空 处理海量的天文时序数据,比如来自Kepler、TESS这些“巡天巨眼”的光变曲线,早已不是靠人眼一张张图去翻的时代了。数据量太大,噪声复杂,信号微弱,传统方法常常力不从心。这…...

别再盲调temperature=0.2!DeepSeek补全效果突变的4个隐藏参数,资深架构师压箱底调参清单
更多请点击: https://intelliparadigm.com 第一章:别再盲调temperature0.2!DeepSeek补全效果突变的4个隐藏参数,资深架构师压箱底调参清单 DeepSeek-R1/VL 等开源大模型在实际部署中,仅靠调节 temperature 往往收效甚…...

Claude Code + LM Studio + CC-Switch 本地自动化编程部署指南
Claude Code LM Studio CC-Switch 本地自动化编程部署指南 本指南汇总了在 Windows 本地环境下,使用 Claude Code 配合 LM Studio 本地模型、CC-Switch 代理进行自动化编程开发的完整配置方案。 目录 硬件与模型选型LM Studio 本地模型部署CC-Switch 代理配置Cla…...