polars as pl
import `polars as pl#`和pandas类似,但是处理大型数据集有更好的性能.
#necessary
import pandas as pd#导入csv文件的库
import numpy as np#进行矩阵运算的库
#metric
from sklearn.metrics import roc_auc_score#导入roc_auc曲线
#KFold是直接分成k折,StratifiedKFold还要考虑每种类别的占比
from sklearn.model_selection import StratifiedKFold
from sklearn.decomposition import TruncatedSVD#截断奇异值分解,是一种数据降维的方法
import dill#对对象进行序列化和反序列化(例如保存和加载树模型)
import gc#垃圾回收模块
import time#标准库的时间模块
#为了方便后期调用训练的模型时不会调用错版本,提供模型训练的时间
#time.strftime()函数用于将时间对象格式化为字符串,time.localtime()函数返回表示当前本地时间的time.s`truct_time对象
current_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
print("this notebook training time is ", current_time)#config
class Config():seed=2024num_folds=10TARGET_NAME ='target'batch_size=1000#由于不知道测试数据的大小,所以分批次放入模型.import random#提供了一些用于生成随机数的函数
#设置随机种子,保证模型可以复现
def seed_everything(seed):np.random.seed(seed)#numpy的随机种子random.seed(seed)#python内置的随机种子
seed_everything(Config.seed)#读取训练数据中每个特征的dtype
colname2dtype=pd.read_csv("/kaggle/input/home-credit-inconsistent-data-types/colname2dtype.csv")
colname=colname2dtype['Column'].values
dtype=colname2dtype['DataType'].valuesdtype2pl={}
dtype2pl['Int64']=pl.Int64
dtype2pl['Float64']=pl.Float64
dtype2pl['String']=pl.String
dtype2pl['Boolean']=pl.Stringcolname2dtype={}
for idx in range(len(colname)):colname2dtype[colname[idx]]=dtype2pl[dtype[idx]]#找出表格df里缺失值占比大于margin的列,pandas
def find_df_null_col(df,margin=0.975):cols=[]for col in df.columns:if df[col].isna().mean()>margin:cols.append(col)return cols
#对于某个文件有很多个相同的case_id保留最后一个.
#有些文件我们就需要某个用户最新的某些信息,这时候就可以用这个函数.
def find_last_case_id(df,id='case_id'):#假设传入的df已经按照'case_id'排序好了.df_copy=df.clone()df_tail=df.tail(1)#最后的一个'case_id'单独取出#找出除了最后一个的其他的case_id,shift没用了,也要drop掉df_copy=df_copy.with_columns(pl.col(id).shift(-1).alias(f"{id}_shift_-1"))df_last=df_copy.filter(pl.col(id)-pl.col(f'{id}_shift_-1')!=0).drop(f'{id}_shift_-1')#每个case_id只保留最新的信息.df_last=pl.concat([df_last,df_tail])#这个比赛有很多文件,为了节省内存一定要及时清理.del df_copy,df_tailgc.collect()#手动触发垃圾回收,强制回收由垃圾回收器标记为未使用的内存return df_last
#对表格df的某列col用method进行填充
def df_fillna(df,col,method=None):if method ==None:#我不打算填充这列的缺失值passif method == "forward":#使用前一个值填充缺失值df = df.select([pl.col(col).fill_null('forward')])else:#method=['NaN',0].如果把缺失本身当作一种信息可以填充为"NaN",二分类0和1中0占大多数的列可能会用0填充.df=df.with_columns(pl.col(col).fill_null(method).alias(col))return df#返回填充后的表格#对表格df的某列col进行独热编码,为了保证训练集和测试集增加同样多的列,这里直接给出独热编码的类别unique.
def one_hot_encoder(df,col,unique):#如果类别为2的话,直接选择其中一个=if len(unique)==2:df=df.with_columns((pl.col(col)==unique[0]).cast(pl.Int8).alias(f"{col}_{unique[0]}"))else:#类别为多的时候才一个一个类别考虑过去.for idx in range(len(unique)):df=df.with_columns((pl.col(col)==unique[idx]).cast(pl.Int8).alias(f"{col}_{unique[idx]}"))return df.drop(col)#drop掉col这列,因为有独热编码了.
#由于last_features是每个case_id最新的信息,所以case_id不会有重复的,所以直接按case_id merge到原来表格里就行了.
#last_df是每个case_id保留最新信息的表格,last_features是哪些特征要统计最新信息,feats是总特征表格.
def last_features_merge(feats,last_df,last_features=[]):#从last_df中选出要统计最新信息的几列last_df=last_df.select(['case_id']+[last[0] for last in last_features])#对last_df的那几列填充缺失值for last in last_features:col,fill=lastlast_df=df_fillna(last_df,col,method=fill)#填充好缺失值之后就merge进feats表格.feats填充列还有缺失值是因为那些列有些case_id没有数据在last_df中.feats=feats.join(last_df,on='case_id',how='left')return feats#feats是总特征,group_df是有多个相同case_id的表格,group_features是要用来group的特征,name是csv文件名.
#fillna+one-hot,groupby
def group_features_merge(feats,group_df,group_features=[],group_name='applprev2'):#挑选出group_features这些列group_df=group_df.select(['case_id']+[g[0] for g in group_features])#先把字符串列单独处理.for group in group_features:if group_df[group[0]].dtype==pl.String:#如果是字符串类型是one-hotcol,fill,one_hot=groupgroup_df=df_fillna(group_df,col,method=fill)#填充是第一步if one_hot==None:#如果不要one-hot直接drop colgroup_df=group_df.drop(col) else:#或者one-hot-encodinggroup_df=one_hot_encoder(group_df,col,one_hot)for value in one_hot:new_col=f"{col}_{value}"feat=feat=group_df.group_by('case_id').agg( pl.mean(new_col).alias(f"mean_{group_name}_{new_col}"),pl.std(new_col).alias(f"std_{group_name}_{new_col}"),pl.count(new_col).alias(f"count_{group_name}_{new_col}"),)feats=feats.join(feat,on='case_id',how='left')else:#如果不是字符串,是数值列,对col填充为fillcol,fill=groupgroup_df=df_fillna(group_df,col,method=fill)#填充是第一步feat=group_df.group_by('case_id').agg( pl.max(col).alias(f"max_{group_name}_{col}"),pl.mean(col).alias(f"mean_{group_name}_{col}"),pl.median(col).alias(f"median_{group_name}_{col}"),pl.std(col).alias(f"std_{group_name}_{col}"),pl.min(col).alias(f"min_{group_name}_{col}"),pl.count(col).alias(f"count_{group_name}_{col}"),pl.sum(col).alias(f"sum_{group_name}_{col}"),pl.n_unique(col).alias(f"n_unique_{group_name}_{col}"),pl.first(col).alias(f"first_{group_name}_{col}"),pl.last(col).alias(f"last_{group_name}_{col}"))feats=feats.join(feat,on='case_id',how='left')return featsdef set_table_dtypes(df):for col in df.columns:df=df.with_columns(pl.col(col).cast(colname2dtype[col]).alias(col))return df#after break 就是仔细研究过文件每个特征含义的意思.
def preprocessor(mode='train'):#mode='train'|'test'print(f"{mode} base file after break.number 1")feats=pl.read_csv(f"/kaggle/input/home-credit-credit-risk-model-stability/csv_files/{mode}/{mode}_base.csv").pipe(set_table_dtypes)feats=feats.drop(['date_decision','MONTH','WEEK_NUM'])print("-"*30)print(f"{mode} applprev_2 file after break. number:1")applprev2=pl.read_csv(f"/kaggle/input/home-credit-credit-risk-model-stability/csv_files/{mode}/{mode}_applprev_2.csv").pipe(set_table_dtypes)applprev2=applprev2.with_columns(#账户没有被冻结,所以没有冻结的原因, 以前没有申请过信用卡,也没有留下联系方式( (pl.col('cacccardblochreas_147M')!=pl.col('cacccardblochreas_147M'))&(pl.col('conts_type_509L')!=pl.col('conts_type_509L')) )\.alias("no_credit")#.cast(pl.Int8))applprev2=applprev2.with_columns(#账户没有被冻结,所以没有冻结的原因,但是申请过信用卡( (pl.col('cacccardblochreas_147M')!=pl.col('cacccardblochreas_147M'))&(pl.col('conts_type_509L')==pl.col('conts_type_509L'))) \.alias("no_frozen_credit").cast(pl.Int8))applprev2=applprev2.with_columns(#有冻结的原因,所以账户被冻结过,也自然有信用卡(pl.col('cacccardblochreas_147M')==pl.col('cacccardblochreas_147M'))\.alias("frozen_credit").cast(pl.Int8))applprev2_last=find_last_case_id(applprev2)"""这些列有些是要取最新的特征,有些是需要groupby.联系方式要最新的看一个人最新状态是不是还没有信用卡有没有信用卡冻结也考虑一下最新状态吧,反正就一个特征.信用卡冻结列特征可以从冻结原因那列构造"""#这里只需要把缺失值填充就可以merge了,后续训练数据和测试数据字符串一起one-hot.last_features=[['conts_type_509L','WHATSAPP'],#WHATSAPP只有1个,那就把NaN当成WHATSAPP吧.['no_credit',0],['no_frozen_credit',0],['frozen_credit',0]]feats=last_features_merge(feats,applprev2_last,last_features)#groupby需要考虑fillna,onehot(对于字符串如果是None就是不要one-hot,直接drop掉,如果要one-hot,搞出个类别的列表),然后groupby,mergegroup_features=[['cacccardblochreas_147M','a55475b1',\["P19_60_110","P17_56_144","a55475b1","P201_63_60","P127_74_114","P133_119_56","P41_107_150","P23_105_103""P33_145_161"]],['credacc_cards_status_52L','UNCONFIRMED',\['BLOCKED','UNCONFIRMED','RENEWED', 'CANCELLED', 'INACTIVE', 'ACTIVE']],['num_group1',0],#'num_group1', 'num_group2',暂时不考虑.['num_group2',0],#'num_group1', 'num_group2',暂时不考虑.]feats=group_features_merge(feats,applprev2,group_features,group_name='applprev2')del applprev2,applprev2_lastgc.collect()#手动触发垃圾回收,强制回收由垃圾回收器标记为未使用的内存print("-"*30)print("credit bureau b num 2")bureau_b_1=pl.read_csv(f"/kaggle/input/home-credit-credit-risk-model-stability/csv_files/{mode}/{mode}_credit_bureau_b_1.csv").pipe(set_table_dtypes)bureau_b_2=pl.read_csv(f"/kaggle/input/home-credit-credit-risk-model-stability/csv_files/{mode}/{mode}_credit_bureau_b_2.csv").pipe(set_table_dtypes)bureau_b_1_last=find_last_case_id(bureau_b_1,id='case_id')bureau_b_2_last=find_last_case_id(bureau_b_2,id='case_id')feats=feats.join(bureau_b_1_last,on='case_id',how='left')feats=feats.join(bureau_b_2_last,on='case_id',how='left')del bureau_b_1,bureau_b_1_last,bureau_b_2,bureau_b_2_lastgc.collect()#手动触发垃圾回收,强制回收由垃圾回收器标记为未使用的内存print(f"{mode} debitcard file after break num 1")#'openingdate_857D':借记卡开户日期.暂时不处理.debitcard=pl.read_csv(f"/kaggle/input/home-credit-credit-risk-model-stability/csv_files/{mode}/{mode}_debitcard_1.csv").pipe(set_table_dtypes)debitcard_last=find_last_case_id(debitcard,id='case_id')last_features=[['last180dayaveragebalance_704A',0],#过去180天内借记卡平均余额,用众数0来填充.['last180dayturnover_1134A',30000],#借记卡过去180天营业额,这里没有特别明显的众数,中位数数填充.['last30dayturnover_651A',0]#用众数0来填充.]feats=last_features_merge(feats,debitcard_last,last_features)group_features=[['num_group1',0]#用众数来填充.]feats=group_features_merge(feats,debitcard,group_features,group_name='debitcard')del debitcard,debitcard_lastgc.collect()#手动触发垃圾回收,强制回收由垃圾回收器标记为未使用的内存print(f"{mode} deposit file num 1")deposit=pl.read_csv(f"/kaggle/input/home-credit-credit-risk-model-stability/csv_files/{mode}/{mode}_deposit_1.csv").pipe(set_table_dtypes)#数值列的特征工程 从1开始是为了把'case_id'去掉 for idx in range(1,len(deposit.columns)):col=deposit.columns[idx]column_type = deposit[col].dtypeis_numeric = (column_type == pl.datatypes.Int64) or (column_type == pl.datatypes.Float64) if is_numeric:#数值列构造特征feat=deposit.group_by('case_id').agg( pl.max(col).alias(f"max_deposit_{col}"),pl.mean(col).alias(f"mean_deposit_{col}"),pl.median(col).alias(f"median_deposit_{col}"),pl.std(col).alias(f"std_deposit_{col}"),pl.min(col).alias(f"min_deposit_{col}"),pl.count(col).alias(f"count_deposit_{col}"),pl.sum(col).alias(f"sum_deposit_{col}"),pl.n_unique(col).alias(f"n_unique_deposit_{col}"),pl.first(col).alias(f"first_deposit_{col}"),pl.last(col).alias(f"last_deposit_{col}"))feats=feats.join(feat,on='case_id',how='left')del depositgc.collect()#手动触发垃圾回收,强制回收由垃圾回收器标记为未使用的内存print(f"{mode} other file after break number 1")other=pl.read_csv(f"/kaggle/input/home-credit-credit-risk-model-stability/csv_files/{mode}/{mode}_other_1.csv").pipe(set_table_dtypes)other_last=find_last_case_id(other)#这里只需要把缺失值填充就可以merge了,后续训练数据和测试数据字符串一起one-hot.last_features=[['amtdepositbalance_4809441A',0]#amtdepositbalance_4809441A:客户存款余额.用众数0来填充.]feats=last_features_merge(feats,other_last,last_features)group_features=[['amtdebitincoming_4809443A',0],#amtdebitincoming_4809443A,0传入借记卡交易金额,用众数0来填充.['amtdebitoutgoing_4809440A',0],#amtdebitoutgoing_4809440A传出借记卡交易金额,用众数0来填充.['amtdepositincoming_4809444A',0], #amtdepositincoming_4809444A客户账户入金金额.众数为0.['amtdepositoutgoing_4809442A',0]#amtdepositoutgoing_4809442A:客户账户出金金额.众数为0.]feats=group_features_merge(feats,other,group_features,group_name='other')del other,other_lastgc.collect()#手动触发垃圾回收,强制回收由垃圾回收器标记为未使用的内存print("person 1 num 1")person1=pl.read_csv(f"/kaggle/input/home-credit-credit-risk-model-stability/csv_files/{mode}/{mode}_person_1.csv").pipe(set_table_dtypes)#缺失值>=0.99的列直接drop掉.person1=person1.drop(['birthdate_87D','childnum_185L','gender_992L','housingtype_772L','isreference_387L','maritalst_703L','role_993L']) person1=person1.select(['case_id','contaddr_matchlist_1032L','contaddr_smempladdr_334L','empl_employedtotal_800L','language1_981M','persontype_1072L','persontype_792L','remitter_829L','role_1084L','safeguarantyflag_411L','sex_738L'])person1_last=find_last_case_id(person1)feats=feats.join(person1_last,on='case_id',how='left')del person1,person1_lastgc.collect()#手动触发垃圾回收,强制回收由垃圾回收器标记为未使用的内存print(f"{mode} person2 file after break number 1")#经过检查person2训练集和测试集对应的列dtype都对应的上person2=pl.read_csv(f"/kaggle/input/home-credit-credit-risk-model-stability/csv_files/{mode}/{mode}_person_2.csv").pipe(set_table_dtypes)#这些特征缺失值占比>=0.96,不用填充,直接drop吧.person2=person2.drop(['addres_role_871L','empls_employedfrom_796D','relatedpersons_role_762T'])#个人地址,地址邮政编码,雇主名字算私人信息,不拿来训练.person2=person2.drop(['addres_district_368M','addres_zip_823M','empls_employer_name_740M'])group_features=[['conts_role_79M','a55475b1',#人员的联系人角色类型.['a55475b1', 'P38_92_157', 'P7_147_157', 'P177_137_98', 'P125_14_176', 'P125_105_50', 'P115_147_77', 'P58_79_51','P124_137_181', 'P206_38_166', 'P42_134_91']],['empls_economicalst_849M','a55475b1',['a55475b1', 'P164_110_33', 'P22_131_138', 'P28_32_178','P148_57_109', 'P7_47_145', 'P164_122_65', 'P112_86_147','P82_144_169', 'P191_80_124']],['num_group1',0],#用众数0填充.['num_group2',0],#用众数0填充.]del person2gc.collect()#手动触发垃圾回收,强制回收由垃圾回收器标记为未使用的内存print(f"static_0 file num 2(3)")#pipe用于在DataFrame上自定义自己的函数static_0_0=pl.read_csv(f"/kaggle/input/home-credit-credit-risk-model-stability/csv_files/{mode}/{mode}_static_0_0.csv").pipe(set_table_dtypes)static_0_1=pl.read_csv(f"/kaggle/input/home-credit-credit-risk-model-stability/csv_files/{mode}/{mode}_static_0_1.csv").pipe(set_table_dtypes)static=pl.concat([static_0_0,static_0_1],how="vertical_relaxed")#垂直合并,并且放宽了数据类型匹配的限制if mode=='test':#如果是测试数据的话还有一个文件static_0_2=pl.read_csv(f"/kaggle/input/home-credit-credit-risk-model-stability/csv_files/{mode}/{mode}_static_0_2.csv").pipe(set_table_dtypes)static=pl.concat([static,static_0_2],how="vertical_relaxed")feats=feats.join(static,on='case_id',how='left')del static,static_0_0,static_0_1gc.collect()#手动触发垃圾回收,强制回收由垃圾回收器标记为未使用的内存print(f"{mode} static_cb_file after break num 1")static_cb=pl.read_csv(f"/kaggle/input/home-credit-credit-risk-model-stability/csv_files/{mode}/{mode}_static_cb_0.csv").pipe(set_table_dtypes)#缺失值占比>=0.95的直接drop掉.static_cb=static_cb.drop(['assignmentdate_4955616D', 'dateofbirth_342D','for3years_128L','for3years_504L','for3years_584L','formonth_118L','formonth_206L','formonth_535L','forquarter_1017L', 'forquarter_462L','forquarter_634L','fortoday_1092L','forweek_1077L','forweek_528L','forweek_601L','foryear_618L','foryear_818L','foryear_850L','pmtaverage_4955615A','pmtcount_4955617L','riskassesment_302T','riskassesment_940T'])static_cb=static_cb.drop(['birthdate_574D','dateofbirth_337D',#两个都是客户的出生日期,暂时不用这个数据.'assignmentdate_238D','assignmentdate_4527235D',#税务机关数据:分配日期和转让日期.'responsedate_1012D','responsedate_4527233D','responsedate_4917613D',#税务机关回复日期有3个特征.])#static_cb中每个case_id都是1个数据,所以需要填充缺失值,然后merge即可.last_features=[ ['contractssum_5085716L',0],#从外部信贷机构检索到的合同价值总额['days120_123L',0],#过去120天信用局查询数,0是众数但是不突出.['days180_256L',0],#过去180天的信用局查询数,0是众数但是不突出.['days30_165L',0],#过去30天的信用局查询数,这里0突出一点.['days360_512L',1],#1略比0多一点.['days90_310L',0],#0稍微多一点.['description_5085714M','a55475b1'],#按信贷局对客户进行分类.10:1的二分类.#['education_1103M','a55475b1'],#外部来源的客户受教育水平,5个类别,['education_88M','a55475b1'],#客户受教育水平.['firstquarter_103L',0],#第一季度从信贷局获得的业绩数量['secondquarter_766L',0],#第二季度的业绩数.['thirdquarter_1082L',0],#第3季度的业绩数量.['fourthquarter_440L',0],#第4季度的业绩数.['maritalst_385M','a55475b1'],#客户的婚姻状况.#['maritalst_893M', 'a55475b1'],#客户的婚姻状况.['numberofqueries_373L',1],#向征信机构查询的数量.['pmtaverage_3A',0],#'税收减免的平均值#['pmtaverage_4527227A',7222.2],#'税收减免的平均值.#['pmtcount_4527229L', 6],#税收减免数量['pmtcount_693L', 6],#'税收减免数量'['pmtscount_423L',6.0],#'税款扣减付款的数量.['pmtssum_45A',0],#客户的税收减免总额.['requesttype_4525192L','DEDUCTION_6'],#税务机关请求类型]feats=last_features_merge(feats,static_cb,last_features)#60天的信用局查询数.feats=feats.with_columns( (pl.col('days180_256L')-pl.col('days120_123L')).alias("daysgap60"))feats=feats.with_columns( (pl.col('days180_256L')-pl.col('days30_165L')).alias("daysgap150"))feats=feats.with_columns( (pl.col('days120_123L')-pl.col('days30_165L')).alias("daysgap90"))#一年的业绩数.feats=feats.with_columns( (pl.col('firstquarter_103L')+pl.col('secondquarter_766L')+pl.col('thirdquarter_1082L')+pl.col('fourthquarter_440L')).alias("totalyear_result"))del static_cbgc.collect()#手动触发垃圾回收,强制回收由垃圾回收器标记为未使用的内存print("-"*30)print(f"{mode} tax_a file after break num 1")tax_a=pl.read_csv(f"/kaggle/input/home-credit-credit-risk-model-stability/csv_files/{mode}/{mode}_tax_registry_a_1.csv").pipe(set_table_dtypes)#雇主名字属于私人信息,表格中的数据很可能是加密过的,所以没什么用.recorddate_4527225D暂时不使用.group_features=[['amount_4527230A',850],#政府登记的税收减免金额,如果有缺失值用众数850填充['num_group1',0]]feats=group_features_merge(feats,tax_a,group_features,group_name='tax_a')del tax_agc.collect()#手动触发垃圾回收,强制回收由垃圾回收器标记为未使用的内存print("-"*30)print(f"{mode} tax_b file after break num 1")tax_b=pl.read_csv(f"/kaggle/input/home-credit-credit-risk-model-stability/csv_files/{mode}/{mode}_tax_registry_b_1.csv").pipe(set_table_dtypes)#雇主名字是私人信息,不能用来训练模型.num_group1,'deductiondate_4917603D'暂时不使用.group_features=[['amount_4917619A',6885],#政府登记处跟踪的税收减免金额,如果有缺失值用众数填充['num_group1',0]]feats=group_features_merge(feats,tax_b,group_features,group_name='tax_b')del tax_bgc.collect()#手动触发垃圾回收,强制回收由垃圾回收器标记为未使用的内存print("-"*30)print(f"{mode} tax_c file after break num 1")tax_c=pl.read_csv(f"/kaggle/input/home-credit-credit-risk-model-stability/csv_files/{mode}/{mode}_tax_registry_c_1.csv").pipe(set_table_dtypes)if len(tax_c)==0:tax_c=pl.read_csv(f"/kaggle/input/home-credit-credit-risk-model-stability/csv_files/train/train_tax_registry_c_1.csv").pipe(set_table_dtypes)#employername_160M:雇主的名字,隐私信息不使用.processingdate_168D:处理税款扣减的日期.tax_c=tax_c.drop(['employername_160M','processingdate_168D'])group_features=[['pmtamount_36A',850],#pmtamount_36A:信贷局付款的税收减免额,用众数850填充['num_group1',0]#0是众数但是并不是特别突出.]feats=group_features_merge(feats,tax_c,group_features,group_name='tax_c')del tax_cgc.collect()#手动触发垃圾回收,强制回收由垃圾回收器标记为未使用的内存print("-"*30)return feats
train_feats=preprocessor(mode='train')
test_feats=preprocessor(mode='test')train_feats=train_feats.to_pandas()
test_feats=test_feats.to_pandas()# 计算每列的众数,忽略含有缺失值的列
mode_values = train_feats.mode().iloc[0]
# 使用众数填充训练集中的缺失值
train_feats = train_feats.fillna(mode_values)
# 使用众数填充测试集中的缺失值
test_feats = test_feats.fillna(mode_values)#对字符串特征列进行独热编码的转换
print("----------string one hot encoder ****")
for col in test_feats.columns:n_unique=train_feats[col].nunique()#如果是类别型变量的话,独热编码转换#如果类别是2类,像性别一样,如果是(0,1)了,或者说数值类型的话,没必要转换.如果是字符串类型的话,转换成数值if n_unique==2 and train_feats[col].dtype=='object':print(f"one_hot_2:{col}")unique=train_feats[col].unique()#随便选择一个类别进行转换,比如gender='Female'train_feats[col]=(train_feats[col]==unique[0]).astype(int)test_feats[col]=(test_feats[col]==unique[0]).astype(int)elif (n_unique<10) and train_feats[col].dtype=='object':#由于内存有限 类别型变量的n_unique设置为10print(f"one_hot_10:{col}")unique=train_feats[col].unique()for idx in range(len(unique)):if unique[idx]==unique[idx]:#这里是为了避免字符串中存在nan值的情况train_feats[col+"_"+str(idx)]=(train_feats[col]==unique[idx]).astype(int)test_feats[col+"_"+str(idx)]=(test_feats[col]==unique[idx]).astype(int)train_feats.drop([col],axis=1,inplace=True)test_feats.drop([col],axis=1,inplace=True)
print("----------drop other string or unique value or full null value ****")
drop_cols=[]
for col in test_feats.columns:if (train_feats[col].dtype=='object') or (test_feats[col].dtype=='object') \or (train_feats[col].nunique()==1) or train_feats[col].isna().mean()>0.99:drop_cols+=[col]
#'case_id'没什么用.
drop_cols+=['case_id']
train_feats.drop(drop_cols,axis=1,inplace=True)
test_feats.drop(drop_cols,axis=1,inplace=True)
print(f"len(train_feats):{len(train_feats)},total_features_counts:{len(test_feats.columns)}")
train_feats.head()#遍历表格df的所有列修改数据类型减少内存使用
def reduce_mem_usage(df, float16_as32=True):#memory_usage()是df每列的内存使用量,sum是对它们求和, B->KB->MBstart_mem = df.memory_usage().sum() / 1024**2print('Memory usage of dataframe is {:.2f} MB'.format(start_mem))for col in df.columns:#遍历每列的列名col_type = df[col].dtype#列名的typeif col_type != object:#不是object也就是说这里处理的是数值类型的变量c_min,c_max = df[col].min(),df[col].max() #求出这列的最大值和最小值if str(col_type)[:3] == 'int':#如果是int类型的变量,不管是int8,int16,int32还是int64#如果这列的取值范围是在int8的取值范围内,那就对类型进行转换 (-128 到 127)if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:df[col] = df[col].astype(np.int8)#如果这列的取值范围是在int16的取值范围内,那就对类型进行转换(-32,768 到 32,767)elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:df[col] = df[col].astype(np.int16)#如果这列的取值范围是在int32的取值范围内,那就对类型进行转换(-2,147,483,648到2,147,483,647)elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:df[col] = df[col].astype(np.int32)#如果这列的取值范围是在int64的取值范围内,那就对类型进行转换(-9,223,372,036,854,775,808到9,223,372,036,854,775,807)elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:df[col] = df[col].astype(np.int64) else:#如果是浮点数类型.#如果数值在float16的取值范围内,如果觉得需要更高精度可以考虑float32if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:if float16_as32:#如果数据需要更高的精度可以选择float32df[col] = df[col].astype(np.float32)else:df[col] = df[col].astype(np.float16) #如果数值在float32的取值范围内,对它进行类型转换elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:df[col] = df[col].astype(np.float32)#如果数值在float64的取值范围内,对它进行类型转换else:df[col] = df[col].astype(np.float64)#计算一下结束后的内存end_mem = df.memory_usage().sum() / 1024**2print('Memory usage after optimization is: {:.2f} MB'.format(end_mem))#相比一开始的内存减少了百分之多少print('Decreased by {:.1f}%'.format(100 * (start_mem - end_mem) / start_mem))return df
train_feats = reduce_mem_usage(train_feats)
test_feats = reduce_mem_usage(test_feats)def pearson_corr(x1,x2):"""x1,x2:np.array"""mean_x1=np.mean(x1)mean_x2=np.mean(x2)std_x1=np.std(x1)std_x2=np.std(x2)pearson=np.mean((x1-mean_x1)*(x2-mean_x2))/(std_x1*std_x2)return pearson
#有没有和target相关性特别高的特征,拿来做逻辑回归
choose_cols=[]
for col in train_feats.columns:if col!='target':pearson=pearson_corr(train_feats[col].values,train_feats['target'].values) if abs(pearson)>0.0025:choose_cols.append(col)
print(f"len(choose_cols):{len(choose_cols)},choose_cols:{choose_cols}")#mean_gini:0.5428968427934477
from sklearn.linear_model import LinearRegressionX=train_feats[choose_cols].copy()
y=train_feats[Config.TARGET_NAME].copy()
test_X=test_feats[choose_cols].copy()
oof_pred_pro=np.zeros((len(X)))
test_pred_pro=np.zeros((Config.num_folds,len(test_X)))
del train_feats,test_feats
gc.collect()#手动触发垃圾回收,强制回收由垃圾回收器标记为未使用的内存#10折交叉验证
skf = StratifiedKFold(n_splits=Config.num_folds,random_state=Config.seed, shuffle=True)for fold, (train_index, valid_index) in (enumerate(skf.split(X, y.astype(str)))):print(f"fold:{fold}")X_train, X_valid = X.iloc[train_index], X.iloc[valid_index]y_train, y_valid = y.iloc[train_index], y.iloc[valid_index]# 创建线性回归模型model = LinearRegression()model.fit(X_train,y_train)oof_pred_pro[valid_index]=model.predict(X_valid)#将数据分批次进行预测.for idx in range(0,len(test_X),Config.batch_size):test_pred_pro[fold][idx:idx+Config.batch_size]=model.predict(test_X[idx:idx+Config.batch_size]) del model,X_train, X_valid,y_train, y_valid#模型用完直接删掉gc.collect()#手动触发垃圾回收,强制回收由垃圾回收器标记为未使用的内存
gini=2*roc_auc_score(y.values,oof_pred_pro)-1
print(f"mean_gini:{gini}")test_preds=test_pred_pro.mean(axis=0)
submission=pd.read_csv("/kaggle/input/home-credit-credit-risk-model-stability/sample_submission.csv")
submission['score']=np.clip(np.nan_to_num(test_preds,nan=0.3),0,1)
submission.to_csv("submission.csv",index=None)
submission.head()
相关文章:

polars as pl
import polars as pl#和pandas类似,但是处理大型数据集有更好的性能. #necessary import pandas as pd#导入csv文件的库 import numpy as np#进行矩阵运算的库 #metric from sklearn.metrics import roc_auc_score#导入roc_auc曲线 #KFold是直接分成k折,StratifiedKFold还要考虑…...
)
重构(4)
(一)添加解释性变量,使得代码更容易理解,更容易调试,也可以方便功能复用 解释性的变量 总价格为商品总价(单价*数量)-折扣(超过100个以上的打9折)邮费(原价的…...
神经网络|(三)线性回归基础知识
【1】引言 前序学习进程中,已经对简单神经元的工作模式有所了解,这种二元分类的工作机制,进一步使用sigmoid()函数进行了平滑表达。相关学习链接为: 神经网络|(一)加权平均法,感知机和神经元-CSDN博客 神经网络|(二…...
deepseek R1 高效使用学习
直接提问 1、可以看到思考过程,可以当个学习工具 2、高效简介代码prompt <context> You are an expert programming AI assistant who prioritizes minimalist, efficient code. You plan before coding, write idiomatic solutions, seek clarification …...

STM32_SD卡的SDIO通信_基础读写
本篇将使用CubeMXKeil, 创建一个SD卡读写的工程。 目录 一、SD卡要点速读 二、SDIO要点速读 三、SD卡座接线原理图 四、CubeMX新建工程 五、CubeMX 生成 SD卡的SDIO通信部分 六、Keil 编辑工程代码 七、实验效果 实现效果,如下图: 一、SD卡 速读…...

【Docker】私有Docker仓库的搭建
一、准备工作 确保您的系统已安装Docker。如果没有安装,请参考Docker官方文档进行安装。 准备一个用于存储仓库数据的目录,例如/registry_data/。 二、拉取官方registry镜像 首先,我们需要从Docker Hub拉取官方的registry镜像。执行以下命…...

linux 管道符、重定向与环境变量
1. 输入输出重定向 在linux工作必须掌握的命令一文中,我们已经掌握了几乎所有基础常用的Linux命令,那么接下来的任务就是把多个命令适当的组合到一起,使其协同工作,会更高效的处理数据,做到这一点就必须搞清楚命令的输…...

Ansible fetch模块详解:轻松从远程主机抓取文件
在自动化运维的过程中,我们经常需要从远程主机下载文件到本地,以便进行分析或备份。Ansible的fetch模块正是为了满足这一需求而设计的,它可以帮助我们轻松地从远程主机获取文件,并将其保存到本地指定的位置。在这篇文章中…...
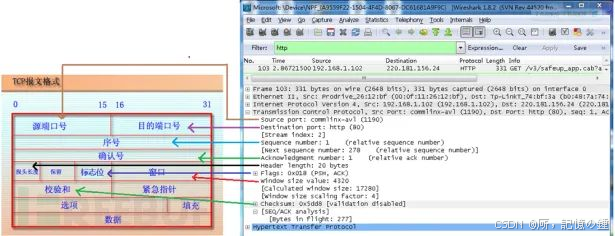
wireshark工具简介
目录 1 wireshark介绍 2 wireshark抓包流程 2.1 选择网卡 2.2 停止抓包 2.3 保存数据 3 wireshark过滤器设置 3.1 显示过滤器的设置 3.2 抓包过滤器 4 wireshark的封包列表与封包详情 4.1 封包列表 4.2 封包详情 参考文献 1 wireshark介绍 wireshark是非常流行的网络…...

51单片机——按键控制LED流水灯
引言 在电子制作和嵌入式系统学习中,51 单片机是一个经典且入门级的选择。按键控制 LED 流水灯是 51 单片机的一个基础应用,通过这个实例,我们可以深入了解单片机的输入输出控制原理。 51 单片机简介 51 单片机是对所有兼容 Intel 8051 指…...

【opencv】第9章 直方图与匹配
第9章 直方图与匹配 9.1 图像直方图概述 直方图广泛运用于很多计算机视觉运用当中,通过标记帧与帧之间显著的边 缘和颜色的统计变化,来检测视频中场景的变化。在每个兴趣点设置一个有相近 特征的直方图所构成“标签”,用以确定图像中的兴趣点。边缘、色…...

HTML5 Web Worker 的使用与实践
引言 在现代 Web 开发中,用户体验是至关重要的。如果页面在执行复杂计算或处理大量数据时变得卡顿或无响应,用户很可能会流失。HTML5 引入了 Web Worker,它允许我们在后台运行 JavaScript 代码,从而避免阻塞主线程,保…...

MVCC底层原理实现
MVCC的实现原理 了解实现原理之前,先理解下面几个组件的内容 1、 当前读和快照读 先普及一下什么是当前读和快照读。 当前读:读取数据的最新版本,并对数据进行加锁。 例如:insert、update、delete、select for update、 sele…...

基于ESP32-IDF驱动GPIO输出控制LED
基于ESP32-IDF驱动GPIO输出控制LED 文章目录 基于ESP32-IDF驱动GPIO输出控制LED一、点亮LED3.1 LED电路3.2 配置GPIO函数gpio_config()原型和头文件3.3 设置GPIO引脚电平状态函数gpio_set_level()原型和头文件3.4 代码实现并编译烧录 一、点亮LED 3.1 LED电路 可以看到&#x…...

【优选算法】9----长度最小的子数组
----------------------------------------begin-------------------------------------- 铁子们,前面的双指针算法篇就算告一段落啦~ 接下来是我们的滑动窗口篇,不过有一说一,算法题就跟数学题一样,只要掌握方法,多做…...

LabVIEW太阳能照明监控系统
在公共照明领域,传统的电力照明系统存在高能耗和维护不便等问题。利用LabVIEW开发太阳能照明监控系统,通过智能控制和实时监测,提高能源利用效率,降低维护成本,实现照明系统的可持续发展。 项目背景 随着能源危机…...

MongoDB中单对象大小超16M的存储方案
在 MongoDB 中,单个文档的大小限制为 16MB。如果某个对象(文档)的大小超过 16MB,可以通过以下几种方案解决: 1. 使用 GridFS 适用场景:需要存储大文件(如图像、视频、文档等)。 原…...

三维激光扫描-用智能检测系统提升效率
当下,企业对生产效率和质量控制的要求越来越高。传统的检测方法往往难以满足高精度、快速响应的需求。三维激光扫描技术结合智能检测系统,为工业检测带来了革命性的变革。 传统检测方法的局限性 传统检测方法主要依赖于人工测量和机械检测工具…...

css遇到的一些问题
1.vw单位,在PC端vw单位是包含右侧滚轮的宽度,而在移动端不会包含滚轮的长度,在PC端运用vw单位进行居中对齐,会比实际偏左盒子偏右一点,因为内容区域并不包含滚轮。 2.运用媒体查询进行响应式布局式,媒体查询…...

【langgraph】ubuntu安装:langgraph:未找到命令
langgraph 在ubuntu24.04 参考:langgraph运行:报错: (05_ep_dev) root@k8s-master-pfsrv:/home/zhangbin/perfwork/01_ai/05_ep_dev/expert# langgraph dev langgraph:未找到命令查看langraph的安装情况 pip show langgraph...

AMLP框架实战:基于MACE构建高精度机器学习势函数
1. 项目概述:当机器学习势函数遇上自动化管道在计算化学和材料科学领域,我们长久以来面临着一个核心矛盾:精度与效率的权衡。密度泛函理论(DFT)能提供接近实验的精度,但计算成本高昂,通常只能处…...

AI赋能5G核心网故障诊断:从PCAP解析到智能根因分析的工程实践
1. 项目概述:当AI遇见5G核心网故障诊断在5G核心网的运维与测试一线干了这么多年,最头疼的莫过于面对海量的PCAP抓包文件。一个复杂的信令流程下来,动辄几千甚至上万个数据包,工程师需要像侦探一样,逐帧审视协议交互&am…...

利用DiSEqC协议与AVR单片机驱动卫星天线电机改造户外设备
1. 项目概述:用卫星天线电机驱动一切如果你手头有一些需要承受风吹日晒、还得精确转动的设备,比如一个户外的大型定向天线,或者一个需要定期调整角度的太阳能板支架,甚至是一个坚固的监控云台,你可能会为驱动机构发愁。…...

Redis分布式锁进阶第二十篇
一、本篇前置衔接 第二十篇我们完成了全系列终局复盘,整理了故障排查SOP与企业级落地铁律。常规单资源锁、热点分片锁、隔离锁全部讲透,但真实复杂业务永远不是单一资源:下单要扣库存、扣优惠券、扣积分、冻结余额,多资源并行争抢…...

别只拿PotPlayer看片了!挖掘它的采集录制功能,做Switch游戏存档大师
别把PotPlayer当普通播放器!解锁它的Switch游戏录制黑科技 你是否已经厌倦了在OBS、Bandicam等专业录制软件中反复调试参数的繁琐?是否想过那个每天用来看视频的PotPlayer,其实隐藏着令人惊喜的游戏录制能力?今天,我们…...
做电影评论情感分类)
告别数据饥荒:用PyTorch手把手实现原型网络(Prototypical Networks)做电影评论情感分类
告别数据饥荒:用PyTorch手把手实现原型网络做电影评论情感分类 在自然语言处理领域,情感分析一直是热门研究方向,但现实中的开发者常面临一个尴尬困境:标注数据太少。传统深度学习方法动辄需要成千上万的标注样本,而实…...
)
告别SVN恐惧症:美术策划也能轻松上手的Unity PlasticSCM极简入门(附团队项目拉取实战)
告别SVN恐惧症:美术策划也能轻松上手的Unity PlasticSCM极简入门(附团队项目拉取实战) 在游戏开发团队中,版本控制系统是协作的基石,但传统工具如SVN往往让非技术成员望而生畏。当美术资源频繁更新、策划案不断迭代时&…...

C++ vector容器总结
vector基本概念功能:vector数据结构和数组非常相似,也称为单端数组vector与普通数组区别:不同之处在于数组是静态空间,而vector可以动态扩展动态扩展:并不是在原空间之后续接新空间,而是找更大的内存空间&a…...

基于GSM与Arduino的远程控制系统:DIY电话控制与短信报警方案
1. 项目概述与核心价值如果你曾经想过,在离家几十公里外,仅凭一部普通的手机,就能远程打开家里的车库门、查看门窗是否关好,甚至在异常情况发生时让系统自动打电话给你报警,那么这个基于GSM的远程控制系统项目…...

InVideo插件深度解析:如何在Unreal Engine中实现高效视频流播放与录制
InVideo插件深度解析:如何在Unreal Engine中实现高效视频流播放与录制 【免费下载链接】InVideo 基于UE4实现的rtsp的视频播放插件 项目地址: https://gitcode.com/gh_mirrors/in/InVideo InVideo是一个基于Unreal Engine 5开发的RTSP视频播放插件࿰…...